
MapReduce(1): Prepare input for Mappers
According to Wikipedia MapReduce, there are two ways to illustrate MapReduce. One contains three steps: Map, Shuffle and Reduce; Another one with 5 steps is my preference:
a. Prepare the Map() input,
b. Run the user-provided Map() code
c. "Shuffle" the Map output to the Reduce processors,
d. Run the user-provided Reduce() code,
e. Produce the final output
This blog focuses on how to prepare the Map() input:
1. Block and InputSplit:
As shown in the HDFS blogs, super huge dataset is physically stored in HDFS. But Mappers do not directly process physical blocks, instead InputSplits converts the physical representation of the block into logical for the Hadoop Mappers.
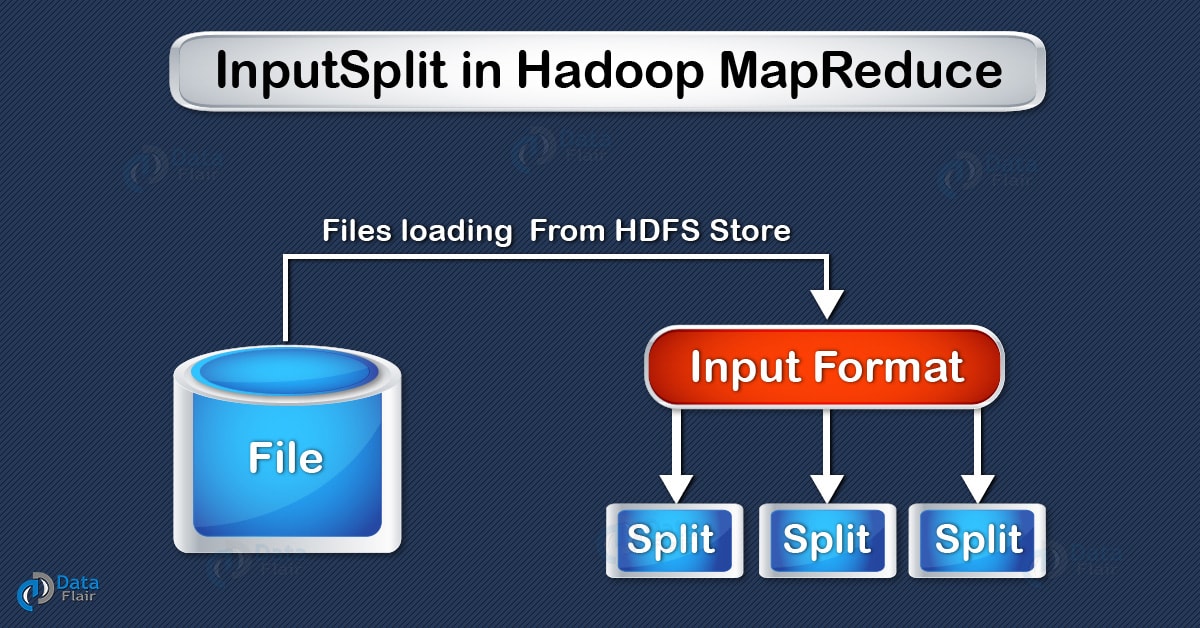
InputSplit is the logical representation of data. It describes a unit of work that contains a single map task in a MapReduce program. It is created by InputFormat. FileInputFormat, by default, breaks a file into 128MB chunks (same as blocks in HDFS),framework assigns one split to each Map function. Inputsplit does not contain the input data; it is just a reference to the data.

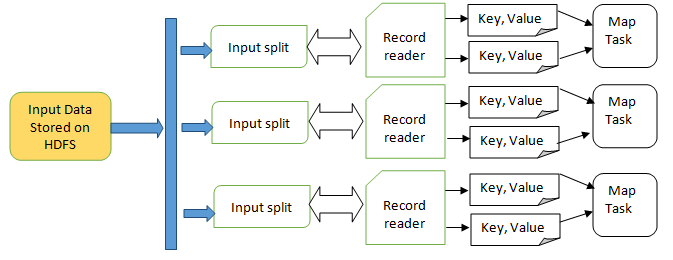
2. RecordReader:
It determines how an InputSplit is passed into a Map function. The RecordReader instance is defined by the InputFormat. By default, it uses TextInputFormat for converting data into a key-value pair. TextInputFormat provides 2 types of RecordReaders: LineRecordReader, SequenceFileRecordReader
References:
https://hadoopabcd.wordpress.com/2015/03/10/hdfs-file-block-and-input-split/
https://en.wikipedia.org/wiki/MapReduce
https://data-flair.training/blogs/shuffling-and-sorting-in-hadoop/
https://zhuanlan.zhihu.com/p/34849261
https://www.edureka.co/blog/mapreduce-tutorial/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号