网络游戏核心技术与实战 (中嶋謙互 著)
第0章 [快速入门]网络游戏编程 网络和游戏编程的技术基础 (已看)
第2章 何为网络游戏 网络游戏面面观 (已看)
第3章 网络游戏的架构 挑战游戏的可玩性和技术限制 (已看)
第4章 [实践]C/S MMO 游戏开发 长期运行的游戏服务器 (已看)
第5章 [实践]P2P MO 游戏开发 没有专用服务器的动作类游戏的实现 (已看)
第6章 网络游戏的辅助系统 完善游戏服务的必要机制 (已看)
第7章 支持网络游戏运营的基础设施 架构,负荷测试和运营 (已看)
第0章 [快速入门]网络游戏编程 网络和游戏编程的技术基础
0.1 网络游戏开发者所需了解的网络编程基础
0.1.1 网络编程是必需的
0.1.2 网络编程与互联网编程
为了使运行在两台以上机器的相关进程能够协调工作,必须在它们之间实现一些必要的通信功能,网络编程就是指实现进程间通信所需的编程技术
网络编程的范畴非常广泛.比如,在使用USB接口将外置HDD(Hard Disk Drive, 硬盘驱动器)连接到PC的情况下需要网络编程,因为要使PC上运行的进程与HDD控制器上运行的进程进行通信.再有,SCSI(Small Computer System Interface),红外线通信,以至空调的遥控器等都离不开网络编程
除了任天堂DS之间使用有线连接的情况之外,网络游戏中的网络编程一般只使用与互联网有关的技术.这种互联网方面的通信编程称为"互联网编程"(Internet Programming),在国外有很多这方面的参考资料
实现多人网络游戏的前提就是使用互联网,因此本书只讨论以互联网编程为主的网络编程技术
0.1.3 互联网编程的历史和思想
在互联网通信的事实标准中, IP(Internet Protocol, 网际协议), TCP(Transmission Control Protocol, 传输控制协议), UDP(User Datagram Protocol,用户数据报协议)等网络通信协议自定义以来的三十几年里,基本的通信方式并没有发生什么变化.IP协议等以安全,舒适地使用互联网服务为目的而产生的网络协议,被技术标准化组织IETF(Internet Engineering Task Force,互联网工程任务组)作为基础资料收录在RFC(Request For Comments)中.RFC并不具有法律上的强制力,但是遵守这些标准可以带来经济上的利益,所以很多人都以此为准
RFC以编号排定,比如, TCP是在RFC793中定义的,DNS(Domain Name System, 域名系统)的实现是在RFC 1123中,HTTP(HyperText Transfer Protocol,超文本传输协议)的HTTP1.0则是在RFC 1945中定义的.每次版本更新后,RFC的编号也会随之更新.截至本书撰写时(2010年9月),RFC的文档总数已经超过了6000份
IETF是为了共享通信形式和协议而产生的,它里面并没有定义实际的编程接口,因此要开始网络编程,还必须要进一步掌握一些基础知识
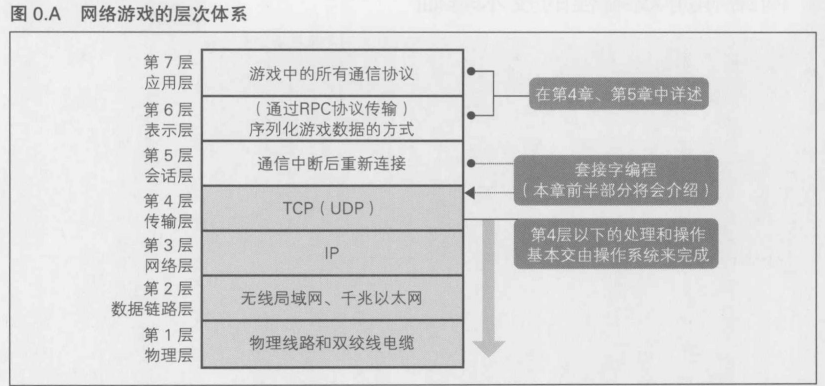
0.1.4 OSI参考模型----透明地处理标准和硬件的变化
- 第7层: 应用层
提供具体的通信服务,比如文件和邮件的传送,访问远程数据库等,这一层的协议包括HTTP,FTP(File Transfer Protocol,文件传输协议)等
- 第6层: 表示层
规定数据的表现形式,比如将EBCDIC表示的文本文件转换成以ASCII码表示的文件
- 第5层: 会话层
规定应用程序之间的通信从开始到结束之间的顺序(在连接中断的情况下,尝试恢复连接)
- 第4层: 传输层
实行网络中应用程序进程之间的端到端的通信管理,如差错恢复,重发控制等
- 第3层: 网络层
对网络中的通信链路进行选择(路由选择),中继
- 第2层: 数据链路层
控制直接相连(相邻)的通信设备之间的信号收发
- 第1层: 物理层
规定物理连接,包括连接器的引脚数,连接器形状等,以及铜缆与光纤之间电气信号的转换等
0.1.5 网络游戏系统及其层次结构
第4层大多使用TCP协议,不需要直接操纵第3层以下的分层
第5层以上的分层需要在游戏中予以实现
0.1.6 套接字API的基础知识
BSD套接字API是为了实现互联网连接而开发的API,它是在所有操作系统(包括嵌入式系统)上进行网络开发的首选.使用TCP/IP(不是BSD套接字)开发的API不胜枚举,但是如今在广泛用于网络游戏的环境上(包括游戏机)全都可以使用套接字API
标准化的C,Java和Ruby,Perl,C#等几乎所有的编程语言都能使用这一API.套接字API在20世纪80年代开始普及,此后基本没有进行过变更,因此当时开发的程序有很多至今仍在照常运行
0.1.7 网络游戏和套接字API----使用第4层的套接字API
专栏 网络编程的特性和游戏架构的关系
那么网络游戏到底需要哪些网络编程技术呢?为了回答这一问题,我们先来简单了解一下网络编程的特性与游戏架构之间的关系.网络编程的特性根据游戏架构的不同而有所差异,作为铺垫.我们以第2章中会讲到的C/S MMO, C/S MO, P2P MO这几种游戏架构为例,看一下它们之间的区别
- C/S 架构的游戏(C/S MMO, C/S MO)
高性能,功能强大的服务器端编程 x 一般的客户端编程
所有的处理都再服务器运行,每台服务器要容纳尽可能多的用户.另一方面,客户端的通信相对比较简单
- P2P 架构的游戏(P2P MO)
一般程度的(Web)服务器编程 x 高性能,功能强大的客户端编程
进行游戏处理的服务器只起辅助作用,由于客户端也要扮演服务器的角色,为此需要在客户端实现支持大量通信量的功能
总而言之,C/S架构的游戏要求编程结构满足"服务器端具有高性能",而P2P架构的游戏则要求"客户端具有高性能"
尽管如此,本书中涉及的一些实时游戏,不管作为服务器端还是客户端,都要求高性能,高功能的网络编程
高性能,高功能服务器的特性----网络游戏所需具备的要素
C/S MMO, C/S MO游戏所要求的高性能,高功能服务器需要具备以下这些特性
- 小带宽
每秒几次至20几次,达到几百位通信量的持续连接
- 极高的连接数
每台服务器需要维持数千至数万个连接
- 低延迟
处理,结果返回的延迟只能在几毫秒至20毫秒以内
- 稳定
服务器端保持游戏状态(Stateful),敌人等可以移动的物体实时地持续行动
Web服务器的特性与此截然不同.所以一般来说,Web系统中使用的编程技术在其他的网络游戏中是不使用的.
高性能,高功能客户端的特性----网络游戏客户端所需具备的要素
另一方面,P2P架构的游戏要求高性能,高功能客户端具备以下特性
- 小带宽
每秒几次至20几次,达到几百位通信量的持续连接
- 连接数少
每个客户端只连接几台机器
- 低延迟
处理,结果返回的延迟只能在几毫秒至20毫秒以内
- 稳定
服务器端保持游戏状态,敌人等可以移动的物体实时地持续行动,此外,画面渲染等非常重要的处理要同时进行
- 多样性
必须应对客户端的各种网络状况
与服务器相比,客户端的连接数较少,但是在进行渲染等重要处理的同时,必须在延迟很低的情况下进行通信,还要应对网络状况的多样性,不管是性能上还是功能上,都需要具备一般的Web服务所不具有的要素
0.2 套接字编程入门----处理多个并发连接, 追求性能
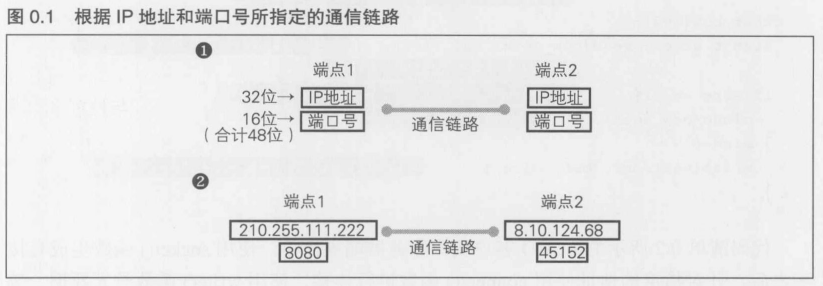
0.2.1 通信链路的确定(复习)
TCP通信链路(面向连接的通信链路)并不是自然发生的,这是建立在一方提出"想要进行连接",而一方接受这一连接请求的基础上.提出"想要进行连接"的这一方称为客户端(client),接受方则称为服务器(server).服务器在接受请求之前,还需要做一些准备工作
IP是由位于通信链路端点的一个IP地址(32位)和一个端口号(16位)来指定的.IP地址和端口号一共有48位,位于通信链路两端的IP信息作为一组,根据这总共96位的信息,可以指定互联网上任意一条通信链路
IP地址是一组32位的数据,使用十进制值来表示就是0.0.0.0~255.255.255.255,接入互联网的Web服务器需要一个固定的IP地址,这是在国际规定下获取的
另一方面,16位的的端口号可以由服务器的实现者酌情决定,但是有些端口号已经被使用了,比如HTTP所使用的80端口号这种公认端口号(WELL KNOWN PORT NUMBER, 经常被使用的端口号)和注册端口号(REGISTERED PORT NUMBERS, 已经等级过的端口号),这些端口号都可以在IANA(Internet Assigned Numbers Authority)的端口表中进行确认.此外,在Linux和FreeBSD,Mac OS X 等基于Unix的系统中,在etc/services文件里包含这些端口号的子集.根据这一点,我们可以使用如下命令来指定端口号
shell> telnet localhost hptt <-与 tlenet localhost 80 相同
0.2.2 套接字API基础----一个简单的ECHO服务器, ECHO客户端示例


ECHO 服务端 int sock = socket(PF_INET, SOCK_STREAM); 指定类型 bind(sock, addr); 设置监听端口号 listen(sock); 监听开始.待机中 while (1) { int new_sock = accept(sock, &addr); 在新的连接请求到来之前一直"等待"(阻塞) char buf[100]; size_t size = read(new_sock, buf, 100); 在读满最大的100字节之前一直等待 if (size == 0) { 如果read函数返回了0,意味着接收到了EOF close(new_sock); } else { write(new_sock, buf, size); } } ECHO 客户端 int sock = socket(PF_INET, SOCK_STREAM); 生成新的套接字 connect(sock, addr); 使用生成的套接字 while (1) { write(sock, "ping"); char buff[100]; read(sock, buf, 100); }
0.2.3 TCP通信链路的状态迁移和套接字API
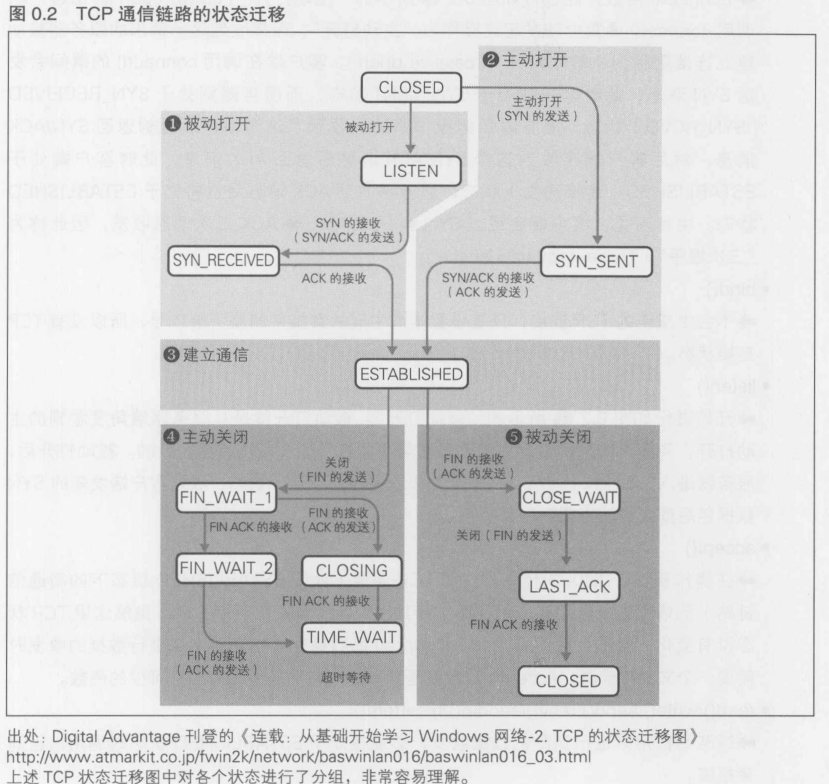
- socket()
因为还不会生成新的TCP连接,所以还不存在TCP连接状态
- connect()
connect()函数开始进行如图(2)所示的"主动打开"(active open).由客户端调用connect()函数主动发起连接称为"主动打开",而接收到这一请求的服务器被动建立连接则称为"被动打开"(passive open).客户端在调用connect()的瞬间会发送SYN消息,此时客户端处于SYN_SENT状态,而服务器则处于SYN_RECEIVED(SYN_RCVD)状态.服务器端的操作系统在收到了这个消息后立刻返回SYN/ACK消息,然后客户端在收到这个SYN/ACK消息h后返回ACK消息,此时客户端处于ESTABLISHED(连接建立)状态,服务器收到ACK消息后也将处于ESTABLISHED状态.由此可见,客户端会经过 SYN->SYN/ACK->ACK 三次消息收发,因此称为"三次握手"(Three-way handshake)
- bind()
不会生成新的TCP连接,只是设置本地生成的套接字的监听端口号,所以没有TCP连接状态
- listen()
开始进行如图(1)所示的"被动打开".被动打开就是从服务器端角度看到的主动打开,实际上这里的数据包流动顺序与主动打开的顺序是完全一致的.被动打开后,服务器进入LISTEN(待机)状态.如果服务器处于这一状态,收到客户端发来的SYN数据包后就会开始生成新的套接字
- accept()
在操作系统(UNIX内核)建立了TCP连接(处于ESTABLISHED状态下的新通信链路)的情况下,我们在应用程序中将其作为新的套接字获取下来.虽然这里TCP状态没有变化,但是之后使用read()和write()函数通过连接套接字来进行数据的收发时需要一个文件描述符,accept()函数就是获取这个文件描述符的必不可少的函数
- read()/write()/send()/recv()/sendto()/recvfrom()
这些函数用来进行实际的数据收发,必须在处于ESTABLISHED状态时调用,否则会报错
- shutdown()
通知操作系统不要再进行数据的写入和读取了.当在参数中指定了SHUT_RD停止数据读取时,本地的状态就发生了变化,不再是可读取的状态了,所以会话状态也就不会变化了;而在指定SHUT_WR通知操作系统不再向其发送数据(写入数据)的情况下,就会开始关闭套接字,这样,如图(4)所示的"主动关闭"流程就开始了.主动关闭与主动连接不同,服务器端和客户端都可以发起.如果再次进入ESTABLISHED状态,客户端和服务器的处理都是相同的
在主动关闭的过程中,首先从SHUT_WR侧发送FIN数据包,接收方(被动关闭的一方)会立刻返回FIN,然后进入CLOSE_WAIT状态.SHUT_WR侧一旦接收到这个FIN消息就立刻发送FIN/ACK消息,然后释放通信链路.被动侧接收到FIN/ACKh后也同样关闭通信链路.这个关闭过程也需要三次握手
- close()
等同于调用shutdown(SHUT_RD|SHUT_WR)来同时关闭读写双方
0.2.4 处理多个并发连接----通向异步套接字API之路
从现在开始就要进入本章的核心内容了.代码清单0.1所示的ECHO服务器存在一个很大的缺陷.由于accept()函数在"新的连接请求到来前一直等待着",所以read()函数在接收新的连接请求前不会再被第2次调用.这就导致为了调用read()函数,必须每次接收新的l连接
此外还有一个问题.read()函数在客户端发来数据之前也会"等待",所以在开始读取数据前,accept()函数也不会调用第2次,也就是说,在接收了客户端发来的一次新的连接请求后,在数据到达之前无法再接收其他连接请求
为多个客户端同时提供服务的网络游戏在这种情况下是不可能实现的.为了解决这个问题,必须要处理多个并发连接,为此,需要同时控制多个套接字.方法大致有如下这些.
- 每次连接时启动一个进程
- 实行异步的多重输入输出(多重I/O)
- 使用线程并行进行同步处理
虽然在inetd(Internet超级服务器)和从很早开始就在Web使用的CGI(Common Gateway Interface, 通用网关接口)中都采用了方法1,但是在网络游戏中,需要多个用户(连接)实时共享同一个游戏状态,所以不能使用这种方式.可以在方法2和方法3中选择
0.2.5 同步调用(阻塞)和线程
套接字API的connect(), accept(), read()函数在处理成功之前会一直处于等待状态,而其他函数则不会等待,而是立刻返回(在几微妙时间内).通常,像这种同步调用connect(),accept()和read()这类"永远等待着"的函数称为"阻塞"(Blocking)
处理这种情况的方法一般是使用线程(Thread).使用线程的示例如代码清单0.3所示.它与代码清单0.1的不同之处在于, read()和write()函数的反复调用是在create_thread中并行执行的
int sock = socket(PF_INET, SOCK_STREAM); bind(sock, addr); listen(sock); while (1) { int new_sock = accept(sock, &addr); create_thread( { char buf[100]; size_t size = read(new_sock, buf, 100); if (size == 0) { close(new_sock); } else { write(new_sock,buf, size); } }); }
根据代码清单0.3中的多线程,我们可以实现向多个客户端同时提供服务(这里是返回数据).使用线程可以同时处理多个"等待"场景.从结构上来看,同步调用是在多个线程的内部并行执行的
线程方式下的负载处理问题
上述的线程方式在网络游戏的服务器中存在"负载处理"问题.在每次创建线程时都会启动1个线程和进程,如果同时连接数为3000,就会同时启动3000个线程,对现在的机器来说,3000个并行处理数实在太过庞大,服务器的性能会大幅下降
活跃进程一般要控制在操作系统能够同时执行的进程数或线程数的4到10倍以内
如果超出了这一范围,操作系统内部进行线程切换的开销就会变得很大.比如,4核处理器下的最佳线程数是十几个.3000个线程实在太多了,但是考虑到服务器成本,每台机器又不得不处理3000个左右的并发连接
0.2.6 单线程, 非阻塞, 事件驱动----使用select函数进行轮询
在实际调用read函数和accept函数之前,我们可以使用select函数事先查询一下这些函数所等待的消息(数据以及连接请求)是否已经到达了.这种事先询问的方式称为轮询(Polling).根据操作系统的版本,使用poll函数及更高速的epoll函数等多种接口都能实现同样的功能
代码清单0.4展示了使用select函数的服务器端代码.在实际的服务器上运行的代码需要进一步设置标志和定义结构体,等等,但是基本的逻辑结构是相同的
代码清单0.4在调用accept()和read()之前,为了确定该套接字所需处理的事件(数据)是否到达而调用了select()函数.这样,read()和accept()函数就可以在几微妙内返回并且获取到数据.实际上,select()h函数不会像这样调用多次,调用一次就能一下子确认几千个套接字
代码清单0.4中的代码与代码清单0.3的差别就是没有创建线程(单线程)就向多个客户端多重话化地提供了服务.这种实现方式称为异步调用,非阻塞(Non-blocking)方式.另外,因为这种方式会事先查询数据到达这一事件是否发生,然后再调用相关函数,所以也叫做事件驱动(Event-driven)
int sock = socket(PF_INET, SOCK_STREAM); bind(sock, addr); listen(sock); allsock.add(sock); 向allsock队列注册sock while (1) { result = select(sock); 插入select函数进行事先检测 if (result > 0) { int new_sock = accept(sock, &addr); allsock.add(new_sock); 向allsock注册新的连接 } foreach (sock = allsock) { result = select(sock); 插入select函数进行事先检测 if (result > 0) { char buf[100]; size_t size = read(new_sock, buf, 100); if (size == 0) { close(new_sock); } else { write(new_sock, buf, size); } } } }
0.2.7 网络游戏输入输出的特点----单线程, 事件驱动, 非阻塞
在游戏编程中,同时处理数千个可移动物体是很平常的,这与"使用1个线程处理数千个套接字"类似.为此,在网络游戏中,客户端和服务器端通常都使用select函数(或者poll/epoll函数)在单线程中实现非常简单的事件驱动的非阻塞方式
0.2.8 网络游戏和实现语言
0.2.9 充分发挥性能和提高开发效率----从实现语言到底层结构

网络游戏中的特殊性所造成的编程语言性能差异
表0.1中,Java的吞吐量比C/C++低了10倍,这是由于网络游戏的特殊性所造成的.一般在配备了JIT(Just In Time)编译器的虚拟机(Virtual Machine, VM)中,Java的运行速度会因JIT编译的效果变得很快,某些情况甚至会比C语言更快
但是这种效果只发生在以CPU为中心的应用程序中,而在那些与操作系统频繁进行输入输出操作的应用程序中无效.比如,在一个对100MB的文件进行读取,每次读取1KB并对行数进行计数的程序中,C语言都要比Java快上10倍左右的情况也是常有的.这是因为Java VM在系统调用前后,每次都会进行缓存溢出和异常对象的处理.这是无法省去的处理过程,所以使用VM的处理系统存在一定的局限性.网络游戏的服务器每秒会进行数万次输入输出,这是Java和C语言产生速度差异的典型例子.Apache和MySQL等服务器软件都用C/C++编写也是基于同样的原因
其次,动态语言的吞吐量比起Java更是低了10~100倍,为什么会这样呢?这是因为每次进行一些处理时,对象调用的方法可能会发生变化,所以每次都必须进行检查确认
顺带提一下,Google的Go语言是一种静态的,本地执行的语言,它具有垃圾回收机制,程序员可以在代码的不同部分中选择类型化的强度,既不牺牲服务器的性能又可以提高开发效率,笔者对此十分期待.让人不禁感叹Google对服务器开发确实颇为了解
0.2.10 发挥多核服务器的性能
通过单线程,事件驱动和非阻塞的实现,就可以充分发挥出多核服务器的性能
举例来讲,在CPU只有一个处理核心的情况下,不可能同时执行多个线程或进程,而是为每个线程或者进程划分一小段时间片,轮流执行.例如,如下所示暂停1毫秒的程序:
while (1) {
usleep(1000);
}
如果有两个这样的程序同时运行,那么1秒内要切换1000次.由于要从进程A切换到进程B,又要从进程B切换到进程A,每秒总共要切换2000次.这里的切换次数可以在Linux上用vmstat命令来确认
上下文切换----保存CPU的设置状态
上文提到的"切换"称为"上下文切换"(Context Swtich),在进行上下文切换时,CPU核心内部将执行注册(Register),保存虚拟内存(Virtual Storage)的管理表以及安全性设置的切换等.至笔者撰稿时,在Linux上,平均每个CPU内核一秒内可以执行10万~20万次上下文切换.这也与CPU的高速缓存内容等应用程序的执行情况有关,这一点需要注意,但是,比如前文中提到过的那个暂停1毫秒的程序,如果运行了200个左右的程序,仅仅是上下文切换大约就会使当前时间CPU的系统占用率(由vmstat命令获得当前的时间的CPU统计信息)达到100%
上下文切换要处理CPU设置状态的保存工作,CPU内核多的话,整个系统每秒能执行的次数也会增加.比如,在拥有10个CPU内核的机器上执行同样的任务,基本上可以进行100万~200万次上下文切换
因为一个内核的处理能力已经达到极限,而内核的处理也已达到了最优化,所以在今后的机器中,一个内核所能进行的上下文切换次数与上面给出的值相比,很有可能不会发生很大的变化了
多核处理器上不要运行过多的服务器进程
在网络游戏的服务器上实现单线程,事件驱动,非阻塞的情况下,如果服务器的每个内核运行1个进程,就能充分利用多核处理器的性能
上下文切换在针对网络的输入输出中也是必须的.假设1个内核可以执行10万次上下文切换,那就可以进行10万次网络输入输出.平均每个内核能有1000个同时连接数的话,每秒就可以进行100次输入输出,通常,每秒的输入输出只有几次的程度,可以说非常宽裕.因此,多核服务器中,服务器进程只要不增长过多的话就不会有问题
0.2.11 多核处理器与网络吞吐量----网络游戏与小数据包
服务器通常使用以太网[或许是千兆以太网(1 Gbit Ethernet)]连接至数据中心内的网络中.现在在Linux中,以太网在基础设施层次中可达到其名所示的速度.也就是说,千兆以太网的通信速度就是1Gbit.交换集线器也可以应对这一速度
但是,网络游戏中发送大量小数据包的情况下,有时也会无法达到预期的通信速度
以太网帧
首先,以太网在发送IP数据时,会向数据包中添加IP数据以外的信息一起发送.包括这些附加信息在内的总带宽是1Gbit/s,实际上应用程序能够使用的带宽比这要小
比如,在Windows中使用telnet命令连接TCP服务器,按下A键就会发送"a"这个1字节的数据.此时,以太网实际消耗的带宽是多少呢?在最典型的以太网中,发送数据包时会发送图0.3所示的信息
在图0.3中,(1)中的(7)表示7个octet.octet的意思是"8位位组".因为有一部分机器"一个字节(byte)不等于8位(bit)".这样就不能用bit来进行划分,所以在严格定义通信方法的情况下都使用octet这个单位
"a"这样的一个字符可以用1octet来表示,用16进制来表示就是0x61,2进制表示就是8位的01100001

图0.3中(1)(2)所示的开头7octet的"前导码信号"(Preamble, 同步信号)和其后1octet的SFD(帧首定界符, Start Frame Delimiter)总是固定的(最后的1连续重复了2次)
1010
这是一种为了从流入电缆的噪声中找出通信信号的固定型号.这会持续长达64bit的时间(虽说这是微秒以下的单位),所以以太网的转换器可以由此分辨出噪声和信号
在图0.3中(3)(4)中,接收方和发送方的MAC地址各有6octet,总共12octet.MAC地址是分配给与以太网连接在一起的所有设备的一个数值,由每个设备厂商进行分配
接下来,(5)用2 octet来指定数据的长度和类型,(6)是数据本身,最后(7)是4octet的FCS(Frame Check Sequence,帧检验序列,用于修正信号错误的总和检验码)
各个网络层的头信息
使用TCP协议发送数据时,也会同时发送以太网帧头信息以外的一些头信息.在使用TCP发送"a"这样1octet数据时,在OSI参考模型的层次结构中会用到以下4个下层系统
- 第4层(传输层): TCP
- 第3层(网络层): IP
- 第2层(数据链路层): 以太网协议
- 第1层(物理层): 双绞线电缆
因为采用了层次结构这种方式而不是直接利用以太网,即便更上层的系统要使用不同的物理媒介(比如Wi-Fi和3G网络等)来进行通信,也不需要修改程序.为了享受到这一优势,必须要向各个层添加必要的头信息
具体来说就是加上第4层TCP的头信息(20 octet),第3层IP的头信息(20 octet)和以太网的帧头信息和帧尾信息(22 octet)
TCP头如图0.4所示,必须包括源端口号(16位,2octet),目的端口号(16位,2octet),序列号(32位,4octet),ACK序列号(32位,4octet),标志(代码位),窗口大小,(数据的)校验位,紧急标志等20octet

IP头如图0.5所示.图0.5的前3行( x 4 = 12 octet)包括版本号(4位),头部长度(4位),服务类型(8位),数据包长度(16位)等各种通信设置.紧随其后的是32位的源IP地址和目的IP地址.至此为止的5行20octet是IP报文必须包含的内容.图中IP报文的"数据"部分放入了TCP头所包含的数据,而TCP的"数据"部分则放入了"a"这个应用想要发送的数据
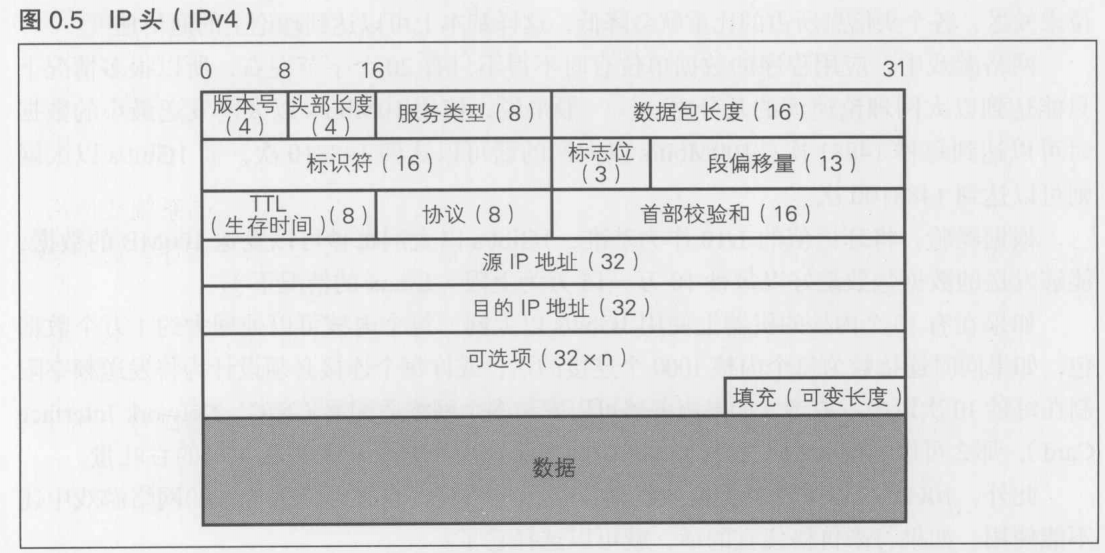
由此可见,为了发送"a"这个1 octet的数据,需要用掉如下这些 octet
- TCP: 总共21 octet
头: 20 octet
数据"a": 1 octet
- IP: 总共41 octet
头: 20 octet
数据(TCP的部分): 21 octet
- Ethernet: 总共67 octet
前同步信号: 7 octet
SFD: 1 octet
接受方: 6 octet
发送方: 6 octet
长度: 2 octet
数据: 41 octet(IP的部分)
FCS: 4 octet
可以看到,传输"a"总共需要耗费67 octet.假设使用1Gbit/s以太网,应用程序每次发送1字节的数据,实际可能用到的带宽为1Gbit/s的1/67,大约是1.5Mbit/s
多核处理器的数据传输能力
如上所述,使用OSI参考模型时,如果将数据分成非常小的数据块来发送.头信息就会占据很大一部分,对物理层来说负担非常大.相反,如果以1400字节的大数据为单位来发送,各个头信息所占的比重就会降低,这样基本上以达到理论上的通信速度
网络游戏中,应用程序的数据单位有时不得不只有20个字节左右,所以很多情况下只能达到以太网理论速度的几分之一.一般来说,使用10Mbit/s以太网发送最小的数据时可以达到每秒14881次,100Mbit/s以太网的话以达到148810次,而1Gbit/s以太网则可以达到1488100次
根据经验,将理论值的1/10作为基准,1Gbit/s以太网每秒可以发送100MB的数据,能够发送的数据包最好以每秒10万~15万为上限(Linux的情况下)
如果在有10个内核的机器上使用1Gbit/s以太网,每个内核可以处理大约1万个数据包,如果同时连接数为每个内核1000个连接的话,或许每个连接必须设计为将发送频率限制在每秒10次以内.或者,如果服务器可以安装多个网络适配器(NIC, Network interface Card),那么可以连接4根LAN(Local Area Network)电缆,以实现4倍的吞吐量
0.2.12 简化服务器实现----libevent
最后,我们l来了解一下服务器实现的简化.在"单线程+事件驱动+非阻塞调用"模式下,实现服务器的最佳程序库是libevent. libevent是从文件共享软件Tor派生出来的库,在memcahed等系统中也有使用,在追求与网络游戏的服务器和客户端系统同等服务性能的网络服务器软件中,它被持续使用长达5年以上
libevent在全世界的网站中都有运用,不管是性能方面还是稳定性方面都很成熟.尽管如此,libevent在实际用于商业服务时,在嵌入到游戏服务中后,应该进行并入单独的游戏内容中的负载测试
libevent的特点
使用libevent时需要注意以下关键点
- 如果套接字处于某个指定状态时(可以write,可以read,可以accept),调用事先指定的函数
- libevent库会自动选择各个OS中最高效的方法(比如,在Linux中当套接字数量很多时,选择epoll函数等)来轮询套接字的当前状态
- 应用程序用事先设置的函数调用(称为回调函数)来获取这一结果,在这回调函数中实际执行read,accept等本来应该在等待的函数
0.3 RPC指南----最简单的通信中间件
0.3.1 通信库的必要性
0.3.2 网络游戏中使用的RPC的整体结构
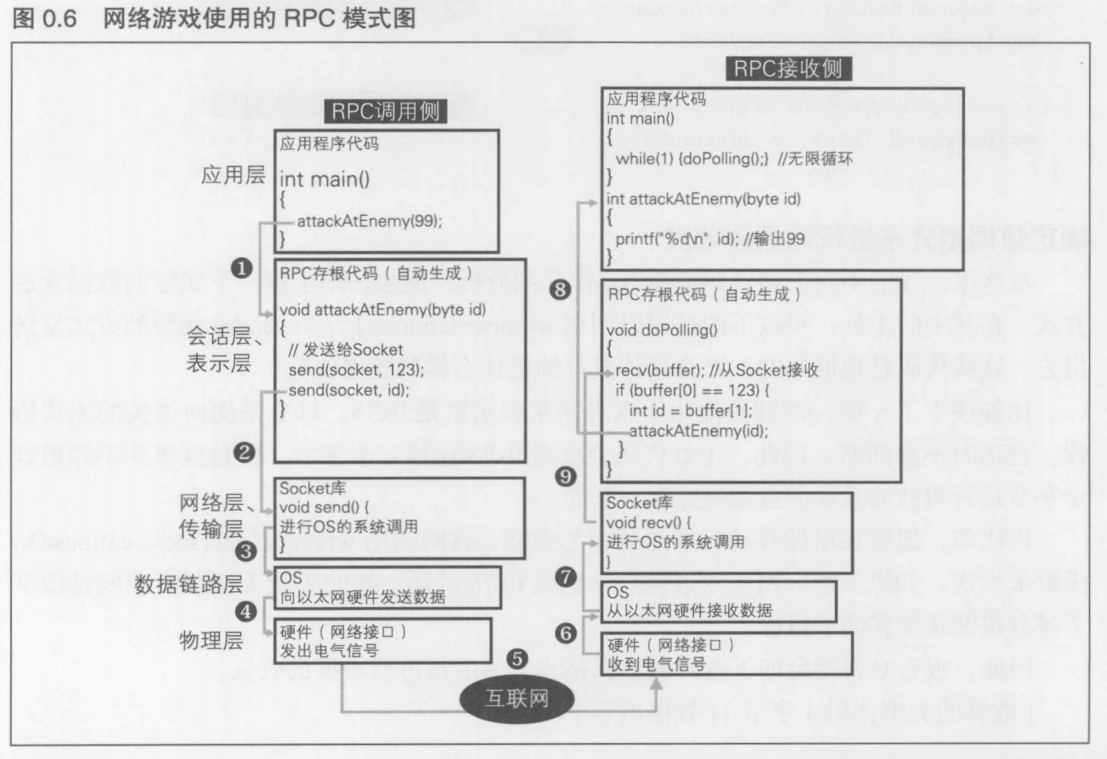
0.3.3 [补充]UDP的使用
0.4 游戏编程基础
0.4.1 游戏编程的历史
0.4.2 采用"只要能画点就能做出游戏"的方针来开发入侵者游戏
0.4.3 游戏编程的基本剖析
定义画面大小 #define WIDTH 256 #define HEIGHT 256 定义出场的图像编号(类别ID) enum { MYSHIP = 0 己方战机 INVADER = 1, 敌对的入侵者 MISSILE = 2, 己方子弹 BULLET = 3, 敌方子弹 }; (以下待续) class Sprite { public: int img; 图像编号(MYSHIP, INVADER, MISSILE, BULLET) int x,y; 当前位置的坐标(单位为像素) int dx, dy; 行进方向, 前进1帧(单位为像素) 构造函数 Sprite(int x, int y, int img) { this->x = x; this->y = y; this->img = img; this->dx = this->dy = 0; } 移动1步 void move() { this->x += this->dx; this->y += this->dy; } 碰撞检测,范围为8像素 bool hit(Sprite *sp) { if (!sp) return false; return (this->x + 8 > sp->x && this->y + 8 > sp->y && sp->x + 8 > this->x && sp->y + 8 > this->y); } };
初始化
int main() { int i, j; Sprite *myship = new Sprite(WIDTH/2, HEIGHT*0.8, MYSHIP); Sprite *missile = 0; #define NUM_INVADERS(12 * 5) Sprite * invaders[NUM_INVADERS]; for(i = 0 ; i < 5; i++) { for (j = 0; j < 12; j++) { invaders[i * 12 + j] = new Sprite((WIDTH / 12) * j, (HEIGHT/10) * i); } } #define NUM_BULLETS 10 Sprite *bullets[NUM_BULLETS]; for (i = 0; i < NUM_BULLETS; i++) { bullets[i] = 0; } }
无限循环
while (1) { int key = getKey(); if (key & 0x1) { myship->dx = 1; } else if (key & 0x2) { myship->dx = -1; } else if (key & 0x4) { if (missile == 0) { missile = new Sprite(myship->x, myship->y, MISSILE); missile->dy = -1; } else { myship->dx = 0; myship->dy = 0; } } }
各个Sprite的行为----游戏逻辑主体
myship->move(); if (missile) { missile->move(); if (missile->y < 0) { delete missile; missile = 0; } } for (i = 0; i < NUM_BULLETS; i++) { if (bullets[i]) { bullets[i]->move(); if (bullets[i]->hit(myship)) exit(0); if (bullets[i]->y > HEIGHT) { delete bullets[i]; bullets[i] = 0; } } } for (i = 0; i < NUM_INVADERS; i++) { if (invaders[i]) { invaders[i]->move(); if (invaders[i]->hit(missile)) { delete invaders[i]; invaders[i] = 0; } if ((random() % 10000) == 0) { for (int k = 0; k < NUM_BULLETS; k++) { if (bullets[k] == 0) { bullets[k] = new Sprite(invaders[i]->x, invaders[i]->y, BULLET); bullets[k]->dy = 1; break; } } } } }
绘制
全部清除后进行绘制 clearScreen(); drawSprite(myship); drawSprite(missile); for (i = 0; i < NUM_INVADERS; i++) { drawSprite(invaders[i]); } for (i = 0; i < NUM_BULLETS; i++) { drawSprite(bullets[i]); } } }
子过程
Sprite 的大小为8x8.用64个字符来定义图像 char imaged[BULLET + 1][] = { "", myship "", invader "", missile "" bullet }; int imageColor[BULLET + 1] = { 3, myship为绿色 1, invader为白色 1, missile为白色 1, bullet为白色 } void drawSprite(Sprite *sp) { int i, j; if (!sp) return; char *toDraw = imageData[sp->img]; int col = imageColor[sp->img]; for (i = 0, i < 8; i++) { for (j = 0; j < 8; j++) { point(sp->x + j, sp->y + i, toDraw[i * 8 + j] * col); } } } void clearScreen() { int i, j; for (i = 0; i < WIDTH; i++) { for (j = 0; j < HEIGTH; j++) { point(i, j, 0); } } }
0.4.4 游戏编程精粹----不使用线程的"任务系统"
0.4.5 两种编程方法的相似性----不使用线程
0.5 小结
专栏 确保开发效率和各平台之间的可移植性
网络游戏的开发中,也有以Linux服务器作为主要目标的云基础服务(IaaS, Infrastructure as a Service),正式服务器的运行环境平台集中在Linxu的Red Hat Linux和CentOS系统.另一方面,客户端的平台环境则非常多样,包括iPhone,Web浏览器,Windows,Android,移动电话,游戏机等
提高开发效率
为了提高开发效率,这里在平台方面提出两点主要要求
正式服务器采用Linux操作系统,但开发环境则是在Windows下使用Visual Studio以高效地进行开发
服务器端和客户端在碰撞检测等方面使用相同的游戏处理代码
这两点都与"同一个程序要在不同的操作系统上运行,即确保可移植性"这一要求联系在一起
同时,这也要求在C/S MMO中,服务器端和客户端使用相同的编程语言.也就是说,客户端和服务器端双方都要使用C,C++或者Java编写.顺带一提,现在这种情况下能够选择的编程语言只有C,C++或者Java,但是将来,C#,Objective-C和Go语言等也极有可能加入这一行列,轻量级语言和node.js等也是有力的候选语言
P2P MO游戏不包含服务器,所以一般不需要满足这些要求
使用封装保持源代码级的兼容性
除了为了实现画面渲染,声音输出,键盘和鼠标输入,触屏,视频输出等客户端用户体验的功能,在使用C/C++的情况下,现在通过简单的封装就能保证源代码级的兼容性.这种封装自然是在通信中间件的层次上实现的
降低OS差异性的封装工作
为了降低OS的差异性,需要对以下这些方面进行封装
- 内存管理
malloc几乎在所有的系统都会使用,所以很容易进行封装
- 套接字API
Windows与Unix系统(包括iOS)中,套接字API的方法有所不同,所以需要将函数全部封装
- 线程
将pthread的基本API进行封装就足够了.线程的使用部分限定在客户端中,调度标志等细微部分在每个操作系统中都不兼容,就像本书建议的那样,不要使用多个线程,使用单线程来实现服务器端就不会有问题.在完全不使用线程的情况下,不需要与服务器端共享源代码,所以也需要进行封装
- 信号
远程管理服务器的情况下需要使用信号,而这是一种可移植性很低的方法,所以并不推荐.实现工作再TCP之上的HTTP服务,再通过套接字来实现服务的停止具有更高的可移植性
- 事件与计时
使用本书介绍的libevent,可以有效地进行封装,性能非常高
基本上以接近POSIX(Portable Operating System Interface of Unix,可移植操作系统接口)标准来进行封装,可以降低整体的工作量
第1章 网络游戏的历史和演化 游戏进入了网络世界

1.1 网络游戏的技术历史
1.1.1 网络游戏出现前的50年
1.1.2 20世纪50年代前: 计算机诞生
1.1.3 20世纪50年代: 早期的电子游戏
世界上最早的电子游戏OXO是使用设立在英国剑桥大学的第一台计算机EDSAC开发的.该游戏使用CRT(阴极射线管)显示器,这是个如其名的OX游戏.OXO游戏是玩家与计算机进行1对1对局的单人"完全信息博弈"型游戏
1958年,布鲁克海文国家实验室(Brookhaven National Laboratory)为了让来访的客人消磨时间,制作了一款名为《双人网球》(Tennis For Two)的双人游戏.这是最早的多人游戏.该游戏的特点是: 他不是在计算机上开发的,而是仅仅使用模拟电路制作出来的.在游戏中可以看准时机使用专门的开关来打开,关闭电流,同时还能使用把手调节击球的角度
《双人网球》的玩家数为两人,在游戏中,双方玩家需要把握时机将球打向对方,双方分别在球桌的两端击球,同时注意不要把球打到球网上.这一规则非常简单,人们理解起来毫不费力,所以在这个游戏中并没有加入胜负判定,因为人们可以自己来判定胜负
当时,不管是否使用了计算机的电子游戏,只要是用了CRT示波器的设备,就常会使用多个发光二极管,通过控制其明暗来输出逻辑状态
此外,在20世纪50年代已经开始出现了一些重要术语.
1.1.4 20世纪60年代: 各种颇具影响的机器登上历史舞台
1960年,对后来的电子游戏产生重大影响的两款商用机器开始发售,那就是DECPDP-1和教学用的PLATO

首先来看一下PDP-1.这款机器拥有9KB以上的内存和200KHz的时钟速度,就当时来说,它的处理性能十分强大.PDP-1的设计思想发挥了非常大的作用,在整个计算机历史上留下了重要的一笔.另一方面,当时其他很多计算机的价格都超过了100万美元,而整套PDP-1才12万美元,相对来说非常廉价,但是这款机器只制造了50多台就停止生产了,在商业上并不成功
PDP-1可以高速处理sin(),cos()这列类算术函数.1961年,麻省理工学院计算机科学专业的3名研究人员Peter Samson, Dan Edwards和Martin Graetz运用PDP-1的处理能力开发了一款单人射击游戏《空中大战》(Spacewar!,参见图1.2),游戏中的玩家需要躲避漂浮在宇宙中的敌人,同时发射导弹击倒敌人.《空中大战》与如今使用操作杆等设备进行操作的游戏有着基本相同的外观和感觉,它成为了最早可供多人进行的游戏

