Kubernetes CNI网络插件
CNI
容器网络接口,就是在网络解决方案由网络插件提供,这些插件配置容器网络则通过CNI定义的接口来完成,也就是CNI定义的是容器运行环境与网络插件之间的接口规范。这个接口只关心容器的网络连接,在创建容器是分配网络,删除容器是移除网络。插件就是对CNI的规范的具体实现。
Network Namespace提供的是什么
这里我们简要回顾一下,容器具有自己的网络协议栈而且被隔离在它自己的网络名称空间内,在这个隔离的网络空间里会为容器提供网卡、回环设备、IP地址、路由表、防火墙规则等这些基本的网络环境。
为什么POD中的容器共享同一网络名称空间
每一个POD中都有一个特殊的容器且永远是POD中创建的第一个容器,只是我们查看的时候看不到,因为它完成作用就暂停了。这个容器就是Infra容器,使用汇编语言编写。当创建POD的时kubernetes先创建名称空间,然后把其中的网络名称空间和这个Infra关联,后面属于你的创建的容器都是通过Join的方式与这个Infra容器关联在一起,这样这些容器和Infra都属于一个网络名称空间,这也就是为什么POD中多个容器可以使用本地通信的原因,所以严格意义来说网络名称空间属于Infra。我们看下面的演示
我们启动POD
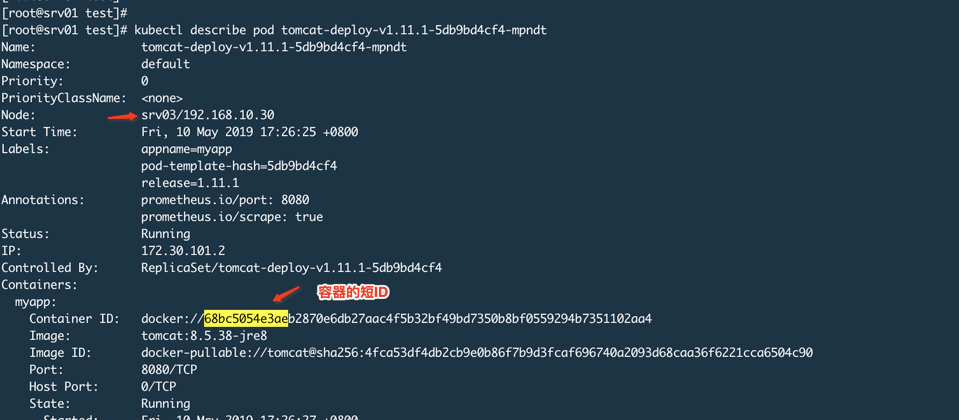
登陆Srv03

查看这个进程所属的名称空间,如下图:
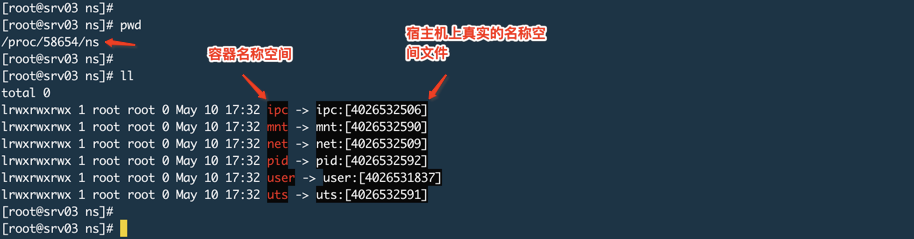
上图说容器名称空间,其实是那个进程的名称空间,名称空间名称-->该名称空间的文件描述符。
就拿net来说,它为进程提供了一个完全独立的网络协议栈视图,包括网络接口、IPV4/6协议栈、IP路由表、防火墙规则等,也就是为进程提供一个独立的网络环境。
进入POD中的容器,查看这个名称空间

可以看到链接的文件的指向的都是一样的,我这里的POD只有一个容器,如果设置2个你就可以分别进入查看,指向都是一样的。
上面的结果其实为进程创建的名称空间,Infra容器抓住网络名称空间,然后POD中的容器JOIN到Infra中,这样POD中的容器就能使用这个网络名称空间。所以Kubernetes的网络插件考虑的不是POD中容器的网络配置,而是配置这个POD的Network Namespace。
Infra是为了给容器共享网络名称空间,当然也可以共享volume。
理解了为什么POD里面的容器可以进行本地通信的原因,我们就要向下看一层,是谁给这个Infra使用的网络名称空间提供的各种网络栈配置呢?
