集合-Conllection
一.集合的分类
Conllection 定义在java.util包中:
-
List:一种有序列表的集合,允许重复,
- ArrayList 是动态数组实现的非线程安全的集合
- LinkedList 基于链表实现的非线程安全的集合
-
Set:一种保证没有重复元素的集合,
- HashSet 是无序的,实现了Set接口,但是没有实现SortedSet接口 (JDK1.8版本之前: 哈希表 = 数组+链表,JDK1.8版本之后: 哈希表 = 数组+链表+红黑树)
- TreeSet是有序的,实现了SortedSet接口,添加的元素必须正确实现Comparable接口。
-
Map: 一种通过键值(key-value) 查找的映射表集合.
Map 中key是不能重复的,vaule是可以重复的,
Map是无序的,遍历的时候不能保证其顺序 ,
Map中不存在重复的key,因为放入相同的key,只会把原有的key-value对应的value给替换掉- HashMap 的使用 : 作为key必须覆写equals() 和hashCode()方法 ,
a: 如果equals()返回true,则hashCode()返回值必须相等
b: 如果equals()返回false,则hashcode()返回值尽量不要相等 - EnumMap 内部以一个非常紧凑的数组存储value,并且根据enum类型的key直接定位到内部数组的索引,并不需要计算hashCode(),不但效率最高,而且没有额外的空间浪费。
- SortedMap 保证遍历时以key的顺序来进行排序, 它的实现类是:TreeMap, TreeMap 放入的Key必须实现Comparable接口
- HashMap 的使用 : 作为key必须覆写equals() 和hashCode()方法 ,
-
Queue: 实现了先进先出的有序表
- Deque: 允许两头都进,两头都出,这种队列叫双端队列(Double Ended Queue)
-
Stack: 栈(Stack)是一种先进后出的数据结构
java.util.Concurrent包下⾯的常见类:
-
ConcorrenctHashMap 分段锁
先说HashMap,HashMap是线程不安全的,在并发环境下,可能会形成环状链表(扩容时可能造成),导致get操作时,cpu空转,所以,在并发环境中使⽤HashMap是⾮常危险的。
HashTable : HashTable和HashMap的实现原理⼏乎⼀样,差别⽆⾮是1.HashTable不允许key和value为null;2.HashTable是线程安全的。但是HashTable线程安全的策略实现代价却太⼤了,简单粗暴,get/put所有相关操作都是synchronized的⾸先将数据分成⼀段⼀段的存储,然后给每⼀段数据配⼀把锁,当⼀个线程占⽤锁访问其中⼀个段数据的时候,其他段的数据也能被其他线程访问 ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成,Segment是⼀种可重⼊锁ReentrantLock, get操作不需要锁。 除⾮读到的值是空的才会加锁重读,我们知道HashTable容器的get⽅法是需要加锁的,那么ConcurrentHashMap的get操作是如何做到不加锁的呢?原因是它的get⽅法⾥将要使⽤的共享变量都定义成volatile 1.Put⽅法 1.定位segment并确保定位的Segment已初始化 2.调⽤Segment的put⽅法。 2.Get⽅法⽆需加锁,由于其中涉及到的共享变量都使⽤volatile修饰,volatile可以保证内存可见性,所以不会读取到过期数据。 3.Romove 操作⼀样,⾸先根据散列码找到具体的链表;然后遍历这个链表找到要删除的节点;最后把待删除节点之后的所有节点原样保留 每⼀个 Segment 对象都有⼀个 count 对象来表⽰本 Segment 中包含的 HashEntry 对象的总数。 注意,之所以在每个 Segment 对象中 ,包含⼀个计数器,⽽不是在 ConcurrentHashMap 中使⽤全局的计数器,是为了避免出现“热点域”⽽影响 ConcurrentHashMap 的并 发性。 ConcurrentHashMap 在默认并发级别会创建包含 16 个 Segment 对象的数组, 在 ConcurrentHashMap 中,不允许⽤ null 作为键和值 在新链表中,把待删除节点之前的每个节点克隆到新链表中。 写线程对某个链表的结构性修改不会影响其他的并发读线程对这个链表的遍历访问。 ConcurrentHashMap 的⾼并发性主要来⾃于三个⽅⾯: 1.⽤分离锁实现多个线程间的更深层次的共享访问。 2.⽤ HashEntery 对象的不变性来降低执⾏读操作的线程在遍历链表期间对加锁的需求。 3.通过对同⼀个 Volatile 变量的写 / 读访问,协调不同线程间读 / 写操作的内存可见性。 -
BlockingQueue 阻塞队列
抛出异常 特殊值 阻塞 超时 插入 add(e) offer(e) put(e) offer(e,time,unit) 移除 remove() poll() take() poll(time,unit) 检查 element() peek() 不可用 不可用 1)add(anObject):把anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则招聘异常
2)offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳,则返回true,否则返回false.