接着是PLATO(Programmed Logic for Automatic Teaching Operation),它是伊利诺伊大学(University of Illinois)开发的用于教学的计算机.虽然在商业上并不成功,但它引入了分时系统等先进功能,以大学为中心进行销售,最终售出了1000台以上的终端.之后,世界各地的学生们使用PLATO开发了各种各样的游戏.
PLATO系统在1960年到1970年,经过了多次版本更新后确定了最终的形式.最早的版本是安装在由伊利诺伊大学开发,名为ILLIAC I的具有高达5吨的电子管计算机上的,并配备了显示设备.最初的设计目的是为了实现"跳过课题布置进行计算练习".1961年,PLATO的第二个版是为了让两名学生能够同时进行计算练习
之后,PLATO仍在继续更新版本.1967年,PLATO 3 在CDC 1604计算机(由日后创立了专门生产超级计算机的Cray公司的Seymour Cray研发)上,实现了能够让20个人同时进行计算练习的功能,此外还使用了称为TUTOR的语言处理系统,老师们不仅能提供计算练习,还能使用图像和文字自由编写学习教材.在学校让多名学生同时或者非同时进行计算练习,这一要求在当时的其他计算机系统上是无法实现的,这成为了引入分时系统的重要契机
另一方面,在1957年,前苏联发射了人造卫星伴侣号(Sputnik 1),成功围绕地球轨道航行. 美国受此冲击,为重获优势地位,他们认为应该对能够高度应对攻击的信息通信技术进行大规模投资,为此将分组通信(Packet Communication)和分组交换技术联系在了一起
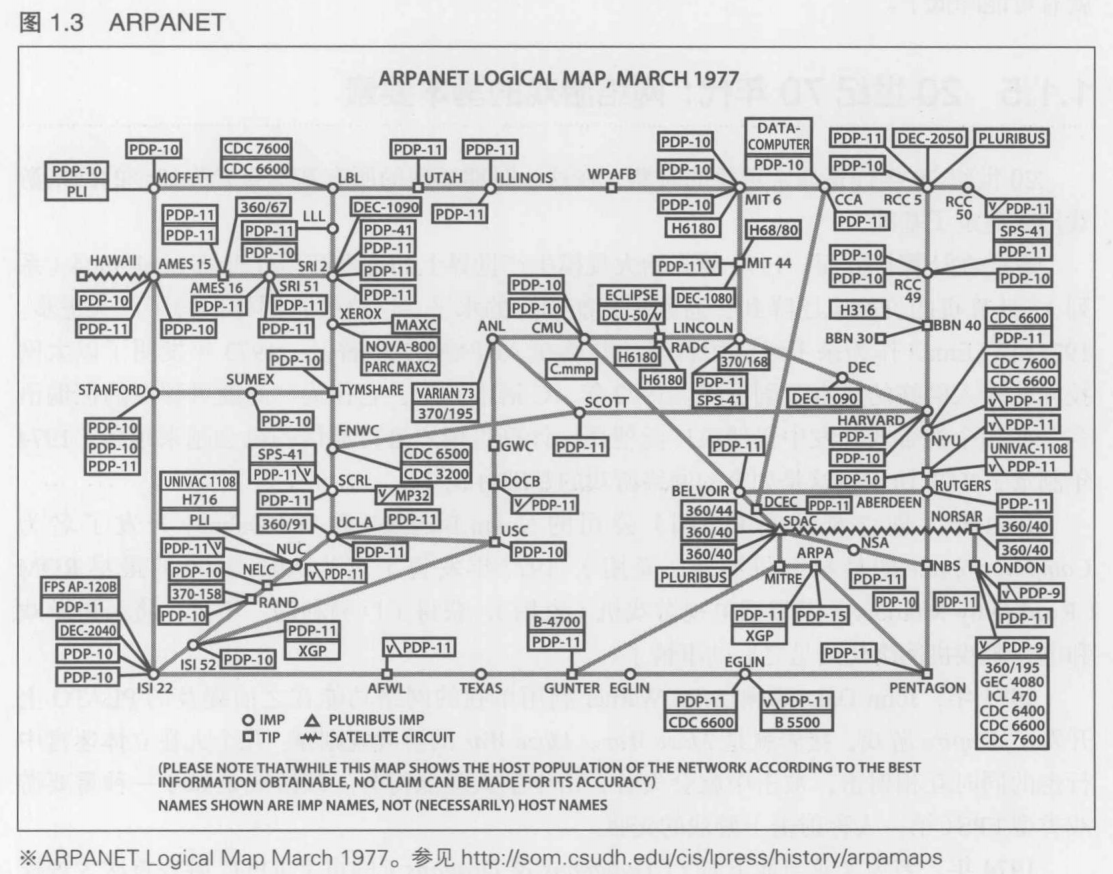
由此研发了计算机网络ARPANET, 1969年,美国国防部开始投入使用.当时只在非常重要的国防要地设置了4台计算机,以50kbit/s 的速度将它们联结在一起,之间采用分组交换机制.而在之后的10年中,主机数量飞速增加(参加图1.3).1968年左右提出了汇集各种网络技术的RFC文档,1969年公开发布了RFC的第一份文档RFC 1
连接到ARPANET的计算机大多是PDP系列的,在1960年到1969年的10年内,PDP系列从PDP-1到PDP-10进行了多次频繁的更新,微处理器也不断变更,所以就必须要在不同的机器之间对程序进行移植.为此,产生了TOPS-10这种吸取各机器之间差异的系统.TOPS-10是操作系统的始祖
TOPS-10不仅具有可移植性,还引入了内存保护机制等为了充分发挥不断增强的机器性能而提出的概念.根据这些方面的功能,在一个机器上可以并行运行多个用户的多个进程.对共享内存(Share Memory)和套接字这类进程间通信(InterProcessCommunication,IPC)概念的研究也是在这个时期开始发展的
1969年,供PDP-7使用的UNIX系统诞生了. Kenneth Thompson 针对Multics操作系统开发的Space Travel对UNIX的开发起到了重要作用.开发了UNIX的Kenneth Thompson团队起初是使用汇编语言将Space Travel移植到PDP-7上的,最后灵活运用了这些经验,开发了针对PDP-7的操作系统.Thompson和Dennis Ritchie 逐步实现了独立的文件系统,多任务机制和shell命令行等必须的要素
即使在21世纪的今天,特别是任天堂Nintendo Dual Screen(NDS)和索尼电脑娱乐(SEC)的PlayStation Portable(PSP)等便携计算机,都不使用庞大的操作系统,而倾向于直接利用硬件性能,程序的开发很多都是基于独立的文件系统和多任务机制.可以说,这些工作有一部分是和操作系统本身的工作重复的.在今后的便携式游戏机中,随着可用的计算机资源的增加,移植层的功能也应该更为丰富,那么这些工作的必要性就有可能降低了
1.1.5 20世纪70年代: 网络游戏的基本要素
20世纪70年代是非常重要的时期,在这一时期涌现的所有基本要素为如今的网络游戏形式奠定了基础
首先在计算机方面,1971年开始大规模生产世界上的首批商用处理器Intel 4004(系列),计算机的价格也已降到普通家庭就能购买的水平.网络技术同样取得了巨大进步.1971年,Email作为杀手级应用程序,开始在ARPANET中普及.1973年发明了以太网技术,接入网络的成本急剧下降.1972年,C语言诞生,它作为"高度可移植的汇编语言"在如今的游戏开发中仍然被广泛使用.计算机用户进行通信的机会越来越多,1974年指定了TCP协议,这是如今的网络游戏的基础协议
1971年,创立雅达利(Atari)公司的Nolan Bushnell和Ted Dabney开发了名为 Computer Space的最早街机游戏(商用),1977年发售了名为Atari 2600的最早ROM(Read Only Memory)卡带型电视游戏机(家用),获得了巨额利润.不过,将街机游戏和电视游戏机网络化则是之后的事情了
1973年,John Daleske和Silas Warner利用单独的网络功能在之前提及的PLATO上开发了Empire游戏,接着就是Maze War. Maze War的游戏规则是: 几个人在立体迷宫中行走的同时互相射击,被击中就会失分,击中别人就能得分.该游戏是如今一种重要游戏类型FPS(第一人称射击)游戏的先驱
1974年,名为《龙与地下城》(Dungeons & Dragons)的桌上RPG游戏首次大规模商业化,受其影响的开发者为数众多(笔者也是其中之一).1975年,还是在PLATO上重现了这款游戏,名为Dungeon,这是首款电脑RPG游戏,以文字来表示游戏内容.没多久,Dungeon针对网络确立了基于文字的MUD(Multi User Dungeon)游戏形式.如今基于文字的MUD游戏仍在各类网站上运营
到70年代后期,在活跃于PDP系列的UNIX系统上开发出了各种各样的MUD服务器端,其中的技术基础也用在了以后的游戏服务器端中
1.1.6 20世纪80年代: 网络对战游戏登场
1981年,IBM PC上市,计算机开始大规模普及.1982年指定了发送Email的标准协议SMTP(Simple Mail Transfer Protocol, RFC821),使用电话线和调制解调器将个人电脑和服务器连接,使用ISP服务并且在Email地址上加上@标记来发送电子邮件,成为了很普通的事情.网络操作系统也在不断进步,1983年Netware出现,与此同时在Netware平台上开发了一款名为Snipes(参见图1.A)的P2P网络对战游戏
1983年,随着雅达利游戏机的日渐衰退,任天堂的家用电子游戏机(Nintendo Entertainment System,缩写为NES, 或称为Famicom(Family Computer))快速普及,《马里奥兄弟》(1983年),《塞尔达传说》(1987年)等游戏发售了几百万份
20世纪70年代的文字MUD在进入20世纪80年代后,在富士通Habitat上开始以2D图像显示游戏内容,这与如今的大型多人网络游戏(MMO游戏,MMOG)使用了基本相同的客户端/服务器端(C/S)架构.使用Email进行RPG游戏的Play by Email(以邮件的方式进行游戏)的玩家也在增加,与网络上不认识的玩家一起游戏的机会也在增加

之后在1989年,在CERN上开发了HTML和世界上首个Web浏览器WorldWideWeb.1989年后期,连接到互联网的主机数量达到了30万台
1.1.7 20世纪90年代: 游戏市场扩大
20世纪90年代初期,电视游戏机市场急剧扩大,在任天堂的Super Nintendo Entertainment System(SNES)和世嘉企业(当时叫做SEGA enterprise)的Mega Drive上,开始使用了电话线网络对战游戏服务XBAND,但是最终在商业上失败了.当时的带宽速度和严重的延迟对持续高负载的游戏来说很成问题
另一方面,MMOG中的一款游戏《子午线59》(Meridian 59)在商业上获得了极大的成功,而在P2P对战游戏中,1993年发布的《毁灭战士》则引起了极大轰动

在Web方面,1993年NCSA(National Center for Supercomputing Applications, 美国国家超级计算机应用中心)的Mosaic浏览器以及1994年Netscape Navigator浏览器的问世,不仅可以使用文字来表示内容,还可以显示图片,为基于浏览器的网页游戏提供了契机
到了20世纪90年代后期,针对Netscape Navigator浏览器开发了Shockwave(现在是Adobe Shockwave),Flash(现在是Adobe Flash),Java等扩展功能,同时也开始运用在游戏中.笔者使用Java Applet 开发MMORPG游戏Lifestgorm也是在那个时候

此外,1997年《网络创世纪》(Ultima Online,UO)进一步推动了MMOG的发展.1999年,美国索尼在线娱乐(Sony Online Entertainment,SOE)发行的《无尽的任务》(EverQuest)将真正的3D显示带入了MMOG中.这些软件几千日元的包装费加上每月固定收取的1000日元,一年可以获得数亿日元的利润,但是与现有的游戏软件相比,还需要庞大的服务器运营成本.顺带一提,UO的制作者Richard Garriott称"我最大的失败就是月收费一律9美元"

P2P游戏的设定数据文件可以被替换,于是,玩家开始使用这项功能制作出各种各样的衍生游戏.这些衍生游戏被称为MOD(全称Modification, 游戏增强程序),为了交换MOD而产生的网络社区随之急速扩大
由Valve Software公司开发,Sierra公司在1998年发行的FPS游戏《半条命》(Half-Life)的MOD《反恐精英》(Counter-Strike)反响巨大,特别是在亚洲,影响力之大,竟然达到了在网络上出现了数万个网络游戏咖啡馆的程度.在游戏玩家中也存在着游戏制作者
尽管如此,其实直到20世纪70年代前期,电子游戏的玩家和游戏开发者还基本都是研究人员,大学生和计算机迷,他们大多在之前提到的网络社区中.20世纪90年代,家用游戏和商业电子游戏纷纷产业化,因为考虑到MOD变得日益重要,制作商开始和消费者分离
1.1.8 本世纪前10年的前期: 网络游戏商业化
本世纪初,游戏市场上出现了利润高达数百亿日元的韩国《天堂》(Lineage)系列游戏,因为有了成功实现网络游戏商业化的例子,其他的大企业也纷纷加入这一行列
2000年,SCE发售了PlayStation2游戏机,2001年针对这款游戏发售了PlayStation Extension Bay(用于连接网络的辅助设备.BB Unit),对此,Square(现在是Square Enix)的《最终幻想》(Final Fantasy)系列,《信长之野望》系列(光荣株式会社出品,当时公司名是KOEY,现在是Tecmo Koei Games)等日本知名的系列游戏纷纷发布网络版,如今收益依然可观

1.1.9 本世纪前10年的后半期: 基于Web浏览器的MMOG在商业游戏上获得成功

1.1.10 2010年之后: 究竟会出现怎么样的游戏呢?
1.2 从技术变迁看游戏变化和经济圈
1.2.1 解读技术发展图
1.2.2 3各圈(三大范畴)
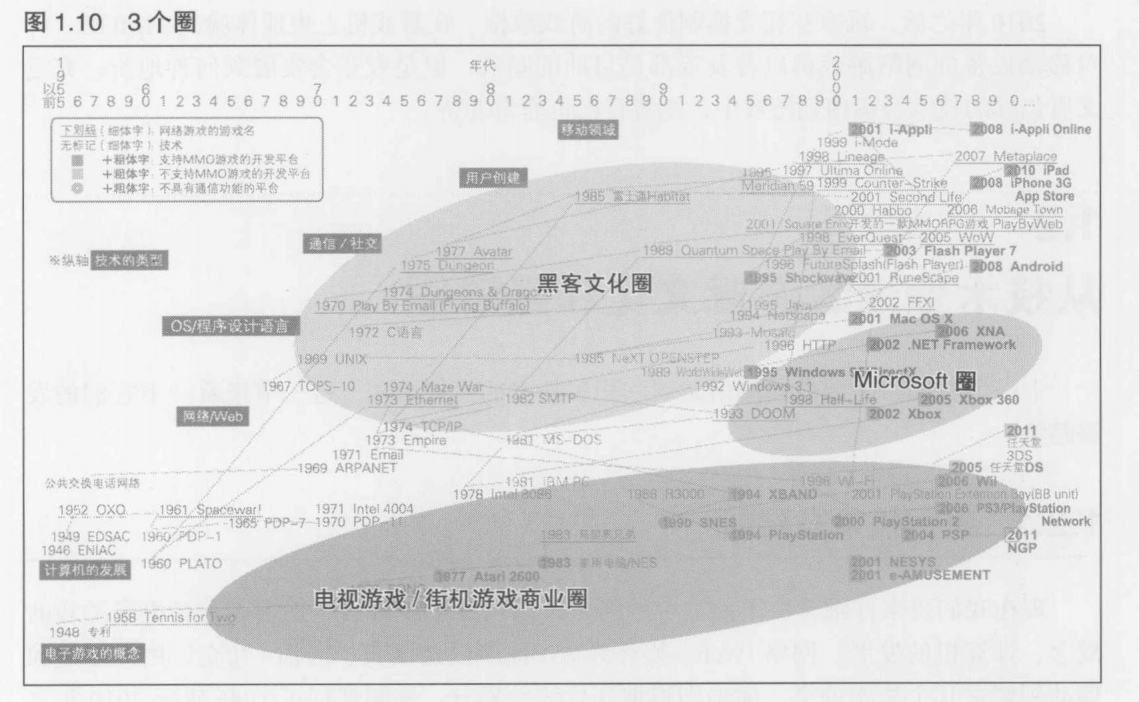
1.2.3 两个游戏经济/文化圈
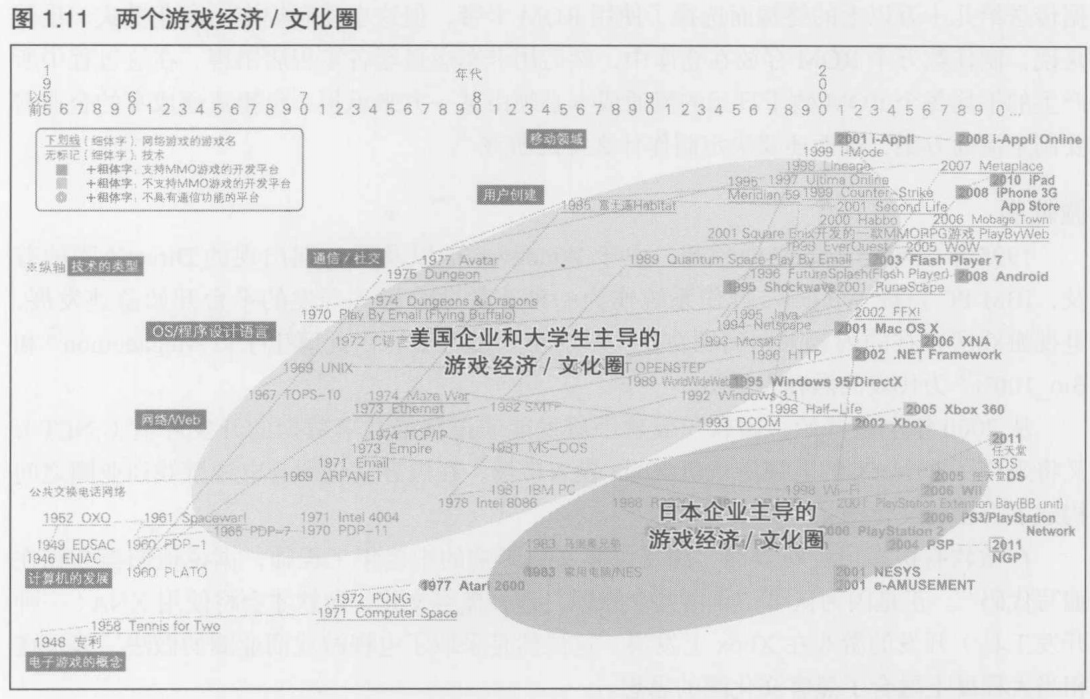
1.2.4 文化,经济与技术的关系
1.3 小结
专栏 成为出色的网络游戏开发程序员的条件
网络游戏行业中,为了成为出色的游戏开发工程师(深受信赖,加薪快),需要具备怎样的条件呢?笔者咨询了相识的企业管理人员和技术人员,总结了如下几条建议.
喜欢游戏
对于自己非常喜欢的游戏类型,要非常投入地去玩其中的某款游戏,并且对一款网络游戏要有非常深入的了解.人的精力有限,不可能精通各种类型的游戏.但是有自己非常擅长的游戏类型和游戏并对其非常了解,这一点是非常重要的
喜欢编程和实际工作
网络游戏的开发永远不会有终点.为了向用户提供持续服务,开发人员需要不断改进游戏,修复BUG,修正各类问题.如果不能先享受这一过程,那就很难在项目中体会到乐趣.要出于兴趣而开始游戏开发
第2章 何为网络游戏 网络游戏面面观
2.1 网络游戏术语的定义
"网络游戏"这个说法并非是一种专业用语, 而是一种商业用语; 更进一步说, 这是一种通称,所以无法严格定义.
技术与市场的发展是不可分割的
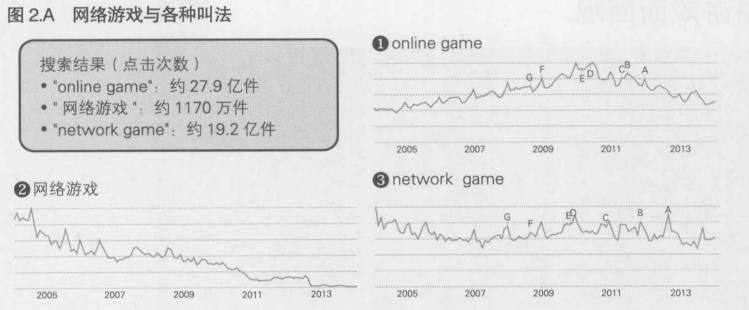
网络游戏的4个层面
https://en.wikipedia.org/wiki/Online_game
网络游戏是指通过计算机网络, 与专用服务器和用户的客户端设备(PC, 游戏机等)相连, 包含让多名玩家共同进行游戏的软件的服务
1. 物理层面
2. 概念层面
3. 商业层面
4. 人员和组织层面
2.2. 网络游戏的物理层面
2.2.1 物理构成要素
计算机网络
计算机
客户端设备
各种PC, 台式游戏机, 掌上游戏机, 移动电话, PDA等
服务器设备
放置在数据中心的服务器
负载均衡设备(Load Balancer)等
网络设备(集线器, 路由器, Wi-Fi适配器)等
网络
使用互联网协议进行通信的网络
WAN(Wide Area Network 广域网)(基本所有的网络游戏都是通过WAN实现的)
LAN内部网[一部分街机游戏和多人网络游戏(MOG)]
LAN与专用网络连接的内部网络(大多数街机游戏)
使用局域网的物理网络进行通信的网络
使用红外线和ad-hoc(点对点)模式的网络
使用RS-232和MIDI(Musical Instrument Digital Interface), USB电缆等的网络
2.2.2 物理模式/物理上的网络构成
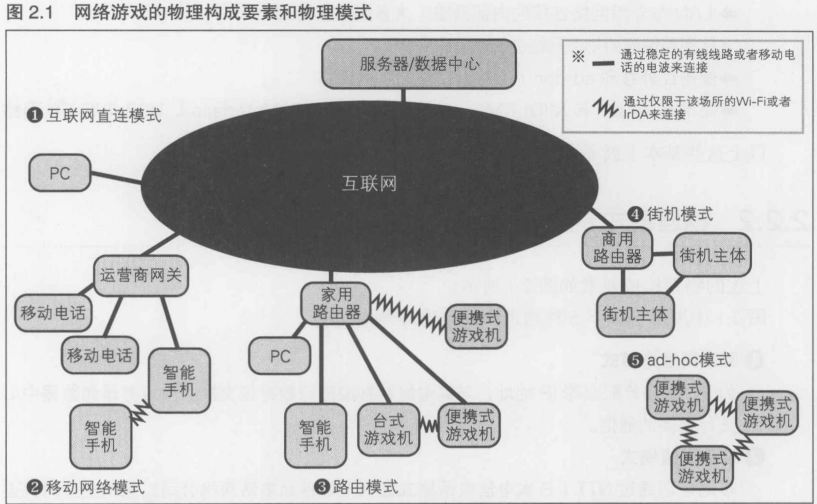
5种物理模式
1. 互联网直连模式
为PC直接分配全球IP地址, 与其他终端直接进行数据包交换.与服务器和数据中心进行必要的通信
2. 移动网络模式
移动电话通过NTT(日本电信电话株式会社)等移动电话网络公司运营的企业网关连接到网络中. 通过au(日本移动电话网络品牌)等服务, 移动电话之间可以直接进行数据包的收发, 但是有些情况下无法接收到除此之外的数据包. 本模式在必要时, 会与服务器和数据中进行通信
3. 路由模式
一般的PC和游戏机通过宽带路由连接至互联网. 因为要通过NAT(Network Address Translation, 网络地址转换)访问互联网, 所以通常无法直接从路由外部的终端上接收数据包. 本模式在必要时, 会与服务器进行必要的通信
4. 街机模式
与路由模式相近, 使用专用线路直接连接到数据中心. 本模式从互联网与隔离的服务器和数据中心进行通信
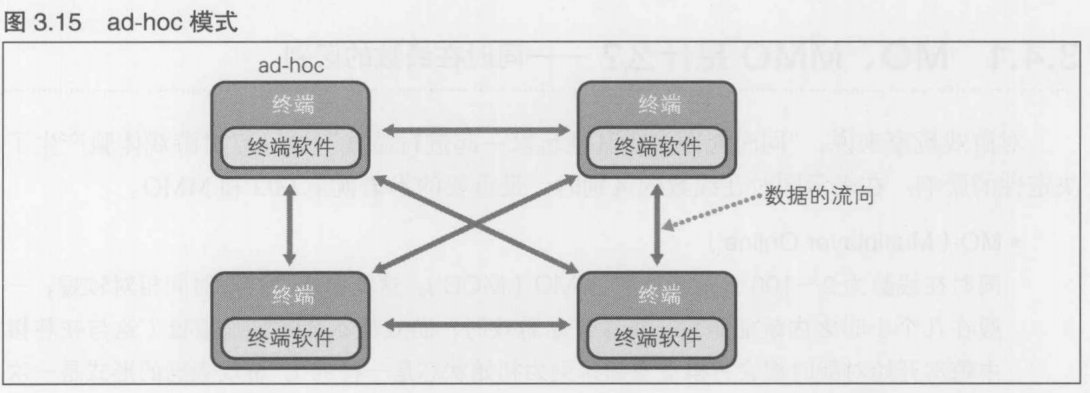
5. ad-hoc模式
PSP与任天堂DS, iPhone与Android终端等智能手机的无线LAN功能使用ad-hoc模式, 即使没有接入互联网, 也能构建独立的小规模网络, 几个人共同进行对战游戏. 由于没有连接到互联网, 所以不能与服务器和数据中心连接
开发工作量按如下顺序递增: 5: ad-hoc模式 -> 4: 街机模式 -> 2: 移动电话模式 -> 3: 路由模式 -> 1: 互联网直连连接模式
按照网络速度的快慢分类: 1,2,3 使用互联网这种较慢的路线, 4 因为使用了专用线路, 所以延迟较小. 5 是本地通信, 所以通信延迟比互联网地得多
2.3 网络游戏的概念层面
2.3.1 网络游戏及其基本结构
游戏的基础----认知 ,判断, 操作的重复
在进行游戏时, 玩家就是在重复着认知->判断->操作这一过程. 这并不仅限于电子游戏, 也包括离线游戏和体育游戏等
这里的"认知"对象就如同棋盘上象棋子的当前位置, 对其有所"认知"(看到)后, 使用自己的y原有知识加以"判断", 进而基于这一判断"操作"棋盘上的棋子. 然后不断重复这一过程.

电子游戏的结构
在进行电子游戏时, 软件的运行结果以画面显示和声音的方式输出, 这就是人们的"认知"过程. 此外, 人们使用鼠标, 键盘, 游戏手柄, 触摸板等输入接口j进行操作
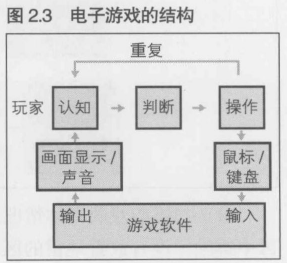
2.3.2 游戏进行空间----进行游戏时所需的所有信息
游戏程序员将游戏软件的内存状态称为"游戏进行空间", 或者"游戏状态", 或者就叫"状态", "游戏空间", "空间", 等等. 笔者多使用"游戏状态"或"游戏进行空间"这种叫法. "游戏状态"是一般的术语组合, 为了便于区分, 本书采用"游戏进行空间"这种说法.
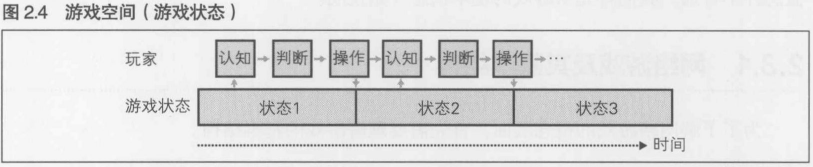
2.3.3 游戏的进展----游戏进行空间的变化
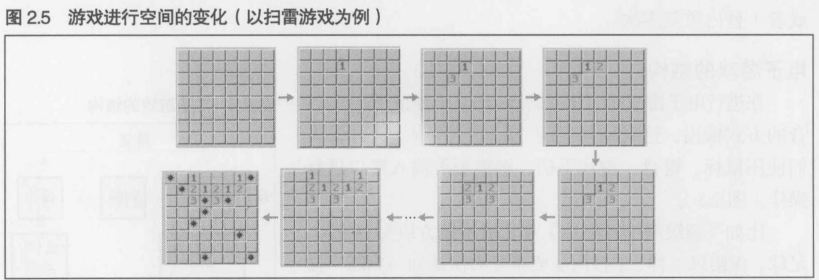
在这个例子中, 游戏进行空间一共变化了9次. 这9次的游戏过程称为"游戏的进展". 网络游戏中这些(相同的游戏进展)是在线共享的.
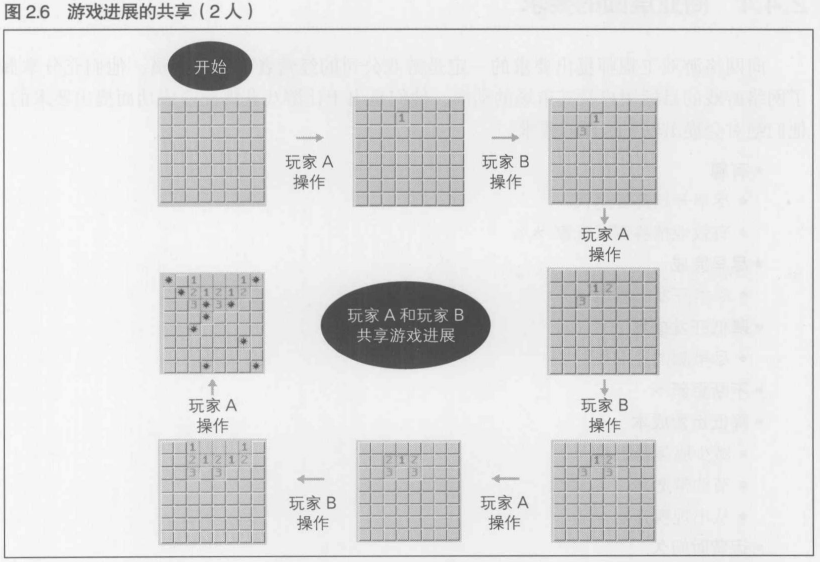
2.3.4 共享相同的游戏进展
2.4 网络游戏的商业层面
2.4.1 商业层面的要求
有趣
尽早开始开发迭代
有效地招募测试玩家 *
尽早完成
尽早开发出原型 *
降低开发成本
尽早测试
不断更新 *
降低运营成本
减少服务器数量 *
节约带宽 *
从小规模开始 *
运营时间久
具有可扩展性 *
评价高
提供多种收费选择 *
希望有大量玩家参与
适配多个平台
为多个国家提供服务
不希望给玩家添麻烦
低成本, 尽早地, 可靠地消除攻击者
尽量减少服务器停止的情况
bug要尽可能少
更佳的用户体验
频繁进行各类活动 #
反馈游戏结果 *
促进玩家之间的交流 #
能够更容易地与其他玩家相遇 *
能够长时间游戏(不会觉得厌烦)
上述条目中标有*, #的, 表示这是"网络游戏所特有的".
在游戏业界, 有种说法是"网络游戏是服务业, 单机游戏是制造业"
2.4.2 有效地招募测试玩家----网络游戏与测试
封闭测试 (CBT)
公开测试 (OBT)
2.4.3 不断更新----网络游戏的运营和更新
定期的补丁
大型补丁 (扩展包, 追加包)
紧急维护
2.4.4 节约服务器数量和带宽----网络游戏开支的特殊性
2.4.5 从小规模开始, 确保可扩展性----将风险降到最低, 不要错过取胜的机会
2.4.6 提供多种收费方式----收费结算方式的变化
2.4.7 低价, 快速地根除攻击者----攻击,非法行为及其对策
商业目的的攻击
首先, 商业目的的攻击中有一种行为称为RMT(Real Money Trade, 真实货币交易). RMT指的是, 用真实的货币来交易需要花时间培养的道具和角色. 虽然人们强烈认为这种做法是很不公平的, 但毕竟这还算是一种合法的行为, 至于摒除RMT到底是好还是坏还存在诸多争议, 包括政治上的争议. 另外, 对企业来说, 这是否与利益紧密相关还有待探讨. 由于这与技术无关, 所以在此不讨论RMT的是非
关系到网络游戏的技术人员的问题是: 以RMT为目的, 称为Gold Farmer(打金者)的人实现了一种称为bot(外挂, 也叫做宏)的特殊工具, 可以自动进行游戏并以此敛财.
bot是一种以人类无法达到的速度反复进行游戏的软件, 这种速度是人类可达速度的几倍甚至几百倍以上. 使用bot会在服务器和数据库中产生大量流量, 因此很有必要对此进行检测并且进行适当的处理. 执行自动测试的测试bot也是其中一种
被评为AAA的具有大规模运营体制的游戏也设立了专门的对策小组, 为了杜绝这些攻击, 由专人在游戏中进行巡视, 比如日本FFXI的运营团队为了管制来自中国的Gold Farmer, 成立了专门的小组, 成功地大幅效减了Gold Farmer的人数
对于那些占据了游戏市场大半江山的中小型游戏, 要经常人为打击Gold Farmer是很难做到的, 因此需要寻求一些自动的处理方法. 目前在业界中还没有防止这一问题的常规技术, 各个公司都是使用脚本语言编写一些简单的工具来个别处理. 日志的格式化与处理方式等也尚未确定, 事实上, 即使是大企业也还无法做到有效地利用日志. 要求开发更加易于使用的日志分析工具的呼声很高, 大家都希望技术获得进一步发展
非商业目的的攻击----各种攻击方式, 3D网络游戏专用的客户端
接着来看一下非商业目的的攻击, 这是出于个人兴趣和某些目的而进行的攻击, 大致可以分为以下这些攻击手段:
1. 非法侵入服务器/篡改数据
2. 根据程序和对数据包的逆向工程盗取数据
3. 拒绝服务攻击等
2.4.8 减少服务器停止的次数和时间----不要让玩家失望
1. 计划中的例行维护所造成的服务器停止
2. 故障或攻击所造成的服务器停止
a. 游戏平衡性和游戏内经济方面的缺陷
b. 服务器崩溃
c. 超负荷
2.4.9 反馈游戏结果----日志分析和结果的可视化
1. 高分排行榜
2. 游戏成就
3. 其他统计
2.4.10 更容易地与其他玩家相遇----玩家匹配
1. 自动选择
自动选择这种方式与Web很接近.比如, 现在想要进行奥赛罗(黑白棋)对战, 系统就将按照各种条件对玩家排序. 这些条件首先包括当前在线的玩家, 这个是必须满足的条件, 其次是尽可能与当前玩家的等级相近, 比赛时中途退出次数少, 曾经与其对战过的玩家, 等等, 系统从中挑选出最合适的玩家推荐给该玩家. 有些实现方法可以在从推荐结果中选择玩家时做到完全自动匹配. 这与Web系统比较相似
2. 专用游戏大厅
专用游戏大厅是一种"等待系统", 是指为了让多名玩家(比如3人)共同游戏而专门构建的系统, 在集结了一定数量的玩家之后才正式开始游戏. 通常, 这是通过很早就开始使用的中继聊天(IRC, Internet Relay Chat, 互联网中继聊天)机制来实现的
3. 虚拟世界(可视化游戏大厅)
虚拟世界又叫做可视化游戏大厅, 将3D虚拟世界在计算机上重现. 在这个世界中, 玩家化身为各种"虚拟人物"(avatar), 操纵自己的虚拟人物与其他玩家的虚拟人物进行交流. 通过交流找到想要共同游戏的玩家, 然后一起开始游戏. 使用虚拟人物可以进行深度交流, 因此不可能仅仅根据文字和关键字, 玩家分数等定量化的信息来寻找其他玩家, 而是要参考对方的想法和性格
这种方式通常用在需要长时间共同游戏的MMORPG, MORPG等类型的游戏中.
专用游戏大厅和虚拟世界的区别
虚拟世界与专用游戏大厅的区别在于: 在虚拟世界中, 玩家可以实时地进行交流
将虚拟世界作为Web服务来实现是很困难的, 这需要专门用户交流的实时服务器, 所以专用游戏大厅与虚拟世界在技术上存在极大的差异
未来的玩家匹配
虽然可以使用以上3种匹配方式, 但是在匹配的精度和使用的容易程度上, 现在都还不够完善, 期待将来能有飞跃性的提升. 此外, 我们希望在降低系统负荷优化匹配时的响应, 改进搜索算法使匹配结果更符合要求等方面的技术, 将来也能取地进一步发展
2.5 网络游戏的人员和组织\
2.5.1 与网络游戏服务的运营相关的人员

有一点要先说明一下, "运营"和"运维"这两个词很容易混淆, 事实上它们是不同的. "运营"是指网络游戏服务中所有商业方面的管理工作. 确切地说, "运营" = "管理". 而"运维"则是指设置专门的团队, 从事网络游戏的系统维护方面的技术工作
2.5.2 网络游戏服务运营的3项专门职责

2.5.3 开发团队
网络游戏的开发团队有如下这些规模: 小型开发团队通常有2~4名开发人员, 20人左右的开发团队是最多的, 而大型团队中有超过150人的
不可或缺的4种职业
项目总监: 统筹管理整个游戏开发过程
程序员: 编写游戏程序
美术工程师: 制作游戏图像
设计师: 根据策划主旨, 进行详细设计
小型团队
一个团队中, 如果上述4种职位各有一名经验丰富的成员, 就能开发一款小型的网络游戏了
大型团队
20人左右的团队, 通常会细分为如下结构. 超过150人的团队会根据20人的团队分工进一步细分, 调整各项分工的人数
项目总监(2人)
技术总监: 负责游戏技术方面的事项, 制定开发计划
美术总监: 负责游戏中的世界观设定以及保证美术制作的质量
程序员(4人)
主程序员: 负责程序的整体架构
系统程序员: 负责游戏程序的底层部分
游戏逻辑程序员: 在搭建好的底层架构上实现游戏逻辑
工具程序员: 负责开发包括美工和设计在内的各项工作所需的工具
美术工程师(6人)
角色设计: 负责人物和其他生物的造型设计
动画设计: 负责人物和其他生物的动作设计
地图设计: 负责建筑物和地形的构思和各种组件的设计
设计师(8人)
关卡编辑: 使用地图设计人员的构思和组件制作大量的游戏关卡
游戏剧本编写: 负责设计出场人物的台词以及游戏中事件的发生顺序, 逻辑关系等
脚本编写: 将实际的游戏数据集成到程序员开发的系统中
20人中有两名管理人员在游戏行业中是很普遍的. 此外, 在有8名设计师的情况下, 为了降低沟通成本, 需要由1人担当主设计师
从职责平衡来看游戏开发的特点----数据制作人员的比例
这里的游戏开发的特点就是制作数据的人员(美术工程师+ 设计师)占了开发团队的一大部分. 以20人的团队为例, 如上所述, 项目总监l两名, 程序员4名, 美术工程师6名, 设计师8名, 共有14人担任数据的制作工作. 是程序员的3倍以上. 在Web服务的开发项目中就不会出现这种情况
游戏中各项职责的人员比例, 不管是网络游戏还是单机游戏都没有根本性变化. 但是根据游戏的类型和内容却有很大变化. 在更接近于"工具"的游戏中(比如《第二人生》等), 程序员占主要部分, 而在更接近于"电影"的游戏中(比如像《勇者斗恶龙》这样的日式RPG等), 数据制作人员则占大多数. 根据游戏类型和游戏内容的不同, 所需的职责平衡也完全不同
如今, 在游戏市场极具竞争力的企业都有自己的一套流程, 它们井然并有序, 高速, 高质量地制作大量数据. 游戏开发不是靠几个天才来完成的, 而是由整个团队来完成的, 这主要是受到由数据构成的系统的影响
因此, 当新的小型企业进入游戏市场时, 都会避开电影式的游戏, 而是会选择开发工具类游戏, 社交类游戏和小型游戏等.
2.5.4 运维团队
在大型团队中, 职责会进一步细分, 但即使是兼任, 也要基本分成以下两种
系统工程师
把握整体计划和游戏的商业模式等, 与开发团队协调
网络/基础设施工程师
负责设备和线路的搭建
这些人员的工作成果对网络游戏的运维是很重要的, 而他们所构建的系统的组成要素分为: (1) 服务器设备, (2) 网络设备
在服务器设备方面, 基本工作是根据层次结构来分工. 在路由器和交换集线器等网络设备方面, 如今已经能够很容易地安装和配置高性能的设备了. 在使用HTTP以外的协议进行传输时, 在传输量(持续会话产生的流量)方面的性能也很不错, 所以这里省略(2)这一点, 只讨论(1)服务器设备的内容
服务器设备
游戏行业所使用的与服务器设备相关的典型层次结构如下所示
应用程序本身
应用程序的基本设施
数据库, 文件系统, 备份设备, 网络设置
操作系统
硬件
上述结构中, 硬件设备位于底部, 应用程序位于顶部. 以每月10万活跃玩家为例, 即使服务器数量和通信流量与支持玩家游戏所需量相同, 但是根据游戏的内容, 类型, 以及通信机制的不同, 服务器负载和潜在的瓶颈所在也会大幅变化. 比如, 在某些游戏中, 数据库很容易发生瓶颈, 而有一些游戏则是语言处理系统的性能容易成为瓶颈
因此, 担任网络游戏系统设计的系统工程师需要从游戏的策划和设计阶段开始就积极地与开发人员沟通. 系统工程师在游戏开发的最初阶段与开发人员进行交流后, 再在开发进行了80%左右时与开发人员进行最终商讨, 游戏发布后, 以这个系统工程师团队为中心进行运维管理
2.6 网络游戏程序员所需的知识
2.6.1 网络游戏程序员所需的技术和经验
网络游戏程序员所需的技术和经验实际上涉及很多方面. 编程基本技术, 游戏编程, 游戏客户端开发, 数据库, 系统运维等领域中, 都需要网络游戏特有的知识
编程的基本技术
设计
架构: 处理拥有几十万行代码的大规模软件的技术
网络游戏是一种复杂的系统, 多个进程包含分散在多台服务器上的数据库, 他们通过跨越互联网和企业内部网的网络连接, 实时协作运行. 每个进程的程序大约几千到几万行, 从整个系统来看, 中等规模的游戏在20万到30万行左右, 大型游戏甚至能达到100万行. 因为必须要高效处理各种规模的软件, 所以需要一些设计方面的技术. 这是一项与游戏内容的规模相关, 而与通信形式无关的技术
设计技术: 结构化, 模块化, 面向对象编程, 设计模式等
设计任务: 并发性, 事件驱动, 错误处理, 容错性, 可用性
需要上面这些基本技术的原因有很多, 比如, 在互联网中直接暴露服务器和客户端的进程, 所提供的服务是实时并且双向的, 游戏服务并非是广告模式, 以及如果在进行收费时服务器停掉了, 就会给用户带来很坏的影响, 等等
质量: 质量定义, 基准, 服务水平定义, 检测
很多情况下, 网络游戏, 特别是服务端的程序问题只有在进入公测, 大量玩家登录游戏后才会显露出来. 这是因为有些程序部分(管理计算机资源的机制)只有在接收了来自各种环境的多个同时连接的情况下才有多个. 所以必须将这些系统细分为多个子系统分别进行负载测试, 然后再同时使用多个子系统进行组合测试, 在公测之前验证是否能够实现必须达到的服务水平
记法: UML(Unified Modeling Language)和各种图示, 结构, 以及行为图的表示
架构
管理: 大规模协调工作的计划, 预算
商业游戏的开发项目中, 中小型项目一般有3~4名程序员, 2~3倍的数据制作人员,大型项目将达到相当于中小型项目的10倍左右的人数(100~200人).另一方面, 游戏开发的过程中常有变数. 在这种环境下要遵守预算的制约来进行开发是很不容易的, 所以管理非常重要
编码: 多种编程语言, 安全模型, 排他机制, 内存管理, 文档化, 优化, 松耦合模式
复用
在笔者参与过的项目中, 尽管没有同时使用到C/C++, Ruby, PHP, Java, Python, C#, Perl, Lua等所有的编程语言, 但是有同时使用多种语言来进行开发的情况. 此外, 即使是同一种编程语言, 也混合了代码规范, 设计规则等各种组成要素. 因此,为了在有限的预算中控制成本, 必须尽可能利用商业渲染库, 过去开发的工具资产, 自己公司开发的程序库等各种可用的资源. 为此, 必须具备复用以及降低耦合度方面的知识
质量: 单元测试, 组合测试
测试
各种测试: 功能, 性能, 负载, 安装, 可用性测试, 各种检测
测试时需要大量人员参加,这一点是增加网络游戏的测试难度的一个因素. 功能测试,性能测试, 可用性测试等, 不管是哪一种都是如此. 无论如何, 网络游戏都必须有大量人员参与测试, 而且在不能进行公测的情况下, 需要准备能够模拟玩家的程序
管理: 测试计划
维护: 现有代码的修复, 移植, 交接, 文档化, 说明书
游戏编程的基础知识(对网络游戏的开发是必需的或者有用的知识)
版本管理, 自动化构建/测试 Perforce
对排序等基本算法的理解
对CPU结构, 命令集等的理解
特定于硬件的知识, 内存系统等
对OS, SDK的理解
制作简单的编译程序
对加密方式的理解
特定于游戏类型的知识 动作游戏,RPG游戏,射击游戏,卡片游戏,冒险游戏,竞速游戏等不同的游戏类型中,程序的基本架构差别很大(网络游戏也同样如此)
碰撞检测,物理运算
AI
对象, 任务系统
嵌入式脚本 Lua, Squirrel, Python
转换工具,设置工具,GUI工具 游戏开发中有编程,数据制作,美术制作和策划几大类.其中占比例最高的是前述的数据制作这一块.数据制作指地图制作,事件制作,物品制作等.
游戏客户端开发的知识
二进制操作,数据文件操作
文件的打包
操作菜单和特效
渲染(2D, 3D)
数据库知识
SQL, 查询优化, 高速缓存, 扩展性
根据各种DBMS和DB库的用途分开使用
系统运维知识
各种业务流程
服务器部署
负载均衡
数据备份, 数据恢复
服务器监控(Monitoring, 状态监控), 服务器心跳监控(监测服务器是否在运行), 监控工具
2.6.2 各种网络游戏开发知识
2.7 支持网络游戏的技术的大类
支持网络游戏的技术的4种形式
支持网络游戏的技术分为物理结构和逻辑结构li两大部分, 总共分为4种形式(类型)
C/S架构和P2P架构----物理结构的两种典型模式
支持网络游戏的技术的物理结构就是指"实际进行通信的设备之间存在怎样的关系"

MMO架构和MO架构----逻辑结构的两种典型模式
逻辑结构则是指"实际进行游戏的玩家之间存在怎样的关系". 逻辑结构中有MMO和MO这两种典型模式, 它们拥有完全不同的游戏内容
前面讲过, MMO是Massively Multiplayer Online 的缩写, 这类游戏的目的是让大量玩家长期游戏. 因为要接收大量玩家, 所以必须会牺牲响应时间. 又因为要供玩家长期游戏, 所以必须处理大量数据
MO是Multi-player Online的缩写, 这类游戏意在让少数玩家享受实时对战的乐趣. 这类游戏需要尽可能追求高速的响应时间. 由于要在短时间内实时进行游戏, 所以处理的数据微不足道

网络游戏的4种形式----物理结构 x 逻辑结构
物理结构有C/S和P2P两种, 逻辑结构有MO和MMO两种, 它们各自独立, 所以总共有4种形式. 在实际的游戏中, 除了P2P加MMO(P2P MM)这种模式是不存在的, 其他的所有模式在游戏中都有广泛运用

2.8 影响开发成本的技术要素
2.8.1 网络游戏与如今的开发技术
2.8.2 支持网络游戏主体的3大核心
网络游戏的整体技术可以分为"游戏主体"的软件技术和"辅助要素"(辅助系统)两大类. 其中, 辅助要素已经得到了相当程度的封装. 我们先来看一下形成有关"游戏主体"的典型模式的3大核心(技术要素)
这些核心有如下方面, 对这些方面都要有所权衡
游戏的数据形式
游戏的通信方式
游戏的反应速度(延迟)
上面这3个技术要素会影响到程序在实现上的难易程度. 这里的"实现上的难易程度"指的是如果需要更复杂的算法, 或者要处理很多异常情况, 又或者因为估计到攻击种类会有很多而必须采取多种防御手段等, 由于种种理由而导致的编程工作增加, 软件复杂性增加. 这与"开发成本"直接相关. 总成本的大小可以通过将上面这些技术要素相乘来加以想象
游戏的数据形式 包含了一系列于游戏进行相关的所有信息的数据是以怎样的形式存储在物理媒介上并加以使用的
游戏数据形式的分类
从本书中游戏内容的持久性的观点来看, 游戏的数据形式分为以下两大类
一次性的(disposable): 每次初始化游戏内容就丢弃
持久化的(persistent): 游戏内容持续存在于服务器端
游戏的通信方式 游戏的数据包通过怎样的路由在玩家(客户端)之间进行交换
P2P: 没有中央服务器, 各个终端之间直接相连的通信方式
C/S: 只在客户端/服务器之间进行通信的星型结构的通信方式
游戏的反应速度
游戏处理的冗余化和异步化----网络延迟的问题
冗余化指的是游戏数据在较远处和较近处的两个地方进行复制, 保持数据的冗余(主数据和副本数据之间的关系)
异步化指的是保持冗余的游戏数据在不同的时刻发生变化
在互联网上, 分散的, 冗余的, 异步的游戏数据要保持整体的完整性在理论上是不可能的. 但是保持从玩家角度看到的完整性就并非不可能了, 为了这个目的, 特定于各种游戏类型的方法在不断发展
网络延迟的3种形式----同步方式, 异步方式, 浏览器方式
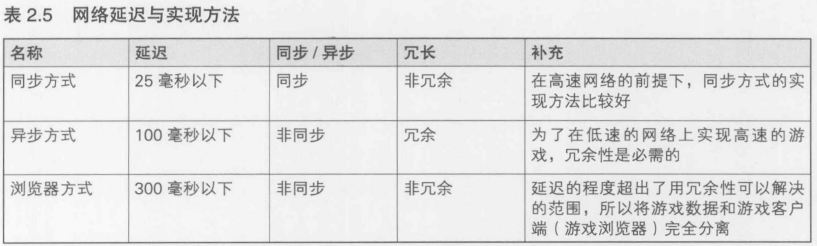
同步方式指的是, 运行在所有进行游戏的玩家的设备上的程序是同时运行的. 也就是说, 只要有一个人的网络发生延迟, 程序运行变慢, 所有人都会受到影响
异步方式指的是终端程序异步运行, 各个终端上的游戏进行状态也是异步的. 就算某一台终端上的程序停止运行, 其他终端的程序也能照常运行, 但是会发生"游戏数据不匹配"的情况
浏览器方式是指所有的游戏内容都运行在某个中心程序(通常称为主机, 服务器等)上, 其他程序只起到浏览游戏内容的作用.这种情况下, 即使服务器以外的程序都停止运行, 游戏也能继续运行, 也不会发生数据的不匹配.因此, 游戏停止的概率可以大幅下降. 但是由于所有的信息都经过服务器, 延迟j就会相应增加
2.9 小结
专栏 网络游戏编程的最大难点
游戏处理的冗余化->解决主数据和副本数据之间的关系的问题
游戏处理的异步化->解决在处理数据变化时同步和异步之间的关系的问题
主数据和副本数据----游戏处理, 游戏的冗余化
主数据指的是原本的数据, 副本数据是复制之后派生出来的数据.
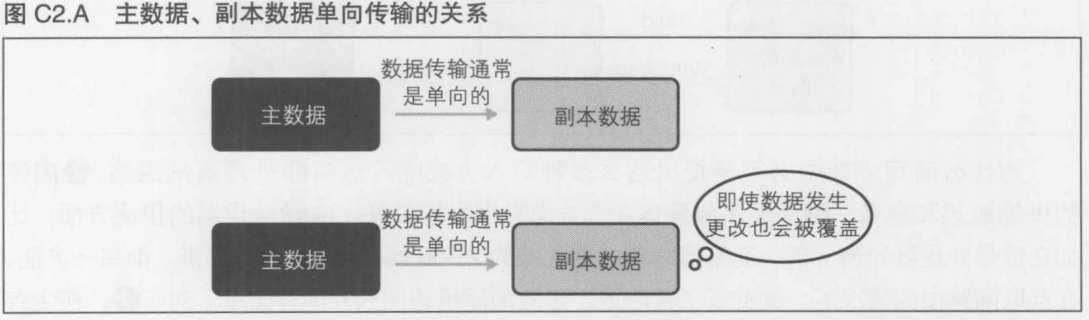

