学会使用Kafka(二)Kafka集群搭建
Kafka集群部署
容量规划
操作系统的选择
操作系统来说优先选择Linux因为它支持的IO模型并支持零拷贝技术,而且主要是因为Kafka社区对Linux上的更新比较迅速,所以生产环境建议使用Linux系统。
磁盘的选择和磁盘容量
磁盘的话机械硬盘和SSD均可,因为kafka是顺序读写的。至于是否需要RAID,因为Kafka本身的副本机制就具有冗余性所以如果要使用RAID那就使用RAID0,这样可以提高磁盘的IOPS。
总容量=(平均消息大小KB * 平均每天消息条数 * 副本数量 * 保存天数) \ 1000000 * 压缩比
内存容量
无论是Kafka还是Elasticsearch还是Redis,在读写的时候的都会使用内存,数据先进入内存,刷盘操作可以等待OS自己来完成也可以设置一个刷盘频率,不过频率越高意味着磁盘IO开销越大。
其实就算不谈上面的这些开源组件,我们自己创建一个文件在磁盘上,然后写入一些数据,当我们使用比如cat命令读取的时候其实是从内存返回的而不是硬盘,这就是为什么我们关机的时候要使用sync命令同步一下内存数据到磁盘的原因,因为如果没有同步那么这些未落盘的数据在机器重启或者意外重启后就会丢失,这是操作系统的延迟写入机制。
针对于kafka来说JVM堆内存没有必要设置非常大反而是文件缓存使用的比较多,所以kafka主机的内存应该给与大一些,至少要比单个日志段文件要大,JVM堆内存给6G也就可以了,另外还要给操作系统预留一写内存。
我们上面说的内存主要是page cache,其实就是你通过free命令看到的buffer/cahce中的cache这一项,在Linux中没有一个明确的指标来限制cache的大小,因为cache本身用的就是物理内存。
另外就是禁用swap机制。
服务器的数量
服务器数量,你需要设定一个SLA也就是多长时间处理多少消息,这样来规划。一般机器的带宽是千兆网卡,而且也不能把带宽占满,通常我们按照50%来计算,千兆网卡的50%也就是500Mb。如果1小时需要处理100G的数据量,那么一秒就要处理237Mbps,总处理量(Byte) * 1024 * 8 \ 3600(秒) ,按照这样的计算1台就可以了,但是考虑到副本数量如果为3,那么就需要3台的集群。
集群部署
从Kafka官网下载,我们选择该版本,kafka_2.11-2.3.0.tgz,其中2.11是Scala的版本,后面的2.3.0是Kafka的版本。
部署环境如下:
| 服务器名称 | 角色 | IP地址 |
|---|---|---|
| Srv01 | Zookeeper,Kafka | 172.16.100.10 |
| Srv02 | Kafka | 172.16.100.20 |
| Srv03 | Kafka | 172.16.100.30 |
由于Kafka是Scala语言开发,运行在JVM上,所以所有主机需要安装JDK,如果是二进制包安装请配置好环境变量。
解压缩二进制文件到目标目录,我这里就放到/work目录下(在所有主机都做同样操作)
tar xzf kafka_2.11-2.3.0.tgz -C /work

编辑配置文件
这里还有一个zookeeper.properties配置文件,该文件是如果你使用kafka自带zookeeper那么你就需要配置它。如果你有另外的zookeeper集群那就忽略就好了。
下面是运行一个Kafka集群最少的配置:
# kafka服务器监听IP和端口,这里也可以写域名,只要能解析就行
listeners=PLAINTEXT://172.16.100.10:9092
# 三台服务器的ID不能相同,第一台是0,第二台是1,第三台是2
broker.id=0
# 数据存储路径
log.dirs=/work/kafka-data
# Zookeeper连接参数
zookeeper.connect=172.16.100.10:2181/kafka
# 另外我还配置了
message.max.bytes=5000000
default.replication.factor=3
上面的log.dirs并不是Kafka工作产生的日志,这个日志路径在一个脚本文件中定义,kafka目录的bin下的kafka-run-class.sh文件中定义
base_dir=$(dirname $0)/..
....
