OOD 启思录 (Arthur J.Riel 著)
第1章 面向对象编程的动因(已看)
第2章 类和对象: 面向对象范型的建材 (已看)
第4章 类和对象的关系 (已看)
第5章 继承关系 (已看)
第7章 关联关系 (已看)
第8章 与特定类相关的数据行为 (已看)
第9章 面向对象物理设计 (已看)
第10章 经验原则和模式的关系 (已看)
第1章 面向对象编程的动因
1.1 革命家, 改革家与面向对象范型
1.2 Frederick Brooks 观点: 非根本复杂性与根本复杂性
软件危机的真正原因是根本复杂性,根本复杂性来自这一事实:软件本质上就是复杂的,没有哪种方法学或者工具可以消除这一复杂性。软件具有根本复杂性的理由如下:
- 从规模上来说,软件应用程序是人类创建的最复杂的实体
- 软件是难以把握的,而且大部分是无形的
- 软件不会像具有移动零件的机器那样会在传统意义上磨损折旧。但是,人们常常会以软件编写者从未想到的方式来使用软件(并常常发现错误),而且最终用户始终希望他们的软件得以扩展
1.3 瀑布模型

1.4 迭代模型
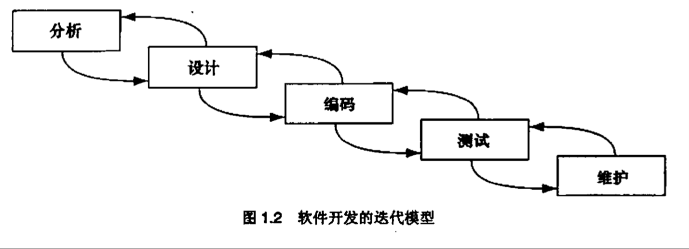
1.5 构造原型: 相同语言与不同语言
1.6 软件复用性
1.7 优秀设计者阶层
术语表
Accidental complexity 非根本复杂性,在应用程序中使用不合适的软件开发范型或者工具造成的复杂性
Different-language prototyping 不同语言原型化。一种创建原型的方式,用来创建原型的语言和项目语言不同
Essential complexity 根本复杂性,因为应用软件本身的性质造成的复杂性
Multiparadigm language 多范型语言,既支持面向对象范型又支持面向动作范型的编程语言
Paradigm shift 范型迁移,从旧的编程模型到新的编程模型的迁移
Programing paradigm 编程范型,开发软件的模型
Pure object-oriented language 纯面向对象语言。只支持面向对象范型的语言
Same-language prototyping 相同语言原型化。一种创建原型的方式,用来创建原型的语言和用来创建最终产品的语言是一样的
Software prototype 软件原型。应用软件的模型,用来测试软件设计,实现或者解决方案的可行性。常常为了可以快速完成而省略了可扩展性,效率和稳定性这些特性
Software prototyping 软件原型化,创建最终应用软件产品的模型的行为,用来测试或者证明特定软件的设计,实现或者解决方案的可行性
Iterative model(of software development)(软件开发的)迭代模型,一种设计软件的灵活性的模型,它意识到软件开发是一个迭代的过程,必须允许实践者可以修改已有得成果来改正前面犯下的错误
Waterfall model(of software development)(软件开发的)瀑布模型,一种设计软件的不灵活的模型。它注重的是产生精确定义的工件的里程碑,开发过程是单向的,也就是说,一旦到达一个里程碑,那么前面所做的步骤就不能改变了
第2章 类和对象: 面向对象范型的建材
2.1 类和对象导引
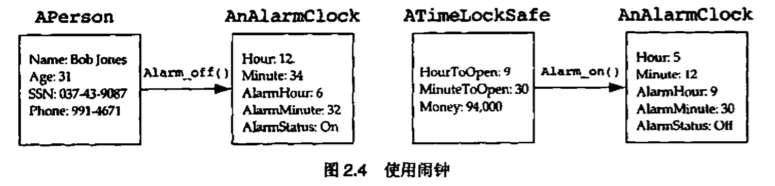
大多数人会使用闹钟, 但不会装配闹钟
在现实世界中, 有很多东西是我们会使用但不会制造的, 比如冰箱 汽车, 复印机, 计算机等等.
为什么我们可以不知道它们的实现却能轻松使用它们? 因为它们被设计为通过一个精确定义的公有界面(接口)来使用. 这个公有界面极大地依赖于内部的实现, 但又向用户隐藏了内部实现.这一策略还允许闹钟制造商把目前闹钟用到的60个小零件替换成进口的3个子部件, 而闹钟的使用者对此不会有意见
面向对象泛型的一个基本想法就是这样. 所有构成系统的实现细节都应该隐藏在精确定义并且一致的公有接口后面. 使用这些构造的用户需要知道这个公有接口, 但你不让他们看见实现细节
你知道闹钟的概念, 这一概念用一个简洁的组合表示了所有闹钟的数据和行为. 这种概念称为类(class). 而你拿在手上的闹钟实物叫做闹钟类的对象(object)或者实例(instance).类和对象之间的关系叫做实例化关系(instantiation relationship). 我们说, 闹钟对象是从闹钟类实例化(instantiate)而来, 闹钟类是你遇到的所有闹钟对象的泛化(generalization)(也有译为 归纳, 一般化的)
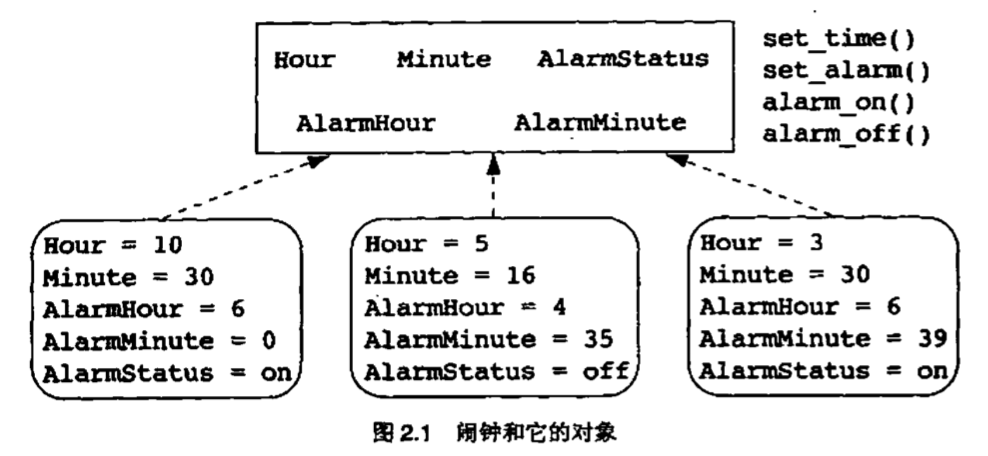
如果我告诉你, 我的闹钟从我的床头几上跳起来, 咬了我一口, 然后去追邻居的猫了, 你一定会认为我疯了. 但如果我告诉你, 我的狗做了这些事情, 你会觉得这挺合理的. 这是因为, 类的名字不仅意味着一组属性, 还表示实体的行为. 这种数据和行为的双向联系是面向对象泛型的基石之一
一个对象一定会有如下4个重要方面:
- 它自己的身份标识 (可能只是它在内存中的地址)
- 它的类的属性 (通常是静态的)和这些属性的值(通常是动态的)
- 它的类的行为 (从实现者的角度看)
- 它的类的公开接口 (从用户的角度看)
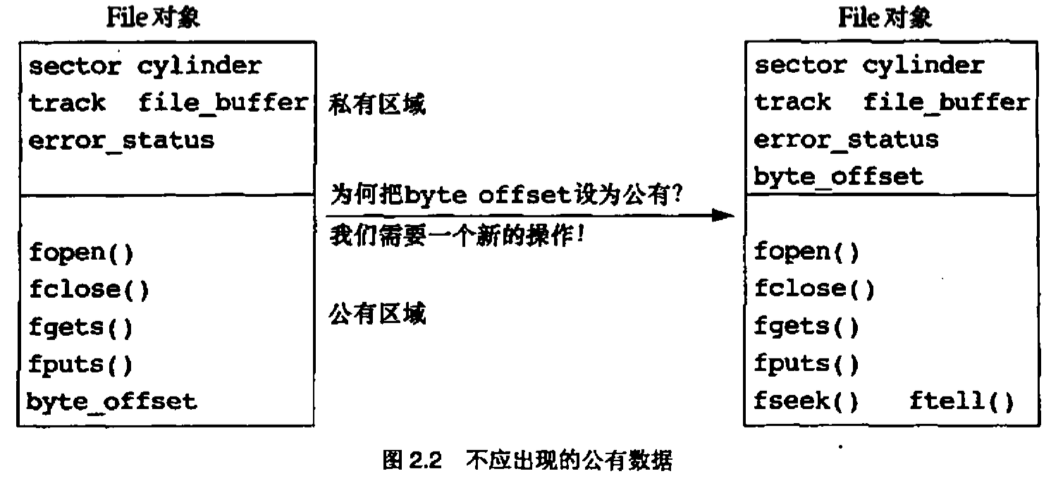
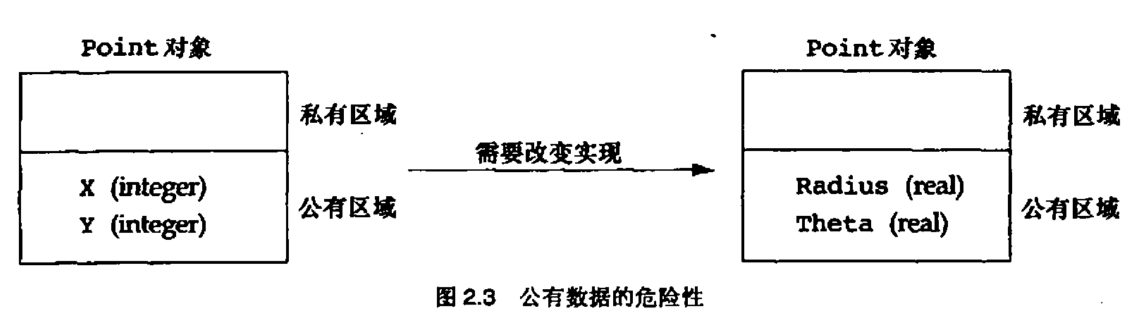
将这一讨论置于软件开发的语境, 类可以被实现为一个结构定义以及一组可以处理这个结构的操作. 在过程式语言中, 任给一个函数, 很容易找出数据依赖性. 只要检查函数实现并看一下所有参数, 返回值以及局部变量声明的数据类型就可以了. 但是, 如果你想要找出一个数据定义的函数依赖性, 那你就不得不检查全部代码, 寻找依赖于这个数据得函数. 而在面向对象模型中, 两种依赖性(函数对数据的依赖性和数据对函数的依赖性)都现成摆明在那里了. 对象是类数据类型的变量. 它们的内部细节只对同它们的类关联的那组函数可见. 这种对内部细节的访问限制称作信息隐藏(information hiding). 在很多面向对象语言中, 这种隐藏不是强制的, 这样我们就有了第一条(也是最重要的一条)经验原则
经验原则 2.1
所有数据都应该隐藏在它所在的类内部
违反这条经验原则意味着你不重视可维护性.面向对象泛型所带来的益处, 大部分归因于在设计阶段和实现阶段始终确保信息隐藏. 如果你把数据设定为公有, 那么就很难判断系统哪部分的功能依赖于这个数据. 事实上, 这样一来, 数据变动与函数的映射关系就和面向动作泛型一摸一样了. 我们不得不检查所有的函数以判断哪些函数依赖于公有数据
有时开发者会争辩说, "我需要把这个数据设为公有, 因为..."在这种情况下, 开发者应该问自己, "我到底要用这个数据来做什么?为什么不是类为我提供这个操作?"在所有这类情况下, 问题出在类缺少了一个必需的操作
2.2 消息和方法
对象应当被看作机器, 机器只为提出恰当请求的人执行公有接口所定义的操作. 因为对象独立于使用者, 也因为一些实现了面向对象概念的早期语言的语法, 术语”发送消息"用于描述执行对象的行为. 它必须判断是否理解该消息. 如果理解, 那么对象就把消息映射为一个函数调用, 并把自身作为隐含的第一个参数传递过去. 对解释语言而言, 判断是否理解一个消息是在运行时完成的, 而编译语言则是在编译时完成的
对象行为的名称(或者原型)被称作消息(message)
消息的实现, 也即实现消息的代码, 被称作方法(method)
对象所能响应的消息列表被称作对象的协议(protocol)
经验原则 2.2
类的使用者必须依赖类的公有接口, 但类不能依赖它的使用者
这条经验原则背后的基本原理是可复用性
经验原则 2.3
尽量减少类的协议中的消息
庞大的公有接口的问题是, 你永远都无法找到你想要找的东西. 这严重损害了接口的可复用性. 而如果让接口最小化, 我们就可以让系统易于理解, 并使组件易于复用
经验原则 2.4
实现所有类都理解的最基本公有接口[例如, 拷贝操作(深拷贝与浅拷贝), 相等性判断, 正确输出内容, 从ASCII描述解析等等]
经验原则 2.5
不要把实现细节(例如放置共有代码的私有函数)放到类的公有接口
这条经验原则用于为使用者降低类的接口的复杂性

经验原则 2.6
不要以用户无法使用或不感兴趣的东西扰乱类的公有接口
2.3 类耦合与内聚
类之间有5种形式的耦合关系
- 零耦合 (nil couple)是最佳的,因为这意味着两个类丝毫不依赖于对方。若只用到零耦合,我们最多只能创建类库
- 导出耦合 (export coupling)则表明,一个类依赖于另一个类的公有接口。也就是说,这个类用到另一个类的一个或多个公有操作
- 授权耦合 (overt coupling)则意味着一个类经允许使用另一个类的实现细节。C++的友元机制是授权耦合的典型例子。一个C++类X可以声明类Y是它的友元。这样,Y的方法就获得授权可以访问X的实现细节。
- 自行耦合( covert coupling)和授权耦合差不多,也就是类Y访问类X的实现细节,但区别在于类Y是未经授权的。如果我们发明一种语言机制,允许类Y声明自身是X的友元并且将使用X的实现细节,那么X和Y就是自行耦合
- 暗中耦合(surreptitious coupling)这种耦合是指类X通过某种方式知道了Y的实现细节。如果类X使用类Y的公有数据成员,那么X就和Y暗中耦合.暗中耦合是最危险的耦合形式,因为它在Y的行为和X的实现之间建立了很强的隐式依赖关系
经验原则 2.7
类之间应该零耦合,或者只有导出耦合关系.也即, 一个类要么通同另一个类毫无关系,要么只使用另一个类的公有接口中的操作
所有其他形式的耦合都允许类把实现细节暴露给其他类, 这样就在两个类的实现之间建立了隐含依赖关系.将来如果一个类想要修改它的实现, 那么这些隐含依赖关系总会带来维护问题
经验原则 2.8
类应当只有一个关键抽象(key abstraction)被定义为领域模型中的一个主要实体.关键抽象经常以名词形式出现,并伴随着需求规约.每个关键抽象都应当只映射到一个类, 如果它被映射到多个类,那么设计者可能是把每个功能都表示为一个类了.如果多个关键抽象被映射到了同一个类,那么设计者可能在创建一个集中化的系统.这些类经常被称为含糊的类(vague classes),并且需要分割成两个或多个类,每个类表示一个关键抽象
经验原则 2.9
把相关的数据和行为集中放置
如果违反这条经验原则,那么开发者就不得不按以往方式编程.为了实现单一的系统需求,开发者不得不改动系统的两处或者多出.其实这两处(或者多处)是同一个关键抽象所以应当用同一个类表示
经验原则 2.10
把不相关的信息放在另一个类中(也即:互不沟通的行为)


