

美团外卖配送部后台开发面经---牛客网
1、hashMap和ConcurrentHashMap的区别
答:hashMap是无序键不可重复值可以重复;线程不安全的;可存一个null键和多个null值,“数组加链表”结构,数组长度默认16;通过key的hashCode值去决定该键值对存 在数组哪个空间上即hashCode%lenth=index,此处length一般默认16,如果该位置上已经有其他的;若要使其线程安全,则可使用Collections类的方法:Map<String,String> map = Collections.synchronizedMap(new HashMap());
ConcurrentHashMap:是在hashMap的基础上,把数据分成许多的segment(默认16个)每次操作时会对该segment(一个存放Entry的桶,默认实现ReentrantLock)加锁,避免多线程锁的几率,提高并发效率
补充:
问题¥:hashMap中key为null的值存在哪里?
for循环会默认在table[0]中查找key为null的值,若是找到了,就把这个新value值赋给这个元素的value,并返回原来的那个value,若没找到,就把该键值对存到table[0]链表的表头。
问题¥¥:ConcurrentHashMap详解:
ConcurrentHashMap是线程安全的(基于lock实现的,同步的时候锁住的不是整个对象,而加了synchronized的是锁住了整个的对象),实现了Map接口,他是在hashMap的基础上,将数
据分为很多个小的segment(桶,他继承了ReentrantLock),默认16,每次操作都对segment加锁,避免多线程的几率,提高并发效率,从他的源码中可以看出,他引入了一个“分段锁”的概
念,就是可以看作把一个Map分成很多个HashTable(hashTable每次是对一整张表加锁),根据key.hashCode()来决定把key放到哪个hashTable中,get时根据计算出来的key.hashCode(),从哪
个hashTable中拿出
装载因子:0.75,如果表中75%的位置已经填入元素,就会扩容两倍(例如:默认初始容量为16,当已用空间为12(75%)时,会自动扩容为2*16=32)
装载因子就是hash表中已占空间和全部空间的比值,默认0.75
初始容量:默认为16
装载因子越大,空间利用率越高,但是冲突机会加大,增大查询数据的开销,查询速度慢,反而空间利用率低,冲突机会减小
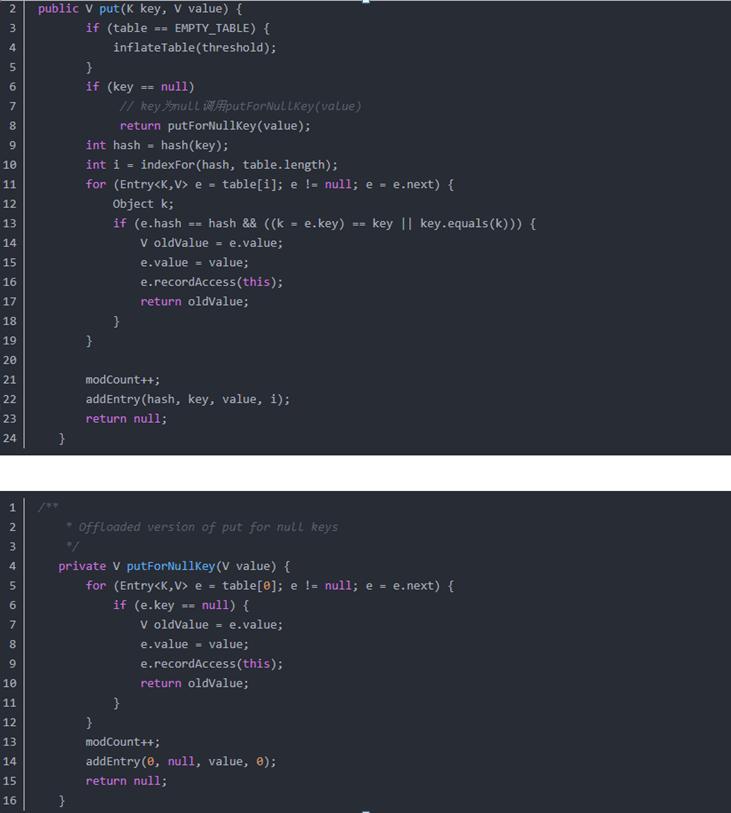
2、hashMap内部具体如何实现的
hashMap实现了map接口,无序不重复,可存一个null键和多个null值,线程不安全,,底层是“数组加链表“结构,默认初始容量是16,加载因子是0.75,当调用put方法存储键值对时,会先调用key的
hashCode方法计算hashCode值,通过hashCode%length=index来决定把Entry存在数组的下标,此时若是该下标已经存在entry了,则调用key的equals方法,再去比较,若此时不相同则把新添加进来的entry
存在链表头部,之前的entry往后移,此时若是用equals比较相同表示重复则用新的value去替换旧的value
3、如果hashMap的key是一个自定义的类,怎么办
