

Airflow速用
Airflow是Apache用python编写的,用到了 flask框架及相关插件,rabbitmq,celery等(windows不兼容);、
主要实现的功能
- 编写 定时任务,及任务间的编排;
- 提供了web界面 可以手动触发任务,分析任务执行顺序,任务执行状态,任务代码,任务日志等等;
- 实现celery的分布式任务调度系统;
- 简单方便的实现了 任务在各种状态下触发 发送邮件的功能;https://airflow.apache.org/concepts.html#email-configuration
- 对组合任务 可以根据 不同参数进入不同分支进行处理 http://airflow.apache.org/concepts.html#branching
- 执行 bash脚本命令;
- 对组合任务 设置触发条件(如:全部失败/成功时执行某任务 等等)http://airflow.apache.org/concepts.html#trigger-rules
- 简单实现随机 负载均衡和容错能力 http://airflow.apache.org/concepts.html#connections
- 对组合任务 间进行数据传递 http://airflow.apache.org/concepts.html#xcoms
- 对分布式任务指定 queue, worker可以指定消费的queue(celery的使用) http://airflow.apache.org/concepts.html#queues
- 存储日志到远程 http://airflow.apache.org/howto/write-logs.html
- 调用 远程 谷歌云,亚马逊云 相关服务(如语音识别等等)https://airflow.apache.org/integration.html#integration
- 调用 钉钉 相关服务
实现功能总结
不仅celery有的功能我都有, 我还能通过页面手动触发/暂停任务,管理任务特方便;我他妈还能 调用谷歌云等服务,日志也能方便打印到云服务上。。。。。。;我就是牛!
核心思想
- DAG:英文为:Directed Acyclic Graph;指 (有向无环图)有向非循环图,是想运行的一系列任务的集合,不关心任务是做什么的,只关心 任务间的组成方式,确保在正确的时间,正确的顺序触发各个任务,准确的处理意外情况;http://airflow.apache.org/concepts.html#dags
- DAGs:多个任务集(多个DAG)
- Operator: 指 某些类型任务的模板 类;如 PythonOperator(执行python相关操作),EmailOperator(执行发送邮件相关操作),SimpleHttpOperator(执行发送http请求相关操作) 等几十种(源码可见)http://airflow.apache.org/howto/operator/index.html#
- Task:当通过 Operator定义了执行任务内容后,在实例化后,便是 Task,为DAG中任务集合的具体任务
- Executor:数据库记录任务状态(排队queued,预执行scheduled,运行中running,成功success,失败failed),调度器(Scheduler )从数据库取数据并决定哪些需要完成,然后 Executor 和调度器一起合作,给任务需要的资源让其完成。Executor间(如 LocalExecutor,CeleryExecutor)不同点在于他们拥有不同的资源以及如何利用资源分配工作,如LocalExecutor只在本地并行执行任务,CeleryExecutor分布式多机器执行任务。 https://www.astronomer.io/guides/airflow-executors-explained/
- Hook:是airflow与外部平台/数据库交互的方式,如 http/ssh/sftp等等,是Operator的基础部分(如SimpleHttpOperator 需要依赖HttpHook)

任务间定义排序的方法
官方推荐使用 移位操作符 方法,因为较为直观,容易理解
如: op1 >> op2 >> op3 表示任务执行顺序为 从左到右依次执行
官方文档介绍:http://airflow.apache.org/concepts.html#bitshift-composition
提高airflow相关执行速度方法
通过修改airflow.cfg相关配置
官方文档如下:http://airflow.apache.org/faq.html
安装及启动相关服务
- 创建python虚拟环境 venv
- 添加airflow.cfg(此配置注解在下面)的配置文件夹路径:先 vi venv/bin/active; 里面输入 export AIRFLOW_HOME="/mnt/e/project/airflow_config/local"
-
命令行:pip install apache-airflow
-
根据airflow.cfg的数据库配置,在连接的数据库服务创建一个 名为 airflow_db的数据库
-
命令行初始化数据库:airflow initdb
-
命令行启动web服务: airflow webserver -p 8080
-
命令行启动任务调度服务:airflow scheduler
- 命令行启动worker:airflow worker -q queue_name
使用 http_operator发送http请求并在失败时,发送邮件
1.设置邮件html模板(如下为自定义模板)
<h2 style="color: red">Xxx service task exception,please fix them!!!</h2> Try {{try_number}} out of {{max_tries + 1}}<br><br> <b>dag id: </b>{{ti.dag_id}}<br><br> <b>task id: </b>{{ti.task_id}}<br><br> <b>task state: </b>{{ti.state}}<br><br> <b>Exception:</b> <p style="color: #0d7bdc">{{exception_html}}</p> <b>Log Url: </b> <a href="{{ti.log_url}}" style="color: red">Link</a><br><br> <b>Host: </b> {{ti.hostname}}<br><br> <b>Log file path: </b> {{ti.log_filepath}}<br><br> <b>Mark success: </b> <a href="{{ti.mark_success_url}}">Link</a><br>
模板效果图:

2. airflow.cfg文件中配置 发送邮件服务
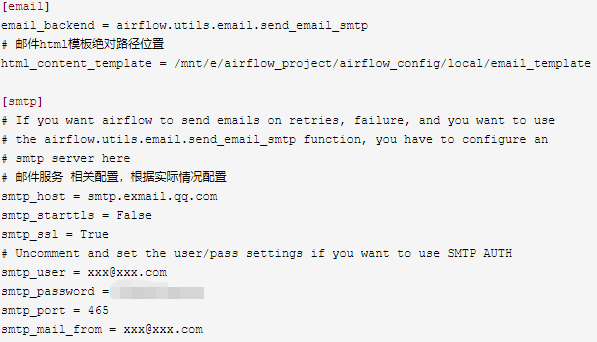
3.编写代码:
1 # -*- coding: utf-8 -*- 2 """ 3 (C) xxx <xxx@xxx.com> 4 All rights reserved 5 create time '2019/10/21 09:27' 6 """ 7 import os 8 from datetime import datetime 9 10 import pytz 11 from airflow import DAG 12 from airflow.models import Variable 13 from airflow.operators.http_operator import SimpleHttpOperator 14 15 # 设置第一次触发任务时间 及 设置任务执行的时区 16 tz = pytz.timezone("Asia/Shanghai") 17 dt = datetime(2019, 10, 11, 0, 0, tzinfo=tz) 18 utc_dt = dt.astimezone(pytz.utc).replace(tzinfo=None) 19 20 # 从环境变量找到 当前环境 21 env = os.environ.get("PROJECT_ENV", "LOCAL") 22 # 添加 需要的相关环境变量,可在 web网页中设置;注意 变量名 以AIRFLOW_CONN_开头,并且大写 23 os.environ["AIRFLOW_CONN_OLY_HOST"] = Variable.get("OLY_HOST_%s" % env) 24 25 # dag默认参数 26 args = { 27 "owner": "Rgc", # 任务拥有人 28 "depends_on_past": False, # 是否依赖过去执行此任务的结果,如果为True,则过去任务必须成功,才能执行此次任务 29 "start_date": utc_dt, # 任务开始执行时间 30 "email": ["rgc@bvrft.com"], # 邮件地址,可以填写多个 31 "email_on_failure": True, # 触发邮件发送的 时机,此处为失败时触发 32 } 33 34 # 定义一个DAG 35 # 参数catchup指 是否填充执行 start_date到现在 未执行的缺少任务;如:start_date定义为2019-10-10,现在是2019-10-29,任务是每天定时执行一次, 36 # 如果此参数设置为True,则 会生成 10号到29号之间的19此任务;如果设置为False,则不会补充执行任务; 37 # schedule_interval:定时执行方式,推荐使用如下字符串方式, 方便写出定时规则的网址:https://crontab.guru/ 38 dag = DAG("HttpSendDag", catchup=False, default_args=args, schedule_interval="0 19 * * *") 39 # 设置 dag文档注释,可在web界面任务详情中看到 40 dag.doc_md = __doc__ 41 42 # 定义此 http operator相关详情,详细使用方法 可访问此类定义__init__()方法 43 task = SimpleHttpOperator( 44 task_id="task_http_send", # 任务id 45 http_conn_id="oly_host", # http请求地址,值为上面23行定义 46 method="POST", # http请求方法 47 endpoint="user/manage", # http请求路径 48 dag=dag # 任务所属dag 49 ) 50 # 定义任务 文档注释,可在web界面任务详情中看到 51 task.doc_md = f"""\ 52 #Usage 53 此任务主要向Project服务({Variable.get("OLY_HOST_%s" % env)})发送http请求,每天晚上7点定时运行! 54 """
任务间数据交流方法
使用Xcoms(cross-communication),类似于redis存储结构,任务推送数据或者从中下拉数据,数据在任务间共享
推送数据主要有2中方式:1:使用xcom_push()方法 2:直接在PythonOperator中调用的函数 return即可
下拉数据 主要使用 xcom_pull()方法
官方代码示例及注释:


