

03 并发篇
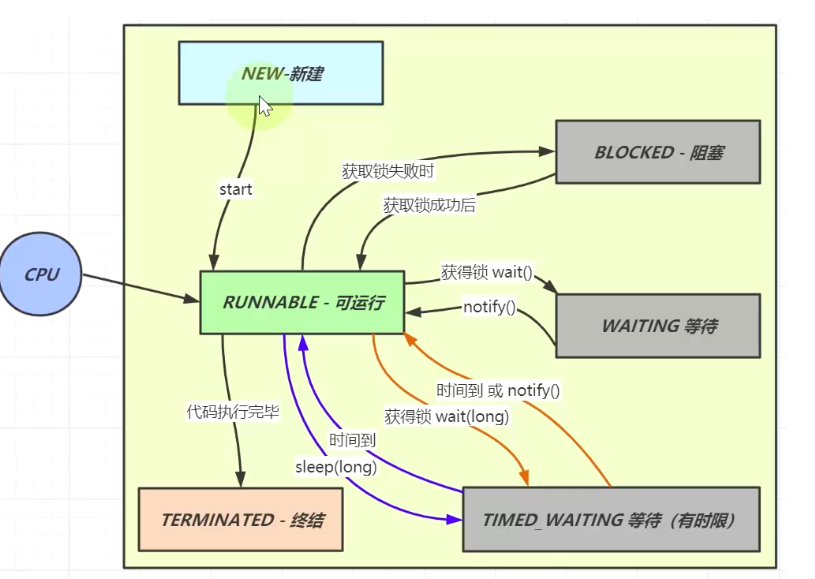
线程有哪些状态
新建、可运行、阻塞、等待、等待(有时限)、终结
操作系统层面有物种状态:新建、就绪、运行、终结、阻塞
1.分到CPU时间的:运行
2.可以分到cpu时间的就绪
3.分不到cpu时间的:阻塞
线程池的核心参数(ThreadPoolExecutor)
1.corePoolSize:核心线程数目:最多保留的线程数
2.maximumPoolSize 最大线程数目:核心线程数+救急线程
3.keepAliveTime生存时间:针对救济线程
4.unit时间单位:针对救济线程
5.workQueue:阻塞队列
6.threadFactory线程工厂:可以为线程创建时起个好名字
7.handler:拒绝策略(四种)
sleep vs wait
wait必须在同步代码块中执行
共同点:wait(),wait(long)和sleep(long)的效果都是让当前线程暂时放弃CPU的使用权,进入阻塞状态
方法归属不同:
- sleep(long)是Thread的静态方法
- wait(),wait(long)都是Object的成员方法,每个对象都有
醒来时机不同: - 执行sleep(long)和wait(long)的线程都会等待响应毫秒后醒来
- wait(long)和wait()还可以被notify唤醒,wait()如果不唤醒就一直等下去
- 他们都可以被打断唤醒
锁特性不同: - wait方法的调用必须先获取wait对象的锁,而sleep则无此限制
- wait方法执行后会释放对象锁,允许其它线程获得该对象锁(我放弃,但你们还可以用)
- 而sleep如果在synchronized代码块中执行,并不会释放对象锁(我放弃,你们也用不了)
lock vs synchronized
语法层面:
synchronized 是关键字,源码在jvm中,用c++语言实现
Lock是接口,源码由jdk提供,用Java语言实现
使用Synchronized时,退出同步代码块锁会自动释放,而使用Lock时,需要手动调用unlock方法释放锁
功能层面:
二者均属于悲观锁,都具有基本的互斥、同步、锁重入功能
Lock提供了许多synchronized不具备的功能,离离如获取等待状态、公平锁、可打段、可超时、多条件变量
Lock有适合不同场景的实现,如ReentrantLock,ReentrantReadWriteLock
性能方面:
在没有竞争时,synchronized做了很多优化,如偏向锁、轻量级锁,能能不来
在竞争激烈时,Lock的实现通常会提供更好的性能。
volatile是否能保证线程安全
1.线程安全要考虑三个方面:可见性、有序性、原子性
可见性指,一个线程对共享变量修改,另一个线程能看到最新的结果(JIT优化)
有序性:一个线程内代码按编写顺序执行
原子性:一个线程内多行代码以一个整体运行,期间不能有其他线程的代码插队
2.volatile能搞保证共享变量的可见性和有序性,但不能保证原子性
悲观锁 vs 乐观锁
- 悲观锁的代表是synmchronized和Lock锁
- 其核心思想是线程只有占有了锁,才能去操作共享变量,每次只有一个线程占锁成功,获取锁失败的线程,都得停下来等待
- 线程从运行到阻塞、再从阻塞到唤醒,涉及线程上下文切换,如果频繁发生,影响性能
- 实际上,线程在获取synchronized和Lock锁 时,如果锁已被占用,都会做几次重试操作,减少阻塞机会
- 乐观锁的代表时AtomicInteger,使用cas来保证原子性
- 其核心思想是无需加锁,每次只有一个线程能成功修改共享变量,其它失败的线程不需要停止,不断重试直至成功
- 由于线程一直运行,不需要阻塞,因此不涉及线程上下文切换
- 它需要多核cpu支持,且线程数不应超过cpu核数
Hashtable vs ConcurrentHashMap
1.Hashtable 与 ConcurrentHashMap都是线程安全的Map集合
2.Hashtable并发度低,整个Hashtable对应一把锁,同一时刻,只能由一个线程操作它
3.1.8之前ConcurrentHashMap使用Segment+数组+链表的结构,每个Segment对应一把锁,如果多个线程访问不同的Segment,则不会冲突
4.1.8开始ConcurrentHashMap将数组的每个头节点作为锁,如果多个线程访问的头节点不同,则不会冲突
ApplicationContext refresh的流程(12个方法)
-
prepareRefresh
- 这一步创建和准备了Environment对象(主要获取一些键值信息,值注入,StandardEnvironment)
-
obtainFreshBeanFactory
- BeanFactory的作用是负责bean的创建、依赖注入和初始化
- BeanDefinition作为bean的涉及蓝图,规定了bean的特征,如单例多例、依赖关系、初始销毁方法等。
- BeanDefinition的来源有多种多样,可以是通过xml获得、通过配置类获得、通过组件扫描获得、也可以是编程添加
