
《算法问题实战策略》-chaper32-网络流
基本的网络流模型:
在图论这一块初步的应用领域中,两个最常见的关注点,其一时图中的路径长度,也就是我们常说的的最短路径问题,另一个则是所谓的“流问题”。
流问题的基本概念:
首先给出一张图。
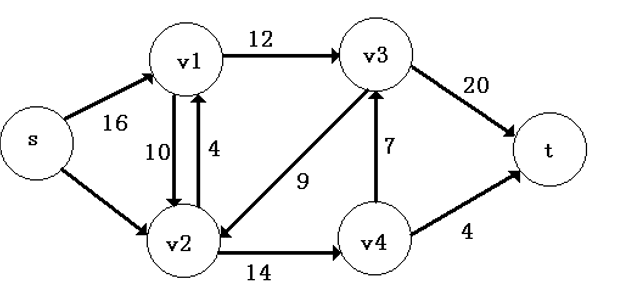
其实所谓“网络流”,其模型是非常有现实意义的。我们将该图视为计算机网络结构。此图中,s称其为源点而t称其为汇点。这个图中剩余的源泉代表网络设备,连接个顶点的边线表示连接两个设备的数据线缆,边的权值表示这条线缆能够传输的最大数据。
首先我们应该能够注意到,有向路径<s,t>就是一条传输路线,而这条传输数据的流的大小x,满足x = min{|e| | e ∈<s,t>},|e|表示边e的权值。这一点很好理解,它是基于基本的物理现实的。
通过我们已经学习过的知识,我们容易找到一条路径权值最大的<s,t>,因为我们知道最短路径怎么求嘛,最长路也是一样的。但是在这里仅仅找到一条最长路径显然是不能满足我们的需求的。因为我们发现在一个图结构中,我们仅仅通过一个最长路径进行传输,往往不如多个相对较短的路径进行“联合传输”的效果好,因此,我们现在面临的问题就是,如何找到一个网络流模型中的最大流呢?
在解决这个问题之前,我们先对这个模型进行更加量化的描述。
设此处有两个顶点u,v,定义c(u,v)表示从u到v的容量,f(u,v)表示从u到v的实际流量。基于这种定义,我们能够看出网路的流一定会满足如下的几个性质:
(1) 容量限制性:f(u,v)≤c(u,v)
(2) 流量对称性:f(u,v) = -f(v,u)
(3) 流量守恒:对于顶点u,经过该点的所有流的和为0
求解最大流的Ford-Fulkerson算法:
我们可以遍历所有的路径<s,t>,然后记录总流量,但是这样我们面临一个问题,如果在这个过程中我们访问的一条边之后便标记不再访问的话,对于某些边,当f(u,v)<<c(u,v)的时候就造成了资源的浪费,没有很好地体现出“最优”策略。因此在这里我们要很自然的引出一个新的量r<u,v>用来表示u到v剩余的流量空间,即有如下的等式成立。
r(u,v) = f(u,v) – c(u,v).
那么这样我们在每次遍历的时候,只需要在每条边的r值上做出改动,就能够很好的弥补上面的缺憾。
但是我们还是无法很好的保证这个过程的最优性,比如给出下面一个反例。

(0/2中分子表示实际流量,分母表示容量)
能够看到实线标注出来当前不满足最大流要求的路径,面对这种“岔口情况”,选择不当往往会“堵塞通路”,我们应该如何应对呢?
在这里我们巧妙的利用最大流的方向性。拿上图来举例子,当出现这种某条路径被单独孤立出去的情况时,我们假想b到a有一条路径,为什么可以这么做呢?因为如果我们想要求r(b,a),会发现有r(b,a) =f(b,a) – c(b,a) = 0 – (-1) = 1.也就是说这里<b,a>路径练一条通路都没有,但是现在却存在了大小为1的剩余流量?因为这里<a,b>的流减少就等效于<b,a>的流增加,而此前<a,b>的流恰好是1.这样我们在下次寻找通路<s,t>的时候,就对得到<s,b,a,t>这条路径,与此同时我们发现<a,b>和<b,a>之间互通流数据并没有什么意义,因此我们就可以排除掉路径<a,b>,通过这种“假想流通路”的等效方法,我们能够很好地解决搜索输出流<s,t>可能会引起的“阻隔道路”的问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号