1 from __future__ import print_function 2 3 import airflow 4 from airflow import DAG 5 from airflow.operators.python_operator import PythonOperator 6 7 args = { 8 'owner': 'airflow', 9 'start_date': airflow.utils.dates.days_ago(2), 10 'provide_context': True, 11 } 12 13 dag = DAG('example_xcom', schedule_interval="@once", default_args=args) 14 15 value_1 = [1, 2, 3] 16 value_2 = {'a': 'b'} 17 18 19 # 2种推送数据的方式,分别为xcom_push,和直接return 20 21 def push(**kwargs): 22 """Pushes an XCom without a specific target""" 23 kwargs['ti'].xcom_push(key='value from pusher 1', value=value_1) 24 25 26 def push_by_returning(**kwargs): 27 """Pushes an XCom without a specific target, just by returning it""" 28 return value_2 29 30 31 def puller(**kwargs): 32 """ 33 下拉数据的方法 34 :param kwargs: 35 :return: 36 """ 37 ti = kwargs['ti'] 38 39 # get value_1 40 v1 = ti.xcom_pull(key=None, task_ids='push') 41 assert v1 == value_1 42 43 # get value_2 44 v2 = ti.xcom_pull(task_ids='push_by_returning') 45 assert v2 == value_2 46 47 # get both value_1 and value_2 48 v1, v2 = ti.xcom_pull(key=None, task_ids=['push', 'push_by_returning']) 49 assert (v1, v2) == (value_1, value_2) 50 51 52 push1 = PythonOperator( 53 task_id='push', 54 dag=dag, 55 python_callable=push, 56 ) 57 58 push2 = PythonOperator( 59 task_id='push_by_returning', 60 dag=dag, 61 python_callable=push_by_returning, 62 ) 63 64 pull = PythonOperator( 65 task_id='puller', 66 dag=dag, 67 python_callable=puller, 68 ) 69 70 # 任务执行顺序为 71 # push1 >> pull 72 # push2 >> pull 73 74 pull << [push1, push2]
开启 web网页登录需要用户名密码功能
1.airflow.cfg文件修改
# 设置为True
rbac = True
2.重启airflow相关服务
3.通过 命令行 添加 用户
airflow create_user -r Admin -e service@xxx.com -f A -l dmin -u admin -p passwd
4.访问页面,输入用户名,密码即可
忽略某些DAG文件,不调用
在dag任务文件夹下,添加一个 .airflowignore文件(像 .gitignore),里面写 文件名即可(支持正则)
启动及关闭airflow内置 dag示例方法(能够快速学习Airflow)
开启:修改airflow.cfg配置文件 load_examples = True 并重启即可
关闭:修改airflow.cfg配置文件 load_examples = True,并清空数据库,并重启即可
效果图:
airflow配置文件 相关中文注解:
1 [core] 2 # The folder where your airflow pipelines live, most likely a 3 # subfolder in a code repository 4 # This path must be absolute 5 # 绝对路径下 一系列dags存放位置,airflow只会从此路径 文件夹下找dag任务 6 dags_folder = /mnt/e/airflow_project/dags 7 8 # The folder where airflow should store its log files 9 # This path must be absolute 10 # 绝对路径下的日志文件夹位置 11 base_log_folder = /mnt/e/airflow_project/log/ 12 13 # Airflow can store logs remotely in AWS S3, Google Cloud Storage or Elastic Search. 14 # Users must supply an Airflow connection id that provides access to the storage 15 # location. If remote_logging is set to true, see UPDATING.md for additional 16 # configuration requirements. 17 remote_logging = False 18 remote_log_conn_id = 19 remote_base_log_folder = 20 encrypt_s3_logs = False 21 22 # Logging level 23 logging_level = INFO 24 fab_logging_level = WARN 25 26 # Logging class 27 # Specify the class that will specify the logging configuration 28 # This class has to be on the python classpath 29 # logging_config_class = my.path.default_local_settings.LOGGING_CONFIG 30 logging_config_class = 31 32 # Log format 33 # Colour the logs when the controlling terminal is a TTY. 34 colored_console_log = True 35 colored_log_format = [%%(blue)s%%(asctime)s%%(reset)s] {%%(blue)s%%(filename)s:%%(reset)s%%(lineno)d} %%(log_color)s%%(levelname)s%%(reset)s - %%(log_color)s%%(message)s%%(reset)s 36 colored_formatter_class = airflow.utils.log.colored_log.CustomTTYColoredFormatter 37 38 log_format = [%%(asctime)s] {%%(filename)s:%%(lineno)d} %%(levelname)s - %%(message)s 39 simple_log_format = %%(asctime)s %%(levelname)s - %%(message)s 40 41 # Log filename format 42 # 实际处理任务日志 相关 43 log_filename_template = {{ ti.dag_id }}/{{ ti.task_id }}/{{ ts }}/{{ try_number }}.log 44 log_processor_filename_template = {{ filename }}.log 45 # dag处理日志 绝对路径,精确到日志文件 46 dag_processor_manager_log_location = /mnt/e/airflow_project/log/dag_processor_manager.log 47 48 # Hostname by providing a path to a callable, which will resolve the hostname 49 # The format is "package:function". For example, 50 # default value "socket:getfqdn" means that result from getfqdn() of "socket" package will be used as hostname 51 # No argument should be required in the function specified. 52 # If using IP address as hostname is preferred, use value "airflow.utils.net:get_host_ip_address" 53 hostname_callable = socket:getfqdn 54 55 # Default timezone in case supplied date times are naive 56 # can be utc (default), system, or any IANA timezone string (e.g. Europe/Amsterdam) 57 # 默认时区,改为上海,然而 没卵用 58 default_timezone = Asia/Shanghai 59 60 # The executor class that airflow should use. Choices include 61 # SequentialExecutor, LocalExecutor, CeleryExecutor, DaskExecutor, KubernetesExecutor 62 # 指定executor(任务分配执行方式) 63 executor = CeleryExecutor 64 65 # The SqlAlchemy connection string to the metadata database. 66 # SqlAlchemy supports many different database engine, more information 67 # their website 68 # 存储airflow相关数据的 数据库路径 69 sql_alchemy_conn = mysql+pymysql://root:passwd@127.0.0.1:3306/airflow_db 70 71 # The encoding for the databases 72 sql_engine_encoding = utf-8 73 74 # If SqlAlchemy should pool database connections. 75 sql_alchemy_pool_enabled = True 76 77 # The SqlAlchemy pool size is the maximum number of database connections 78 # in the pool. 0 indicates no limit. 