深入学习Redis(四) Redis高可用之集群
概述
Redis的集群主要是使用切片技术来搭建的,简单来说就是把所有KEY分散存放到不同的redis节点上(不要把鸡蛋都放在一个篮子里)。
1. 集群基本原理
Redis集群中内置了16384个槽位,当需要放置数据时,Redis先对KEY使用CRC16算法计算出一个结果,然后把结果对16384求余数,这样每个KEY都会对应一个编号在0---16383之间的槽号码,Redis会根据节点数量大致均等的原则将哈希槽映射到不同节点。比如有3个Redis节点,把16384分成3段,每个节点承担一段范围的哈希槽。
好处是添加和移除节点非常容易。比如要新增一个节点,值需要从其他节点上移动一些槽位到新节点即可,如果要删除一个节点,那就把它拥有的槽位移动到其他节点,然后进行删除。上面这种移动过程不需要任何停机时间。
- 所有的redis节点彼此互通
- 节点的失败是通过集群中超过半数的节点检测失效才生效的
- 客户端与Redis节点直连,不需要中间的代理,客户端不需要连接集群所有节点,只需要连接任何一个可用的节点即可
Redis集群是通过分片的方式来保存数据库中的键值对,也就是把所有键值对分摊的放在0---16383之间的槽位上。在一个集群中16384个槽位必须同时在线否则集群就会失败。
1.1 集群使用的数据结构
- ClusterState:这个结构记录了在当前节点的视角下,集群此时所处的状态,比如集群是否在线、集群有多少个节点等。每一个节点都保存着一个ClusterState结构。
- ClusterNode:保存了一个节点的当前状态,比如创建时间、节点名字、节点的配置纪元、节点的IP以及端口号等。每一个节点都会使用一个ClusterNode结构来记录自己的状态,并为集中的其他节点也创建一个这个结构用于记录其他节点的状态。
- ClusterLink:这个是ClusterNode中Link属性用到的一个结构,该结构保存连接节点的信息,比如套接字ID、输入和输出缓冲区等。这里的输入和输出缓冲区和RedisClient结构中的输入输出缓冲区是由区别的,它的输入输出缓冲区用对于节点来说的,也就是节点间的传输所使用的,而RedisClient的输入输出缓冲区是给客户端使用的。
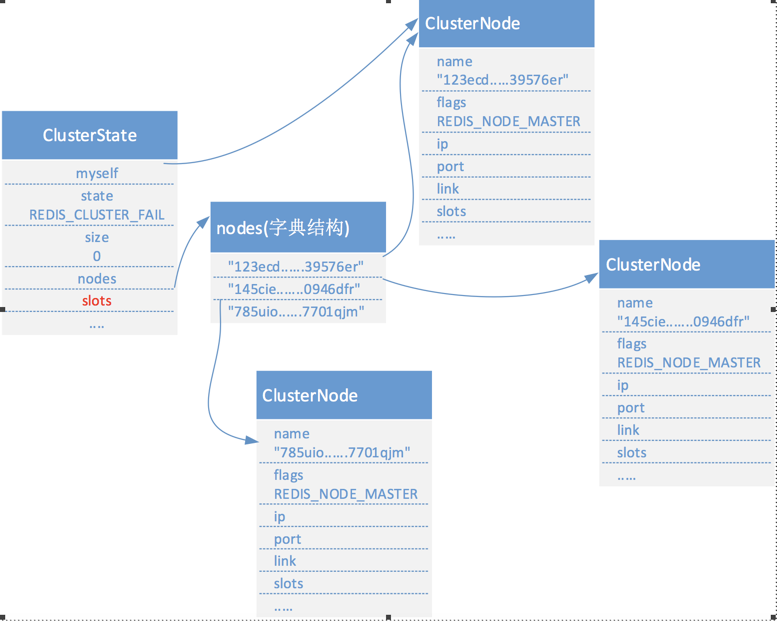
16384个槽位是保存在一个二进制的数组中(slots)。该数组是由ClusterNode结构中的slots字符变量来实现的,数组里面存储的都是1或者0,如果数组中的某个索引位的值为1表示该槽由当前的节点来处理,如果为0则表示该槽不由当前节点来处理。
为什么是当前节点?因为ClusterNode记录的当前节点的状态。一个节点除了记录自己的槽位信息之外,还会把该信息传播给其他节点,告知它们自己负责哪些槽位。也就是说集群中的每个节点都是值得数据库中的16384个槽位都分配给了谁。
在ClusterState结构中也有一个slots,它记录了集群中所有16384个槽的指派信息,这个数组有16384个项,每个项都是一个只向ClusterNode结构的指针。如果slots[i]指向NULL,则表示该槽未被指派,如果指向某个ClusterNode,则表示该槽已经被分配某个节点。如下图:
