数据爬取后台(PHP+Python)联合作战
一. 项目声明
本项目从前端,到后台,以及分布式数据抓取,乃我一个人所写,因此项目并不太完善!在语义分析以及数据处理上并不能尽如意。但是极大的减轻了编辑的工作量!
二. 项目所用技术
本项目中前端采用bootstrap栅格系统布局,后台服务端语言采用PHP,数据抓取所用Python完成 (scrapy/requests/BeautifulSoup/threading/selenium/jieba)
三. 项目说明
1.拿到对应的关键词 -〉从百度知道 找出 对应的问题;
2.得到对应的问题 -〉搜全网,排名前10篇的文章(过滤掉百度知道的文章正文,通过特征库过滤一些官网与专题页面等)
3.得到的对应正文 -〉将得到的文章,进行去头,去尾。随机拼接!
4.数据处理-〉用遗忘算法,对处理数据进行筛选,过滤品牌词! (目前暂未完善,避免误删除,导致文本不通顺,目前只是标红,训练该特征模型)
5.本项目基于多线程!可扩展成多进程(因为不考虑效率,加之本机电脑配置较低,所以采用的是单进程下的多线程!)
四. 项目仍需完善之处
1.文本语义不通顺,不能完全机器识别运用(任然需要人工审核),特征库不完善。
2.过滤品牌词,仍然存在有一些特殊的品牌词过滤不掉的问题
3.没有实现无监督学习,对自然语言分析(NLP)任然不熟悉!导致这些问题,无法解决!
五.该项目需要准备
1.IP代理池来源于(免费IP提供商)
2.下载github开源的分词库(jieba)
3.采用selenium抓取,充分模拟浏览器行为,因此要有一个无头浏览器作为工具
六.项目截图:

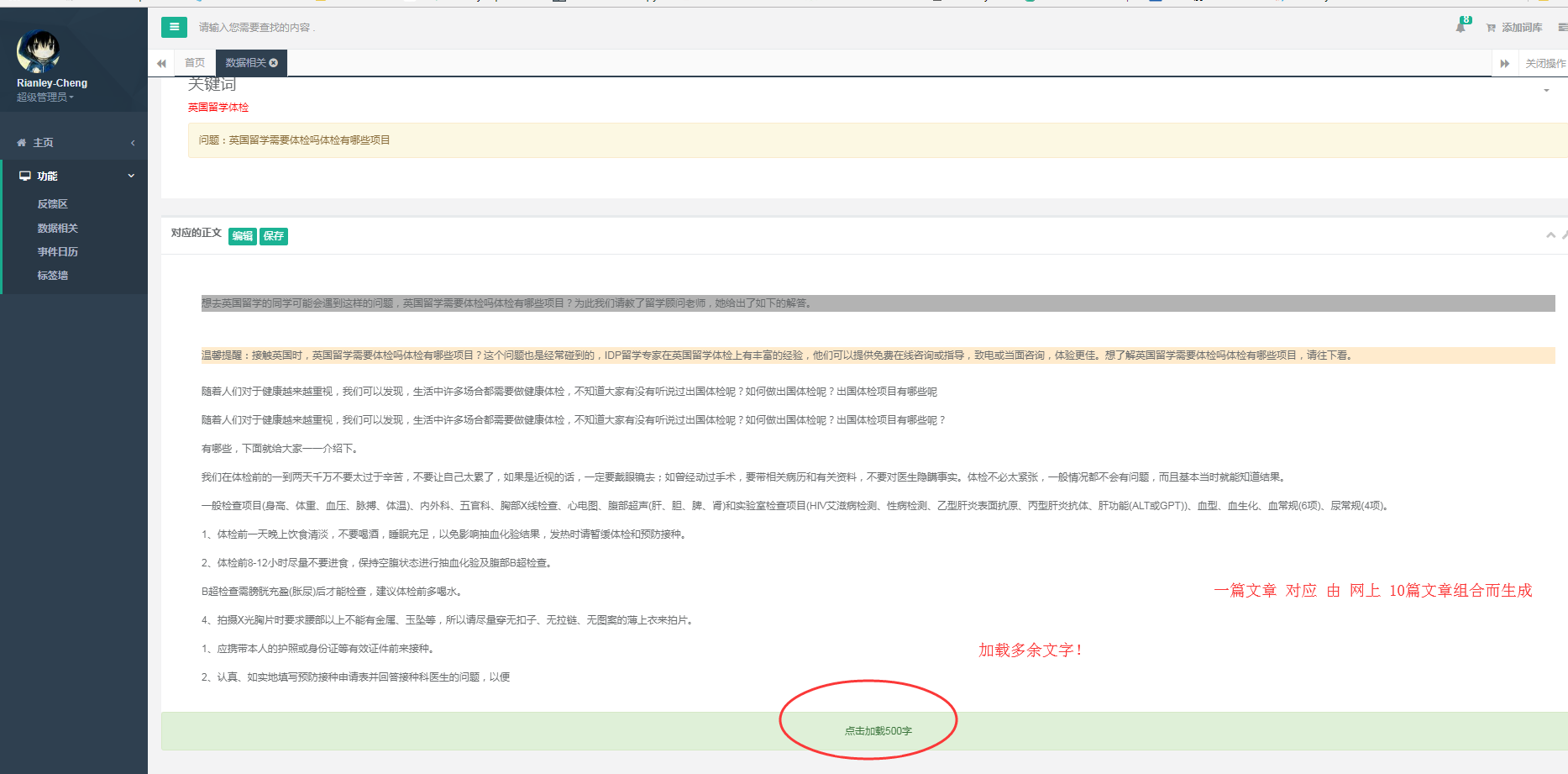
七.结言:
本项目仍处于开发阶段,希望各位自然语言处理的大佬,能给予一些数据清洗方面的帮助!感激不尽!
公司项目,暂不提供源码... 仅探讨思路!
联系Email:rianleycheng@gmail.com
联系QQ:2855132411

 浙公网安备 33010602011771号
浙公网安备 33010602011771号