79 sql_alchemy_pool_size = 5 80 81 # The maximum overflow size of the pool. 82 # When the number of checked-out connections reaches the size set in pool_size, 83 # additional connections will be returned up to this limit. 84 # When those additional connections are returned to the pool, they are disconnected and discarded. 85 # It follows then that the total number of simultaneous connections the pool will allow is pool_size + max_overflow, 86 # and the total number of "sleeping" connections the pool will allow is pool_size. 87 # max_overflow can be set to -1 to indicate no overflow limit; 88 # no limit will be placed on the total number of concurrent connections. Defaults to 10. 89 sql_alchemy_max_overflow = 10 90 91 # The SqlAlchemy pool recycle is the number of seconds a connection 92 # can be idle in the pool before it is invalidated. This config does 93 # not apply to sqlite. If the number of DB connections is ever exceeded, 94 # a lower config value will allow the system to recover faster. 95 sql_alchemy_pool_recycle = 1800 96 97 # How many seconds to retry re-establishing a DB connection after 98 # disconnects. Setting this to 0 disables retries. 99 sql_alchemy_reconnect_timeout = 300 100 101 # The schema to use for the metadata database 102 # SqlAlchemy supports databases with the concept of multiple schemas. 103 sql_alchemy_schema = 104 105 # The amount of parallelism as a setting to the executor. This defines 106 # the max number of task instances that should run simultaneously 107 # on this airflow installation 108 parallelism = 32 109 110 # The number of task instances allowed to run concurrently by the scheduler 111 dag_concurrency = 16 112 113 # Are DAGs paused by default at creation 114 dags_are_paused_at_creation = True 115 116 # The maximum number of active DAG runs per DAG 117 max_active_runs_per_dag = 16 118 119 # Whether to load the examples that ship with Airflow. It's good to 120 # get started, but you probably want to set this to False in a production 121 # environment 122 load_examples = False 123 124 # Where your Airflow plugins are stored 125 # 自定义 界面及api所在 绝对路径文件夹 官网用法: http://airflow.apache.org/plugins.html 126 plugins_folder = /mnt/e/airflow_project/plugins 127 128 # Secret key to save connection passwords in the db 129 # 对使用到的 连接密码 进行加密,此为秘钥 官网用法: https://airflow.apache.org/howto/secure-connections.html 130 fernet_key = Et8ULvn0biL8X0xXl66wHawhdetf7utIDYDgNzZh4nCnE= 131 132 # Whether to disable pickling dags 133 donot_pickle = False 134 135 # How long before timing out a python file import while filling the DagBag 136 dagbag_import_timeout = 30 137 138 # The class to use for running task instances in a subprocess 139 task_runner = StandardTaskRunner 140 141 # If set, tasks without a `run_as_user` argument will be run with this user 142 # Can be used to de-elevate a sudo user running Airflow when executing tasks 143 default_impersonation = 144 145 # What security module to use (for example kerberos): 146 security = 147 148 # If set to False enables some unsecure features like Charts and Ad Hoc Queries. 149 # In 2.0 will default to True. 150 secure_mode = False 151 152 # Turn unit test mode on (overwrites many configuration options with test 153 # values at runtime) 154 unit_test_mode = False 155 156 # Name of handler to read task instance logs. 157 # Default to use task handler. 158 task_log_reader = task 159 160 # Whether to enable pickling for xcom (note that this is insecure and allows for 161 # RCE exploits). This will be deprecated in Airflow 2.0 (be forced to False). 162 enable_xcom_pickling = True 163 164 # When a task is killed forcefully, this is the amount of time in seconds that 165 # it has to cleanup after it is sent a SIGTERM, before it is SIGKILLED 166 killed_task_cleanup_time = 60 167 168 # Whether to override params with dag_run.conf. If you pass some key-value pairs through `airflow backfill -c` or 169 # `airflow trigger_dag -c`, the key-value pairs will override the existing ones in params. 170 dag_run_conf_overrides_params = False 171 172 # Worker initialisation check to validate Metadata Database connection 173 worker_precheck = False 174 175 # When discovering DAGs, ignore any files that don't contain the strings `DAG` and `airflow`. 176 dag_discovery_safe_mode = True 177 178 179 [cli] 180 # In what way should the cli access the API. The LocalClient will use the 181 # database directly, while the json_client will use the api running on the 182 # webserver 183 api_client = airflow.api.client.local_client 184 185 # If you set web_server_url_prefix, do NOT forget to append it here, ex: 186 # endpoint_url = http://localhost:8080/myroot 187 # So api will look like: http://localhost:8080/myroot/api/experimental/... 