# Log directory to use
if [ "x$LOG_DIR" = "x" ]; then
LOG_DIR="$base_dir/logs"
fi
修改好配置,这里要注意broker.id和listeners字段要修改为对应的。然后启动Kafka集群,进入kafka的bin目录,运行下面的命令,它有2种方式:
# 第一种方式(推荐)
kafka-server-start.sh -daemon ../config/server.properties
# 第二种方式
nohup kafka-server-start.sh config/server.properties&
# 停止
kafka-server-stop.sh
最好设置一下kafka命令的环境变量,否则使用相关命令就要使用全路径,在/etc/profile.d目录下建立一个kafka.sh的文件,文件名随便。
#!/bin/bash
KAFKA_HOME=/work/kafka_2.11-2.3.0
export PATH=$KAFKA_HOME/bin:$PATH
然后应用一下source /etc/profile.d/kafka.sh
依次在三台主机执行启动集群命令

下面是产生的日志
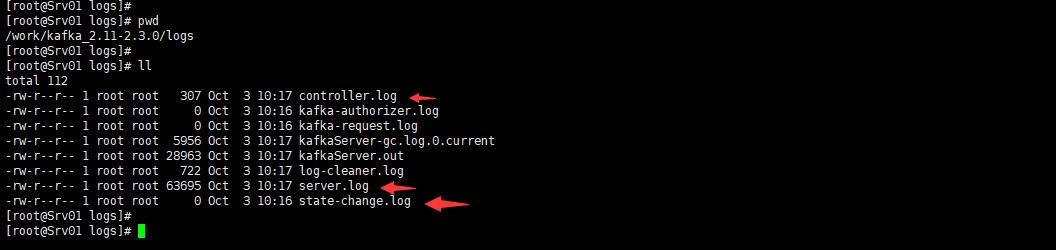
server.log 是kafka系统日志,这个比较常用
state-change.log 是leader切换日志,是broker宕机副本切换
controller.log kafka集群中有一台机器是控制器,那么控制器角色的日志就记录在这里
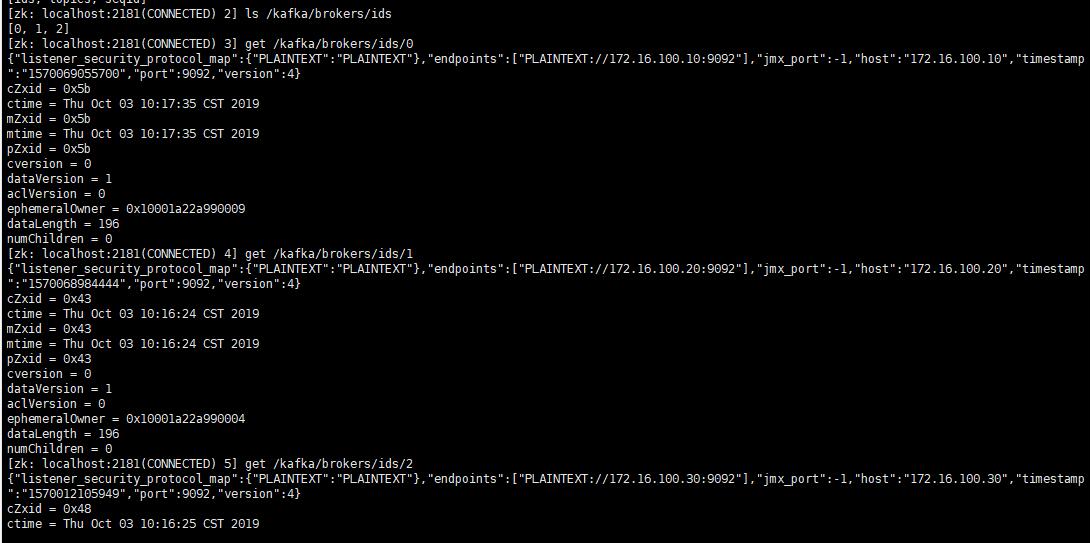
下面在Zookeeper中看一下Broker的注册信息
主题操作命令
创建一个主题,该主题有3个副本,1个分区
kafka-topics.sh --create --zookeeper 172.16.100.10:2181/kafka --replication-factor 3 --partitions 1 --topic Test
删除主题
kafka-topics.sh --delete --zookeeper 172.16.100.10:2181/kafka --topic Test
查看所有主题
kafka-topics.sh --list --zookeeper 172.16.100.10:2181/kafka
查看特定主题的详细信息
kafka-topics.sh --describe --zookeeper 172.16.100.10:2181/kafka --topic Test

PartitionCount:显示分区数量一共有多少
ReplicationFactor:副本数量
Partition:分区编号
Leader:该分区的Leader副本在哪个broker上,这里显示的是broker的ID
Replicas:显示该partitions所有副本存储在哪些节点上 broker.id 这个是配置文件中设置的,它包括leader和follower节点
Isr:显示副本都已经同步的节点集合,这个集合的所有节点都是存活的,并且跟Leader节点同步
通过生产和消费者命令进行测试
生产者
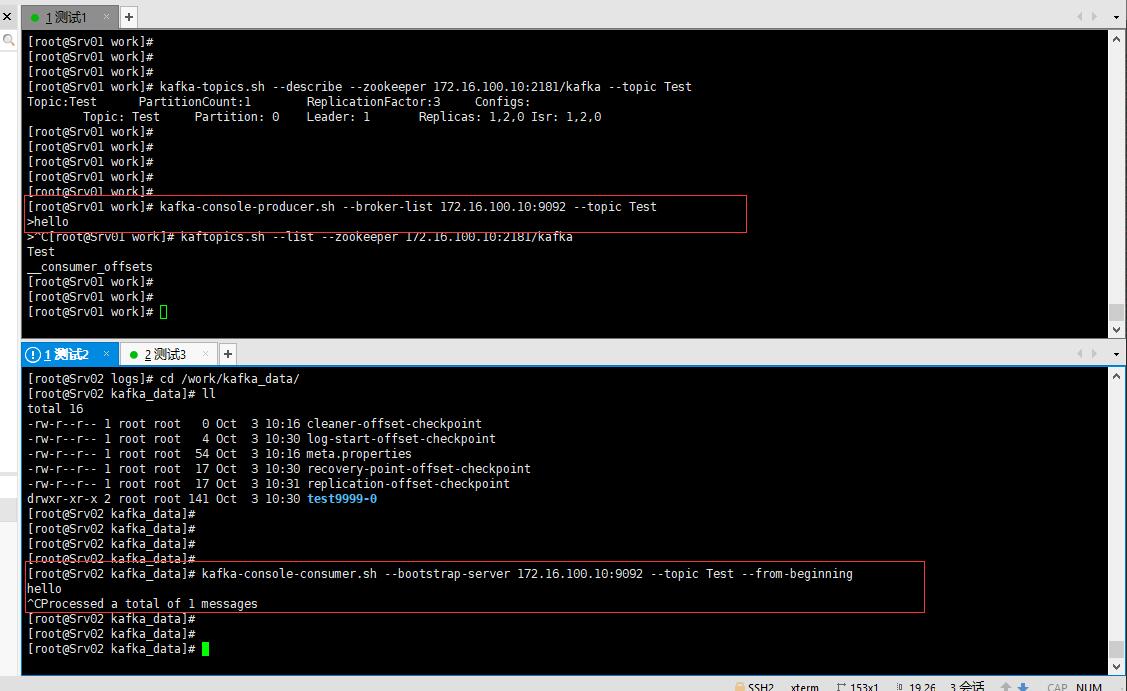
kafka-console-producer.sh --broker-list 172.16.100.10:9092 --topic Test
消费者
kafka-console-consumer.sh --bootstrap-server 172.16.100.10:9092 --topic Test --from-beginning
启动生产者后会出现“>”提示符,启动完消费者后,在生产者的提示符下输入文字那么消费者就会收到,如下图:
JVM参数
建议将JVM的堆大小设置为6GB
关于GC,如果是JAVA 7:
-
如果CPU资源充裕建议使用CMS,-XX:+UseCurrentMarkSweepGC
-
如果不充裕则使用吞吐量收集器,-XX:+UseParallelGC
如果是JAVA 8就使用默认的G1收集器
综合上述,启动Kafka前设置如下环境变量参数
