深入学习Redis(三) Redis高可用之主从复制
Redis高可用
高可用简称HA,这里面包含很多种类似的高可用,比如数据的高可用、服务的高可用以及数据和服务的高可用等。
在Redis中常用的是主从复制,这个更多体现在数据高可用,把主服务器的数据同步到从服务器上,因为从服务器不建议开启写操作,所以任何对数据库的写操作都会在主服务器上进行。
另外就是Redis Cluster,这个是Redis自带的功能,其实这个侧重点是负载均衡并不能完全算在高可用里面,这个后面介绍。还有就是Keepalived+redis的组合,实现故障转移。
1. 主从复制
按照上面的步骤安装2台Redis服务器。下面是我的结构:
| 名称 | 地址 |
| Redis01 | 172.16.100.10 |
| Redis02 | 172.16.100.20 |
和MySQL的主从一样,这种结构主要是为了数据冗余和提示性能。Redis的主从同步是异步进行的,所以并不会影响主的处理性能。在数据持久化方面,可以把这个任务交给从服务器来做,这样可以减小主服务器的负担。在主从结构中,一般把从服务器设置为只读模式,这样也是为了更好的保持数据一致性。
Redis主从同步有两种方式,一种是全同步和部分同步,当然执行哪种同步是自动判断的无需人工干预。
Redis的复制功能分为同步(SYNC)和命令传播(COMMAND PROPAGATE)两个操作:
- 同步操作:将从服务器的数据库状态更新至主服务器当前所处的状态
- 命令传播:当主服务器数据被修改后,通过命令传播使主从数据库状态一致
1.1 旧版的复制(Redis 2.8以前的版本)
上面提到同步有两种方式全同步和部分同步,在旧版中只有全同步没有部分同步。同步过程如下:
- 从服务器向主服务器发送SYNC命令