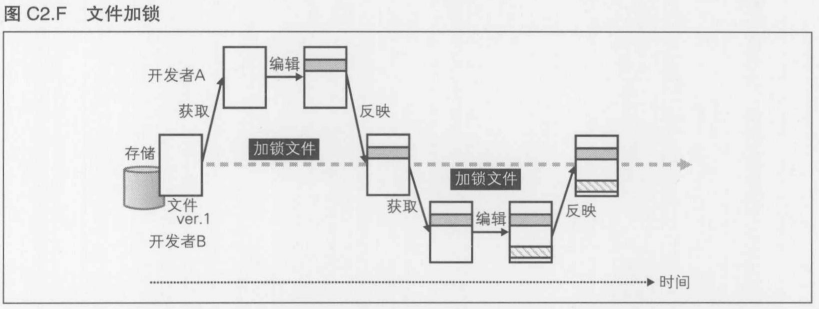
异步方式, 同步方式----游戏处理的异化
Subversion----异步方式
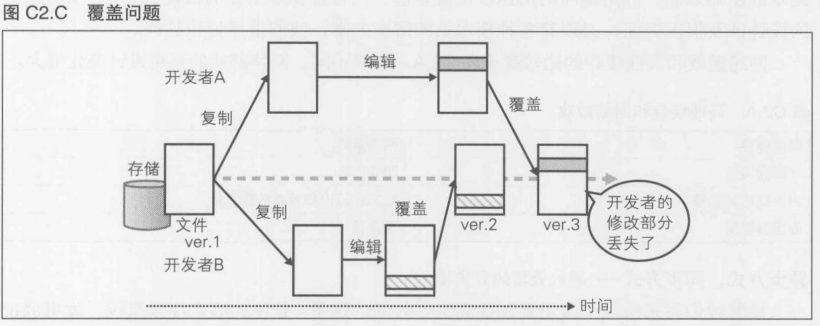


Visual Source Safe----同步方式

第3章 网络游戏的架构 挑战游戏的可玩性和技术限制
3.1 游戏编程的特性----保持k快速响应
3.1.1 响应速度的重要性----时间总是不够的
视频游戏软件的最大特点就是: 为了最大限度地发挥其可玩性, 必须流畅地持续进行实时的高速处理. 而且网络游戏的程序还必须始终保持高速响应
为了始终保持实时的高速处理和稳定的高速响应, 通常游戏程序会将所有必要数据都存放在内存中(on Memory)进行处理. "存放在内存中"指的是, 在花费几个CPU时钟周期(几纳秒至几百纳秒)就能取得信息的距离内所配备的内存中存放数据
除此之外, 在开发网络游戏时还必须于网络数据包的"通信延迟"这一强敌作战. 这里的延迟是纳秒的100万倍, 也就是以毫秒为单位. 为了不让这么高的延迟破坏游戏的乐趣, 开发人员必须想尽各种方法来解决这个问题
3.1.2 将数据存放在内存中的理由----游戏编程真的有三大痛苦吗
之所以将数据存放在内存中, 是因为游戏编程中存在被称为"三大痛苦"的三种特性, 即:
1. 游戏数据要在"16毫秒”这一短暂的时间内持续变化
2. 大量对象的显示直接关系到游戏的可玩性
3. 不知道玩家会在什么时候进行操作, 所以无法事先进行计算
这些特性并非只出现在当今的游戏中, 而是之前就已经存在了. 正是因为这些特性, 数据才需要存放在内存中.
3.1.3 (1) 每16毫秒变化一次----处理的信息及其大小
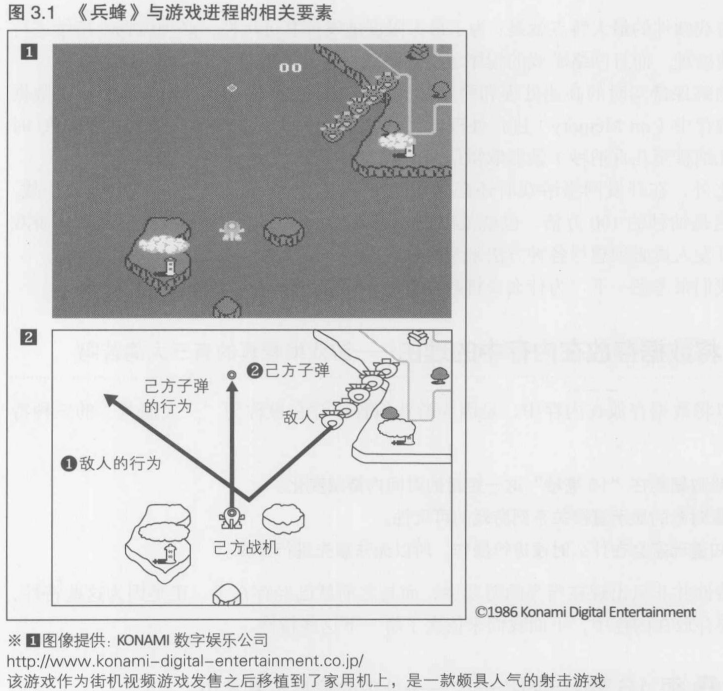
敌人飞出来后如图3.1 2-1 所示的那样行动. 玩家按下家用游戏机的控制键后, 自己的子弹(图3.1 2-2)就会在1秒内发射30次. 显示器画面的帧速率(更新速度)是前一章所提及的每秒60次, 程序的处理也是每秒60次, 因为当时的家用机每一帧都要判断按钮的On/Off状态, 一次判定需要花费2帧,因此1秒内最多只能判断30次
己方子弹以每帧8像素的速度在画面上飞行,最多显示2个. 敌方的移动速度为每帧2像素. 击中敌人后加100分, 而被敌人击中就算失败. 当时的游戏机画面显示能力有限,所以无法在画面上显示剩余的己方战机数
表现游戏进程所需的信息及其大小
- 己方战机(1架)
- 己方子弹(2发)
- 敌人(5个)
- 背景
- 得分
那么在以上这些方面, 从程序的角度来看各自需要哪些信息呢? 敌人的配置, 打到单个敌人时的得分表等, 这些直接写在源代码中的固定数据, 以及与背景相关的数据是不会发生变化的, 所以在此不作说明. 此外, 得分也不一定每帧都会改变, 所以也排除在外. 那么, 以下这些信息就是必不可少的
- 己方战机(1架)
坐标: 因为是二维坐标, 所以需要2个16位数据->4个字节
- 己方子弹(2发)
坐标: 二维坐标, 需要2个16位数据->4个字节 x 2个子弹 = 8个字节
速度: 二维坐标, 需要2个16位数据->4个字节 x 2个子弹 = 8个字节
- 敌人5个
坐标: 二维坐标, 需要2个16位数据->4个字节 x 5个敌人 = 20个字节
速度: 二维坐标, 需要2个16位数据->4个字节 x 2个敌人 = 20个字节
计数: 因为在某个时刻敌人会返回(路线返回), 所以在敌人个数不固定的情况下需要进行计算. 需要8位数据->1个字节
由此可知, 共计4+8+8+20+20+1 = 61个字节就可以将该图中的游戏内容表现出来. 看到这个数字, 读者或许会觉得"还挺少的"吧
可以用RDBMS实现吗?----与在内存中存放数据进行比较
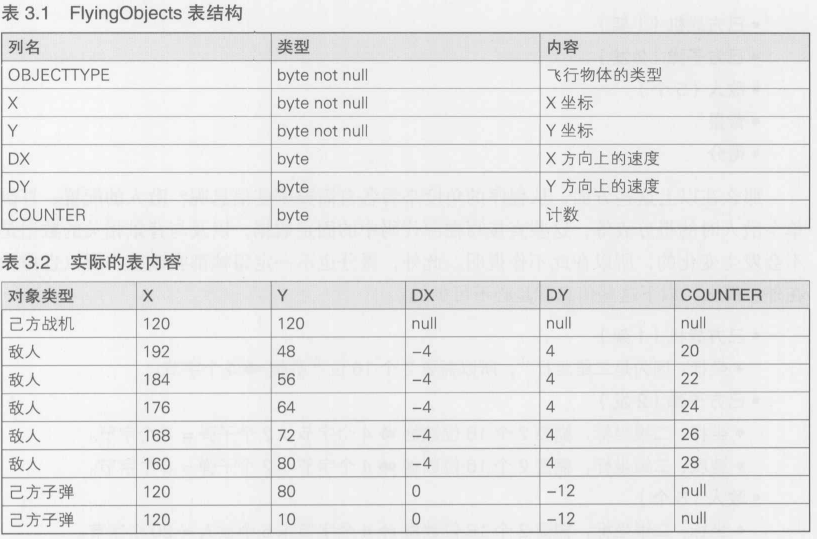
针对图3.1的画面状态, 实际的表内容如表3.2所示. 其中有两点很重要
- 所有的物体在每一帧中都是持续运动的
- 下一帧会发生什么是无法预测的
FlyingObjects中的所有对象在每一帧中都是持续运动着的. 因此, X,Y的值会不断变化. 另外, 因为无法预测玩家会在哪一帧中做出怎样的操作, 所以无法将事先计算好的数据存入表中. 因此, 每一帧都要取出表中的所有行, 进行判断, 然后再全部存在表中, 如此反复. 这些操作必须在1秒内重复60次, 也就是每16毫秒重复一次.
RDBMS本来并不是刻意设计成这种使用方式的. 尽管如此, 必须现在的MySQL, 对于每行几个字节的数据, 每秒能更新1万~10万次以上. 也许有人会认为能做到这样的话就没问题了, 然而果真如此吗?
3.1.4 (2) 大量对象的显示----CPU的处理能力
家用游戏机与CPU周期
1984年左右, 任天堂家用游戏机(HVC-001)采用的是6502(MOS 6502)的兼容芯片(处理器), 主频1.79MHz. 这款25年前的CPU与现在的芯片比起来, 足足慢了2的12次方, 也就是4096倍
单单说4096倍也很难想象, 我们来具体分析一下. 如果使用这种芯片, 数据在1秒内变化60次的情况下, CPU处理能力大约是1次(1帧)179万 / 60 = 29666, 也就是大约3万周期
为了让飞行物移动起来, 必须进行以下处理: 读取坐标, 读取速度, 进行计算, 保存结果. 使用6502处理器的命令集处理以上操作需要2~8个周期, 假设在效率较高的程序中需要4个周期, 如果飞行物有8个, 就要对二维坐标中X, Y两方数据各处理一次, 共计两次, 由此可知, 总共需要(4 + 4 + 4 + 4) x 2 x 8 = 256个周期. 对于3万周期来说可谓十分充裕
接着需要判断己方子弹是否击中了敌人. 假设要对正在飞行的8个物体全部进行碰撞检测, 那就必须进行 8 x 8 = 64 次检测. 碰撞检测不能根据两个物体的坐标是否一致来进行判断, 而是必须通过矩形来判断, 所以需要进行二次比较. 因此必须进行如下处理: 读取坐标, 二次比较, 以及根据结果进行不同的处理. 这次每项处理需要10个周期. 又因为要处理X, Y坐标两方数据, 所以还要翻一倍. 最终需要(10 + 10 + 10 + 10) x 2 x (8 x 8) = 5120个周期. 再加上移动处理的256个周期, 也就5400个周期到, 看上去还挺充裕吧
家用游戏机上的经典游戏通常有20个左右的角色登场. 若对20个对象进行碰撞检测时, 根据上面的计算方式, 需要(10 + 10 + 10 + 10) x 2 x (20 x 20) = 32000个周期, 这个就超过了3万周期的上限. 另外还有其他操作以及声音等的处理, 所以必须采取一些措施来降低所消耗的周期. 比如, 把"己方子弹之间不会发生碰撞", "敌方子弹与己方子弹不会发生碰撞"等游戏内容考虑在内, 从而对内存进行优化
实际上, 为了增强游戏的可玩性, 一般会根据情况使物体运动更为复杂, 而不是简单的匀速直线运动, 这样一来, CPU周期就更显不足了. 一旦CPU周期不足, 游戏中物体的运动就会显得迟缓, 导致游戏体验急剧下降. 而另一方面, 如果CPU周期过于空闲, 游戏的进行速度就会显得过快, 需要追加一些额外的"为了配合显示设备的渲染更新速度稍作等待"的处理
在家用游戏中使用RDBMS时
假如要在搭载了6502芯片的家用游戏机上使用RDBMS会怎么样呢? 当然首先必须通过SQL语句, 但是像 SELECT * from FlyingObjects这样的语句, 单单判断语法是否正确就要消耗几百个CPU周期, 显然不现实
游戏编程必须在1帧内完成坐标的判断和保存. 为此, 必须只通过组合CPU所具有的一些最原始的命令来实现这些处理, 只是读取数据就要花费几百个周期是相当不合理的. 因此, 在家用游戏机中, 基本不考虑使用RDBMS这种方式
PlayStation 3(PS3) 与 CPU周期----可以用RDBMS来开发吗
那么如今的游戏机又如何呢? PlayStation(PS3)自诩具有卓越的性能. 主频 3.2GHz的8核处理器, 128bit访问总线, 确实是优势明显的. 有了这样的性能, 或许可以使用RDBMS的方式来开发呢......那么, 真是这样吗

图3.2是PlayStation 3的一款游戏《星际出击HD》(STAR STRIKE HD)的画面. 在画面中我们可以看到许多细小的粒子, 这些粒子实际上使用了绿色, 粉色, 橘黄色等颜色, 虽然《星际出击HD》与《兵峰》一样都是射击游戏, 但是闪烁的粒子过多, 几乎都看不到己方的战机了
每一个粒子的运动轨迹都比匀速直线运动复杂, 而且还是在三维空间内运动的. 在这个游戏中, 单单需要进行碰撞检测的对象就高达数千个, 除此之外还有数万个以上的粒子要以每秒60次的速度四处移动, 为了进行这样的移动, 必须通过三阶行列式来进行计算
在主频3.2GHz的设备中, 1 / 60秒内可以利用5300万的CPU周期. 假设每次有2000个物体互相碰撞, 总共就是2000 x 2000 = 400万, 5300万/ 400 万 = 13.25个周期. 在三维空间内运动的对象进行1次碰撞检测就要13个周期, 这对于现在的设备是不可能的, 所以需要运用空间分割等各种优化手段. 所以对于在PlayStation3中是否可以使用RDBMS, 还有很多方面是必须要考虑的.
3.1.5 (3) 无法预测玩家的操作----游戏状态千变万化
在对象会发生碰撞的游戏中, 一般来说, “物体的行为比较混乱", 所以无法预测数据何时会发生变化. 而且玩家什么时候会进行操作也是完全无法预测的. 在《星际出击HD》这个例子中, 无法预测几千个对象在下一帧会移动到何处
用RDBMS方式无法实现的信息量和处理速度
假设玩家可以作出选择比较少, 而可能的模式又很有限, 虽说只要事先保存所有的状态, 只在需要时读取出来就可以了, 但是因为数据的变化每次都不可预测, 结果还是必须在每1/60(16毫秒)内从数据库读取几万行的数据进行重新计算. 无论MySQL的速度有多快,都无法做到以这样的速度读写
3.1.6 必须将游戏数据放在CPU所在的机器上
游戏过程中的数据需要以非常快的速度不断变化, 所以这些数据必须在内存中进行管理. 从支持网络游戏的技术这一层面来说, 从这一点可以引出更为重要的问题. 在内存中进行管理的关键是注意CPU频率, 也就是要在几纳秒至几百纳秒的延迟内访问数据. 在光速下就是1纳秒30厘米的距离
3.2 网络游戏特有的要素
3.2.1 通信延迟----延迟对游戏内容的限制

传输时间的具体内容
光的速度是30万千米/秒, 单模光纤的折射率是1.5, 30万/1.5 = 20万千米/秒. 东京与大阪之间的距离是500千米, 往返一次就是1000千米. 光速往返一次需要花费1000 / 200000 = 0.005秒,也就是用了5毫秒
笔者家中与大阪大学之间配置有20台以上的路由软件和硬件, 剩下的14毫秒就用在了这些路由的处理上. 但是其中有1毫秒左右是由笔者所用笔记本电脑的无限LAN所消耗的
无法避免的延迟----延迟与游戏类型
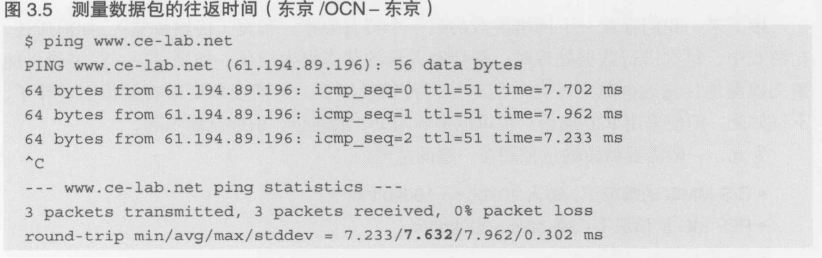

19毫秒比显示设备16.7毫秒(16毫秒)的显示速度慢, 即使面向日本互联网市场的网络游戏可以做到最大限度地利用显示设备的显示速度, 但是东京和大阪的玩家进行对战时还是无法达到这一速度. 由此可见, 网络游戏并不适合那种挑战反应神经的游戏
物理规律不会变化, 只要地球的大小保持现状, 日本玩家和美国玩家就不能进行挑战反应神经的视频游戏
3.2.2 带宽----传输量的标准
- C/S MMO 的情况下: 每人10kbit/s ~ 100kbit/s
- P2P MO 的情况下: 30kbit/s ~ 300kbit/s
3.2.3 服务器----成本,服务器数量的估算
- C/S MMO: 每台服务器有1000~3000个同时连接, 那么服务器数量预计等于设想的同时连接数 / 1000~3000个同时连接
- P2P MO: 每台服务器的同时连接数相当于上面的3~5倍, 计算方式同上
3.2.4 安全性----网络游戏的弱点
作弊----最大的安全隐患
作弊就是指通过某种方式非法利用构成网络游戏的系统
作弊行为的手段
- 内存破解 直接篡改终端的内存上所存储的游戏过程数据
- 数据包破解 使用某些工具篡改游戏程序所收发的数据包的内容
- 数据文件破解 篡改游戏程序所读取的文件的内容
- DLL(Dynamic LInk Library)破解 对游戏程序启动时所读取的动态链接二进制文件进行篡改
- 时钟破解 将操作系统的时钟设置为与当前不同的时间, 使程序作出错误的行为
- UI工具破解 鼠标点击和键盘操作等游戏必不可少的操作通过自动化工具反复高速地进行, 而无需人工操作
- 服务器攻击 非法侵入服务器, 偷看, 篡改服务端数据
- 伪客户端 制作假的游戏程序, 生成, 收发正常的游戏程序不可能具有的数据
此外, 还有一些虽然不是作弊, 但也存在问题的行为
- 违反规则 正常使用游戏, 但是违反游戏规则
- 非法利用bug 不管什么游戏都有一些广为人知的bug. 利用这种bug获取大量利益
- 给服务器造成极大负担[Dos, Denial of Service attack(拒绝服务攻击)]
通过向服务器和其他玩家的终端发送极其大量的数据包, 反复登录, 造成超负荷, 处于超负荷状态下的服务器运行状态变得很不稳定, 这些入侵者就利用这一状况复制(Dupe)游戏物品
- 滥用隐藏命令 滥用调试或者开发用的命令. 与非法利用bug类似
作弊操作的对象
- 本地的内存文件 试图作弊的玩家自己终端上所保存着的资源
- 其他玩家的内存和文件 没有进行作弊的其他玩家所使用的终端保存着的资源
- 数据中心服务器上的内存和文件 运营公司所有的服务器上的资源
- 存在于本地与其他玩家之间的数据包
- 存在于本地与数据中心的服务器之间的数据包
3.2.5 辅助系统(相关系统)
3.3 物理架构详解----C/S架构,P2P架构
3.3.1 基本的网络拓扑架构
网络拓扑结构(Network Topology)是指构成网络的要素之间的连接形状, 有助于研究网络的连接要素是以怎样的结构加以构建的
圆形部分称为节点(Node), 实线称为边(Edge), 或者线路, 链路. 在网络游戏中, 节点就是PC和服务器等各种计算机设备, 线路就是指网络连接. 如果从某个节点到另一个节点经过了两条线路, 就称为"拓扑数为2".
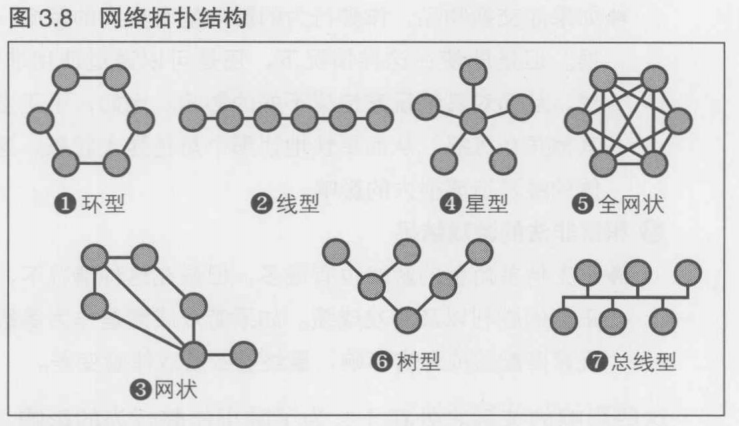
- 环形(Ring) 形成一个环状, 即使一条线路中断, 还是能使用反方向的线路将信息传输到所有的节点中. 从一个节点到另一个节点的平均拓扑数为所有节点数的一半
- 线型(Line) 从一端的节点开始以管线方式依次传输信息, 包括缓存方式在内, 单纯地维持各节点的运行方式. 从任意一个节点到另一个节点的拓扑数可能最长(节点数-1)
- 网状(Mesh) 多个节点由不规则的线路连接在一起. 从一个节点到另一个节点的线路有多种. 需要注意很多方面, 比如不要将负荷集中在某个特定的节点上
- 星型(Star) 多个节点连接到一个特殊的中央节点上. 从一个节点到另一个节点必然经过两条线路. 另一方面, 中央节点的处理负荷很高
- 全网状(Full Mesh, Fully connected) 所有的节点全部互相连接. 因此一个节点到另一个节点都只需要经过1条线路. 这种连接方式并不适合那些线路维护成本很高的网络
- 树型(Tree) 将信息传输给所有节点时, 根据作为信息发送方的节点所处位置的不同, 拓扑数也会相应变化
- 总线型(Bus) 多个节点由一条共同的总线(Bus, 传输线路)连接. 也被认为是对星星结构的应用, 但是不存在中央节点, 因为只是简单地复制信息, 所以中央节点就被整个省略了.
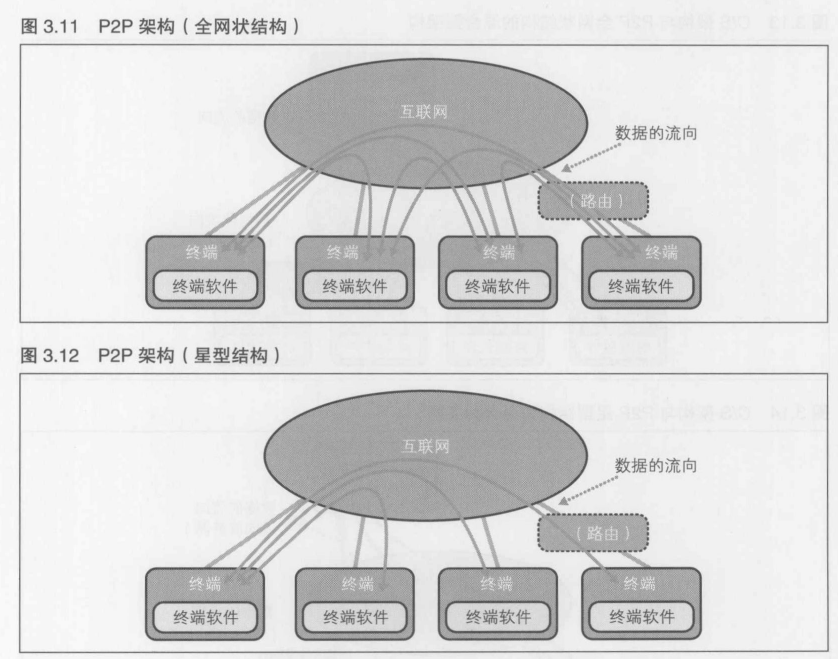
实际使用的有星型(和总线型), 全网状结构----把通信延迟降至最低
P2P架构常用全网状结构(如同步方式的实现), 星型结构(如存在主机游戏的实现), 总线型结构(如反射型的实现). C/S MMO 架构则常用星型结构
采用这些结构主要还是因为, 相对于游戏中的容错性和整体的吞吐量, 优先级最高的还是"尽可能降低通信延迟"
比如, 在星型结构中, 如果中央节点被破坏了, 那么整个网络就会全部中断. 全网结构中, 虽然整体的传输量最大, 但是确实只要经过一条线路就能将信息送至目标节点, 所以速度最快. 环型, 线型, 网状, 树型结构在节点与节点之间都存在两条以上的线路, 通信延迟过大, 所以不予使用
因此, 目前的情况就是只使用"星型结构"(及作为其应用的总线型结构)和"全网状结构"
3.3.2 物理架构的种类
- C/S 结构(客户端/服务器架构)
- P2P架构
- C/S + P2P混合型架构
- ad-hoc 模式
3.3.3 C/S架构----纯服务器型, 反射型
C/S架构根据服务器功能的不同,分为 纯服务器型, 反射型两种类型
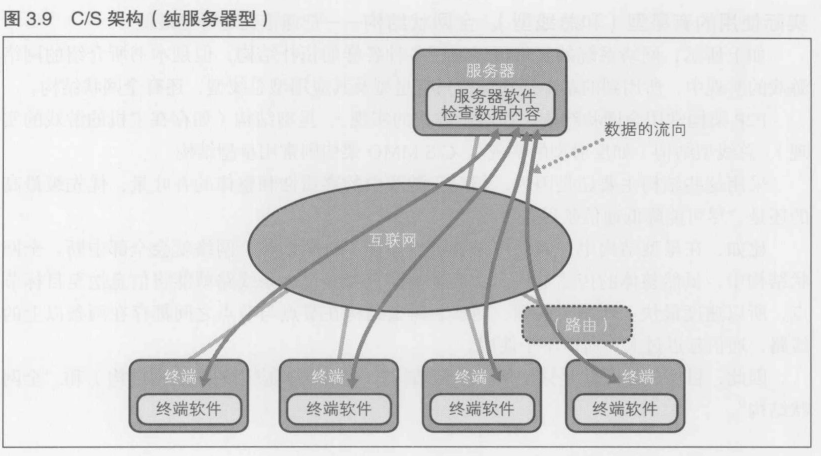
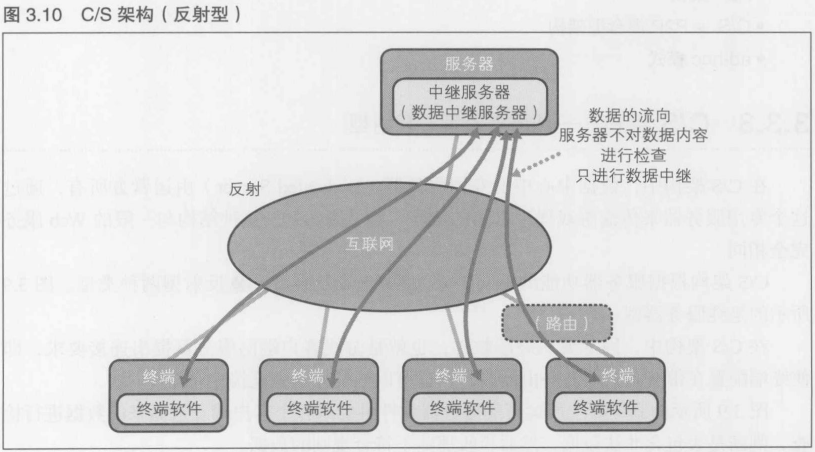
3.3.4 P2P架构
3.3.5 C/S + P2P混合型架构

3.3.6 ad-hoc模式
专栏 游戏客户端是什么
在网络游戏的开发中,在玩家所用设备上(PC机或游戏机)由玩家启动的为了进行游戏而运行着的, 用来进行渲染处理和输入输出处理的专用游戏软件称为"游戏客户端"(Game Client). 事实上, 这并不是那些与网络上的服务器进程进行连接的软件, 但是通常它们都统称为客户端, 所以在严格说明网络架构时, 有时会引起混乱
比如, 在P2P架构的网络游戏中, 在网络架构上, 一个游戏软件接收来自另一个游戏软件的连接, 而服务器也是存在的, 在这种情况下, 如果单单使用"客户端"这样的术语, 就会说"这个客户端, 既有服务器也有客户端......", 或者说"连接玩家A的客户端",等等, 这就造成了混淆
因此, 本书不使用作为通称的"客户端", 而是使用"游戏客户端", "游戏终端软件"或者"终端软件"这样的名称. 此外, 在网络结构的说明中, 运行终端软件的计算机就称为"终端". 而在表示telnet和ssh命令等用于远程操作计算机的通信软件时, 也常使用"终端软件"这样的术语
3.4 逻辑架构详解----MO架构
3.4.1 MO, MMO是什么?----同时在线数的区别
对游戏玩家来说, "同时能跟多少其他玩家一起进行游戏"这一点对游戏体验产生了决定性的影响. 在表示同时在线数的区别时, 最重要的术语就是MO和MMO
- MO (Multiplayer Online)(MOG)
同时在线数为2~100人的游戏称为MO(MOG). 这类游戏的游戏时间相对较短, 一般在几个小时之内就能结束, 每次开始游戏时, 游戏的状态都会被重置. 游戏数据的形式是一次性的(disposable)
- MMO (Massively Multiplayer Online)(MMOG)
同时在线数达到数百, 数千以上的游戏称为MMO(MMOG). 因为游戏参与人数众多, 所以游戏时间通常长达几十个小时, 而且也不能重置游戏数据. 游戏数据的形式是永久性的(persistent)
现在, 同时在线数与网络的物理结构已经划不上等号了, 但是基本上会采取以下方针
- 同时在线数少(MO), 采用"同步方式"和"异步方式"
- 同时在线数多(MMO), 采用"浏览器方式"
MMO和MO的混合
此外, 作为现在的市场上的另一种趋势, 又出现了第三种形式, 也就是同时使用MO和MMO的混合架构,这种架构的游戏也为数不少. 根据游戏的策划内容, 想要同时兼具MMOG的优点和MOG的优点时就会采用这种混合架构, 它成为了从MMO游戏启动MO游戏的形式. 在MMO游戏中, 游戏玩法涉及很多方面, 可以在特定的场所, 与特定的敌人作战时采用MO架构, 也可以在每次进行游戏时对一部分游戏状态进行重置, 还可以解决带宽. 比如, 在Wow中, 地面上的地图和大部分的地下城(Dungeon)都是以MMO架构来实现的, 而那些供少数人重复在短时间内进行游戏的暂时性的地图则是以MO架构来实现的, 通过这种方式将两种架构结合了起来.
3.4.2 MO架构,MOG
MO架构经常在FPS和RTS(Real-time Strategy, 即时战略)等类型的游戏中使用. 这种架构适合那些在线人数较少, 实时性很高的游戏
MO架构
- 同步方式/全网状结构
- 同步方式/星型结构
- 异步方式/全网状结构
- 异步方式/星型结构
3.4.3 同步方式----获得全体玩家的信息后, 游戏才能继续
同步方式是一种只有在获得了全体玩家的信息之后, 游戏才能继续进行下去的方式.
同步方式/全网状结构就是, 参与游戏的所有终端都拥有主数据, 这些终端互相传输所有的控制设备输入信息, 在获得所有终端的输入数据之前, 游戏始终处于等待状态.
同步方式/星型结构是, 配置一个综合管理游戏数据的根服务器, 所有参与游戏的终端(客户端)将玩家的所有输入信息发送至服务器, 游戏状态一旦有所进展, 服务器就将那些改变了的状态数据返回给所有客户端. 在服务端返回信息之前, 所有的客户端都不进行任何渲染, 只是单纯地等着
3.4.4 同步方式/全网状结构的实现----所有终端都拥有主数据
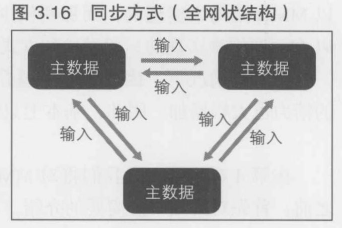
各个终端所持有的数据全都是"主数据", 所以不会复制任何信息. 而且各个终端通过网络互相传输的都只是控制设备的信息(比如按下方向键, A键, B键等), 所以在图3.16中标为"输入".所有的终端都会将这些输入信息发送给除了自己以外的其他各个终端.

各终端(玩家)收发的信息内容
这里有一点很重要, 那就是各终端之间只发送"控制设备的输入信息".游戏过程数据都是数字数据, 所以如果能毫无遗漏地发送初始状态及其对应的变更部分,所有玩家的状态就能始终保持一致了
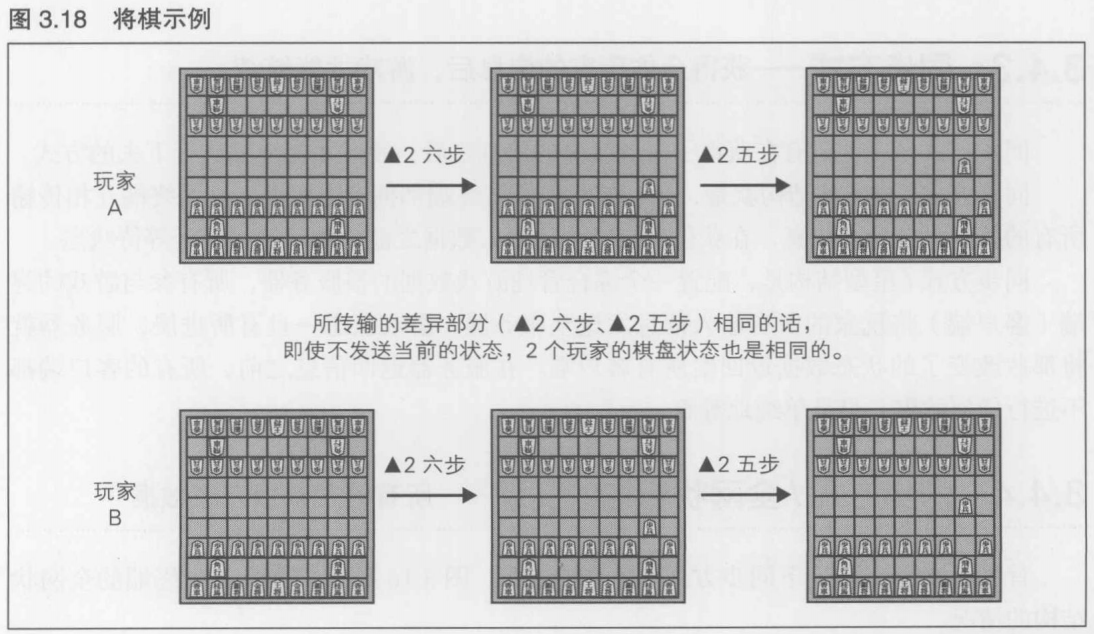
在将棋中, 玩家A和玩家B在初始状态下是相同的. 从初始状态开始, 如果只发送了"2六步"这样的输入信息, 那么, 即使不发送当前的棋盘状态和其他棋子的状态,两个玩家的棋盘状态也是相同的
有3个玩家的情况下, 各个玩家之间收发的信息内容如图3.19所示, 从图中可知, 游戏状态每次有所进展时, 所有终端都将把各自的信息发送给其他终端, 从而玩家A,B,C都接收到了相同的输入信息
当从状态1进入状态2时, 各个终端都向其他终端发送输入信息, 当所有终端都收取完成时就进入状态2. 此时, 输入的内容在所有的终端上都是相同的, 所以作为处理结果的状态2也是相同的. 然后到状态3, 状态4......一直这么持续下去
同步方式/全网状结构的必要条件和优势
到此为止所说明的同步方式/全网状结构, 有没有觉得它有点"危险"?事实上确实如此
首先我们来看一下这种结构的前提条件和它的优势
为了使之前的假设成立, 必须满足以下几个条件
- 初始状态完全相同
- 所有的输入信息数据包都确确实实地, 毫无遗漏地发送至其他所有终端
- 游戏过程数据不会随机变化(如果是结果完全相同的伪随机数也没有问题)
- 游戏过程数据的变化不会发生波动.具体来讲, 比如输入有限资源的数据包不会互相竞争到达的顺序, 不会因为微妙的时机问题产生不同的结果,等等
以上的4个条件并不难满足,只要游戏程序做到以下几点, 就能简单地满足这4个条件
- 伪随机数的种子在所有终端上都保持一致
- 所有终端都以完全相同的数据来初始化游戏
- 循环开始
- 所有终端开始进行输入信息的的传输,在全部接收完成前始终处于等待状态
- 按照玩家A~Z的顺序进行处理, 依次改变游戏状态
- 渲染
- 受理下一个操作
- 发送自己这部分的输入信息
以前的家用机游戏基本都是按照这几点来实现的. 循环中的a处并不检查本地的控制输入, 只要检查来自网络中的输入, 本地的双人游戏就可以支持网络功能了.这种方式的优点是:使用一般的方法开发的游戏能够很容易地支持网络功能, 而且可以使程序非常简单
同步方式/全网状结构的3个问题----通信网和收发信息在完整性上较为脆弱,中途加入游戏
此前说过同步方式/全网状结构有点"危险",这种结构存在着以下3个问题
- 人数增加后, 收发信息的完整性极易崩溃
- 最慢的终端会拖长整体的传输时间(这个问题是同步方式普遍存在的)
- 不能中途加入游戏
3.4.5 同步方式/星型结构----暂时将输入信息集中到服务器上

在这种情况下, 网络中的所有成员并不是完全平等的, 星型结构的中央终端称为"服务器",其他终端则称为"客户端". 客户端将控制设备上的方向键等输入信息发送至服务器, 服务器在接收完所有客户端发来的输入数据前一直处于等待状态,接收完成后则将接收到的输入信息同时发送给所有客户端
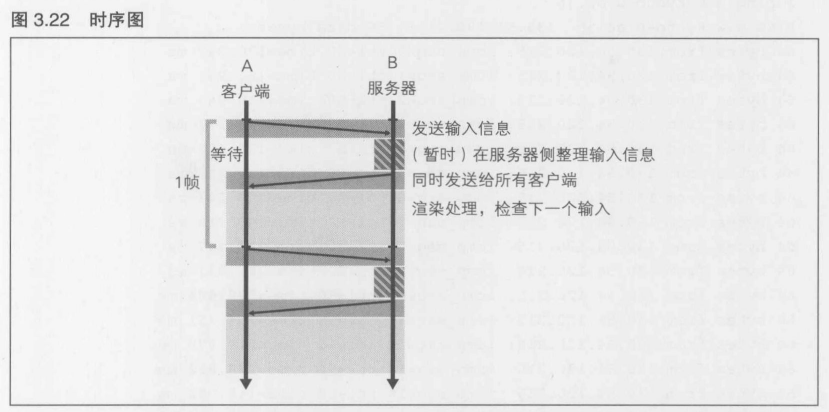
在图3.22中, 玩家A这一端是客户端,玩家B这一端则是服务器. 在最初的1帧中, 首先A向B发送输入信息, B侧接收该信息,等到接收完所有客户端的输入信息后就将其发送给A.对玩家B来说, 这些输入信息就这么原封不动地反映在自己管理的游戏数据中再加以显示就可以了,所以不需要传输. 星型结构的特点就是"暂时将输入信息集中到服务器上",这一点与全网状结构不同.
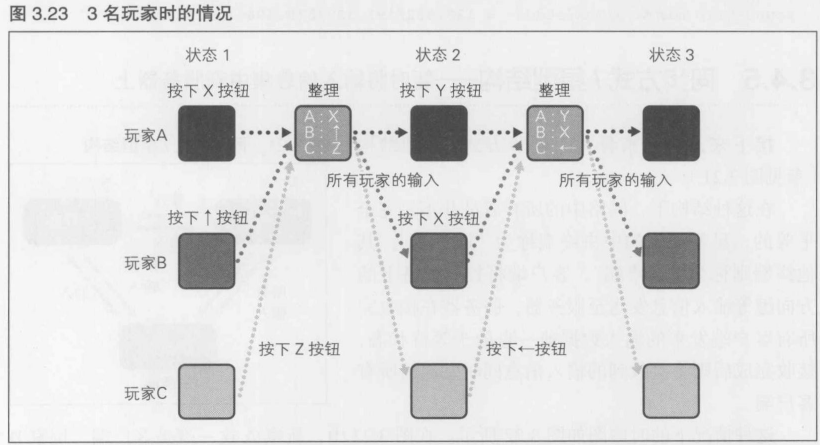
玩家数为3时的情况如图3.23所示. 在从状态1进入状态2之前, 首先将所有终端的输入信息全部集中到玩家A的终端上, 它作为所有终端的代表来接收输入信息
图3.23这种方式的最大优点就是, 所需增加的传输线路与所增加的玩家数的一次方成正比. 传输线路不会爆发性地增长, 所以发生游戏数据不一致的概率将大幅降低. 从这个意义上来说, "危险的感觉"确实比全网状结构来得薄弱
星型结构的4个问题
- 响应较慢
- 如果玩家A中途离线, 游戏无法恢复, 只能强行中止
- 信息整理方面的逻辑增加时, 程序的结构比全网结构稍稍复杂一些
- 玩家A的终端上的传输负荷比其他终端高出许多, 不甚公平
同步方式不可避免的重大问题----不能中途加入游戏

在图3.24中, 新加入的玩家C可以向任何一个玩家要求当前的游戏状态(这里是玩家B), 这个例子中由玩家B返回游戏数据.如果这里的数据量达到1兆字节, 仅仅是传输就需要花费好几秒. 在这段时间内, 游戏的状态不能改变, 所以不仅仅是玩家C,所有的玩家都必须暂时中断游戏。这里所说的"不能中途加入游戏"就是因为"在中途加入游戏的这一刻, 为了传输游戏数据, 所有玩家都必须长时间停止游戏"
同步方式的优势和问题解决的方法
不管是星型结构还是全网状结构, 只要使用的是同步方式,就能简单地保存程序内容, 这是一个很大的优势, 所以有时会为了使用同步方式而采取各种各样的方法
为了使用同步方式, 可以采用以下方法
- 像竞速游戏和对战游戏这样, 在几分钟之内结束一回合的游戏(竞速和比赛), 这样就没必要中途加入游戏了
- 考虑玩家匹配系统, 优先匹配地理位置相近的玩家
以上我们讨论了同步方式的两种结构: "全网状结构"和"星型结构". 不管使用哪种结构, 每个终端都要在"获得全体玩家的信息后, 才能继续游戏",这一点是最基本的, 所以根据传输线路的可靠性和延迟的长短, 玩家人数在达到一定程度后就不能再继续增加了
3.4.6 异步方式----接受各终端上游戏状态的不一致
与同步方式相同, 异步方式也有全网状结构和星型结构这两种实现方式
异步方式的最大特点就是: 各个终端上的游戏状态是不同的, 也就是说, 在游戏数据的一致性方面作出妥协, 不要求数据完全一致
由于这种妥协, 比起同步方式, 在异步方式下可以使用更加不稳定的传输线路和延迟更大的线路, 也可以支持更多的同时在线数.但是另一方面, 程序相较于同步方式j就略显复杂了些,而且在有些情况下游戏体验也更差一些
异步方式下实现方针的制定方法----对游戏内容的详细分析是不可缺少的
在异步方式的实现方面, 应该对什么样的游戏数据做出何种妥协完全依赖于游戏内容. 在同步方式下, 选择了全网状结构或者星型结构后就自动决定了相应的实现方式,但是在异步方式中,对游戏内容的详细理解和分析是不可缺少的
3.4.7 三大基本要素: 自己, 对手, 环境----异步实现的指导方针
首先将构成游戏世界的基本要素分为三大类: "自己的状态", "对手(们)的状态","环境状态". 可以说这些就涵盖了游戏中的所有基本要素
"自己"指的是, 在可以直接操纵虚拟人物(avatar)的游戏中, 玩家自己所操纵的角色. "自己的状态"就是指该角色的坐标, 剩余体力, 装备, 剩余战机数, 等等. 如果操纵的不是单个人物, 而是一个群体或者一个军队, 那么"自己的状态"就是指这个群体的状态. 而在那些像俄罗斯方块这样的完全没有人物登场的益智游戏中,指的就是正在往下掉落的屏幕最中间的那个可以直接操纵的物体的状态. 总而言之, 就是处于自己控制下的, 自己必须注意的一系列数据
"对手"则是指必须注意的其他玩家的一系列数据. 玩家之间基本上是对等的, 所以自己必须注意的角色所具有的信息量对于对手来说也是相同的
“环境”就是指掉落在地上的物体, 天气情况, 敌人的状态等所有不属于任何玩家的东西. 在俄罗斯方块这样的游戏中, 已经堆叠在下方区域中的方块就是"环境"
三大要素之间的关系
- 自己和对手
- 自己和环境
- 环境和对手
这3种关系中, 哪些比较重要呢? 1, 2两点不管在什么游戏中都非常重要, 而3就不怎么重要了
3.4.8 (1) 自己和对手----对战游戏和玩家之间往来数据的抽象程度
在网络游戏中, 玩家与玩家直接对战以一决胜负的游戏称为PVP(Player versus Player), 这类游戏拥有着以男性玩家为主的庞大市场. 玩家之间进行对战以决出胜负是充满乐趣的. 以玩家之间进行激烈交锋为中心的PvP游戏主要有对战格斗游戏,FPS这样的射击游戏,竞速游戏, 以战争为主的MMORPG等
格斗游戏的例子
首先假设有两名玩家: 玩家A,玩家B各自进行操作.画面的显示每16毫秒更新一次. 在日本国内使用互联网提供的对战游戏服务,数据包延迟几帧是很有可能的,所以必须考虑到通信延迟的问题

攻击, 防御, 碰撞检测
玩家的动作分为攻击, 防御, 被打倒三种. 受到攻击后会被打倒在地,每次被打倒就会计算伤害值,一旦达到最大值就判为负. 当前的伤害值总是会在画面上方的横条中以易于理解的方式显示.游戏中最重要的就是通过组合击打,踢腿等基本动作,首先对对方造成一定量的伤害
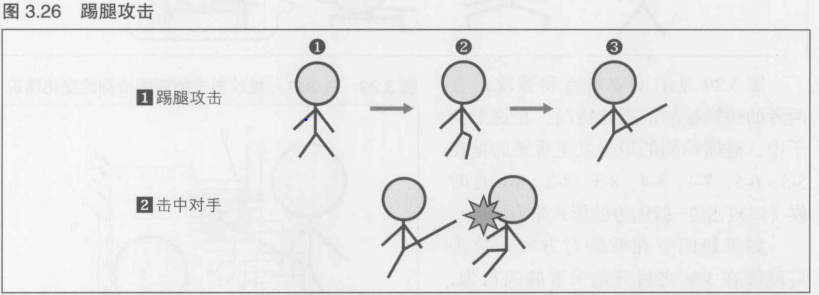
图3.26 [1]中的(1)~(3)是基本动作中的踢腿攻击. 在图3.26 [1]中将这个动作分解成了 (1)~(3)这3种形式进行了说明, 但是一般来讲, 从按下按钮开始, 就会立刻流畅地开始踢腿动作的动画, 通常使用200~500毫秒,也就是10~30帧来表现整个动作. 在3D游戏中,这样的动画称为"Motion"
如果在攻击动作进行时命中了对手,那么就如图3.26 [2]所示, 对手被击倒了
在显示攻击动画的状态下, 每一帧都要对不同的坐标进行碰撞检测. "碰撞检测"就是判断攻击是否命中了对方角色,这是游戏开发中的一个基本术语
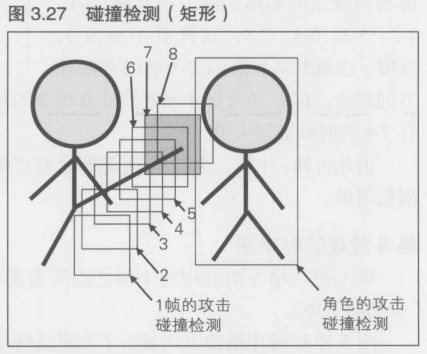
图3.27中, 在总共8帧的踢腿动作中, 与对战对手的角色进行碰撞检测时, 在第7帧时两者的矩形首次发生了重叠. 如果对手完全不动, 玩家开始攻击后, 就会在第7帧,也就是大约116毫秒(16.6 x 7)后命中对手. 攻击命中后, 就会中断第8帧的动画显示,如果游戏规则允许后续动作的话, 玩家可能在那一瞬间进行操作

