学会使用Kafka(四)日志
日志
这里所说的日志是用来记录生产者向主题发送消息而产生的日志,但日志中记录的并不是消息而是record,因为Kafka并不是将原始消息直接写入日志的,而是把消息和其他元数据封装在一个record里写入日志,我们把这个record叫做消息集合。
这些日志信息放在配置文件的log.dirs指定的目录中
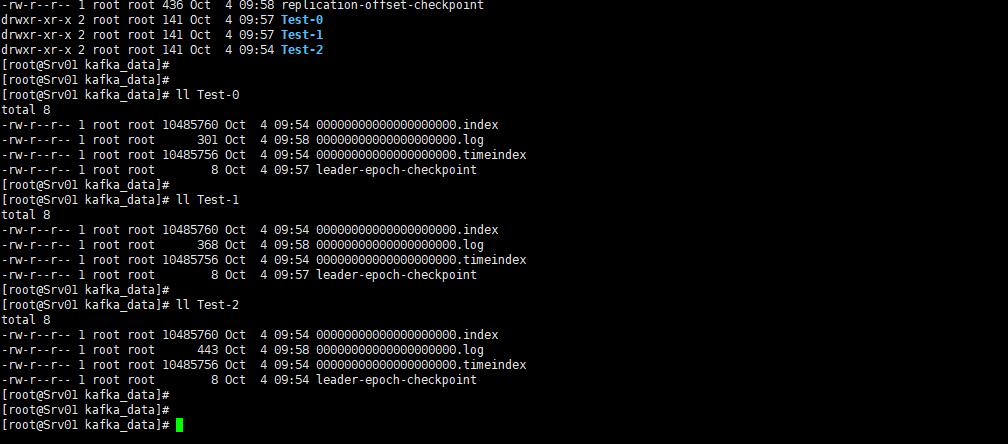
我们可以看到日志是按主题的分区来创建目录的(Test-0、Test-1、Test-2),每个目录里都有相同的文件类型,这里说类型而不是文件名。
日志文件
.log 是具体的日志文件,而日志文件时分段的,起始都是从0开始,在满足条件的时候进行截断。日志文件名称就是该日志段文件中保存的第一条日志的位移数值。
索引文件
.index:是位移索引文件,是用来帮助Kafka来快速定位记录在哪个物理文件
.timeindex:是时间索引文件,是用来帮助Kafka通过时间戳来查找对应记录的位移信息。
它俩都属于稀疏索引,也就是说它们不会保存每一条记录的的索引而且一个范围或者说是N个记录的索引区间,如下图:
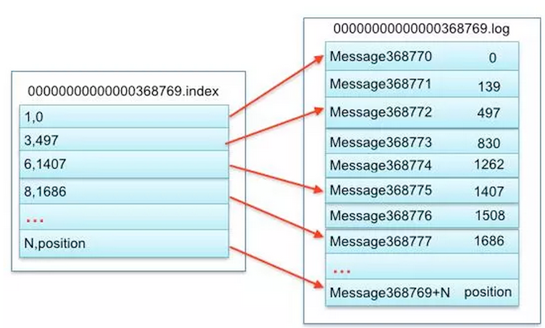
无论是位移索引文件还是时间戳索引文件都是这种形式,通过这种形式可以进行二分查找从而提高定位记录的速度。
索引文件有两种打开模式:只读和读写,除了当前日志的索引文件外其他的也就是以前的索引文件都是只读的。而且索引文件和日志文件是对应的,日志文件进行切割的时候索引文件也要进行切割,索引文件切割的时候要进行文件裁剪,因为新的索引文件大小预先分配为10M(读写模式的文件),而进行切割的时候要进行裁剪来还原为真实大小,所以只有当前读写模式的索引文件是10M,只读默认的历史索引文件大小都是真实大小。
用下面的命令就可以打开日志或者索引文件
kafka-run-class.sh kafka.tools.DumpLogSegments --files ./Test-0/00000000000000000000.index
我这里使用线上Kafka来查看一下,索引文件和日志文件的关系。
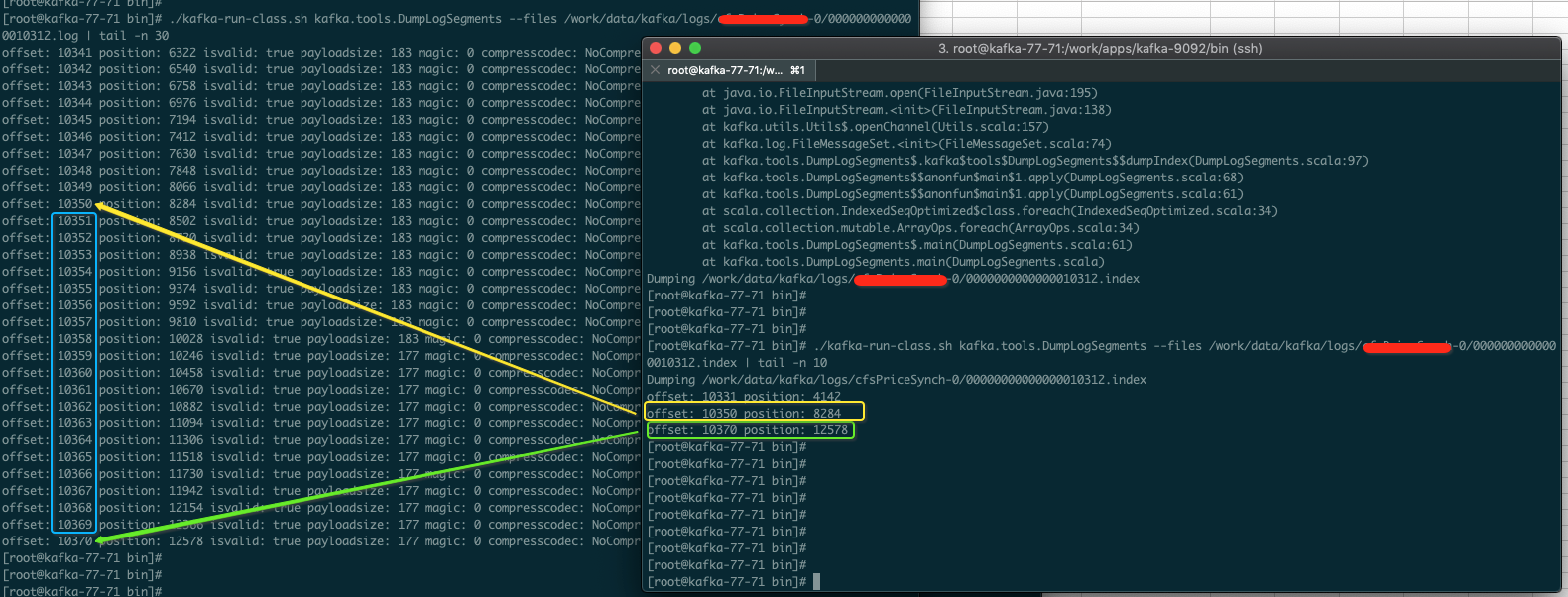
从上图可以很明显的看出它是怎么记录的,左侧是日志文件,右侧是索引文件。
索引文件中保存数据格式如下:相对位移|物理文件位置
上图黄色部分的索引文件offset也就是相对偏移是10350,物理文件位置是8284,顺着黄色箭头就可以看到日志文件中的位置。
如果要想找offset为10365的记录,那么通过索引文件找到小于10365的最大索引项就是 offset: 10350 position: 8284,然后就从日志文件中的position的8284开始进行顺序查找,直到找到10365的记录。
对于时间索引文件来说就是保存的是时间戳与位移的关系,通过给定的时间戳来查找不大于该时间戳的最大位移,然后Kafka拿着位移去日志文件中查找。
leader-epoch-checkpoint是leader-epoch的检查点文件,该文件与Leader epoch有关。
日志保留策略
Kafka会定期清理日志,清理的单位是日志段。它有2种策略:
-