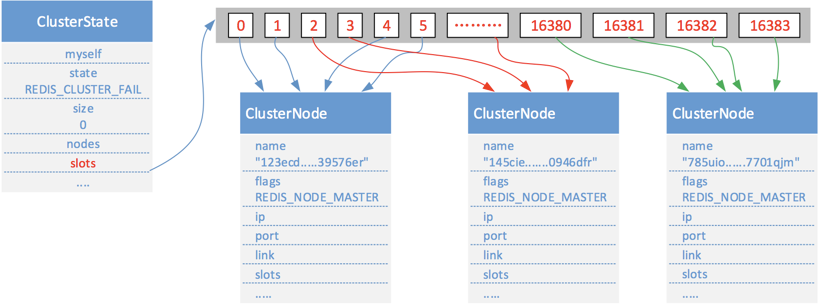
我们看到在ClusterState中的slots和ClusterNode中的slots是不一样的,既然ClusterState中的slots中保存着所有槽位的指派信息难道还需要ClusterNode中的slots吗?在一个在线集群中ClusterState里的slots数组中每一位都对应一个ClusterNode,而且有可能不是顺序的就像上图。如果这时要把某个节点的槽位信息发送给其他节点,那么如果只有ClusterState也是可以的,不过要遍历整个slots数组,显然效率很低,如果使用ClusterNode中的slots就方便了,直接把整个数组复制给节点就行了,因为该数组里面1为指派,0为不指派,对于其他节点来说非常容易识别。
1.2 集群中的数据访问
因为采取了数据库切片技术,整个数据库分片到了N个服务器上,这时候去访问数据库就会出现一个问题,因为程序是直接访问集群节点的,如果程序此时要获取的数据不在当前访问节点会怎么办?处理过程是这样的:
当节点接收到一个命令请求时首先会计算出该键属于哪个槽,并检测该槽是否指派给了自己:
- 如果是则直接处理命令
- 如果不是则会向客户端返回一个MOVED的错误,并指引客户端重定向到正确的节点,客户端再次发送命令给正确的节点
1.3 如何确定哪个键属于哪个槽位
节点使用CRC-16的算法计算KEY的校验和,然后再做一个和16383的与操作(&),这样就计算出一个0-16383之间的一个整数,这样就确定了该键应该被分配到哪个槽中。
1.4 故障转移过程及故障检测
上面一直在说集群的一些原理,而集群的目的为了提高处理能力,当出现节点故障的时候怎么办呢?
Redis集群提供故障转移功能,该功能是通过主从复制来实现的。默认情况下集群中的任何节点都是主节点,大家并不相互复制,这点很好理解,因为整个0号数据库被分片指派到了不同的物理服务器上,大家存储的数据是不同的,只有这样才能提高整体的IO性能。
为了实现故障转移,我们就需要为集群中的主服务器建立一个从服务器,进而实现从服务器与某一个主服务器的同步,从服务器拥有和主服务器一致的槽位信息。其复制原理和普通的主从复制一样,只是配置集群的主从复制方法不同而已。
1.4.1 故障检测
集群中的每个节点都会定期向集群中的其他节点发送PING消息,来检查对方是否在线,如果接受PING消息的节点没有在规定时间内回复PONG消息,则发送PING消息的节点就会将接受PING消息的节点标记为可能下线(probable fail, PFAIL)。
集群中各个节点会通过相互发消息的方式来交换集群中各个节点的状态,如在线、可能下线(PFAIL)和下线(FAIL)。
如果一个集群,半数以上的主节点将某一个主节点标记为可能下线(PFAIL),那么这个主节点将会被判定为下线(FAIL),并将下线标记扩散到整个集群中。
B和C定期发送PING消息,D确没有回复,那么B和C就会更改自己视角中的D节点的下线报告,然后他们又把消息传送给了A,A是如何处理呢?看下图。

