
mysql 尚硅谷版
最基本的select语句
SELECT 字段1,字段2,... FROM 表名
列的别名:as:全称:alias(别名),可以省略,列的别名可以使用一对""引起来
去重:DISTINCT
空值参与运算:null不等同于0,'','null',空值参与运算结果一定也为空
着重号:``,用于标识字段,表名(如果表名和字段名与关键字重名)
查询常数:每一行都会匹配常数
显示表结构:DESCRIBE(DESC) 表名;
过滤数据: where
运算符
算术运算符:+ - * / %
比较运算符
符号运算符
= 等于 判断两个值、字符串或表达式是否相等 0='a' 1 null=1 null
<=> 安全等于 安全判断两个值、字符串或表达式是否相等(与=的区别是可对null可进行判断)
<>(!=) 不等于运算符 判断两个值、字符串或表达式是否不相等
< <= > >=
非符号运算符:
IS NULL 为空运算符
IS NOT NULL 不为空运算符
LEAST 最小值运算符
GREATEST 最大值运算符
BETWEEN AND 两值之间运算符
ISNULL 为空运算符
IN 属于运算符
NOT IN 不属于运算符
LIKE 模糊匹配运算符 %:标识任意多个字符 _:表示任意一个单个字符
REGEXP 正则表达式运算符
关于正则表达式:
1.'^'匹配以该字符后面的字符开头的字符串
2.'$'匹配以该字符前面的字符节位的字符串
3.'.'匹配任何一个单字符
4."[...]"匹配再方括号内的任何字符。例如:"[abc]"匹配"a"或"b"或"c"。为了命名字符的范围,使用一个'-'。"[a-z]"匹配任何字母,而"[0-9]"匹配任何数字
5.'*'匹配灵蛊蛾或多个在 它前面的字符。例如"x*"匹配任何数量的'x'字符,"[0-9]*"匹配任何数量的数字,而"*"匹配任何数量的字符串"
6.{9}表示前面必须出现9次
逻辑运算符 NOT ! AND %% OR || XOR(逻辑异或)
AND的优先级高于OR
位运算符 & | & ~ >> <<
排序与分页
排序
使用ORDER BY 子句排序 ASC(ascend):升序 DESC(descend):降序。
ORDER BY子句在SELECT语句的结尾。
如果在ORDER BY后没有显示指明排序的方式的话,则默认按照升序排列。
也可以使用列的别名进行排序 列的别名只能在ORDER BY中使用,不能在WHERE中使用。
在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序
分页
LIMIT子句必须放在整个SELECT语句的最后。
LIMIT pageSize*pageNum-1,pageNo; #每页显示pageSize条数据,此时显示pageNo页