另一方面, 被攻击的一方可以采取躲闪行为而不是站在原地不动.
与攻击方一样, 采取下蹲行为的角色的碰撞检测也是随着时间变化的
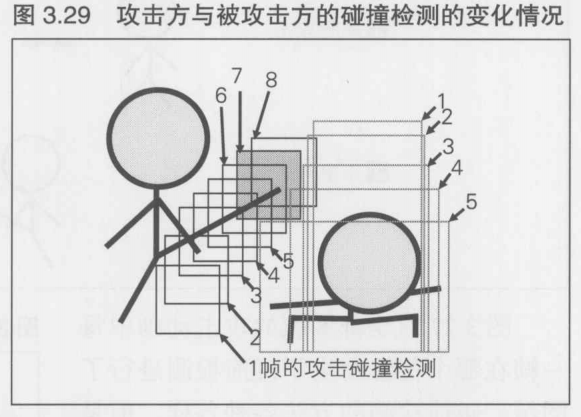
图3.29显示了攻击方和被攻击方两者的碰撞检测的变化情况. 在这个例子中, 碰撞检测的矩形发生重叠是在 5-5, 6-5, 7-4, 8-4, 8-3, 8-2, 8-1 的时候(以攻击方-躲闪方的形式来表示)
如果躲闪方在看到对方发动攻击后能够在3帧之后开始采取躲闪行为, 那么两者之间动画帧的关系就是: 3-1, 4-2, 5-3, 6-4, 7-5,这样就不会发生碰撞, 也就意味着躲闪方能够闪避掉对方的攻击.但是如果在4帧之后才开始躲闪行为,那么就是4-1, 5-2, 6-3, 7-4, 可见, 在7-4的时候被踢中了
由此可知, 1帧, 也就是16毫秒之差直接关系到游戏中的所有动作,从而影响了对战的结果
格斗游戏的时序图
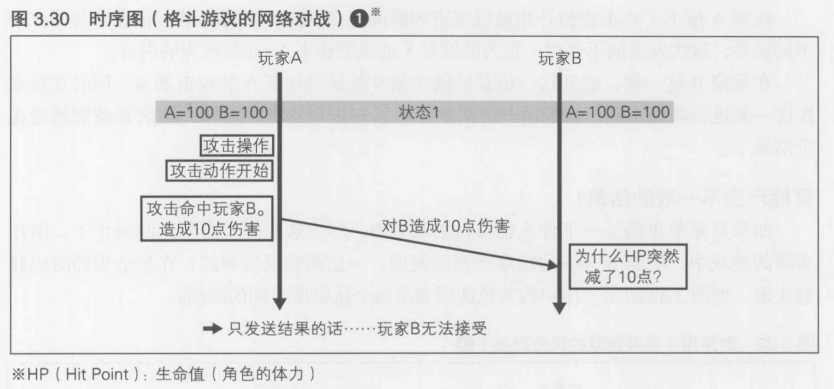
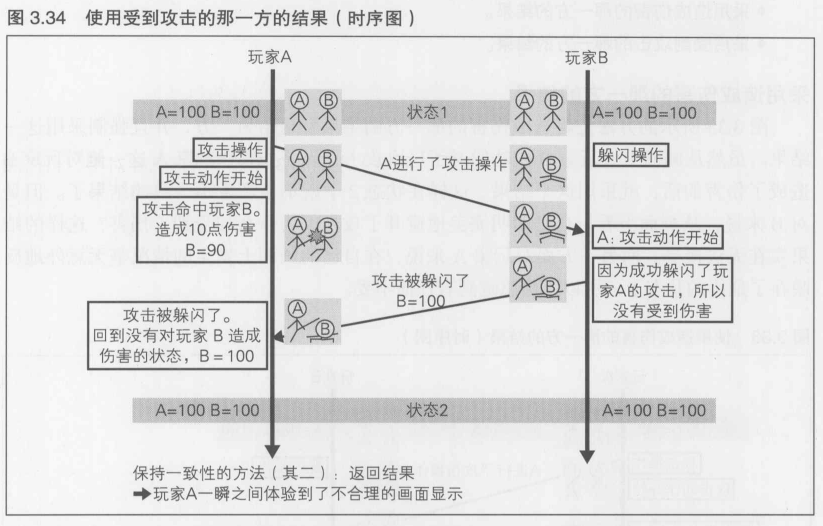
图3.30以时序图的方式显示了在对战格斗游戏中进行1次攻击时, 玩家A和玩家B之间的关系. 横向的箭头表示传输的内容和方向,为一个数据包.为了表现通信延迟,将这个箭头向下倾斜了一下.时间顺序以向下的方式表示.围在长方形中的内容是各个玩家的行动和体验
每个玩家的角色在初始状态下拥有的伤害量都是100点,受到伤害后该数值就会减少,首先减至0的玩家算败北.以A=100, B=100这种记法来表示该时刻下的剩余伤害量
在初始状态(状态1)下, 玩家A和玩家B看到的状态是完全相同的.在图3.30所示的最初的时序中, 发送了游戏结果(玩家B受到了伤害),但是只是突然发送一个结果的话,玩家B无法获得产生这一结果的信息,所以也就无法理解和接受这样的游戏结果
必须发送抽象度较低, 表示原因的数据----对结果的接纳感
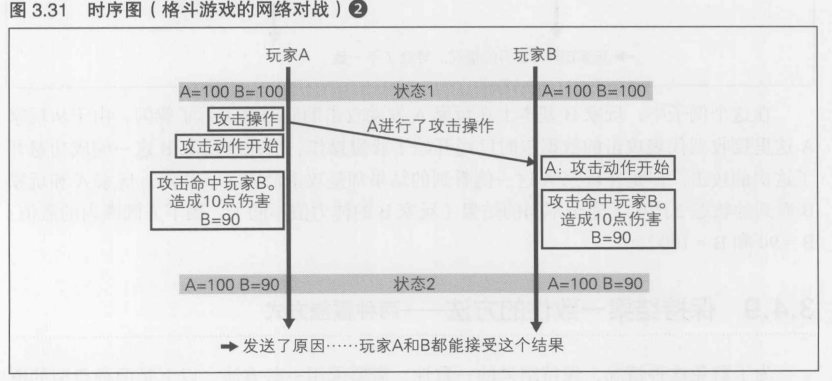
格斗游戏中的格斗过程是非常重要的,所以必须发送造成伤害这一"结果"的"原因".如果将其以"抽象度"这样的概念来表示,就是"因为在格斗游戏中,具体的格斗过程对游戏来说非常重要,所以必须发送抽象度较低的数据"
玩家A按下了攻击按钮开始进行攻击的瞬间,立刻向B发送了这一信息.与图3.30不同的是, 这次发送的不是这一行为的结果(造成的伤害),而是行为的内容
在玩家B这一侧,收到这一信息后就立刻开始显示玩家A的攻击动画. 同时在玩家B这一侧进行碰撞检测,攻击命中的话就对玩家B造成伤害. 这样, 玩家B就能接受这个结果了
可能产生不一致的结果!
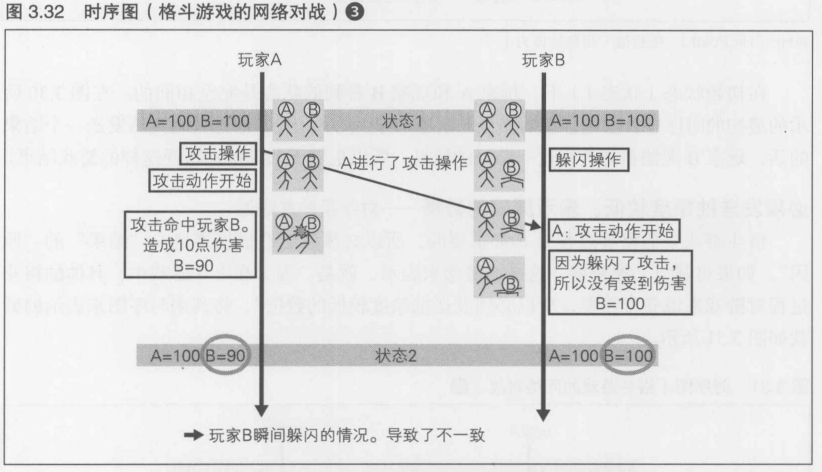
如果只是单单踢了一下什么也没做的玩家B,那么这次的攻击就到此为止了.但在实际的游戏中,玩家B会一边揣摩比赛的发展, 一边调用反应神经, 在最恰当的时机躲避攻击
在这个例子中, 玩家B基本上在玩家A发动攻击时的同时就进行了躲闪,由于从玩家A这里接收到代表攻击的数据包时已经开始了躲避操作, 所以在玩家B这一侧成功避开了这次的攻击.但是在玩家A这一侧看到的结果确实攻击命中了.从而, 玩家A和玩家B看到的状态2产生了完全不同的结果
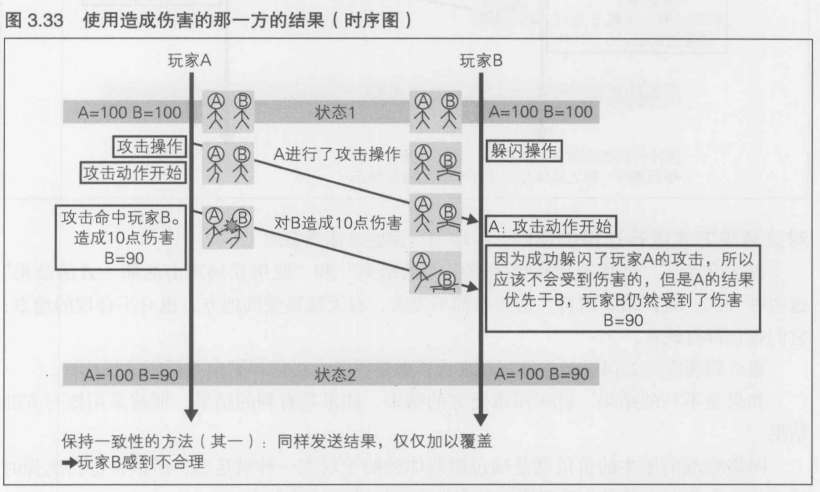
3.4.9 保持结果一致性的方法----两种覆盖方式
为了避免这种情况, 保持结果的一致性,需要采用一些方法.以下是两种典型的覆盖方式
- 采用造成伤害的那一方的结果
- 采用受到攻击的那一方的结果
采用造成伤害的那一方的结果
采用受到攻击的那一方的结果
对这两种方式进行选择的原则----增加玩家的总体满意度
以上介绍了"使用造成伤害的那一方的结果"和"使用受到攻击的那一方的结果"这两种方式.就其结果而言,这两者都不完美,有无法接受的地方,也有不合理的地方,它们各自都有缺点
那么到底应该如何进行选择呢?在大多数情况下,可以根据以下原则进行选择
如果是不利的结果,就采用承受方的结果.如果是有利的结果,那就采用施与方的结果
网络游戏的原本的价值就是通过游戏体验给给予玩家一种满足感,所以在进行选择时就要从这个角度去考虑,采用能给玩家带来更多满足感的方法
比如在之前所举的格斗游戏中,进行攻击以对对方造成伤害的这一行为,对于受到伤害的这一方来说是绝对的不利情况,所以使用被攻击方的结果, 而不是攻击方的结果.受到损害的玩家为什么受到了损害,如果不能对此做到正确把握,就无法使玩家获得满足感
与此相对, 如果是在多人动作游戏中给同伴回复体力的这种使对方获利的行为,即使在对方的画面上碰撞检测并不成立,但是仍然使其得以回复,那么该玩家就会感到非常满足
能够通过上面这个方针来判断的只有那些"自己与对方之间存在直接的得失关系,以及游戏响应非常重要"的内容.以直接的得失关系为主,而且响应又很重要的游戏包括对战格斗/FPS这类互相攻击的游戏, 以及竞速游戏等, 这类游戏需要更为具体的,与游戏过程相关的信息,所以需要尽可能频繁地发送抽象度较低的数据
3.4.10 (2) 自己和环境----可使用物品的格斗游戏和互斥控制
"环境"就是既非自己也非对手的东西, 包括地面等背景, 掉落的物品,共同的敌人,天气情况,等等. "环境"要素根据"是否需要互斥控制"分为两大类
需要互斥控制的环境要素----互相竞争的资源"炸弹"
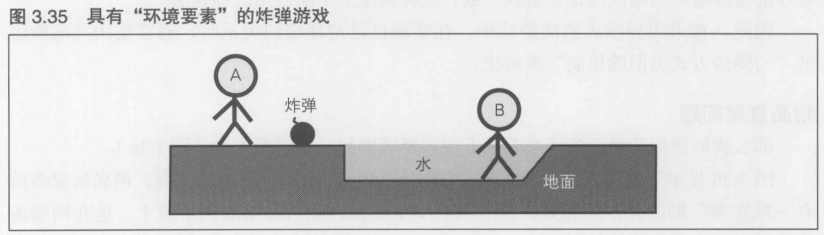
在图3.35所示的游戏中有一条规则: 在比赛场上会落下一颗炸弹, 而且只有这一颗,首先拾得这颗炸弹的玩家可以用它给对方造成极大的伤害.在这种情况下, 一旦某个玩家首先得到了这颗炸弹,就必须确确实实地将其消除, 不能再次获得它.这种类型的游戏资源称为"互相竞争的资源".对战双方中只有一名玩家能够获得炸弹,这条规则是游戏可玩性的关键所在,所以绝对不能二度获得.这就是"需要互斥控制的环境"
不需要互斥控制的环境要素----不会减少的资源"水"
与此相对, 图3.35所示的游戏还有一条规则: 在水中的玩家, 移动速度和攻击速度减半. 在这种情况下, 虽然用到了"水"这个元素, 但是它并不会减少, 所以这是种不需要互斥控制的环境.一般来讲, 在不需要限制事项发生次数的,或者事项的发生不会造成环境变化的, 不需要向全体玩家告知这种变化的情况下,就不需要互斥控制
游戏中的环境要素极难处理----必须详细理解游戏内容
环境的变化经常会导致玩家很难明确判断自己和对手之间的得失关系
比如, 由于炸弹能给对手造成伤害, 所以起初会觉得如果自己得到了炸弹, 对手就明显处于不利状态了.但是如果这个游戏还规定,炸弹使用不当也会给自己造成伤害,那情况又如何呢?或者, 在有第3个玩家----玩家C的情况下,玩家C被炸弹击倒后对玩家B来说或许更有利了.又或者, 使用炸弹可以在地面上炸个洞出来,如何利用这样的地形,这之间的得失关系还要在之后才能确定
在游戏中, 自己和环境要素之间的关系并不像自己和对手这么直接,而是一种间接的关系.但是因为也有像炸弹这样会造成强大威力的元素,所以为了避免出现问题,必须进行一些技术处理
3.4.11 互斥控制的实现----采用与同步方式类似的机制来实现异步方式
上面简要介绍了一下互斥控制, 但是异步方式下的互斥控制实现起来并不容易, 虽然已经采用异步通信发明了一致性算法(Consensus Algorithm), 在Google的服务器内部也有使用. 但是这种算法需要多次往返传输消息,采用异步方式的网络游戏需要在几十毫秒的这段极短的时间内保证数据一致,这种情况下不能使用这种算法
因此, 在采用异步方式的游戏中, 在实现自己与环境的关系时, 通常使用之前所说的"与同步方式类似的机制"来解决
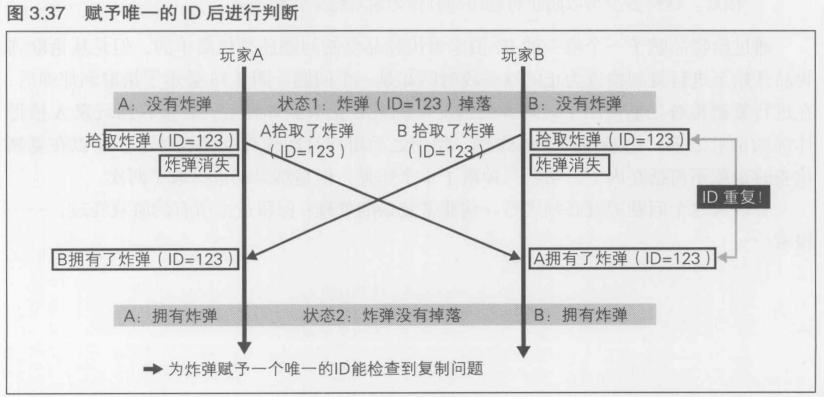
物品复制问题

图3.36显示了从"状态1: 掉落1个炸弹"到"状态2: 不掉落炸弹,两名玩家各持有一颗炸弹"的时序.问题是, 明明只有一个炸弹, 最后却增加到了两个.这在网络游戏的术语中称为"物品复制"(Item Dupe),也就是说游戏内的物品被复制了
在网络游戏中,由于没有解决这一问题(可能在经过考虑之后决定置之不理)而导致物品复制现象猖獗,最终缩短游戏寿命的例子数不胜数.无论如何, 这个问题都必须解决
一开始, 只有1个炸弹掉落画面,玩家A和玩家B可以在短于传输所需的时间内取得炸弹, 于是就发生了物品复制. 这种类型的复制可以有意而为,比如, 在可以"放置炸弹"的情况下, 反复进行炸弹的放置, 拾取操作,几次里有1次是在微妙的时刻进行了操作, 就能够进行复制
给物品赋予唯一的ID----判断物品是否被复制, 发生的问题
通过为炸弹赋予一个唯一的ID,可以判断物品是否被复制了.如果能够判断是否发生了物品复制,接下来就可以采取以下这些手段
- 被复制了的物品毫无疑问要消除
获取物品是构成玩家满足感的基本要素, 所以要消除相当有害的物品(比如《超级马里奥兄弟》中碰到后就会受到伤害的毒蘑菇等)时不能使用这种方法
- 允许复制
如果存在有意进行反复操作的玩家,物品"以稀为贵"的价值就降低了, 从而导致玩家满足感降低,游戏寿命缩短.但是, 如果该物品对游戏过程的影响很小,只是用于显示则可以进行复制
- 通过某些规则确定优先级最高的玩家
将物品给予优先级最高的玩家, 而从优先级较低的玩家处剥夺该物品的所有权.比如, 玩家ID号小的玩家优先,偶数号码的玩家优先; 或者等级较低的玩家,刚开始游戏的玩家优先等.考虑到应尽可能不让玩家的满足感降低,或许让刚开始游戏的玩家优先获得物品更为自然.但是这也可能产生一个弊端: 有经验的玩家申请多个账号,假装自己刚开始游戏
- 使用专用的交易接口来解决
发生物品复制时, 会有一种"发生物品复制了, 谁猜拳决定"的感觉,为此, 可以采用专门用于解决复制问题的接口.但是在这种情况下, 直到从所有相关的玩家处获得猜拳结果之后才会决定由谁获得该物品, 这一点可以部分引入同步方式来解决
- 允许复制,但是通过其他方法减小影响
比如在游戏结束时检查物品总数. 如果游戏结果保存在服务器中, 可以将最大值设为每天10个,在保存时进行检查,超过最大值的话就无法保存或者弹出警告或者进行封号判断.此外还有种方式,事先共享"物品最多可能出现5个"的信息,之后进行核对.这样多少可以防止将超出部分作为游戏结果保留下来
通过给物品赋予一个唯一的ID值来解决物品复制问题还是很简单的, 但是从拾取到物品开始至进行复制检查为止的这一段时间却是一个问题.图3.38显示了拾取到炸弹后, 在进行复制检查之前使用了该炸弹的情况. 玩家B拾取到炸弹后,在接收到玩家A拾得炸弹的消息之前,已经使用了该炸弹.使用之后所持有的炸弹就消耗掉了,所以在复制检查时也就不包括在内了.明明只掉落了1个炸弹,但是结果却被拾取了两次
要解决这个问题就必须进行一些非常复杂的处理: 保留过去所有的游戏经过,一一检索
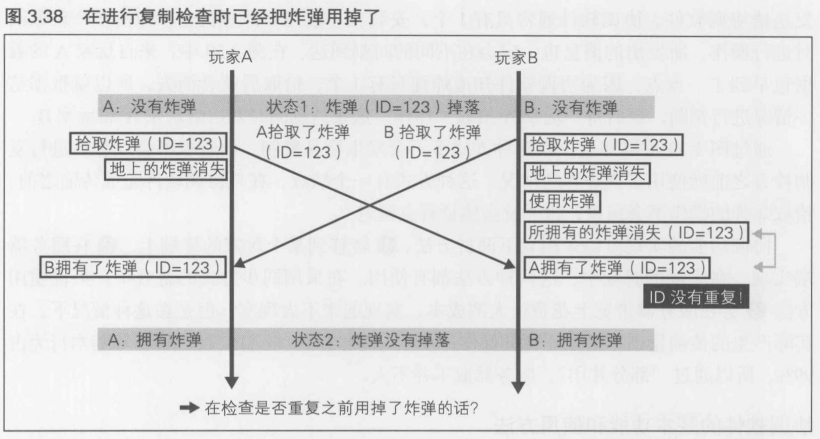
物品复制的解决对策----由专门的软件负责协调
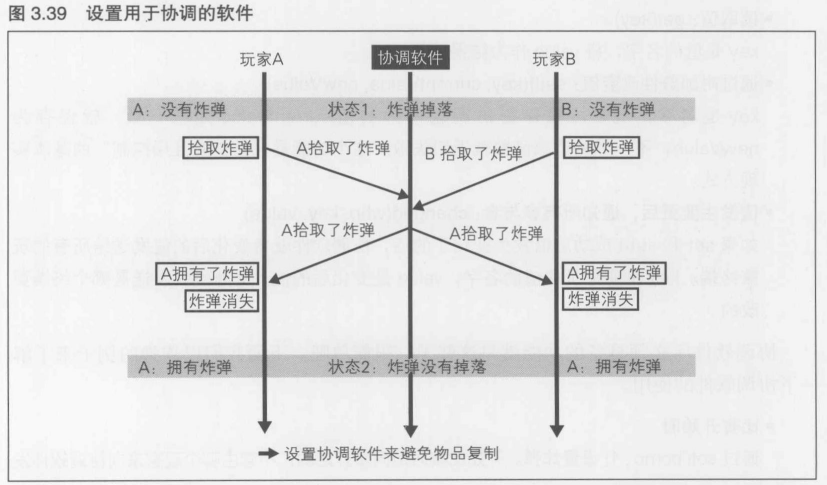
在图3.39中, 在玩家A和玩家B之间设置了协调软件,将获得炸弹的相关操作首先发送给协调软件.协调软件通常只有一个,安装在计算机上,即使多个玩家同时进行操作,所发出的消息也一定会在不同的时刻到达. 在图3.39中, 来自玩家A的数据包早到了一点点,因为协调软件知道炸弹只有一个,拾取后就会消失,所以就根据这一情况进行判断, 最后将"玩家A拾取了炸弹"这条消息同时发送给玩家A和玩家B
通过图3.39可以知道, 在这种情况下不会发生物品复制.而且也不会发生在进行复制检查之前就使用了该炸弹的情况. 这种方式有一个缺点,在与协调软件完成传输之前,拾取炸弹的操作不会结束,这样就会感觉有点有延迟
协调功能的实现可以采用如下两种方法: (1) 转移到某个玩家的终端上, (2) 在服务器端实现. 在实际的游戏中, 这两种方法都有使用. 在采用同步方式的游戏中, 虽说使用方法(2)会在服务器带宽上花费很大的成本,实现起来不大现实,但是在这种情况下, 在实际产生的传输量中,拾取炸弹的操作占1%, 除此之外, 击打, 踢, 移动等基本行为占99%, 所以通过"部分并用",服务器成本并不大
协调软件的基本功能和使用方法
不管使用上述(1),(2)的哪种实现方法,协调软件的基本功能都是相同的.下面以伪代码的形式(类似于Java)对这些功能进行说明
- 为值赋予一个名字来保存:set(key, value)
key是赋予值的一个名字, value是要保存的值
- 读取值:get(key)
key是值的名字, 将value作为结果返回
- 通过附加条件改变值:setlf(key, currentValue, newValue)
key是名字, 现在, 保存在协调软件内的值currentValue如果一致, 就保存为newValue, 不一致的话该函数就返回失败.这个功能是"完全的互斥控制"的基本实现方式
- 值发生变更后, 通知所有参与者: changed(who, key, value)
如果set和setlf成功后值发生变化了的话, 协调软件就将变化后的值发送给所有的玩家终端.key是变化了的值的名字,value是变化后的值.另外也会发送是哪个终端更改的
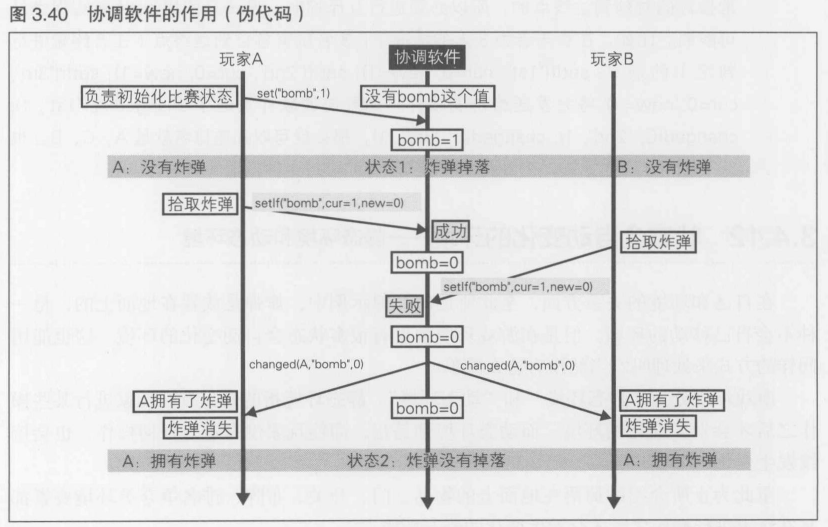
协调软件所必须具备的功能就是这些了, 很简单吧. 下面我们以炸弹的例子来了解以下协调软件的使用
- 比赛开始时
通过set("bomb", 1)设置炸弹.开始比赛时是同步开始的, 不管由哪个玩家来向协调软件发送必要的信息都没有问题. "1"这个值以"bomb"为名进行保存."1"就是炸弹的个数
- 比赛中
拾取炸弹时调用setlf("bomb", currentValue=1, newValue=0),只有当炸弹在协调软件内部为1个时,这条语句才会成功地将值更改为0,然后发送changed("bomb", 0).如果玩家A和玩家B同时拾取了炸弹,协调软件就会收到两次拾取炸弹的消息. 但是changed("bomb", 0)只会群发一次
在图3.40中, 首先玩家A负责比赛状态的初始化(由玩家B负责也可以).然后炸弹掉落, 进入状态1
接着在游戏的进行过程中, 玩家A和玩家B几乎同时拾取了炸弹,然后向协调软件发送了同一个函数.在协调软件中,调用setIf函数进行处理. 因为cur=1,new=0,只有在当前值为1时才会成功写入0.在从玩家B处接收到拾取炸弹的消息时,协调软件已经完成了对玩家A的操作的处理,所以当前值就改为0了, 此时setIf返回失败.因此, 协调软件向所有玩家发送表示"数据被玩家A改变了"的消息: changed(A, "bomb", 0). 接收到这条消息后,各个终端都能意识到是玩家A获得了炸弹,然后消除显示在画面上的炸弹
炸弹以外的环境要素
在实际的游戏中, 除了炸弹之外, 还有其他各种各样的环境要素, 但是基本上都可以通过组合以上所述的协调软件的功能来实现
- 放置的物品只能获取1次(炸弹的例子就与此对应)
- 门和开关, 控制杆
起初是关上的, 之后只能打开一次
这种情况下不需要互斥控制, 只要发送set("door", OPEN)就可以了
每一次操作都可以关上打开着的物体, 打开关着的物体
这种情况下实际上也不需要互斥控制. 如果在玩家A这一侧, 门是打开着的, 而玩家A又没有进行操作, 不需要发送set("door", CLOSED)的话, 就只要发送set("door", OPEN)就可以了
- 布阵
如果只能获取一次的物品以日本地图的形状来配置多个, 也只是归结为有很多炸弹的问题.地形的变更也是同样
- 争夺排名
在竞速游戏中, 必须确定作为比赛结果的排名, 在胜负难分的情况下,由于是在非常接近的时刻到达终点的, 所以必须进行互斥控制.设法只使用setlf来实现也是可能的. 比如, 在参与者为3人的情况下, 3名玩家给自到达终点(在各终端进行判定)的消息: setif("1st", cur = 0, new = 1)将会发送给协调软件.如果协调软件发送了changed(A, "1st", 1); changed(C, "2nd", 1); changed(B, "3rd", 1),那么就可以知道排名就是A,C,B.也有不使用这样的方法, 在协调软件中实现专门进行这种处理的功能
3.4.12 状态会自动变化的环境----静态环境和动态环境
动态环境引起的问题----很难完全并行管理
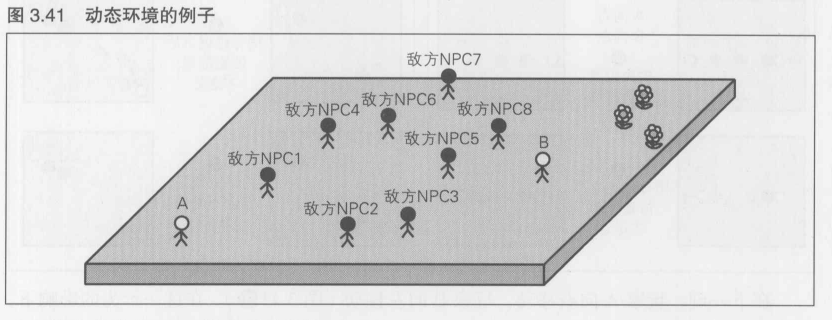
在图3.41中, 平坦的地面上有玩家A,玩家B,以及8名地方角色.地方角色由程序控制.这种由程序控制的角色在技术术语中称为NPC(Non-Player Character).NPC编号为1~8号
即使玩家不进行操作, NPC也会自己行动,也就是说,移动, 踢, 拾取炸弹等行为都是自动进行的. NPC通常具有与玩家同等以上的能力. NPC始终运动着, 并非特定玩家的操作对象,所以可以说是动态环境
游戏中地方NPC的典型动作如下:
- 逼近距离最近的玩家(移动)
- 如果玩家进入了攻击范围, 则对其发动攻击(踢)
NPC每16毫秒进行移动等行为, 坐标和速度等状态一直在改变.那么这些NPC的信息存放在哪里的内存中, 由哪里的CPU来进行处理呢?
图3.41的游戏所涉及的只有玩家A的终端和玩家B的终端.NPC的处理就要在其中一方进行
作为最原始的模式. 首先考虑在玩家A,B两方的终端上各自并行进行管理. 游戏刚开始时, 玩家A和玩家B处于完全相同的初始状态下,如图3.42所示.该图比图3.41更为模块化,图中的大四边形代表游戏的整个区域.白色圆圈代表玩家A和B,黑色圆圈代表地方NPC,地方NPC的数量减少到了3个

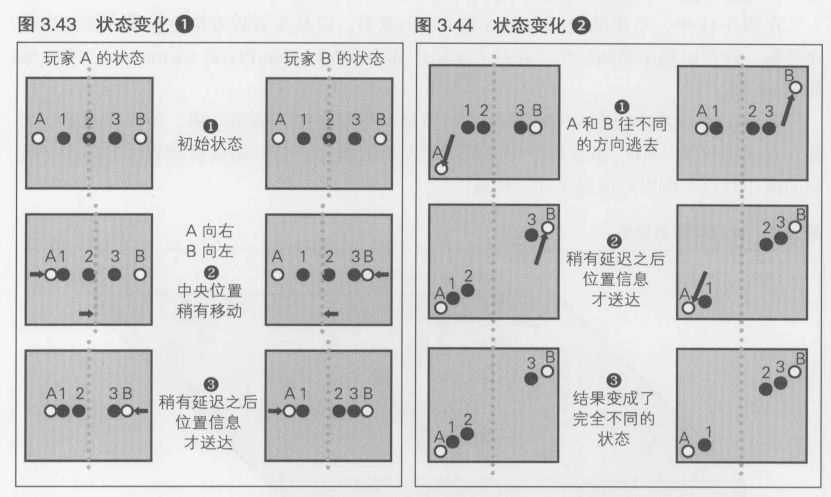
图3.43,3.44 对玩家A和玩家B的状态进行了对比.当然初始状态是相同的
在下一刻, 玩家A向右移动, 玩家B向左移动.在这一行为的影响下, 玩家A和玩家B之间的中心位置在玩家A的终端上稍稍向右偏移,而在玩家B的终端上则稍稍向左偏移.因此, 对于NPC2来说, 在玩家A的终端上,最近的玩家是玩家A,而在玩家B的终端上则是玩家B.在整个阶段中, 由于网络延迟,各个玩家的移动信息尚未送达
结果,在下一个瞬间, 在玩家A的终端上, NPC2为了追赶玩家A开始向左移动, 而在玩家B的终端上则向玩家B的方向移动. 此时, 各个玩家的移动信息终于送达,反映在了画面上
在图3.44中, 玩家A与玩家B往完全相反的方向逃去,但是因为是朝着终点对称的方向移动. 所以中央线的位置没有变化
接着,图3.44, 敌方NPC继续向着最靠近自己的玩家追去,在玩家A的终端上,玩家A被NPC1和NPC2两名敌人追击,另一方面, 在玩家B的终端上,玩家B被NPC2和NPC3追击. 相互之间的位置更新仍然有所延迟
最终, 产生了完全不同的结果.因为NPC "持续追赶距离最近的目标",所以"一点小小的差异累积i起来就会产生极大的差异".在游戏中这种情况是很普遍的
由此可知, 完全并行的管理方式是有很大问题的
解决动态环境所引起的问题的几种选择方案
实际使用的解决方案有如下几种
- 所有NPC的相关信息都在玩家A(或者玩家B)的终端上进行处理
在这种情况下可以很简单地解决之前的问题. 总是按照单个玩家所管理的坐标信息进行处理. 这里的问题是, 不负责处理的玩家对NPC采取踢等行为所产生的结果(对NPC造成伤害)总是通过另一方的终端来发送, 所以很容易感觉到通信延迟.而且因为所有NPC的所有行动都必须通过网络来传输, 所以传输量大增. 尤其是在延迟方面,在游戏内容较为苛刻的情况下会让玩家感到不公平, 可能降低玩家的满足感. 此外传输量问题也导致这种方法无法在移动终端上使用
- 定时修正NPC的位置
继续进行基本的并行处理, 但是定时发送所有NPC坐标,在差异较大的情况下, 强制采用某一个终端上的坐标. 这种方法的问题是,偶尔会发生正在追赶自己的敌人突然消失了, 或者从未存在过的敌人突然出现了的状况. 但是只要能尽可能频繁地进行修正处理,至少能避免突然大规模发生这种现象.实际上不仅仅是坐标,伤害值等信息也必须加以修正.与方法(1)相比, 这种方式用几十分之一的传输量就足够了. 对1秒内发送多次相关信息所需的传输量,与几秒发送一次的情况下所需的传输量进行比较,由此找到最合适的修正频率
- 根据某些规则将NPC进行分组
a. 根据ID编号的奇偶等机械地进行分组
看上去很简单也很不错, 但是通常比起这个方法, 方法(1)更好一些, 比如, 有两名玩家正在进行游戏, 其中一半的NPC有延迟,有延迟的NPC与没有延迟的NPC混在一起, 这种情况下的游戏体验还不如所有的NPC都有延迟
b. 根据某些条件转移管理权限
这种方法相对用得较多. 比如, 根据NPC出现的时间, 在距离较近的玩家的终端上进行管理, 每隔一段时间计算与各个玩家之间的距离, 然后将管理权限转移给最近的那个玩家的终端.在之前所举的NPC"向较近的玩家靠近"的例子中, 这种方法尤为有效.游戏基本上是以逐渐逼近的NPC交互为中心, 使用这种方法可以降低距离自己较近的NPC的延迟, 从而在很大程度上防止游戏体验的恶化.这种方法也有个问题,在转移管理权限时, 必须暂时(大约几百毫秒至1秒左右)停止NPC的行动.传输量比方法(1)少, 比方法(2)多
c. 使用AI管理的信息来进行分组
这也是较为常用的一种方法, 这里所说的AI就是人工智能(Artificial Intelligence),这里所指的并非一般意义上的人工智能,而只是NPC的行为算法.在游戏行业中,即使是"冲向最近的玩家"这样简单的动作也叫作AI
在实际的游戏中, NPC的行为并没有这么简单, 一种典型的方法是, NPC具有一个称为“仇恨值”的数值, 仇恨值可以在敌人受到玩家攻击时增加, 一段时间之后降低. 比如, 某个敌人最初的仇恨值为0, 在受到了玩家A的攻击之后, 该敌人对玩家A的仇恨达到100, 然后该敌人不再逼近距其最近的玩家, 而是冲向仇恨值最高的玩家, 也就是玩家A. 这个仇恨值每过1秒就减少1点,所以1000秒之后该敌人就会忘记玩家A, 不再继续追赶该玩家.而在攻击过后50秒,该敌人对玩家A的仇恨值降低50,此时另一个玩家,比如玩家B向该敌人发起攻击, 该敌人对玩家B的仇恨值就达到了100, 于是转而开始追赶玩家B,但是如果之后玩家B被打倒了,那么该敌人对玩家B的仇恨值就会恢复为0, 然后再次开始追赶玩家A.
采用仇恨值作为基本AI的游戏很多, 在这种游戏中, 基本的游戏玩法就是与跟自己有仇的敌人作战.也就是说, 由于作战对手主要就是这个对自己仇恨值最高的敌人, 所以如果在自己的终端上管理这个敌人,玩家所感觉到的延迟就会降低,从而提高玩家的满足感
3.4.13 (3) 对手和环境的关系
就结果而言, 大部分游戏并不重视自己以外的玩家与环境之间的关系. 比如, 不需要接收"敌方NPC攻击了自己以外的玩家"这样的信息
在很多游戏中,自己以外的玩家的情况只是出于"游戏显示"方面的考虑,只在游戏画面上反映那些必不可少的部分. 这么做的原因有如下几点
- 在游戏画面上表示其他玩家会加重渲染处理的负担
- 增加传输量
- 画面上表示的物体过多的话会引起混乱,导致游戏困难
但是其他玩家的信息也不应该完全没有, 以下这些内容就需要传达给玩家
- 如果是以聚会为中心的游戏, 必须向参加聚会的成员通知所发生的一些重要变化. 假设自己与对手的关系所需的信息量为10,那么那些变化所需的就要在5左右
- 在MMORPG等想要让玩家感觉到是一个世界的情况下,远处所发生的事件即使只能粗略表现出来,也应该传达给玩家. 假设自己与对手的关系所需的信息量为10, 那么那些远处的事件大约在0.5左右
在网络游戏中, 为了传达对手和环境之间的关系,大多会采用大幅降低传输内容,仅传达一种氛围而非精确的信息等方法.在上面的例子中, 对手和环境的关系所需的信息量是自己和对手的关系所需信息的一般至1/20,在实际的游戏中, 为了判断具体的信息量, 必须对游戏的细节内容进行详细分析
比如, 在两人对战格斗游戏中, 只有自己和对手, 因此并不存在对手和环境这样的概念. 于此相对地, 在10对10的集体对战游戏中, 远处的玩家和环境的关系只需发送极少的一部分信息.通常, 在发送1秒内移动10次这样的数据包时, 1秒内只发送一次.这样传输量就很简单地降低到1/10了.此外, 更远一些的情况则通常不在画面上显示,而只是播放一些音效.这样可以大幅降低渲染负担
综上所述,在对手和环境的关系方面的开发方针在很多情况下并不重要,所以只要"分析游戏的策划内容, 讨论要减少多少信息"
3.5 逻辑架构详解----MMO架构
3.5.1 MMO架构,MMOG----在大量玩家之间共享长期存在的游戏过程
MMO架构就是"在大量玩家之间共享长期存在的游戏过程".为此应该尽可能防止游戏的过程信息被破坏.在发生Bug等异常问题时, 需要对游戏数据进行回退
MMOG也叫做"持久的游戏",英语中称为Persistent game, Persistent world等
什么是持久?----游戏所需的时间和积累性
这里所说的"持久"究竟指的是什么呢?其实就是一系列的游戏过程持续多长时间.
- 2~3分钟
在街头霸王系列这类典型的对战格斗游戏中, 一个回合大约几秒至几十秒,一场比赛有3个回合,所以2名玩家的比赛大约持续2~3分钟. 胜负情况作为比赛(游戏)结果将被记录下来.赛车类游戏也是一回合2,3分钟~5分钟左右, 跑完全程的时间和排名也会被记录下来
- 20分钟~1小时
FPS和RTS的对战通常持续20分钟~1小时
- 1小时~几小时
将棋和《奥赛罗》,《大富翁》(Monoplay)和《人生游戏》(The Game of Life)等棋盘游戏持续的时间稍长一些,大约1小时至几小时
- 10~20小时
以模拟城市为代表的模拟类游戏大约持续10~20小时
- 30~200小时
RPG游戏可以达到30~200小时
- 1000~5000小时以上
在MMORPG游戏中, 大多具有游戏时间长达1000~5000小时以上的大规模的游戏内容
以上这些游戏所需时间的长短,根据游戏内容从2分钟到5000小时不等,它们之间的差异达到了15万倍
网络游戏中说得上"持久"(Persistent, 对于人们来说相当于一生)的游戏包括MMORPG和诸如《网页三国志》这样的大规模对战网页游戏等
在游戏行业中, 花费时间很长的游戏称为"高累积性的游戏".也就是说, 玩家的游戏时间等重要财产在游戏数据中累积的程度很高.玩家投入了大量时间的游戏数据, 其相对价值也因此而得以提高,所以为了防止游戏数据遭到破坏,游戏系统必须具有很高的可靠性
保持持久性数据, 不断累积的大量数据的一致性的难度
那么, 人们可以连续进行游戏的时间上限一般是45分钟~1小时, 在利用连休长时间进行游戏的情况下, 也就8小时, 最多十几个小时
在一系列的游戏过程在几分钟内就结束的游戏中, 游戏内容只会在游戏从开始到结束的几分钟之内保存在内存中, 只要在这段期间保证数据正确就不会发生任何问题
但是在那些游戏时间长达几十个小时, 几百小时以上的游戏中, 中途中断游戏后, 不仅需要某种机制能支持之后继续开始游戏, 而且因为众多玩家共享这耗时颇长的游戏, 所以还必须在服务器的内存和磁盘上准确无误地,完整地保存游戏中的各种信息,当玩家需要时瞬间取出来展现给玩家.因为有永久存在的含义,所以称为persistent.在RAM上互不干扰地, 保证一致性地维护大量游戏数据是需要非常注意的
在持久性的游戏中, MMORPG和虚拟世界这类网络游戏出现了一种动态持久化类型(dynamic persistent)的游戏, 在服务器内部实现物理模拟和经济模拟结构,游戏的设置数据会持续变化.在这种情况下, 当玩家再次登录游戏时, 即使玩家什么也没做也能感觉到跟以前不一样了.这类游戏中的设置数据包括游戏地图的形状,生物, 物品的出现场所及其出现频率的设置,数据量高达几十吉字节至几十钛字节.因为这种规模的数据始终在动态变化着, 所以对这些数据的保存,以及在其遭到破坏时进行修复的技术是非常必要的
客户端和服务器的完全分离
因为数据一致性方面的要求非常苛刻,所以在构建系统时要将"游戏客户端或者说游戏浏览器"和"游戏服务器"完全分离
严格来讲, 物理架构和逻辑架构之间没有什么关系,不具备服务器的MMO游戏在理论上也是可以实现的, 但是以现在的技术还无法实现. 所以目前所有MMOG都是C/S架构的
3.5.2 MMOG的结构

MMO架构的实现方针----浏览器方式,纯粹的C/S模式
不论是MO架构还是MMO架构, 都可以通过"同步方式", "异步方式"和"浏览器方式"来实现,是MMO架构时, 因为游戏内容有如下这些特点:
- 持久性
- 累积性
- 大规模(大量玩家同时在线)
所以能够使用的方法有所限制
就其结果而言,能用的只有"浏览器方式",其他几种实现方法基本上都不合适, 慎重起见, 我们还是对各种方式作一下简要说明
- 可以使用同步方式吗
只要一个人处理延迟, 所有玩家都只能等待,所以同步进行几百个玩家的程序处理是很不现实的
- 可以使用异步方式吗
因为游戏内容是持久累积的, 如果能在客户端侧篡改游戏数据则会给其他玩家造成很大的影响,所以不能使用异步方式
- 浏览器方式呢
可以使用, 但是需要设法最小化服务器与客户端之间的传输量,减少操作频率, 考虑能够负担较大通信延迟的游戏内容
浏览器方式, 同步方式和异步方式的差异
首先我们比较一下浏览器方式和同步方式, 这两种方式的差异在于"传输内容".同步方式下收发的只有玩家输入的信息(也就是游戏的原因),而在浏览器方式下,浏览器向服务器只发送玩家的操作信息(也就是原因),服务器只向浏览器发送游戏过程中的结果
此外, 在同步方式和异步方式下, 共享游戏过程的所有终端都共享游戏过程中的所有主数据. 而在浏览器方式下, 管理游戏数据的只有服务器, 各个终端(浏览器)只是将当前的游戏情况可视化展现给玩家, 这一点与同步方式和异步方式不同
MMO架构中服务器, 客户端的功能
MMO架构的实现采用浏览器方式, 而物理架构则采用纯粹的C/S架构. 顺带一提, 如前所述, 用户直接使用的相当于游戏浏览软件(浏览器)的程序称为"游戏客户端"
在MMO架构中, 游戏逻辑全部都在服务器上实现, 自己与对手的关系, 自己与环境的关系, 以及环境与对手的关系都是如此, 客户端并不包含用于使游戏发展下去的程序,而只包含与渲染,音效以及操作有关的处理, 所以服务器和客户端的功能组织完全不同.而且对应的操作系统也不同,通常, 客户端使用Windows, 服务器使用Linux等
于此相对, 同步方式和异步方式下, 每个终端都是同等的,所以所实现的功能也是同等的.浏览器方式下, 客户端和服务器在功能上的差异就相当于Web中客户端和服务器功能的差异.服务器数据难以篡改的程度也与Web相同.比如, 通过限制远程shell的登录, 防止利用SQL注入(SQL injection)和缓存溢出的程序非法运行,基本上可以防止直接的作弊行为
服务器端处理----游戏在服务器上持续运行
在网页游戏中,就算没有客户端(指浏览器本身),游戏也会在服务器上持续运行
网页游戏中所有的操作都是按照如下流程来进行的: 所有的操作都在客户端上进行->服务端进行处理->将处理结果显示在客户端上.在这整个过程中, 信息需要来回发送, 于是在客户端和服务端之间会进行两次通信.因此, 玩家在完成一次操作得到反馈之间会存在一段时间的间隔
由于所有的步骤都是在服务端上一次进行处理的,所以画面的显示不会出现不一致.但是在通信延迟过长的情况下, 画面就显得不连贯,玩家的游戏体验就会变得很糟糕
在网页游戏中, 服务端不进行画面渲染,几乎所有的渲染都能在游戏进行时由客户端加以处理,因此, 可以以同步和异步方式实现大量玩家同时在线
比如, 在使用CPU主频为2GHz的机器来实现游戏内容的情况下, 对于以同步方式来处理的游戏,1秒钟的CPU时间片会以如下方式进行分配(粗略估计).顺带踢一下,以下的分配方式不仅只针对CPU, 内存的分配也是如此
- 50%: 用于处理3D渲染
- 30%: 用于处理物理计算
- 20%: 用于处理游戏逻辑
- 误差度: 通信处理
于此相对, 在2GHz的服务i器上实现网页游戏的内容时, 则是按以下方式分配CPu时间
- 将近100%: 用于处理游戏逻辑
- 误差度: 通信处理
单纯地对这两者进行比较, 对于网页游戏中的游戏内容, 由于每个CPU可以处理5倍的游戏逻辑, 使用5倍的内存, 所以它能比同步方式处理更大的地图,更多样的敌对角色等
3.5.3 大型多人网络游戏(MMO)
3.6 小结
专栏 设法改善网页游戏的画面显示间隔
在只能以网页方式开发的大型多人网络游戏中,如果设法在客户端进行开发, 就能稍稍降低一些画面显示的时间间隔,本专栏对此作一下简要介绍
假设网络延迟为200毫秒,实际移动需要500毫秒,在网页游戏中事件的发生顺序为
- 0毫秒: 玩家开始操作(移动到坐标XY处)
- 0毫秒: 操作消息开始向服务器发送
- 200毫秒: 消息到达服务器
- 205毫秒: 服务器处理结束, 将结果(移动开始)发送给客户端
- 405毫秒: “移动开始”的消息到达客户端, 开始进行渲染
- 905毫秒: 移动画面渲染结束
在这种情况下, 玩家在操作之后大约400毫秒之后, 角色才开始移动, 从我们的感觉来看, 这种效果实在太差了
只要将事件发生顺序更改为如下形式就能改善操作时的体验
- 0毫秒: 玩家开始操作(移动到坐标XY处)
- 0毫秒: 操作消息开始向服务器发送
- 0毫秒: 客户端并不等待服务器送来的结果消息, 立即开始渲染画面
- 200毫秒: 消息到达服务器
- 205毫秒: 服务器处理结束, 将结果(移动开始)发送给客户端
- 405毫秒: "移动开始"的消息到达客户端, 如果移动成功则忽略该消息*.
- 500毫秒: 移动画面渲染结束
这样就将完成移动所需的905毫秒缩短到了500毫秒, 由此, 玩家就能感觉到自己的角色在很流畅地移动
这里的问题是, 在上文的*处, 如果从服务端发回了"移动失败"的消息,就需要立即回到原本的位置,否则游戏状态会不一致,导致后续操作(比如遇敌进入战斗)出现问题
因此, 根据游戏内容, 如果是在静态地形以外不会出现移动失败的情况下,这种方法是可行的,但是如果遇到敌人或者其他角色等正在移动的物体,而需要进行碰撞检测时, 这种方法就未必有效了
那么, 对于"自己以外"的其他角色呢?人们的感觉是很奇怪的,其他角色就算移动得很慢,或者很不流畅,又或者突然返回到原位,玩家也不会感觉到不协调
第4章 [实践]C/S MMO 游戏开发 长期运行的游戏服务器
4.1 网络游戏开发的基本流程
4.1.1 项目文档/交付物

