
Temporal-Difference Control: SARSA and Q-Learning
SARSA
SARSA algorithm also estimate Action-Value functions rather than State-Value function. The difference between SARSA and Monte Carlo is: SARSA does not need to wait the actual return untill the end of the episode, instead it learns from each time step using estimations of the return.
In every step, the agent takes an action A from state S, then it receives a reward R and gets to a new state S'. Based on the policy π, we know the algorithm will greedily pick the action A'. So now we have:S,A,R,S',A', and the task is to estimate Q function of S,A pair.

We borrow the idea of estimating State-Value functions and use it onto Action-Value function estimation, then we get:
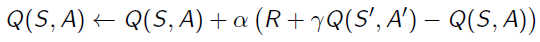
Here is the Sudo code for SARSA:

On-Policy vs Off-Policy
If we look into the learning process, there are actually two steps, firstly taking an action A from state S based on policy π, geting the reward R, and the next state S' coming; the second step is using the Q-function of action A' followd the same policy π. Both of the two steps use the same policy π, but actually they can be different. On the first step, the policy is called Target Policy, which is the policy that we will update. The second policy is Behavior Policy, this is how we pick the oprimal action from S'. Q-Learning uses different Policies on the two steps.
Q-Learning
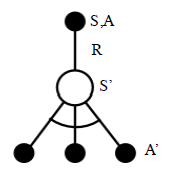
From state S', Q-Learning algorithm picks the action maximizing the Q-function. It stands at state S', looking into all possible actions, and then chooses the best one.
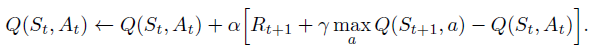


 浙公网安备 33010602011771号
浙公网安备 33010602011771号