8.0新特性:LIMIT 2 OFFSET 31;只获取32、33条数据
多表查询
笛卡尔积(交叉连接): 笛卡尔乘积是一个数学运算。假设我有两个集合X和Y,那么X和Y的笛卡尔积就是X和Y的所有可能组合,也就是第一个对象来自于X,第二个对象来自于Y的所有可能。组合的个数即为两个集合中元素个数的乘积数。
多表查询的正确方式:需要有连接的条件
如果查询语句中出现了多个表中都存在的字段,则必须指明此字段所在的表(从SQL优化的角度,建议多表查询时,每个字段前都指明其所在的表)
可以在where中给使用表的别名,而不能在使用表的原名
如果有n个表实现多表的查询,则需要至少n-1个连接条件
多表连接欸的分类
等值连接 vs 非等值连接
非等值连接:查询 条件不用"=",等值连接,查询条件用"="
自连接 vs 非自连接
自连接:自己和自己连接,给自己起两个别名,非自连接:自己跟其他连接
内连接 vs 外连接
内连接:合并具有同一列的两个以上表的行,结果集中不包含一个表与另一个表不匹配的行 inner join on
外连接:合并具有同一列的两个以上表的行,结果集中除了包含一个表与另一个表的行之外,还查询到了左表或右表中不匹配的行。
外连接分为,左外连接 left join,右外连接 right join、满外连接 FULL OUTER join on(MYSQL不支持)
左外连接:两个表在连接过程中除了返回满足连接条件的行意外还返回坐标中不满足条件的行,这种连接称为左外连接,反之称为右外连接
满外连接:(UNION)
合并查询结果:
利用UNION关键字,可以给出多条SELECT语句,并将它们的结果组合成单个结果集。合并时,两个表对应的列数和数据类型必须相同,并且相互对应。各个SECELT语句之间使用UNION或UNION ALL关键字分隔
SELECT COLUMN,... FROM table1
UNION [ALL]
Select column,... FROM table2
UNION:操作符返回两个查询的结果集的并集,去除重复的记录
UNION ALL:操作符返回两个查询结果集的丙级,对于两个结果集的重复部分,不去重。
执行UNION ALL语句所需要的资源比UNION语句少,如果明确知道合并数据后的结果数据不存在重复的数据,或者不需要去除重复的数据,则尽量使用UNION ALL语句,以提高数据查询效率
NATURAL JOIN:它会帮你自动查询两个表中所有相同的字段,然后进行等值连接
USING:替换连接条件,需要在()中填入同名的字段
强制:超过三个表禁止join,需要join的字段,数据类型保持绝对一致,多表关联查询时,保证被关联的字段需要有索引。
单行函数
数值函数
基本函数:
| 函数 | 用法 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| SIGN(x) | 返回x的符号,正数返回1,负数返回-1,0返回0 |
| PI() | 返回圆周率的值 |
| CEIL(x),CEILING(x) | 返回大于或等于某个值的最小整数 |
| FLOOR(x) | 返回小于或等于某个值的最大整数 |
| LEAST(e1,e2,e3) | 返回列表中的最小值 |
| GREATEST(e1,e2,e3) | 返回列表中的最大值 |
| MOD(x,y) | 返回X除以y后的余数 |
| RAND() | 返回0-1的随机值 |
| RAND(x) | 返回0-1的随机值,其中x的值用作种子值,相同x值会产生相同的随机数 |
| ROUND(x) | 返回一个对x的值进行四舍五入后,最接近X的整数 |
| ROUND(x,y) | 返回一个对x值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| SQRT(x) | 返回x的平方根,当x的值位负数时,返回NULL |
三角函数:
| 函数 | 用法 |
|---|---|
| SIN(x) | 返回x的正弦值,其中,参数x为弧度值 |
| ASIN(x) | 返回x的反正弦值,及获取正弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| COS(x) | 返回x的余弦值,其中x为弧度值 |
| ACOS(x) | 返回x的反余弦值,急获取余弦为x的值。如果x的值不在-1到1之间,则返回NULL |
| TAN(x) | 返回x的正切值,即返回正切值为x的值 |
| ATAN(x) | 返回x的反正切值,即返回正切为x的值 |
| ATAN2(m,n) | 返回两个参数的反正切值 |
| COT(x) | 返回x的余切值,其中X为弧度 |
| RADIANS(x) | 将角度转换为弧度,其中x为角度值 |
| DEGREES(x) | 将弧度转换为角度,其中参数为弧度值 |
指数和对数:
| 函数 | 用法 |
|---|---|
| POW(x,y),POWER(x,y) | 返回x的y次方 |
| EXP(x) | 返回e的X次方,其中e是一个常数,2.718281828459045 |
| LN(x),LOG(x) | 返回以e为底x的对数,当x<=10时,返回的结果为NULL |
| LOG10(x) | 返回以10为底x的对数,当x<=10时,返回的结果为NULL |
| LOG2(x) | 返回以1为底x的对数,当x<=10时,返回的结果为NULL |
进制间的转换:
| 函数 | 用法 |
|---|---|