- 主服务器收到SYNC命令后执行BGSAVE命令,在后台生成一个RDB文件,并使用缓冲区记录从现在(当BGSAVE执行的那一刻)开始执行的所有写命令。
- 当主服务器使用BGSAVE命令执行完毕后,主服务器会将RDB文件发送给从服务器,从服务器载入这个RDB文件,将自己的数据库状态更新至主服务器执行BGSAVE那一刻的状态。
- 主服务器将缓冲区里面记录的所有写命令发送给从服务器,从服务器执行这些命令,从而使主从数据库状态一致。
同步完成后,主服务器的数据也会随着后期的写操作而变化,所以就需要通过命令传播功能把在主服务器上执行的写命令传递给从服务器来实现主从数据库状态一致。
旧版复制功能的缺陷:
- 初次复制:从服务器以前没有同步过任何主服务器,或者从服务器当前要同步的主服务器和上次同步的不同
- 断线后复制:处在同步过程中,但因其他原因导致网络中断,进而造成复制中断,再重新恢复网络连通后的复制。
对于初次复制整个过程没有问题,但是断线后复制则会执行全同步,这样效率比较低。因为SYNC过程很消耗资源,生成RDB会消耗CPU、内存和磁盘IO资源,发送RDB的过程会占用网络带宽,从服务器载入RDB时会阻塞服务器从而无法处理请求。
1.2 新版的复制实现(Redis 2.8以后版本)
在新版中使用了PSYNC来代替SYNC执行同步任务。PSYNC有两种模式也就是上面提到的全同步和部分同步:
- 全同步用于初次同步,执行过程和SYNC一致
- 部分同步则重点在于同步断线期间(一定期间而非无限期间)的内容,也就是说在规定期间内执行增量部分的同步,如果超过了规定期间则执行全同步。
部分同步的三个重要概念:
- 主服务器的复制偏移量和从服务器的复制偏移量
- 服务器的复制积压缓冲区
- 服务器的运行ID