重写equals方法和hashCode方法,如果不用对象的话就用的是那些已经默认重写过equals和hashCode的String或者其他的一些引用对象,如Date,所以如果是自己定义的类时就要重写equals和hashCode方法,因为hashCode方法构造的hashCode值是默认的内存地址,这样即便有相同含义的两个对象,比较也是不相等的,例如:
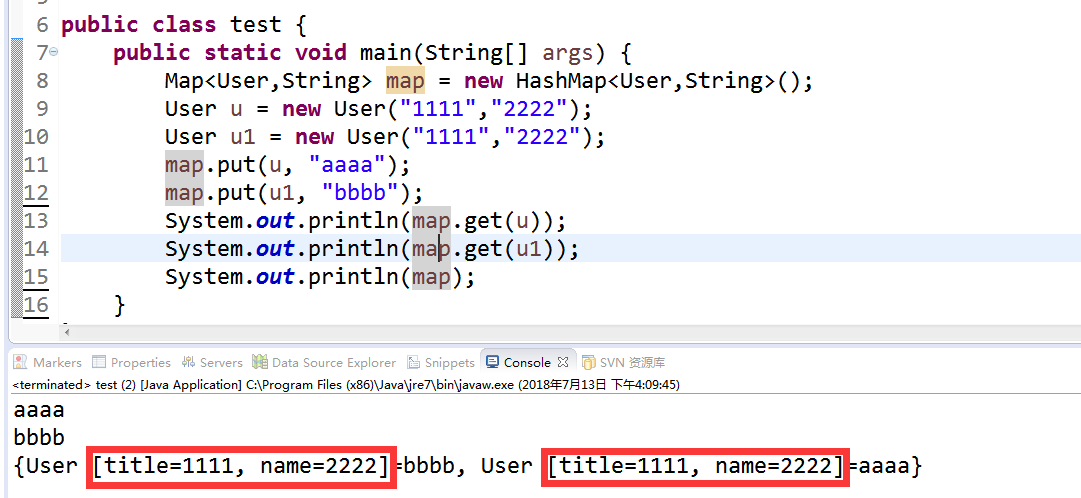
User u1 = new User (“hello”,”ren”);
User u2 = new User (“hello”,”ren”);
正常理解这两个对象加入HashMap应该是一样的,只添加一个,添加的第二个的value把第一个的覆盖掉,但是如果不重写的话比较是其地址,不相等,添加的是两个。
补充:
问题¥:equals和==的区别:
1)对于==:用于基本数据类型比较的是数值大小是否相等,对于非基本数据类型(引用类型)比较其地址是否一致
2)对于equals:不能用于比较基本数据类型,只能用于比较引用类型,没有重写equals方法时,直接比较的是两个对象的地址,若是重写了equals方法,如
String、Date等比较的是所指向对象的内容
4、为什么重写equals还要重写hashcode?
hashCode没有重写时用地址构造hashCode值,地址不同值不同,此时若是有两个对象,u.equals(u1)只能说明内容相同(此时已经重写了equals方法),调用map.put()方法,hashCode值不同,就会把u和u1分别放入两个桶中,但是这时候把map中的内容打印出来就会发现:
一、这时候就会造成重复
二、再者hashCode就是确定entry存在哪个桶中的,此时若是只知道两个两个键equals方法为true,但是不知道是否在一个桶,这样的比较毫无意义
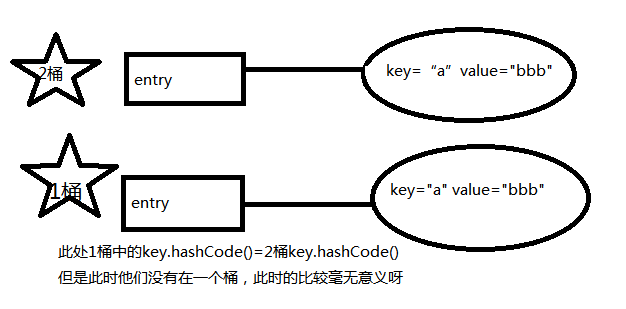
通俗来讲:想想,你要在一个桶里找东西,你必须先要找到这个桶啊,你不通过重写hashcode()来找到桶,光重写equals()有什么用啊
重写后的hashCode方法中通过String类型参数去调用了String类的hashCode方法,此时若是参数相同则值相同,参数不同值不同,如若此处name,title参数是其他引用类型,则在其他类型中也要重写hashCode和equals方法

5、ArrayList和LinkedList的区别,如果一直在list的尾部添加元素,用哪个效率高?
(1)ArrayList:底层是数组实现,有下标空间连续所以查询快,随机读取效率很高,增删慢,存储的是对象的引用而不是对象本身,但是线程不安全,替代了vector
LinkedList:底层是基于链表实现的,有指针所以增删快(比如新来一个节点只需要把上一个节点告诉他(上个节点的指针有指向)即可),但空间不连续查询很慢,需要遍历整个链表,不具有随机访问性
(2)效率:
list开始LinkedList>ArrayList
list中间LinkedList=ArrayList
list最后LinkedList<ArrayList
list随机插入LinkedList>ArrayList

 浙公网安备 33010602011771号
浙公网安备 33010602011771号