2.4 动态语义
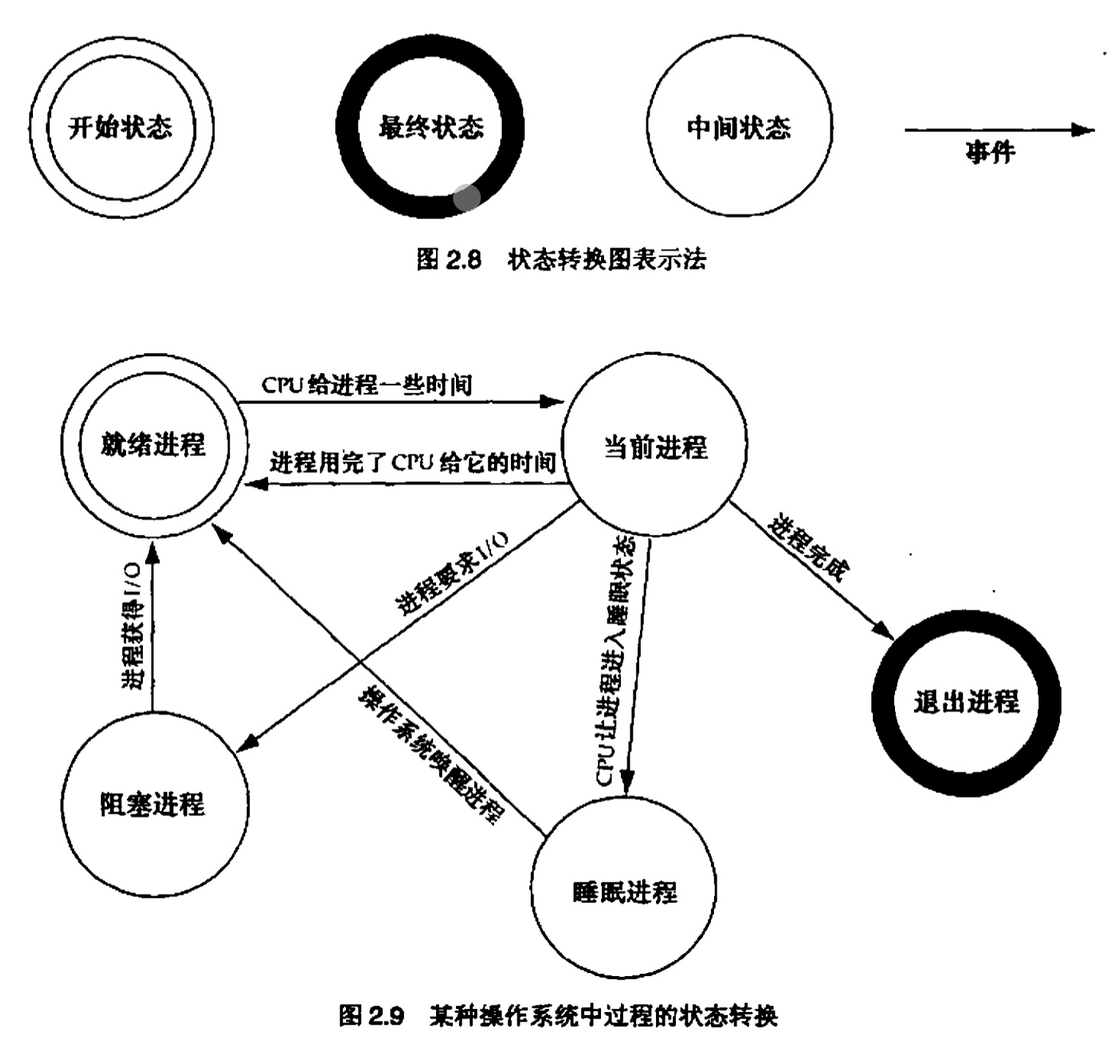
除了固定的数据和行为的描述之外,对象在运行时还随着其数据描述的动态取值具有局部状态(即当时的"快照")。类的对象的所有状态的集合以及状态间合法的变换称为类的动态语义(dynamic semantic)。动态语义允许对象对其生命周期的两个不同时候发来的相同的消息作出不同的回应。
Method junk for the class X if (local state #1) then do something else if (local state #2) then do something different End Method
对象的动态语义是任何面向对象设计的有机组成部分。一般而言,任何具有有意义动态语义的类都应当用一个状态转换图来把这些动态语义归档。具有有意义动态语义的类是指具有有限状态和精确定义的状态变换的类
2.5 抽象类
不知道如何实例化对象的类称为抽象类(abstract class)
知道如何实例化对象的类称为具体类(concrete class)
2.6 角色与类
经验原则 2.11
确保你为之建模的抽象概念是类,而不只是对象扮演的角色
"母亲"或者"父亲"是不是类,还是某个"人"所扮演的角色?答案取决于设计者为之建模的领域是什么。如果在给定的领域中, 母亲和父亲具有不同的行为, 那么或许他们应当被建模为类。如果他们的行为相同,那么他们只是"人"类的对象所扮演的不同角色
术语表
Abstract class
抽象类。不知道如何实例化自身对象的类
Class
类。以双向联系的方式封装数据和行为的构造。与现实世界中的一个概念对应。抽象数据类型(ADT)是类的同义词
Concrete Class
具体类。知道如何实例化自身对象的类
Constructor
构造函数。类的一个特殊的操作,负责创建/初始化该类的对象
Destructor
析构函数。类的一个特殊的操作,负责销毁/清除该类的对象
Dynamic semantic
动态语义。类的对象所能具有的所有可能状态,以及这些状态之间被允许的转换的集合。常用状态转换图来表示
Information hiding
信息隐藏,类向该类的对象的使用者隐藏它的实现细节的能力
Key abstraction
关键抽象,关键抽象被定义成领域模型中的一个主要实体。关键抽象经常表现为领域词汇中的一个名词
Message
消息。类中定义的操作的名称。在强类型语言中,消息可以包含名称,返回类型以及操作参数类型(也即操作的原型)
Method
方法。消息的实现
Object
对象,属于它的类的一个样例,包含它自己的标识,类的行为,类的接口,类的数据的一份拷贝。也称为类的实例
Overload function
重载函数。系统中的两个函数可以有相同的名字的能力,只要它们的参数类型不同(类内重载)或者所属的类不同(类间重载)
Protocol
协议。类能响应的消息列表
Self object
Self对象。控制位于方法内部,接受消息的对象的引用
经验原则小结
第3章 应用程序布局: 面向动作与面向对象
3.1 应用程序的不同布局
面向动作的软件开发所涉及的主要是通过非常集中化的控制机制来分解功能,而面向对象范型则主要关注在非常分布的环境中分解数据以及同数据相关联的功能。但也正是学习曲线的主要来源。当面向对象社群谈及"设计者们需要经受一次范型迁移"时,他们实际上指的就是这一分布化
无论如何,很多开发者相信,普遍的面向动作开发接近于最坏情况,而普遍的面向对象开发则接近于最好情况(特别是在有了重要的设计经验原则之后)
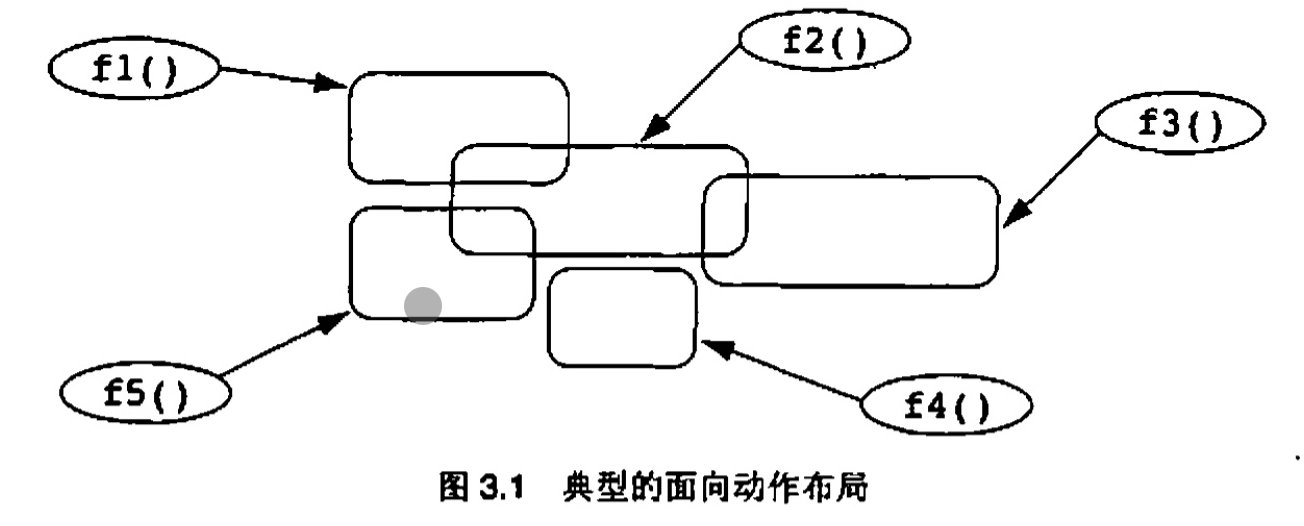
3.2 面向动作范型何时适用
很多面向对象解决方案把每个数据结构放在一个单独的文件中, 如果系统中哪个函数依赖于这个数据结构,那么就包含这个单独的文件。确实,这样做使得系统的可维护性得以提高。但是他们创建的文件是什么呢?它是数据和行为之间的双向关系,或者如果用面向对象的术语来说的话,是一个类。面向对象范型所做的是把这一用文件系统来封装数据和行为的惯例替换成一个设计语言层面的机制。 简而言之,它把最好的程序员的依照惯例编程行为替换成了一个低层机制。这样,普通的程序员就能从良好的设计/实现技术中获得好处,而不必完全理解它们背后的原则。依照惯例编程的主要问题在于,首先开发者必须理解它,其次,开发者必须坚持遵循它,而后者是最难保证的
面向对象范型在两个非常显著之处会把设计向危险的方向引导。第一个问题是分布不佳的系统功能,第二个问题是对于设计问题的规模而言,人们往往会创建太多的类。我们把第一个陷阱称作"全能类"(the god class)问题,并把第二个陷阱称作"泛滥成灾"(the proliferation of classes)问题
3.3 问题: 全能类(行为表现)
全能类问题的行为表现是由面向动作开发者们在向面向对象范型迁移的过程中易犯的错误引起的。这些开发者试图用面向对象设计来表现他们在面向动作范型中如此熟悉的中央控制机制。结果就是,创建了一个全能对象,执行了大多数工作,只把一些次要的细节留给了一些次要的类。有几条经验原则可以共同帮助你避免写出这样的类
经验原则 3.1
在水平方向上尽可能统一地分布系统功能,也即:按照设计,顶层类应当统一地共享工作
经验原则 3.2
在你的系统中不要创建全能类/对象。对名字包含 Driver,Manager,System, Subsystem的类药特别多加小心
经验原则 3.3
对公共接口中定义了大量访问方法的类多加小心。大量访问方法意味着相关数据和行为没有集中存放
经验原则 3.4
对包含太多互不沟通的行为的类多加小心,互不沟通的行为是指在类的数据成员的一个真子集上进行操作的方法,全能类经常有很多互不沟通的行为
违反这些规则意味着创建了一个行为表现的全能对象
面向对象范型则力图把数据和行为放在一个让它们双向关联的包中