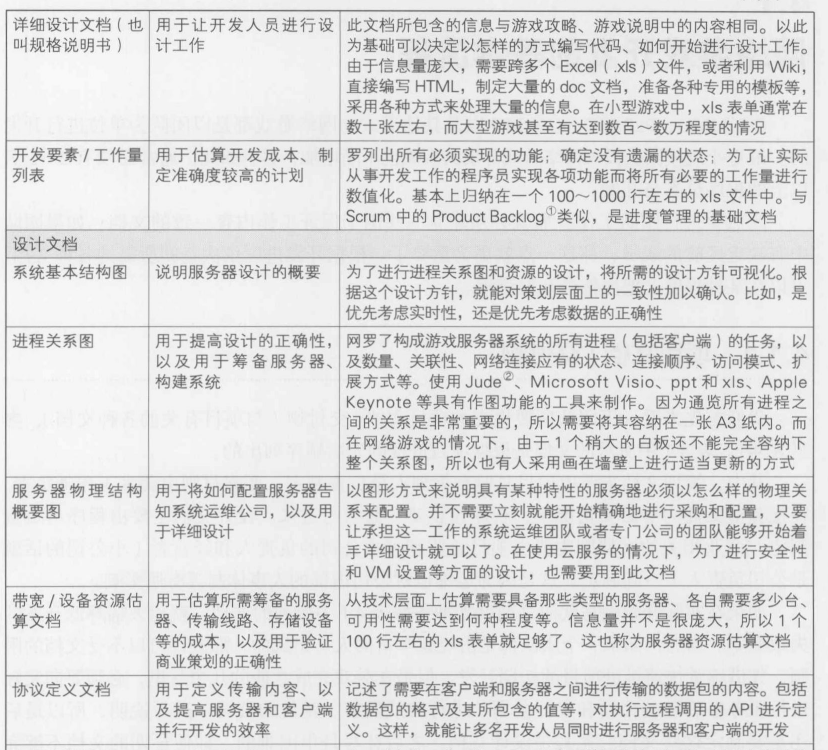


4.1.2 开发的进行和文档准备的流程
- 准备概要设计文档,商业计划书
- 对概要设计文档, 商业计划书进行评估,如果没有问题则继续下一步
- 准备详细设计文档, 各种设计文档, 开发要素列表, 工作量列表, 开发日程等所需得文档, 开发原型
- 以原型为基础, 使游戏始终保持可玩状态, 同时把握服务器得性能指标, 然后进一步进行详细开发,编写程序, 制作数据等.不断更新工作量列表, 任务列表, 开发体制图, 开发要素列表
- 程序和数据得形式大致确立后,开发用于管理/运营得工具
- 在完成前的半年左右决定服务器的筹备方式,更新估算好了的资源计划书,将这些信息交给系统管理/游戏运营公司,开始进行服务器的筹备和运营体制的构建
- 实现收费系统
- 进行内部alpha测试(不包含玩家的多人测试)
- 进行封测beta测试(限制玩家人数的多人测试).需要提交面向运营团队的测试说明书
- 进行公测beta测试(不限制玩家人数的多人测试)
- 开始收费
- 在半年内进行第一次更新(需要不断重复此过程)
4.1.3 技术人员的文档/交付物
4.2 C/S MMO游戏的发展趋势和对策
4.2.1 C/S MMO游戏的特点
"在数据中心被安全管理着的服务器中, 存在着持续运行着的游戏服务器",这一点是C/S MMO技术上的最显著的一个特点.由于这个特点, 商业模式也受到了很大的影响
4.2.2 C/S MMO架构(MMO架构)特有的游戏内容
- 处理大量的数据
- 向玩家严格保密设定信息
- 严格维护游戏数据的更改内容
- 简单地进行设定信息的更改
- 易于结合SNS等其他服务系统
C/S MMO架构的限制
- 延迟较大
- 游戏服务器的带宽负荷很高
- 游戏服务器的维护费用很高
- 服务器停止期间, 无法进行游戏
4.3 策划文档和5种设计文档----从虚构游戏K Online的开发中学习
实际试玩Runescape http://www.runescape.com
Web上提供的规范文档汇总 http://runescape.wikia.com/wiki/RuneScape_Wiki
4.3.1 考虑示例游戏的题材
4.3.2 详细设计文档
4.3.3 MMOG庞大的游戏设定
4.3.4 5种设计文档
- 系统的基本结构图
- 进程关系图
- 带宽/设备资源估算文档
- 协议定义文档
- 数据库设计图
4.3.5 设计上的重要判断
在Runescape游戏中, 设计上的重要判断有如下两个
- 一概不采用实时性高的策划内容
- 并行启动多个具有相同内容的游戏世界,不与朋友在同一个世界游戏也没有关系(平行世界方式)
通过这样的决策, 服务器系统就能够得以简化.另一方面, 从如何实现游戏可玩性的观点来看,我们不得不放弃那些动作性强的游戏内容, 而且之后参与游戏的玩家不能与之前就已经参与游戏的玩家在同一个服务器上注册,这是策划上的不足之处.但是接受这些不足可以一下子提高技术上的实现程度
在Runescape中,如何来判断这些限制呢?
- 延迟较大
Runescape以游戏内容的探索, 经济活动, 与敌方怪物战斗为中心, 不需要在16毫秒内进行操作, 即使是200毫秒~500毫秒的延迟也完全没有问题. 其游戏内容完全可以在这样的延迟下体验
- 游戏服务器的带宽负荷很高
Runescape对游戏内容进行了限制, 不需要任何激烈的操作.基本上来讲, 几秒内只需要进行1次鼠标点击,操作频率低.此外, 也不需要频繁发送其他玩家的动作方面的数据,平均下来不倒10kbit/s
- 游戏服务器的维护费用很高
不仅操作频率较低, 敌人的行为也调整得较慢.因此, 服务器得逻辑负荷非常小
- 服务器停止期间,无法进行游戏
因为同时启动了多个具有相同内容得服务器(平行世界),因此可以避免所有得玩家都无法进行游戏得情况.在Runescape中, 这并非是刻意实现的
4.4 [1] 系统基本结构图的制定
4.4.1 系统基本结构图的基础
系统基本结构图的目的就是明确设计方针.只要能确认程序内容符合商业游戏K Online的策划内容和商业模式就可以了.其顺序如下所示
- 确认期望的同时连接数, 以及能否免费进行游戏等商业模式
- 确认预想的瓶颈内容, 并且选择用来避免瓶颈的扩展方式
4.4.2 服务器必须具有可扩展性----商业模式的确认
启动少量的服务器, 根据需要予以增加, 这并不是一个很难得问题.在没有特别限制得情况下, 服务器得配备少则数日,多则两周左右就能准备妥当了, 而现在有些地区也能使用云服务.但是, 程序必须事先在可扩展性方面做好充分的准备
4.4.3 各种瓶颈----扩展方式的选择
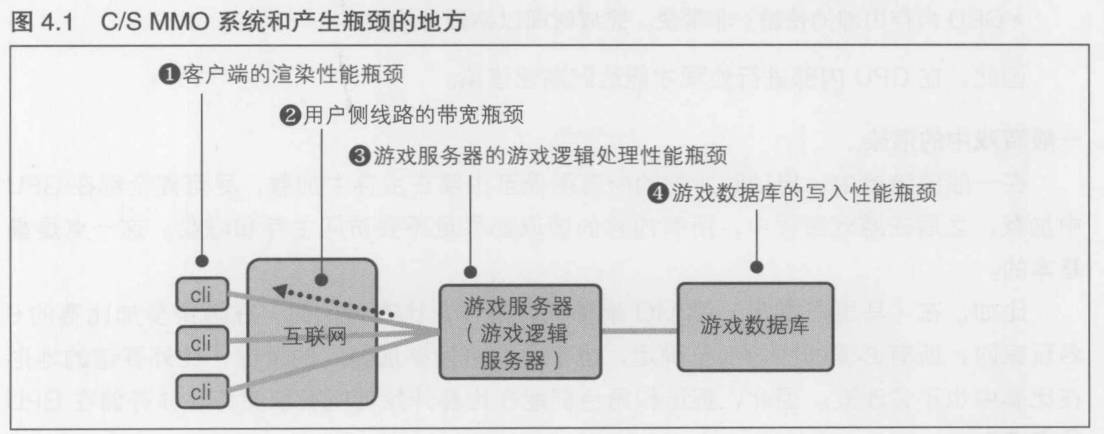
专栏 MMO客户端特有的渲染性能瓶颈
MMO架构的游戏客户端有一种特有的瓶颈.首先, 游戏客户端整体的处理性能瓶颈产生在"游戏处理"和"渲染处理"这两个地方.在MMO架构中, 游戏的处理全部在服务端进行,所以在MMOG的客户端中,只会在"渲染处理"上产生瓶颈
通常,渲染就是从磁盘中读取模型数据和纹理数据,然后将其交给GPU加以处理.渲染的处理速度在不同阶段中有所不同
- 从磁盘读取数据至主存中: 非常缓慢, 所需要的时间以毫秒为单位
- 从主存中读取数据至GPU的内存中: 较慢, 所需的时间以微妙为单位
- GPU内存内部的传输: 非常快, 完成时间以纳秒为单位
因此, 在GPU内部进行处理才能达到高速渲染
一般游戏中的渲染
在一般的游戏中, 启动时所需的所有的图像至少要在主存中加载,尽可能全都在GPU中加载,之后在游戏过程中, 所有内容的读取都尽量不要访问主存和磁盘. 这一点是最基本的
比如, 在《马里奥赛车》等MO架构的游戏中, 比赛开始时, 在渲染参加比赛的8名玩家时,所有必要的图像都已确定,也不会有中途参加游戏的情况,此外赛道的地形在比赛中也不会改变.因此, 赛道和角色都能在比赛开始前就读取完毕,并存储在GPU的内存中
MMO中的渲染----玩家角色
但是在MMO游戏中, 游戏过程中所需的图像是无法完全确定的. 其中最典型的就是玩家角色.在本章的示例游戏K Online中, 玩家具有各种不同的能力,能够同时加入游戏.此外, 各种元素的组合方式几乎接近无限.如果其他玩家的形象都跟自己很相似, 那就辨别不出玩家角色了,也很难判断游戏的进展,游戏体验也就因此大打折扣.为此, 在K Online中, 我们想要使玩家角色的形象多样化,各个玩家的个性和能力都能尽可能地通过角色反映出来
其结果就造成了无法"在内存中存储所有可能出现的模型"这种情况. 这样就必须动态地从主存或者从磁盘中加载. 通常, 从一个人烟稀少的地方移动到一个聚集着大量玩家的地方时, 必须一口气读取大量的纹理数据. 为了应对这种情况,我们可以采取以下这样的方法,尽可能避免游戏体验的恶化
- 不要"一口气读取所有必需的数据",而是在保持帧速率的情况下花时间一点点读取
- 即使是在读取纹理数据的过程中, 也尽量只先进行轮廓的渲染, 只对所处位置有所了解
MMO的渲染瓶颈----敌方,友方,总共要显示多少名呢?

不管是3D渲染还是2D渲染,瓶颈都是发生在"要在1个画面中总共显示多少名玩家角色和敌方角色"的敌方,所以在进行策划工作时,首先必须对该数量进行明确和验证
比如图C4.A所示的MMORPG Lineage的战斗画面, Lineage的卖点就在于庞大的玩家群体之间所进行的战斗(称为攻城战)
在MMORPG中, "哪种形态的玩家角色在哪个时刻初次出现在画面上"是无法进行定义的. 像Lineage这样, 200名以上的敌友在混战之中, 每秒都会有多人交替. 如果不尽可能在画面上显示出玩家角色的职业和能力的差别,画面就会变得鼓噪无味
为此,如何减少图像数据, 如何重新使用这些数据以及高效地在VRAM(Video RAM)中存储这些数据都必须好好考虑
4.4.4 解决游戏服务器/数据库的瓶颈
首先, 解决游戏服务器的瓶颈主要有以下两种方法
1.空间分割法(空间地理上的分割)
根据地理结构将游戏世界进行分割, 分配给其他的服务器j进程或者服务器设备进行处理
2.实例法(游戏副本实例)
将负荷特别高的, 用户集中在一起的部分独立出来, 将这些部分分配给专用的服务器来处理. 这些部分未必都是以游戏副本的形式来呈现, 但典型情况下都是使用这种形式的, 所以也称为游戏副本实例(instance dungeon)
接着, 解决数据库瓶颈的方法是
3.平行世界方式
使容易成为瓶颈的数据库本身并行化, 以此将瓶颈分为多个.但是保存了玩家信息的数据库分成多个后,角色就无法在不同的世界之间移动,所以玩家之间的交流也被切断了
上述3种方法也可以同时使用.比如在Wow中就同时使用了上述3种方法, 从而得以支持数百万玩家参与游戏
决定C/S MMO服务器的基本架构,也就是要判断使用上述3种方法种的哪种
4.4.5 什么都不做的情况(1台服务器负责整个游戏世界)
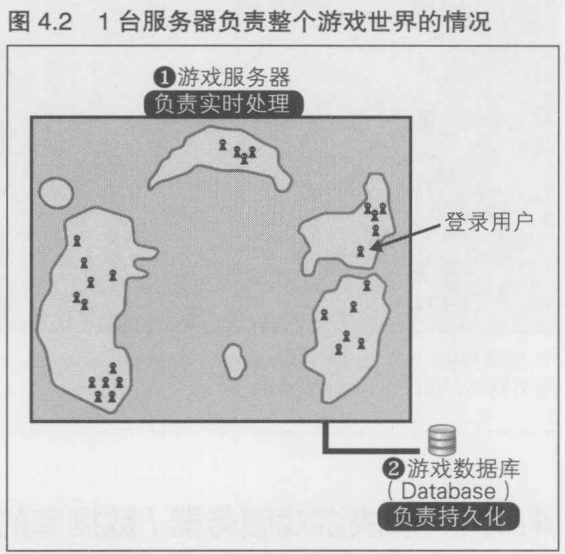
首先,什么都不做的情况是指,在Linux等服务器上只运行1个进程,数据库也只有1个.这里的数据库指的是MySQL等DBMS服务器实例,该实例只有1个
请看一下图4.2, 登录游戏的玩家分散在游戏世界的各个地方, 根据游戏中实时处理的复杂性,每一台服务器大约可以处理200~2000左右的登录数.这里存在着10倍的差异,这是因为根据游戏世界中四处徘徊的敌人的数量以及敌人动作算法的复杂性,服务器能处理的登录数会有很大的变化.在图4.2的示例中, 每个玩家的游戏结果都存储在用于持久化游戏数据的数据库中
在开发游戏原型时, 最多也只有10个左右的开发人员登录游戏, 所以即使是在这种单进程的形式下也不会出现问题. 但是如果就这么开始商业服务的话, 游戏服务器(负责游戏实时处理的服务器)和游戏数据库肯定会成为瓶颈
4.4.6 空间分割法----解决游戏服务器的瓶颈

图4.3是使用空间分割法的示例. 通过使用空间分割法,实时处理这一部分的负荷就能够得以减轻.由于玩家角色在游戏世界中的移动受到了很大的空间限制, 所以MMOG的实时处理负荷在空间上具有局部性. 因此, 利用这一局部性, 通过将游戏世界在空间上进行分割,基本上就能线性地提高性能.图4.3将世界等分为上下左右4部分, 但是为了充分利用空间的局部性,根据各个大陆板块, 各个城市来进行分割更为有效
空间分割法对实时处理的部分进行了分割, 但是它并没有分割游戏数据库. 因此,在图4.3中, 如果服务器1~4的总访问量增加, 还是无法避免游戏数据库成为瓶颈
此外, 即使事先对空间进行了分割,也还遗留了一个问题: 由于游戏中会有一些吸引玩家的活动,所以无法排除玩家一时之间大量集中在某台服务器上的可能性.在这种情况下, 玩家会感觉到无法前往某些区域,这与"无法登录游戏"一样都是最坏的情况
空间复制
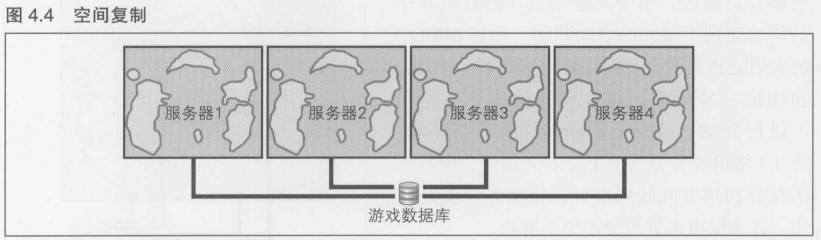
作为空间分割法的一种简化形式,有种方法是将看上去完全相同的世界复制4次.这称为"空间复制法"(复制法).决定玩家登录哪一台服务器可以有以下几种选择: (1)明确指定, (2)随机选择, (3)自动选择空闲的服务器.在C/S MMO的情况下, 比如K Online,各个服务器上有怎样的玩家正在进行游戏?物品拍卖行和用于集结成员的"广场"上有着怎样的玩家?情况各不相同,所以为了满足玩家的需求,一般需要采用方法(1)
在图4.4中, 并没有将游戏世界进行分割, 而是准备了4个完全相同的世界, 这一点也请加以注意.严格来讲,这不能叫空间分割法,但是所需的技术更为简单,实现也较为简单
空间复制法有个缺点, 简单来讲, 就是有时会产生"玩家过少的感觉".比如, 在整个的游戏世界地图中, 对某个特定岛屿感兴趣的玩家总共占了1万名玩家中的300人.此时, 如果像游戏世界的空间分割图那样将游戏世界进行4等分,在该岛上就会聚集前述的300人. 而如果是像空间复制图那样进行划分的话, 每个世界就只有1/4的玩家聚集在一起了(也就是75人),大家零零散散,在互相看不到对方的状态下进行游戏,也就是说, 对同一个地方感兴趣的玩家明明有300人, 但是玩家只能实际感觉到75人的热闹程度. 在C/S MMO中, 这被称为"玩家过少感".
虽然存在着以上这个问题, 但空间复制法仍然是一种能够通过较少的工作量来扩展游戏服务器的有效方法
4.4.7 实例法----解决游戏服务器的瓶颈
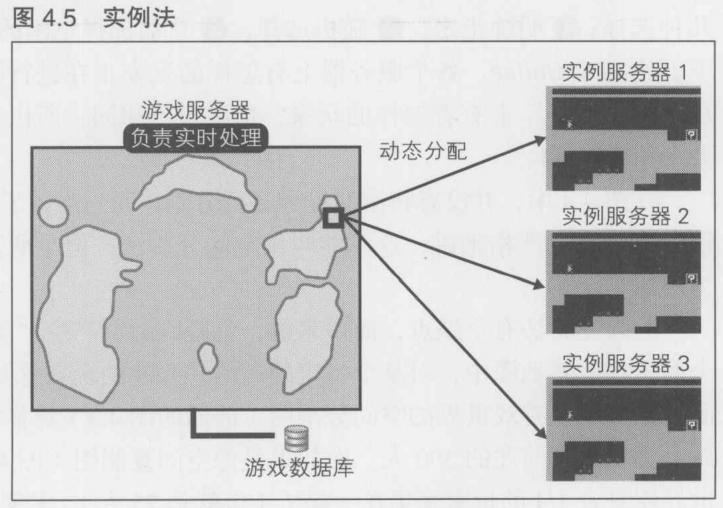
在讲解空间分割法时, 我们提到过这样一个问题: 由于受到潮流等方面的影响,无法排除大量玩家聚集在某个场所的可能性.想要完美解决这个问题就要用到实例法(游戏副本实例)
在大多数MMOG中, 玩家只集中在整个游戏空间中极其有限的地区和场所中.在图4.5中, 就是世界地图上正方形围起来的地方.在典型的MMORPG中, 就是被称为"游戏副本"的地方.玩家集中在那里的理由是,在那里能高效地赚取经验的怪物比其他地方更为密集,还特别设有一些珍贵的宝物, 以及一些功能便利又常用的道具
在游戏的设计阶段我们就已经能够设想到玩家会聚集在这样的地方了,所以可以启动多个只负责处理这一小部分内容的专用服务器(实例服务器),当玩家进入该场所时,动态选择实例服务器,然后就让玩家登录那个被选择了的实例服务器
可以采用以下几种方法来确定登录哪个实例服务器: (1)玩家自己进行选择; (2)自动分配空闲的服务器; (3)根据朋友的登录信息等社交信息来进行计算
在图4.5中, 右侧的3个黑色地图代表聚集了大量玩家的地下城副本,在负责进行处理的游戏处理服务器中并行地运行着这3个副本. 当玩家角色从这一狭小的区域退出时, 就会自动回到原来所在的地方(由负责整个世界的服务器处理)
4.4.8 平行世界方式----解决数据库瓶颈
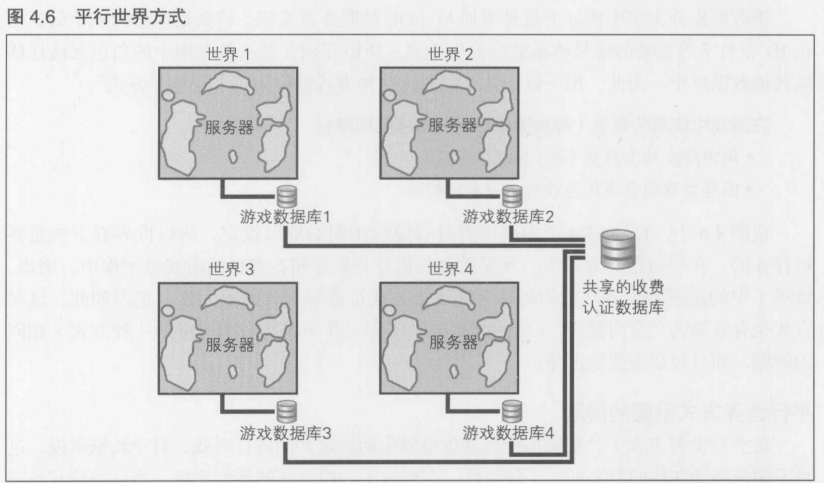
空间分割方式和实例法都是用于解决服务器瓶颈的方法.所以用来存储游戏数据的数据库只有1个.如前所述, 平行世界方式就是用来解决数据库瓶颈的主要方法.
最容易产生瓶颈的是数据库写入操作
在C/S MMO中, 如何高效地向数据库中写入数据是一个很重要的问题.在普通的Web服务访问模式中, 数据库写入操作的频率还不到读取频率的10%.但是在网络游戏中,这一频率正好相反, 写入操作占了90%
这是因为数据的读取是由负责实时处理的游戏服务器在内存中进行管理的,可以随时从内存中读取这些数据.可以说C/S MMO系统是一个具有内置了处理功能强大的高速缓存服务器的Web系统
C/S MMO中的游戏信息主要是玩家角色的状态变化.在K Online中, 玩家每次对物体进行操作或者使用技能时, 玩家角色的状态都会一点一点地发生变化. 这一频率大约是10秒~1分钟一次.在理想情况下, 每次发生变化时都写入数据库.同时连接数为1000时, 如果平均每10秒需要存储1次, 1秒内就要发生100次写入操作.如果玩家信息很多, 就需要同时, 同步写入多个表中, 所以1秒内要持续进行100次的写入事务, 其处理量是相当大的.因此, 数据库写入操作很容易成为瓶颈
此外, 即使是在平行世界方式中, 也还需要一个供整个系统使用的数据库来实现收费认证功能.对于这个数据库, 当天初次登录游戏时只进行1次认证,实际支付时进行结算事务等操作的写入频率并没有10秒1次这么频繁,而是几十分钟还不到1次的程度
平行世界方式下的数据库分割
平行世界方式是将1个游戏数据库分割为多个, 以此来处理数据库存储性能上的瓶颈
将数据库分为多个实际上就是增加MySQL的服务器实例.将数据库分为多个后, 角色ID和名字等重要的编号体系就会发生重复,所以存储在某个数据库中的角色无法迁移到其他数据库中. 为此,出于以下几个原因,这种方式被称为"平行世界方式"
在游戏中使用的角色(等重要信息)的转移受到限制
- 角色所在的世界并不相同->世界不同
- 但是世界的呈现和游戏的内容完全相同
在图4.6中, 1~4这4个游戏世界具有完全相同的地形设定, 所以世界看上去是并行存在的.在平行世界方式中, 玩家的角色信息分别存储在各自的游戏数据库中.所以, 世界1中的玩家和世界2中的玩家无法进行共同抗敌等多人游戏元素.正因如此, 这种方式也存在着与"空间复制"(空间分割法中实际上并不进行空间分割的一种方式)相同的问题,而且可以说更为严重
平行世界方式引起的问题
在平行世界方式下, 玩家不能与其他世界中的玩家共同进行游戏, 对于玩家来说, 这种不便是强加在它们身上的.不仅如此,在经过了一段时间的运营之后,当玩家数有所减少时,还会产生更为强烈的"玩家过少感".这比空间复制法所引起的问题更为深刻
比如, 游戏开始运营后的第一年里有1万名玩家,世界增加到4个之后, 过了3年,玩家总数减少到了3000人,此时, 如果还是4个世界, 每个世界中的人数就比一开始少了很多
为了解决这个问题, 就需要采取"世界合并"等处理方法.但是实际上并没有那么简单.很多玩家在经过了这么长的一段游戏时间之后,在各自的世界中都已经形成了自己的人脉,各自的团队和用户组都有着各自的作风和文化, 所以单单因为人数减少而合并世界会给玩家团体带来更大的影响.这样一来, 可能会导致大量的玩家离开游戏
为了尽量避免这个问题,必须对玩家团体(公会和帮会等)的名字和昵称等与命名相关的信息进行检查以防止冲突.这样就要事先在数据库中加入这样的检查功能,但这么一来, 越是使各个世界的数据相关,数据库的瓶颈就越容易发生,原本是为了解决瓶颈而引入的平行世界体系反而造成了相反的结果
4.4.9 同时采用多种方法----应对越来越多的玩家
玩家进一步增加后, 游戏服务器和数据库两方面都可能发生瓶颈.为了应对这一情况, 可以同时采用空间分割法和平行世界方式这两种方法.

至此, 如果还需要进一步扩展, 可以同时采用空间分割, 平行世界,实例法.
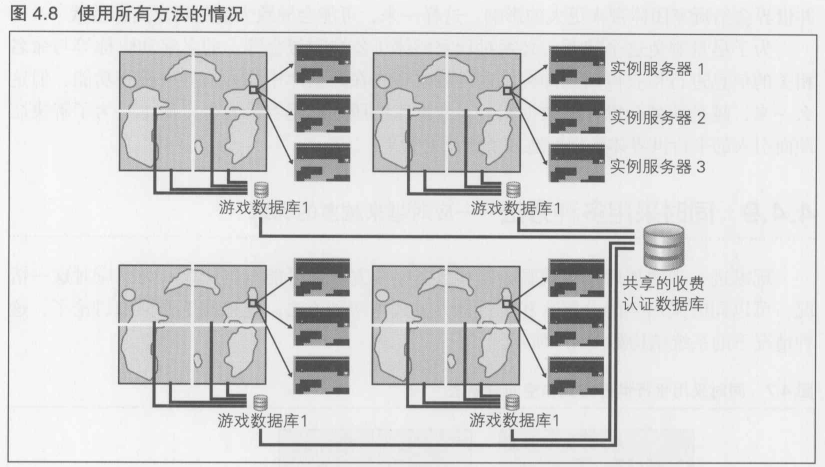
4.4.10 各种方式的引入难度
空间分割法, 实例法, 平行世界方式这3种类型的方法都用于在玩家数增加后, 确保系统可扩展
但是, 参与游戏的玩家什么时候会超过最大限制是很难事先预料的, 在游戏还没全部完成, 并且尚未正式开始运营时,很难对大量的用户资源进行分割来为将来的扩展做准备.但是如果所做的设计会导致之后很难进行修改,服务器负荷加重而导致玩家无法登录游戏的情况持续一周的话,玩家对游戏的评价或许就会一落千丈.一般来讲,一旦对网络游戏的评价下降后,就不会再有起色了,为了避免这种情况的发生,应该怎么做才好呢
通常, 后期引入平行世界方式还是比较简单的, 可以在一定程度上实现实时追加, 但是在采用空间分割和实例法时,游戏数据的存储和制定,客户端的处理逻辑以及用户界面等很多地方都需要更改,所以后期引入需要很长的时间.尤其是在已经运行着的游戏中, 要向玩家说明这一情况也很困难.就笔者所知, 在运营正式开始之后, 不可能有效引入后面两种方法来实现可扩展性
4.4.11 各个世界中数据库(游戏数据库)服务器的绝对性能的提高
一般来讲, 要提高游戏数据库的综合性能只能采用平行世界方式, 但是为了让每个世界能够支持数千以上的同时在线玩家,还必须考虑一些方法来提高各个世界中游戏数据库的绝对性能.要想使用实例法来妥善处理更多同时在线的玩家,还必须考虑一些方法来提高各个世界中游戏数据库的绝对性能.要想使用实例法来妥善处理更多同时在线的玩家,这些方法是必不可少的
随着DBMS处理性能的提高和服务器性能的提高, 游戏数据库的绝对性能也在持续提高. 但是每秒处理事务的性能, 3年也提高不了4倍.当然, 今后, 随着SSD,重视高速性的KVS(Key-Value Store, 键值存储)技术, 以及DBMS的表压缩技术的发展, 事务处理性能可能也会受到影响,但在现在,这些是否符合C/S MMO游戏的要素还不明确
因此, 目前的现状就是, 为了设法达到数倍,数十倍的高速, 在应用程序成面上追加某些方法是不可或缺的.这里, 我们来看一下不依赖平行世界方式来提高性能的一些技巧
应用层面的技巧
提高各个世界中游戏数据库的绝对性能的代表性方法是: 在保存玩家角色的状态变化(该部分占了访问过程中的绝大部分)时, 设置执行写入缓存的中间高速缓存服务器.
这种方式最大程度地发挥了游戏过程中的一个特点: "玩家角色的状态变化是局部于用户ID的".虽然对游戏数据库进行写入操作的频率很高,但是同一个ID的玩家角色的信息是反复保存多次的
比如, 假设同时连接数为1万名玩家, 每个玩家角色的信息为2兆字节, 如果具有2兆字节 x 10000 = 20吉字节的内存,那么几乎所有的写入操作都能在内存中缓存.这样, 如果两次中有1次是保存到数据库表,负荷就基本可以减少一半
如果想要使所开发的游戏大获成功,必须准备这种中间缓存层.在实现数据库访问网关的功能的过程中, 自然要实现这个功能
4.4.12 K Online的设计估算----首先从同时在线数开始
接着, 我们就对示例游戏K Online的系统基本结构图中所涉及的各个部分进行估算
这里, 我们考虑与玩家数众多的中国网吧签订特殊的宣传合同.这样我们必须假定同时在线数将会达到3万, 截至原稿攥写时(2010年9月),中国最具人气的游戏达到了60万的同时在线数,所以在中国市场上,如果进行大规模宣传,必须预计会有3万的同时在线数, "3万的同时在线数"这个数字是之后进行各种估算的根据
瓶颈的确认
首先我们来确认一下前面说的4种瓶颈
- 客户端渲染性能的瓶颈
预计画面上需要同时渲染的敌人和NPC的数量为10~20左右, 渲染性能验证的结果是, 即使运行在性能较差的Windows PC上, 渲染性能也没有问题
- 用户侧线路带宽的瓶颈
平均下来不到10kbit/s,完全没有问题
- 游戏服务器的游戏逻辑处理性能的瓶颈
这里的瓶颈在于CPU的处理性能, 所以需要估算实际处理的游戏逻辑的利用量
- 游戏数据库写入性能的瓶颈
瓶颈在于数据库的存储性能,所以需要估算实际要存储的数据内容,数据量以及存储频率.
问题在于最后两点. 下面我们针对(3)游戏服务器的游戏逻辑处理性能的瓶颈和(4)游戏数据库的写入性能的瓶颈进行评估
设计估算的思考原则
思考原则有以下两点
- 对特别耗费处理成本的部分进行估计, 求出"绝对的服务器数量"
- 对特别难以扩展的部分进行估计, 求出"每个平行世界可能扩充的最大服务器数"
(1)中耗费成本的部分在于敌人的行动算法,以及与同时在线数成正比增加的"游戏逻辑"主题部分的处理.(2)中难以扩展的部分是"游戏数据库"的处理.明确了(1),(2)这两点,就能根据"平行世界数=绝对的服务器数/每个平行世界可能扩充的最大服务器数"这个等式来计算平行世界的数量
平行世界越少越好, 这个是前提, 最好是1个,所以在技术上需要讨论能够减少多少台绝对的服务器,每个平行世界可以扩充的最大服务器数能够增加多少这些问题, 我们的目标是精度"相差不到2倍",下面我么就以此为目标来进行估计
4.4.13 根据游戏逻辑的处理成本来估算----敌人的行动算法需要消耗多少CPU
在游戏逻辑处理成本的估算方面, 有一种观点认为"很多情况下最内侧的循环占了执行时间的8成".在K Online中, 从策划内容来看,CPU执行的游戏逻辑很大一部分都把时间花在"敌人的行动算法"中(除此之外就是误差程度).这里要计算出"1个服务器内核能够处理多少同时在线数".其结果是"1个内核处理500个同时在线玩家".下面我们将介绍这个结论是如何得到的.为了得到结果, 只要对等式"同时在线数 x 每个玩家所面对的敌人数 x 每秒敌人的行动数 x 每次行动所需的CPU时间 x 安全系数 = 1秒"进行求解就可以了
在上面这个等式中, “同时在线数”是需要求解的值, 每个玩家所面对的敌人数,每秒敌人的行动次数, 每次行动所需的CPU时间都能根据游戏的策划内容推断出来, 这样最后就能求出1个CPU(1个内核)时间内所能处理的同时在线数了
- 每个玩家所面对的敌人数
首先,根据K Online的策划内容, 我们要实现"整个画面被敌人包围,玩家要在其中杀出重围"的场景."整个画面"具体指出20个左右的敌人.在最坏的情况下,K Online的大多数玩家都没有组队作战,而是一个个分开行动,不断攻击敌人,拾取地上的物品.所以, 最坏的情况就是每个玩家可能同时面对10~20个左右的敌人
- 每秒敌人的行动次数
在K Online中, 玩家角色的移动速度更快一些,策划要求每秒处理5次
- 每次行动所需的CPU时间
大致需要以下这些处理
- 通过简单的循环来检查敌人周围的地形数据
- 查找附近的玩家角色
- 通过非常简单的排序方法来决定下一次的行动
- 执行1次预订的行动
上面1~4这几个方面通过编写小段程序来进行验证,所以可以编写游戏逻辑来尝试.由此得到, 每次行动平均需要10微秒, 娴熟的开发人员在平时,总会经常无意间进行这样的计算,但在C/S MMO中, 在实现服务器时就需要运用这类计算
- 安全系数
目前, 大约增加两倍就可以了吧, 看上去很合适,但是根据经验, 增加两倍是之后稍微下点工夫就能做到的,而增加10倍就需要一定的技术支持
那么, 将上面这些数值带入等式中, <所要计算的值> x 20 x 5 x 10微妙 x 2 = 1秒,就可以求得"同时在线数"为500
网络, 安全性, 用于提高开发效率得间接成本也是需要考虑的, 但是这些就像加在安全系数中这么小, 但是如果使用了尚未取得实效得通信中间件,或许最好还是对其进行测定
在K Online中, 总共需要3万同时在线数得处理能力, 所以可以得出, 需要3万/500 = 60个内核所具有的处理能力.至此我们估算出了K Online整体需要的绝对的服务器数
4.414 根据游戏数据库的处理负荷进行估算----找到"角色数据的保存频率"与"数据库负荷"的关系
接着我们来估算一下1个平行世界可能扩充的服务器数.如果可以扩充到60个以上,那怎么样呢?结果是需要5个平行世界,下面我们就介绍一下得到这个结论的计算过程
我们转到一个另一个问题上: 执行游戏处理的60个内核实际上如何配置呢?原则上, 应该尽可能不影响玩家的游戏.如果只使用平行世界方式,从玩家角度来看, 60个服务器林立着,不仅引起混乱,而且还非常不方便.至少平行世界要设置3个左右,最多不超过10个(因此同时还需要使用空间分割法和实例法)
那么,1个平行世界可以投入多少个处理游戏逻辑的内核呢?对此起决定性作用的是数据库(游戏数据库)的处理负荷.而数据库的处理负荷一般由写入性能来决定
将写入成本以公式来表示的话就是: 同时在线数 x 每个连接平均的数据存储频率 x 1次存储所需的查询数 x 安全系数 = 数据库服务器总共可以查询的频率.这里, 游戏数据库相关的写入成本一般是指对“角色数据的存储频率”和"数据库负荷"的权衡.也就是说, 如果存储频率低,玩家好不容易在游戏过程中积累起来的进展就容易丢失,但是游戏数据库的负荷就会下降.这就需要根据策划内容决定两者之间的关系.接着我们来求解刚才的公式
- 每个连接平均的数据存储频率
首先我们来考虑一下每个连接平均的数据存储频率.K Online与一般的MMOG相同, 执行游戏逻辑处理的游戏服务器(gmsv)总是要执行一些复杂的,无法完全预测的游戏逻辑,所以无法完全避免程序崩溃问题. 在发生崩溃的情况下,内存中的游戏过程信息就会丢失,于是就会发生游戏状态的的回退(总的来说就是, 角色明明已经升级了, 但是现在又降下来了).可以通过定期在数据库中存储游戏信息来防止这种情况.平均1分钟存储1次就基本上不会有什么问题了.
K Online可以以这个"1分钟存储1次"的频率为基准吗?首先我们从策划内容开始判断, 在K Online中, 1次战斗和拾取操作大约要花费30秒~5分钟,于敌对角色的战斗一般需要1分钟~几分钟. 通过这些游戏内部的基本活动, 玩家角色可以获得随机定义的, 或许有利于推动游戏进程的一些重要物品以及经验值.出于这些原因, 如果能平均1分钟存储1次,那这些游戏相关的更新就能被存储了.因此, 我们可以判断,在K Online中1分钟存储1次是很合适的.整体的同时在线数是3万,除以60秒,也就是1秒存储500次.
- 1次存储所需的查询数
接着,我们来考虑1次存储所需的查询数.角色数据可以有两种方式来存储: 一种是以BLOB等形式,每1行存储1个角色的信息; 第二种是将角色数据的各个参数作为数据库的表字段来存储.后一种方式对数据的复用性更高,检索性更好,也更容易对用户提供支持,但是数据库的性能就有所下降.这就需要加以权衡.在K Online中, 首先要考虑的就是最大限度地高效使用数据.为了存储1名玩家角色的游戏数据,假设进行10次SQL UPDATE操作
- 安全系数
最后, 安全系数于之前计算内核数时一样,也是2
将上面这些数值代入之前的公式中, 可以得到: 3万 x (1 / 60) x 10 x 2 = 10000
具备与正式服务中使用的服务器相同的设备,并且配置用于备份的副本, 测定实际的MySQL速度, 在行数非常多的情况下, 如果是2000次查询/秒的程度,那么处理起来就很宽裕.因此, 绝对要达到的10000次查询/秒除以2000, 就可以得到平行世界的数量为"5"
通过以上计算, 我们估算出"平行世界数=5","每个平行世界的同时在线数=6000".每个平行世界的游戏服务器平均有12个内核(60内核/5)
4.4.15 可扩展性的最低讨论结果,追求进一步的用户体验
通过以上讨论,有关服务器的可扩展性问题已经告一段落了,但是为了追求更好的用户体验, 我们还要进一步进行探讨
首先, 1个平行世界中有12台游戏服务器的情况下, 要将哪个玩家分配到哪个服务器中呢?如果要让两名玩家共享相同的游戏画面, 一起进行游戏, 他们必须登录到同一台服务器.通常, 玩家通过聊天等方式商量决定"今天上3号服务器进行游戏",然后在该服务器上碰头.最简单的就是将12个服务器以列表形式显示在界面上,让玩家从中手动选择,很多情况下这样是可以的,但是非常麻烦.而K Online的负责人认为进行这样的选择很麻烦, 所以希望有更为简单的方式
- 50%~70%的玩家(同时在线3000~4000人)集中在游戏副本, 塔, 广场等20个左右的小场所中
- 剩余的玩家(同时在线2000~3000人)在广阔的地上世界中冒险
这里同时在线总数为6000
游戏世界大致分为8个岛屿和大陆, 此外, 游戏副本和塔等有20个左右, 所以合计为28个, 比游戏服务器的数量(12台)大得多, 所以根据地区来划分服务器, 当玩家角色从过一个地区移动到另一个地区时,如果能自动切换服务器, 玩家就可以省去对服务器进行选择得操作了
这样就能大幅改善用户体验了, 但是我们不得不承认, 这种方式有一个问题, 在发生一些特殊事件(比如政治家得演说突然开始, 或者发生游戏平衡性的问题)时, 玩家就会集中在某个地区内,负责该地区的逻辑处理的服务器就无法应对这种情况了, 想要移动到该地区时, 如果发生了这种情况,就能只能给出"服务器已满, 无法进入"的提示.但这毕竟是特殊情况,所以最好还是便利性高一些
这里所说的游戏体验恶化,具体是指, 当大量玩家集中在一个狭小的的空间中时, "对地方怪物和物品的争抢"就会频繁发生. 所以, 为了降低人口密度, 还是应该将游戏副本实例化比较好. 至于实例化的单位,根据副本地图的大小和长度来考虑,平均10~20个玩家1个实例
这里假设总共有3600名玩家同时访问塔和副本等的实例.在K Online中, 平均必须要有10~20名玩家同时进入副本展开与敌人的战斗(特别是在与boss战斗时),所以假设平均每个副本10人,就需要3600 / 10 = 360个实例.之前已经估算出,服务器的每个内核可以处理500个同时在线.3600 / 500 = 7.2个内核的话就可以了,考虑到比起一般的处理, 实例处理多少增加了地图数据初始化等额外工作,再加上安全系数,估计需要16个核心
4.4.16 服务器的基本结构, [1] 制定系统基本j结构图
K Online的服务器基本结构总结如下, 这反映了以上的讨论内容
- 收费认证服务器是通用的
- 分割为5个平行世界, 1个世界允许同时在线6000人, 总共3万人同时访问
- 1个世界分为8个地区(8核)
- 1个世界准备360个实例
- 玩家继续增加的情况下, 追加平行世界
这样,K Online就同时使用了3种方法, 玩家的体验也不会受到太大影响了,同时还预见了游戏的大规模化, 确保了服务器的扩展性.根据服务质量, 实际需要多少内核数会有所变化
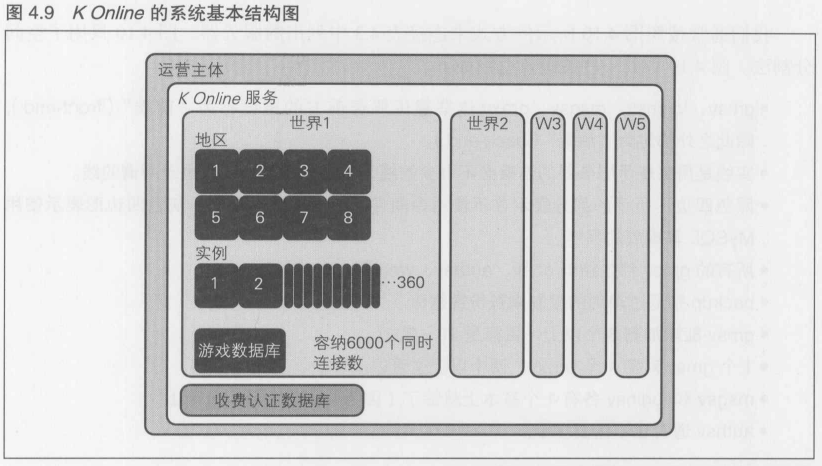
图4.9中, 运营主体是指,比如将K Online授权给越南的游戏运营公司时,图4.9所示的系统结构应该运行在越南本土所设置的数据中心中,在这种情况下运营主体会增加.在通过游戏进行交流的方面, 即使运营主体增加了,收费验证数据库还是要求通用的,这部分在之后不易更改, 所以需要在这里予以明确
4.5 [2] 进程关系图的制定
4.5.1 [2] 进程关系图的准备
4.5.2 服务器连接的结构----只用空间分割法
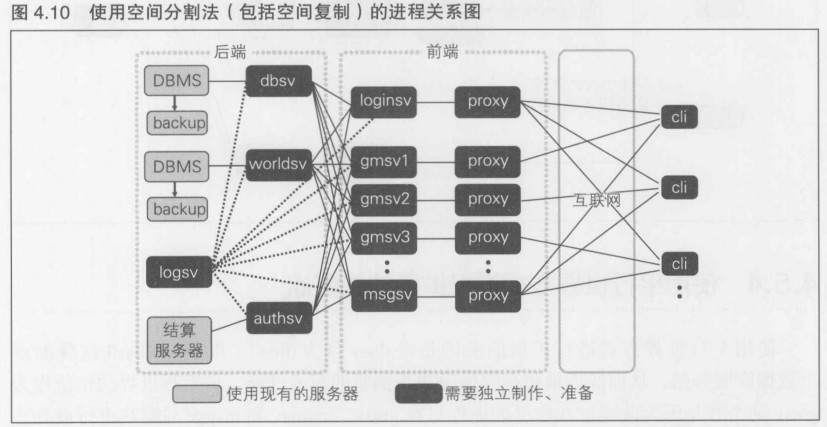
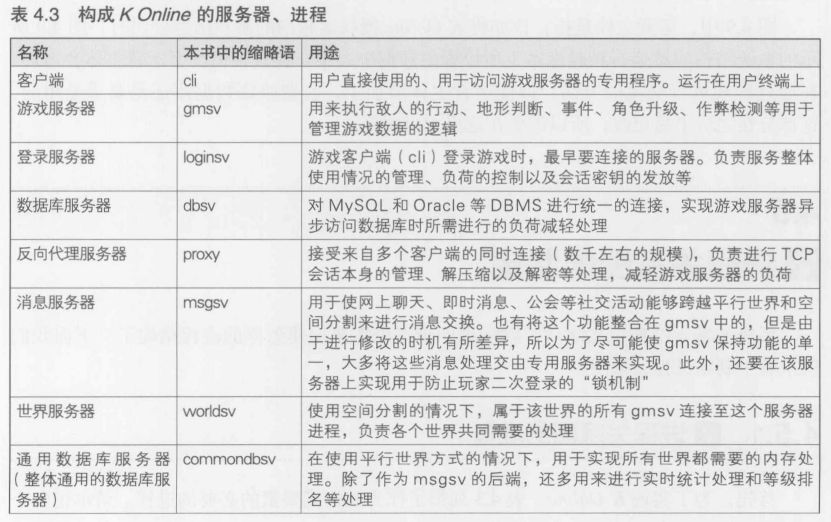

