
Hadoop(1): HDFS基础架构
1. What's HDFS?
Hadoop Distributed File System is a block-structured file system where each file is divided into blocks of a pre-determined size. These blocks are stored across a cluster of one or several machines. Apache Hadoop HDFS Architecture follows a Master/Slave Architecture, where a cluster comprises of a single NameNode (Master node) and all the other nodes are DataNodes (Slave nodes). In the practical world, these DataNodes are spread across various machines.
2. Basic ideas of HDFS
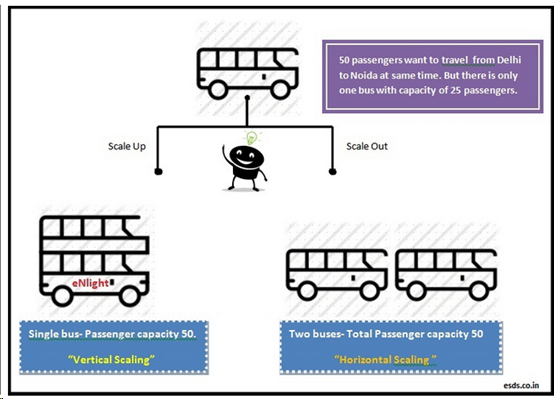
a.面向大数据:当需要存储巨大的数据集时,有两个选择:其一是所谓的Scale Up or Vertical Scaling,也就是升级你的单机存储空间,并且将该数据集放置在这个单独的存储空间中;其二是Scale Out or Horizontal Scaling,使用多个存储空间,将数据集分割成子集,存放在不同的地方。例如下图:当一辆荷载25人的Bus,坐不下50人时的解决方案:
b.数据存储于Commodity Hardware:使用普通商业硬件存储数据,意味着硬件Failure是正常状态之一,而不是异常,文件系统需要有容错能力(fault tolerance)。所以HDFS中的文件会被复制多份,备份存储于不同的硬件中。
c.数据块(Blocks):HDFS将大数据集,分割成默认为128m的Block进行存储,除最后一个Block之外,其余的Block大小相同。
d.流数据(Streaming Data Access):HDFS采用的并非是面向日常运营活动的OLTP(OnLine Transaction Processing)模式,而是面向分析的OLAP (OnLine Analytical Processing),其基本思想是一次写入,多次读取(Write-Once-Read-Only)
3. Master/Slave Architecture:
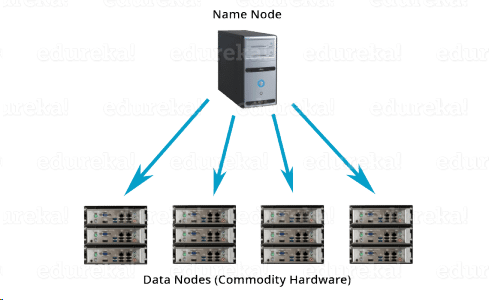
a. Name Node (Master)
每个集群(Cluster)有1至2个Name Node,对集群内数据块存储和分布进行管理。Name Node只存储Metadata,而不存储任何用户数据(User data never resides on the NameNode. The data resides on DataNodes only.)。Master Deamon会在Name Node上面运行,用于管理Data Node。在Metadata中存储着Cluster中所有block的存储位置、大小以及filesystem的变更记录(FsImage,EditLogs)。
b.Data Node (Slave)
每个Cluster中,有众多Data Node,用来存储数据。每个Data Node是一个Commodity Hardware,即性能无法保证,访问失败属于正常状态。Slave Deamon会在Data Node上面运行,并且周期性地向Name Node上报Heartbeat(3s).
4. Blocks:Hadoop将超大文件分割为一个个的Blocks,然后将各个Blocks分散到Cluster的各个Data Nodes中。除最后一个Block外,各个Blocks都有相同的大小(128m)。见下图的例子。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号