export KAFKA_HEAP_OPTS=--Xms6g --Xmx6g
export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
上面的这些JVM设置都可以通过在kafka-server-start.sh脚本中完成
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx6G -Xms6G"
export KAFKA_JVM_PERFORMANCE_OPTS= -server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true
export JMX_PORT="9999"
fi
当然上面的JVM设置你可以通过直接修改kafka-run-class.sh脚本来完成,如下所示:
# Memory options
if [ -z "$KAFKA_HEAP_OPTS" ]; then
KAFKA_HEAP_OPTS="-Xmx256M"
fi
# JVM performance options
if [ -z "$KAFKA_JVM_PERFORMANCE_OPTS" ]; then
KAFKA_JVM_PERFORMANCE_OPTS="-server -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35 -XX:+ExplicitGCInvokesConcurrent -Djava.awt.headless=true"
fi
Kafka的JMX设置
打开JMX端口方法1:
在kafka程序的bin目录下的kafka-server-start.sh启动脚本程序
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
export JMX_PORT="9999" # 默认没有这一句,增加上
fi
打开JMX端口方法2:
或者直接在启动命令中增加export JMX_PORT=9988 kafka-server-start.sh -daemon ../config/server.properties
无论上面是什么方式,其实最终是由bin目录中的kafka-run-class.sh脚本来使用的,下面是该脚本的JMX设置
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false "
fi
# JMX port to use
if [ $JMX_PORT ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT "
fi
通过上面设置好之后使用hostname -i检查一下输出内容是否包含你要连接的IP地址,如果没有则修改/etc/hosts文件进行添加
如果发现依然连接不上但是telnet这个JMX端口可以连接,那么你就要修改上面的kafka-run-class.sh脚本中的内容
# JMX settings
if [ -z "$KAFKA_JMX_OPTS" ]; then
KAFKA_JMX_OPTS="-Dcom.sun.management.jmxremote -Dcom.sun.management.jmxremote.authenticate=false -Dcom.sun.management.jmxremote.ssl=false -Djava.rmi.server.hostname=[IP_ADDRESS]"
fi
# JMX port to use
if [ $JMX_PORT ]; then
KAFKA_JMX_OPTS="$KAFKA_JMX_OPTS -Dcom.sun.management.jmxremote.port=$JMX_PORT "
fi
增加-Djava.rmi.server.hostname=有些时候无法自动绑定尤其是多IP的时候,所以我们就需要手动绑定,如果hostname -i只有一个IP且就是需要被远程访问的IP,而且你的localhost可以解析到这个IP,那么不需要这个参数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号