根据上图,其实对于集群中第一个发现某个节点可能下线的过程也是一样的,它在一定时间内没有收到PONG消息,就会更新自己的表,同时向集群其他节点发送消息。
1.4.2 故障转移过程
要想故障转移,首先要为主节点设置一个从节点。当从节点发现自己复制的主节点下线时,从节点将执行故障转移:
- 在该下线主节点的所有从节点(与下线主节点有复制关系,其他主节点的从节点不算)中会有一个从节点被选中。
- 被选中的从节点执行SLAVEOF on one命令,取消复制,把自己变成主节点
- 新的主节点会把下线主几点的所有指派槽指派给自己
- 新的主节点广播一条PONG消息,通知其他主节点,自己变成了主节点
- 新主节点开始接受与自己负责槽位有关的命令请求。
1.4.3 关于集群消息
| 消息 | 含义 |
| MEET | 接收者收到这个命令表示被邀请加入到集群中 |
| PING |
每个节点默认每一秒就会从已知节点中随机选出5个节点,然后对这5个节点中最长时间没有发送过PING消息的节点发送PING消息。 如果节点A最后一次收到节点B发送的PONG消息,超过了节点A的cluster-node-timeout参数的一半,那么A还会再给B发送一条PING消息。 |
| PONG |
接收消息的节点无论是接收到MEET还是PING,都会以PONG消息作为回复,以确认自己收到了之前的消息。 |
| FAIL | 当一个节点A判断另外一个节点B为FAIL状态后,节点A会向集群广播一个节点B的FAIL消息,收到该消息的节点会更新自己的ClusterState中对B节点的状态描述符flags,为下线。 |
| PUBLISH | 当节点收到一个PUBLISH消息后,节点会执行这个命令,并向集群广播一条PUBLISH消息,所有收到该消息的节点都会执行相同的命令。 |
1.5 什么时候集群不可用
- 集群中的任意Master失败,且当前的Master没有Slave,则集群进入失败状态,其实就是整体的0---16383这些槽不完整。
- 如果集群中超过半数的Master失败,无论是否有slave,集群宣告失败
当集群不可用时,所有对集群的操作都不可执行
1.6 部署
注意:Redis默认需要3个主节点,所以一个完整的集群是6个节点。
部署分为几个阶段:启动实例、建立集群、节点加入集群、为集群中的节点分配槽位、配置复制。
部署的结构分为两种:单台Redis服务器启动多个实例以不同端口号运行、多台独立的Redis的服务器端口相同但是IP地址不同。如果是实验环境可以采取第一种,但是生产环境还是第二种更合适。
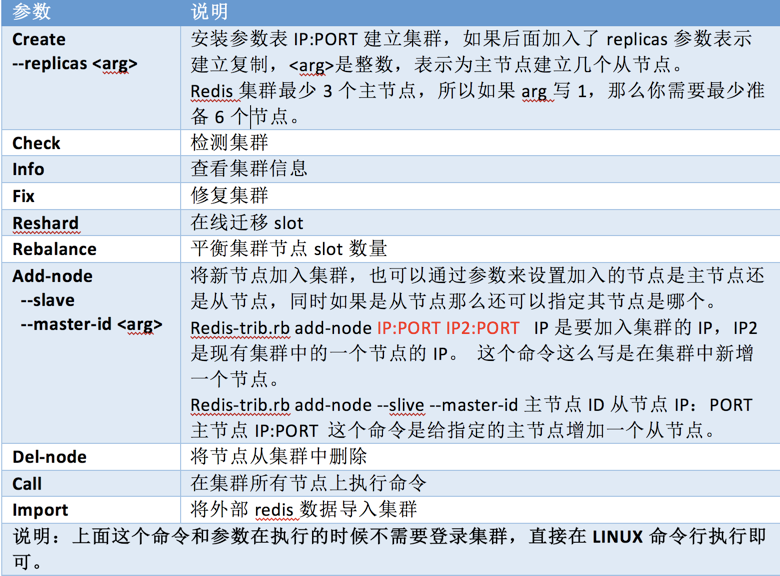
不论哪种部署结构其部署的方式都是一样,也有两种:手动建立和自动建立。手动建立的方式就是通过客户端命令手动完成、自动建立则是通过集群管理命令redis-trib.rb来自动完成。
注意:如果采用自动建立的方式那么服务器环境中需要安装ruby和gem。YUM安装如下
yum install ruby rubygems gem install redis -v 具体版本
https://rubygems.org/gems/redis/versions 参考这个网站针对不同版本的redis有不同的gem install redis –v 命令,我这里是3.0.7 gem install redis -v 3.0.7
1.6.1 集群相关命令
# ====== 集群信息 ====== Cluster info # 打印集群信息 Cluster nodes # 显示当前集群所有的节点
# ====== 节点操作 ====== Cluster meet <ip> <port> # 将指定的IP和端口的节点加入到集群中 Cluster forget <node_id> # 将指定的节点从集群中移除 Cluster replicate <node_id> # 将当前节点设置为指定节点ID的从节点,<node_id>是主节点的ID Cluster saveconfig # 将节点的配置文件保存到硬盘中 Cluster nodes # 查看节点间相互连接情况 Cluster failover # 在从节点上执行,执行主从切换,如果主节点不可用,则命令无法完成切换,该命令是在主 # 从都可用的情况下进行切换的 Cluster failover force # 功能同上,只是进行强制切换,无论主是否可用 Cluster slaves <node_id> # 在主节点上执行,返回该主节点下所有从节点
# ====== Slot槽操作 ====== Cluster addslots <slot> [slot…] # 将一个槽或多个槽指派给当前节点,槽号码之间有空格 Cluster delslots <slot> [slot…] # 将一个或多个槽从当前节点中移除,也就是解除指派 Cluster flushslots # 移除指派给当前节点的所有槽 Cluster setslot <slot> NODE <node_id> # 将指定的槽委派给指定的节点,如果该槽已经被指派给其他节点,则要先删除指派再进行重新分配。 Cluster setslot <slot> Migrating <node_id> # 将当前节点的slot迁移到指定节点中 Cluster setslot <slot> Importing <node_id> # 把指定节点的槽导入到当前节点中 Cluster setslot <slot> Stable # 取消对槽的导入或迁移 Cluster slots # 返回集群所有slot与node的映射关系
# ====== 键操作 ====== Cluster keyslot <key> # 计算键应该被放在哪个槽上 Cluster countkeysinslot <slot> # 返回槽目前包含键对的数量 Cluster getkeysinslot <slot> <count> # 返回count个槽中的键
说明:上面这些命令都是在集群里执行的也就是说要先通过客户端(redis-cli)登录集群才行。
登录集群和登录普通模式不同需要使用-c参数,如下:

1.3.2 自动建立集群
该命令位于Redis安装包里面的src目录下,如下图:


我这里有3台虚拟机分别运行3个Redis实例,IP地址如下:172.16.100.10---60 端口均为默认的6379端口
我这里不采用全自动方式,而是采用半自动方式,集群的建立自动化,但是主从复制我手动来完成,也就是手动指定哪个服务器是哪个主节点的从节点。
如果是全自动的方式命令如下:

Create 是建立集群 --replicas 1 则是说明给每个主节点建立1个从节点
修改配置文件

每一个节点的配置文件都需要修改
建立集群:

注意:建立集群使用数据库0,所以该数据库不能有任何键存在,否则建立集群会失败。登录到客户端用dbsize查看0号数据是否有任何KEY,如果有要使用flushdb清空一个数据。或者使用flushall清空所有数据库。
查看槽位分配信息

设置从节点:
可以通过如下命令实现(任选其一即可):
Cluster replicate <node_id> # 主节点ID。在当前需要被设置为从节点的客户端里执行
Redis-trib.rd add-node # 这个命令可以用来添加主节点,也可以为主节点添加从节点
使用cluster replicate命令添加:
我们为172.16.100.10 添加一个从节点,从节点的IP是172.16.100.40,操作如下:
把40加入到集群中(要用10的客户端)

设置40为10的从节点(要用40的客户端)
下图用的NODE_ID是10的ID


使用Redis-trib.rd add-node命令添加
我们给20设置一个从节点,该从节点IP为50

上图的ID是20的ID信息,后面是从节点的IP和端口,以及20服务器的IP和端口。
测试故障转移:
三个键分别存在在不同的服务器上,如下图:
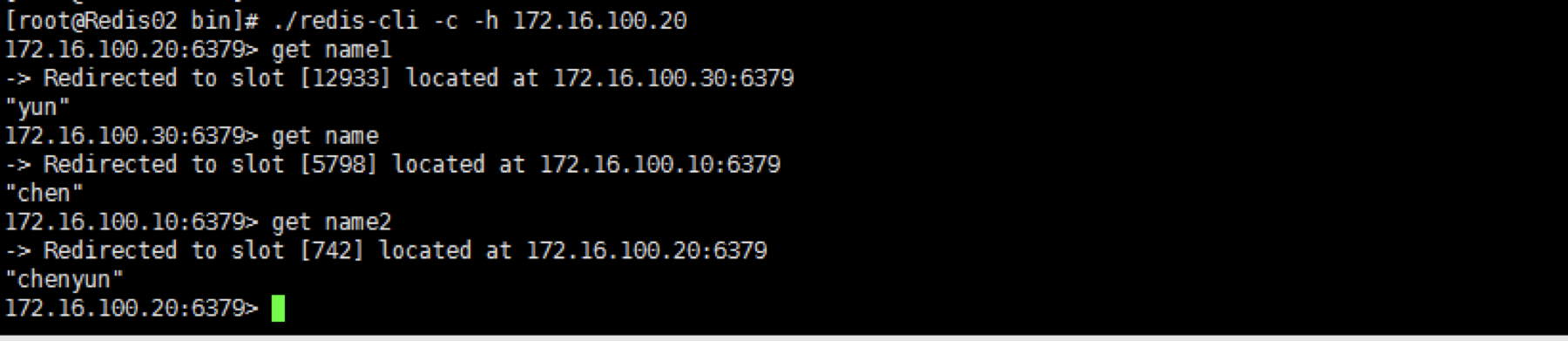
Name在10上、name1在30上、name2在20上