谁为容器提供的网络配置
我们这里以网桥模式为例来说明。容器就是进程,容器拥有隔离的网络名称空间,就意味着进程所在的网络名称空间也是隔离的且和外界不能联系,那么如何让实现和其他容器交互呢?你就理解为2台独立的主机要想通信就把它们连接到一个交换机上,通过一个中间设备来连接两个独立的网络。这个就是能起到交换机作用的网桥,Linux中就有这样一个虚拟设备。有了这样一个设备那么就要解决谁来创建、谁来连接两个容器的网络名称空间的问题。
Docker项目
在Dcoker项目中,这个网桥是由docker来创建的且安装完之后就会默认创建一个这样的设备,默认叫做docker0,这种网桥并不是docker的专利,是属于Linux内核就支持的功能,docker只是通过某些接口调用创建这样一个网桥并且命名为docker0。
网桥是一个二层设备,传统网桥在处理报文时只有2个操作,一个是转发;一个是丢弃。当然网桥也会做MAC地址学习就像交换机一样。但是Linux中的虚拟网桥除了具有传统网桥的功能外还有特殊的地方,因为运行虚拟网桥的是一个运行着Linux内核的物理主机,有可能网桥收到的报文的目的地址就是这个物理主机本身,所以这时候处理转发和丢弃之外,还需要一种处理方式就是交给网络协议栈的上层也就是网络层,从而被主机本身消化,所以Linux的虚拟网桥可以说是一个二层设备也可以说是一个三层设备。另外还有一个不同的地方是虚拟网桥可以有IP地址。
充当连接容器到网桥的虚拟介质叫做Veth Pair。这个东西一头连接在容器的eth0上,一头连接在网桥上,而且连接在网桥上的这一端没有网络协议栈功能可以理解为就是一个普通交换机的端口,只有一个MAC地址;而连接在容器eth0上的一端则具有网站的网络协议栈功能。
完成上述功能就是通过Libnetwork来实现的:
Libnetwork是CNM原生实现的,它为Docker daemon和网络驱动之间提供了接口,网络控制器负责将驱动和一个网络对接,每个驱动程序负责管理它拥有的网络以及为网络提供各种负责,比如IPAM,这个IPAM就是IP地址管理。
Docker daemon启动也就是dockerd这个进程,它会创建docker0,而docker0默认用的驱动就是bridge,也就是创建一个虚拟网桥设备,且具有IP地址,所以dockerd启动后你通过ifconfig 或者 ip addr可以看到docker0的IP地址。
接下来就可以创建容器,我们使用docker这个客户端工具来运行容器,容器的网络栈会在容器启动前创建完成,这一系列的工作都由Libnetwork的某些接口(底层还是Linux系统调用)来实现的,比如创建虚拟网卡对(Veth pair),一端连接容器、一端连接网桥、创建网络名称空间、关联容器中的进程到其自己的网络名称空间中、设置IP地址、路由表、iptables等工作。
在dockerd这个程序中有一个参数叫做--bridige和--bip,它就是设置使用哪个网桥以及网桥IP,如下:
dockerd --bridge=docker0 --bip=X.X.X.X/XX
通过上面的描述以及这样的设置,启动的容器就会连接到docker0网桥,不写--bridge默认也是使用docker0,--bip则是网桥的IP地址,而容器就会获得和网桥IP同网段的IP地址。
上述关于网络的东西也没有什么神秘的,其实通过Linux命令都可以实现,如下就是在主机上创建网桥和名称空间,然后进入名称空间配置该空间的网卡对、IP等,最后退出空间,将虚拟网卡对的一端连接在网桥上。
# 创建网桥
brctl addbr
# 创建网络名称空间
ip netns add
# 进入名称空间
ip netns exec bash
# 启动lo
ip link set lo up
# 在创建的名称空间中建立veth pair
ip link add eth0 type veth peer name veth00001
# 为eth0设置IP地址
ip addr add x.x.x.x/xx dev eth0
# 启动eth0
ip link set eth0 up
# 把网络名称空间的veth pair的一端放到主机名称空间中
ip link set veth00001 netns
# 退出名称空间
exit
# 把主机名称空间的虚拟网卡连接到网桥上
brctl addif veth0001
# 在主机上ping网络名称空间的IP地址
ping x.x.x.x
Kubernetes项目
但是对于Kubernetes项目稍微有点不同,它自己不提供网络功能(早期版本有,后来取消了)。所以就导致了有些人的迷惑尤其是初学者,自己安装的Kubernetes集群使用的cni0这个网桥,有些人则使用docker0这个网桥。其实这就是因为Kubernetes项目本身不负责网络管理也不为容器提供具体的网络设置。而网络插件的目的就是为了给容器设置网络环境。
这就意味着在Kubernetes中我可以使用docker作为容器引擎,然后也可以使用docker的网络驱动来为容器提供网络设置。所以也就是说当你的POD启动时,由于infra是第一个POD中的容器,那么该容器的网络栈设置是由Docker daemon调用Libnetwork接口来做的。那么我也可以使用其他的能够完成为infra设置网络的其他程序来执行这个操作。所以CNI Plugin它的目的就是一个可执行程序,在容器需要为容器创建或者删除网络是进行调用来完成具体的操作。