复制偏移量:主服务器每次给从服务器传递N个字节的数据时,就将自己的复制偏移量增加N,同时从服务器收到N个字节以后,也会再自己的复制偏移量上加N,从而保持主从的复制偏移量一样,这样就可以判断主从的数据库状态是否一致。
复制积压缓冲区:改缓冲区是一个定长的先进先出的队列,默认是1MB。主服务器把命令传递给从服务器的同时也会向自己的积压缓冲区队列写入这个命令。所以这个缓冲区里面保存了一部分最近的写命令,并且缓冲区会为队列的每个字节记录偏移量。
当从服务器断线重新连接后,会发送PSYNC命令,同时包含自己的复制偏移量,主服务器根据这个复制偏移量来决定用何种同步方式。如果该偏移量之后的数据(偏移量+1开始的数据)仍然在复制积压缓冲区内,那么执行部分同步,否则执行全同步。
服务器的运行ID:每个Redis服务器都有一个唯一ID标识符,该ID是自动生成的一个40位十六进制字符。当初次复制时,主从服务器会保存彼此的ID,当断线后,从服务器除了向主服务器提供复制偏移量以外还需提供从服务器保存的主服务器的ID,当主服务器接受到ID后,先检查是否和自己的一样,如果一样表示从服务器请求的是一个断线后同步,再根据偏移量来决定执行全同步还是部分同步;如果该ID不是自己的ID,则表示是一个初次同步,则执行全同步。
在新版中的命令传播,从服务器会以默认每秒的频率向主服务器发送REPLCONF_ACK,该任务会传递从服务器的复制偏移量,同时也是为了进行心跳检测。如果主服务器超过1秒都没有收到从服务器的REPLCONF_ACK,则主服务器会认为连接出现了中断。
在主服务器的控制台输入INFO replication可以在lag一栏看到从服务器最后一次向主服务器发送REPLCONF_ACK命令距离限制过了多少秒,一般该值为0或者1,超过1秒则表示有问题,如下图:


Redis主从复制的特点:
- 同一个Master可以和多个Slave同步