3)put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
4)poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间,取不到时返回null
5)take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到Blocking有新的对象被加入为止
注意点:
【1】BlockingQueue 可以是限定容量的。它在任意给定时间都可以有一个remainingCapacity,超出此容量,便无法无阻塞地put 附加元素。没有任何内部容量约束的BlockingQueue 总是报告Integer.MAX_VALUE 的剩余容量。
【2】BlockingQueue 实现主要用于生产者-使用者队列,但它另外还支持Collection 接口。因此,举例来说,使用remove(x) 从队列中移除任意一个元素是有可能的。然而,这种操作通常不 会有效执行,只能有计划地偶尔使用,比如在取消排队信息时。
【3】BlockingQueue 实现是线程安全的。所有排队方法都可以使用内部锁或其他形式的并发控制来自动达到它们的目的。然而,大量的 Collection 操作(addAll、containsAll、retainAll 和removeAll)没有 必要自动执行,除非在实现中特别说明。因此,举例来说,在只添加了c 中的一些元素后,addAll(c) 有可能失败(抛出一个异常)。
【4】BlockingQueue 实质上不支持使用任何一种“close”或“shutdown”操作来指示不再添加任何项。这种功能的需求和使用有依赖于实现的倾向。例如,一种常用的策略是:对于生产者,插入特殊的end-of-stream 或poison 对象,并根据使用者获取这些对象的时间来对它们进行解释。
BlockingQueue常用的四个实现类:
1)ArrayBlockingQueue:规定大小的BlockingQueue,其构造函数必须带一个int参数来指明其大小.其所含的对象是以FIFO(先入先出)顺序排序的.
2)LinkedBlockingQueue:大小不定的BlockingQueue,若其构造函数带一个规定大小的参数,生成的BlockingQueue有大小限制,若不带大小参数,所生成的BlockingQueue的大小由Integer.MAX_VALUE来决定.其所含的对象是以FIFO(先入先出)顺序排序的
3)PriorityBlockingQueue:类似于LinkedBlockQueue,但其所含对象的排序不是FIFO,而是依据对象的自然排序顺序或者是构造函数的Comparator决定的顺序.
4)SynchronousQueue:特殊的BlockingQueue,对其的操作必须是放和取交替完成的.
其中:BlockingQueue 不接受null 元素。试图add、put 或offer 一个null 元素时,某些实现会抛出NullPointerException。null 被用作指示poll 操作失败的警戒值。
二. HashMap
原文档: https://blog.csdn.net/qq_46329780/article/details/112545332
JDK8之前:数组、链表
JDK8之后:数组、链表、红黑树
重要字段 :
transient int size; //当前存储的键值对总数
int threshold; //阈值,默认为16
final float loadFactor; //负载因子
transient int modCount; //HashMap被改变的次数,比如使用迭代器进行迭代时,如果其他线程对当HashMap进行了修改,则会改变该字段值,即结构已经发生变化,那么迭代器就会抛出并发修改异常
扩容操作:
数组:初始容量为16(2^4),初始负载因子为0.75,即当存储元素个数超过threshold(当前容量)*0.75(负载因子)时会进行扩容,每次扩容后容量为之前得2倍。
链表:使用哈希函数计算存储位置后,如果数组中该位置已经被使用,那么就会在该位置处添加链表,链表的最大容量为8,如果超过8,就会转换为红黑树来存储。
红黑树:使用红黑树的查询效率高于普通链表,因为使用红黑树相当于二分查找,二分查找的效率要高于顺序查找,并且红黑树会自动保持平衡,从而进一步保证查询效率。当红黑树结点减少到6(不是8)时,会转换回链表。
map.put()操作
源码:
....
