
Decision Tree Algorithm
Decision Tree算法的思路是,将原始问题不断递归地细分为子问题,直到子问题直接可获得答案为止。在模型训练的过程中,根据训练集去做树的生长(Grow the tree),生长所有可能的Branches,最终达到叶子节点(leaf nodes)。在预测过程中,则遍历树枝,去寻找和预测目标最相近的叶子。
构建决策树模型:
而在构建过程中的主要问题是,选择数据集的哪个feature来做分割。这里用到了Greedy Search。形象地说,每走一步,都选择当前情况下最好的路径,而不管下一步如何或几步之后如何。那么,定义什么是“最好”,有三个标准:ID3,C4.5和Gini index。
ID3:计算信息增益(Information Gain),即分割前后熵值的差,差值越大,则我们在分割过程中,获得的信息量就越大:
Entropy of the target datase:
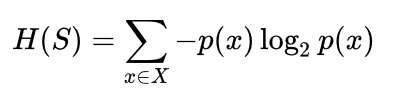
Information Gain by a split:

C4.5:和ID3相似,但采取的是信息增益率(Information Gain Ratio),避免了通过将数据集分割为无限多个从而获得最大信息增益的极限情况:
切割信息量(feature_A将集合S分割为若干个sj):
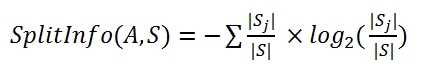
信息增益率=信息增益/切割信息量
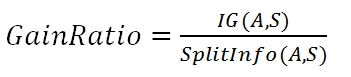
在ID3和C4.5算法中,构建树时需要选择Information Gain或Gain Ratio最大的feature.
CART:与前面两种算法不同,CART计算的是Gini系数。Gini如果为0,说明集合纯净,Gini大则说明集合离散度高。所以我们选择,使Gini系数最小的feature来生成枝叶。同时,在算法比较中,Gini算法没有logrithm的存在,计算速度会更快:
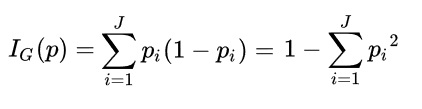
选择ID3, C4.5和CART中的一个标准来递归的生成树,即可完成建模。
利用决策树做预测:
在预测时,根据target example的feature取值,在现有决策树的枝叶路径中搜寻最匹配的路径。如果存在相同的路径,perfect!直接找出输出值。如果不存在,卡在了某个分叉路口,那么就对该分岔路口下的所有节点进行投票,来取得最大可能性的输出值。
问题思考:
如果我的Training Set足够大,同时其多样性也足够,那么在训练过程中生成的决策树就会枝叶茂盛、十分复杂。同时带来的问题就是,过于细枝末节的决策树,会完美拟合训练集,但对于测试集的预测会大打折扣。这是典型的Overfitting,这时就要对决策树进行修剪,具体原理请见下篇博文。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号