188 endpoint_url = http://localhost:18080 189 190 [api] 191 # How to authenticate users of the API 192 auth_backend = airflow.api.auth.backend.default 193 194 [lineage] 195 # what lineage backend to use 196 backend = 197 198 [atlas] 199 sasl_enabled = False 200 host = 201 port = 21000 202 username = 203 password = 204 205 [operators] 206 # The default owner assigned to each new operator, unless 207 # provided explicitly or passed via `default_args` 208 default_owner = airflow 209 default_cpus = 1 210 default_ram = 512 211 default_disk = 512 212 default_gpus = 0 213 214 [hive] 215 # Default mapreduce queue for HiveOperator tasks 216 default_hive_mapred_queue = 217 218 [webserver] 219 # web端访问配置 220 # The base url of your website as airflow cannot guess what domain or 221 # cname you are using. This is used in automated emails that 222 # airflow sends to point links to the right web server 223 base_url = http://localhost:18080 224 225 # The ip specified when starting the web server 226 web_server_host = 0.0.0.0 227 228 # The port on which to run the web server 229 web_server_port = 18080 230 231 # Paths to the SSL certificate and key for the web server. When both are 232 # provided SSL will be enabled. This does not change the web server port. 233 web_server_ssl_cert = 234 web_server_ssl_key = 235 236 # Number of seconds the webserver waits before killing gunicorn master that doesn't respond 237 web_server_master_timeout = 120 238 239 # Number of seconds the gunicorn webserver waits before timing out on a worker 240 web_server_worker_timeout = 120 241 242 # Number of workers to refresh at a time. When set to 0, worker refresh is 243 # disabled. When nonzero, airflow periodically refreshes webserver workers by 244 # bringing up new ones and killing old ones. 245 worker_refresh_batch_size = 1 246 247 # Number of seconds to wait before refreshing a batch of workers. 248 worker_refresh_interval = 30 249 250 # Secret key used to run your flask app 251 secret_key = temporary_key 252 253 # Number of workers to run the Gunicorn web server 254 workers = 4 255 256 # The worker class gunicorn should use. Choices include 257 # sync (default), eventlet, gevent 258 worker_class = sync 259 260 # Log files for the gunicorn webserver. '-' means log to stderr. 261 access_logfile = - 262 error_logfile = - 263 264 # Expose the configuration file in the web server 265 # This is only applicable for the flask-admin based web UI (non FAB-based). 266 # In the FAB-based web UI with RBAC feature, 267 # access to configuration is controlled by role permissions. 268 expose_config = False 269 270 # Set to true to turn on authentication: 271 # https://airflow.apache.org/security.html#web-authentication 272 authenticate = False 273 274 # Filter the list of dags by owner name (requires authentication to be enabled) 275 filter_by_owner = False 276 277 # Filtering mode. Choices include user (default) and ldapgroup. 278 # Ldap group filtering requires using the ldap backend 279 # 280 # Note that the ldap server needs the "memberOf" overlay to be set up 281 # in order to user the ldapgroup mode. 282 owner_mode = user 283 284 # Default DAG view. Valid values are: 285 # tree, graph, duration, gantt, landing_times 286 dag_default_view = tree 287 288 # Default DAG orientation. Valid values are: 289 # LR (Left->Right), TB (Top->Bottom), RL (Right->Left), BT (Bottom->Top) 290 dag_orientation = LR 291 292 # Puts the webserver in demonstration mode; blurs the names of Operators for 293 # privacy. 294 demo_mode = False 295 296 # The amount of time (in secs) webserver will wait for initial handshake 297 # while fetching logs from other worker machine 298 log_fetch_timeout_sec = 5 299 300 # By default, the webserver shows paused DAGs. Flip this to hide paused 301 # DAGs by default 302 hide_paused_dags_by_default = False 303 304 # Consistent page size across all listing views in the UI 305 page_size = 100 306 307 # Use FAB-based webserver with RBAC feature 308 # 是否登录时 需要用户名 密码 验证功能;https://airflow.apache.org/security.html#rbac-ui-security 309 rbac = False 310 311 # Define the color of navigation bar 312 navbar_color = #007A87 313 314 # Default dagrun to show in UI 315 default_dag_run_display_number = 25 316 317 # Enable werkzeug `ProxyFix` middleware 318 enable_proxy_fix = False 319 320 # Set secure flag on session cookie 321 cookie_secure = False 322 323 # Set samesite policy on session cookie 324 cookie_samesite = 325 326 # Default setting for wrap toggle on DAG code and TI log views. 327 default_wrap = False 328 329 # Send anonymous user activity to your analytics tool 330 # analytics_tool = # choose from google_analytics, segment, or metarouter 331 # analytics_id = XXXXXXXXXXX 332 333 [email] 334 email_backend = airflow.utils.email.send_email_smtp 335 # 邮件html模板绝对路径位置 336 html_content_template = /mnt/e/airflow_project/airflow_config/local/email_template 337 338 [smtp] 339 # If you want airflow to send emails on retries, failure, and you want to use 340 # the airflow.utils.email.send_email_smtp function, you have to configure an 341 # smtp server here 342 # 邮件服务 相关配置,根据实际情况配置 343 smtp_host = smtp.exmail.qq.com 344 smtp_starttls = False 345 smtp_ssl = True 346 # Uncomment and set the user/pass settings if you want to use SMTP AUTH 347 smtp_user = xxx@xxx.com 348 smtp_password = xxx 349 smtp_port = 465 350 smtp_mail_from = xxx@xxx.com 351 352 353 [celery] 354 # This section only applies if you are using the CeleryExecutor in 355 # [core] section above 356 357 # The app name that will be used by celery 358 celery_app_name = airflow.executors.celery_executor 359 360 # The concurrency that will be used when starting workers with the 361 # "airflow worker" command. This defines the number of task instances that 362 # a worker will take, so size up your workers based on the resources on 363 # your worker box and the nature of your tasks 364 worker_concurrency = 16 365 366 # The maximum and minimum concurrency that will be used when starting workers with the 367 # "airflow worker" command (always keep minimum processes, but grow to maximum if necessary). 