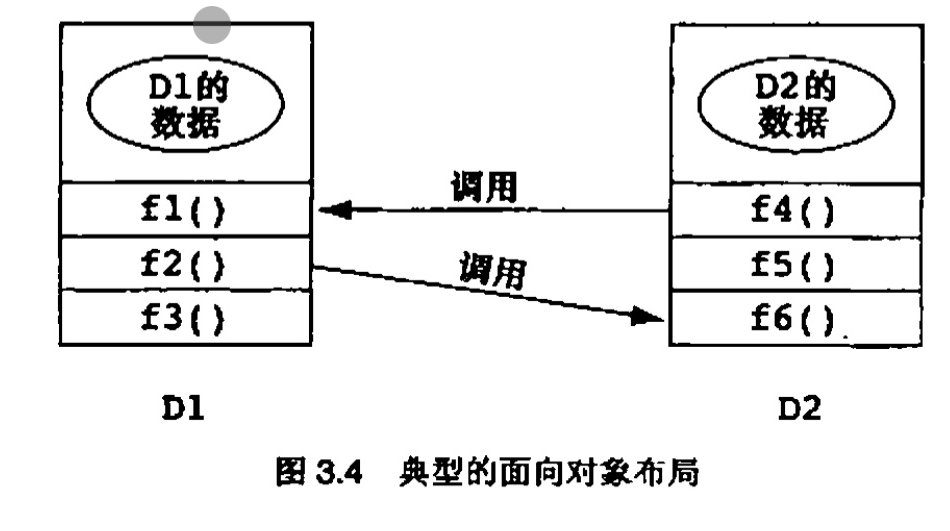
经验原则 3.5
在由同用户界面交互的面向对象模型构成的应用中,模型不应该依赖于界面,界面则应当依赖于模型
3.4 系统功能不良分布的另一个例子
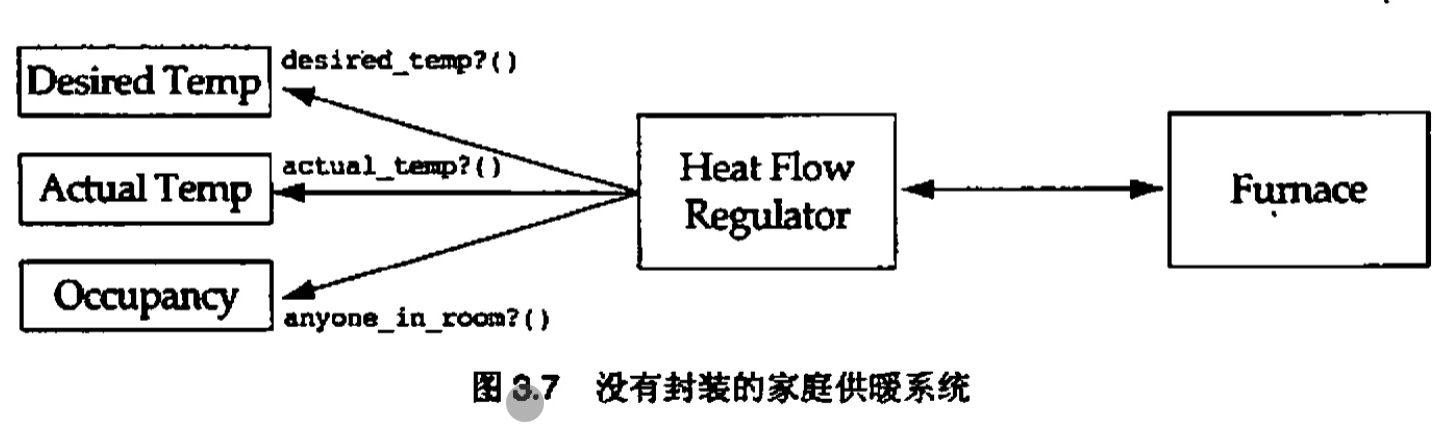
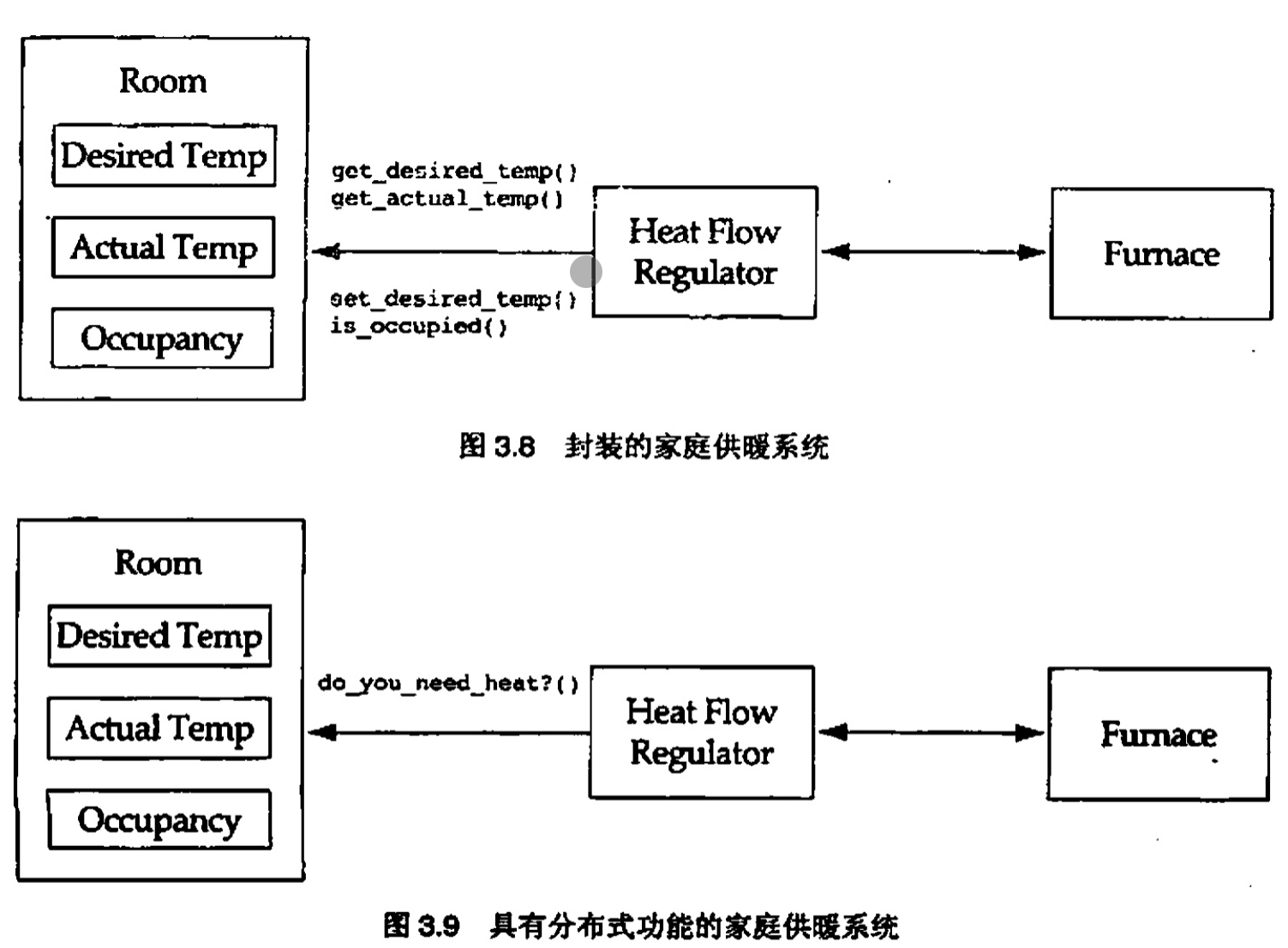
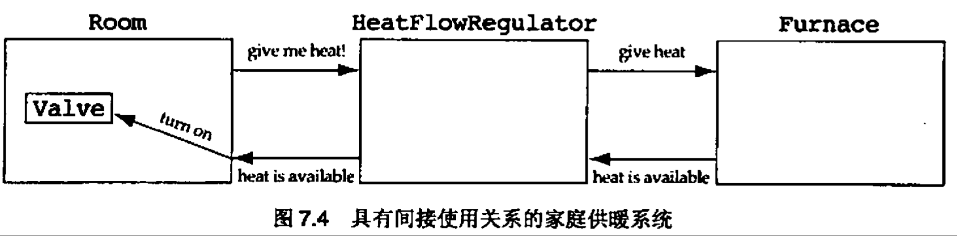
在这个设计中,HeatFlowRegulator是一个全能类。它执行了大多数的工作,而其他3个"字面上和它平起平坐"的类则只执行相对而言很少的工作。这个设计违反了经验原则3.1----水平分布系统功能
对于换个特定问题的最佳解决方案是让房间类来判断自己是否需要供暖(参见图3.8)。或者是由HeatFlowRegulator询问每个房间它是否需要供暖
经验原则 3.6
尽可能地按照现实世界建模(我们常常为了遵守系统功能分布原则,避免全能类原则以及集中放置相关数据和行为的原则而违背这条原则)
3.5 问题: 全能类(数据表现)

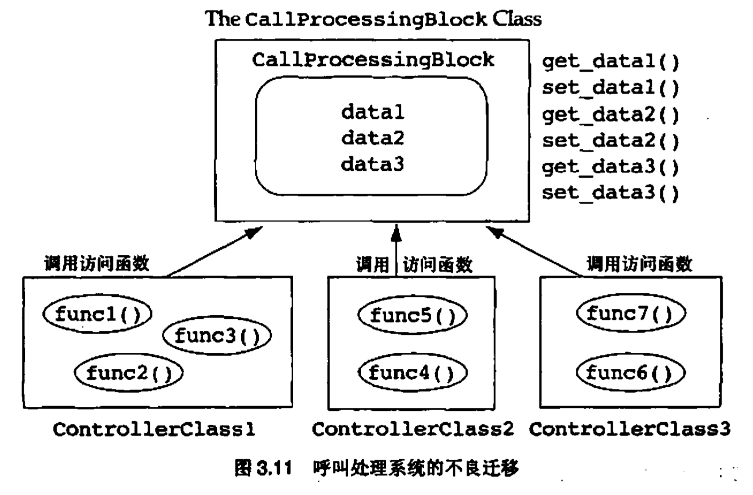
控制类违反了把数据和行为放在一起的经验原则。控制类很受欢迎,我觉得原因在于这使得把具有这种布局的遗产系统向面向对象设计迁移看起来比较容易
正确的迁移是把CallProcessingBlock 按照呼叫处理函数的需要分割成一个小块。根据所用到的CallProcessingBlock的不同子集,那些呼叫处理函数和与之相应的数据应当被放在一起。这样的面向对象设计才具有分布性和数据行为双向性

3.6 问题: 泛滥成灾的类
本书中很多经验原则探讨的是折衷取舍问题,以及对一种设计的改良使之优于另一种设计。很多这样的改良只是对原设计的小小改动,在本质上是局部的。一处经验原则的违背不会导致对整个应用产生全局影响
有位演讲者提出了一个有趣的论点:你在面向对象系统中不可能得到像意大利面条那样纠缠不清的代码(spaghetti code),但是你会得到像馄饨那样的代码(ravioli code)
经验原则 3.7
从你的设计中去除不需要的类
经验原则 3.8
去除系统外的类
如果一个类在系统外部,那么它对特定领域来说当然是没用的。系统外部的类并不总是那么容易发现的
经验原则 3.9
不要把操作变成类,质疑任何名字是动词或者派生自动词的类,特别是只有一个有意义行为(即:不考虑存取和打印成员的行为)的类。考虑一下那个有意义的行为是否应当迁移到已经存在或者尚未发现的某个类中
违反这条经验原则是使得泛滥成灾的主要原因。一定要注意找出那些只有一个有意义的行为的类。并且询问:”这个类是否应当是别的某个类的一个操作?还是它确实代表了某个关键抽象“?注意提出了”我需要一个做......事情的类”这样要求的程序员。“做”这个字听上去太像是一种行为了,显然值得检查。名字是动词或者派生自动词的类也很值得怀疑。面向对象泛型的初学者特别容易违反这条经验原则。这些开发者已经习惯了分解成的实体是函数,常常用一个类来表示一个方法。他们还没能顺利转向面向对象范型中更大的抽象粒度
我最近曾参与的一个电信项目在其系统地面向对象设计中包含了图3.13所示的两个类。这两个类其实是把操作建模成了类,而这些操作其实应该属于一个尚待发掘的类。如果我们看一下这两个类的公有接口,那么我们很可能会发现只有一个方法,这个方法是那个尚待发现的类所需要的某一功能的实现。图3.14展示了一个更好的设计


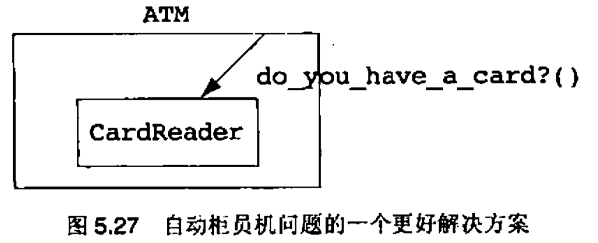
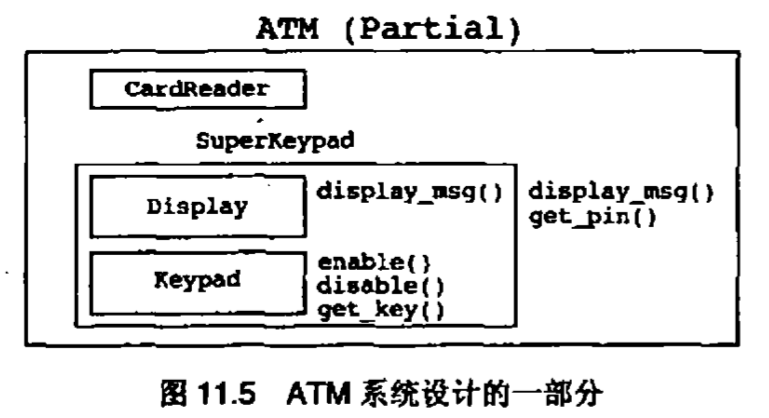
值得注意的是,并不是所有名字是动词的类都应当被去除。在一次设计课程中,有些学生被要求根据一组需求规约设计一个自动柜员机(ATM)系统,按照这组规约,通常会产生如图3.15所示的一部分设计
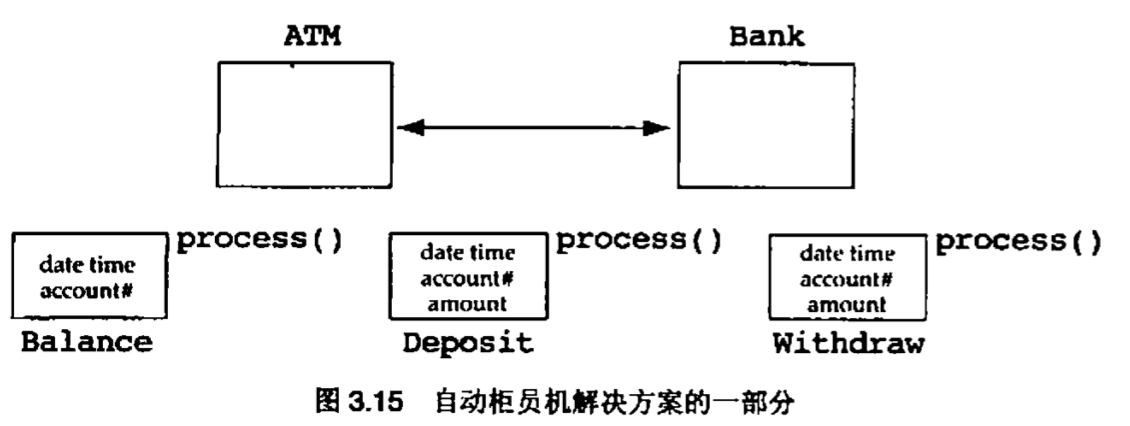
存款(deposit),取款(withdraw)和查询余额(balance)类都是操作的良好候选者,但它们都被设计成了类。这些类的名字是动词,并且它们的公有接口中只有一个有意义的操作。很多学生批评了这个设计,并且认为该ATM系统应当设计成图3.16的样子

如果我们只考虑逻辑设计信息,那么第二个设计更好一些。如果我们能够给银行(Bank)类增加3个额外的操作,那么为什么还要有3个额外的类,每个类只有一个操作呢?第二个设计的问题是,如果增加了一项需求,要求银行负责为客户打印出每个月的结算表,那么需要提供给客户的就不仅是每月结余,还要有每次交易的记录。这就意味着,存款,取款和余额查询这些操作都要持久化。也就是说它们必须存储在系统中以备将来使用。这些实体是持久化的,这一事实就意味着它们应当被建模成类。所以,我们还是回到了第一个设计,把存款,取款和查询余额都建模成类
3.7 代理类的角色
在一个面向对象的农场上有一头面向对象的母牛,母牛产面向对象的牛奶。那么,究竟是应当由面向对象的母牛向面向对象的牛奶发出“uncow yourself”消息,还是应当由面向对象的牛奶向面向对象的母牛发出“unmilk yoursel”消息呢?
这听上去有点傻,但是却指出了一个很有意思的问题。
问题在于,缺少了一个关键元素----面向对象的农夫,以及面向对象的图书馆管理员。这些是抽象类吗
在分析时,常常会尽可能地按照现实世界建模。在设计过程中会把这个真实世界模型按照分布系统功能和避免全能类这样的经验原则进行修改。面向对象的农夫和面向对象的图书馆管理员是一种特殊的例子,这种类叫做代理类(agent)。代理常常在分析阶段被建模成类,如图3.17所示