- Slave也可以接受来自其他Slave的同步请求,这样可以减少Master的同步压力
- Master以非阻塞的方式为Slave提供同步服务,所以在同步期间,客户端仍然可以向Master提交读写操作。
- Slave之间同样也是以非阻塞的方式完成数据同步,所以在同步期间,Slave是可以向客户端提供查询服务的。(允许分区容错)
- 写操作只能由Master来完成,默认情况下Slave只提供读服务。(保证一致性)
- Master可以把数据持久化的工作交给Slave来做,这样可以降低Master的负载。
1.3 配置主从复制
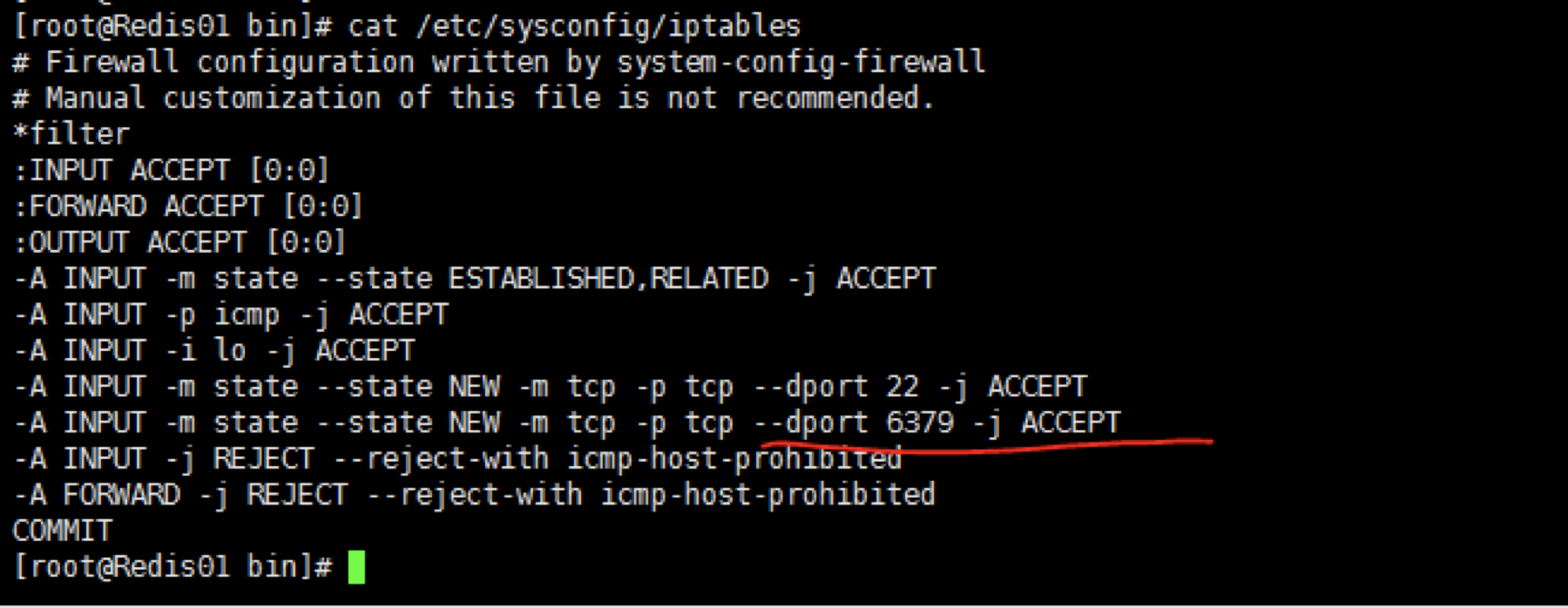
1.3.1 开启防火墙
打开6379端口
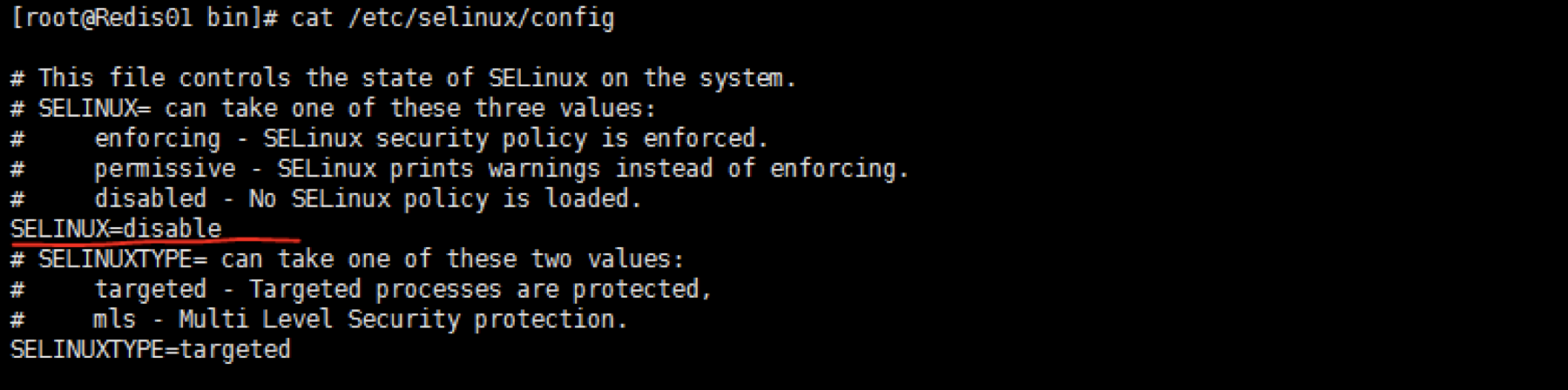
关闭selinux
然后重启iptables服务
1.3.2 修改配置文件
修改主服务器配置文件,如果不需要密码验证可以不用修改此文件
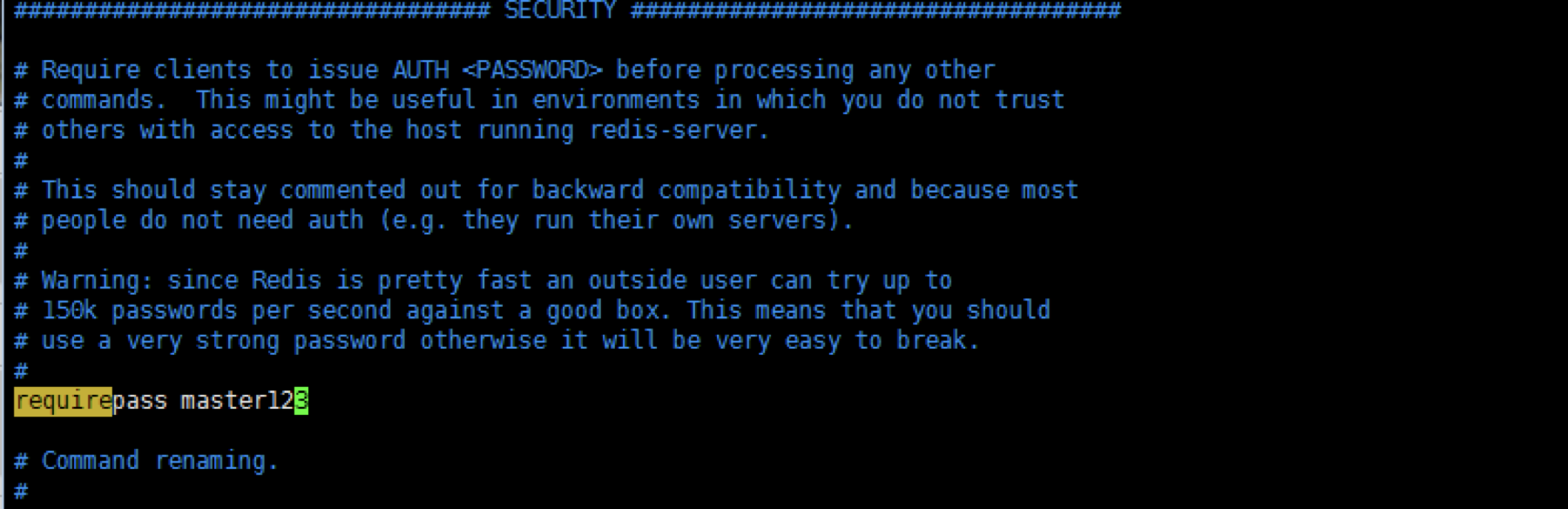
保存并退出,然后重启服务
修改从服务器配置文件,找到slaveof字段,如果主服务器有密码验证,则要配置为相同的密码,如下图:

保存并退出,然后重启服务。
1.3.3 验证主从复制
在主服务器设置一个键值数据

在从服务器上获取这个键值

通过info查看链接信息,在主服务器执行下面的命令:


1.3.4 不停机主从切换(手动切换)
Redis的主从模式中的主与从没有什么区别,唯一的区别就是在这个模式下从服务器是不允许被写入数据的,看下图:
我在从服务器上做一个SET操作,提示如下:

其实主从切换就是把从变成主,主变成从。基本步骤如下:
设置从服务器可写:
修改配置文件,如下图:
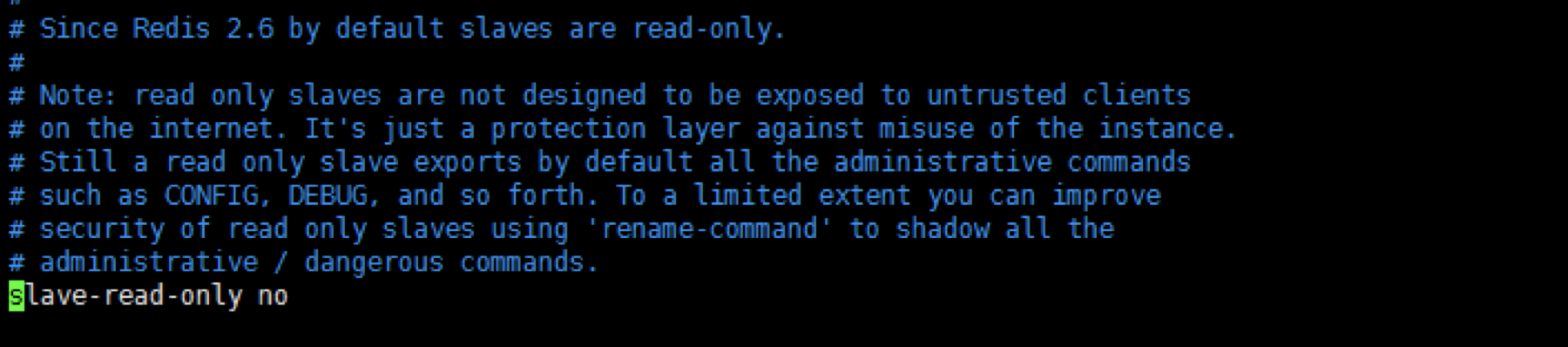