10已经看不到了,但是所有数据都在。
1.3.3 集群日常操作
添加节点以及添加从节点上节已经说过,下面我们说明一下其他操作。
删除从节点:
执行redis-trib.rb这个脚本命令来完成
10是40的从节点,我们删除10这个节点
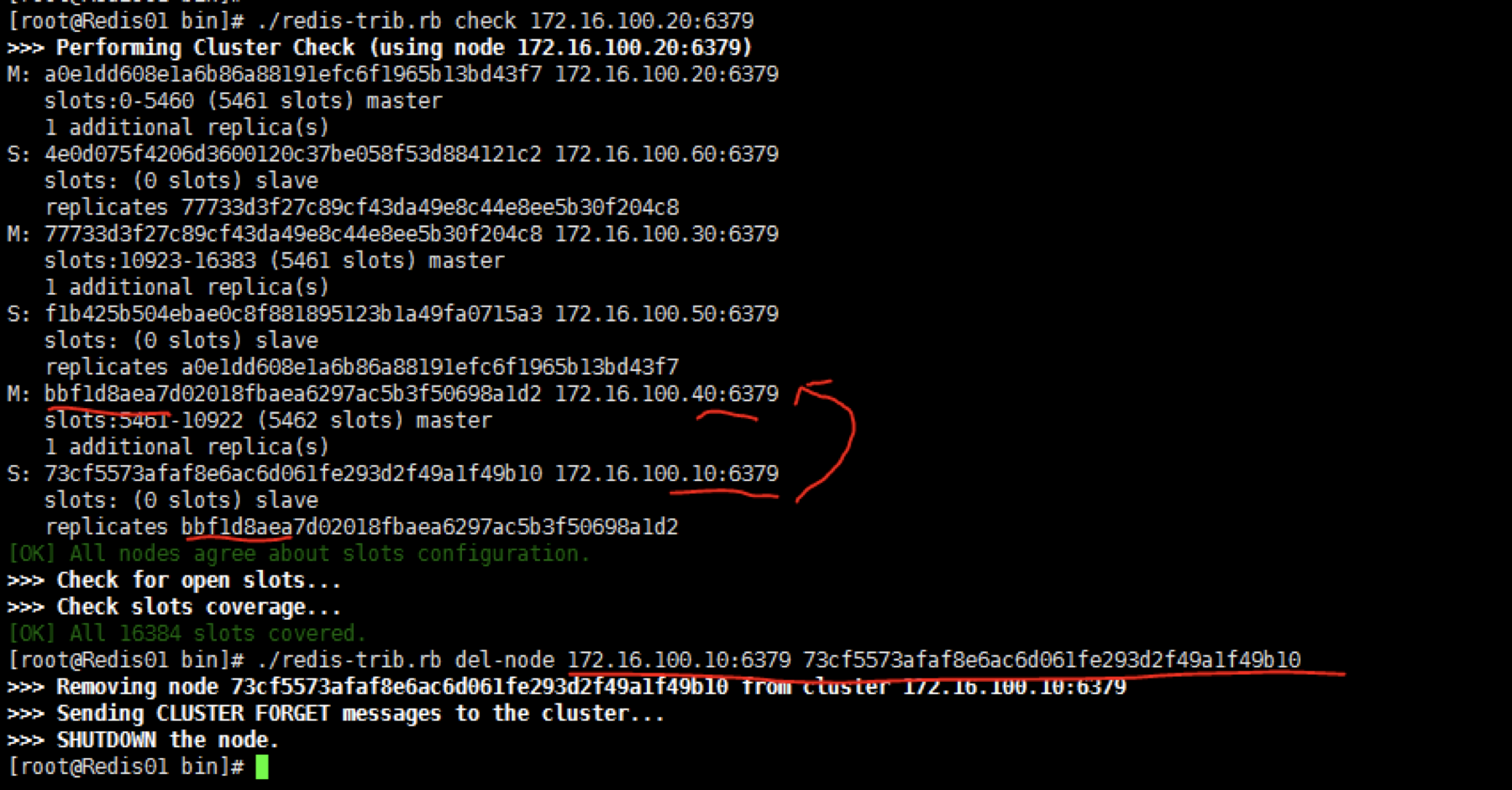
说明:命令后面是10的IP和端口,以及10的NODE_ID。我们看到后面输出信息是发送CLUSTER FORGET信息到集群,但是如果在客户端里执行CLUSTER FORGET 返回OK,但是从节点并没有删除。
删除后10节点没有了