所以这就是为什么之前要说一下POD中多容器是如何进行本地通信的原因,你设置POD的网络其实就是设置Infra这个容器的Network Namespace的网络栈。
在Kubernetes中,kubelet主要负责和容器打交道,而kubelet并不是直接去操作容器,它和容器引擎交互使用的是CRI(Container Runtime Interface,它规定了运行一个容器所必须的参数和标准)接口,所以只要容器引擎提供了符合CRI标准的接口那么可以被Kubernetes使用。那么容器引擎会把接口传递过来的数据进行翻译,翻译成对Linux的系统调用操作,比如创建各种名称空间、Cgroups等。而kubelet默认使用的容器运行时是通过kubelet命令中的
--container-runtime=来设置的,默认就是docker。
如果我们不使用docker为容器设置网络栈的话还可以怎么做呢?这就是CNI,kubelet使用CNI规范来配置容器网络,那么同理使用CNI这种规范也是通过设置Infra容器的网络栈实现POD内容器共享网络的方式。那么具体怎么做呢?在kubelet启动的命令中有如下参数:
-
--cni-bin-dir=STRING这个是用于搜索CNI插件目录,默认/opt/cni/bin -
--cni-conf-dir=STRING这个是用于搜索CNI插件配置文件路径,默认是/opt/cni/net.d -
--network-plugin=STRING这个是要使用的CNI插件名,它就是去--cni-bin-dir目录去搜索
我们先看看CNI插件有哪些,官网分了三大类,如下图:

-
Main插件:这就是具体创建网络设备的二进制程序文件,比如birdge就是创建Linux网桥的程序、ptp就是创建Veth Pair设备的程序、loopback就是创建lo设备的程序,等等。
-
IPAM插件:负责分配IP地址的程序文件,比如dhcp就是会向DHCP服务器发起地址申请、host-local就是会使用预先设置的IP地址段来进行分配,就像在dockerd中设置--bip一样。
-
Meta其他插件:这个是由CNI社区维护的,比如flannel就是为Flannel项目提供的CNI插件,不过这种插件不能独立使用,必须调用Main插件使用。
所以要用这些东西就要解决2个问题,我们以flannel为例,一个是网络方案本身如何解决跨主机通信;另外一个就是如何配置Infra网络栈并连接到CNI网桥上。
下面我们以flannel为例的网桥模式为例说一下流程
结合使用docker容器引擎以及flannel插件来说就是,kubelet通过CRI接口创建POD,它会第一个创建Infra容器,这一步是调用Dokcer对CRI的实现(dockershim),dockershim调用docker api来完成,然后就会设置网络,首选需要准备CNI插件参数、其次就是传递参数并调用这个CNI插件去设置Infra网络。对于flannel插件所需要的参数包含2个部分:
-
kubelet通过CRI调用dockershim时候传递的一组信息,也就是具体动作比如ADD或者DEL以及这些动作所需要的参数,如果是ADD的话则包括容器网卡名称、POD的Network namespace路径、容器的ID等。
-
dockershim从CNI配置文件中加载到的(在CNI中叫做Network Configuration),也就是从
--cni-conf-dir目录中加载的默认配置信息。
有了上面2部分信息之后,dockershim就会把这个信息给flannel插件,插件会对第二部分信息做补充,然后这个插件来做ADD操作,而这个操作是由CNI bridge这个插件来完成的。这个bridge使用全部的参数信息来执行把容器加入到CNI网络的操作了。它会做如下内容:
-
检查是否有CNI网桥,如果没有就创建并UP这个网桥,相当于在宿主机上执行
ip link add cni0 type bridge、ip link set cni0 up命令 -
接下来bridge会通过传递过来的Infra容器的网络名称空间文件进入这个网络名称空间中,然后创建Veth Pair设备,然后UP容器的这一端eth0,然后将另外一端放到宿主机名称空间里并UP这个设备。
-
bridge把宿主机的一端连接到网桥cni0上
-
bridge会调用IPAM插件为容器的eht0分配IP地址,并设置默认路由。
-
bridge会为CNI网桥添加IP地址,如果是第一次的话。
-
最后CNI插件会把容器的IP地址等信息返回给dockershim,然后被kubelet添加到POD的status字段中。
现在我们再来回顾一下之前那个问题,我的环境是kubernetes、flannel、docker都是二进制程序安装通过系统服务形式启动。我没有/opt/cni/bin目录,也就是没有任何CNI插件,所以也就没有设置--network-plugin。那通过kubernetes部署的POD是如何被设置网络的呢?