在设计时,我们需要问自己:“究竟面向对象的图书馆管理员有什么用”?答案常常是这样的代理类是没有用的类。图书馆管理员类仅仅是从书和书架接收消息并把它们再发送到合适的目标。为什么不干脆去除图书馆管理员以减少我们的设计中类的数量和协作的数量呢(参见图3.18)?
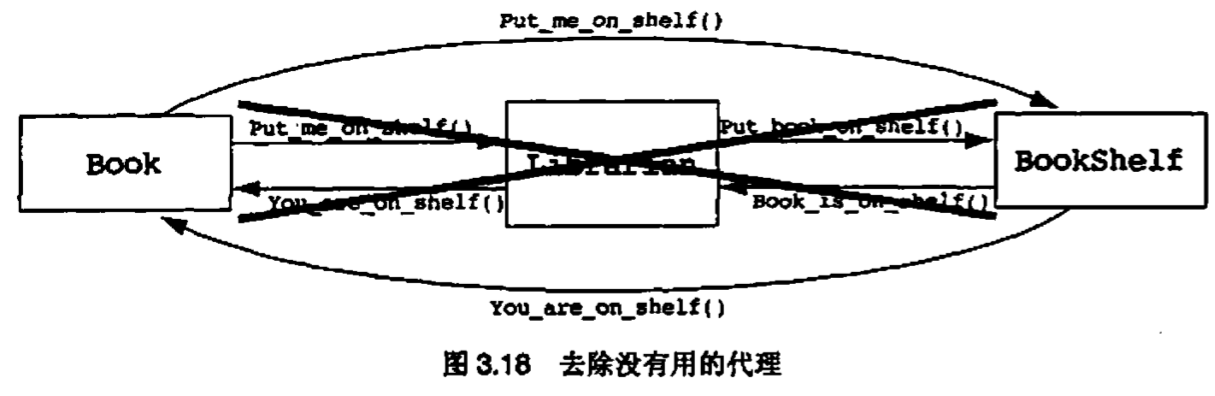
在很多情况下,这就是我们想做的事情。但是,如果图书馆管理员还有其他有用的行为(比如检查书的到期日期,发出图书馆罚款通知,采购新书)呢?我们可以把这些新的功能增加到书和书架类中,但是,如果常常是这两个类变得越来越复杂。基于分布系统功能的需要,我们使用代理类来承担一些工作。如果代理类表示了有用的抽象,那么把它们留在设计中并没有错。把没有用的代理类留在系统中则会使得设计过分复杂化,而且对设计者也没有好处
经验原则 3.10
我们在创建应用程序的分析模型时常常引入代理类。在设计阶段,我们常会发现很多代理是没有用的,应当去除
3.8 用途考察: 单独实体和控制类
面向对象社群需要认真地检查面向对象设计中控制类和代理类的角色。虽然通过使用把实体类(模型)同它们的行为(控制器)分离的技术能使得遗产系统到面向对象的迁移变得容易,但是在实践中这会导致数据和行为的人为分离。这一分离应被看作是违背了面向对象范型的基本原则,明确地说,是违背了数据和行为作为一个概念块双向联系的原则。在业务建模时,不同的应用常常会以不同的方式使用相同的数据,这常常是导致人为分离的原因。因为这常常会导致设计者创建实体类来为数据建模,并创建单独的控制类来以不同的方式使用数据模型
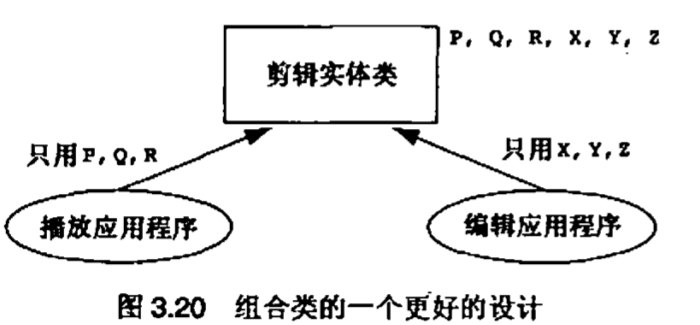
来看一下我最近工作的一家公司的基于媒体的框架设计。这个公司有很多应用程序的工作对象是媒体工业所称的剪辑。剪辑类包含了一系列不同的项目,这些项目共同描述了一个编辑过的电影作品,或者更一般地说,媒体作品。数据模型可以很容易地复用于所有这些应用程序。但问题在于,这些应用程序执行的功能各不相同。例如,当编辑程序使用剪辑时,剪辑需要支持X,Y,Z这些功能,而播放程序使用剪辑时,剪辑需要支持P,Q,R这些功能。如图3.19所示,通过控制类来设计这样的系统会导致一个支持剪辑类的实体类以及它的各部分和分层体系,另外两个控制类处理不同的功能

这个设计的问题在于,我无法再检查一组数据并询问“谁依赖于你”。我需要检查所有的控制类才能判断依赖关系,这和一个没有行为的数据库模型以及一组拥有所有行为的应用程序又有什么差别呢?我认为,控制类的受欢迎情形与它们同面向动作范型的语义相似性具有直接关系。事实上,控制类面临的一些问题也就是面向动作范型所面临的问题,例如不确定的数据/行为依赖性
一个更好的设计是让剪辑类在公有接口中提供6个操作(P,Q,R,X,Y,Z),如图3.20所示。一个应用程序只用到一半的公有接口并没有关系。没有哪条经验原则说类的使用者必须用到整个公有接口。我有一个链表类,这个类大约有30个操作。如果你只打算使用插入,删除,遍历这几个操作也并没有错。问题在于,并不是每个应用程序都愿意为不使用的操作的目标代码付出代价。这并不是设计问题(逻辑设计),而是源代码维护问题(物理设计)。不要为了简单的物理设计问题而放弃一个更好的逻辑设计
避免实体/控制器设计形式的一个更主观的理由是,人们在现实世界中的喜欢控制器。上次你放错冰箱控制器,烤炉控制器,轿车控制器或者投影仪控制器是在什么时候?我们不会放错它们,因为数据和行为被封装在同一个包装中。当然,现实世界中也有这样的例子。控制器和数据是分离的。我认为,所有这些情况都不是因为人们的偏好,而是成本问题。一个经典例子是录像机和录像带。我们购买录像机(控制器),然后再单独购买或者租借录像带(实体)。我相信,这是因为控制器非常昂贵(物理设计问题),而不是因为设计选择。人们希望最好每盘录像带都自带播放器,这样就把控制器和实体信息封装到了同一个包装中。在旅行的时候,我常常想租一盘电影,但是无法如愿,因为我把控制器留在家里
在最近一次讲座中,关于录像机的解释使得一位“怀疑论者”大叫起来,他说让每盘录像带都自带控制器的想法简直荒谬。另一位学生也附和着说,认为人们希望照相机(控制器)和胶卷(实体)用一个小巧的外壳封装在一起的想法也同样荒谬。但是今天,随着价格的降低,人们对一次性的可抛弃的相机的需求越来越大了。关于控制类的讨论持续了几个小时,然后投影仪的灯泡爆了。我们不得不花15分钟来等待专人替换灯泡。对此,一位学生说,我或许会希望每张幻灯片都自带行为部分,而不必依赖于外部的控制器。我对此完全同意!
术语表
Accessor method
访问方法。对类的数据成员执行get和set操作的方法
Agent class
代理类。仅有的职能是解耦两个或更多个类的类。代理类的特征是把方法委托到其他类的消息
Controller class
控制类。只有行为没有数据的代理类。所有必要的数据都是通过其他类的访问方法来获取
Design pattern
设计模式。已知问题在多个领域内(常常是与领域无关)的一般化解决方案
Logical object-oriented design
面向对象逻辑设计。面向对象设计的一个侧面,涉及的事项包含找出类,决定它们的公有接口以及它们的行为
Physical object-oriented design
面向对象物理设计。面向对象设计的一个侧面,涉及的事项包含硬件和软件平台对系统逻辑设计的影响,效率,可移植性,以及可能的未来需求
Policy
策略。应用程序的一部分,描述基于一个或多个类的信息的与领域相关的计算
经验原则小结
第4章 类和对象的关系
4.1 类和对象关系导引
面向对象设计要求开发者首先找出系统的一些关键抽象,以及它们的精确定义的公有接口。然后就是描述这些关键抽象之间的关系。我们对这些关系的描述常常可归入一下4类:
- 使用关系(基于对象)
- 包含关系(基于对象)
- 继承关系(基于类)
- 关联关系(基于对象)
术语“基于对象”和“基于类”并不是描述关系定义的方式(是针对类还是针对对象定义的),而是表明是否类的所有对象都必须遵守这一关系。我们将看到。对于使用,包含和关联。并非类的所有对象都必须服从,而继承则是类的所有对象都服从的关系。面向对象设计由类,它们的协议以及对前面列出的4类(最基本的)关系的描述组成。每种关系都有其自身的特性,并且在设计中被误用时具有危险性。因此,每种关系都有相关经验原则来确保对其的正确使用
4.2 使用关系
大多数开发者用得最多的关系,是“使用”关系(use relationship)。简而言之,如果某个类的一个对象向另一个类的某个对象发送了消息,那么我们就说第1个类与第2个类有使用关系。 APenrson(人)类的对象在向闹钟(AnAlarmClock)类的对象发消息,让它把时间设置为10:30.我们说,APerson类使用了闹钟类。这是否意味着APerson类的所有对象向闹钟类的所有对象发送消息呢?当然不是。所以我们说使用关系是基于对象的,也即:不是类的所有对象都必须遵从这一关系

4.3 实现使用关系的6种不同方法

自动柜员机如何知道吐钞装置对象的名字呢?在这种情况下,我们会发现,实际的关系是一种包含关系,而不是使用关系。自动柜员机是否把吐钞装置作为一个数据成员包含其中并不是那么显而易见的事情。自动柜员机隐式地知道它的数据成员的名字,因此不需要额外努力就可以向其发送消息。我们将会看到,有很多使用关系都被细化为包含关系。同样地,所有的包含关系首先是使用关系
如果使用关系不是包含关系,那么第1个对象(发送者)如何知道第2个对象(接收者)的名字呢?请考虑轿车和加油站之间的关系。让轿车包含加油站显然是不合理的。但是,轿车的确需要加油站来给它们加油。轿车如何知道加油站的名字呢?除了包含关系之外,使用关系还有5种实现

除了通过包含之外,使用关系的第一种实现是通过消息的形参向轿车传递加油站的名字。想象一下一个更高层的对象向轿车发出了get_gasoline()消息,并把加油站的名字作为参数传递:“轿车从位于......地方的加油站G加油"
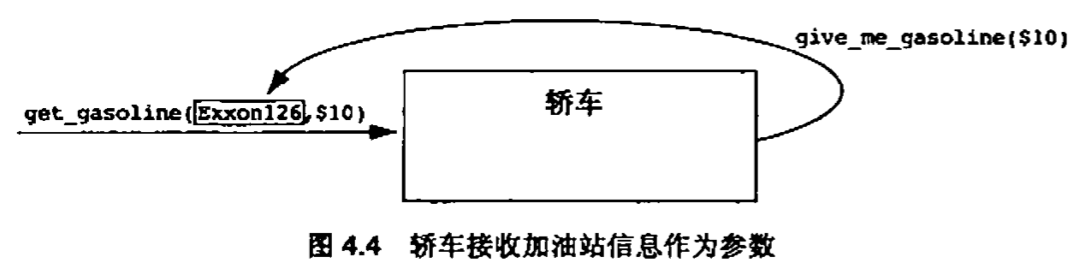
另一种方式是,轿车查询另一个类(地图类)来获取一个合适的加油站的名字。当然,这只是暂时回避了问题----我们如何知道地图对象的名字呢?

第3种方式是,所有的轿车都是用同一个全局加油站,并且我们都通过约定知道它的名字。这实际上是第1种方法的一个特例,因为全局数据被看作是方法的隐式参数

第4种方式是为有钱人设计的。每当轿车需要加油时,我们停在路边,买下那块地,建一个加油站,然后使用这个加油站,在离开的时候再拆毁它。简而言之,轿车类的get_gasoline()方法会创建一个局部的加油站对象,使用这个对象,然后在方法推出时销毁这个对象。对于轿车/加油站领域,这并不是好办法,但在很多领域中这种创建局部对象来执行某项功能的方法是很有用的
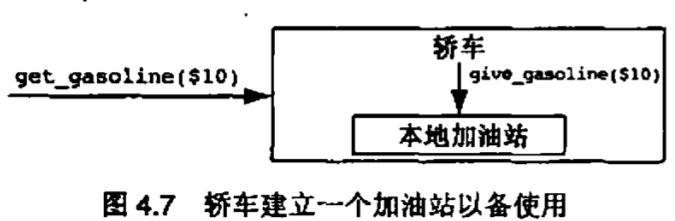
实现使用关系的第5种(也是最后一种)方法是”上帝“在轿车建造的时候告诉它,它的指定加油站是哪一座。轿车把这一条信息保存在某种特殊类型的属性(称为引用属性)种,以备调用get_gasoline方法时使用
4.4 使用关系的经验原则
应用程序中主要的顶层对象之间的典型关系是使用关系。在最佳的面向对象设计中,这些使用关系都不能细化为包含关系。
经验原则 4.1
尽量减少类的协作者的数量
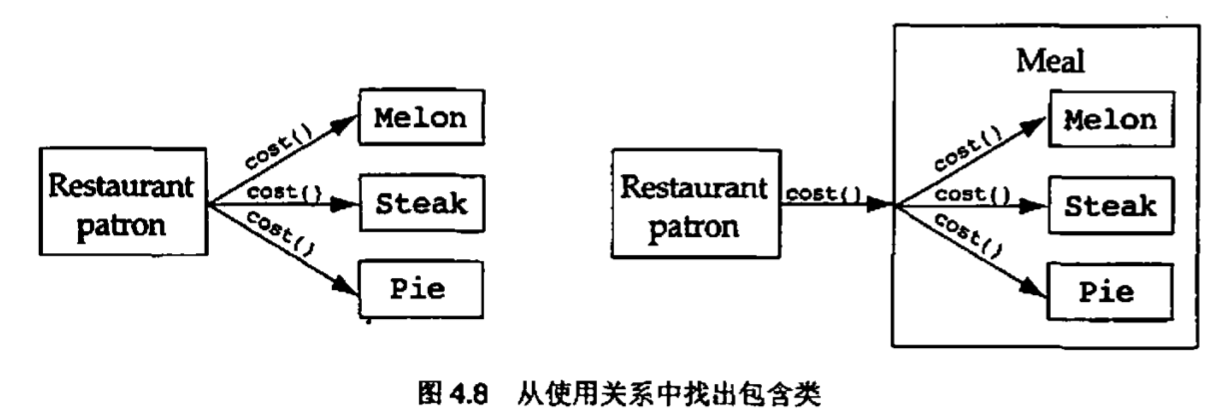
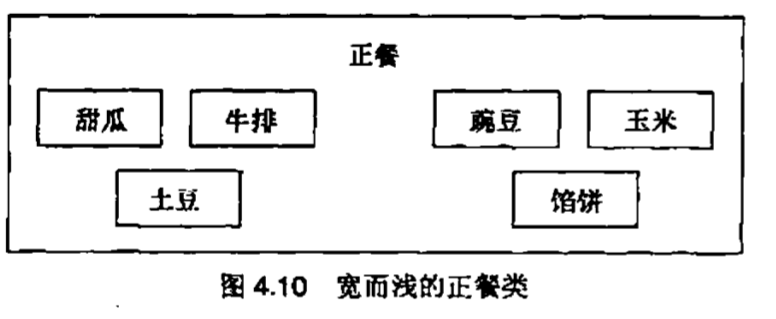
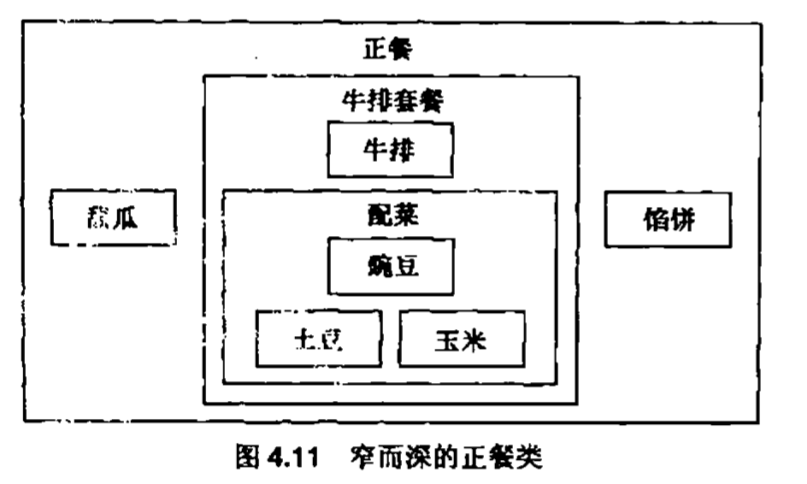
这条经验原则指出。一个类用到的其他类的数目应当尽量少。在最糟糕的情况下,一个面向对象的设计由一系列基本的,简单的类组成,这些类彼此之间都相互使用。这样的顶层很难理解。请注意,这并没有违反“避免全能类”这条经验原则。我们可以在大量顶层对象中一致地分配系统功能。解决办法是在使用关系图中找出一个类同其他类通信的地方,并且问自己:“我能否用一个类来包含这些类,从而减少协作的数量?”你会遇到很多这样的情形,其中有一部分你能回答“是的”。这些类就应当用包含类来加以包装,从而降低复杂性。例如,思考一下图4.8所示的餐馆顾客和食品种类。更好的解决方案是用包含类“主餐“来包装这些食品,这样就能在顶层设计中减少交互的数量
可能有人会争辩说,我们实际上增加了使用关系的数目,从3增加到了4.但是,因为数据封装的缘故,我们并不计入主餐类内部的使用关系,它们只是正餐的实现细节,对于餐馆顾客而言是不可见的。我们在本章的稍后部分将会看到,包含是面向对象范型用于简化设计的一种关系。无论如何,当我们可以在一个事物中包含另一个事物时,就意味着我们可以在某个较高的设计层次上忽略被包含的对象
值得指出的是,一旦某个类的一个对象向另一个类的另一个对象发送消息,那么这两个类之间就存在着协作。有些开发者曾尝试将类之间协作数量最小化这条经验原则加以量化,并指出一个类的协作类不应当多于6个 。这些开发者试图基于短期记忆限制来创建复杂性度量。虽然对于包含关系和继承关系而言这一信息有价值,但我并不认为这里短期记忆限制理论适用。为了理解一项需求(比如,一个场景,一个用例),我们并不需要把类的所有协作都概念化。因为我们常常通过分析类在应用需求中的橘色来理解一个类,所以开发者很少在一项需求之外分析全部协作关系
4.5 精确调整两个类之间的协作量
从逻辑设计的角度来看,一旦两个类之间存在协作关系,那么系统的复杂性就有了一定程度的增加