在现有集群中添加主节点并重新分配槽位:
集群最少3个主节点,那么日后再添加一个节点作为主节点时,该主节点被添加完成后是无法存放数据的,因为没有槽位(槽位都已分配到了之前的3个主节点上),所以就需要重新分配槽位。查看现有集群情况并添加50到集群中
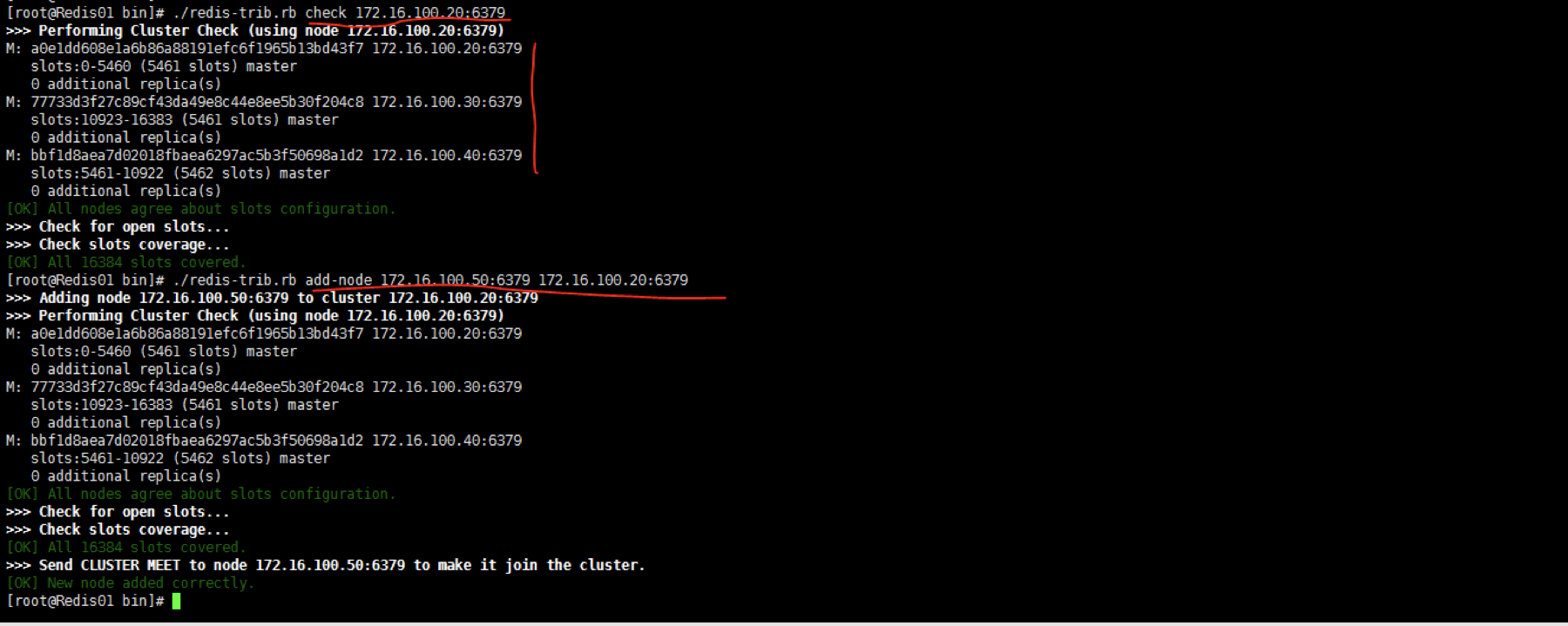
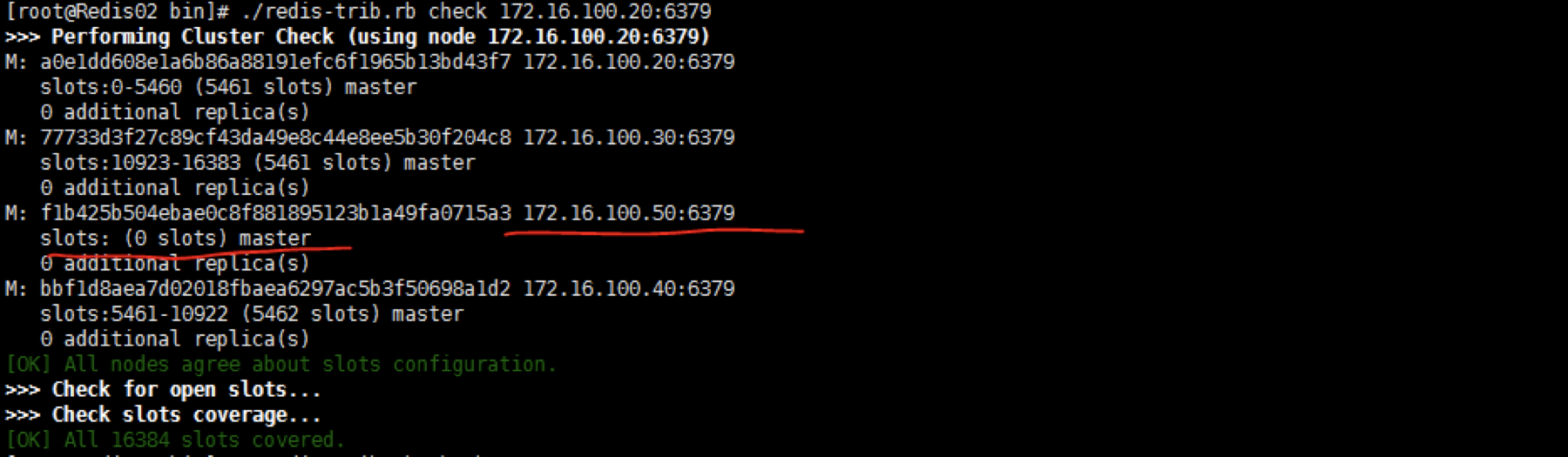
添加后查看集群情况,没有槽位信息。如果用上面的命令添加后在查看20集群时看不到50这个机器,那么就登录20的客户端,运行一下cluster meet IP PORT这个命令。