- gmsv, loginsv, msgsv, proxy这些靠近服务前方的进程称为"前端"(front-end),除此之外都称为"后端"(back-end)
- 实线是用来表示服务器的连接必不可少的线, 虚线表示即使切断也无所谓的线
- 黑色四边形所示的部分表示在不使用中间件时, 必须自己制作. 灰色四边形表示使用MySQL等现成的程序
- 所有的gmsv都连接到dbsv, authsv, worldsv上
- backup指通过单纯的复制来备份数据库
- gmsv能增加到3个以上, 目标是20~30个
- 1个gmsv对应1个proxy, 两个以上也可以
- msgsv和loginsv各有1个基本上就够了(因为并不总会造成负荷)
- authsv通常也不需要多个
4.5.3 服务器连接的结构----使用平行世界方式和空间分割法
使用平行世界方式和使用空间分割法时, 它们的关系图如图4.11所示
在仅使用空间分割法还无法达到足够的可扩展性的情况下, 需要增加平行世界的个数.在图4.11中, 世界1, 世界2, 世界3这3个灰色方框代表了3个世界, 实际上,按照同样的这种结构,可以将世界的个数增加到10个.由于1个世界可以处理1万~2万个同时连接,所以如果在这种结构下将世界增至10个,可以将同时连接数扩展到数十万的规模
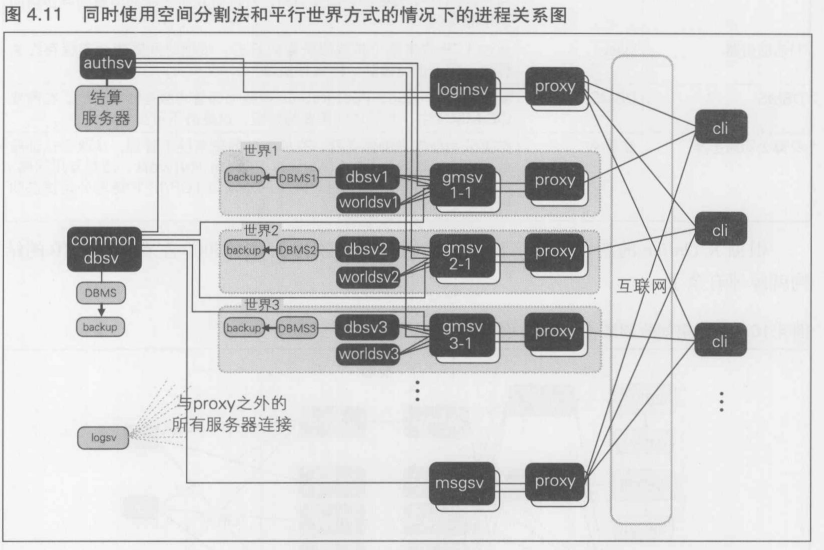
4.5.4 使用平行世界方式进行扩展的关键点
使用平行世界方式进行扩展的关键是将dbsv分为dbsv1, dbsv2, dbsv3这样的多个数据库服务器,从而线性地提高存储游戏数据时的写入性能.将平行世界的单位作为gmsv的个数是因为改变游戏的进程只有gmsv. loginsv和msgsv与游戏进行没有直接关系, 所以与gmsv的个数无关
在K Online中, 我们已经进行了估算
- 收费认证服务器是共通的
- 分为5个平行世界, 1个平行世界允许同时连接6000名玩家, 总共允许3万名玩家同时访问玩家
- 1个平行世界分为8个地区(8核)
- 1个平行世界准备360个实例(16核)
- 玩家继续增加的情况下, 追加平行世界
图4.11反映了这样的设计
- 尽量使authsv进程并行化,实际的进程数由结算公司的程序所约定的结算执行速度来决定
- 各个世界中, worldsv为1个进程,gmsv中地区用到8个进程,实例用到16个进程,不能动态增减
- proxy和gmsv的个数相同(8 + 16)
- dbsv, MySQL,备份用的MySql每个世界1套
- msgsv是所有世界共用的, 尽量并行化.实际的进程数要根据之后的基准测试来决定
- logsv是所有世界共用的, 只要1个进程, 生成多少日志要在开发中决定
4.6 [3] 带宽/服务器资源估算文档的制定
4.6.1 以进程列表为基础估算服务器资源

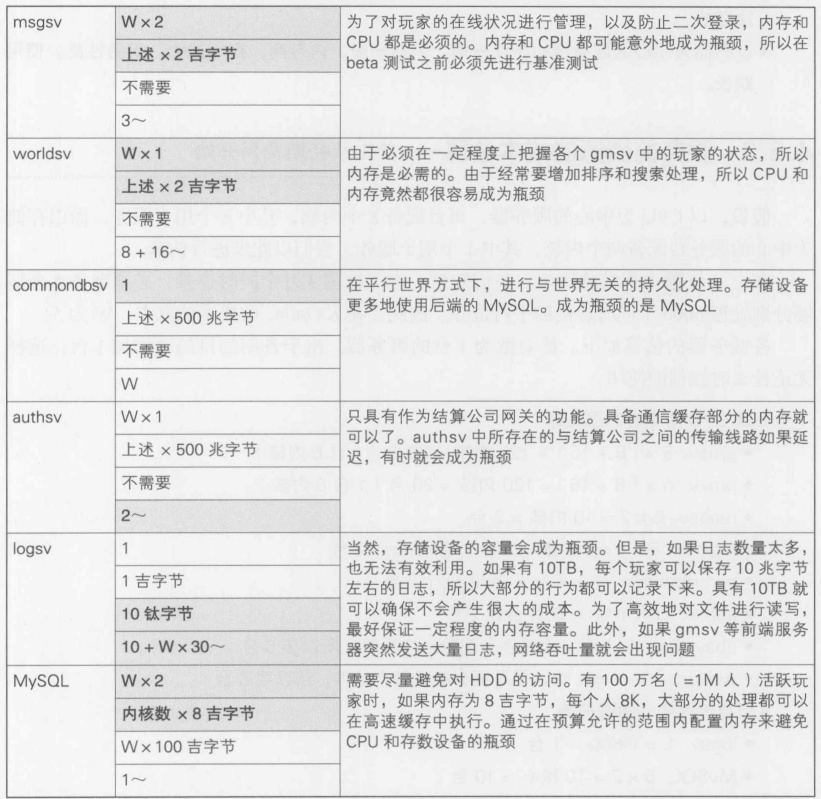
- CPU(内核)
表示所需的CPU内核数.1表示常数,整个服务器只要1个就可以了.W x 2表示需要的个数为世界数的2倍
- RAM
服务器所需的物理内存. 内核数 x 2 吉字节表示: 如果内核数预计为 W x 2,RAM就必须达到 W x 2 x 2 吉字节
- 存储
所需的存储量. 事实上, 对数据内容进行持久化的只有MySQL, 所以在MySQL的地方, 存储量与W成正比,除此之外并不特别需要(网络引导等也可以)
- TCP会话数
TCP会话数以及通信吞吐量会给操作系统和路由等造成负荷,需要作为必要的资源来进行估计. 因为只有proxy大量接收来自玩家的TCP,所以除了proxy,TCP会话数成为瓶颈的可能性很低
4.6.2 以CPU为中心的服务器和以存储为中心的服务器
在进行估算时, 服务器可以大致分为"以CPU为中心的服务器"和"以存储为中心的服务器"两大类.它们各自的特点如下所示:
- 以CPU为中心的服务器: CPU较快,内核较多, 内存一般, 存储量少, 容错性低, 一次性的
- 以存储为中心的服务器: CPU一般, 内核一般, 内存高, 存储量大,容错性高.使用期长
4.6.3 服务器资源的成本估算----首先从初期费用开始
假设,以CPU为中心的服务器,每台配备8个内核, 其中6个用于服务, 而以存储为中心的服务器配备两个内核,其中1个用于服务,我们以此来进行估算
在上一节[2]进程结构图中, 我们知道, 为了处理3万个同时连接,必须准备个能够分别处理6000个同时连接的平行世界.因此, 在K Online的成本估算中, W为5
各服务器的估算如下. 绝对数为1台的服务器,出于备用的目的再增加1台,这样无论什么时候都能使用
- 以CPU为中心的服务器
gmsv: 5 x (8 + 16) = 120内核 = 20台(1台6内核)
proxy: 5 x (8 + 16) = 120内核 = 20台(1台6内核)
msgsv: 5 x 2 = 10内核 = 2台
loginsv: 5 x 1 = 5内核= 1台 + 备用 合计2台
commondbsv: 1 = 1台 + 备用 合计2台
authsv: 1 = 1台 + 备用 合计2台
dbsv: 5 x 1 = 1台, 但是要分配给每个世界,所以要5台
worldsv: 5 x 1 = 1台, 但是要分配给每个世界, 所以要5台
- 以存储为中心的服务器
logsv: 1 = 1核心 = 1台
MySQL: 5 x 2 = 10核心 = 10台
以CPU为中心的服务器合计58台,以存储为中心的服务器有11台.除去监控费用和配置费用,仅考虑单纯的初期费用的话, 以CPU为中心的服务器需要20万日元,以存储为中心的服务器需要80万日元,合计就是20 x 58 + 11 x 80 = 1160 + 880万日元 = 2040万日元.再加上备用费, 大概是2300万日元.至此, 用于支持3万个同时连接的服务器成本就大致估算出来了
服务器资源的维护成本
服务器维护成本分为两部分, 第一部分是最初购入服务器设备的成本,第二部分就是恒定的维护成本.事实上, 最初所需的成本与所有的费用比起来并不算多.恒定的维护成本包括: (1)监控成本, (2)更换故障设备的成本,其中服务器的更换费用并不高.故障服务器的更换,每3年全部更换一次就可以
最大的问题是为了确保服务器处于正常状态而需要的监控成本.在24小时监控的情况下, 聘用专业人员的话, 1台服务器每月需要花费3万~10万日元.假设按照最低费用,K Online中监控对象为69台,所以每个月为69 x 3 = 207万日元,每年需要花费2500万日元.3年的话就比初期服务器费用高了两倍.所以, 很有必要尽量减少服务器的数量
4.6.4 带宽成本的估算
除了服务器资源, 带宽方面也要花费很大的成本.带宽是所需资源中非常重要的一部分, 所以必须对其消费量进行估算.在C/S MMO的情况下, 对带宽消费量的估算非常简单
98%的传输量用于玩家和NPC的移动通知
在C/S MMO中, 通信传输量的98%是用在玩家和NPC的移动通知上的. 只要对显示在画面上的角色每秒移动几次进行估算就可以了
在K Online中,1名玩家大致与20名敌人作战. 游戏画面是由二维平面构成的, 所以20个角色的每个坐标用一个4字节的整数(int)表示
- 移动物体的ID: 4字节
- X坐标: 4字节
- Y坐标: 4字节
- 移动方向等附加信息: 8字节
总计20字节, 20个角色的就是400字节,再加上TCP报文头信息总共440字节,由于这些信息每秒发送5次, 所以就是2.2千字节/秒,也就是17.6kbit/s.这是1个人进行战斗时所需的平均传输量.这些都是从服务器发送给客户端的数据包.反之, 从客户端给服务器发送数据包时, 由于只有在玩家进行某些操作时才会发送1次, 所以基本上可以忽略
在K Online中, 游戏内容并非全部都是战斗,如果有一半左右的玩家在战斗,那么每个人平均需要17.6 / 2 = 8.8kbit/s的带宽.3万人同时在线时, 就需要264Mbit/s.通常1Mbit/s每月需要1万日元,所以所需的带宽成本大约为每月200万~300万日元.1年算下来比服务器的成本还高
付费玩家与同时在线数是相同的,这是C/S MMO的定律. 也就是说, 将每月200万~300万日元的成本除以3万,每个玩家需要支付70日元以上的带宽费用.这笔费用是高还是低,这是商业层面的判断,超出了本书的范围,但是玩家还是会觉得偏高吧,如果可以, 最好还是控制在20~30日元之间
4.6.5 带宽减半的方针----首先是调整策划, 然后在程序上下功夫
出于商业角度判断, 如果需要将带宽成本控制在每人每月20~30日元之间, 那么带宽的使用量就要控制在一半一下.毫无疑问, 如果放任不管当然是无法降低成本的
通常, 首先要考虑是否可以调整策划内容,接着再来考虑在程序上下功夫, 虽然实际上两者基本上都是需要的,但是通过调整策划,可以大幅度降低通信传输量.在程序上下功夫不仅会延长开发时间, 也会增加代码的复杂度,导致可维护性下降.而策划的调整,则可以在保持简单的情况下降低传输量
策划的调整----带宽降低方案
那么, 要如何调整策划呢?我们首先来考虑一下,之前说过, 战斗中的移动数据每秒发送5次, 那能不能只发送两次呢?如果可以, 那么通过牺牲一部分游戏动作性,就能将传输量减少一半
事实上, 在Ultima Online等游戏中也是每秒发送两次的,所以我们以此为参考,考虑一下发送次数降低是否会影响到战斗的趣味性
那么我们就来具体看一下. 比如, 对于移动速度很快的敌人,考虑使其不是一步一步行走,而是以一半的频率,一次移动两步以上.这就需要从游戏策划的层面上进行深入探讨,比如, 这么做会对敌人和地形之间的关系造成怎样的影响呢?如果策划内容需要利用细微的地形差异, 那么就可能出现问题.
如果对策划内容进行更为详尽的审查, 或许可以提高传输量估算的精度.传输量的估算是通过对一些恶劣情况的假设计算出的.但是仔细分析一下策划内容就可以知道其实并不需要这么大的传输量
这里, 我们对"每个玩家与20名敌人作战"这一点进行分析, 20名这个数量其实是相当多的,事实上,很难想象所有的玩家都到处与大量的敌人作战,平均下来很可能在10名一下.因此, 策划人员要对制作中的地图以及敌人的分布进行确认,明确一下那些敌人密度很高的地区所占的比例. 经过确认之后, 就能知道其实在一半以上的地区中, 敌人的密度都很低, 只有2~3名同时出现.因此, 将敌人的数量估算为原先的一半也没有问题
在程序上下功夫----带宽降低方案
在程序上下功夫又如何呢? 有一个非常简单的方法. 虽然有10~20名敌人在画面上移动,但并非所有的敌人都在玩家角色的旁边.很多都在稍微离开一些的地方.因此可以这么考虑,在玩家角色3步以内的敌人每次移动时,都发送1次相关的信息,而更远一些的敌人,则是每两次移动发送1次数据.当然还必须确认会不会对想要运用这种方法的策划内容造成影响.确认之后我们可以知道, 在使用魔法进行攻击的情况下, 虽然仍然必须正确地攻击与远处的敌人,但即使将两次发送降低到1次,也没有任何问题.因此可以判断, 远处的敌人可以以50%的一半的发送频率进行发送.这样一来, 50%的50%.也就是可以降低25%
4.6.6 策划内容的分析对带宽的降低很有效
4.7 [4] 协议定义文档的制定----协议的基本性质
一般的协议是指, 为了使计算机通过网络进行通信而互相决定的各种约定事项的集合. 另一方面, 在C/S MMO中, 我们将"进程与进程之间以怎样的顺序交换怎样的内容"这一块称为"协议".为了正确定义这些协议所需的文档则称为"协议定义文档".请注意不要混淆
4.7.1 [4] 协议定义文档的基础
协议定义文档中需要记录以下信息
- 协议的基本性质
- 协议的API规范. 包括函数定义, 参数定义, 调用时序
- 数据包格式. 包括分隔符(Delimiter), 大小, 字节顺序等
C/S MMO 并不使用HTTP, 而是使用采用TCP的专用二进制协议,所以需要单独定义数据包的格式(在使用中间件的情况下就遵循中间件的规定)
4.7.2 "协议的基本性质"的要点
在C/S MMO系统中, 要在TCP的基础上构建专用的协议. 那么这些协议的基本性质有哪些呢?主要有以下这些
- 哪些作为服务器, 哪些作为客户端
- 永久连接,还是一次性连接
- 是否需要在服务器端管理各个会话的状态(是否是有状态的)
- 是否有必要管理认证状态
- 1对1?1对多?还是多对多?
- 是否要推送(Push)信息
- 连接中断时是否需要立即结束服务
简称
- 客户端->cli
- 游戏服务器->gmsv
- 登录服务器->msgsv
- 数据库服务器->dbsv
- (逆向代理服务器->proxy)
- 世界服务器->worldsv
- 全体公用服务器->commondbsv
- 收费认证服务器->authsv
- 日志服务器->logsv
- DBMS->DBMS
- 结算公司服务器->结算sv
4.7.3 协议的种类, 以及进程之间关系的种类
典型的进程之间的关系如表4.5所示, 各个服务器与其他进程使用专用的协议进行连接.这里, proxy通常夹在cli和gmsv之间, 不需要专用的协议,所以这里省略了
表4.5中标有圆圈的地方表示进程之间要进行通信
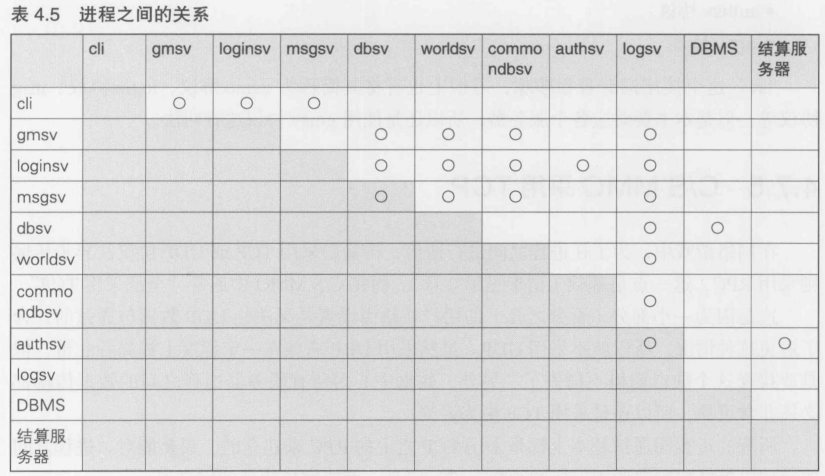
4.7.4 8种类型的协议
- gmsv协议
- loginsv协议
- msgsv协议
- dbsv协议
- worldsv协议
- commondbsv协议
- authsv协议
- logsv协议
4.7.5 C/S MMO采用TCP
在网络游戏中, 为了在进程之间进行通信, 传输层采用TCP或UDP协议, 异步传输则采用RPC, 这一点是基础.而在C/S MMO中通常"全部采用TCP"
这是因为一小部分(百分之几)的用户端路由设置是无法让UDP数据包通过的,为了避免这种情况,所以就不采用UDP. 虽然采用UDP有望在一定程度上提高吞吐量,但是要接受这个缺点就得不偿失了.另外, 数据中心内所有服务器进程之间的数据传输都必须非常可靠,所以还是采用TCP更为妥当
所有的进程间通信基本上都是采用TCP之上的RPC来建立的,只要能对"进程之间的通信以怎样的顺序调用怎样的函数"进行定义,就能完成协议的定义了
4.7.6 与"协议的基本性质"的对应
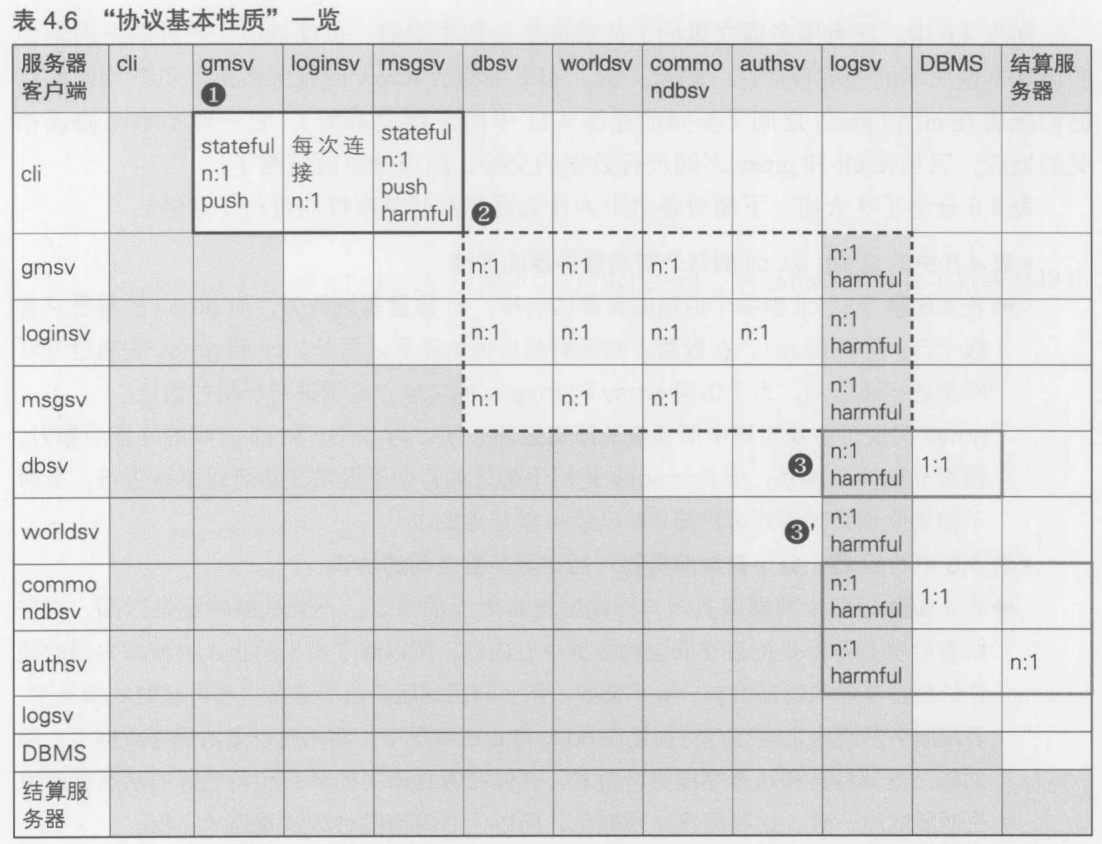
- 哪些作为服务器, 哪些作为客户端
通过表的列和行来表示. 左侧的列表表示客户端,上面的行表示服务器
- 永久连接, 还是一次性连接
基本上所有都是始终连接的,不是的话就写明"随时连接"
- 是否需要在服务器端管理各个会话的状态
需要的情况下记为"stateful"
- 是否有必要管理认证状态
需要的情况下记为"auth"
- 1对1?1对多?还是多对多?
记为"1: 1", "1: n", "n: n"
- 是否需要推送信息
要推送的记为"push"
- 连接中断时是否需要立即结束服务
把这种情况作为critial,但是基本上都是critical的, 所以不需要的情况下就记为"harmful"
在表4.6中,所有服务器在纵向上的值都是一种类型的.也就是说, 一种服务器不会实现基本性质不同的多种协议.顺带一提,本书中称为proxy的服务器出于负载均衡的目的而配置在cli和gmsv之间,它一概不参与协议相关的处理,只是在cli和gmsv之间进行数据的交换,所以省略
表4.6分为了3大组.下面对各组中为什么需要这些基本性质进行了总结
- 表4.6中的组(1): 从cli和各个前端服务器的连接
表4.6(1)是从cli到各个前端服务器的连接.cli数量高达数万,而gmsv的数量只有数十台.即使是n:1, 在数量上也是相当大的差异.另外,cli和gmsv是通过互联网来进行通信的,为了访问gmsv和msgsv的功能,必须进行严格的验证.gmsv实现了游戏过程中所需要的所有逻辑, 所以当gmsv和cli之间的连接中断时, 需要立刻停止游戏, 但是msgsv是用于聊天的,由于游戏还是可以继续进行,有时不需要立刻关闭游戏客户端(K Online就是如此)
- 表4.6中的组(2): 各个前端服务器与后端服务器之间的协议
表4.6(2)是各个前端服务器与后端服务器之间的协议. 不管是前端还是后端,这些所有的服务器都是配置在安全的数据中心内的, 所以除了用于防止人为操作失误的验证机制,其他的验证机制一概不需要.所有与后端服务器的连接中断或超时的情况下,前端服务器则停止运行.特别是在dbsv停止的情况下,明明已经无法保存数据了,但如果还是保持这种状态继续进行游戏, 存储在数据库中的状态和角色等的状态就会发生明显的不一致,这种情况必须避免,所以没有等待数秒尝试重连的空闲
- 表4.6中的组(3)(3)': 具有某些低速输入输出处理的服务器
表4.6中组(3)(3)'是具有某些低速输入输出处理的服务器. 使用DBMS的唯一的服务器dbsv, 以及使用作为外部服务器的结算服务器authsv, 会进行低速输入输出处理.在无法使用DBMS和外部结算服务器的情况下,整个服务无法正常继续, 所以dbsv和authsv都要停止运行. 而由此, 所有的服务都会发生连锁反应停止运行
协议设计的基本策略
总体而言, 出于对编程复杂度, 调试容易度, 测试简单化等方面的考虑, 在与后端服务器通信时应尽可能无状态(Stateless).K Online的游戏内容可以对所有的后端服务器做到无状态
此外, 查询频率在每秒数十次到数百次以上的情况下,每次开始TCP会话所产生的开销会变得很高, 所以需要选择永久连接而非一次性连接.如果一次性连接没有问题, 采用使用HTTP的Web API形式来实现也是可以的
4.8 [4] 协议定义文档----协议的API规范(概要)
4.8.1 协议的实现原则
在K Online中, 8种服务器实现各自的协议. 各协议的基本性质如前所述, 但是各个服务器通过这些协议具体需要提供哪些功能,如何决定调用顺序呢?这里有一系列的原则.
后端实现基本的, 通用的功能, 前端实现专用功能
首先, 一般来讲, 如果要修改某些被依赖的基本要素,依赖这些部分的内容就要全部进行修改,在C/S MMO中也是如此
因此, 通过在后端实现基本的,通用的功能,而前端实现更为专用的功能, 就可以降低系统的修改成本,提高开发效率,如果在各自的进程中实现各项功能,即使发生了内存访问冲突,也可以防止包含了相关功能的部分同时崩溃
前端依赖于后端的结构
尽可能采用前端依赖于后端的结构
实际使游戏进行下去的主服务器当然是gmsv了. 如前所述, 在gmsv中, 大量的游戏逻辑和游戏数据在内存中处理.从程序的复杂度和代码量(行数)来看,特别大的就是gmsv了.gmsv经常需要修改,每周服务器维护时需要修改,每月要修改数十到数百次
但是每次在修改游戏逻辑时, 基本上不需要修改后端的功能, 随着对游戏逻辑的修改, 有时也要在数据库表中添加新列,但这种频率很低,在100次的gmsv逻辑修改中最多只会发生1次, 1年也只有几次
在商业C/S MMO游戏中, 必须每年进行两次"大规模更新"以挖掘潜在用户,开发过程中的列增加姑且不谈,在正式运营之后能进行增加就可以了. 事实上, "对于表4.6中的后端服务器,两年以上都不需要修改"的情况也很多
综上所述, 位于后端部分的服务器先行启动,前端部分的之后启动,然后连接至后端服务器,建立这样的依赖关系比较好
协议是无状态和简单操作的集合
另外, 应该尽可能使协议无状态.这与Web中的REST的思想相同.不要保持协议的状态, 这是因为为了实现应用程序,在客户端自由地进行必要的状态管理,可以简化难以修改的服务端的实现.在C/S MMO中,通过将复杂的处理集中在gmsv中, 可以将需要有状态的协议限制在cli和gmsv之间,这是最低限度的,大家尽量接近这一状态吧, K Online的游戏内容也是可以实现这一点的.如果除了gmsv协议, 还有其他协议需要是有状态的,那还应该进一步讨论是否真的需要
再进一步看, 还应该尽量使协议只具有简单的操作,这也是REST的概念. 在C/S MMO的协议中, 各个后端服务器的协议基本上可以只集中于CRUD这种非常基本的操作.这样可以将后端服务器的修改频率控制在最低程度,从而提高系统整体的可维护性.在gmsv的协议方面,也应该尽量简化操作
在一个地方接受外部的异常状态
还有一个原则就是要尽量在一个地方接受和处理外部异常.比如, 在访问1个文件时, 如果在两个地方对文件读写进行系统调用(比如write()函数),那就在这两个地方都要检查返回值, 如果又增加了好几个地方,检查起来就会很复杂,而且容易出错和遗漏,为了覆盖到这些情况,测试案例也会相应增加.所以, 为了防止这种情况,实际调用write()的地方通常应该限制在1个地方,这样代码就能得以简化, 程序也可以更为健壮
C/S MMO的服务器实现中使用到的输入输出方式只有"网络和文件".这些都是通过调用套接字API, 数据库的API和C语言运行库等程序库和中间件来进行输入输出的,调用失败即为异常
C/S MMO服务器系统中最致命的, 由外部原因引起的异常有以下两处
- DBMS查询失败
- 网络发送失败
这是因为在文件进行读写时就不会执行了
网络发送失败指的是, 由于要在各个进程之间进行网络通信, 所以每个进程都有发生异常的可能
但是执行DBMS查询的地方是可以锁定的. 在K Online的服务器设计中, 之所以要在1个地方进行数据的持久化,就是因为对于游戏服务的进行, "DBMS调用失败"这个最致命的异常只会在1个进程,也就是dbsv中发生.除了dbsv, 其他地方都不会发生这种情况, 所以可以确确实实地抓住问题所在,发生数据库连接异常时的问题也很容易定位
进行某些数据持久化操作的API应该尽可能集中在dbsv协议的一个地方.也许有人会因为担心瓶颈问题而想在系统中配置多个DBMS,但是将其集中在1个地方反而更容易对瓶颈和bug进行检查和修改, 这一点很关键
优秀的API的调用时序----不调用才好吗
最后, API的调用时序以下面的顺序为优
- 不调用API.也就是说不需要(笑. 但这是认真的)
- 只调用而没有返回值的API的单向时序图
- 只调用一次然后获取返回值的呈三角状的时序图
- 呈锯齿状的时序图
gmsv中采用的是使用比线程更轻量级的"回调"和"任务系统"来实现的异步编程, 所以为了实现图4.14所示的这种锯齿状的时序图,回调函数就要增加,导致程序过于复杂,更容易产生bug和时序异常.在K Online中, 在处理角色制定和物品交易等需要互斥机制的部分时, 可以采用图4.13的"三角状时序图"来实现, 除此之外还可以采用图4.12的"线状时序图"来实现.当C/S MMO中存在"锯齿状时序图"时, 就需要对其必要性重新加以讨论

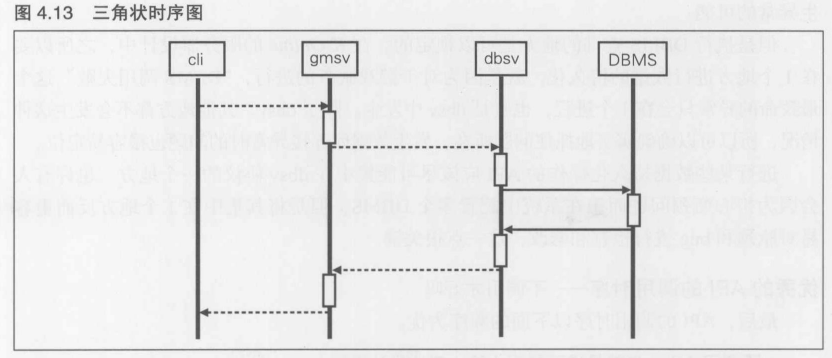
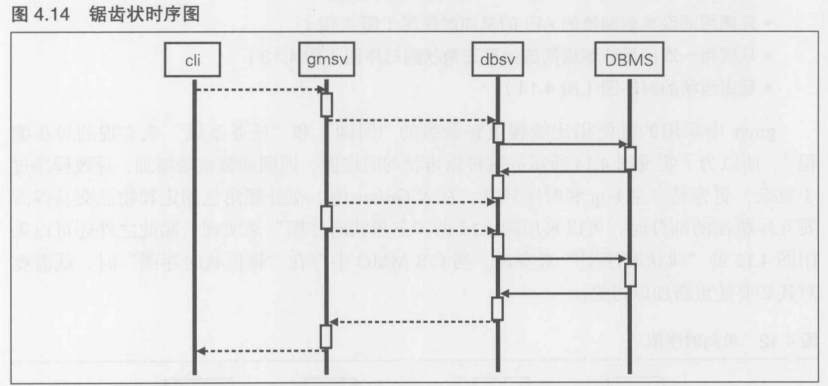
有必要推送(Push)吗
还有一点......将某些信息从服务器推送至客户端,或者说从后端推送至前端时,需要好好考虑一下. 多用信息推送的问题就是, 实际上调用该功能的是其他的进程或其他的程序, 所以在服务端程序中查看代码时,也弄不清是在哪里调用的
比如, 要从dbsv向gmsv推送某些信息, 就要在gmsv中编写回调函数.但是实际调用该函数的是dbsv,如果不看dbsv的代码, 就无法把握整个程序.换句话说, 应该在调用处的附近管理函数的返回.此外, 对接受异步推送的程序进行自动测试也很难编写.如果这样来使用推送,程序的可维护性就会下降
在gmsv和msgsv的协议中, 无论如何都需要推送数据,这时推送就成为核心部分了, 但是除此之外基本上不需要推送.如果随着设计的深入,需要推送时,就应该好好考虑一下是否可以排除这种可能性
4.8.2 8种协议的功能/形式概述
- gmsv 协议
gmsv协议负责执行管理敌人的行动, 事件, 角色升级, 作弊行为检测等的游戏逻辑
gmsv针对cli实现的API大致可以分为以下3种. "通知"反映了只调用, 没有返回值的单向时序图."请求"反映了调用1次, 期望返回1次的"三角时序图"
1. 来自cli的通知
典型示例: 使用鼠标移动角色立即发送的移动通知API. 不需要返回值,之后消息从gmsv送达. 全部通过写操作来改变gmsv内存中的数据. 如果有必要,gmsv需要通过dbsv对这些数据进行持久化
2. 来自cli的请求
典型示例: 打开物品栏时, 获取当前所持物品列表的API. 这是获取信息的请求. gmsv原样返回内存中游戏状态的信息
3. 来自gmsv的通知
典型示例: 敌人的行为.即使cli没有发送任何指示, gmsv仍然要每秒发送数次通知. 内存中的游戏状态发生变化的瞬间,gmsv对必要的cli发送信息
在gmsv的内存中, 以对象数组或列表(List)来存储玩家角色, NPC, 物体, 效果, 物品等,对此可以通过 1~3的方式来访问
- loginsv 协议
loginsv是游戏客户端(cli)登录游戏时最先连接的服务器, 负责服务器整体使用情况的管理, 负荷的控制以及会话密钥的分配等
loginsv对cli提供的API只有从cli对loginsv发出请求,包括密码验证, 以及查询能够使用的gmsv列表
- msgsv 协议
msgsv是用于使聊天, 即时消息, 公会等社交活动能够跨越平行世界和空间分割来进行消息交换的服务器
msgsv对cli提供的API与gmsv一样, 也大致分为3类
1. 来自cli的通知
典型示例: 聊天输入, 只是调用不需要返回值,所以一旦用户按下Enter键就立刻发送.msgsv接收到该消息后, 就向其他玩家发出通知.好友的添加也是如此
2. 来自cli的请求
典型示例: 获取好友列表
3. 来自msgsv的通知
典型示例: 好友登录时发送的上线通知. 作为1的结果而发送的来自其他玩家的聊天消息也对应这一点
- dbsv 协议
对MySQL和Oracle等DBMS进行统一的连接, 在异步访问数据库时, 实现必要的负荷降低处理
将DBMS中各个表的CRUD操作作为API来提供.虽然从gmsv, loginsv, msgsv等前端服务器进行访问, 但只有以下两点不从dbsv推送数据
1. 来自前端服务器的通知
典型示例: 玩家角色的保存.保存是绝对必要的, 一旦保存失败就意味着gmsv需要强制终止, 所以不需要返回值
2. 来自前端服务器的查询
典型示例: 玩家角色的加载
- worldsv 协议
使用空间分割时, 属于世界的所有gmsv都连接到这个服务器进程上,负责为各个世界提供通用处理.在K Online中, 用来实现"显示世界地图(用来指示玩家处于游戏世界的哪个位置)"的功能.具体有以下两点,不从worldsv推送
1. 来自gmsv的通知
典型示例: 保存所有在线玩家的坐标
2. 来自gmsv的请求
典型示例: 获取包括其他gmsv在内的所有玩家的坐标
worldsv不需要对坐标信息进行持久化, 所以不使用DBMS
- commondbsv 协议
在使用平行方式的情况下,对所有的世界共同需要的信息进行持久化.在K Online 中需要保存用户ID, 密码信息, 以及好友列表信息.这些都是与世界无关的而又必要的信息. 所有的gmsv, loginsv, msgsv连接至该服务器
提供的API有以下两种, 不推送
1. 来自gmsv的通知
典型示例: 通知指定的gmsv中当前有多少人在线
2. 来自loginsv, msgsv, gmsv的请求
典型示例: 获取各个gmsv中当前的在线的总人数
不使用平行世界方式时, 不需要commondbsv, 这种情况下commondbsv的所有功能都由dbsv来实现
- authsv 协议
authsv调用结算公司所提供的API(大多是Perl和C语言编写的程序库),相当于与结算公司之间的网关
K Online采用"每月定额计算"的方式, 提供的API只有"来自loginsv的请求",
- logsv 协议
通过TCP收集整个游戏服务中的日志, 根据时间顺序来罗列, 保存在文件中, 用于进行循环检索等处理, 提供的API是"各服务器的日志写入",只有单方向的通知, 所以没有请求,推送
4.9 [4] 协议定义文档----协议的API规范(详细)
4.9.1 协议API规范(详细)的制定
4.9.2 API的函数定义
各个服务器所提供的API, 也就是函数, 在K Online这种规模的游戏中大致有200~500个.比如, 进行信息持久化的数据库表有30种, 各自包含CRUD操作和应用方面的API,实际对各种数据库表的操作进行定义时, 差不多就是这种程度的量. 因为需要定义如此多的API,所以通常使用中间件等支持工具,以某种机器可读的形式来定义函数, 常量和类型,否则很难进行控制
gmsv 协议
首先从gmsv协议的代表性API开始
- 使用鼠标移动角色时, 立即发送的移动通知
void move(int x, int y); (1) one-way message(单向消息)
- 打开物品栏时, 获取当前的所持物品的列表
void get_inventory_list(); (2) query查询
void inventory_list(int item_id[]); (2)' query result(查询结果)
- 从gmsv向cli通知敌人的行动
void notify_move(int id, int x, int y); (3) notification(通知)
针对(2)的请求, 从gmsv返回给cli是通过异步调用其他API来实现的. 也就是上面(2)'这个API
因为在K Online中, 所持物品的状态可以用整型数组来表示, 所以可以通过(2)'的API, 从服务器返回所持物品的所有信息.因为它所表示的是查询结果,所以注释标为"query result"
API的类型和消息的特性

loginsv 协议
游戏客户端(cli)在登录游戏时最先连接到loginsv, 由该服务器负责进行验证,管理服务器整体的使用情况,控制负荷以及分配会话密钥.
void get_session_key(char email[], char password[]); query
void session_key(int result, char key[]); query result
msgsv 协议
通过msgsv协议, 聊天, 即时消息, 公会等社交活动就能够跨越平行世界和空间分割来进行消息的交换
- 聊天消息的输入
void say(char text[]); (1) one-way message
void notify_say(int said_by, char text[]); (1) notification
- 好友列表的获取
void get_friend_list(); (2) query
void friend_list(friend_t contacts[]); query result
- 上线通知
void notify_presence(int); (3) notification
friend_t: {
int player_id;
char player_name[];
}
dbsv 协议
dbsv协议是用于将游戏数据在数据库中进行持久化的协议. dbsv是后端服务器,所以调用这个API的是gmsv和msgsv等前端服务器
void save_character(int player_id, character_t data); (1) one-way message
character_t: {
unsigned int hp; 角色的当前体力值
unsigned int maxhp; 角色的最大体力值
unsigned int money; 所持有的金钱
...
}
void get_character(int player_id); (2) query
void character(int player_id, character_t data); (2)' query result
worldsv 协议
worldsv协议是世界中所有gmsv都要连接的服务器协议, 负责各个世界都需要的处理. K Online中使用worldsv来实现"显示世界地图(用来指示玩家处于游戏世界的哪个位置)"的功能
void update_player_position(int player_id, int x, int y); (1) one-way message
void get_all_player_position(); (2) query
void all_player_position(player_position_t list); (2)' query result
player_position_t {
unsigned int player_id;
unsigned int x, y;
}
commondbsv 协议
commondbsv协议是实现所有世界共同需要的内存中处理的进程.所有的gmsv, loginsv, msgsv都连接到该服务器上
void update_concurrent_player_num(int world_id, int gmsv_id, int num); (1) one-way message
void get_concurrent_player_num(); (2) query
void concurrent_player_num(concurrent_player_t list); (2)' query result
concurrent_player_t {
int world_id;
int num;
}
authsv 协议
authsv服务器进程调用结算公司提供的API, 相当于与结算公司的网关
void get_payment(char email[]); (2) query
void payment(int result, char email[]); (2)' query result
logsv 协议
通过TCP收集游戏服务中的所有日志, 按时间顺序排列,保存在文件中,用于进行循环检索等处理
void print_log(char message[]);
4.9.3 常量定义
typedef enum {
PAID, 完成支付
UNPAID, 未支付
SUSPENDED,
...
} auth_result_t; 表示authsv协议所用的值
typedef enum {
SUCCESS, 成功
NO_CHARACTER, 角色不存在
...
} db_result_t;
4.9.4 API的调用时序

必要的时序图----关系到多个进程的典型处理是什么
- 验证
- gmsv中的角色创建
- 登录gmsv, msgsv
- 从gmsv登出
- gmsv中的角色移动
- gmsv中角色的商业操作(购物, 交易)
- msgsv中向好友列表添加, 删除好友
- 向在线好友发送消息
复杂性尽可能集中在网络的终端, 也就是cli侧
复杂性指的是条件分支和异常处理等根据情况的不同而由所差异的程序所特有的处理. 后端服务器侧应该尽可能不依赖于上下文,只实现简单的功能. 这样一来, 之后需要修改处理内容时, 就可以减少要修改的地方了
1. 验证
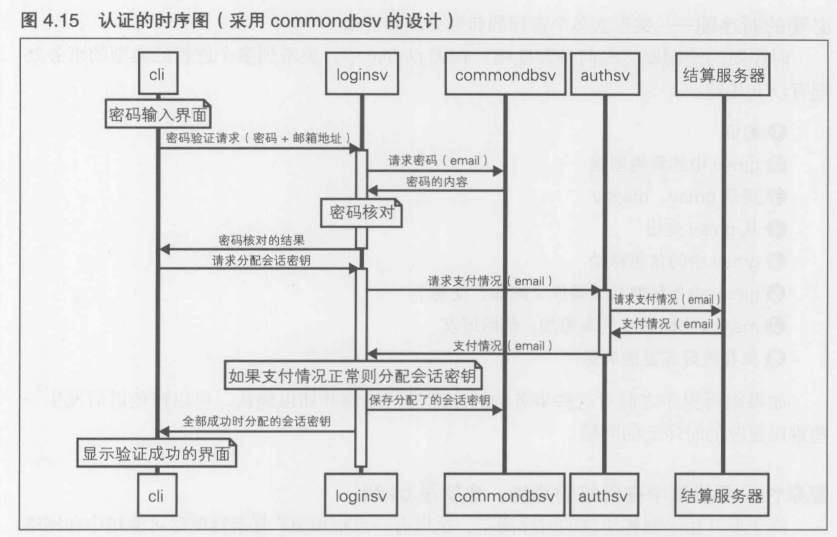
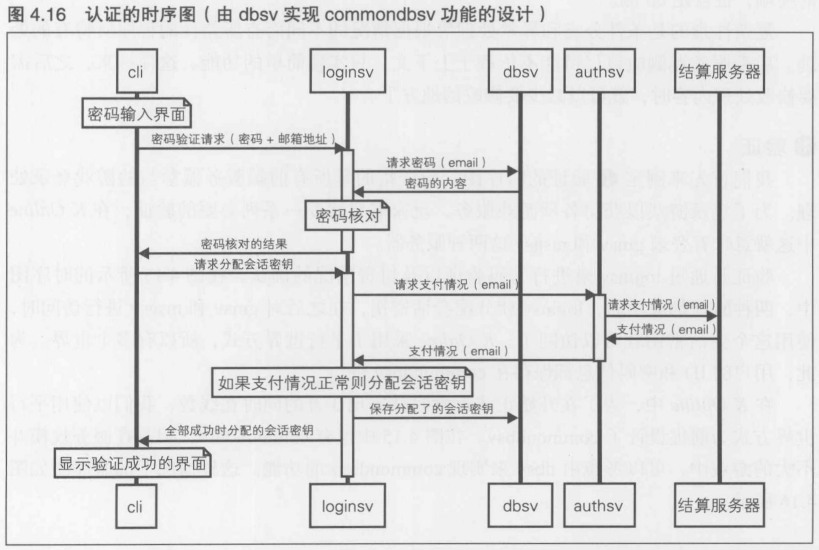
2. gmsv中的角色创建

3. 登录gmsv, msgsv
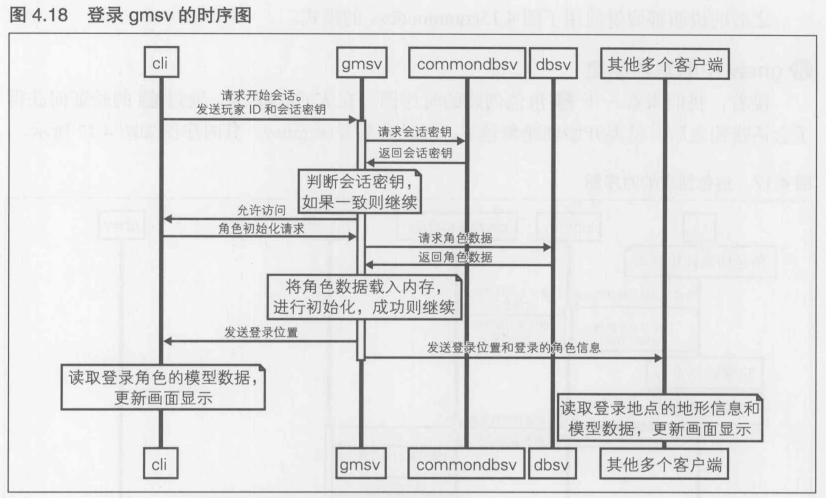
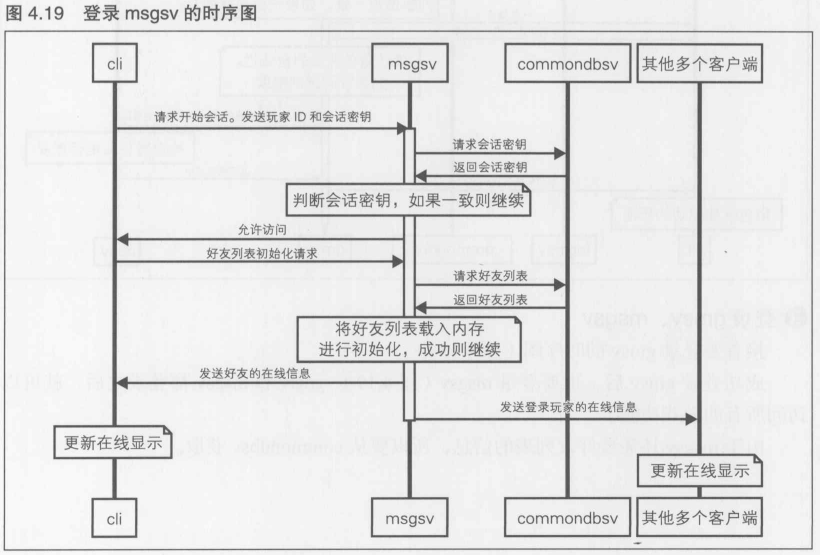
4. 从gmsv登出
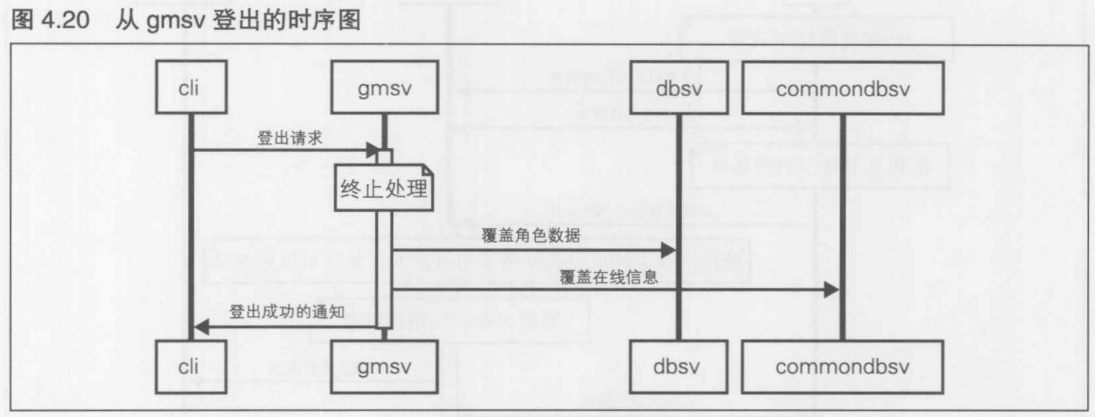
5. gmsv中的角色移动