基于时间:默认会清除7天之前的日字段包括索引文件。方法是比较当前时间戳和该日志段第一条消息的时间戳的差值。
-
基于大小:默认不会对大小进行限制
日志清理是一个异步过程,日志清理策略对当前使用的日字段不生效,Kafka不会清理当前使用的日志段。
日志compaction
这个需要说明,它不是日志压缩,而是基于消息key的去重,而且这种去重只是保留位移最大的一个。也就是说这种机制必须启用消息的key,没有key的消息无法进行去重。
怎么理解呢?比如用户邮箱的修改,用户的ID是位移的,邮箱可以修改多次,比如该用户短时间内反复修改了邮箱,那么就会产生多条消息,其实真正有用的就是最后一次修改中的邮箱地址,前面的都没用,所以就可以启用这个功能,当出现KEY重复的消息时采用什么策略,这种机制在Kafka的__consumer_offsets这个保存消费者消费偏移量的主题中就用到了。
日志相关参数
# 设置单个日志段文件大小,超过就会进行日志截断
log.segment.bytes=536870912
# 设置索引区间,也就是记录多少消息后记录一条索引项,默认4KB
log.index.interval.bytes=4096
# 索引文件最大大小,默认10M
log.index.size.max.bytes=10 * 1024 * 1024
# log.retention的检查周期,检查当前日志段是否达到log.segment.bytes设置大小
log.retention.check.interval.ms=60000
# 日志清理时间间隔,默认是7天
log.retention.hours=168
# 日志段大小限制,-1表示没有限制
log.retention.bytes=-1
# 是否启用日志清理,如果设置了false则日志的compaction不生效
log.cleaner.enable=true
# 日志清理策略,如果是compact则表示启用日志基于KEY的去重
log.cleanup.policy=delete,compact
# log文件"sync"到磁盘之前累积的消息条数,因为磁盘IO操作是一个慢操作,但又是一个"数据可靠性"的必要手段
# 所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.
# 如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞),消息多了自然时间长
# 如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.消息少所以同步频率就搞了。
# 物理server故障,将会导致没有fsync的消息丢失.
log.flush.interval.messages=100000
# 检查是否需要固化到硬盘的时间间隔
log.flush.scheduler.interval.ms =3000
# 仅仅通过interval来控制消息的磁盘写入时机,是不足的.
# 此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔
# 达到阀值,也将触发.
log.flush.interval.ms = None

 浙公网安备 33010602011771号
浙公网安备 33010602011771号