| BIN(x) | 返回x的二进制编码 |
| HEX(x) | 返回x的十六进制编码 |
| OCT(x) | 返回x的八进制编码 |
| CONV(x,f1,f2) | 返回f1进制数变成f2进制数 |
字符串函数:
| 函数 | 用法 |
|---|---|
| ASCII(s) | 返回字符串s中第一个字符的ASCII码值 |
| CHAR_LENGTH(s) | 返回字符串s的字符数 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| CONCAT(s1,s2,...,sn) | 连接s1,s2,...,sn为一个字符串 |
| CONCAT_WS(x,s1,s2,...,sn) | 同上一个函数,但是每个字符串之间要加上x |
| INSERT(str,idx,len,replacestr) | 将字符串str从第idx位置开始,len个字符场的字符串替换为字符串replacestr |
| REPLACE(str,a,b) | 用字符串b替换字符串str中所有出现的字符串a |
| UPPER(s)或UCASE(s) | 将字符串s的所有字母转换成大写 |
| LOWER(s)或LCASE(s) | 将字符串s的所有字母转换成小写字母 |
| LEFT(str,n) | 返回字符串str最左边的n个字符 |
| RIGHT(str,n) | 返回字符串str最右边的n个字符 |
| LPAD(str,len,pad) | 用字符串pad对str最左边进行填充,知道str长度为len个字符,可以实现右对齐 |
| RPAD(str,len,pad) | 用字符串pad对str最右边进行填充,知道str长度为len个字符,可以实现左对齐 |
| LTRIM(s) | 去掉字符串s左侧的空格 |
| RTRIM(s) | 去掉字符串s右侧的空格 |
| TRIM(s) | 去掉字符串s开始于结尾的空格 |
| TRIM(s1 FROM s) | 去掉字符串s开始于末尾的s1 |
| TRIM(LEADING s1 FROM s) | 去掉字符串开始处的s1 |
| REPEAT(str,n) | 去掉字符串s结尾处的s1 |
| SPACE(n) | 返回n个空格 |
| STRCMP(s1,s2) | 比较字符串s1,s2的ASCII码值大小 |
| SUBSTR(s,index,len) | 返回从字符串s的index位置其len个字符,作用域SUBSTRING(s,n,len)、MID(s,n,len)相同 |
| LOCATE(substr,str) | 返回字符串substr在字符串str中国你首次出现的位置,作用于POSITION(substr IN str)、INSTR(str,substr)相同,未找到返回0 |