368 # Note the value should be "max_concurrency,min_concurrency" 369 # Pick these numbers based on resources on worker box and the nature of the task. 370 # If autoscale option is available, worker_concurrency will be ignored. 371 # http://docs.celeryproject.org/en/latest/reference/celery.bin.worker.html#cmdoption-celery-worker-autoscale 372 # worker_autoscale = 16,12 373 374 # When you start an airflow worker, airflow starts a tiny web server 375 # subprocess to serve the workers local log files to the airflow main 376 # web server, who then builds pages and sends them to users. This defines 377 # the port on which the logs are served. It needs to be unused, and open 378 # visible from the main web server to connect into the workers. 379 worker_log_server_port = 8793 380 381 # The Celery broker URL. Celery supports RabbitMQ, Redis and experimentally 382 # a sqlalchemy database. Refer to the Celery documentation for more 383 # information. 384 # http://docs.celeryproject.org/en/latest/userguide/configuration.html#broker-settings 385 # celery服务 broker连接,此处使用 rabbitmq 386 broker_url = pyamqp://role:passwd@127.0.0.1:5672/ 387 388 # The Celery result_backend. When a job finishes, it needs to update the 389 # metadata of the job. Therefore it will post a message on a message bus, 390 # or insert it into a database (depending of the backend) 391 # This status is used by the scheduler to update the state of the task 392 # The use of a database is highly recommended 393 # http://docs.celeryproject.org/en/latest/userguide/configuration.html#task-result-backend-settings 394 # celery服务 结果存储连接 395 result_backend = redis://localhost/15 396 397 # Celery Flower is a sweet UI for Celery. Airflow has a shortcut to start 398 # it `airflow flower`. This defines the IP that Celery Flower runs on 399 flower_host = 0.0.0.0 400 401 # The root URL for Flower 402 # Ex: flower_url_prefix = /flower 403 flower_url_prefix = 404 405 # This defines the port that Celery Flower runs on 406 flower_port = 5555 407 408 # Securing Flower with Basic Authentication 409 # Accepts user:password pairs separated by a comma 410 # Example: flower_basic_auth = user1:password1,user2:password2 411 flower_basic_auth = 412 413 # Default queue that tasks get assigned to and that worker listen on. 414 default_queue = default 415 416 # How many processes CeleryExecutor uses to sync task state. 417 # 0 means to use max(1, number of cores - 1) processes. 418 sync_parallelism = 0 419 420 # Import path for celery configuration options 421 celery_config_options = airflow.config_templates.default_celery.DEFAULT_CELERY_CONFIG 422 423 # In case of using SSL 424 ssl_active = False 425 ssl_key = 426 ssl_cert = 427 ssl_cacert = 428 429 # Celery Pool implementation. 430 # Choices include: prefork (default), eventlet, gevent or solo. 431 # See: 432 # https://docs.celeryproject.org/en/latest/userguide/workers.html#concurrency 433 # https://docs.celeryproject.org/en/latest/userguide/concurrency/eventlet.html 434 pool = prefork 435 436 [celery_broker_transport_options] 437 # This section is for specifying options which can be passed to the 438 # underlying celery broker transport. See: 439 # http://docs.celeryproject.org/en/latest/userguide/configuration.html#std:setting-broker_transport_options 440 441 # The visibility timeout defines the number of seconds to wait for the worker 442 # to acknowledge the task before the message is redelivered to another worker. 443 # Make sure to increase the visibility timeout to match the time of the longest 444 # ETA you're planning to use. 445 # 446 # visibility_timeout is only supported for Redis and SQS celery brokers. 447 # See: 448 # http://docs.celeryproject.org/en/master/userguide/configuration.html#std:setting-broker_transport_options 449 # 450 #visibility_timeout = 21600 451 452 [dask] 453 # This section only applies if you are using the DaskExecutor in 454 # [core] section above 455 456 # The IP address and port of the Dask cluster's scheduler. 457 cluster_address = 127.0.0.1:8786 458 # TLS/ SSL settings to access a secured Dask scheduler. 459 tls_ca = 460 tls_cert = 461 tls_key = 462 463 464 [scheduler] 465 # Task instances listen for external kill signal (when you clear tasks 466 # from the CLI or the UI), this defines the frequency at which they should 467 # listen (in seconds). 468 job_heartbeat_sec = 5 469 470 # The scheduler constantly tries to trigger new tasks (look at the 471 # scheduler section in the docs for more information). This defines 472 # how often the scheduler should run (in seconds). 