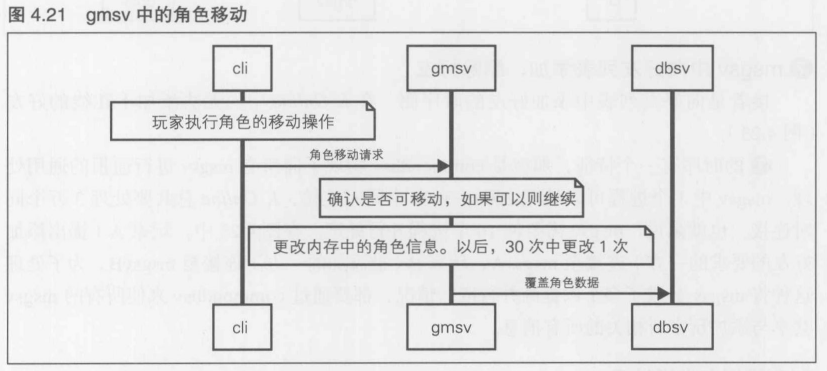
6. gmsv中角色的商业操作(购物, 交易)
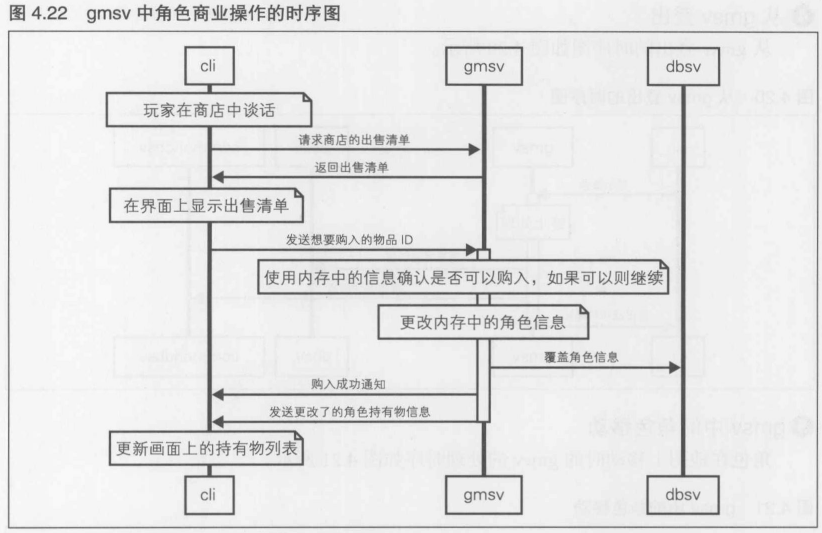
7. msgsv中向好友列表添加, 删除好友
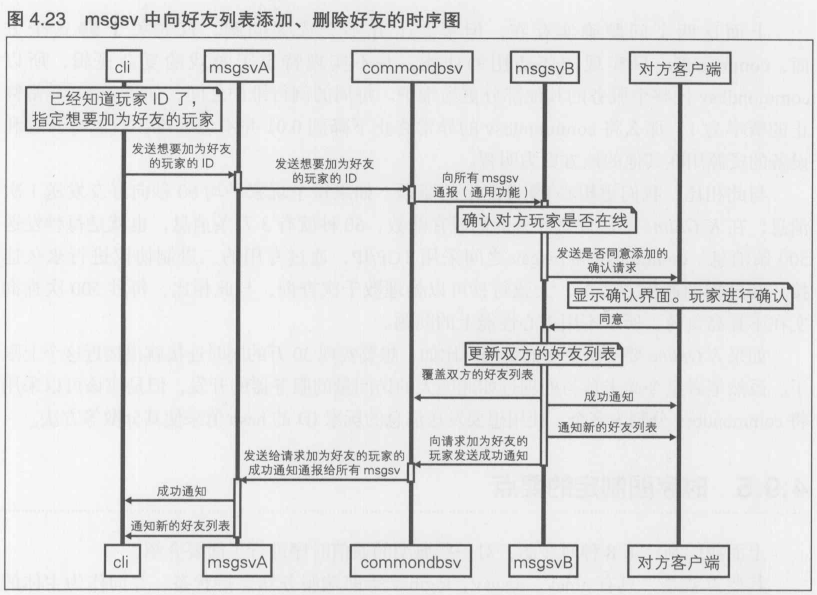
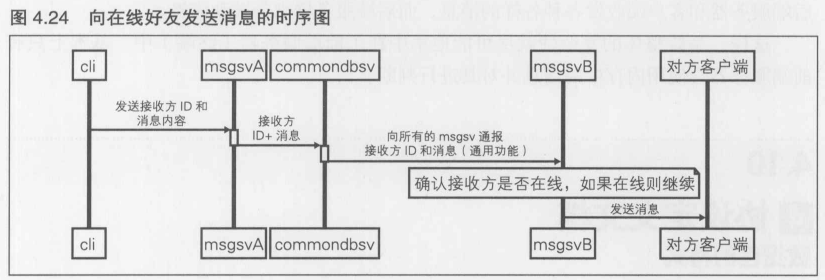
4.9.5 时序图制定的要点
上面我们指定了8种时序图, 对一些典型的通信时序进行了简要介绍
其要点就是, 只有gmsv, msgsv, loginsv等前端服务器保持状态, 并向作为主体的后端服务器和客户端收发各种各样的消息,而后端服务器则是被动应答
这样, 系统整体的复杂性就尽可能地集中在了前端服务器(终端)中. 基本上只有前端服务器会使用内存中的信息并对其进行判断
4.10 [4] 协议定义文档----数据包的格式
4.10.1 C/S MMO主要采用TCP(复习)
4.10.2 C/S MMO使用包含专用字节数组的二进制协议
TCP是一种流式协议,理论上数据包是连续的,不存在间隔.因此当调用了两次RPC时, 为了在数据接收侧判断到底调用了1次还是2次,需要有一些规则来分隔各个数据包
在Web和电子邮件等通用系统中, 通常使用以HTTP为首的文本协议,这类协议使用换行记号来分隔记录,但是在C/S MMO中, 需要实现"处理负荷降低","耐得住更改和攻击", "要有良好的开发效率".为了满足这些条件,除非特殊的情况,否则都使用"包含专用字节数组的二进制协议".这是因为,由于C/S MMO的服务器中每秒几千次的RPC调用都是从cli接收的,为了进行庞大的文本处理,需要避免过多使用CPU
4.10.3 二进制协议的实现----首先从术语的整理开始
那么, 我们就来看一下如何实现二进制协议. 通常, 与IP和TCP等通用协议相同, 采用交替发送固定长度的报文头和可变长度的数据的形式.报文头中保存了数据部分的长度等元信息.下文中,我们将1组的报文头和数据部分称为"记录"
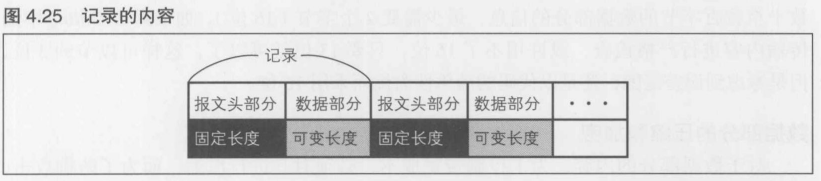
"TCP流"由一系列0字节~1400字节左右的不定长的"TCP数据包"组成. 根据途中经过的路由, 操作系统的设置等, 流的长度会发生变化.通常最大长度为1460字节.之后所说的"数据包"指的就是TCP的数据包
我们接着来看一下TCP数据包的内部, TCP数据包的边界指的是先前所述的由报文头和数据组成的记录. 图4.26中只标示了1个记录,但事实上, 流中各记录之间是没有间隔的,全都紧密相连
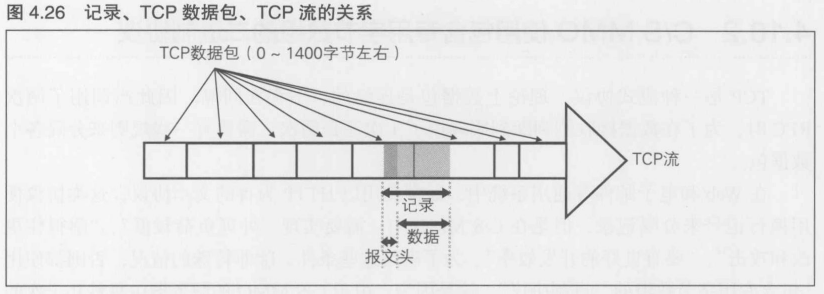
记录的大小
在C/S MMO中, 1个RPC参数并不需要这么庞大的数据, 这是因为虽然用户每次进行某些操作时都会调用某些RPC, 但是用户的操作基本上就是从鼠标和键盘进行输入, 虽然操作频率很高, 但是字节数并不多, 充其量也就数十字节的程度
C/S MMO中各个记录的长度也就数十至数百字节,虽然很短, 但是发送频率很高, 综合下来, 传输量也不小. 实际的传输量就如"必要的带宽估算"中所述的那样
报文头
下面来考虑以下实际的数据内容.毫无疑问, 报文头还是短一点比较好. 为了保存数十至数百自己的数据部分的信息,最少需要2个字节(16位). 如果对K Online中的传输内容进行严格检查, 或许用不了16位,只要13位就可以了, 这样可以节约3位, 但是考虑到误差范围,还是以代码的简单性为优而采用16位
数据部分的压缩和加密
对于数据部分的内容,为了控制带宽成本, 必须对其进行压缩,而为了防御攻击, 必须对其进行加密
如果使用了合适的压缩算法,可以将从gmsv到cli的传输量降低50%.虽然数据包内容的压缩会对CPU造成一定的负荷,但是比起带宽成本, 服务器的CPU成本还是很低的,所以在商业上的优势非常大.然而, 从cli到gmsv的传输不会重复发送同样的数据, 基本上无法对压缩效果进行估算, 所以就算不压缩也没关系.在数据包中设置两个字节的报文头来存储压缩后的大小, 适时地将数据传递给解压缩程序
接着, 为了提高安全性, 需要对数据部分加密.其目的是在数据包的传输过程中, 对来自怀有恶意的第三方的入侵(称为 Man in the middle 攻击, 中间人攻击)进行基本的防御. 这里说"基本"是因为, 在知道了在cli和gmsv中实现的加密算法后, 从开始TCP会话起, 除非拦截所有的数据包,否则无法得知数据包中的内容
一般来讲, 肯定是通信链路越安全越好. 但是, 加密程序会给CPU带来很高的处理负荷, 而且对用户来说, 每次输入密码也很不方便, 所以也有缺点.作为娱乐性质的服务, 不仅支付不了这么巨大的成本, 还给玩家带来了很大的麻烦.因此, 公认为最可靠的电子签名的的机制并不符合C/S MMO的要求.在很多情况下, 使用RSA 和 Diffie-Hellman 等密钥交换方式来共享密钥, 然后在会话存在期间持续使用该密钥,这样可以大幅降低Man-in-the-middle攻击的风险(完全消除是不可能的),而不管在CPU成本方面,还是在给玩家带来的体验方面,在C/S MMO中都还不错
实现上的要领
综上, 通过RPC发送的数据被序列化之后, 对其所生成的字节序列,需要一个用来对其进行压缩的层和一个用来加密的层
至此所考虑的报文头的最小长度为两个字节. 但是在从cli到gmsv的通信中不需要压缩, 而前端服务器和后端服务器等数据中心内部的传输则不需要加密, 即使是在一个C/S MMO系统内部,对通信链路的要求也各不相同,为了充分实现用来生成各个进程之间的记录内容的程序,建议对加密层和压缩层进行划分,使其可以交换
比如, 划分成一个具有两个字节报文头的压缩层和一个具有两个字节报文头的加密层, 虽然这样一来原本两个字节的报文头就变成了4个字节,但这么做就可以用很简洁的方式来实现加密功能的去除, 压缩功能的去除,对单个功能进行测试以及进行性能测试等. 典型的针对C/S MMO的通信中间件就是这么实现的
图4.27中所示的记录中具有两个报文头, 其最内侧保存了序列化之后的数据. 此外, 为了提高压缩率,加密一定要在压缩完成之后进行,这一点请务必注意

专栏 C/S MMO的压缩和加密
包括OSI参考中的物理层在内, 本文所提到的RPC序列化层的层次结构入下
- RPC序列化(序列化通过RPC发送的数据)层: 将RPC转换为二进制数据
- 压缩层: 对序列化之后的数据列进行压缩
- 加密层: 对压缩之后的数据进行加密
- TCP: 将加密后的数据放在数据流中
- IP(IPv4): 将数据流放在数据报中, 在cli和gmsv之间传递
- 以太网(等): 在链路中的各设备之间传递数据
- 物理层, 在链路中, 传递电信号和光信号
从上到下依次对应着层次的从高到低. 在C/S MMO中, 由于压缩和加密功能的增加, TCP上面增加了两个处理层
4.11 [5] 数据库设计图
在同时在线数众多,累积性很高的某些C/S MMO中, 用于数据持久化的数据库设计非常重要.
4.11.1 要在编程之前进行对重要的表进行设计
在C/S MMO中, 良好的数据库设计就意味着被持久化的信息的结构非常清晰, 能够高效检索所需的信息. 这样运营和管理工作也就更容易进行了. 比起持久化信息较少的其他形式的网络游戏, 数据库设计在C/S MMO中格外重要
4.11.2 C/S MMO中的数据库实现的历史变迁
20世纪70~80年代: 没有数据持久化,复活咒语
20世纪90年代: 保存在文件中
本世纪初前期~: RDBMS
4.11.3 整理K Online所需的表
专栏 百花缭乱的KVS 未来C/S MMO中数据库的使用情况
现在, 距离RDBMS的使用已经过了好几年, 在今后的MMO开发中,作为RDBMS之外的另一种选择,KVS(Key-Value Store, 键值存储)开始暂露头角
以笔者使用过的MongoDB为例, 介绍一下KVS的典型特征, 以及它和RDBMS之间的区别
- 无模式
- 只有简单的查询
- 高速
- 不能使用事务功能
需要持久化的信息以及数据的包含关系
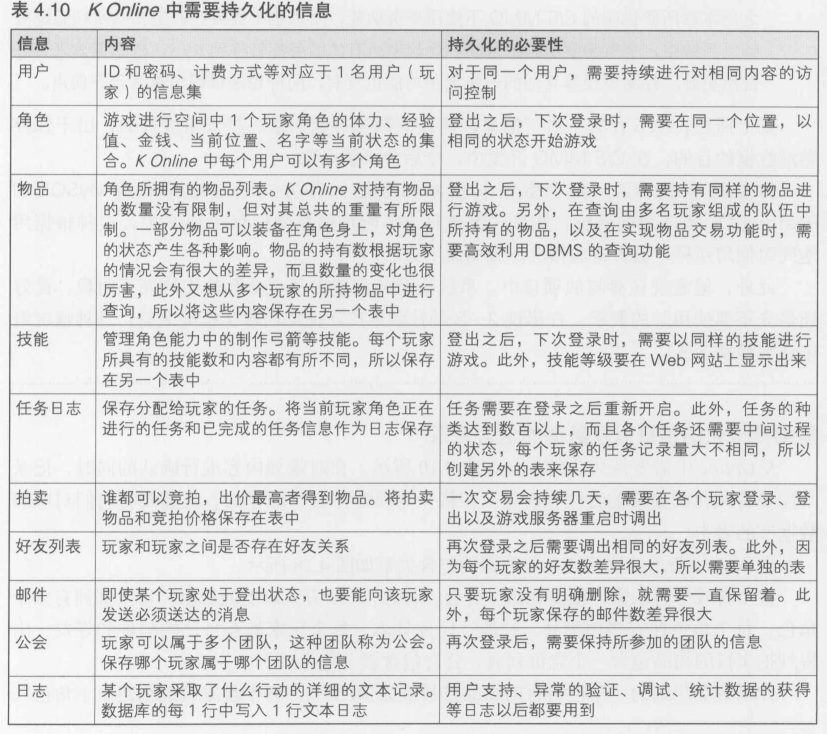
4.11.4 数据性能预测
数据库的处理性能大致与表中存储的数据量(行数)的对数成正比, 与访问频率的1倍成正比.此外, 一般来说, 数据库写入操作方面的性能是很难提高的,而读取操作的性能则相对比较容易提升.因此, 一开始只要在数据量和访问频率方面, 将读取操作和写入操作分开预测就足够了
对数据库的查询大致分为以下几种
- 类型1: 指定主键, 只取出1行的查询
- 类型2: 使用包含主键在内的1个以上的索引,以一定的条件(比如两个值之间的范围等)来检索, 排序的查询
- 类型3: 不使用索引的查询
从数据库性能的观点来看, 基本上不要采用类型3这种方式, 类型2也应该控制在最小程度, 大部分由类型1构成是最理想的
表4.11中针对各个表, 以运营开始1年后达到100万登录用户, 3万同时连接为前提, 进行了预测

表的特性,必须注意的表
首先是关于read的, 除了日志以外, 其他表的访问模式都是10分钟1次, 另外, 只有在拍卖和邮件等历史信息很重要, 需要进行检索的表中采用类型2,其他都是采用类型1.对于类型1, 具备KVS的功能就足够了
接着, 关于write, 对于用户表, 基本上不进行写入.对于角色, 物品, 任务日志,1分钟写入1次,是读取频率的10倍.C/S MMO与其他Web服务的一大区别就是"写入占了绝大部分"
对于日志表, 10秒进行1次write, 整体就是每秒3000次,频率相当高, 所以必须采取一些措施.其他的表都是1小时~1天1次,频率很低,不会成为负荷
综上所诉,对于read, 只要注意"拍卖", "邮件"这两个表.对于write,注意"角色","物品", "任务日志"这几个表就可以了
查询的内容----read篇
知道了需要注意的表后, 我们就可以回到游戏的策划内容上,简单地来看一下实际上要进行怎样的查询.首先来看一下read中的拍卖表
游戏世界中设有拍卖行, 如果玩家角色与那里的NPC进行对话后, 就会打开专门的交易窗口,使用该窗口进行所有的操作. K Online中的竞拍规则与Yahoo!相同, 出价最高者可以得到竞拍物品.这与股票市场不同,各个被拍卖的物品具有很多信息,完全相同的拍卖品基本上一个也没有.比如,在K Online中, 拍卖物品具有"等级23的铁剑,攻击魔法+3%, 嵌有宝石"等各种信息
拍卖的典型实现方法是分为两个表: "拍卖物品表"(每一行对应一个拍卖物品)和"竞价表"(每一行对应一名买家的竞拍价格).只有在拍卖和出价时才会进行write, 查询频率很低,所以完全没有问题
"在买家查询拍卖物品时显示列表"和"获取某个拍卖物品的竞价列表"这两种处理的负荷较高
列表的显示需要同时用到多个设置在拍卖物品表中的索引,将其进行排序, 然后每次显示20项左右的结果. 每秒50次, 也就是说要在20毫秒内完成1次处理.这相当令人担忧.估计拍卖表的大小为10吉字节左右,所以通过装配更大的服务器内存,可以全部在内存中进行处理,这样处理速度可能比20毫秒更快,但是在测定处理时间之前,最好还是不要做出这么乐观的估计.必须想好将来处理性能不足时所能采取的措施. 那时, 还是要回到策划内容上来加以考虑
首先, 查询是只读处理.通常, 如果允许read操作在时间上有所延迟,就可以获得很大的扩展性.对K Online的策划内容加以确认. 由于是在新物品加入拍卖之后才开始更新拍卖物品列表的,就算延迟10~20秒以上也没关系,所以在DBMS的处理性能不足的情况下,可以考虑使用DBMS的复制功能和memcached等在之后改变表的数据项结构. 获取竞价历史也可以考虑同样的方法
与拍卖一样具有很多read的操作的还有邮件, 在提高邮件读取的性能时, 可以采取与拍卖相同的方式
查询的内容----write篇
接着考虑一下对角色表,物品表, 任务日志表的write操作.同时连接数为3万的情况下, 每秒对这些表写入500次
- 角色表
- 物品表
- 任务日志
保存的数据最多的显然是角色表. 对于100个列, 如果每秒500次, 每次写入10千字节,就相当于5兆字节/秒. 频率相当高,单从数字来看,就相当于在1台Linux机器上运行1个DBMS(比如MySQL)实例所处理的量. 但是万一用户进一步增加的话,还可以做些什么呢?
在K Online中, 我们使用所以来查询角色的状态,所以对数据库进行横向分割是很容易的.横向分割是指什么呢?比如说, 将表示用户ID的字符串按照A~M,N~Z这样根据取值的范围来分割.通常使用的分割方式有取值范围, 列表, hash值等.这是一个不用更改表结构,之后还能采取一些对策的好方法.
4.12 服务器/客户端软件 + 中间件----实践中不可或缺的开发基础
4.12.1 网路游戏的中间件
K Online是商业项目, 编程工作应该尽可能简化, 如果能降低工作量就能提高利润,这是因为收回投资所需的时间变短了.此外,在要编写的程序中, 对于那些与游戏差异化元素无关的部分,应该积极使用已有的资源, 把时间花在开发差异化内容的工作上.
C/S MMO中间件
C/S MMO中间件有好几种形式. 一般来讲, 中间件中存在着一种基本的权衡关系: "越是对应用程序的用途加以限制, 就越能减少编程量"
全功能型中间件
在C/S MMO中也有售卖以现有C/S MMO游戏为基础的工具.当前最著名的有美国Bigworld公司的产品BigWorld MMO Technology Suite. 该产品以市场规模最大的幻想MMORPG为中心.其特点就是完整包括了以下这些内容: 在模拟了广阔的3D地球环境的自然环境中高效部署地下洞窟, 神殿和高塔等在RPG中经常出现的地形的工具, 定义敌人行为的工具, 可以使用Python来自定义游戏服务器的系统,与3ds Max等建模工具进行协作的功能,以及客户端程序的框架, 等等. 仅仅是备齐这些功能恐怕就要数千万日元以上.这种中间件可以称为"全功能型中间件",使用这种中间件基本上可以省掉编程工作
关注于幻想MMORPG的全功能型中间件还有Hero Engine和Monumental公司的产品等. 这类中间件经常在拥有几亿日元预算的大规模游戏中使用
C/S MMO并不只有预算规模相当大的幻想MMORPG. 这几年, 休闲MMO和虚拟世界类游戏的用户急剧扩大.这些项目的预算额也有在5000万日元以下的, 非3D的也很多
事实上, K Online所参照的Runescape就是其代表, 所以不需要像BigWorld产品或Hero Engine这样处理真正的3D空间,也不需要那些基于物理规则的实时行为以及服务器地形的无缝连接.比起这些功能,更需要关注物品的拍卖功能和任务脚本的实现等独特的功能,但这些功能大多不包含在全功能型的中间件中
小规模性MMOG中间件
在预算规模较小, 游戏内容不是幻想MMORPG的情况下, 全功能型中间件就不怎么适用了.但即使是这种情况, 也应该尽量避免完全自己开发.减少自己开发的内容,参考已有的内容,在这一点上,与《网络创世纪》兼容的协议所对应的服务器充斥着市场, 所以也可以参考.此外也有一些商业MMOG(比如Ryzom等)公开源代码的情况. 过去一段时期中, 也有一些实现了MMORPG中部分功能的开源中间件可供获取,但是使用这种中间件的引擎基本都没有被广泛使用.在使用开源MMO中间件的情况下,需要自己对源代码的使用负责.特别是, 与Web服务等不同, MMO并不是游戏通用的工具, 所以没有像针对Web的框架那样的用户社区很发达的工具.因此, 参考源代码跟自己来开发基本上没什么差别
开源中间件可以称为"小规模型MMOG中间件".比起全功能型中间件,使用这种小规模型的中间件,可以制作更多类型的游戏, 但是需要自己开发的部分多了很多
通信中间件
还有种更加不涉及游戏内容的解决方案.那就是对游戏内容一概不作规定, 纯粹只用通信中间件,除此之外全部自己制作.这里所说的通信中间件指的是libevent和Twisted等用于处理网络事件的中间件
在称为虚拟空间和虚拟人物聊天的服务中, 虽然服务器的基本结构以及数据库设计都与MMORPG的相似, 但是它不存在游戏世界的概念, 没有活动在服务器中的敌人, 玩家之间的交互除了聊天就再没有别的了,所以只要具备及其简化的服务器就足够了.为此, 反倒是只有通信中间件更为简洁,不需要进行某些清理工作,开发效率更好
4.12.2 开发的基础软件----可以立刻尝试的C/S MMO开发体验
服务器相关的软件
- Linux
作为操作系统的一个选择, Linux操作系统是很具有代表性的.2~3年以内发布的任何一种主套件都可以.其他的选择还有FreeBSD, Solaris, Windows Server. 从安全性,维护性, 以及高负荷下的稳定性等观点来考虑,基本上都使用UNIX内核的操作系统.本书假设使用Ubuntu Linux, 要求具备标准的socket/inet体系的系统调用和标准库函数
- MySQL
DBMS中大多数使用MySQL,多数情况下都能实现足够的性能.同样, 2~3年内发布的任何一种稳定版本都可以.其他也有使用PostgreSQL, Microsoft SQL Server, Oracle的, 但是网络游戏还是使用MySQL居多
- OpenSSL
游戏客户端和服务器之间会通过TCP通信来传输数据流,为了对数据流进行加密,需要对使用RSA和Diffie-Hellman等方法的密钥交换,块密钥加密算法以及能够高效应对攻击的hash函数加以实现,所以要使用2~3年以内的稳定版本
- GCC(Gnu Compiler Collection)
C/S 服务器开发中最常用的编程语言是C语言或C++,其次是Java,轻量级语言在游戏服务器中基本不使用.本书使用的是最为常用的C++, 所以使用GCC进行来编译. 为了节约代码量,部分内容使用STL来实现.实际上, 为了节约编程时间, 也有适当使用JSON(JavaScript Object Notation)库和XML读取程序等小型程序库的,但基本上只要是开源的, Google能搜索到的工具就够用了
- 轻量级语言
Python, Perl, Ruby等在通用的系统编程中使用的语言,本书假设使用Ruby. 为了开发用来实现辅助服务器和用来生成代码的工具,以及开发管理工具, 轻量级语言是必不可少的
客户端相关的软件
- DirectX
渲染画面必须具备的库, 比DirectX移植性更高的还有OpenGL, SDL(Simple DirectMedia Layer)和Orge等各种库. 渲染方面的内容超出了本书的范围,所以不作详细介绍.使用DirectX时, 可以通过少量的程序来实现动画,而3ds Max 和maya等很多3D建模工具都可以输出建模数据,非常便利, 在游戏行业中使用最为广泛..DirectX有一点非常好, 那就是有很多易于使用的示例程序,可以以这些示例为基础进行简单的扩展来制作游戏
- Winsock
Windows下的标准套接字库. 可以免费使用
- Visual Studio.NET
集成的编程环境, 使用Cygwin/GCC和免费编辑器这种组合也没有问题,但是通常,客户端程序的调试与服务器的不同,3D和GUI的实现等方面需要大量用到复杂的数据结构, 如果不能运用功能强大的调试器,就会严重降低开发效率,所以通常必须使用Visual Studio(服务器则没有这个限制)
- OpenSSL
不仅在服务器端需要加密程序,在客户端上也同样需要.因为要与Windows兼容, 所以要使用相同的包下的相同的源代码
4.13 程序开发中的基本原则
4.13.1 如何开始编程,如何继续编程
1. 数据结构优先原则: 构成游戏世界的数据结构要在编写代码之前大致决定下来
2. 维持可玩状态原则: 经常试玩游戏, 在对游戏的可玩状态进行确认后进行开发
3. 后端服务器延后原则: 整个系统并非一下子能构建出来,而是以客户端->前端游戏服务器->后端服务器的顺序, 从最靠近终端用户的一端开始开发.特别是后端服务器的开发要尽可能靠后
4. 持续测定原则: 经常对延迟,带宽, CPU时间进行测定,将其表示出来,以此为参照进行开发
4.13.2 数据结构优先原则----基本原则 [1]
首先来学习"数据结构优先原则"
构成游戏世界的"数据结构"是游戏策划负责人和程序开发负责人两方都能理解的共同的部分, 通过审视这些数据结构并且事前进行商谈,策划人员可以对能否实现策划的游戏内容进行确认. 而程序开发人员可以对在游戏程序中使用怎么样的算法来处理这些已经决定了的数据结构进行考虑
在游戏开发中,后续更改数据结构会对整体的游戏规则产生很大的影响,所以基本上是不可能的.因此, 在实际编程之前, 使用两方都能理解的方式来说明是很重要的
视频游戏中的数据分类
不仅是C/S游戏,几乎所有的视频游戏都可以将数据分成两大类来加以实现, 第一种类型就是以地形数据和棋盘信息为代表的"基本不会变化的部分", 第二种就是部署在其上的"频繁变化的部分".不会变化的部分称为地图,BG(Background),棋盘, 地形,背景等. 经常变化的部分称为对象, 角色, NPC, 行动者, 可移动的, 可动物体等.它们的动作频率的差异在100~1000倍. 动作指的是对保存在内存中的值进行写操作的频率很高,会对实现算法产生影响
在这些术语中, 本书将不会动的物体称为"BG", 会动的物体称为"可动物体"A.
C/S MMO游戏中的游戏世界由BG和可动物体构成. 以K Online为例, 游戏内出现的物体可以分为"明显作为BG存在","明显作为可动物体存在", "介于两者之间的物体",下面我们j就来看一下每种类型中各有些什么样的物体
- 明显作为BG存在的物体
地面
地面是完全固定的, 不会发生变化.对地面没有什么可做的操作, 但是地面的类型分为可以通行的和无法通行的.地面由称为"高度图"(Heightmap)的具有高度信息的顶点数据的集合组成,用格状形式来表示

图4.29所示的顶点数据的集合一次大致能在画面上显示15x15个顶点的范围.因此, 3D多边形需要用15x15x2 = 450个顶点来表示.此外, 策划要求在服务器中表现出一个具有4000x4000=1600万个顶点的广阔世界,如果预计每个顶点包括高度和种类信息在内, 需要20个字节的话,那么1600万x20=320兆字节的数据量全部都要在内存中处理. 从现在的服务器性能来考虑,该数据量并不是很大,大概没什么问题.用一个二维数组(数组中的元素就是保存着高度和种类信息的结构体)来管理就基本上可以了
天空
也称为"天体".用来进行云彩和太阳等的渲染.根据时间段而变化.策划上需要白天, 黑夜, 早晨, 傍晚4种类型. 通常画面上只显示一种.天空的信息不会给服务器的内存造成负担,所以服务器方面不会有什么问题.不需要特别的数据结构
建筑物
K Online中, 建筑物都是背景,不会发生变化.在画面上, 建筑物一次最多显示10个. 从策划的层面出发,确认全部需要多少建筑物,整个游戏世界1000个左右的建筑物应该就可以了.相对于之前的1600万个顶点数,这里的1000足足小了5位数,位置也不会发生变化,所以具有一个保存所有建筑物的列表, 从坐标开始用R-treeA来检索就可以了(另外, 或许也有引用顶点数据的方法)
- 明显作为可动物体存在的物体
玩家角色
玩家角色每秒行动2~5次. 可见范围内1次最多显示20人.虽然希望有尽可能多的玩家参与游戏,但是如前所述,每个服务器内核可以实现500人同时在线.这也可以采用列表+ R-Tree,或者在顶点中维护指针的方法.一个单元中可以存在多名玩家角色时可以使用列表吗?如果不可以,能使用引用吗?顺便提一下, 这里所说的"单元"指的是由4个顶点围成的四边形区域,在K Online中, 可动物体可以在单元为单位的区域中行动
敌方角色
敌方角色每秒移动0~2次, 画面中1次最多出现20个. 如前所述, 整个世界中, 每个登录玩家对应10~20名左右的敌人,所以从服务器的每个内核来考虑的话, 就是要使5000~1万个敌人行动.这是相当多的,所以服务器的内存和CPU都消耗相当大.这比地形的顶点数小了3位数,所以可以采用指针, 或者列表 + R-Tree的方式
NPC(Non-PlayerCharacter, 非玩家控制角色)
NPC有数秒内来回走动1次的,也有站在原地不动的,即使是不动的NPC,也可以点击它,与它进行对话等操作.同时显示在画面上NPC最多有5个.其数量与建筑物大致相同的话就足够了,所以设定当1000个. 因为数量较少, 所以基本不会给服务器内存造成负担. 也可以采用列表 + R-Tree
飞行中的炮弹和魔法效果
飞行中的炮弹和魔法效果每秒移动1~5次.同时出现在画面上的数量相当于玩家角色与敌方角色数量的总和,也就是最多40个.考虑到如果每名玩家1个,每个服务器内核处理500~1000个, 如果进一步考虑敌人发射炮弹,可能会出现2000个左右.该要素最可能消耗CPU, 数量上还是比顶点少了3位数,所以不用数组保存,用列表 + R-Tree就可以了
- 介于两者之间的物体
地面上生长的植物
包括作为背景生长的花草, 以及可以砍倒的大树等.草是背景, 树木是可动物体.被砍倒的树木过几分钟之后会在同一个地方再生.通常, "树木"在草原上为数百单元1棵,在较为稀疏的树林中为数十单元1棵.最好的情况是处于画面中所显示的单元的一半, 最坏的情况是配置为所有单元的一半, 所以估计大约要在画面上显示15 x 15 / 2 = 110个, 这由制定地形数据的人员来决定. 在服务器中,整个游戏世界的面积为 4000 x 4000, 如果以世界中所有场所平均一半的密度来配置,大约800万.与顶点数具有相同的位数, 所以如果每个消耗20字节的内存,就需要160兆字节. 因为树木不会移动(位置不会发生变化),所以应该没关系
地面上的岩石
小沙砾为背景,击碎后可以出矿石的大岩石为可动物体.同样, 击碎后过了数分钟会自动再生.这与之前所述的树木相同,在画面上最多表示110个, 这个数字是与植物加起来的总和. 岩石也不会移动,所以没关系. 与定点数量具有相同的位数,使用数组存储
其他
空中飞行的昆虫, 喷泉, 流淌的水和雨滴等出现在游戏画面上的所有要素, 它们是背景还是可动物体,要与策划人员进行确认后加以分类.这些总共要在画面上显示100个.数量很少, 所以没有什么问题
4.13.3 实现数据结构之前的讨论----出现在画面上和不出现在画面上的元素
450个作为背景地面的多边形, 天空, 10栋建筑, 20个玩家角色, 25个NPC(包括敌人), 40个效果,合计110个的植物和岩石,所有这些同时显示在画面上时, 客户端程序的渲染性能会不会出现问题呢?这需要程序员结合玩家的运行环境的条件来确认.对整体的数量与单个物体的渲染品质进行权衡.此外,在服务器方面, 还要考虑总共需要多少内存(在K Online中, 每个内核需要将近1吉字节)和CPU(K Online中, 同时在线数为500左右),以此来讨论其可行性
以上,我们对实际出现在画面上的要素进行了分类,也考虑了各类物品的最大数量.同时, 不出现在画面上的要素,也就是维持可动物体密度的处理也是需要考虑的
敌方角色和POP设定
在K Online中, 作为代表性可动物体的"敌方角色"在被玩家攻击, 受到一定的伤害之后就会被打倒,然后消失.根据K Online的游戏策划,在沙漠中会有一种名为"蝎子"的敌人以一定的密度出现,由于在C/S MMO中, 所有的玩家都是共享游戏信息的,所以玩家打倒蝎子之后,其数量就会减少,很快就会灭绝了.如果敌方角色灭绝,之后的玩家就无法获得经验值了,所以必须采用某种方法来恢复蝎子的数量
一般在C/S MMO中, 敌方角色出现被称为"POP".为了使敌方角色以一定的密度存在于某个范围之内,需要进行如下处理: (1) 对该范围内的敌人进行计数;(2) 数量没有达到要求的数量时,在随机位置上POP.这种处理在单纯使用随机数的情况下负荷并不高
4.13.4 维持可玩状态的原则----基本原则 [2]
游戏开发中难度最高的就是"使游戏具有可玩性",不做做看的话是不知道游戏是否具有可玩性的.一边开发一边反复进行调整,反复调整的次数越多,游戏就会越有趣.这与"制定计划->设计->实现->单元测试->集成测试"这种瀑布模型不符
在游戏开发中,如何增加"一边开发一边调整"的迭代次数是开发的一大课题,C/S MMO也不例外.首先要快速制作原型,对其进行修改,并且在此过程中确认对游戏的可玩性.在原型开发阶段,如果达不到预期的可玩性,或者无法发现预料之外的可玩性,那么即使进一步推进开发,也很难使游戏具有可玩性
4.13.5 后端服务器的延后原则----基本原则 [3]
整个大的流程就是: 一口气实现在客户端中显示游戏信息的程序,随后定义通信协议的API, 在gmsv中实现那些API.还是从靠近终端用户的一侧开始逐步进行开发. K Online 的原型就是一口气完成的,这是大部分C/S MMO游戏通用的模式.
4.13.6 持续测定的原则----基本原则 [4]
在网络游戏中, 如果通信和渲染方面存在延迟, 就会有损游戏体验, 游戏处理的简单程度在游戏价值中占了很大一部分.之后集中进行性能试验后再进行调整是很难的,所以在游戏的开发过程中, 需要时常对处理速度进行监控,从而尽早发现问题,保持程序稳定
在C/S MMO中,从原型开发阶段开始, 主要程序要素包括"客户端"和"服务器",这两者都可能发生性能上的问题
客户端开发中持续测定的例子

K Online的客户端中要显示的基本内容就是以上这些了,但在实际的商业游戏开发中, 应该尽可能通过输入客户端调试命令来详细追踪VRAM和内存的使用情况等
服务器开发中的持续测定
游戏服务器是长时间持续运行的进程,要持续地定期向日志文件输出状态.可以使用tail -f命令来查看日志文件
服务器的消息循环每循环100次,就对该文件输入1个点号(.).在服务器的开发中, 设置一个子显示器,在画面中显示tail -f的输出结果,由此来检查循环是否中断,是否不均匀.此外, 当发生了对服务器来说很重要的事件时, 就输出点号以外的字符.在图4.32(1)(1)'(1)''的例子中, "S"表示保存玩家数据的瞬间, "I"表示玩家登录的瞬间,"O"表示登出的瞬间,这样, 对服务器进行访问的集中度就能一目了然
图4.32(2)(2)'中, 10秒1次,进一步地将过去10秒内的统计数据以字符串的方式输出.其内容包括: 过去10秒内有多少次消息循环,内存中处理的角色数量, 物品数量,植物数量, 效果数,整体的合计,玩家数,TCP会话数,过去10秒内的平均传输速度以及通过RPC调用API的次数等
比如, 比起前一次的统计(2), (2)' 循环数多了一倍,由此可知由于某些原因导致访问模式发生了变化.如果呈数倍或者数十倍的规模发生变化,一定是发生了预料之外的事件.除了定期输出文字信息,查看使用其他工具输出的内容(比如, 使用top命令后显示出来的内容,以及正在使用的带宽的情况等)也是很有帮助的.其关键就是, 不仅要在游戏的服务运营中显示这些信息, 在开发过程中,甚至是在原型中也要显示
4.14 C/S MMO游戏 K Online的实现----编程开始
4.14.1 开发的安排
如前所述,为了说明支持网络游戏的技术,本书不使用全功能型的中间件.在这种情况下, 推荐按照以下阶段来进行开发
- (1) 框架阶段
对于游戏客户端(cli),游戏服务器(gmsv)和数据库(dbsv),编写可以对最低程度的动作进行测试的1组程序.这个阶段编写的程序还谈不上是"游戏"
- (2) 原型阶段
保持运行状态,持续进行扩展和调整, 将可以作为游戏来玩的版本作为原型来开发.最好是开发1个自动对服务器进行测试的测试客户端和1个用于让人们进行游戏的客户端
- (3) 整体框架的实现阶段
试玩游戏的原型版, 如果能确信游戏具有可玩性, 就可以开始制作开发工具,dbsv以外的后端服务器,以及登录服务器等为了将游戏商业化所必须具备的相关要素
- (4) 量产阶段
进行游戏数据的量产
- (5) 收尾阶段
为了正式运营游戏,这个阶段以Bug修正, 平衡性调整, 试玩等为主要的开发活动
- (6) 运营开始后的阶段
并行实施用户支持和补丁的追加
在上述阶段中,阶段(1)由1名主程序开发1周左右是最适当的.在阶段(2)中,根据策划内容,通常由两人以上分担能完成得更快.比如, 由两名程序员进行开发, 测试客户端由阶段(1)中得主程序员负责,包含渲染在内得玩家客户端则由另一名程序员负责. 进入阶段(3)后, 可以由2~4人负责.(4)之后, 由于所有的基本工作都已经完成了,所以由10~20人分担也是可能的
4.14.2 K Online中的分工计划
4.14.3 K Online中"框架阶段"和"原型阶段"的区别
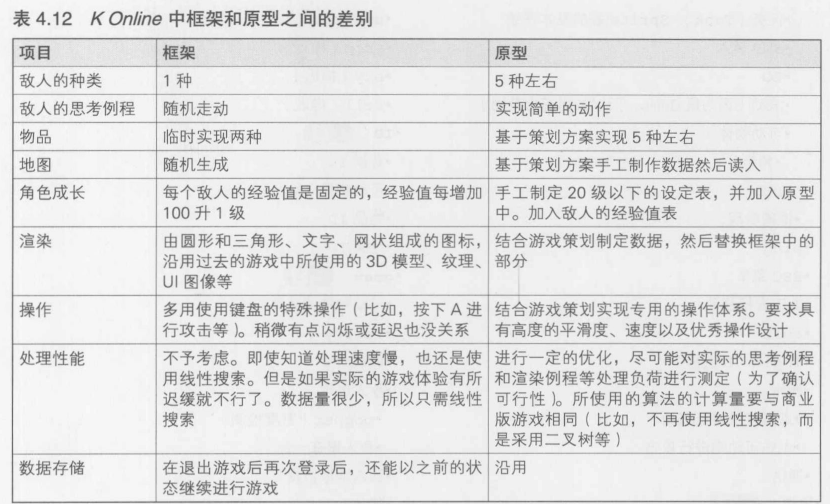
可以说框架和原型的区别就在于是否实现了游戏的可玩性要素
4.14.4 [步骤1~2]框架~原型阶段
框架代码的准备
首先准备框架代码. 为此我们来考虑一下一些必要的元素.首先准备一个文本文件,列出各项实现事项,基本上要按顺序来实现.将该文件命名为todo.txt,将其放置在项目目录的顶部以便随时可以在编辑时参照, 这种做法是笔者非常赞同
此外, 在这个阶段中, 不仅需要实现的内容增减很厉害, 实现顺序经常发生变化,而且由于是一个人进行开发的,因此比起任务管理系统的跟踪管理,使用易于灵活操作的文本文件更为适合.下面依次列出各项内容
todo.txt(的内容)
autocli(用于自动测试的客户端) <-[1]
对各种协议进行整体测试的bot
任务(Task),Sprite等的基本系统
BMP读入
滚动(因为是demo, 所以画面超出范围)
可动物体
角色
HUD
性能表现
ping
ESC菜单
上下光标移动
quit
login ID选择
操作
点击背景进行移动
点击可动物进行攻击
通信
cli<-[2]
系统
渲染(SDL)
useskill
shop(推迟)
buy(推迟)
sell(推迟)
协议<-[3]
signup
login
landscape
move
movablestatus
disappear
attack
quest
item
useItem
equip
chat
ID<-[4]
背景ID
可动物体ID
物品ID
结果ID
gmsv<-[5]
可动物体的分类
verify()
调试命令
敌人出现
popper(密度检测)
敌人聚在一起
读入地形数据
移动
不能进入水中
攻击
敌人 damage
HP = 0(打到)
经验值上升
等级上升
掉落物品
拾取物品
被敌人攻击
如果死了则受到处罚
在数据库中保存变化了的状态
dbsv<-[6]
- [1] autocli
autocli是自动测试程序. 也叫做bot, 测试bot. 网络游戏中的bot指的是像自动赚取经验值的违反使用规则的专用程序,但是在开发初期,由开发人员自己制作的bot程序指的是对协议的功能进行整体的测试, 判断服务器是否有问题等的命令行程序
采用自动测试可以大幅提高开发的迭代速度.比如,一次一次地点击地图,或者一次一次地点击敌人来进行攻击,以此来赚取经验值进行升级,等等, 实际操作起来相当花时间,但是有了bot就可以将这些操作自动化了,程序员在这期间可以去做其他的工作
- [2] cli
cli包括系统, 背景, 可动物,HUD.画面渲染和鼠标操作等,实际的终端用户所接触到的客户端
如前所述, 即使是最终数据量很大的游戏, 到原型开发为止的阶段(以下称为原型阶段),很多情况下也是由1个人进行开发的.但是也有由擅长处理渲染和用户界面的程序员, 以及擅长实现游戏逻辑的程序员两个人来分担客户端和服务端的开发. 在这种情况下,autocli和cli的划分最能发挥效力
首先, 客户端开发的主要工作包括画面的操作和渲染,效果等与通信和游戏逻辑无关的内容, 而服务器的实现则是在框架开发完成之后, 将几乎所有的时间用在实现各协议的函数以及实现游戏逻辑上. 对于相同的部分(比如, 服务端在战斗中受到伤害的处理, 和客户端的表现该伤害的处理),服务端和客户端并不同时进行开发,如果可以, 最好在j进行其他工作时,在其他时刻进行开发
在这种情况下,如果能确保在autocli中对各协议在服务器中实现的行为都进行了测试, 那么客户端的负责人员在通信部分的开发阶段中,就可以将autocli的协议调用部分的代码作为"应用实现"来参考,同时加入到自己的代码中
这样一来,就不需要同时进行这两者的开发, 工作的分配可以更为灵活
- autocli和cli合并在一个程序中的例子
开发原型时, 由一个人负责客户端开发和服务器开发的情况下, 也有考虑将autocli和cli合并在一个程序中进行实现的.autocli和cli在通信部分的实现上基本是共通的, 所以如果将它们合并在一起程序中,可以大幅减少重复
在将autocli和cli综合在一个程序中,将通信部分作为共同使用的部分, 完全不进行画面渲染就可以了.如果不进行画面渲染,1台机器中可以同时运行数十至数百个客户端,这样可以模拟大量的访问来进行负载测试.
- 用于负载测试的客户端开发方法
(1) 使用多个游戏会话, 从1个客户端进程访问服务器. 1台机器也可以运行多个客户端进程
因为1台设备造成1000~5000个连接这样的高负荷,所以可以对服务器的最大性能进行测算. 但是测试结果只限于将某些统计信息(差错率等)显示在标准输出中.有时, 游戏服务开始后,可能会发生"由登录认证的高负荷所引起的系统宕机",为了降低其发生的可能性,需要对后端服务器进行负载测试,在进行包含后端服务器在内的系统整体的负载测试时使用这种方式
(2) 使用1个会话, 从进行最低程度的窗口显示的GUI执行程序访问服务器,1台服务器启动多个客户端进程
1台机器造成50~100个连接的负荷.还可以在每个窗口中,对最低程度的信息(角色状态和周围的地形等)进行图示. 因此, 可以比统计信息更详细地把握服务器实现的正确性.这种类型的自动测试用于在游戏服务的运营中确认服务器是否碰到了预料之外的事件,以及用于检测进行非法活动的用户的活动
(3) 在1台服务器上启动多个客户端程序(包括面向终端用户的画面渲染),在客户端上加入某些进行自动操作的结构(比如, 使用Lua的脚本结构),给服务器造成负荷
1台机器最多建立10个连接.在这种情况下, 主要从用户角度进行自动化测试
对于这里的autocli, 原型开发时所需的自动测试就是(1)或者(2).(3)在实际的客户端开发中需要
- [3] 协议
在协议项中, 根据列出的顺序依次实现RPC的各函数.通过依次实现其中的函数,可以把握整体的进度.在一般的MMORPG中, 最初需要实现20~30个左右的协议
- [4] ID
在ID这一项中, 对背景,可动物体, 物品等游戏内容所需的ID进行定义.在K Online中,预计在框架阶段定义10个左右,原型阶段扩展到100个左右, 而产品版中将增至数千个
- [5] gmsv
在gmsv中, 为了实现游戏的策划内容, 需要编写必要的逻辑, 但是, 基本上, 终端用户也能看到游戏内容,所以应该在协议中列出,这里只编写与协议不重复的部分
gmsv的源代码的规模/行数
在K Online中, 预计框架阶段的代码在2000行以内, 原型阶段的在4000~5000行以内, 商业版的则在3万~5万行以内(错误处理占了一大部分)
事实上, 对于这里代码的行数,说是预计,其实更有一种"如果不控制在这个程度内就糟了"的含义,这是一种设计上的指导方针.在K Online中, gmsv的代码是使用C++来编写的.为了编写健壮的代码,使用C++也有很多必须注意的地方.而且gmsv包含了所有的游戏逻辑, 最为复杂,加上玩家终端还可能会通过互联网直接,大量地发送包含恶意数据的信息,因此, 如何健壮地编写这个进程可以说是K Online开发项目的关键之处, 在K Online的项目中,从头编写的C++代码的量必须尽量控制在最小程度
在K Online中, 物品和技能都达到了"数千以上",敌人的种类则达到了"数百以上",可见具有庞大的游戏策划量.如果单从这个数量来进行简单估算, 每种物品必须在1万~3万行左右,但是笔者并不认为通过这么几行就能把各个功能实现完整.这里并不这么做,为了尽量将C++代码量控制在最小程度,需要尽可能采用一些方法来避免直接编写C++代码,比如从数据文件中读取, 或者使用Lua等语言来定义gmsv的开发专用语言等.
出于这些考虑, 应该牢记"即使是最终版, 也应该将gmsv的代码控制在3万~5万行以内,否则就糟了"这点, 以此来估算代码量
实际上, 在笔者曾经开发过的游戏中, 基本上每次都通过引入DSL来控制C++的代码量. 与其说DSL是代码,它其实更像数据,所以, 通常使用用Microsoft的Excel等制定的易于从C++读入的CSV(Comma-Separated Values), XML, YAML(YAML Ain't Markup Language, Yet Another Markup Language),JSON等,或者使用Ruby和Phython用的模板引擎来自动生成C++代码.从扩展性的角色来看,笔者喜欢"使用代码来生成代码",但是在除了程序员, 还有很多其他人员参与制作游戏数据的情况下,使数据(而非代码)成为主要部分,通常这样更为安全, 适当地结合在一起使用会更好
- [6] dbsv
在原型阶段,虽然后端服务器全部都不需要予以实现, 但是应该加入dbsv.持久化的结构会影响到游戏逻辑以及协议的调用顺序,所以要尽早发现问题
专栏 每一步的进度管理形式
我们对框架, 原型, 整体框架实现这几个步骤中所需的要素进行了总结,下面简单介绍一下推荐的形式:
- 文件文本: 在步骤1~2(框架阶段和原型阶段)中最适合
- xls文件: 在步骤2~3(原型阶段和整体框架的实现阶段)中最适合
- 项目管理工具: 最适合步骤3(整体框架的实现阶段)之后
- 跟踪管理工具: 最适合步骤3(整体框架的实现阶段)之后
4.14.5 "不实际运行起来是不会理解的!"----游戏开发的特殊性
典型的失败----企业中的网络游戏开发
企业中的网络游戏开发, 典型的失败之处有如下这些
1. 不是可玩状态
a. 1个人可以进行游戏, 但两人以上就不行了
网络实现方面的欠缺和故障
b. 可以多人进行游戏, 但是动作非常迟缓,明显有损游戏体验
性能和通信算法不充分
2. 可玩, 但是不像游戏
a. 只是某些模拟的物体在行动
开发要素不充分
b. 不是预期中的类型
比如应该是动作类的游戏, 但是开发完成后不像个动作游戏. 对策划的理解不充分
c. 由于通信的问题导致游戏逻辑变得不完整,以致游戏无法正常进行
讨论不充分, 技术不足
3. 可玩, 也确实像个游戏, 但是质量(可玩性)欠缺
a. 数据和程序的数量不足
讨论不充分, 技术不足
b. 数据和程序的质量不足
讨论不充分, 技术不足
对于网络游戏的开发项目,(1)(2)中, ”网络游戏中是否具备特有的技术“是瓶颈所在. 在(3)这个阶段中, 其技术要点是用来制作大量数据的编辑工具和开发支持工具, 策划,为了达到游戏平衡而采用的测试体制等,这些相当于一般的大规模游戏开发中的技术
通过本书所说的"框架"的开发,可以解决上面(1)中的问题,达到(2)的阶段.如果进行"原型"开发,则可以解决(2)中的问题
专栏 C/C++以外的语言
MMOG服务器特有的条件具有如下这些特征
- 确保要在数百MB至数GB的内存下运行
- 玩家数千, 可动物体数百万以上, 这么多的对象并行运行
- 网络的输入输出每秒发生数千~数万次
- 要求稳定而高速的相应
4.14.6 框架的整体结构
- SDL: 在cli中使用的开源渲染库
- boost: 在cli/gmsv中使用的开源C++通用库
- cli: cli的所有源码
- dbsv: dbsv的所有源码
- gmsv: gmsv的所有源码
- proto: 协议的定义文档, 以及生成的源文件
- vce: 通信中间件
cli中的文件
cli目录下的文件如下所示
- 用于构建
Makefile
Makefile.bak
- 源文件
app.cpp: 游戏程序所需的所有过程
app.h: 上述文件的声明部分
font.cpp: 用来渲染使用SDL的英文数字字体的类
font.h: 上述文件的声明部分
kcli.cpp: 定义用来接收服务器的协议调用的函数
kcli.h: 上述文件的声明部分
sdlmain.cpp: SDL的main函数的封装
sprite.cpp: 用于渲染画面上的Sprite的库
sprite.h: 上述文件的声明部分
util.cpp: 算术运算符等必要的使用函数的定义
util.h: 上述文件的声明部分
- 数据文件
fonts/: 渲染使用SDL的英文, 数字所需的位图字体文件
images/: 背景和角色等图像文件

