
Dynamic Programming and Policy Evaluation
Dynamic Programming divides the original problem into subproblems, and then complete the whole task by recursively conquering these subproblems. The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies. It assumes the full knowledge of the environment: someone tells us the state space, action space, transition struction, the reward structure, discounted factor...
We start with policy evaluation: given the MDP and an arbitary Policy π, we use Bellman Equation to recursively calculate the State-Value function:
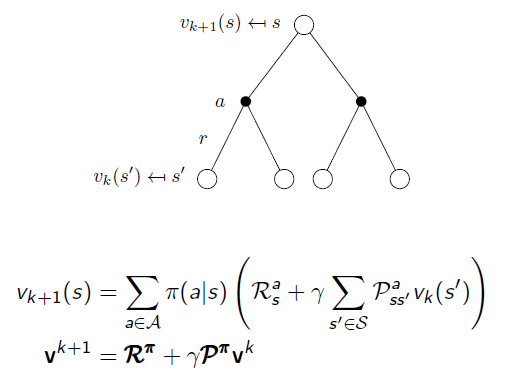
And the policy evaluation algorithm is given by following:

The stop criteria is only very small change for the value state function.
The example is a GridWorld puzzle, the task is to reach grey cell with most reward. The policy for the possible actions (up,down,left,right) are equivalent, all 25%.
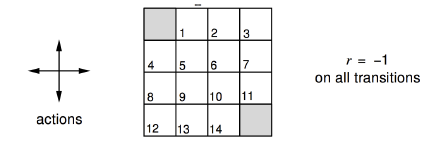
Like a random walk, after calculation, we got :


 浙公网安备 33010602011771号
浙公网安备 33010602011771号