-
prepareBeanFactory
StandardBeanExpressionResolver来解析SpEL
ResourceEditorRegistrar会注释类型转换器,并应用ApplicationContext提供的Environment完成${}解析
特殊的bean指beanFactory 以及 ApplicationContext,通过registerResolvableDependency来注册它们 -
postProcessBeanFactory
一般Web环境的ApplicationContext都要利用它注册新的Scope,完善Web下的BeanFactory,体现的是模板方法的设计模式 -
invokBeanFactoryPostProcess
beanFactory后处理器,充当beanFactory的扩展点,可以用来补充活修改BeanDefinition。ConfigurationClassPostProcessor-解析@Configuration、@Bean、@Import、@PropertySource等。PropertySourcePlaceHolderConfigurer替换BeanDefinition中的${} -
registerBeanPostProcess
bean后处理器,充当bean的扩展点,可以工作再bean的实例化、依赖注入、初始化阶段
AutowriedAnnotationBeanPostProcessor功能有:解析@Autowired @Value注解
CommonAnnotationBeanPostProcessor功能有:解析@Resource,@PostConstruct,@PreDestory
AnnotationAwareAspectJAutoProxyCreator功能有:为复核切点的目标bean自动创建代理 -
initMessageSource
实现国际化,容器中一个名为messageSource的bean,如果没有,则提供空的MessageSource实现 -
initApplicationEventMulticaster
用来发布事件给监听器,可以从容器中找明为applicationEventMulticaster的bean作为事件广播器,若没有,也会新建默认的事件广播器 -
onRefresh
SpringBoot中的子类可以在这里准备WebServer,即内嵌web容器
体现模板方法的设计模式 -
registerListeners
用来接收事件,一部分监听器是事先编程添加的,另一部分监听器来自容器中的bean、还有一部分来自于@EventListener的解析
实现ApplicationListener接口,重写其中onApplicationEvent(E e)方法即可 -
finishBeanFactoryInitialization
conversionService也是一套转换机制,作为对PropertyEditor的补充
内嵌值解析器用来解析@Value中的${},接用的是Environment的功能
单例池用来缓存所有单例对象,对象的创建都分三个阶段,每一阶段都有不同的bean后处理器参与进来,扩展功能 -
finishRefresh
用来控制容器内需要声明周期管理的bean,如果容器中有名称为lifycycleProcessor的bean就用它,否则创建默认的声明周期管理器,调用context的start,即可出发所有实现lifeCycle接口bean的start
调用context的stop,即可出发所有实现LifeCycle接口bean的stop
Spring bean的生命周期
阶段一:处理名称,检查缓存
1.先把别名解析为实际名称,再进行后续处理
2.若要FactoryBean本身,需要使用&名称获取
3.singletonObjects是一级缓存,放单例成品对象
4.singletonFactories是三级缓存,放单例工厂
5.earlySingletonObjects是二级缓存,放单例工厂的产品,可称为提前单例对象
阶段二:检查父工厂
* 父子容器的bean名称可以重复
* 优先找子容器的bean,找到了直接返回,找不到继续到父容器找
阶段三:检查DependsOn
阶段四:按Scope创建bean
scope理解为从xxx返回内找到这个bean更贴切
singleton scope表示从单例池返回内获取bean,如果没有,则创建并放入单例池
prototype scope表示从不缓存bean,每次都创建新的
request scope表示从request对象范围内获取bean,如果没有,则创建并放入request..
阶段五:创建bean
阶段六:类型转换
阶段七:销毁bean


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· AI编程工具终极对决:字节Trae VS Cursor,谁才是开发者新宠?
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!