| ELT(m,s1,s2,...,sn) | 返回指定位置的字符串,如果m=1,则返回s1,如果m=2,则返回s2,如果m=n,则返回sn |
| FIELD(s,s1,s2...,sn) | 返回字符串s在字符串列表中给你第一次出现的位置 |
| FIND_IN_SET(s1,s2) | 返回字符串s1在字符串s2中国你出现的位置。其中,字符串s2是一个以逗号分隔的字符串。 |
| REVERSE(s) | 返回s反转后的字符串 |
| NULLIF(value1,value2) | 比较两个字符串,如果value1和value2相等,则返回NULL,否则返回value1 |
日期和时间函数
| 函数 | 用法 |
|---|---|
| CURDATE(),CURRENT_DATE() | 返回当前日期,只包含年、月、日 |
| CURTIME(),CURRENT_TIME() | 返回当前时间,只包含时、分、秒 |
| NOW()/SYSDATE()/CURRENT_TIMESTAMP()/LOCALTIME()/LOCALTIMESTAMP() | 返回当前系统日期和时间 |
| UTC_DATE() | 返回UTC世界标准时间,日期 |
| UTC_TIME() | 返回UTC(世界标准时间)时间 |
| UNIX_TIMESTAMP() | 以UNIX时间戳形式返回当前时间。 |
| UNIX_TIMESTAMP(date) | 将时间date以UNIX时间戳的形式返回 |
| FROM_UNIXTIME(timestamp) | 将UNIX时间戳的时间转换为普通格式的时间 |
| YEAR(date)/MONTH(date)/DAY(date) | 返回具体的日期值 |
| HOUR(time)/MINUTE(time)/SECOND(time) | 返回具体的时间值 |
| MONTHNAME(date) | 返回月份(January) |
| DAYNAME(date) | 返回星期几:MONDAY,TUESDAY...SUNDAY |
| WEEKDAY(date) | 返回周几,周一是0,周日是6 |
| QUARTER(date) | 返回日期对应的季度,范围为1-4 |
| WEEK(date),WEEKOFYEAR(date) | 返回一年中的第几周 |
| DAYOFYEAR(date) | 返回日期是一年中的第几天 |
| DAYOFMONTH(date) | 返回日期位于所在月份的第几天 |
| DAYOFWEEK(date) | 返回周几, 注意:周日是1,周六是7 |