473 scheduler_heartbeat_sec = 5 474 475 # after how much time should the scheduler terminate in seconds 476 # -1 indicates to run continuously (see also num_runs) 477 run_duration = -1 478 479 # after how much time (seconds) a new DAGs should be picked up from the filesystem 480 min_file_process_interval = 0 481 482 # How often (in seconds) to scan the DAGs directory for new files. Default to 5 minutes. 483 dag_dir_list_interval = 300 484 485 # How often should stats be printed to the logs 486 print_stats_interval = 30 487 488 # If the last scheduler heartbeat happened more than scheduler_health_check_threshold ago (in seconds), 489 # scheduler is considered unhealthy. 490 # This is used by the health check in the "/health" endpoint 491 scheduler_health_check_threshold = 30 492 493 # 定时任务 日志位置 494 child_process_log_directory = /mnt/e/airflow_project/log/airflow/scheduler 495 496 # Local task jobs periodically heartbeat to the DB. If the job has 497 # not heartbeat in this many seconds, the scheduler will mark the 498 # associated task instance as failed and will re-schedule the task. 499 scheduler_zombie_task_threshold = 300 500 501 # Turn off scheduler catchup by setting this to False. 502 # Default behavior is unchanged and 503 # Command Line Backfills still work, but the scheduler 504 # will not do scheduler catchup if this is False, 505 # however it can be set on a per DAG basis in the 506 # DAG definition (catchup) 507 catchup_by_default = True 508 509 # This changes the batch size of queries in the scheduling main loop. 510 # If this is too high, SQL query performance may be impacted by one 511 # or more of the following: 512 # - reversion to full table scan 513 # - complexity of query predicate 514 # - excessive locking 515 # 516 # Additionally, you may hit the maximum allowable query length for your db. 517 # 518 # Set this to 0 for no limit (not advised) 519 max_tis_per_query = 512 520 521 # Statsd (https://github.com/etsy/statsd) integration settings 522 statsd_on = True 523 statsd_host = localhost 524 statsd_port = 8125 525 statsd_prefix = airflow 526 527 # The scheduler can run multiple threads in parallel to schedule dags. 528 # This defines how many threads will run. 529 max_threads = 2 530 531 authenticate = False 532 533 # Turn off scheduler use of cron intervals by setting this to False. 534 # DAGs submitted manually in the web UI or with trigger_dag will still run. 535 use_job_schedule = True 536 537 [ldap] 538 # set this to ldaps://<your.ldap.server>:<port> 539 uri = 540 user_filter = objectClass=* 541 user_name_attr = uid 542 group_member_attr = memberOf 543 superuser_filter = 544 data_profiler_filter = 545 bind_user = cn=Manager,dc=example,dc=com 546 bind_password = insecure 547 basedn = dc=example,dc=com 548 cacert = /etc/ca/ldap_ca.crt 549 search_scope = LEVEL 550 551 # This setting allows the use of LDAP servers that either return a 552 # broken schema, or do not return a schema. 553 ignore_malformed_schema = False 554 555 [mesos] 556 # Mesos master address which MesosExecutor will connect to. 557 master = localhost:5050 558 559 # The framework name which Airflow scheduler will register itself as on mesos 560 framework_name = Airflow 561 562 # Number of cpu cores required for running one task instance using 563 # 'airflow run <dag_id> <task_id> <execution_date> --local -p <pickle_id>' 564 # command on a mesos slave 565 task_cpu = 1 566 567 # Memory in MB required for running one task instance using 568 # 'airflow run <dag_id> <task_id> <execution_date> --local -p <pickle_id>' 569 # command on a mesos slave 570 task_memory = 256 571 572 # Enable framework checkpointing for mesos 573 # See http://mesos.apache.org/documentation/latest/slave-recovery/ 574 checkpoint = False 575 576 # Failover timeout in milliseconds. 577 # When checkpointing is enabled and this option is set, Mesos waits 578 # until the configured timeout for 579 # the MesosExecutor framework to re-register after a failover. Mesos 580 # shuts down running tasks if the 581 # MesosExecutor framework fails to re-register within this timeframe. 582 # failover_timeout = 604800 583 584 # Enable framework authentication for mesos 585 # See http://mesos.apache.org/documentation/latest/configuration/ 586 authenticate = False 587 588 # Mesos credentials, if authentication is enabled 589 # default_principal = admin 590 # default_secret = admin 591 592 # Optional Docker Image to run on slave before running the command 593 # This image should be accessible from mesos slave i.e mesos slave 594 # should be able to pull this docker image before executing the command. 595 # docker_image_slave = puckel/docker-airflow 596 597 [kerberos] 598 ccache = /tmp/airflow_krb5_ccache 599 # gets augmented with fqdn 600 principal = airflow 601 reinit_frequency = 3600 602 kinit_path = kinit 603 keytab = airflow.keytab 604 605 606 [github_enterprise] 607 api_rev = v3 608 609 [admin] 610 # UI to hide sensitive variable fields when set to True 611 hide_sensitive_variable_fields = True 612 613 [elasticsearch] 614 # Elasticsearch host 615 host = 616 # Format of the log_id, which is used to query for a given tasks logs 617 log_id_template = {dag_id}-{task_id}-{execution_date}-{try_number} 618 # Used to mark the end of a log stream for a task 619 end_of_log_mark = end_of_log 620 # Qualified URL for an elasticsearch frontend (like Kibana) with a template argument for log_id 621 # Code will construct log_id using the log_id template from the argument above. 