
Bootstrap,Bagging and Random Forest Algorithm
Bootstrap Method:在统计学中,Bootstrap从原始数据中抽取子集,然后分别求取各个子集的统计特征,最终将统计特征合并。例如求取某国人民的平均身高,不可能测量每一个人的身高,但却可以在10个省市,分别招募1000个志愿者来测量并求均值,最终再求取各省市的平均值。
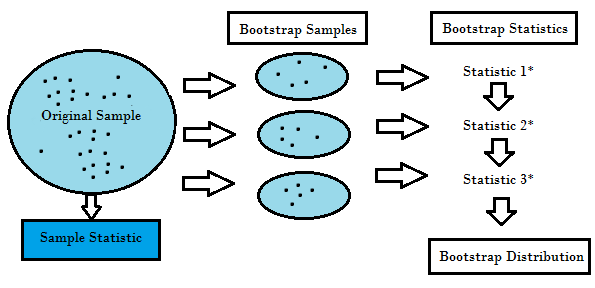
Bagging(Bootstrap Aggregating):应用了 Bootstrap的思想,从Training Set抽取k次subset,分别用来训练k个单独的模型,然后用这k个模型来做预测。最终,如果是Regression问题,则Average k个模型的输出;如果是Classification问题,则进行Majority Vote。
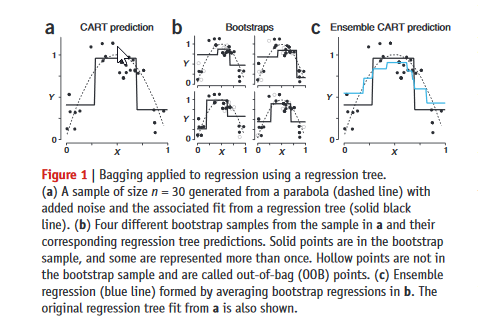
Example:Bagged Decision Trees.引用自Springer Nature的文章‘Ensemble methods: bagging and random forests’。我们可以看到,图a中的数据点,是根据抛物线图(虚线)叠加噪音而生成。如果直接采用CART Decision Tree,拟合模型如图a的实线;图b给出了4个Bootstraps分别的拟合图像;图c的蓝线则是将4个Bootstrap进行了平均,更好的还原了抛物线图像。
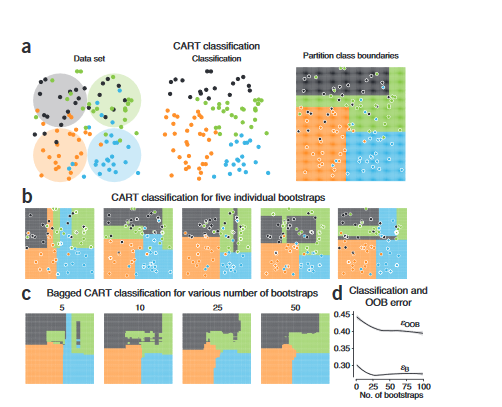
其中εB是对bags内部数据的差错曲线,而εOOB则是对Out-Of-Bag数据的测评。OOB在这里的作用类似于Cross Validation。
Random Forest: 和Bagged Decision Tree的大体结构十分相似,Random Forest也是对Training Set进行k次随机抽样、种树、再求取平均(Majority Vote)。但Random Forest修改了Decision Tree中Greedy Search的部分:Decision Tree在每次分割时,会考虑所有的feature,然后选择最佳分割点;Random Forest为了增加随机性,在分割时使用1/3*D( regression), sqrt(D)(classification)的features来做选择,由此也减少了属于书之间的关联性。
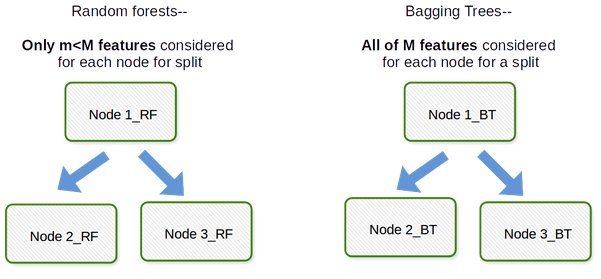
所以说,Bagged Decision Tree只有一个参数,那就是树的数量;而Random Forest却有两个参数:树的数量,以及分割时feature的数量。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号