| EXTRACT(type FROM date) | 返回指定日期中对特定的部分,type指定返回的值。type有:MICROSECOND(毫秒值),QUARTER(季度)SECOND,MINUTE,HOUR,DAY,WEEK,MONTY,YEAR 以及上边的组合比如HOUR_MINUTE |
| TIME_TO_SEC(time) | 将time转化为秒并返回结果只,转化公式为:小时*3600+分钟*60+秒 |
| SEC_TO_TIME(secods) | 将secods描述转化为i包含小时、分钟和秒的时间 |
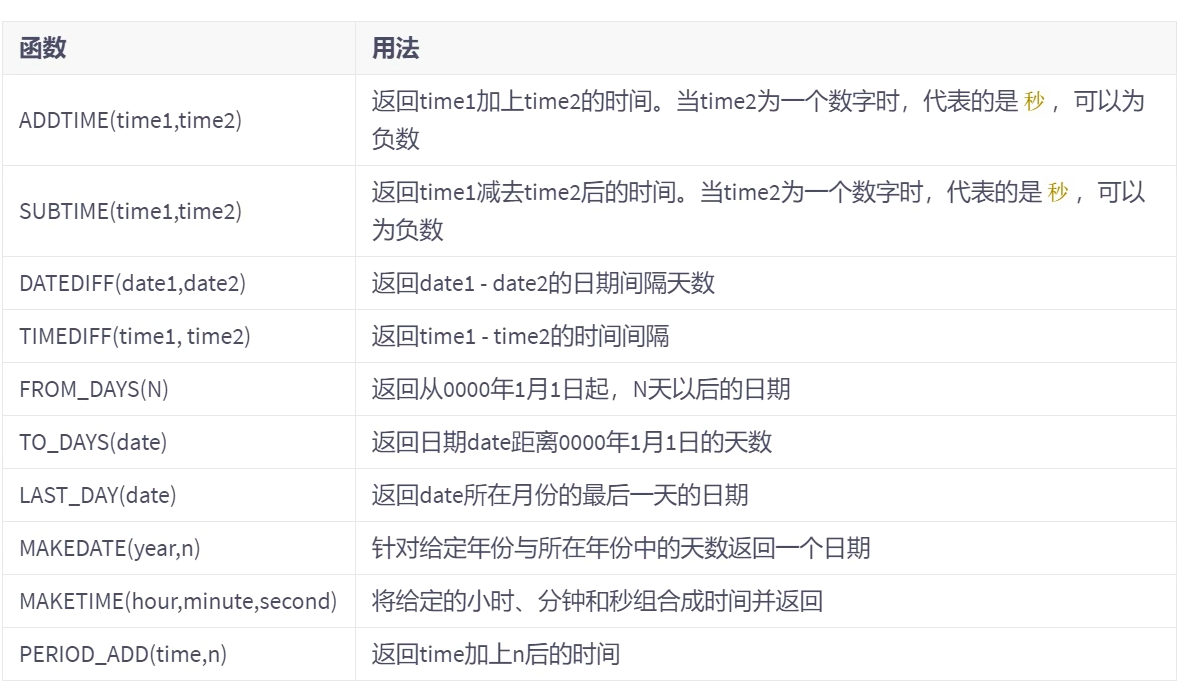
| DATE_ADD(datetime,INTERVAL expr type),ADDDATE(date,INTERVAL expr type) | 返回与给定日期时时间相差INTERVAL时间段的日期时间 |
| DATE_SUB(date,INTERVAL expr type),SUBDATE(date,INTERVAL expr type) | 返回与date相差INTERVAL时间相隔的日期 |
 |
|
 |
|
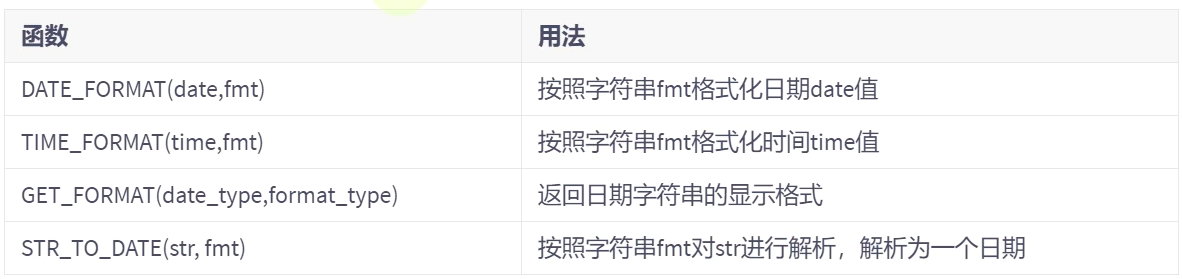
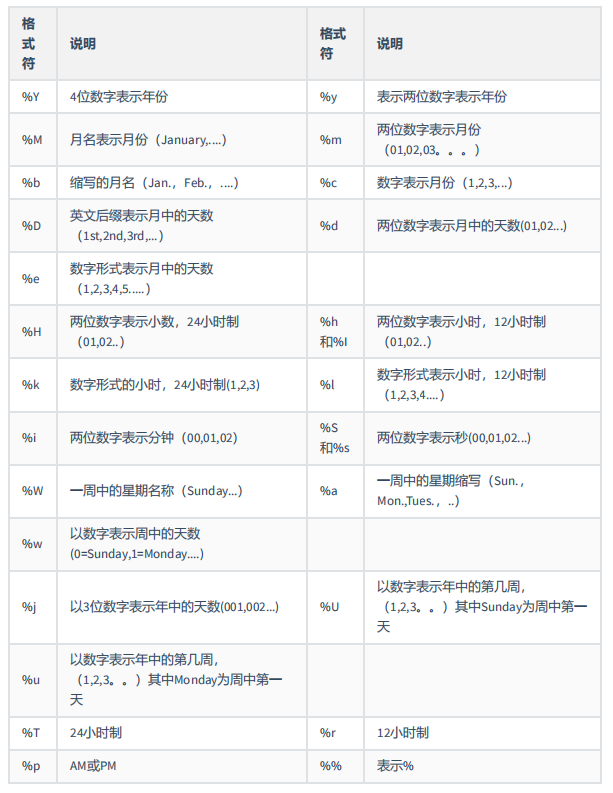
| 上述 非GET_FORMAT 函数中fmt参数常用的格式符: | |
 |
|
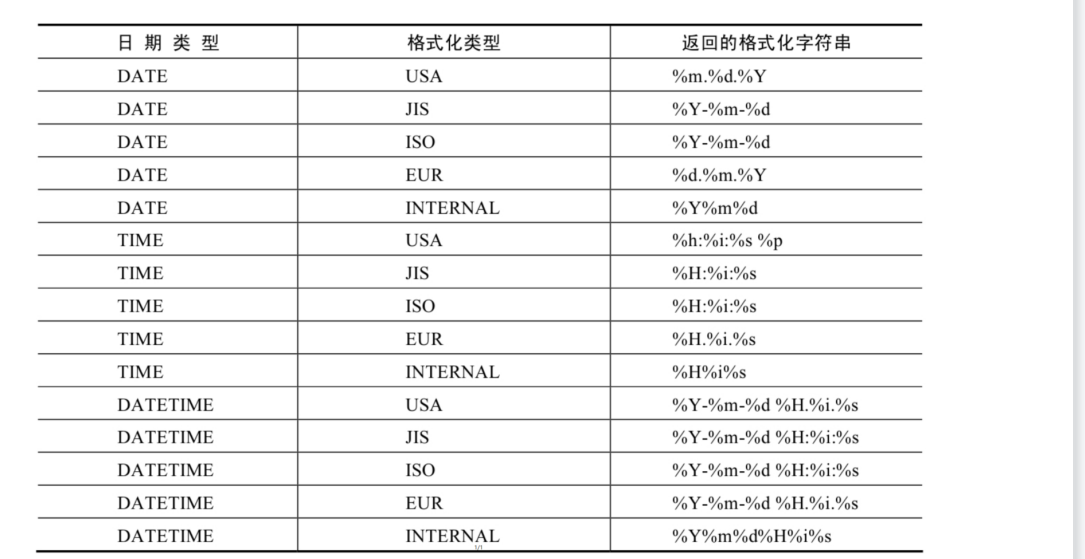
| GET_FORMAT函数中date_type和format_type参数取值如下: | |
 |
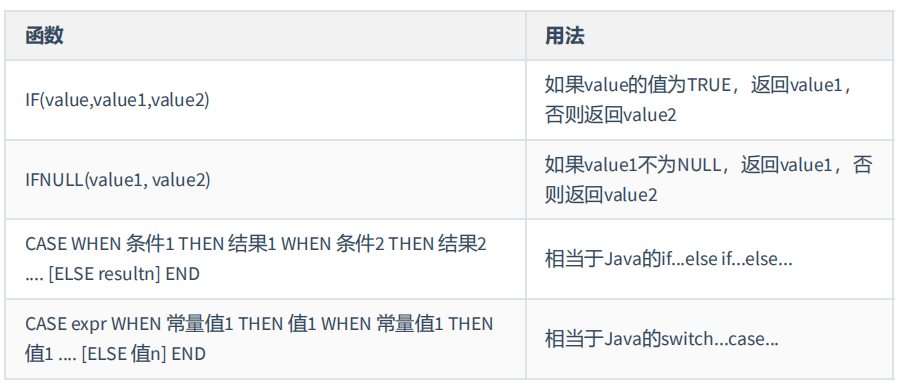
流程控制函数:
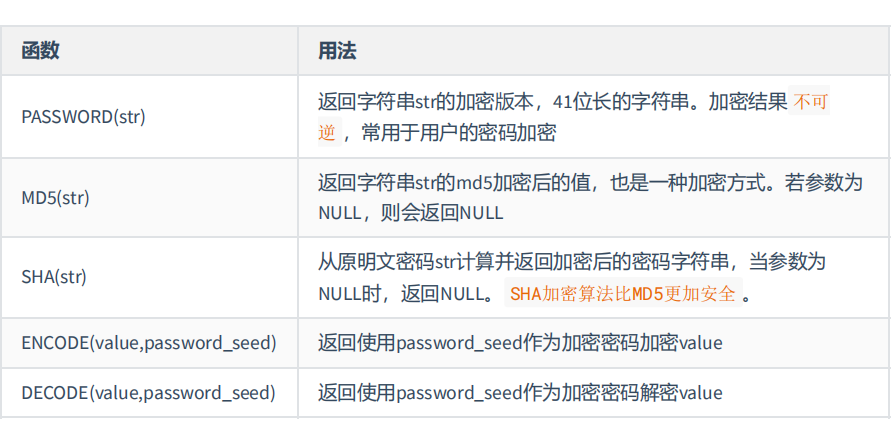
加密与解密函数:
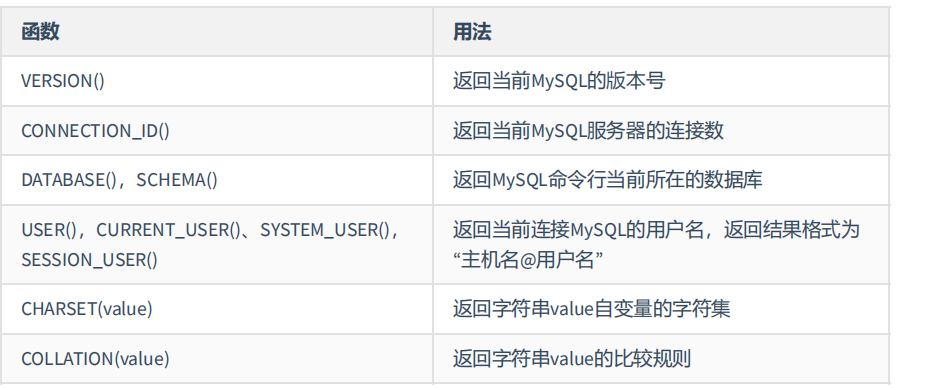
MYSQL信息函数:
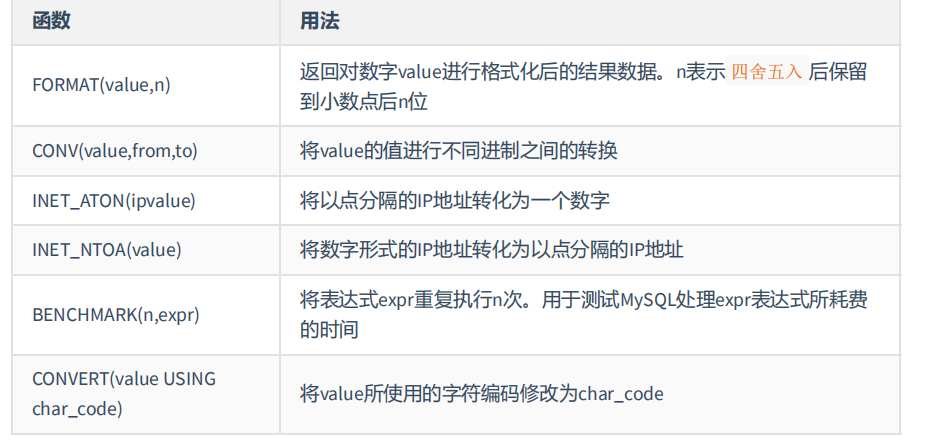
其他函数
聚合函数
可以对数值型数据使用AVG 和 SUM 函数。可以对任意数据类型的数据使用 MIN 和 MAX 函数,COUNT(*)返回表中记录总数,适用于任意数据类型,COUNT(expr) 返回expr不为空的记录总数。
问题:用count(*),count(1),count(列名)谁好呢?
其实,对于MyISAM引擎的表是没有区别的。这种引擎内部有一计数器在维护着行数。
Innodb引擎的表用count(*),count(1)直接读行数,复杂度是O(n),因为innodb真的要去数一遍。但好于具体的count(列名)。
问题:能不能使用count(列名)替换count(*)?