622 # NOTE: The code will prefix the https:// automatically, don't include that here. 623 frontend = 624 # Write the task logs to the stdout of the worker, rather than the default files 625 write_stdout = False 626 # Instead of the default log formatter, write the log lines as JSON 627 json_format = False 628 # Log fields to also attach to the json output, if enabled 629 json_fields = asctime, filename, lineno, levelname, message 630 631 [elasticsearch_configs] 632 633 use_ssl = False 634 verify_certs = True 635 636 [kubernetes] 637 # The repository, tag and imagePullPolicy of the Kubernetes Image for the Worker to Run 638 worker_container_repository = 639 worker_container_tag = 640 worker_container_image_pull_policy = IfNotPresent 641 642 # If True (default), worker pods will be deleted upon termination 643 delete_worker_pods = True 644 645 # Number of Kubernetes Worker Pod creation calls per scheduler loop 646 worker_pods_creation_batch_size = 1 647 648 # The Kubernetes namespace where airflow workers should be created. Defaults to `default` 649 namespace = default 650 651 # The name of the Kubernetes ConfigMap Containing the Airflow Configuration (this file) 652 airflow_configmap = 653 654 # For docker image already contains DAGs, this is set to `True`, and the worker will search for dags in dags_folder, 655 # otherwise use git sync or dags volume claim to mount DAGs 656 dags_in_image = False 657 658 # For either git sync or volume mounted DAGs, the worker will look in this subpath for DAGs 659 dags_volume_subpath = 660 661 # For DAGs mounted via a volume claim (mutually exclusive with git-sync and host path) 662 dags_volume_claim = 663 664 # For volume mounted logs, the worker will look in this subpath for logs 665 logs_volume_subpath = 666 667 # A shared volume claim for the logs 668 logs_volume_claim = 669 670 # For DAGs mounted via a hostPath volume (mutually exclusive with volume claim and git-sync) 671 # Useful in local environment, discouraged in production 672 dags_volume_host = 673 674 # A hostPath volume for the logs 675 # Useful in local environment, discouraged in production 676 logs_volume_host = 677 678 # A list of configMapsRefs to envFrom. If more than one configMap is 679 # specified, provide a comma separated list: configmap_a,configmap_b 680 env_from_configmap_ref = 681 682 # A list of secretRefs to envFrom. If more than one secret is 683 # specified, provide a comma separated list: secret_a,secret_b 684 env_from_secret_ref = 685 686 # Git credentials and repository for DAGs mounted via Git (mutually exclusive with volume claim) 687 git_repo = 688 git_branch = 689 git_subpath = 690 # Use git_user and git_password for user authentication or git_ssh_key_secret_name and git_ssh_key_secret_key 691 # for SSH authentication 692 git_user = 693 git_password = 694 git_sync_root = /git 695 git_sync_dest = repo 696 # Mount point of the volume if git-sync is being used. 697 # i.e. /Users/wudong/work/Python/flow/dags 698 git_dags_folder_mount_point = 699 700 # To get Git-sync SSH authentication set up follow this format 701 # 702 # airflow-secrets.yaml: 703 # --- 704 # apiVersion: v1 705 # kind: Secret 706 # metadata: 707 # name: airflow-secrets 708 # data: 709 # # key needs to be gitSshKey 710 # gitSshKey: <base64_encoded_data> 711 # --- 712 # airflow-configmap.yaml: 713 # apiVersion: v1 714 # kind: ConfigMap 715 # metadata: 716 # name: airflow-configmap 717 # data: 718 # known_hosts: | 719 # github.com ssh-rsa <...> 720 # airflow.cfg: | 721 # ... 722 # 723 # git_ssh_key_secret_name = airflow-secrets 724 # git_ssh_known_hosts_configmap_name = airflow-configmap 725 git_ssh_key_secret_name = 726 git_ssh_known_hosts_configmap_name = 727 728 # To give the git_sync init container credentials via a secret, create a secret 729 # with two fields: GIT_SYNC_USERNAME and GIT_SYNC_PASSWORD (example below) and 730 # add `git_sync_credentials_secret = <secret_name>` to your airflow config under the kubernetes section 731 # 732 # Secret Example: 733 # apiVersion: v1 734 # kind: Secret 735 # metadata: 736 # name: git-credentials 737 # data: 738 # GIT_SYNC_USERNAME: <base64_encoded_git_username> 739 # GIT_SYNC_PASSWORD: <base64_encoded_git_password> 740 git_sync_credentials_secret = 741 742 # For cloning DAGs from git repositories into volumes: https://github.com/kubernetes/git-sync 743 git_sync_container_repository = k8s.gcr.io/git-sync 744 git_sync_container_tag = v3.1.1 745 git_sync_init_container_name = git-sync-clone 746 git_sync_run_as_user = 65533 747 748 # The name of the Kubernetes service account to be associated with airflow workers, if any. 749 # Service accounts are required for workers that require access to secrets or cluster resources. 