经验原则 4.2
尽量减少类和协作者之间传递消息的数量
经验原则 4.3
尽量减少类和协作者之间的协作量,也即:减少类和协作者之间传递的不同消息的数量
经验原则 4.4
尽量减少类的扇出,也即:减少类定义的消息数和发送的消息数的乘积
4.6 包含关系
我们说正餐包含了甜瓜,这是否意味着所有的甜瓜都包含在正餐中?当然不是,还有些甜瓜包含在蔬菜水果店中,在田里面,在垃圾桶里面。所以,包含是基于对象的关系,因为并不是一个类的所有对象都必须遵从这一关系
经验原则 4.5
如果类包含另一个类的对象,那么包含类应当给被包含的对象发送消息。也即:包含关系总是意味着使用关系
这条经验原则的理由是,如果包含类没有向被包含的类发送消息,也没有get方法返回被包含的对象供其他对象使用,那么被包含的类就是无用的信息(因为数据隐藏使它们也无法被别的对象使用)。而后者(即提供get方法)违反了“将相关的数据和行为放在一起”的经验原则,但容器类是一个例外。容器类是用来临时存放其他对象的范型类。它们的有意义行为就是插入和删除其他的对象。除非我们处理的是容器类,否则的话就应当删除被包含的对象并进行合理的抽象设计。换句话说,在设计的这一处,数据分解模型有错误
关键的问题是,哪种设计更好?当问到这类问题时,我们总是需要考虑两种人,一种是类的使用者,另一种是类的实现者。 对于正餐类的使用者而言,哪种设计更好呢?如果你的回答是第1种设计,那你就错而了;如果你回答得是第2种,你还是错了,为什么?作为正餐类得使用者,你应当并不介意使用哪种设计。如果你对某种设计有偏好,那就意味着你依赖于正餐类得实现,这显然违背了数据隐藏原则。我得经验是,对这个问题的回答往往倾向第1种设计的占大多数。这表明,典型的面向动作设计者在进行高层设计时常常忍不住诱惑想要知道实现细节,这也是很多扩展性问题的原因。在面向对象世界中,如果正餐对象的使用者想要知道正餐的价格,他只要向他的对象发送一个“价格”消息就可以了,了解包含层次体系的其他信息会导致维护问题
因为数据隐藏,我们可以随心所欲地深层次嵌套结构,而不会给使用者增加复杂性。
经验原则 4.6
类中定义的大多数方法都应当在大多数时间里使用大多数数据成员
经验原则 4.7
类包含的对象数目不应该超过开发者短期记忆的容量。这个数目常常是6
经验原则 4.8
让系统功能在窄而深的继承体系中垂直分布
这条经验原则和“在顶层类中水平分布系统功能”是配套的。两条都是重要的经验原则,虽然水平分布要比垂直分布更重要一些。不恰当的水平分布会影响整个程序,而不恰当的垂直分布则只影响这个类的实现
窄而深的层次体系的一个副效应是你获得了更多的挂载点,可以更好地复用。不妨假设我们为某个其他领域要办一次火鸡宴会,那么我们想要复用正餐类是很正常的。我们会发现,并不是整个正餐类都可以复用,但是我们可能会在它的黑盒内找到一些有趣的东西。我们打开第1个设计的黑盒,然后大量的细碎东西倾倒了出来。我们捡起土豆,豌豆,玉米,因为我们在火鸡宴上也需要这些东西。现在我们试图玻璃出只处理这3个数据成员的方法代码,但是我们很快会发现这是件令人沮丧的工作,难以分解这一抽象。所以我们把这一团糟的东西丢弃并从头创建自己的抽象。而使用第2个设计,我们打开一个黑盒会发现3个比较小的黑盒。我们抛弃了甜瓜和馅饼,因为它们在我们的新领域中没有用处,但是我们发现牛排套餐或许会有价值。我们打开牛排套餐的黑盒子并发现了另一个叫做配菜的黑盒子,这是一个合适的抽象,因为我们的火鸡宴也需要这些配菜。现在我们可以使用配菜结构,而不必再去看它的内部设计了。这种复用一个包含层次结构中的一个特定部分的能力对于进行新设计是很有好处的
4.7 类之间的语义约束
经验原则 4.9
在实现语义约束时,最好根据类定义来实现。这常常会导致类泛滥成灾,在这种情况下约束应当在类的行为中实现,通常是在构造函数中实现,但不是必须如此
经验原则 4.10
当在类的构造函数中实现语义约束时,把约束测试放在构造函数领域所允许的尽量深的包含层次中
经验原则 4.11
约束所依赖的语义信息如果经常改变,那么最好放在一个集中式的第3方对象中
经验原则 4.12
约束所依赖的语义信息如果很少改变,那么最好分布在约束所涉及的各个类中
4.8 属性与被包含的类
当设计包含层次体系时,请牢记,大多数类都有属性。大多数属性在本质上都是描述性的:轿车的颜色,水果的重量,房间的宽度。这些并不被看作包含关系,因为被包含的数据并没有与之相关联的行为。
4.9 包含关系的更多经验原则
经验原则 4.13
类必须知道它包含什么,但是不能知道谁包含它
如果设计者想要复用他的抽象,那么这条经验原则就显得特别重要
经验原则 4.14
共享字面范围(也就是被同一个类所包含)的对象相互之间不应当有使用关系
共享字面范围的对象就是被同一个类所包含的对象。它们相互之间不应当有使用关系的理由是复用性和复杂性
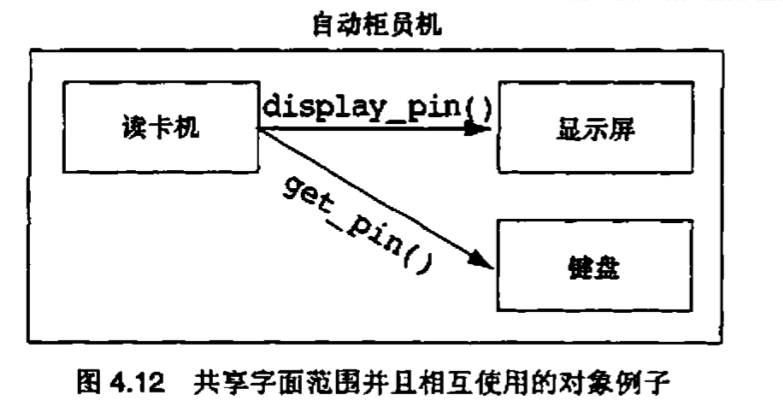

简而言之,让被包含的对象知道包含它的对象要比大量的使用关系好
4.10 使用和包含的关系
有3种,而不是2种涉及使用和包含的关系。第1种显然是使用关系,并且从来不会和包含关系混淆。一个好的例子是“人使用闹钟”。这里一点包含的意思都没有。然后是轿车和引擎的例子。这显然是包含关系(并且也意味着使用)。但是,在这两个极端之间,还有第3种关系,那就是停车场和轿车的关系,教室和学生的关系,加油站和轿车的关系。有的人简单地把这一中间类型认为是使用关系,因为它并没有表现出真正的包含关系所带来的简化设计的特性:这种设计并不能让我们在某个更高的层次上忽略被包含的对象。重要的是理解3个概念,而我们把这些概念叫做什么却并不重要。有些人把这些概念分别称作组合,包含,使用,也有人把它们称作包含,使用,使用,还有人称它们为包含,饱含,使用,甚至还有人称它们为强包含,弱包含,使用。判断是包含的强形式还是弱形式的一种好的测试方法是,问一下自己:“如果我把被包含的对象移除了,那么包含类的行为会改变吗?”如果答案是肯定的,那么这是包含的强形式(组合?);如果答案是否定的,那么这是包含的弱形式。如果从教室中把学生都赶走,教室的行为会有什么改变吗?不会。如果我从轿车中把引擎去掉,轿车的行为会有所改变吗?会的
4.11 值包含与引用包含
值包含意味着一个对象包含另一个对象,而引用包含则意味着一个对象包含到另一个对象的指针。值包含要求两个对象同生共死,而引用包含则允许对象包含可选组件(比如冷盘虾可以带调味酱也可以不带),还允许在一组对象之间共享一个对象,还允许包含抽象类(比如,正餐包含开胃菜),还允许上面提到的包含的弱形式
术语表
Attribute
属性,一个或一组不含行为的数据
Class-based relationship
基于类的关系。两个类之间的一种面向对象关系,在这种关系中类的所有对象都遵守该关系
Container class
容器类,主要用途是存储其他对象的类。常常实现为看上去是一致的列表,但存放不同种类的对象。也即:多态列表
Containment by reference
引用包含,一种包含关系,在这种关系中被包含的对象通常通过指针或者引用属性间接地连接到包含它的类
Containment by value
值包含。一种包含关系,在这种关系中被包含的对象直接连接到包含它的类,也即:该关系所涉及的对象同生共死
Containment relationship
包含关系,两个类之间一种基于对象的关系,在这种关系中,一个类拥有的一个属性(直接或间接地)是另一个类的一个对象。此外,被包含的对象必须在包含它的类之外是不可见的
Descriptive attribute
描述属性,包含关于类的对象的描述数据的属性
Object-based relationship
基于对象的关系。两个类之间的一种面向对象关系,在这种关系中并不是类的所有对象都遵守该关系
Referential attribute
引用属性,一种特殊类型的属性。通过这样的属性,一个对象可以获取另一个对象
Semantic constraint
语义约束,一种应用相关的对面向对象关系的约束,约束面向对象关系的范围或者行为,常常同包含关系相关联
Uses relationship
使用关系,两个类之间的一种基于对象的关系,在这种关系中一个类引用另一个类的公有操作
经验原则小结
第5章 继承关系
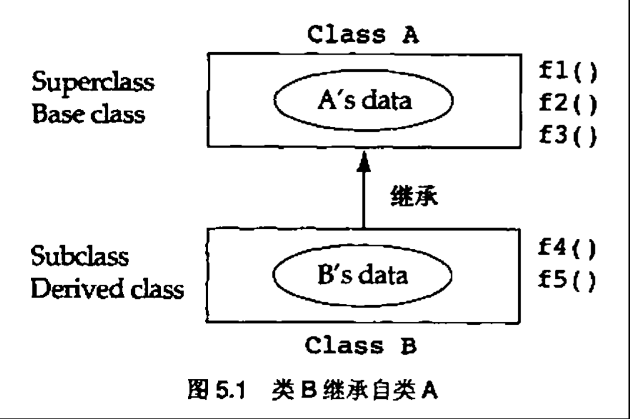
5.1 继承关系导引
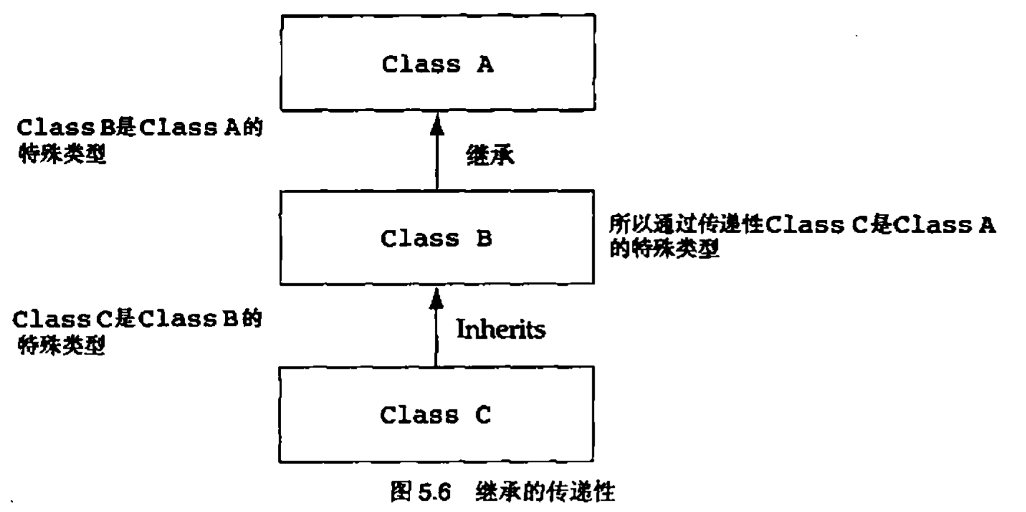
继承关系是面向对象范型中比较重要的关系之一。用它来表示类之间的“a-kind-of”关系是最好不过了,比如雪弗莱是一种轿车,狗是一种动物。它的主要用途有两种,它被用作表示两个类之间的共性的机制(泛化),还用来表示一个类是另一个类的特殊类型(特化)。术语“泛化”和“特化”一般被认为是“继承”的同义词
值得指出的是,学习面向对象范型的一大障碍是开发者在设计中把包含和继承关系混为一谈
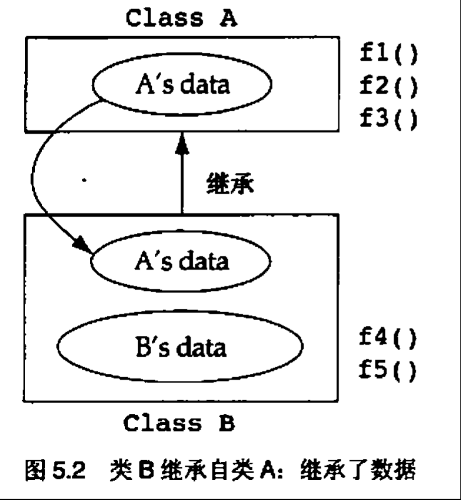
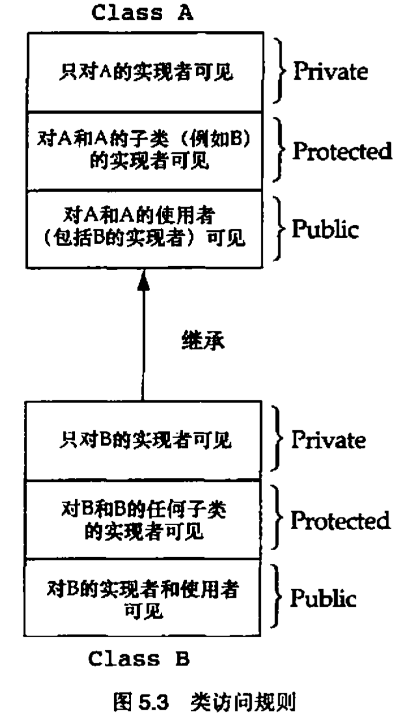
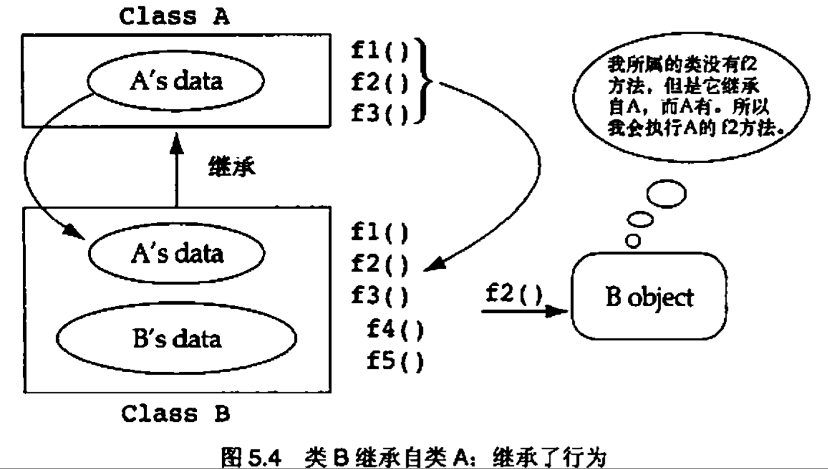
5.2 在派生类中覆写基类方法