不要使用 count(列名)来替代 count(*) , count(*) 是 SQL92 定义的标准统计行数的语法,跟数据库无关,跟 NULL 和非 NULL 无关。
说明:count(*)会统计值为 NULL 的行,而 count(列名)不会统计此列为 NULL 值的行。
GROUP BY
可以使用GROUP BY子句将表中的数据分成若干组
SELECT column, group_function(column)
FROM table
[WHERE condition]
[GROUP BY group_by_expression]
[ORDER BY column];
在SELECT列表中所有未包含在组函数中的列都应该包含在 GROUP BY子句中。
包含在 GROUP BY 子句中的列不必包含在SELECT 列表中。
可使用多个列分组。
GROUP BY中使用WITH ROLLUP。使用 WITH ROLLUP 关键字之后,在所有查询出的分组记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量
注意:当使用ROLLUP时,不能同时使用ORDER BY子句进行结果排序,即ROLLUP和ORDER BY是互相排斥的。
HAVING
1.行已经被分组。2. 使用了聚合函数。3. 满足HAVING 子句中条件的分组将被显示。4. HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
WHERE和HAVING的对比:
区别1:WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
区别2:如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
SELECT的执行过程
# 方式1:
SELECT ...,....,...
FROM ...,...,....
WHERE 多表的连接条件
AND 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
# 方式2:
SELECT ...,....,...
FROM ... JOIN ...
ON 多表的连接条件
JOIN ...
ON ...
WHERE 不包含组函数的过滤条件
AND/OR 不包含组函数的过滤条件
GROUP BY ...,...
HAVING 包含组函数的过滤条件
ORDER BY ... ASC/DESC
LIMIT ...,...
# 其中:
#(1)from:从哪些表中筛选
#(2)on:关联多表查询时,去除笛卡尔积
#(3)where:从表中筛选的条件
#(4)group by:分组依据
#(5)having:在统计结果中再次筛选
#(6)order by:排序
#(7)limit:分页
关键字的顺序是不能颠倒的:SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...
SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT
子查询
语法结构:
SELECT select_list FROM table WHERE expr operator (SELECT select_list FROM table);
子查询(内查询)在主查询之前一次执行完成。子查询的结果被主查询使用。
子查询要包含在括号内,将子查询放在比较条件的右侧,单行操作符对应单行子查询,多行操作符对应多行子查询
我们按内查询的结果返回一条还是多条记录,将子查询分为 单行子查询、多行子查询 。
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为 关联子查询 。
from型的子查询:子查询是作为from的一部分,子查询要用()引起来,并且要给这个子查询取别名, 把它当成一张“临时的虚拟的表”来使用。
EXISTS 与 NOT EXISTS关键字:
关联子查询通常也会和 EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。
如果在子查询中不存在满足条件的行:条件返回 FALSE继续在子查询中查找
如果在子查询中存在满足条件的行:不在子查询中继续查找条件返回 TRUE
NOT EXISTS关键字表示如果不存在某种条件,则返回TRUE,否则返回FALSE。
创建表和管理表
创建数据库
方式1:创建数据库 CREATE DATABASE 数据库名;
方式2:创建数据库并指定字符集 CREATE DATABASE 数据库名 CHARACTER SET 字符集;
方式3:判断数据库是否已经存在,不存在则创建数据库( 推荐 )CREATE DATABASE IF NOT EXISTS 数据库名;
如果MySQL中已经存在相关的数据库,则忽略创建语句,不再创建数据库。
注意:DATABASE 不能改名。一些可视化工具可以改名,它是建新库,把所有表复制到新库,再删
旧库完成的。
使用数据库
查看当前所有的数据库:SHOW DATABASES; #有一个S,代表多个数据库
查看当前正在使用的数据库 SELECT DATABASE(); #使用的一个 mysql 中的全局函数
查看指定库下所有的表 SHOW TABLES FROM 数据库名;
查看数据库的创建信息 SHOW CREATE DATABASE 数据库名;
使用/切换数据库 USE 数据库名;
修改数据库
更改数据库字符集:ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
删除数据库
方式1:删除指定的数据库 DROP DATABASE 数据库名;
方式2:删除指定的数据库( 推荐 ) DROP DATABASE IF EXISTS 数据库名;
创建表
CREATE TABLE [IF NOT EXISTS] 表名(
字段1, 数据类型 [约束条件] [默认值],
字段2, 数据类型 [约束条件] [默认值],
字段3, 数据类型 [约束条件] [默认值],
……
[表约束条件]
);
查看数据表结构: SHOW CREATE TABLE 表名\G
修改表
追加一个列:ALTER TABLE 表名 ADD 【COLUMN】 字段名 字段类型 【FIRST|AFTER 字段名】;
修改一个列:ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
重命名一个列:ALTER TABLE 表名 CHANGE 【column】 列名 新列名 新数据类型;
删除一个列:ALTER TABLE 表名 DROP 【COLUMN】字段名
重命名表
