
Hadoop: 在Azure Cluster上使用MapReduce
Azure对于学生账户有260刀的免费试用,火急火燎地创建Hadoop Cluster!本例子是使用Hadoop MapReduce来统计一本电子书中各个单词的出现个数.
Let's get hands dirty!
首先,我们在Azure中创建了一个Cluster,并且使用putty Ssh访问了该集群,ls一下:
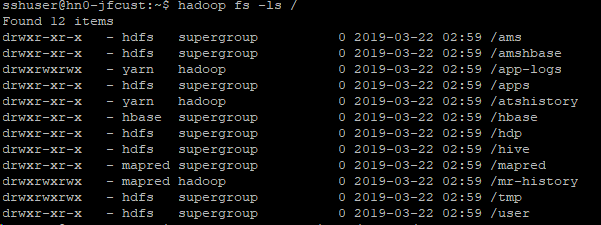
在cluster上创建一个/home/hduser/文件夹

OK,接下来在本地创建一个mapper.py文件和reducer.py文件,注意权限:chmod +x reducer.py(mapper.py)
mapper.py代码
#!/usr/bin/env python
"""mapper.py"""
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word, 1)
reducer.py代码
#!/usr/bin/env python
"""reducer.py"""
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
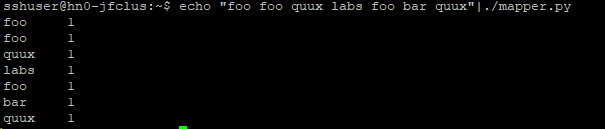
本地mapper.py测试: echo "foo foo quux labs foo bar quux" | ./mapper.py
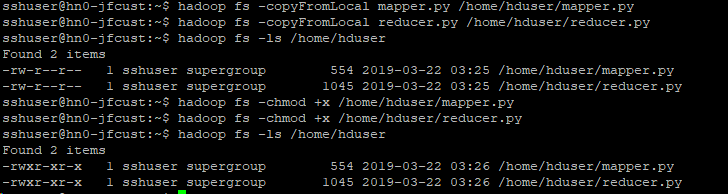
并复制到Cluster上:
本例中,我们使用一本电子书,地址是http://www.gutenberg.org/cache/epub/20417/pg20417.txt,直接在linux客户端下载后,上传到cluster中
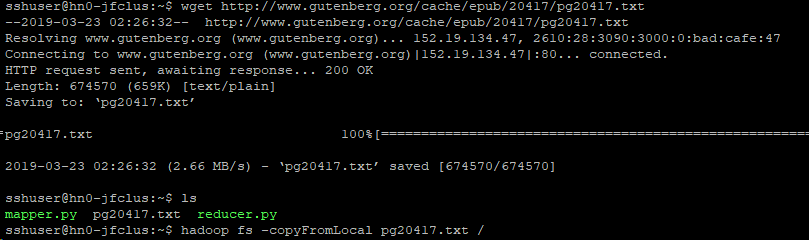
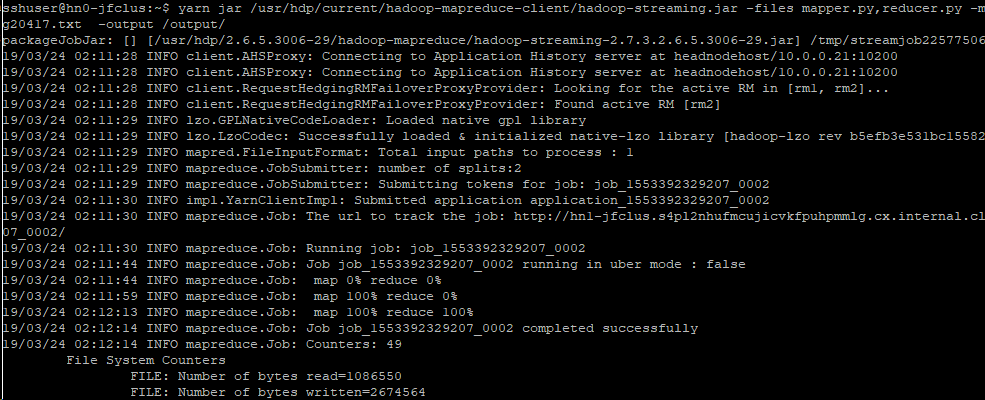
OK,万事俱备,运行MapReduce
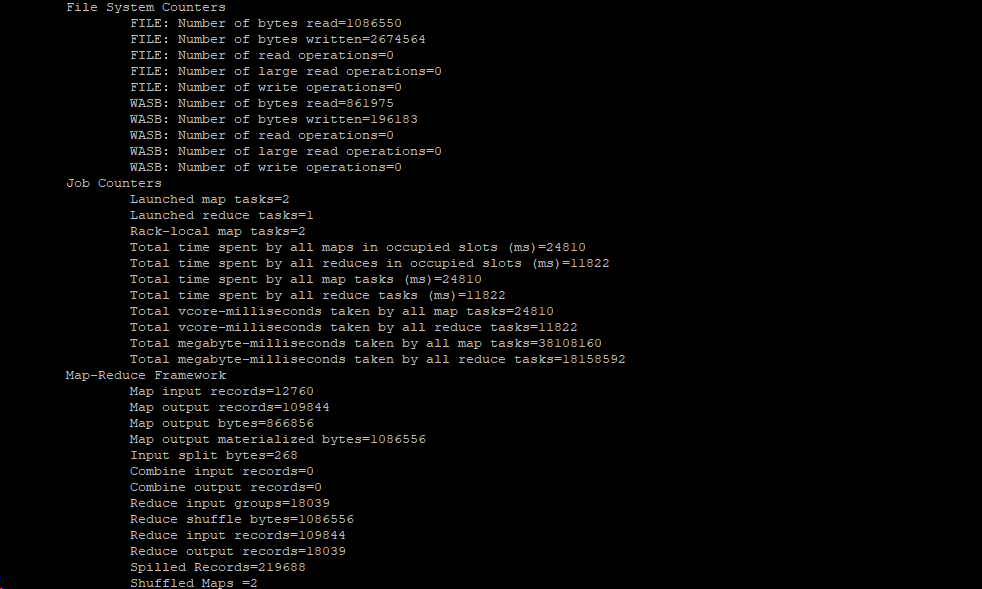

查看输出文件前20行

相关参考文章:
http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
https://docs.microsoft.com/en-us/azure/hdinsight/hadoop/apache-hadoop-streaming-python
http://hadooptutorial.info/hdfs-file-system-commands/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号