经验原则 5.1
继承只应被用来为特化层次结构建模
包含关系定义了一个黑盒设计,在这个设计中类的使用者不需要知道同实现相关的内部类的信息。而继承关系则是一个白盒设计,这是因为继承了功能。为了知道可以向派生类发送什么消息,我们需要查看它继承的类。如果在可以用黑盒设计的地方我们使用了白盒设计,那么我们就不必要地向类的使用者暴露了我们的实现。通过黑盒设计无法有效地表示特化,所以对于这类抽象我们可以暴露设计细节
经验原则 5.2
派生类必须知道它们的基类,基类不应当知道关于它们的派生类的任何信息
如果基类知道它们的派生类,那么这就意味着如果基类有了一个新的派生类,基类中的代码就必须修改,这不是基类和派生类所表示的抽象之间应有的依赖关系
5.3 在基类中使用保护区域
经验原则 5.3
基类中的所有数据都应当是私有的,不要使用保护数据
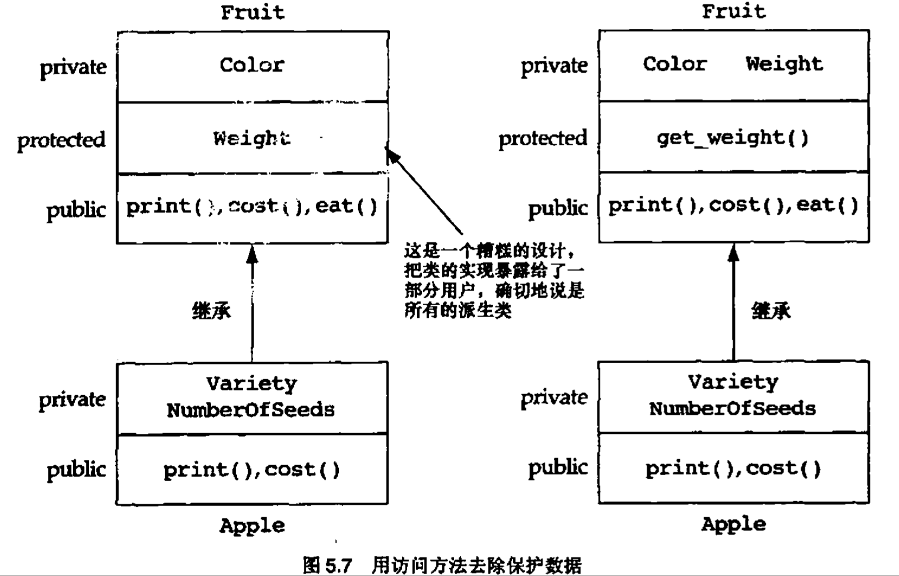
5.4 继承层次结构的宽度和深度
经验原则 5.4
在理论上,继承层次体系应当深一点,越深越好
经验原则 5.5
在实践上,继承层次体系的深度不应当超出一个普通人的短期记忆能力。一个广为接受的深度值是6
5.5 C++的划分: 私有,保护和公有继承
5.6 一个现实世界中的特化例子
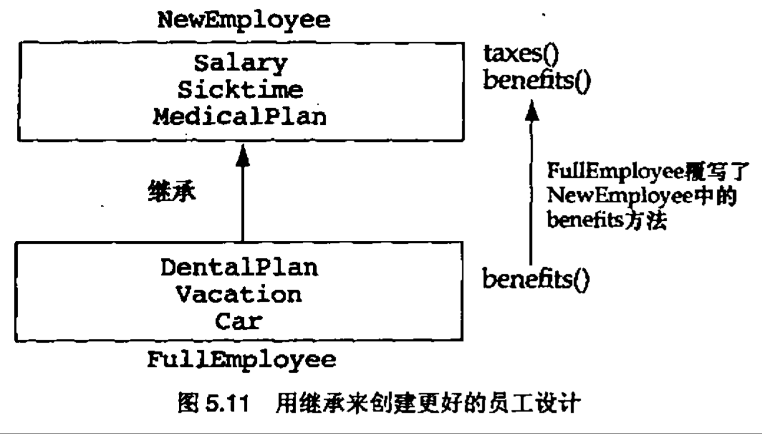
5.7 经验原则: 寻求设计复杂性和灵活性的平衡
经验原则 5.6
所有的抽象类都应当是基类
经验原则 5.7
所有的基类都应当是抽象类
5.8 一个现实世界的泛化例子
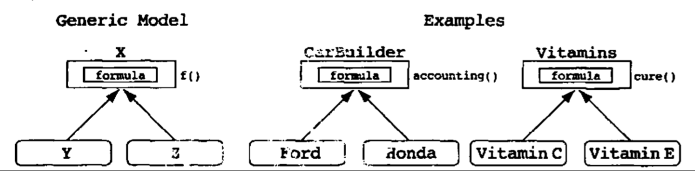
所有这3个类都包含重量和颜色,这本身并不足以构成继承关系。如果两个或更多个类只具有公共的数据,也就是没有公共的消息,那么应该把公共的数据封装到一个新类中,原来得两个(或更多个)共享了公共数据的类都应当包含这个新类。因为面向对象范型把数据和行为以双向的关系封装在一起,所以公共数据常常意味着公共行为在这些情况下,就需要用继承关系来表示公共抽象
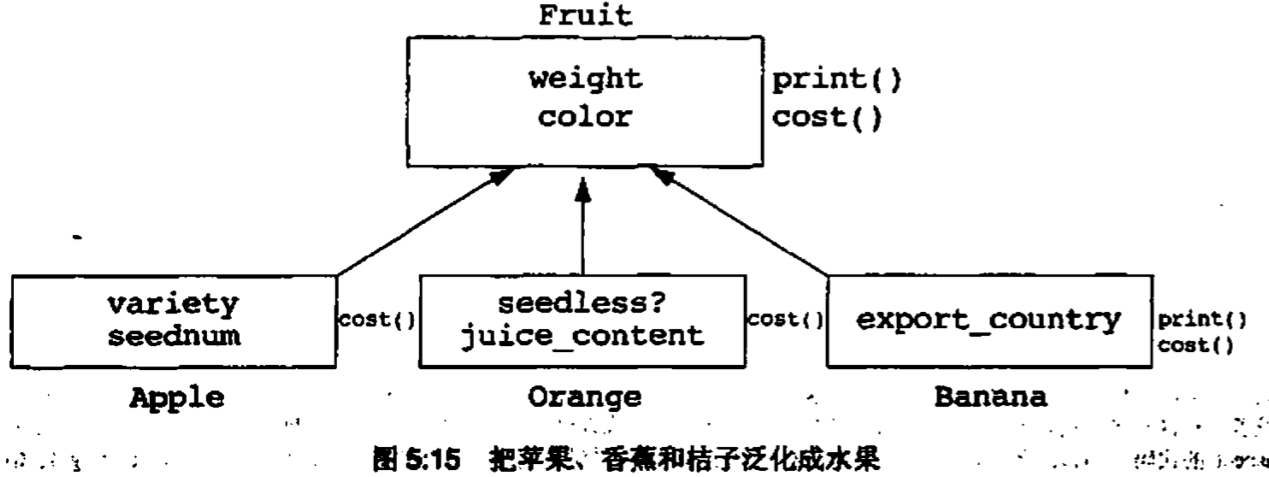
因为我们是从派生类开始的,最后找到基类,所以这叫做泛化
经验原则 5.8
把数据,行为和/或接口的共性尽可能地放到继承层次体系的高端
5.9 多态机制