750 # See the Kubernetes RBAC documentation for more: 751 # https://kubernetes.io/docs/admin/authorization/rbac/ 752 worker_service_account_name = 753 754 # Any image pull secrets to be given to worker pods, If more than one secret is 755 # required, provide a comma separated list: secret_a,secret_b 756 image_pull_secrets = 757 758 # GCP Service Account Keys to be provided to tasks run on Kubernetes Executors 759 # Should be supplied in the format: key-name-1:key-path-1,key-name-2:key-path-2 760 gcp_service_account_keys = 761 762 # Use the service account kubernetes gives to pods to connect to kubernetes cluster. 763 # It's intended for clients that expect to be running inside a pod running on kubernetes. 764 # It will raise an exception if called from a process not running in a kubernetes environment. 765 in_cluster = True 766 767 # When running with in_cluster=False change the default cluster_context or config_file 768 # options to Kubernetes client. Leave blank these to use default behaviour like `kubectl` has. 769 # cluster_context = 770 # config_file = 771 772 773 # Affinity configuration as a single line formatted JSON object. 774 # See the affinity model for top-level key names (e.g. `nodeAffinity`, etc.): 775 # https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.12/#affinity-v1-core 776 affinity = 777 778 # A list of toleration objects as a single line formatted JSON array 779 # See: 780 # https://kubernetes.io/docs/reference/generated/kubernetes-api/v1.12/#toleration-v1-core 781 tolerations = 782 783 # **kwargs parameters to pass while calling a kubernetes client core_v1_api methods from Kubernetes Executor 784 # provided as a single line formatted JSON dictionary string. 785 # List of supported params in **kwargs are similar for all core_v1_apis, hence a single config variable for all apis 786 # See: 787 # https://raw.githubusercontent.com/kubernetes-client/python/master/kubernetes/client/apis/core_v1_api.py 788 # Note that if no _request_timeout is specified, the kubernetes client will wait indefinitely for kubernetes 789 # api responses, which will cause the scheduler to hang. The timeout is specified as [connect timeout, read timeout] 790 kube_client_request_args = {"_request_timeout" : [60,60] } 791 792 # Worker pods security context options 793 # See: 794 # https://kubernetes.io/docs/tasks/configure-pod-container/security-context/ 795 796 # Specifies the uid to run the first process of the worker pods containers as 797 run_as_user = 798 799 # Specifies a gid to associate with all containers in the worker pods 800 # if using a git_ssh_key_secret_name use an fs_group 801 # that allows for the key to be read, e.g. 65533 802 fs_group = 803 804 [kubernetes_node_selectors] 805 # The Key-value pairs to be given to worker pods. 806 # The worker pods will be scheduled to the nodes of the specified key-value pairs. 807 # Should be supplied in the format: key = value 808 809 [kubernetes_annotations] 810 # The Key-value annotations pairs to be given to worker pods. 811 # Should be supplied in the format: key = value 812 813 [kubernetes_environment_variables] 814 # The scheduler sets the following environment variables into your workers. You may define as 815 # many environment variables as needed and the kubernetes launcher will set them in the launched workers. 816 # Environment variables in this section are defined as follows 817 # <environment_variable_key> = <environment_variable_value> 818 # 819 # For example if you wanted to set an environment variable with value `prod` and key 820 # `ENVIRONMENT` you would follow the following format: 821 # ENVIRONMENT = prod 822 # 823 # Additionally you may override worker airflow settings with the AIRFLOW__<SECTION>__<KEY> 824 # formatting as supported by airflow normally. 825 826 [kubernetes_secrets] 827 # The scheduler mounts the following secrets into your workers as they are launched by the 828 # scheduler. You may define as many secrets as needed and the kubernetes launcher will parse the 829 # defined secrets and mount them as secret environment variables in the launched workers. 830 # Secrets in this section are defined as follows 831 # <environment_variable_mount> = <kubernetes_secret_object>=<kubernetes_secret_key> 832 # 833 # For example if you wanted to mount a kubernetes secret key named `postgres_password` from the 834 # kubernetes secret object `airflow-secret` as the environment variable `POSTGRES_PASSWORD` into 835 # your workers you would follow the following format: 836 # POSTGRES_PASSWORD = airflow-secret=postgres_credentials 837 # 838 # Additionally you may override worker airflow settings with the AIRFLOW__<SECTION>__<KEY> 839 # formatting as supported by airflow normally. 840 841 [kubernetes_labels] 842 # The Key-value pairs to be given to worker pods. 843 # The worker pods will be given these static labels, as well as some additional dynamic labels 844 # to identify the task. 845 # Should be supplied in the format: key = value
错误记录:
* 设置supervisor启动airflow服务时,报错如下
Error: No module named airflow.www.gunicorn_config
* 处理方式
在supervisor的配置文件的 environment常量中添加 PATH="/home/work/www/jerry/venv/bin:%(ENV_PATH)s"
* web界面报错
KeyError: 'Variable xxx does not exist'
* 处理方式
在airflow网页的Admin=>Variables页面添加对应的 变量
相关网址:http://airflow.apache.org/index.html

