

mysql数据库优化(一)
在实际项目中,通过设计表架构时,设计系统结构时,查询数据时综合提高查询数据效率
1.适当冗余
数据库在设计时遵守三范式,同时业务数据(对数据的操作,比如资料审核,对某人评分等)和基础数据(比如资料详情,用户描述等)要分开存储,放在不同表中。在设计数据库时,三范式能够最大限度的节省 数据库存储所需的空间,可是缺点是 在查询,修改等操作时,会造成查询缓慢,效率低下。所以对于经常查询的字段应该适当的添加到同一个表中,适当冗余,不必严格按照三范式进行设计,这样 通过舍弃部分存储空间,提高查询效率,能够得到更好的用户体验。
For example:用户基本信息表(用户名,密码,身高,体重,三围),用户信息审核表(审核状态,用户id);系统需求:要求显示审核结果时知道每个用户的用户名和审核状态;那么严格按照三范式,需要查询两张表;如果把用户名添加到 用户信息审核表 中时,只需查询一张表,查询时间肯定小于多表查询。
冗余字段添加条件:经常进行查询的字段放在同一个表中,避免多表查询
2.数据查询时,少用in进行查询
in进行的是全表查询,不使用索引
For instance:
用关联查询:


用in进行嵌套查询:


所以尽量少用in进行查询,多用其他的进行代替;如 between 2 and 4 代替 in (2,3,4) 等等。
3.尽量少设置外键关联
在项目初期进行版本迭代时,对于以后版本无法预测的变更,尽量少使用外键关联,减少表间依赖强度,为以后版本设计提供基础。因为外键关联时,修改删除等操作非常繁杂。
在保证数据完整性时,尽量少设置外键关联,省去每次查询外键是否存在的时间。比如 国家免检产品,在保证产品质量(本表)的前提下,充分相信制造商(外键对应的表)
4.使用redis缓存机制
对于重复查询,没有改变的数据,可以使用redis缓存机制,直接访问内存数据,不再访问数据库,减少访问数据库的时间(数据库在硬盘上,redis缓存在内存中)。思路是:读取数据库数据到redis缓存中,从redis中取数据给前端。如果涉及到数据修改不大的,可以修改到redis中,固定时间同步到数据库,保证数据统一完整性。
5.查询时 尽量不要用 select * from tables;
*代表取表中一组数据到内存中,增加内存消耗,只取需要的字段,如 select id from tables;
在python的sqlalchemy库时,尽量不要用 Table.query.filter_by(id=1).first() ==》select * from Table where id=1 ;应该使用db.session.query(Table.id).filter(Table.id==1).fitst() ==》 select id from tables where id=1;
6.使用index索引进行查询优化
把索引建在经常查询的字段,主键,外键,WHERE子句中的数据列,出现在关键字order by、group by、distinct后面的字段。
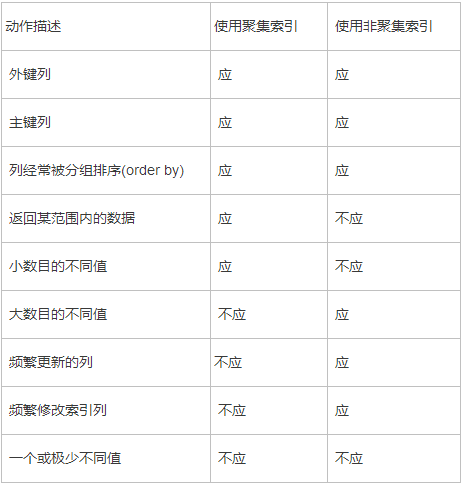
索引创建方法:http://www.cnblogs.com/lixiuran/p/6144319.html,注意索引不同
7.在使用order by进行排序时,最好被排序的字段是索引
8.其他方法:http://www.cnblogs.com/petitprince/archive/2010/11/23/1885994.html
大致思路:减少数据存储空间,减少访问数据库次数,减少读取到内存中的数据量。