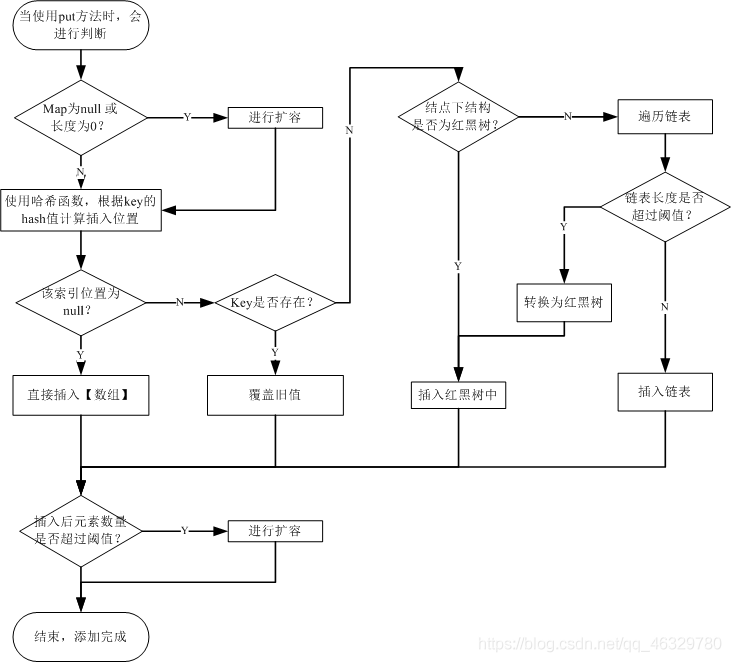
其他的几个问题:
1.为什么JDK8添加了红黑树提高性能? 红黑树查找事件复杂度为O(logn),链表为O(n);
2.为什么会有链表会达到阈值将结构修改为红黑树,而不是直接为红黑树? 红黑树结点基本上为链表结点大小的两倍,所以在存储元素较少时,不宜使用较多的存储空间。
3.为什么会在红黑树结点数量为6的时候转换回链表,而不是和链表转换为红黑树时一样为8? 避免在阈值附近增加删除元素而引起频繁的链表和红黑树的转换。
4.JDK8之前存在的多线程情况下的死循环问题?
JDK 1.7 扩容采用的是“头插法”,会导致同一索引位置的节点在扩容后顺序反掉。而 JDK 1.8 之后采用的是“尾插法”,扩容后节点顺序不会反掉,不存在死循环问题。
HashMap为什么导致CPU100% HashMap死循环分析原文链接: https://blog.csdn.net/hao134838/article/details/107220317/
5.JDK8对Map的优化:
- 底层数据结构从“数组+链表”改成“数组+链表+红黑树”;
- 计算 table (底层数组)初始容量的方式发生了改变;
- 优化了 hash 值的计算方式,新的计算方式是让高16位参与了运算;
- 扩容时插入方式从“头插法”改成“尾插法”,避免了并发下的死循环;
- 扩容时计算节点在新表的索引位置方式从“h & (length-1)”改成“hash & oldCap”。
Map集合的选择问题
| 类 | 介绍 | 使用 |
|---|---|---|
| HashTable | 早期线程安全的Map,使用synchronized修饰方法实现的。 | 基本不会使用 |
| ConcorrenctHashMap | 线程安全的Map,使用synchronized+CAS实现的。 | 需要保证线程安全时使用 |
| LinkedHashMap | 能记录访问顺序或插入顺序 | 需要记录顺序时使用 |
| TreeMap | 可是自定义排序规则进行存储 | 需要自定义排序规则时使用 |
| HashMap | 非线程安全、无序 | 没有特殊要求,一般使用 |
哈希碰撞及解决方案
所谓的哈希碰撞指的是不同的值,经过哈希之后得到的值确是相同的,这种情况就叫做哈希碰撞或哈希冲突。
解决哈希碰撞的常用方法是:开放定址法和链表地址法,而 HashMap 采用的就是链表地址法。它的实现原理就是将 HashMap 中相同的哈希值以链表的形式存储起来。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号