显式情况分析的问题在于,当我们想增加一种新的水果时,我们需要在case语句中增加一个新的case。当我们修改已经存在的代码时,我们就承担了给这些代码引入新的bug的危险。要小心那些声称“只是增加了一个case语句,不会发生错误”的设计者。在现实中,从来都不是增加了“一个”case语句。通常会有很多case语句散布在整个代码中,很有可能会忘记给其中某处增加case语句
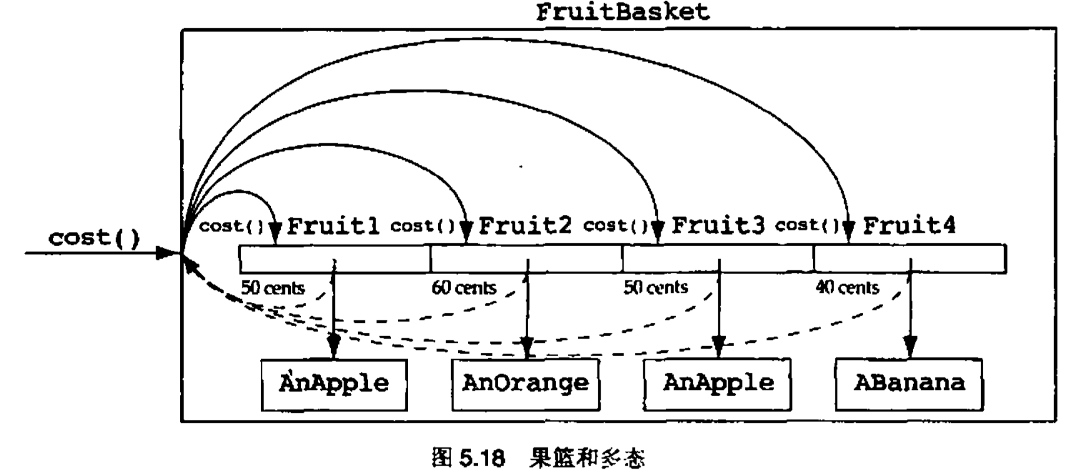
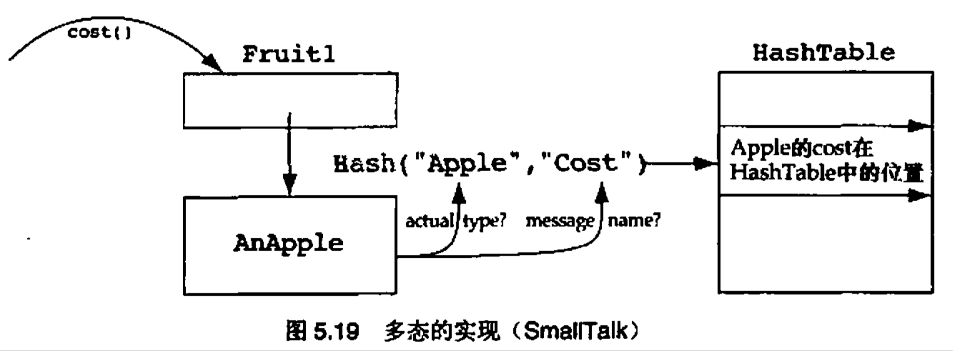
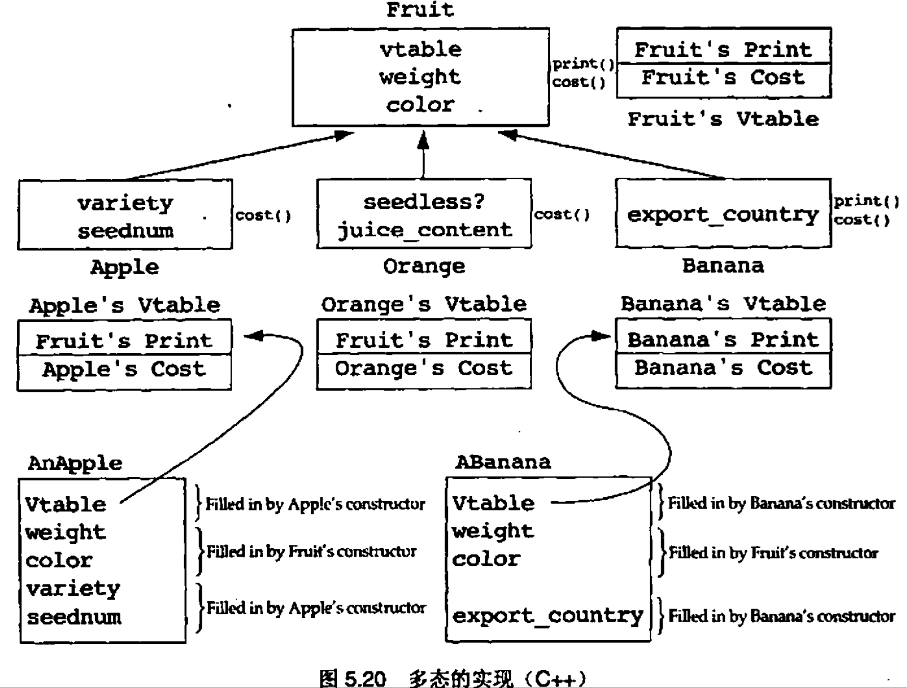
经验原则 5.9
如果两个或更多个类共享公共数据(但没有公共行为),那么应当把公共数据放在一个类中,每个共享这些数据的类都包含这个类
经验原则 5.10
如果两个或更多个类有共同的数据和行为(就是方法),那么这些类的每一个都应当从一个表示了这些数据和方法的公共基类继承
经验原则 5.11
如果两个或更多个类共享公共接口(指的是消息,而不是方法),那么只有它们需要被多台地使用时,它们才应当从一个公共基类继承
经验原则 5.12
对对象类型的显式的分析情况分析一般是错误的。在大多数这样的情况下,设计者应当使用多态
多态机制会隐式地执行情况分析,从而消除了向系统增加新类型时修改已经存在的代码的必要
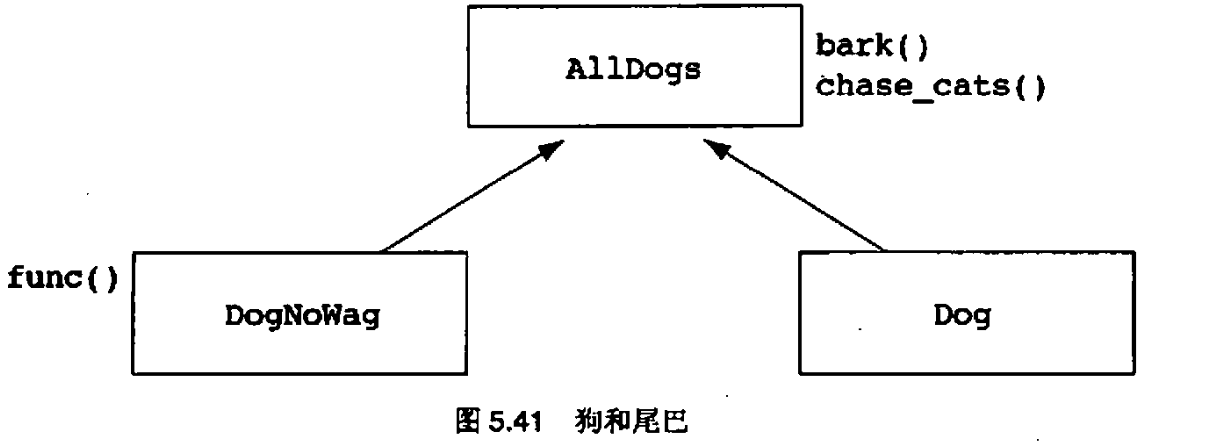
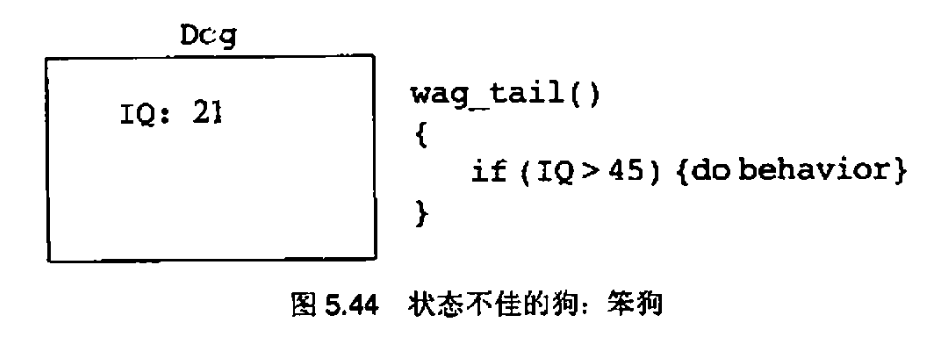
5.10 把继承作为复用机制的一个问题
基类的成熟
5.11 用继承实现中断驱动架构的方案
有位参与者说:“任何事物都是一个轮询系统。轮询和中断驱动的差别在于你的视点。当我们在硬件中轮询时,我们喜欢称之为中断驱动的"
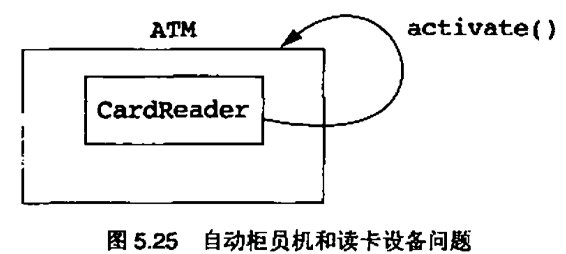
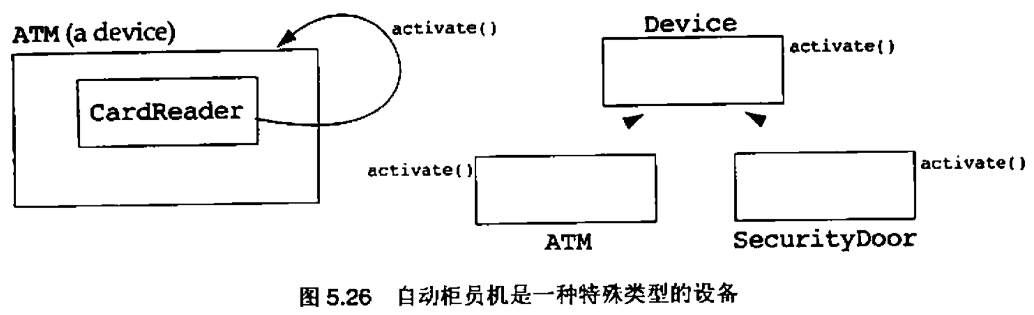
5.12 继承层次结构与属性

决定性的问题是,”这个属性的值是否会影响类的行为"?如果答案是肯定的,那么在大多数情况下我们想要使用继承。如果答案是否定的,那么我们希望把抽象建模成一个可以取不同值的属性。
经验原则 5.13
对属性值的显式的分情况分析常常是错误的。类应当解耦合成一个继承层次结构,每个属性值都被变换成一个派生类
5.13 混淆: 继承的需求与对象动态语义

你觉得这个设计怎么样?一切看上去都很令人满意,但当我们考虑到栈对象的生存周期时情况就不同了。它创建时是一个空栈对象,当某人执行了push操作之后空栈对象就被转换成一个非空栈对象。稍后,当某人执行了一个pop操作,这个非空栈对象又变回了空栈对象。这个对象在运行时一直在改变它的类型。在大多数面向对象实现中,在运行时改变对象的类型都是一个代价高昂的操作。它要求创建新类的一个对象,调用新类的构造函数,这个构造函数要接受旧类的对象作为参数。在从构造函数返回的时候,还必须释放旧的对象
经验原则 5.14
不要通过继承关系来为类的动态语义建模。视图用静态语义关系来为动态语义建模会导致在运行时切换类型
我们如何实现动态语义呢?人们偏爱的方法是对表示状态信息的属性值执行显式情况分析。虽然显式情况分析不太好,但是至少只有类的实现者会用到这个情况分析。而对对象类型的显式情况分析则常常由类的使用者执行,这是更糟糕的维护问题
如图5.30所示。其想法是用一个类内部的继承层次结构来封装类的状态。类的状态字段将会切换类型,但是因为状态类不包含数据,所以类型转变的代价很低

5.14 用继承来隐藏类的实现

5.15 把对象误当作继承类

经验原则 5.15
不要把类的对象变成派生类。对任何只有一个实例的派生类都要多加小心
5.16 把需概括对象误作需在运行时创建类
经验原则 5.16
如果你觉得需要在运行时创建新的类,那么退后一步以认清你要创建的是对象。现在,把这些对象概括成一个类
5.17 在派生类中屏蔽基类方法的尝试
经验原则 5.17
在派生类中用空方法(也就是什么都不做的方法)来覆写基类中的方法应当是非法的
5.18 对象可选部分的实现
经验原则 5.18
不要把可选包含同对继承的需要相混淆。把可选包含建模成继承会带来泛滥成灾的类
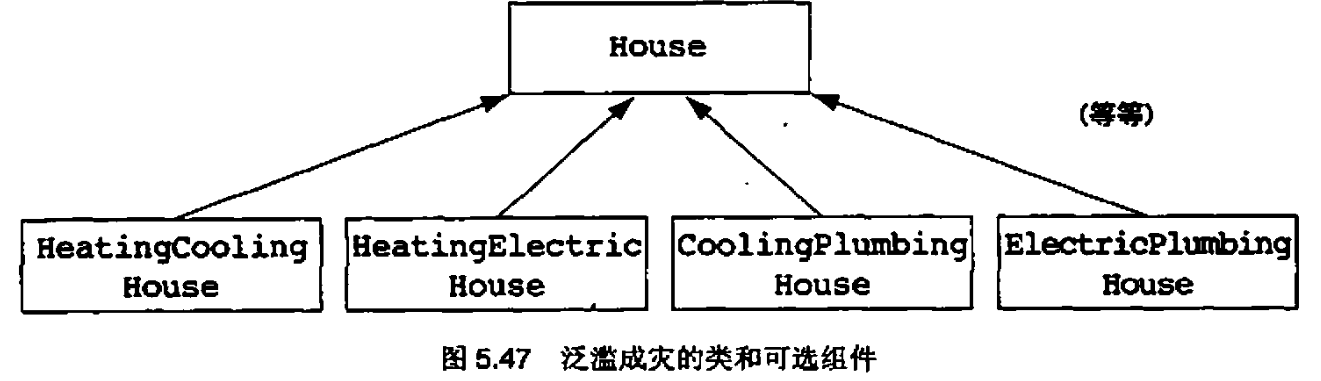
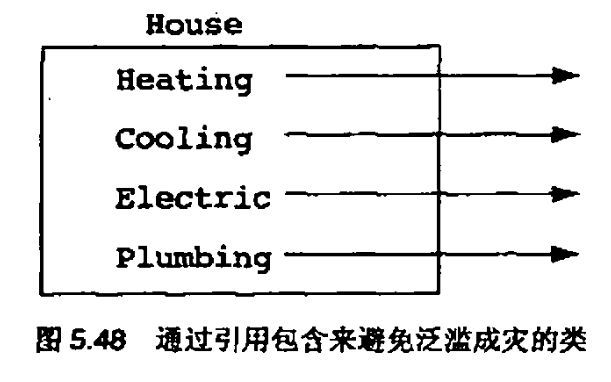
5.19 没有最优解的问题
5.20 复用组件与复用框架
经验原则 5.19
在创建继承层次时,试着创建可复用的框架,而不是可复用的组件
术语表
Dynamic binding 动态绑定。多态的同义词
Dynamic semantic wrapper 动态语义包装器。用来在局部继承层次体系中封装类的状态和变换的构造
Framework 框架。一组类的集合以及他们之间的关系,可能包含或者不包含可复用的代码。但是总是包含一个应用程序族的设计中可复用的部分
Generalization 泛化。继承的同义词。有时候表示继承关系是通过检查已经存在的派生类以找出新的基类来建立的
Specialization 特化。继承的同义词,有时候表示继承关系是通过在已经存在的基类上增加新的继承类来建立的
经验原则小结
第6章 多重继承
6.1 多重继承导引
6.2 多重继承的常见误用
6.3 多重继承的正当使用
6.4 不支持多重继承的语言中的非根本复杂性
6.5 用到多重继承的框架
6.6 运用多重继承: 设计mixin
6.7 DAG多重继承
6.8 可选包含的不良实现造成的不当DAG多重继承
术语表
经验原则小结
第7章 关联关系
7.1 关联导引
关联关系被定义为两个类之间不能被归入(使用,包含,继承)的其他所有关系
你开的轿车和制造它的公司的名字之间是什么关系?
你开的轿车和制造它的公司之间又是什么关系?
制造你的轿车的公司的名字是你的轿车的一个属性。值得指出的是,这个属性要比轿车的其他属性,比如颜色,里程数和车牌号码更重要。后面的三个属性是关于轿车类的描述信息。它们经常被称作描述属性。而制造你的轿车的公司的名字则提供了到整个对象(轿车制造商类的对象)的访问,这个对象位于领域中的其他地方。这类属性称为引用属性。我们可以说,制造你的轿车的公司的名字是你的轿车的引用属性
那么,又该如何回答第二个问题"你开的轿车和制造它的公司之间是什么关系?'。是继承关系吗?不是,因为你的轿车不是轿车制造商的特殊类型。那么是不是包含关系?也不是,你的轿车并没有包含在轿车制造商中,你的轿车也不包含轿车制造商。那么是不是使用关系?有可能,如果轿车向轿车制造商发送消息,或者轿车制造商向轿车发消息,那么两者之间有使用关系。为了便于讨论,我们假设两个类都不向对方发送消息。那么这两个类之间是什么关系呢?我们可以说,轿车是由轿车制造商生产的。这在面向对象范型中不是很精确。可以发现,这不是3种标准面向对象关系(使用,包含,继承)之一,但是这两个类之间确实有某种关系。这就是关联关系的一个例子
有几种关联关系:一对一,一对多,多对一以及多对多。此外,关联关系可以是必要的,也可以是可选的。有两种实现关联关系的主要方法,一种是使用引用属性,另一种是使用一个第三方类。第一种方法在设计一对一或者多对一的必要关联关系时很常用。第二种方法则常常用来实现其余关联关系。两种方法都可以用在所有情况,但是对于某种特定的关联类型,两种方法之一较易于实现。
7.2 用引用属性实现关联
因为每辆轿车都只由一家轿车制造商生产(我们退回到30年前,那时轿车零件并不是全球化生产),那么关联的类型就是一对一必要关联。用引用属性来实现是最佳的。这个属性可以是制造商的名字,或者为了提高效率,也可以是指向关联的轿车制造商的指针。在两种情况下,这个属性都是引用属性,具体是哪种情况只是我们不感兴趣的实现细节