重新分配槽位
第一个问题是:你想移动多少个槽位到新节点,不能写全部,否则就会把所有槽位都分配到该节点上,除非你想这么做。
第二个问题是:新节点的ID是多少
第三个问题是:源节点什么,回答是all,则表示从所有节点中分配,如果输入done则表示你指定到哪个NODE_ID上去移动这些槽位到新的节点。我这里直接在第一个问题上输入了16384,目的是为了演示后面的删除主节点和rebalance操作,所以我把所有槽位都全部移动到了50这个机器上。
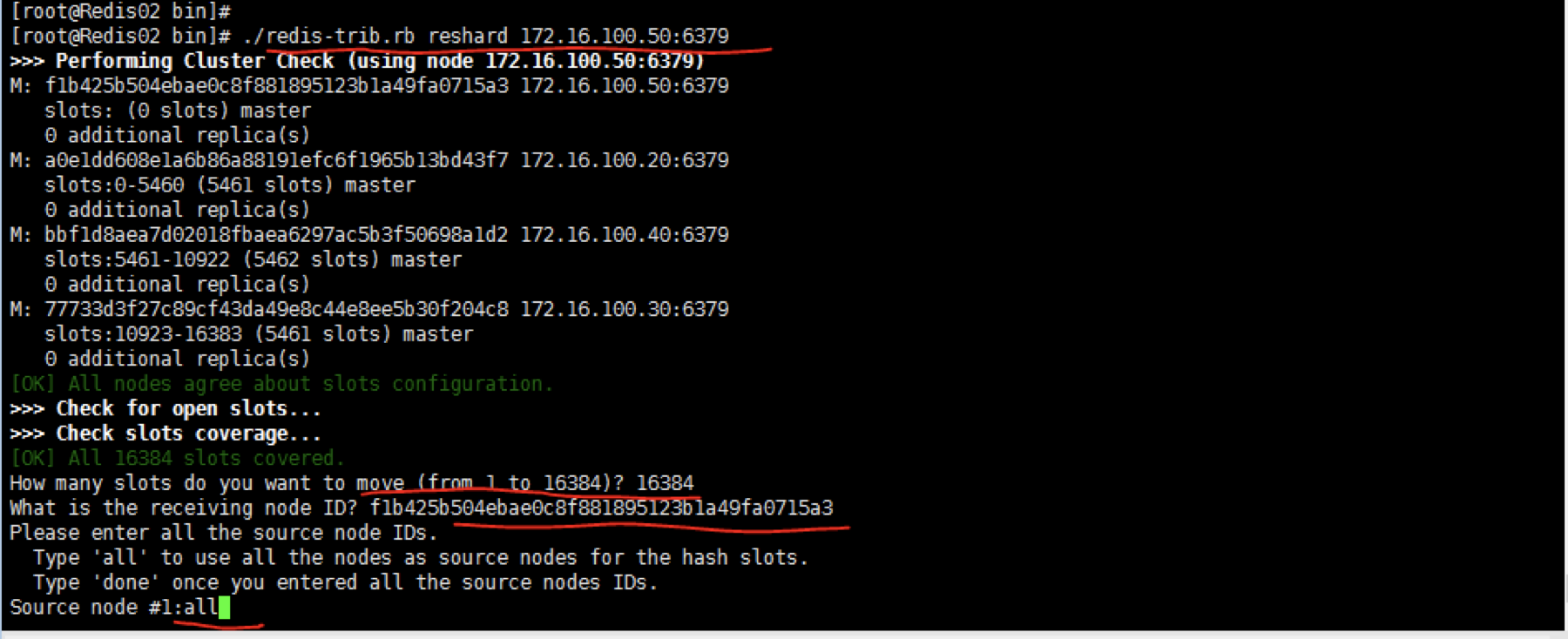