通过之前的介绍我们知道了kubelet通过CRI与容器引擎打交道来操作容器,那么kubelet默认是用容器运行时就是docker,因为kubelet启动参数--container-runtime就是docker,而docker又提供了符合CRI规范的接口那么kubelet就自然可以让容器运行在docker引擎上。接下来说网络,--network-plugin没有设置,那kubelet到底用的什么网络插件呢?而CNI插件里面也没有docker插件这个东西。我们看一下这个参数说明如下:
The name of the network plugin to be invoked for various events in kubelet/pod lifecycle. This docker-specific flag only works when container-runtime is set to docker.
前半句意思是说这个参数定义POD使用的网络插件名称,但是后面半句的意思是如果使用的容器运行时是docker,那么默认网络插件就是docker。
二进制安装环境下如何使用CNI
我的环境所有组件都是二进制安装,以系统服务形式运行。最初是使用docker0网桥。这里说一下过程:
-
你需要向etcd写入子网信息
{"Network":"'${CLUSTER_CIDR}'", "SubnetLen": 24, "Backend": {"Type": "vxlan"}}。 -
flanneld服务启动后会去etcd中申请本机使用的子网网段,然后就会写入到
/run/flannel/subnet.env文件中 -
然后flanneld的service文件中有一条
ExecStartPost=指令,就是在flanneld启动后执行的,作用就是调用一个脚本去修改dockerd的--bip参数把获取的子网信息写入 -
启动docker服务,然后dockerd会根据--bip的信息设置docker0网桥
在上面这个过程中部署的POD容器的网络协议栈都是docker来设置的,当然是kubelet通过调用CRI接口来去和docker交互的,跨主机通信是由flannel来完成的。
现在我们要在某一台主机上切换成CNI,需要做如下修改:
-
建立目录
mkdir -p /opt/cni/{bin,net.d} -
下载CNI插件到上面的bin目录中,然后解压。
-
在上面的net.d目录中建立10-flannel.conflist文件,内容后面再说。
-
停止该主机的docker、kubelet服务,这样该主机的容器就会被master调度到其他可用主机,不过DaemonSet类型的则不行。
-
修改docker服务文件的dockerd的启动参数,去掉那个环境变量,增加--bip=10.0.0.1/16,这个IP随便,主要是为了不占用etcd中要使用的地址段,因为最初它用就是etcd中分配的。
-
修改kubelet服务文件,增加3个参数
--cni-bin-dir=/opt/cni/bin --cni-conf-dir=/opt/cni/net.d --network-plugin=cni,最后这个一定要写cni,不要写flannel,因为这里我们要用的就是cni,而至于cni会使用什么插件,这个在配置文件中写。因为在kubernetes中只有2类插件,一个是cni一个是kubenet,这里设置的是用哪一类插件。 -
然后启动之前停止的服务
10-flannel.conflist文件内容
{
"name": "cni0",
"cniVersion": "0.4.0",
"plugins": [
{
"type": "flannel",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
},
{
"type": "portmap",
"capabilities": {
"portMappings": true
}
}
]
}
还可以简化为这样
{
"name": "cni0",
"type": "flannel",
"subnetFile": "/run/flannel/subnet.env",
"delegate": {
"hairpinMode": true,
"isDefaultGateway": true
}
}
name: 网络名称而不是网桥的名字
cniVersion: 插件版本,可以不写。
subnetFile: 本机flanneld从etcd中申请的本机网段,这个信息存放在哪个文件中,默认就是/run/flannel/subnet.env,我没有改位置,所以可以省略。
plugins:表示使用什么插件
type: 插件类型,这里是flannel
delegate:这个CNI插件并不是自己完成,而是需要调用某中内置的CNI插件完成,对于flannel来说,就是调用bridge。flannel只是实现了网络方案,而网络方案对应的CNI插件是bridge,我们下载的插件里面就包括了bridge,所有flannel对应的CNI插件就已经被内置了,因为flannel方案本身就是使用网桥来做的。
执行过程如下:
kubelet调用CRI接口也就是dockershim,它调用CNI插件,也就是/opt/cni/bin中的flannel程序,这个程序需要2部分参数,一部分是dockershim的CNI环境变量也就是具体动作ADD或者DEL,如果是ADD则是把容器添加到CNI网络里,ADD会有一些参数;另外一部分就是dockershim加载的JSON文件,然后/opt/cni/bin/flannel程序会对2部分参数做整合以及填充其他信息比如ipam信息也就是具体的子网信息,ipMasp信息,mtu信息,这些都是从/run/flannel/subnet.env文件中读取的,然后flannel会调用CNI的birdge插件,也就是执行/opt/cni/bin/bridge这个命令,由它来完成将容器加入CNI网络的具体操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号