在所有的情况下,关联关系都是被某个第三方类使用的,那个类对涉及的两个类会有某种间接的使用关系
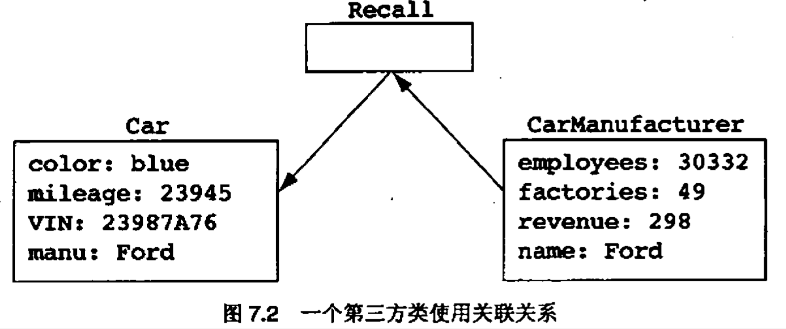
7.3 用第三方类实现关联

不表示使用关系的关联总是意味着某个第三方类希望在间接的使用关系中使用该关联。我们因为特定领域中分布系统功能的要求而创建该第三方类
7.4 在包含关系和关联关系间取舍
经验原则 7.1
在面向对象设计中如果你需要在包含关系和关联关系间做出选择,请选择包含关系

术语表
Associtaion 关联。一种面向对象关系,表明两个类相关,但不是继承,包含或者使用关系
Descriptive attribute 描述属性。一种属性,它的全部用途就是描述属于该类的对象的某些特性
Referentail attribute 引用属性。一种属性,这种属性的用途是允许类的某个对象访问另一个类的某个对象
Simple association 简单关联。 在某些面向对象方法学中用来描述无法归入其他任一种面向对象关系的关联关系
经验原则小结
第8章 与特定类相关的数据行为
8.1 类相关与对象相关数据及行为导引
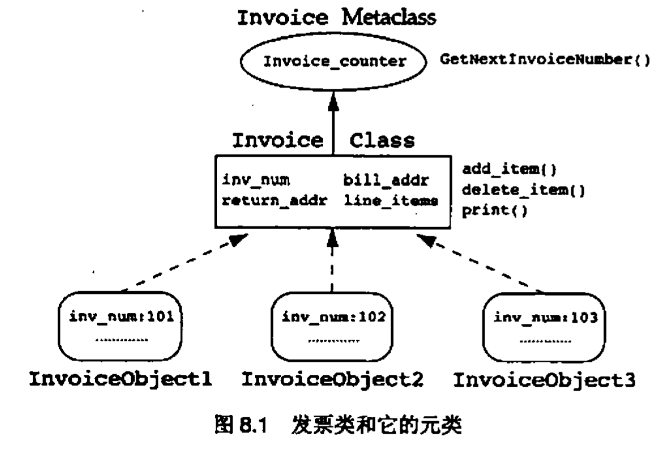
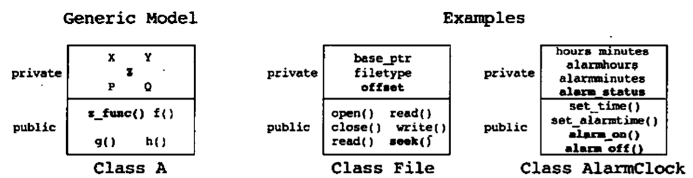
发票计数器是同类相关的数据的一个例子。同类相关的数据经常被叫做类变量。类变量用来存放同类的多个对象相关的信息,而不是同类的一个对象相关的信息。当开发者在类方法中使用全局数据时,他应当判断一下使用类变量是否会更合适
一个同类相关的行为经常被叫做类方法
经验原则 8.1
不要把全局数据或全局函数用于类的对象的簿记工作。应当使用类变量或者类方法
8.2 用元类来表示类相关数据及行为
例如 smalltalk
8.3 用语言层面关键字来实现类相关与对象相关数据及行为
例如 C++

8.4 C++中的元类
所有的C++模板都是元类,但不是所有的元类都是C++模板
8.5 有用的抽象类, 但不是基类

术语表
Metaclass 元类。实例是类的类
经验原则小结
第9章 面向对象物理设计
9.1 面向对象逻辑设计和物理设计的角色
面向对象设计实际上有两个方面:逻辑设计和物理设计。逻辑设计包含了我们已经讨论过的全部东西,包括找出类,类的协议,类之间的使用关系,包含关系和继承关系。简而言之,所有与应用的关键抽象和关键机制相关的东西都可以归入逻辑设计
而物理设计则涉及用来把这些抽象构造映射到软硬件平台的技术。任何基于目标语言,工具,网络及其协议,数据库和硬件的实现细节都可以归入物理设计
经验原则 9.1
面向对象设计者不应当让物理设计准则来破坏他们的逻辑设计。但是,在对逻辑设计做出决策的过程中我们经常用到物理设计准则

9.2 创建面向对象包装器
包装器就是用面向对象风格编写的软件层
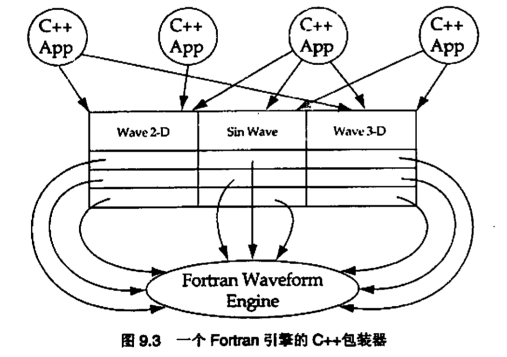

他们的设计没有问题。这只是因为网络不是面向对象的。在任何时候,面向对象应用程序同非面向对象的子系统打交道时,结果常常会出现显式地情况分析
9.3 面向对象系统中的持久化
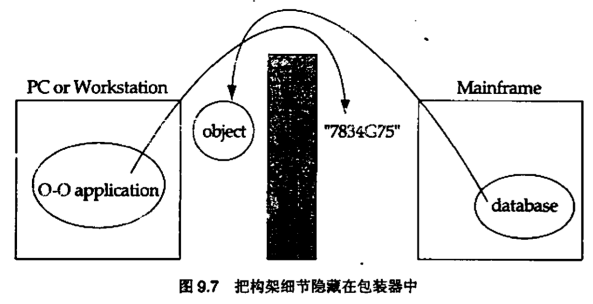
9.4 面向对象应用程序中的内存管理问题
是否有垃圾回收机制
9.5 可复用组件的最小公有接口
构造函数
析构函数
对象复制
对象赋值
相等性检测
输出 所有的类都应当有一个方法知道如何把它的对象以某种格式输出
解析 所有的类都应当有一个解析方法,这个方法知道如何从基于对应的输出方法得到的输出中构造出一个对象
自我测试
9.6 实现安全的浅拷贝
经验原则 9.2
不要绕开公有接口去修改对象的状态
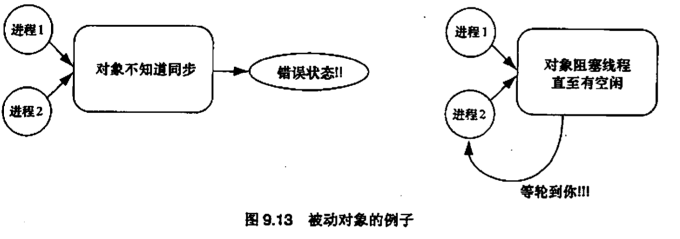
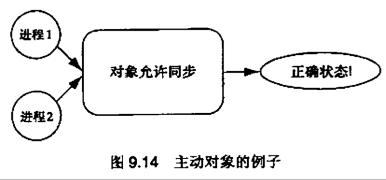
9.7 并行面向对象编程
9.8 用非面向对象语言实现面向对象设计
重载函数
类/对象
数据隐藏
继承
多态
术语表
Active object 主动对象。在多线程控制下依然确保语义的对象
Broadcasting 广播。对象向包含它的对象集合发送消息的行为
CORBA Common Object Request Broker Architecture的缩写。处理面向对象系统如何在不同架构之间分布的构架。该构架是对象管理组织(OMG)开发的
Deep copy 深拷贝。拷贝对象的整个结构,而不是只拷贝它的指针和引用
Local persistence (in time) 局部(时间)持久化。把对象保存到静态媒体的行为。每个类都知道如何保存和获取它的对象
Logical object-oriented design 面向对象逻辑设计。面向对象设计的一方面,负责发现类,它们的协议以及它们相互关系(继承,包含,使用,关联)
OMG 对象管理组织,由很多公司组成的联盟,这些公司都致力于把跨越很多不同开发平台的分布式,持久化的面向对象系统标准化。OMG是CORBA的设计者
Passive objects 被动对象,属于某个类的对象,要么不考虑多线程控制,要么考虑了这个问题并通过阻塞来解决(也就是在一段时间内只允许一个线程控制,强迫其他线程等待)
Persistence 持久化。对象的特性,允许它在电源切断后依然存在
Persistence in space 空间持久化。持久化的一种实现,在这种实现种对象侦知计算机正在关机。就通过网络进入另一台安全的计算机,在那里它们可以继续执行处理,直到它们原本所在的计算机再次启动可用
Persistence in time 时间持久化,持久化的一种实现。在这种实现中对象被保存到某种静态媒体,以使它们将来可以重新加载。这常常意味着使用数据库
Physical object-oriented design 面向对象物理设计。面向对象设计的一个方面,负责处理同软硬件平台相关的问题以及它们对面向对象逻辑设计的影响
Reference counting 引用计数。通过把共享数据同一个整数计数器封装在一起以执行安全浅拷贝的技术。整数计数器维持共享该数据的包含对象的数目
Shallow copy 浅拷贝。只复制对象地址和引用的拷贝操作。原来的对象和它的拷贝共享同一份对象表示
Wrapper 包装器。把应用的一个子系统或者某些实现细节同其他子系统隔离的软件层
经验原则小结
第10章 经验原则和模式的关系
10.1 经验原则与模式

10.2 设计变换模型的传递性
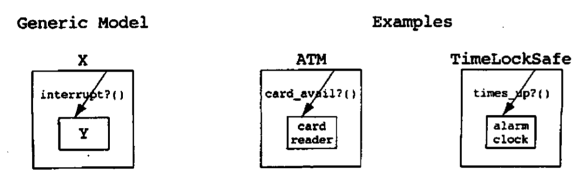
1. Interrupt 模式
若被包含的对象必须向包含它的类发送消息,包含它的类应当通过明智地使用继承来进一步泛化。这样,被包含的对象就不依赖于包含类,而只依赖于包含类的基类。让复用者从某个抽象类继承要比使用某个特定类容易得多(如果必须使用特定类,那么实际上无法在原本的领域之外复用了)
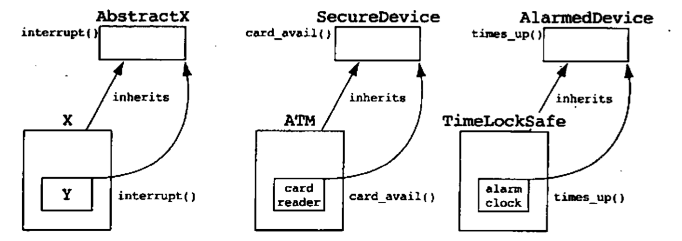
2. Interrupt-Polling 模式
在这种方法中,包含类轮询被包含的发出中断的对象。被包含的对象不依赖于包含它的类,我们就从架构中去除了一个使用关系
10.3 设计变换模式的自反性
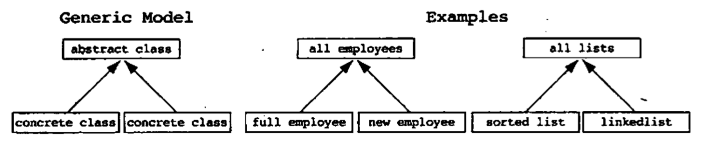
1. Generalization 模式
如果一个类是一个已经存在的具体类的特殊类型,那么它不应该直接从那个类继承。一个更好的架构是让两个类都从一个新的抽象基类继承。用这种方法,如果其中一个类需要扩展,那么改变可以在派生类中实现;如果这两个具体的类都需要改变,那么改变可以在抽象基类中实现
2. Specialization 模式
如果两个类继承自同一个抽象基类,其中一个派生类继承了基类所有的数据和行为,那么就应当重新设计继承层次结构,让第二个派生类直接继承第一个派生类,这样就可以去除抽象基类

10.4 其他设计变换模式
1. Inverted Inheritance 模式

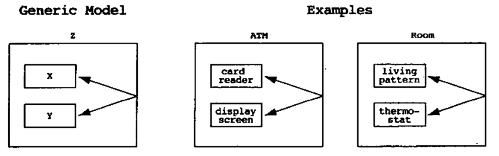
2. Lexical Scope 模式
3. One-Instance 模式
4. Data-Hiding模式
10.5 未来研究
第11章 在面向对象设计中使用经验原则
11.1 ATM问题
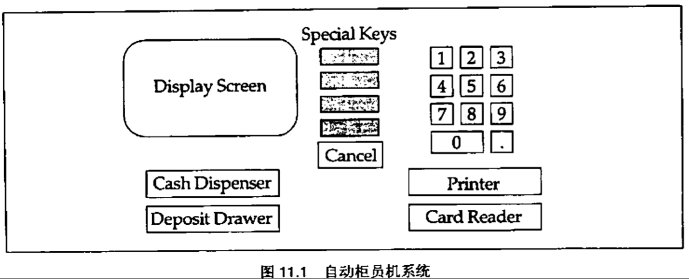
自动柜员机系统需求规约
一台自动柜员机(ATM)是一台机器,银行客户通过这台机器可以执行一系列最常见的金融交易。机器包含一台读卡设备,一个显示屏,一个吐钞口,一个存钞口,一个键盘,还有一台收据打印机
11.2 选择方法学
第一种观点认为,面向对象分析应当是一个数据驱动的过程,在这个过程中开发者检查系统的需求,寻找关联,寻找自然聚合以及继承。系统的行为(就是使用关系)直到设计时才被指定。这种方法的理念是先创建一个完整的对象模型,而不必卷入对行为的指定
第二种观点则基本上是数据驱动建模的对立面,这种观点声称,面向对象分析应当关注系统的行为。设计者应当在分析阶段找出类和它们之间的关系
两种观点都不是整体最优,建议综合使用以上两种方法
11.3 产生ATM对象模型的第一次尝试

11.4 给我们的对象模型增加行为
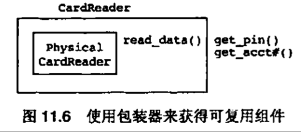
11.5 非根本复杂性带来的显式情况分析
11.6 在不同地址对象间传递消息
11.7 交易处理
11.8 回到ATM的领域
11.9 其他杂类问题
11.10 小结
附录A 经验原则总结
附录B C++中的内存泄露
附录C C++实例精选
本书中引用到的其他图书

参考文献




 浙公网安备 33010602011771号
浙公网安备 33010602011771号