RENAME TABLE emp TO myemp
ALTER table dept RENAME [TO] detail_dept; -- [TO]可以省略
删除表
在MySQL中,当一张数据表 没有与其他任何数据表形成关联关系 时,可以将当前数据表直接删除。
数据和结构都被删除
所有正在运行的相关事务被提交
所有相关索引被删除
语法格式: DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n];
清空表
TRUNCATE TABLE语句:删除表中所有的数据 释放表的存储空间
数据处理之增删改
INSERT INTO 表名 VALUES (value1,value2,....);
INSERT INTO 表名(column1 [, column2, …, columnn]) VALUES (value1 [,value2, …, valuen]);
INSERT INTO table_name
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
INSERT INTO table_name(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
UPDATE table_name
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
DELETE FROM table_name [WHERE <condition>];
约束
非空约束
CREATE TABLE 表名称(
字段名 数据类型,
字段名 数据类型 NOT NULL,
字段名 数据类型 NOT NULL
);
alter table 表名称 modify 字段名 数据类型 not null;
# 删除非空约束:
alter table 表名称 modify 字段名 数据类型 NULL;#去掉not null,相当于修改某个非注解字段,该字段允许为空
或
alter table 表名称 modify 字段名 数据类型;#去掉not null,相当于修改某个非注解字段,该字段允许为空
唯一性约束
create table 表名称(
字段名 数据类型,
字段名 数据类型 unique,
字段名 数据类型 unique key,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] unique key(字段名)
);
# 字段列表中如果是一个字段,表示该列的值唯一。如果是两个或更多个字段,那么复合唯一,即多个字段的组合是唯
一的
#方式1:
alter table 表名称 add unique key(字段列表);
#方式2:
alter table 表名称 modify 字段名 字段类型 unique;
复合唯一约束:
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
unique key(字段列表) #字段列表中写的是多个字段名,多个字段名用逗号分隔,表示那么是复合唯一,即多个字段的组合是唯一的
)
PRIMARY KEY 约束
用来唯一标识表中的一行记录。
一个表最多只能有一个主键约束,建立主键约束可以在列级别创建,也可以在表级别上创建。
主键约束对应着表中的一列或者多列(复合主键)
如果是多列组合的复合主键约束,那么这些列都不允许为空值,并且组合的值不允许重复。
MySQL的主键名总是PRIMARY,就算自己命名了主键约束名也没用。
当创建主键约束时,系统默认会在所在的列或列组合上建立对应的主键索引(能够根据主键查询的,就根据主键查询,效率更高)。如果删除主键约束了,主键约束对应的索引就自动删除了。
需要注意的一点是,不要修改主键字段的值。因为主键是数据记录的唯一标识,如果修改了主键的值,就有可能会破坏数据的完整性。
建表时指定主键约束:
create table 表名称(
字段名 数据类型 primary key, #列级模式
字段名 数据类型,
字段名 数据类型
);
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
[constraint 约束名] primary key(字段名) #表级模式
);
ALTER TABLE 表名称 ADD PRIMARY KEY(字段列表); #字段列表可以是一个字段,也可以是多个字段,如果是多个字段的话,是复合主键
# 复合主键
create table 表名称(
字段名 数据类型,
字段名 数据类型,
字段名 数据类型,
primary key(字段名1,字段名2) #表示字段1和字段2的组合是唯一的,也可以有更多个字段
);
删除主键约束:alter table 表名称 drop primary key;
自增列:AUTO_INCREMENT
create table 表名称(
字段名 数据类型 primary key auto_increment,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 unique key auto_increment,
字段名 数据类型 not null default 默认值,,
primary key(字段名)
);
alter table 表名称 modify 字段名 数据类型 auto_increment;
alter table 表名称 modify 字段名 数据类型; #去掉auto_increment相当于删除
DEFAULT约束
create table 表名称(
字段名 数据类型 primary key,
字段名 数据类型 unique key not null,
字段名 数据类型 unique key,
字段名 数据类型 not null default 默认值,
);
create table 表名称(
字段名 数据类型 default 默认值 ,
字段名 数据类型 not null default 默认值,
字段名 数据类型 not null default 默认值,
primary key(字段名),
unique key(字段名)
);
说明:默认值约束一般不在唯一键和主键列上加
alter table 表名称 modify 字段名 数据类型 default 默认值;
#如果这个字段原来有非空约束,你还保留非空约束,那么在加默认值约束时,还得保留非空约束,否则非空约束就被删除了
#同理,在给某个字段加非空约束也一样,如果这个字段原来有默认值约束,你想保留,也要在modify语句中保留默认值约束,否则就删除了
alter table 表名称 modify 字段名 数据类型 default 默认值 not null;
