学会使用Kafka(六)无消息丢失配置
无消息丢失配置
我们有时候听到开发说消息丢了。遇到这种情况你要想找这个消息通常是去生产者的日志里去看是否发送了这条消息以及去Kafka日志里去找是否有这条消息,不过这都是事后措施,通常来说我们如果要求不丢失消息,那么我们要怎么做呢?
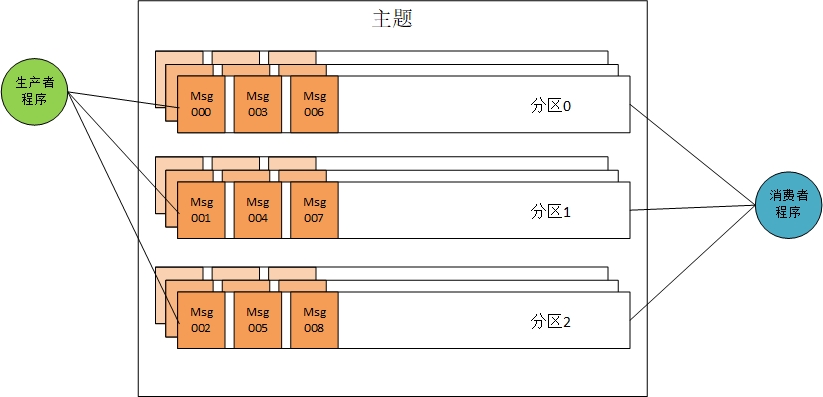
但是从上图可以看出来这里面涉及三方,生产者、broker和消费者。对于每一方的消息不丢失其实定义不同。
生产者:必须要成功发送到Kafka且得到正确的响应,如果生产者发送后就不管了那么显然在这一层就有丢失消息的风险。
broker:收到消息且写入日志文件,且日志有多个副本,并且副本都已经同步,在这种情况下就算某个broker宕机该消息也依然存在。所以Kafka承诺对已提交的消息不丢失,所谓已提交就是成功写入日志文件。
消费者:收到消息并且正确且完整的执行了该消息对应的业务逻辑,如果收到消息在执行业务逻辑的时候线程崩溃那么这条消息可以视为没有收到,线程重启后还必须能都读取到那个没有执行完业务逻辑的消息。
通过上面三方分析,如果我们要做这样的保证那么就要从三个方面来做且缺一不可。
生产者
这里说的是生产者在代码中设置的属性。
-
使用回调,默认消息都是异步发送,也就是在函数中调用了发送其实是发送到了缓冲器,如果因为网络抖动就会导致消息其实没有发送成功,所以这时候我们要采取回调机制,也就是在发送的时候注册回调函数来对没有发送成功的情况做响应处理。
-
设置生产者属性acks=all或者-1,acks代表了对已提交的定义,all表示该主题分区的所有副本都收到这个消息才算已提交,也就说主线程发送消息到缓冲区,异步线程去发送消息的时候要求所有ISR中的副本都同步了该消息后,该异步线程才会返回,该消息才算被提交。
-
设置重试次数retries,也就是说发送失败后可以重试发送几次
-
防止消息错乱,max_in_flight_requests_per_connection=1,在发送多条消息的时候防止第一条发送失败但是第二条发送成功,然后第一条重试发送,导致第二条在第一条之前。该值默认为0。如果设置了上面的retries但是没有设置max_in_flight_requests_per_connection=1那么将会有消息错乱的风险。
下面是Python生产者的属性配置:
PRODUCER_CONFIG = {
'bootstrap_servers': ['172.16.42.156:9092'],
'client_id': 'client01',
'acks': 'all',
'retries': 100,
'max_in_flight_requests_per_connection': 1,
'key_serializer': lambda m: json.dumps(m).encode('utf-8'),
'value_serializer': lambda m: json.dumps(m).encode('utf-8')
}
producer = KafkaProducer(**PRODUCER_CONFIG)
Broker参数
-
unclean.leader.election.enable=false,禁止非ISR列表中的broker参与Leader竞选,因为不是在ISR中的broker的数据是落后的,允许它们竞选Leader必然会导致消息之前在Kafka中,选举完消息就消失了。
-
replication.factor=3,设置副本数量大于等于3,因为多副本才能保证冗余
-
min.insync.replicas=2,其实不一定等于2,但至少要大于1并且小于replication.factor,这个参数的含义就是要求ISR中至少有几个副本,因为它和生产者的acks相关,只有acks=all,这个参数才有意义,所以这个参数的含义应该是生产者发送消息时至少要求ISR中有几个副本
这里可能有疑问,既然acks=all,那就是所有ISR副本,为啥还非要设置一个最小值呢?因为ISR是变化的,会出现进出的情况,如果你有3个副本,正常情况ISR里面是3个副本,但随着时间推移网络质量变化ISR里面的副本数量会变化,当变成1的时候,那么意味着只有leader副本存在,这时候你的acks=all,其实就等效acks=1,这时候写入消息后如果leader副本所在主机突然断电,但是另外2台broker还在,只是由于之前网络抖动导致副本落后被移除了ISR,那么现在由于leader不在了,就需要重新选举,显然肯定会选出一个,但是这个新的leader一定不包含之前写入的消息,这就会造成消息丢失。所以设置min.insync.replicas的含义就是写入消息时要求ISR中至少有几个副本存在,如果小于这个值那么就会写入失败,因为写入失败总比写进去然后丢了强。
但不过这其实也是一个可用性和一致性的权衡问题。比如3个broker ,1个主题单分区3副本,副本平均分布,ISR中有3个副本, min.insync.replicas=2 生产者配置ack=all, 如果2个broker宕机, 生产者就不能写入因为不满足min.insync.replicas=2,但是消费者可以消费。所以你说集群到底是可用还是不可用呢?只能说功能不全。如果你要要求3台主机宕机2台都可以继续读写,那么就设置min.insync.replicas=1,可用性是保证了,但是一致性就丧失了,因为会丢消息。
消费者
对于消费者比较简单就是关闭自动提交功能。如果该功能开启,那么消费者读取消息后,该消息就被自动提交也就是表示该消费者消费了该消息,那么在消费者执行业务逻辑时挂了,那么重启后它需要重新消费,但是由于自动提交导致它会从下一条进行消费,结果就是上一条消息虽然读取到了但是其对应的业务逻辑没有执行完。这种情况对消费者来说就是丢消息。
所以要关闭自动提交功能,该用手动提交。这个也是在消费者程序属性中设置,下面是Python客户端的例子:
self._kwargs = {
"bootstrap_servers": KafkaServerList,
"client_id": ClientId,
"group_id": GroupID,
"enable_auto_commit": False,
"auto_offset_reset": "latest",
"key_deserializer": lambda m: json.loads(m.decode('utf-8')),
"value_deserializer": lambda m: json.loads(m.decode('utf-8')),
}
try:
self._consumer = KafkaConsumer(**self._kwargs)
self._consumer.subscribe(topics=(Topics))
except Exception as err:
print("Consumer init failed, %s" % err)
# 业务逻辑
# .....
# 手动提交
self._consumer.commit()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号