

mysql数据库优化(四)-项目实战
在flask项目中,防止随着时间的流逝,数据库数据越来越多,导致接口访问数据库速度变慢。所以自己填充数据进行测试及 mysql优化
1.插入数据:
通过脚本,使用多进程,每100次提交数据
import multiprocessing import time from flask import Flask from flask_sqlalchemy import SQLAlchemy HOST = '127.0.0.1' USER = "root" PASSWD = "" DB = "fwss_dev" CHARTSET = "utf8" app = Flask(__name__, instance_relative_config=True) # 链接数据库路径 app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://%s:%s@127.0.0.1:3306/%s?charset=%s' % (USER, PASSWD, DB, CHARTSET) # 如果设置成 True (默认情况),Flask-SQLAlchemy 将会追踪对象的修改并且发送信号。这需要额外的内存, 如果不必要的可以禁用它。 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = True # 如果设置成 True,SQLAlchemy 将会记录所有 发到标准输出(stderr)的语句,这对调试很有帮助。 app.config['SQLALCHEMY_ECHO'] = False # 数据库连接池的大小。默认是数据库引擎的默认值 (通常是 5)。 app.config['SQLALCHEMY_POOL_SIZE'] = 6 db = SQLAlchemy(app) def insert(count): start = time.time() for item in range(50000): # time1 = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(time_one)) print(count) for it in range(100): db.session.execute( f"""INSERT INTO order_bang (creator_id,redenvelope,status) VALUES ({count},12,0,'需要')""" # f"INSERT INTO account_realauth (uid,`status`) VALUES({count},2)" ) count += 1 db.session.commit() print((time.time() - start) / 60) if __name__ == '__main__': with app.app_context(): multiprocessing.Process(target=insert, args=(273256,)).start() multiprocessing.Process(target=insert, args=(10273256,)).start() multiprocessing.Process(target=insert, args=(20273256,)).start() multiprocessing.Process(target=insert, args=(30273256,)).start()
以上只是展示 部分插入数据库的脚本,总共插入数据量如下: 用户表(account_user)110万用户,实名认证表(account_realauth)20万用户,某订单表(order_bang)2023万条。相关表结构如下:

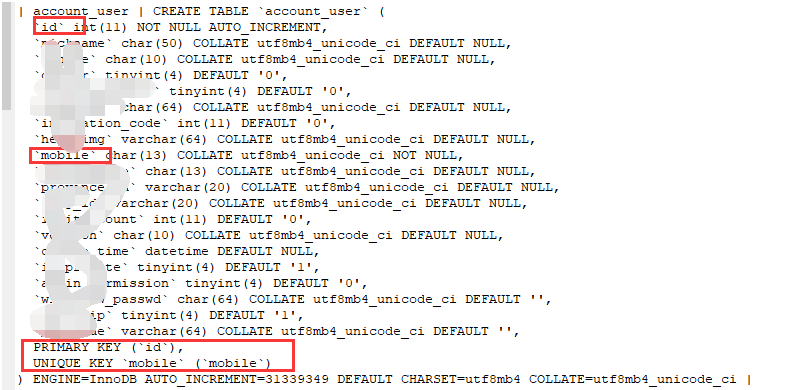
CREATE TABLE `order_bang` ( `id` int(11) NOT NULL AUTO_INCREMENT, `creator_id` int(11) NOT NULL, `status` tinyint(4) DEFAULT NULL, `create_time` datetime DEFAULT NULL, `province_id` char(6) COLLATE utf8mb4_unicode_ci DEFAULT NULL, `city_id` char(4) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
........
PRIMARY KEY (`id`), KEY `ix_order_bang_province_id` (`province_id`), KEY `ix_order_bang_status` (`status`), KEY `bang_addr_index` (`province_id`,`city_id`), KEY `ix_order_bang_create_time` (`create_time`), KEY `ix_order_bang_creator_id` (`creator_id`) )
2.在flask中记录查询较慢的sql语句及相关信息
本人设置最长查询时间为0.1秒便记录
相关 方法在:项目中记录影响性能的缓慢数据库查询
3.关闭mysql缓存功能
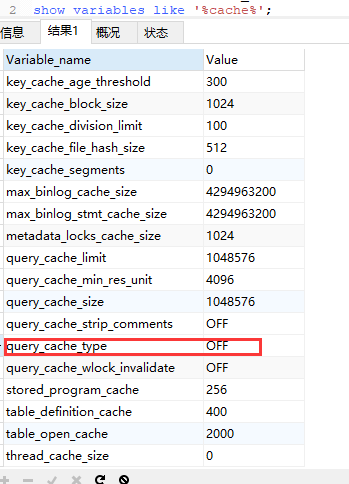
查看缓存是否开启,
输入命令:show variables like '%cache%'; query_cache_type值为OFF表示关闭
关闭方式输入如下:
one.
set global query_cache_type=0 set global query_cache_size=0
two.
查询中添加: Select sql_no_cache count(*) from account_user; 不缓存
4.查看相关结果,并进行优化
一:
时间耗时3.32秒。
分析得知:

where子句条件时uid进行筛选,而索引用的是 id。
解决方法:
第一种:在 uid上添加索引。

分析得知:
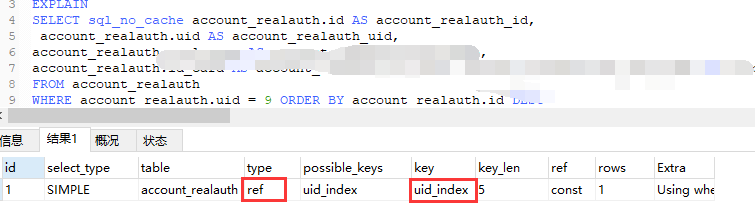

查询使用uid的索引,耗时0.002秒。
第二种:对于客户端不需要表中全部字段的情况,在查询时最好选择具体的字段,而不是直接 select * from table;这样 可以减少网络带宽
在sqlalchemy中为如下(直接使用类方法,及查询具体字段,而不是返回一个对象)
class RealAuth(DB.Model):
@classmethod
def get_success_realname(cls, uid):
db_result = DB.session.query(cls.real_name).filter(
and_(cls.uid == uid, cls.status == RealAuthStatus.SUCCESS)).order_by(
cls.id.desc()).limit(1).first()
总结:
错误原因:由于没有对where子句条件使用索引,导致查询过慢
经验教训:添加索引
二:在查订单时, 接口直接 无响应
sql语句如下:

索引如下:

city字段类型是 char类型
通过 explain查看本条sql,city_id传的值是int类型:
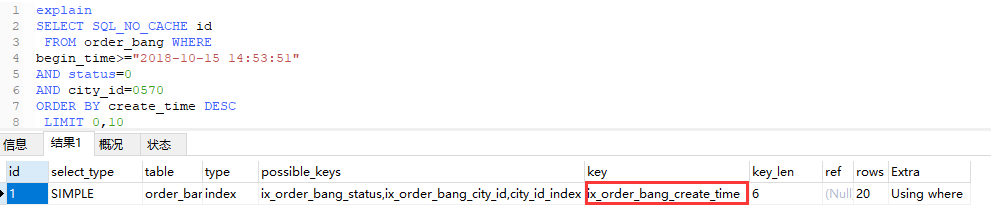
索引使用的是 create_time。
把city_id改为数据库中设定的 str 类型,再次查看


总结:
错误原因:导致此接口查询无响应的原因是 在 大量数据的情况下,没有规范 书写 sql查询的数据类型,导致 无法使用正确的索引,而导致此问题
经验教训:在开发中,在sql执行之前,一定要手动的把 查询条件的值的类型和设计表时的类型相对应,否则可能导致 数据库无法使用此索引,而出错。
待更新;