修改完成后,重启从服务器。
修改和重启从服务器后,从服务器依然可以从主服务器去同步数据,这一点不用担心。
把应用访问的IP更换成从服务器的IP:
这一步忽略,实际上就是业务对数据库访问IP的变更。
把从服务器设置为主服务器:
在从上执行这个命令

上面这个命令是将从服务器关闭复制功能,实际上就是不从任何地方复制,将从服务器作为独立的主服务器运行。这个很好理解,就是它不去同步其他的数据库服务器了,自己单独运行,那么自然就是主服务器。
上面的命令还有其他用法就是动态切换主服务器,比如如果我们要临时让从服务器去其他主服务器去同步数据,可以这样运行,如下图:
slaveof 主服务器IP 主服务器PORT
注意:假如当前服务器已经是A服务器的从服务器,而你又使用该命令让当前服务器成为B服务器的从服务器,也就是从B同步数据,那么当前服务器将丢弃之前同步的就数据,开始对新的主服务器进行同步。这个命令只是临时生效,临时覆盖配置文件中的slaveof设置,重启后恢复。
验证一下复制是否停止:
在原来的主服务器上运行info命令,如下显示:
虽然角色是主,但是SLAVE的连接已经没有了
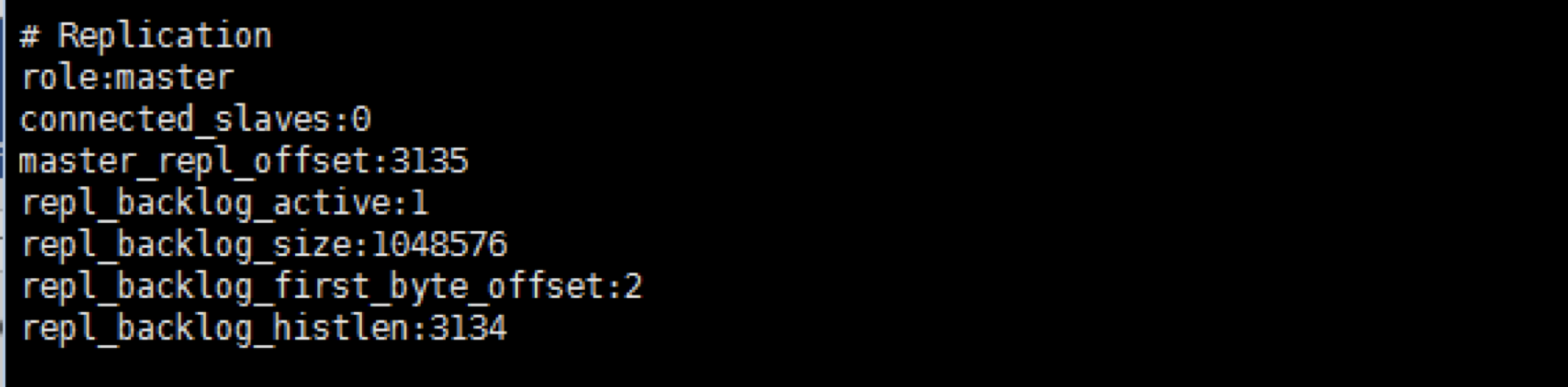
我们做一个SET操作,然后在原来的从服务器(Redis02)上执行一下GET操作,看看是否还可以获取数值:


可以看到无法获取。
在Redis02上执行info命令看看结果:
显示它自己已经变成主了。
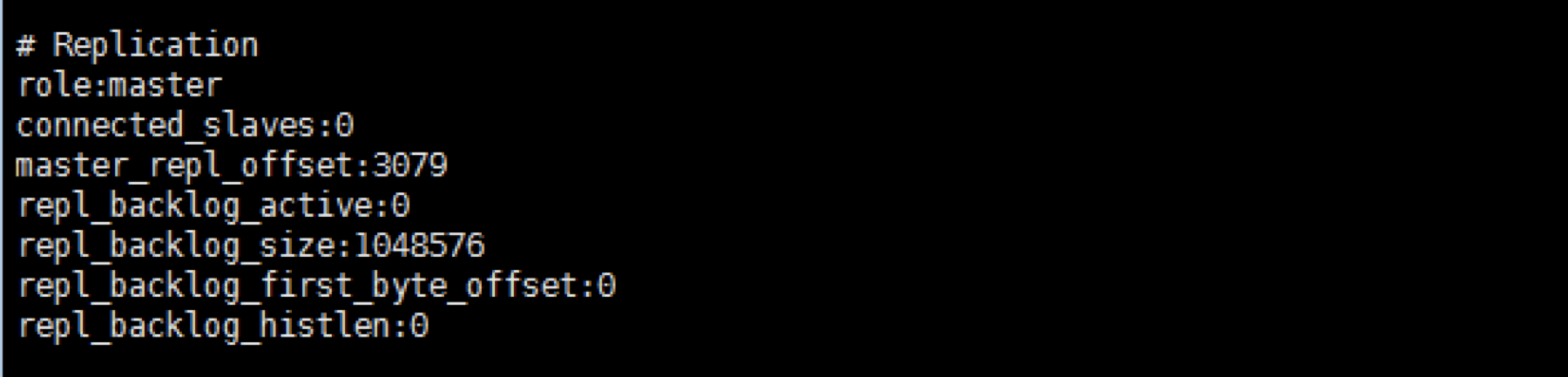
通过上述的操作我们就可以替换原来的主服务器或者在主服务器失败的时候可以手动切换。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号