50具有所有槽位,其他节点的槽位为0。上面的命令也可以这么写:
Redis-trib.rb reshard --from all --to NODE_ID --slots NUMBER IP:PORT --yes # 意思是从所有节点里面迁移NUMBER个槽位到NODE_ID,集群信息从IP:PORT # 这个主机获得。输入这样的命令,就不会有中间哪些问题了。 --yes # 的意思是在打印迁移计划的时候提示用户输入yes,然后在执行从新分配槽位动作。
删除主节点:
删除主节点和删除从节点用的命令相同。只不过会多一步移动该主节点槽位到其他主节点的操作。删除主节点实际上也要重新分配槽,因为要把该主节点上的槽位移动到其他主节点,以保证槽位的完整。

删除20后,以及没有20这个主节点了

平衡集群节点槽位数量:
Rebalance参数可以根据用户传入的参数平衡集群节点槽位数量。看一下现在的槽位分配情况

下面是一条模拟命令,就是去模拟执行重写分配,但是并不会真的重新分配.


我们现在要把16384个槽位重新分配到3个主节点上(30、40、50),此时50拥有所有槽位。
我这里使用了--use-empty-masters参数,因为30和40的槽位数是0,默认槽位数是0的主节点不参与重新分配,所以必须要加这个参数。


整个过程会比较慢因为是所有槽位重新分配到所有主节点上。在生产环境中会更慢因为有大量数据存在。

重新分配之后,每个主节点的槽位是否相等取决于权重以及是否可以被16384整除。
计算KEY应该放在哪个槽位上:
使用cluster keyslot命令

这个命令的意思是给定一个KEY名称,然后后台会根据算法计算出如果建立该键值对象,那么该KEY将会被放置在哪个槽位上。
1.2 ASK和MOVED的说明和区别
对于用户来说,这个两个错误信息都是对用户请求KEY的重定向,但是出现场景还是有区别的,我们先说什么是KEY的重定向
因为16384个槽分配的到了不同的实例上,所有你在连接某一个客户端后,在获取KEY时,该KEY不一定就在你连接的那个数据库实例上,如果是则直接返回,如果没有它会帮
你重定向到正确的数据库上执行命令,并给你返回数据,同时提示你这中间有一个重定向过程。
ASK:在槽被迁移过中发生,KEY原来属于节点B,但是现在要迁移到节点A,如果在迁移过程中客户端连接节点B请求KEY,则发送ASK重定向,把请求重定向到A,由A返回数据。
MOVED:在正常情况下,KEY属于B,而此时连接到A的客户端请求KEY,则发生MOVED重定向,把请求重定向到B,由B返回数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号