gmsv, dbsv, proto中的文件
gmsv, dbsv, proto 目录下的文件如下所示
- gmsv中的文件
- 用于构建
Makefile
- 源代码
climain.cpp: 测试bot客户端. 编译后就是autocli
climain.h: 上述文件的声明部分
common.h: gmsv和cli/sutocli共享的定义.定义地图的最大尺寸和瓷砖等可以共享的数据
floor.cpp: 定义用于管理背景地形的Floor类
floor.h: 上述文件的声明部分
gmsvmain.cpp: gmsv的主程序.在这里编写初始化函数和主循环(无限循环).此外, 编写用来接收dbsv远程函数调用的函数
gmsvmain.h: 上述文件的声明部分
id.h: 实现用于在世界中分配唯一ID的"ID池"机制
movable.cpp: 用于定义可动物体的行为的Movable类
movable.h: 上述文件的声明部分
sv.cpp: 定义最先接收来自cli和autocli的函数调用的函数
sv.h: 上述文件的声明部分
util.cpp: 定义计算hash值的函数等整个服务器将会经常用到的实用函数
utli.h: 上述文件的声明部分
zone.cpp: 定义对服务器进行区域分割时, 用来管理ID和服务器地址的类
zone.h: 上述文件的声明部分
- 文档
spec.txt: 在编写代码之前准备的规范文档
todo.txt: 编程时使用的工作列表和记录文件
- dbsv
- 用于构建
Makefile
- 表定义文件
k_table_def.py: 以该文件为出发点
- 用于自动生成源代码的脚本
dbgen.yp: 实际进行自动生成的脚本
settings.py: 内容为空, 但Django要求具备该文件,所以放在这里
- 用于自动生成源代码的模板
cltemplate.cpp: 用于生成自动进行dbsv单元测试的bot(与gmsv的bot不同)源代码的模板.Django读取该文件和k_table_def文件来生成dbclmain.cpp
cltemplate.h: 上述文件的声明部分
svtemplate.cpp: 用于生成dbsv服务器本身实现的源代码的模板. 生成dbsvmain.cpp
svtemplate.h: 上述文件的声明部分
template.sql: 以这个模板文件为基础生成k_table_create.sql
template.xml: 以这个模板文件为基础, 生成用来定义gsmv和dbsv之间的传输内容的dbproto.xml文件
- 链接使用的源代码
qm.cpp: 安全生成SQL查询, 用来防范注入攻击的查询生成工具的实现文件
qm.h: 上述文件的声明部分
util.cpp: 编写计算数组元素个数的宏等的实用工具
util.h: 上述文件的声明部分
- 自动生成的源代码
k_table_create.sql: 用来初始化K Online数据库所需的SQL. 对于mysql命令,可以从标准输入读入该文件来初始化数据库
dbproto.xml: 定义dbsv和gmsv之间的通信内容.通过VCE的gen进一步生成dbproto.cpp, dbproto.h
dbproto.h: 被dbsv和gmsv使用, 定义gmsv和dbsv之间的传输内容的类的声明文件
dbproto.cpp: 上述文件的实现部分
dbsvmain.cpp: dbsv服务器的实现主体, 包含main()函数
dbsvmain.h: 上述文件的声明部分.gmsv也使用该文件
dbclmain.cpp: 用来自动测试dbsv的测试程序的主程序
dbclmain.h: 上述文件的定义文件.gmsv也使用该文件(实现在其他地方)
- proto
auth.xml: 定义authosv和gmsv之间的传输内容
k.xml: 定义gmsv和cli之间的输入内容
log.xml: 定义gmsv和logsv之间的传输内容
专栏 VCE是什么
VCE是笔者曾经经营的公司Community Engine面向MMO类型的游戏而开发的通信中间件.包括相当于libevent的部分和用于RPC存根代码生成的IDL,不仅是PC,还能生成对应于Flash和各种游戏机的代码
4.14.7 以怎样的顺序来编写代码
在开始编写代码时, 想象一下代码的整体结构, 其中包括3个阶段:
(1) 代码结构尚未确定
(2) 代码结构确定后只要对增加常量种类等进行数量上的增加
(3) 进行少量的错误检测, 异常事件的处理等的收尾阶段
只有在阶段(1)种还不存在可运行的游戏. 在(2)和(3)这两个阶段中, 可以在试玩可运行的游戏时, 不断对其进行修改和改进.因此, 为了尽快达到可运行状态,必须尽早完成阶段(1)
在MMOG的开发中, 要想尽早完成阶段(1)的最好的方法就是: 首先编写决定了客户端和服务器之间如何进行通信的"协议定义".因为实现了协议后, 游戏服务器和客户端实现也就基本决定下来了
4.14.8 首先编写协议定义文件k.xml----开发流程 [1]
4.14.9 协议定义的要点
为了尽量减少开发客户端时修改协议的次数,应该先开发测试bot来对协议进行测试.达到"让游戏运行起来"的状态所需的协议必须具有以下这几项:
- 通信连通确认: ping函数.在密码验证之前确认是否连通
- 账号登录: singup函数
- 账号验证: authentication函数
- 角色创建: createCharacter函数
- 登录: login函数. 需要返回值,所以还定义了ResultCode.
- 在地面上移动: move函数和moveNotify函数
- 攻击: attack函数和attackNotify函数
4.14.10 通信连通确认: ping函数
<method methname = "ping" prflow = "p2p"> <param prtype = "qword" prname = "timestamp" /> </method> bool send_ping(vce::VUint64 timestamp); void KServer::recv_ping(vec::VUint64 timestamp){ send_ping(timestamp); }; void KClient::recv_ping(vce::VUint64 t) { if (g_app->state == App::TEST_INGAME) { g->app->lastRoundTripTime = vce::GetTime() - g_app->lastPingSentAt; std::cerr << " now:" << vce::GetTime() << std::endl; }... }
4.14.11 账户登录和账户认证: signup函数, authentication函数
<method methname = "signup" prflow = "c2s"> <param prtype = "string" prname = "accountname" prlength = "100” /> <param prtype = "string" prname = "password" prlength = "100" /> </method> <method methname = "signupResult" prflow = "s2c"> <param prtype = "ResultCode" prname = "result" /> </method> <method methname = "authentication" prflow = "c2s"> <param prtype = "string" prname = "accountname" prlength = "100" /> <param prtype = "string" prname = "password" prlength = "100" /> </method> <method methname = "authenticationResult" prflow = "s2c"> <param prtype = "ResultCode" prname = "result" /> </method>
4.14.12 角色创建: createCharacter函数
<method methname = "createCharacter" prflow = "c2s"> <param prtype = "string" prname = "characterName" prlength = "100" /> </method> <method methname = "createCharacterResult" prflow = "s2c"> <param type = "ResultCode" prname = "result" /> </method> void KServer::recv_createCharacter(const char * characterName) { if (!m_authenticationSuccess) return; ...
4.14.13 登录: login函数
<method methname = "login" prflow = "c2s"> <param prtype = "string" prname = "characterName" prlength = "100" /> </method> <method methname = "loginResult" prflow = "s2c"> <param prtype = "ResultCode" prname = "result" /> <param prtype = "dword" prname = "movableID" /> </method> m_pc = World::allocPlayerCharacter(World::getFloor(dbpc->floorID), Coord(dbpc->x, dbpc->y), this); m_pc->stat = CharStat(dbpc->hp, dbpc->maxhp, dbpc->level, dbpc->exp);
4.14.14 在地面上移动: move函数, moveNotify
<method methname = "move" prflow = "c2s"> <param prtype = "int" prname = "toX" /> <param prtype = "int" prname = "toY" /> </method>
首先, move函数是在角色移动时调用的.通过toX, toY来指定想要前往的位置(到达地点).在K Online的参照物Runescape中, 用鼠标点击远处的地方, 角色就会自动移动到该处. 但是, 移动时并非是平滑地移过去的,而是以方格为单位来移动.在K Online中, 背景采用格子的方式来管理, 只能像将棋那样以格子为单位来移动. 此外, 格子中可以容纳多个角色(1个格子只能有1名角色时,就会经常发生"走不过去"的这种使人感觉不快的现象和一些异常情况)
比如, 如果1个格子为1, 向右移动记为+X, 向下记为Y+, 那么(1,0)就表示向右前进1个格子.如果是(3,2)的话,在允许斜着移动的情况下,最短的路径就是"右下,右下,右"
以方格为单位
像这样以方格为单位是为了使服务器的处理高速化. 以方格为单位的碰撞检测是一种速度最快的方法,经常被使用.比如, 墙壁, 敌人, 植物, 门等不能通过的物体在策划上是必需的,但是如果以任意尺寸的矩形集合来管理,需要循环的次数就和周围存在的个数成正比,但是如果以方格为单位来记录"是否存在不能通过的物体"的标志, 就与个数无关,不需要循环,可以在一定的处理时间内完成检测. 配置了多扇门等物体之后, 为了实现"不能通过的处理",可以说这是最轻量的处理方法
在K Online中, 预计每秒向服务器发送数千次的移动请求, 所以需要使用最轻量级的方法
路径搜索和实际的移动处理
在K Online中, 我们已经决定以方格为单位进行碰撞检测, 接着必须判断移动路径的搜索和实际的移动处理是在服务端进行, 还是在客户端进行
从结论来讲, K Online采用的方法是: 路径搜索在客户端自动进行,实际的移动处理则在服务端进行
在达到这个设计之前, 从最简单直接的方法开始, 到最充分的方法为止,一共经过了4个阶段的研究.为了对实际开发进程进行充分把握,这里将研究过程也一并包含进来加以说明
首先, K Onine中的"移动路径"如图4.35所示,是由上下左右以及45度斜向的8个方向所组合而成的. 图4.35 所示的是从(5,5)移动到(8.7),为此需要移动3步
其次, "实际移动"指的是是否更改角色的坐标. 比如, 如果在服务端进行实际的移动处理, 那就意味着要在服务端判断是否可以通过该方格
- 阶段1: 玩家自己进行移动路径的计算, 实际的移动也在客户端进行, 服务器无限制的接受
使用这种方法时, 由于只能根据点击次数来移动, 如果点击速度很快, 就无法限制角色的移动速度, 这样就会破坏游戏平衡性.在K Online的游戏策划上,需要将角色的移动速度限制在一定范围内.虽然主要的游戏内容是与敌人作战, 但是既然敌人的移动是一步一步地以某一速度在格子中行走的,那么如果玩家的移动速度没能控制在一个良好的范围之内, 游戏的平衡性就会被破坏.K Online中的理想速度是1秒内移动两步
- 阶段2: 与阶段1相同, 但是在服务端加入一项限制: 限制移动请求的接收频率
既然客户端每0.5秒移动1次是最理想的,那么如果发送速度比这个速度快就移动失败,这样就可以了吧.比如, 以图4.35为例,对于move(6, 6); move(7. 7); move(8, 7);, 每0.5秒发送1条.但是在这种方法下, 由于客户端与服务器是存在于互联网之上的,由于数据包的发送延迟,从服务器角度来看, 这3个消息可能会跳过0.5秒的间隔而同时到达. 因此, 这种方法不能限制速度
- 阶段3: 与阶段2相同,但是在move函数中加入客户端的发送时间, 一起发送给服务器
比如move(6, 6, 时刻0); move(7, 7, 时刻1); move(8, 7, 时刻2); 这样在各个移动请求中增加一个表示时间的参数,然后在服务端对其时间差进行计算, 如果过快, 服务端就拒绝接收. 但是, K Online是向玩家分发程序(Windows的.exe)的, 如果该程序被破解了, 玩家就可以发送虚假的时间.这样一来就会放任作弊行为,所以是个很大的问题
综上, 看来简单直接的方法不能处理实际的移动问题.那么, 我们来进一步讨论一下
- 阶段4: 服务端进行路径搜索和移动处理
在这种情况下, 客户端只发送最终想要到达的目的地(比如: move(8, 7)). 服务器接收到这一信息后,就搜索到达目的地的路径, 得到(6, 6),(7, 7), (8, 7)这3步移动路径. 然后, 服务器基于这个路径,每0.5秒使角色移动1步.每次移动时,向客户端发送新的坐标. 由于所有的处理都在服务器中进行,所以服务器的处理就会相当多,可以说这是一大缺点.如果地形复杂,路径搜索的处理负荷也会上升,如果角色增加,每秒都要对所有的角色确认是否到了设定的时刻, 这样的处理量实在太大了.没有什么办法了吗?
- 阶段5: 在客户端中只进行路径搜索中的搜索处理
K Online的地下城中有很多道路狭窄的迷宫, 所以想在这里下点工夫. 路径搜索处理本身就算碰到作弊, 也不会有实际的损害.因为最短路径的计算本来对玩家来说就是有利的,除了想要攻击服务器,否则用户不会想要特地的在客户端程序中加入对自身不利的因素.在使用这种方法的情况下,客户端就会以服务器发送过来的地形数据为基础来计算移动路径,然后像move([ 6, 6 ], [ 7, 7 ], [ 8, 7 ]); 这样, 将多个表示移动方向的数组合并起来发送给服务器.这样, 虽然通信量增加了一些,但是在最短路径的计算方面(这方面的处理量很大),服务器的处理负担轻了不少
经过这些阶段, 就得出了之前所述的结论, 采用"路径搜索在客户端侧自动进行,实际的移动处理则在服务端进行"的方法
移动路径的发送方式----优先发送最终结果
最后还有个细节需要注意, 移动路径的发送不使用相对坐标,而是采用绝对坐标.之前说过, K Online的世界的面积为4000 x 4000.发送这个坐标需要一个12位的数值.C语言的话, 就相当于一个2字节的short类型的数据. 但是以相对坐标来发送时, 1个字节就够了
比如, 在刚才那个例子中, 自己的角色正位于(5, 5)处,移动到(8, 7)时, 可以发送move(3,2)这样的相对坐标.自己的位置为(2000, 2000)时, 不是发送(2003, 2002),而是发送(3, 2),这样似乎可以节约数据量
但是,发送相对坐标时, 如果角色在移动途中又点击了别的地方,那就会移动到意料之外的地方.在以下这样的情况下就会发生这种意外之事.
- Step0: 自己所处位置的绝对坐标为(5,5)
- Step1: 玩家点击处的绝对坐标为(8,5)
- Step2: 客户端发送相对坐标(3,0)
- Step3: 送达服务器, 角色开始移动
- Step4: 移动1步后, 服务器向客户端发送新的坐标(6, 5)
- Step5: (在接收到新坐标之前)正在移动的玩家再次点击同一个位置(8,5)
- Step6: 客户端发送相对坐标(3, 0)
- Step7: 虽然服务器已经移动了1步, 但又收到了(3,0)
- Step8: 之后根据这进一步的指示移动3步,一共就前进了4步
移动结果的通知范围
那么, 作为角色移动的结果,每0.5秒从服务器向所有看到该角色的客户端(一定范围内的所有客户端)发送以下数据包
"范围"指的是K Online中20个左右的方格所涵盖的范围. 在K Online中, 角色的身高大约1.5米,方格的长宽为1米,画面的显示范围为长宽20米左右的四方形. 所以方格为20个
20米的显示范围是根据敌人的移动速度等策划内容以及画面的渲染性能等来决定的.这里的1.5米也好, 20米也好, 突然用真实世界的单位或许会让人困惑, 但这是为了便于参与开发的开发人员进行交流而经常使用的方式.在3D建模软件中, 人物只是一系列数值的集合,比如, 如果一般人听到"100米",也可以感觉到大致的距离,尤其是在有人物角色出场的游戏中, 人物角色最基本的高度大致为1.5~2米,像这样不单单使用数值, 还会加上"米"等单位来称呼.1.5米的话,数值部分也跟浮点数1.5一致.比起说"此人身高9万2000", 还是说"92厘米"更易理解
此外, 是将浮点数100表示为1m, 还是将1.0表示为1m,有时会根据所使用的渲染库和开发工具的类型而改变
moveNotify函数
<method methname = "moveNotify" prflow = "s2c"> <param prtype = "int" prname = "movableID" /> <param prtype = "MovableType" prname = "typeID" /> <param prtype = "string" prname = "name" prlength = "100" /> <param prtype = "int" prname = "x" /> <param prtype = "int" prname = "y" /> <param prtype = "int" prname = "floorID" /> </method>
- characterStatus 协议
characterStatus: 取出指定ID的可动物体的状态 <method methname = "characterStatus" prflow = "c2s"> <param prtype = "int" prname = "movableID" /> </method> characterStatusResult: 返回结果. ID不存在的话什么也不返回 <method methname = "characterStatusResult" prflow = "s2c"> <param prtype = "int" prname = "movableID" /> <param prtype = "CharacterStatus" prname = "charstat" /> </method> struct PlayerProfle: 传送各玩家的详细信息 <struct structname = "CharacterStatus"> <member mbtype = "string" mbname = "name" mblength = "50" /> <member mbtype = "dword" mbname = "hp" /> <member mbtype = "dword" mbname = "maxhp" /> <member mbtype = "dword" mbname = "level" /> <member mbtype = "dword" mbname = "exp" /> <member mbtype = "dword" mbname = "mapID" /> <member mbtype = "dword" mbname = "x" /> <member mbtype = "dword" mbname = "y" /> </struct>
- send_characterStatus(movableID)
void KViewClient::recv_moveNotify(vce::VSint32 movableID, k_proto::MovableType typeID, const char * name, vce::VSint32 posx, vce::VSint32 posy, vce::VSint32 f) { std::cerr << "kv move: " << Coord(posx, posy).to_s() << " id: " << movableID << std::endl; if (movableID == g_app->myMovableID) return; if (g_app->getMovable(movableID) == NULL) { CliMovable * m = new CliMovable(movableID, typeID, Coord(posx, posy)); assert(m); g_app->movmap[movableID] = m; send_characterStatus(movableID); } else { g_app->movmap[movableID]->setCoord(Coord(posx, posy)); g_app->movmap[movableID]->typeID = typeID; } }
- characterStatus结构体的用途
attack函数, attackNotify函数
attack: 攻击敌人 <method methname = "attack" prflow = "c2s"> <param prtype = "int" prname = "movableID" /> </method> attackNotify: 向其他玩家通知攻击了敌人 <method methname = "attackNotify" prflow = "s2c"> <param prtype = "int" prname = "attackerMovableID" /> <param prtype = "int" prname = "attackedMovableID" /> <param prtype = "int" prname = "damage" /> </method>
4.14.15 编写gmsv/Makefile----开发流程[2]
4.14.16 从示例中复制gmsv/climain.cpp和gmsvmain.cpp----开发流程[3]
在sv.cpp中实现signup 函数
void KServer::recv_signup(const char * accountname, const char * password) { } void KServer::recv_signup(const char * accountname, const char * password) { std::string pw = makeHashString(std::string(password)); db_proto::Player pdata(g_idpool->get()), accountname, pw.c_str()); g_dbcli->send_put_Player(uID, pdata); m_lastFunction = FUNCTION_SIGNUP; }
send_put_Player 函数
bool send_put_Player(vce::VUint32 sessionID, Player data);
recv_put_Player_result 函数
void DBClient::recv_put_Player_result(vce::VUint32 sessionID, ResultCode result, Player data) { KServer * ks = findKServer(sessionID); if (ks) { ks->db_recv_put_Player_result(result, data); } }
db_recv_put_Player_result 函数
void KServer::db_recv_put_Player_result(db_proto::ResultCode result, db_proto::Player data) { if (m_lastFunction == FUNCTION_SIGNUP) { if (result == db_proto::SUCCESS) { send_signupResult(k_proto::SUCCESS); } else { send_signupResult(k_proto::FAIL); } } else { assert(0); } }
"dbsv1次往返"的请求
"dbsv1次往返"的请求和线程
void KServer::recv_signup(const char * accountname, const char * password) { startThread(signupRun, accountname, password); } void signupRun(const char * accountname, const char * password) { std::string pw = makeHashString(std::string(password)); db_proto::Player pdata(g_idpool->get(), accountname, pw.c_str()); int result = g-dbcli->put_Player(uID, pdata); if (result == k_proto::SUCCESS) { send_signupResult(k_proto::SUCCESS); } else { send_signupResult(k_proto::FAIL); } }
单线程/多进程结构更好吗
专栏 dbsv服务器代码的自动生成
tbl = Table(name="PlayerCharacter") tbl.add(Field(name="id", type="qword", primary=True, auto_increment=True)) tbl.add(Field(name="playerID", type="qword", index=True)) tbl.add(Field(name="name", type="string", size=50, index=True)) tbl.add(Field(name="level", type="word", index=True)) Field(name="exp", type="dword")) tbl.add(Field(name="hp", type="dword")) tbl.add(Field(name="maxhp", type="dword")) tbl.add(Field(name="floorID", type="dword")) tbl.add(Field(name="x", type="dword")) tbl.add(Filed(name="y", type="dword")) tbl.add(Field(name="equippedItemTypeID", type="dword")) tb.add(tbl) <struct structname="PlayerCharacter"> <member mbtype="qword" mbname="id" /> <member mbtype="qword" mbname="playerID" /> <member mbtype="string" mbname="name" mblength="50" mbvariable="true" /> <member mbtype="word" mbname="level" /> <member mbtype="dword" mbname="exp" /> <member mbtype="dword" mbname="hp" /> <member mbtype="dword" mbname="maxhp" /> <member mbtype="dword" mbname="floorID" /> <member mbtype="dword" mbname="x" /> <member mbtype="dword" mbname="y" /> <member mbtype="dword" mbname="equippedItemTypeID" /> </struct> <method methname="put_PlayerCharacter" prflow="c2s"> <param prtype="dword" prname="sessionID" /> <param prtype="PlayerCharacter" prname="data" /> </method> <method methname="put_PlayerCharacter_result" prflow="s2c"> <param prtype="dword" prname="sessionID" /> <param prtype="ResultCode" prname="result" /> <param prtype="PlayerCharacter" prname="data" /> </method> <method methname="get_PlayerCharacter_by_id" prflow="c2s"> <param prtype="dword" prname="sessionID" /> <param prtype="qword" prname="id" /> </method> <method methname="get_PlayerCharacter_by_id_result" prflow="s2c"> <param prtype="dword" prname="sessionID" /> <param prtype="ResultCode" prname="result" /> <param prtype="PlayerCharacter" prname="data" prlength="100" prvariable="true" /> </method>
4.14.17 自动测试客户端autocli的实现----开发流程[4]
测试客户端的运行方式如下所示
- 启动
- 向gmsv发起连接(只有1个会话)
- 基于当前的执行状态(TestState state)开始逐个对函数进行测试
- 测试的状态进行到最后,测试结束
- 只要有1个条件没有满足, 就调用assert
测试的状态迁移
测试的状态迁移 typedef enum { TEST_INIT = 0, 连接后的初始状态 TEST_PING_SENT, 发送了ping() TEST_PING_RECEIVED, 接收到了ping()的返回 TEST_SIGNUP_SENT, 发送了signup() TEST_SIGNUP_RECEIVED, 接收到了signupResult() TEST_AUTHENTICATION_SENT, 发送了authentication() TEST_AUTHENTICATION_RECEIVED, 接收到了authenticationResult() TEST_CREATECHARACTER_SENT, 发送了createCharacter() TEST_CREATECHARACTER_RECEIVED, 接收到了createCharacterResult() TEST_LISTCHARACTER_SENT, 发送了listCharacter() TEST_LISTCHARACTER_RECEIVED, 接收到了listCharacterResult() TEST_LOGIN_SENT, 发送了login() TEST_LOGIN_RECEIVED, 接收到了loginResult() TEST_INGAME, 正在进行游戏的游戏 TEST_LOGOOUT_SENT, 发送了logout() TEST_SESSION_CLOSED, 接收到了logoutResult() TEST_FINISHED 测试结束,不管什么时候结束都是良好的状态 } TestState;
autocli的main()函数
int main(int argc, char * argv[]) { KClient * kcli = new KClient(); 创建客户端实例 g_vceobj->Connect(kcli, "localhost", 9000); 连接gmsv while (true) { 进入无限循环 kcli->Poll(); 每次对客户端实例进行状态确认 if (vce::GetTime() > (testStarted + 10 * 1000)) { break; 测试开始10秒后退出循环 } assert(kcli->evaluate()); 评估测试结果 return 0; } }
KClient::Poll()函数
bool KClient::Poll() { switch (state) { case TEST_INIT: send_ping(vce::GetTime()); state = TEST_PING_SENT; break; case TEST_PING_RECEIVED: send_signup(localAccountName.c_str(), localPassword.c_str()); state = TEST_SIGNUP_SENT; break; case TEST_SIGNUP_RECEIVED: send_authentication(localAccountName.c_str(), localPassword.c_str()); state = TEST_AUTHENTICATION_SENT; break; case TEST_AUTHENTICATIONRECEIVED: <继续类似的组合...> case TEST_LOGIN_RECEIVED: state = TEST_INGAME; break; case TEST_INGAME: ingameSender(); break; case TEST_FINISHED: break; default: assert(0); } return true; }
signup()函数
std::ostringstream idss; idss << "ringo" << time(NULL) << "." << g_id_generator; localAccountName = idss.str(); localPassword = std::string("testpass"); g_id_generator ++; send_signup(localAccountName.c_str(), localPassword.c_str()); std::cerr << "signup" << std::endl; state = TEST_SIGNUP_SENT; void KClient::recv_signupResult(ResultCode result) { assert(state == TEST_SIGNUP_SENT); assert(result == SUCCESS || result == ALREADY); state = TEST_SIGNUP_RECEIVED; }
KClient::ingameSender()函数
void KClient::ingameSender() { 事情1: 移动的测试 int dx = -1 + (random() % 3); int dy = -1 + (random() % 3); send_move(myCoord.x + dx, myCoord.y + dy); 移动到附近的1个随机位置处 sendCounter[FUNCTION_MOVE]++; 对移动次数进行计数 事情2: 由于记录了自己以外的可动物(TestMovable),所以对其进行攻击 std::map<vce::VUint32, TestMovable*>::iterator it; int cnt = 0; for (it = movmap.begin(); it != movmap.end(); ++it) { TestMovable *m = (*it).second; if (m->typeID == k_proto::MOVABLE_GOBLIN) { send_attack(m->id); 可动物是GOBLIN的话就发起攻击 sendCounter[FUNCTION_ATTACK]++; 记录攻击次数 cnt++; if (cnt == 15) break; 为了1次不要攻击太多次而进行调整 } } 事情3:还没有请求持有物列表的话, 请求1次 if (recvCounter[FUNCTION_ITEMNOTIFY] == 0) { send_item(); sendCounter[FUNCTION_ITEM]++; } }
专栏 gmsv中线程的使用
在MMOG行业中, 关于如何使用线程这一点议论颇多.大致来看, 作为(1)实现对dbsv的异步通信,(2)发挥多核CPU的性能这两方面的手段,线程是相当有用的.(1))在之前已有论述,(2)是作为一个问题遗留下来的
这里,线程是指"共享进程的内存空间而运行着的多个操作系统本地线程".在1个进程中, 虚拟并行运行的线程无法发挥多核CPU的性能,所以不包含在内
如何在各部分中使用线程呢?
cli: 游戏客户端的实现中,在音效,网络,渲染,AI等功能中使用线程,使这些功能各自独立,从而发挥多核CPU的性能, 并且使代码更为易读.出于这种目的而使用的线程数通常在2~10个之间
gmsv以外的服务器: 基本上都是作为对DBMS的游戏网关的功能,所以并没有必须发挥多核性能的负荷, 所以不需要使用线程
gmsv: 大量用到gmsv的CPU的处理有以下两种
使NPC等可动物体移动的处理
处理几千个以上的cli通过网络发送过来的大量请求(1秒以内几万次)
如果可以使用线程来进行这些处理, 分散到各个内核来执行, 就能提高性能.那么要怎么实现呢?如今, 可以采取的选择有: 为了有效利用像线程和Mac OSX 的 Grand Central Dispatch 这样的本机搭载的CPu的多核性能,而采取"设备内部的分割处理",以及将处理分割为多个进程,由远程机器上运行着的进程j进行协调的"跨设备的分割处理"
可选方法有如下3种:
(1) 只使用设备内部的分割处理
(2) 只使用跨设备的分割处理
(3) 既使用设备内部的分割处理, 也使用跨设备的分割处理
我们比较一下这3种方法
首先, 在"编程所花的工夫"方面, 通常是表4.A种(1)->(2)->(3)的顺序. (3)由于同时使用了(1)和(2),所以所要花的工夫比(1)和(2)加起来的程度还要大.这是因为软件的复杂度并不是简单的相加而得,这样情况下, 由于同时使用了两种并行处理的实现方法,所以其复杂度远远大于1+1=2

接着, 我们来看一下"最大扩展".选用方法(1)时, 为了进行扩展, 除了增加设备的内核数,再无其他方法.因此, 只能在1台物理设备之内进行扩展.在2010年, 一般能用(成本适中)的服务器设备和IaaS云服务大致也只能使用2~8个内核,但是如果将来能发展到32个内核,设置是128个内核, 也许这个方法也很不错
再来看一下"大量的同时崩溃",在使用线程和Grand Central Dispatch的设备内分割处理中, 多个线程共享同一块内存区域,由于它们之间互相不受保护,所以1个线程甚至可以破坏另一个线程的内存区域. 因此, 程序的1个异常就会影响其他线程的执行
比如, 在1个32核的设备中, 使用方法(1)来构建游戏服务器时, 理论上性能最大能提高32倍.如果1个线程能处理100名的同时连接玩家,32个线程就能处理3200个同时连接.但是此时, 如果某1个线程发生了内存访问冲突,或者对内存内容造成了破坏,或者发生了什么异常,其他的31个线程全都会停止,对玩家造成的损害相当严重. 选用方法(2),因为进程具有单独的虚拟内存空间,所以不会发生前面这种情况(受到损害的玩家限制在100人以内)
由此可见, 方法(1)不仅没有充分的可扩展性,在健壮性方面也很薄弱.因此, 必须选择方法(2)
此外, 如果使用方法(2)来实现, 某一台设备搭载了多个内核的情况下, 还具有能够有效利用这一性能的优点.这种情况下, 在操作系统方面, 比起使用线程,进程之间进行切换的成本很高, 所以会导致处理性能有所下降
综上, 在如今的经济条件下,使用方法(2)来实现K Online可以说是最合适的,但是如果今后的经济条件发生变化的话,还需要重新考虑
4.14.18 图形客户端cli的创建和运行确认----开发流程[5]
- SDL
- 绘制图形
- 运行确认
- 实现字体的显示
- 出现敌人, 追赶敌人
- 打到敌人, 获得经验值
- 确保以后可以继续进行游戏----游戏状态的保存
4.14.19 框架之后的开发----开发流程,后续事项
至此, 说K Online的"框架"开发阶段告一段落了.从现在开始, 就要逐步对协议进行定义,反复在gmsv, autocli, cli中添加必要的实现部分.这就是原型阶段.原型阶段的目的是对游戏可玩性的本质部分进行确认.为此, 需要进行一下工作
- 充实游戏设定数据
- 增加图像, 影像, 音效数据, 改善游戏界面
- 用于多人高效进行游戏试玩的服务器启动和版本管理等的工具
- 用于分析游戏结果, 查找问题的日志解析工具
只是从这个阶段开始, 一般的游戏开发流程成为了中心,所以.本章中不涉及这些内容.服务器管理工具, 日志解析工具等不管哪种网络游戏都需要的辅助系统,由于并不在原型阶段进行开发,所以将留到第6章进行介绍
4.15 总结
第5章 [实践]P2P MO 游戏开发 没有专用服务器的动作类游戏的实现
5.1 P2P MO游戏的特点和开发策略
5.1.1 P2P MO和动作类游戏----游戏的状态频繁发生改变
- P2P MO这种典型的多人游戏的设计主要有以下几种分类
- ARPG 例: 暴雪娱乐公司的《暗黑破坏神》,卡普空的《怪物猎人》系列
- FPS 例: 微软的《帝国时代》,暴雪娱乐公司的《星际争霸》系列
- 竞速游戏 例: 任天堂的《马里奥赛车》系列
- 格斗对战游戏 例: 任天堂的《全明星大乱斗》系列
这类游戏都具有动作游戏的特点.动作类游戏的游戏状态频繁发生变化,会产生大量数据交互, 如果使用C/S方式实现, 对服务器,带宽成本要求过高,所以从商业角度考虑是不行的
因此, 即便有使用游戏外挂作弊的风险,P2P的实现方式从经济角度来说也是很合理的.但是,目前服务器硬件以及带宽成本不断降低,这种经济角度的考虑已经变得不那么重要了.所以游戏的数据通信全部通过服务器来传输的方式也在逐渐流行起来.
上述动作游戏都可以使用"同步共享内存"(数据对象同步和事件通信)的方式来开发. 这种方式与C/S类型的MMO游戏中经常使用的RPC方式相比,通信量会增加, 但是程序开发相对简单,而且可以在游戏的单机部分开发完成后再扩展其网络功能
共享内存这种方式是P2P MO游戏开发中经常使用的特有方法
5.1.2 RPC和共享内存
共享内存其实在C/S和P2P游戏中都可以使用. 相对于通信方式来说, 我们更应该根据游戏的内容来选择开发技术
例如, 如果要求单服务器同时连接数在数千级别, 带宽负荷和CPU负荷都应该尽量减少, 就只能选择RPC开发方式. 对于不使用服务器的P2P MO游戏, 即使单个玩家需要的带宽多一点, 也可以使用共享内存的方式来开发
笔者认为, 应该尽量采用共享内存的方式开发游戏, 这是因为共享内存相对于RPC,不需要针对每个操作分别定义函数,开发起来比较容易.但是对于大型MMO游戏来说,由于它们使用了大量数据对象,而且CPU负荷和服务器的带宽要求都很高,只能选择RPC开发方式.随着云计算的使用费逐渐降低, 未来也许可以都采用共享内存的方式来开发, 但目前趋势还不明显
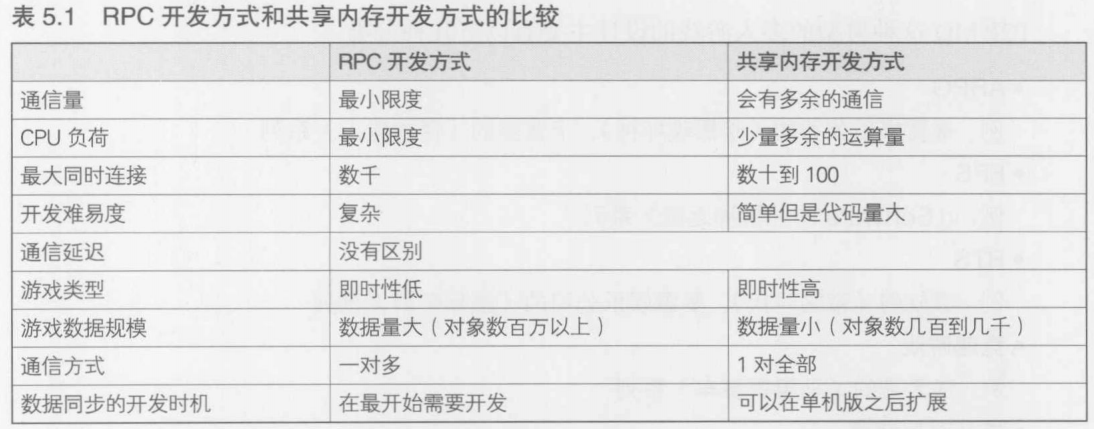
5.1.3 P2P MO 游戏的特点----和c/s MMO游戏的比较和难点
- 不需要大量数据交互
游戏的相关资源, 除了贴图和动画之外一般在几百兆以内, 可以全部安装在普通玩家的PC中, 因为不需要联网也可以进行游戏,所以需要安装全部的数据和资源
- 配置信息对玩家是可见的
因为游戏的配置信息是安装在玩家的电脑中, 所以可以在本地文件中看到配置内容, 游戏运行时也可以跟踪内存信息, 而且还可以通过逆向工程破解全部的游戏内容,这些都是无法预防的
- 不能严格保证游戏数据变更的安全性(可以作弊)
正如前文所述, 玩家可以通过修改内存数据来作弊,要保护游戏数据的安全性是很困难的.这样造成的结果就是, 原本需要玩家花费数百小时, 长时间培养游戏角色的游戏方式, 以及具有精心创造的宏大游戏世界,能让玩家在不知不觉中消耗大量时间和精力的游戏方式就难以实现了.对玩家来说, 这种经过长时间游戏积累的数据一旦损坏或者丢失将是难以承受的损失,游戏体验的品质也就不能得到保证.导致的结果就是P2P MO游戏的游戏时长较短并且以游戏内容为中心
- 不能进行P2P连接的NAT网络环境有很多
玩家之间不能通过端对端方式进行网络连接(TCP或者UDP的连接方式)的情况有很多. 比如在公司局域网游戏时,或者使用公寓楼,大学, 当地的有线电视网络等通过路由器构建的NAT公共网络.在日本,这种情况大概占到10%~30%.另外还有因为P2P通信量的异常增大而禁止直接发送数据的情况. 这种案例最近有所增加.利用这些网络环境的玩家根据所在地区的差别又会出现各种各样的情况. 游戏内容针对的目标玩家不同, 上市时间, 游戏主机等各种因素的复杂组合导致了NAT问题的发生. 为了解决诸如UPnP,SOCKS,UPD Hole Punching等问题考虑了各种方法,但是还是不能完全解决. IPv6网络普及之后也许情况会有所好转,但前景还不是很明朗
- 不能简单地更新游戏
P2P游戏的更新比较麻烦,一般要向玩家发布软件更新包并安装到PC来升级硬盘中的游戏程序, 所以可能会有玩家在玩老版本的游戏. Steam这类新的下载平台虽然可以解决这个问题,但是因为在不能访问网络的情况下一个人也可以玩, 所以玩家往往选择不升级继续在离线的情况下玩老的版本
- 不方便结合社交网络等网络服务
因为游戏程序不联网也可以玩, 所以游戏结果就不能发布到社交网络上
- 玩家掉线的情况比较多
因为没有一直在线的服务器, 游戏的通信依赖于玩家的机器,如果玩家突然关掉电源或者突然结束运行中的游戏就会导致通信中断. 这种情况, 需要同步玩家之间的游戏数据, 同步显然不能花很长时间, 所以如果数据量过大是不可行的
5.1.4 P2P MO 游戏的优点
- 延迟较少
所有的操作都是直接在玩家的机器之间通信, 因为不通过服务器,数据不需要在互联网上通过各种路由器来传输, 所以网络延迟较少, 这样就比较合适动作类游戏的实现
- 游戏服务器的带宽负荷低(甚至没有负荷)
P2P游戏中的数据都不需要通过服务器传送, 所以服务器带宽的负荷很低,甚至没有负荷. 只有MMO游戏带宽负荷的几十分之一到几百分之一, 几乎到了可以忽略不计的程度
- 游戏服务器硬件成本低(甚至零成本)
正如前文所述,因为不需要管理游戏数据的服务器程序,所以也就不需要配置专门的游戏服务器, 也就不存在服务器运营的成本
- 服务器维护期间也可以正常进行游戏
服务器(辅助系统的服务器)在维护期间,玩家也可以正常进行游戏.不过积分榜或者玩家匹配功能还是需要正常的网络连接
5.1.5 从概要设计开始考虑[多人游戏模式]
考虑到之前所描述的那些和C/S MMO游戏的不同, 在概要设计一开始就要有多人游戏的意识,必须针对这些特点进行设计. 游戏设计师如果只是专注于自己的设计而忽略P2P技术开发这个前提,在之后实际开发时就会遇到各种问题, 导致项目失败, 甚至重新开发也不行, 遇到这样严重问题的案例有很多
开始编程时, P2P游戏可以先制作单机版本.之后再使用共享内存技术开发多人游戏部分.但是, 如果游戏设计开始就没有考虑到多人游戏的情况是不行的
5.2 J Multiplayer游戏开发案例的学习----和K Online的不同
本章以J Multiplayer这个假想游戏为案例, 学习如何设计以及采用共享内存方式的实现, 与第4章的K Online MMORPG游戏的不同点也会进行对比说明
5.2.1 J Multiplayer----和K Online的比较
J Multiplayer是一个共享内存开发方式游戏的学习案例,让我们选择适合的游戏方案来进行设计.这里假定以《暗黑破坏神》这种ARPG为基础
5.2.2 P2P MO 游戏开发的基本流程
P2P MO游戏开发的基本流程和C/S MMO相同. 不过和MMO相比,服务器代码相对较少, 开发的迭代速度也比较快.此外还可以采用单机游戏的开发方式, 一边开发一边试玩.从这个角度来说, P2P MO游戏开发的风险相对较低
5.2.3 P2P MO 游戏开发的交付产品----开发各个阶段需要提交的资料
- 框架开发阶段
- 原型阶段
- 商用版本阶段
概要设计的详细资料
- 一张游戏地图
- 敌人在本地机器上移动
暂定一种类型的敌人
不同步全部的敌人
离玩家角色最近的优先移动+攻击
同一层有数十到数百只怪物
路径搜索暂时不做
- 玩家角色
暂定一种类型
直线移动,数据同步
只攻击指定的目标
生命值(HP)和经验值(EXP)随等级上升
- 有房屋和门, 在房屋和走廊里随机动态生成敌人
- 只能重新启动游戏来重置游戏状态
- 原型阶段不添加玩家匹配和聊天功能
- 同一台电脑启动多个游戏程序时使用不同的端口号
- 游戏启动时, 可以指定IP地址和端口号
完成上述功能后, 最基本的游戏玩法就可以实现了
- 敌人会联合起来一起攻击, 如果单个敌人, 会自杀式攻击
- 有2个敌人时, 同伴可以分工合作各个击破
- 门被打开后,同伴也可以通过
为了实现以上概要设计, 需要在详细设计阶段将这些要点反映在设计中
5.2.4 和 C/S MMO 的数据量/规模的比较
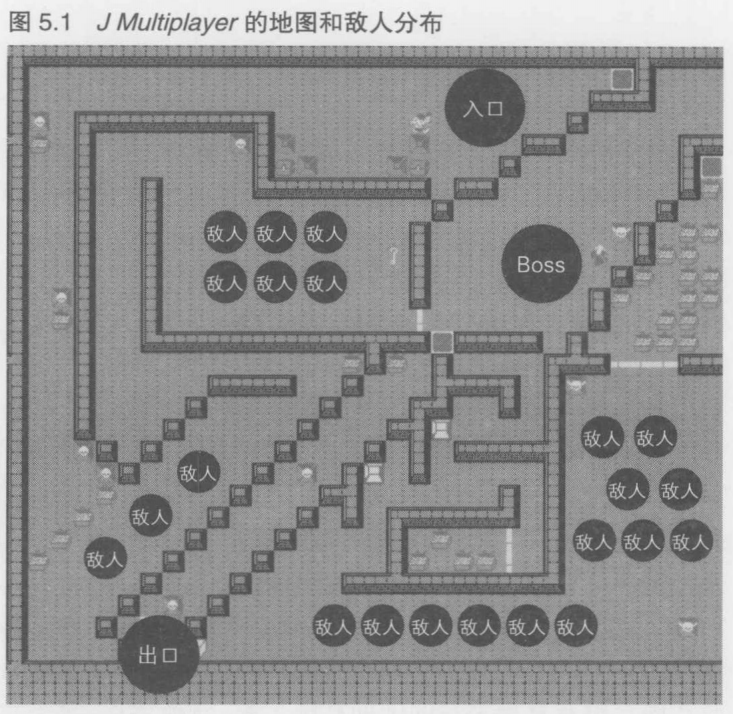
5.3 P2P MO 游戏的设计资料
5.3.1 系统基本结构图
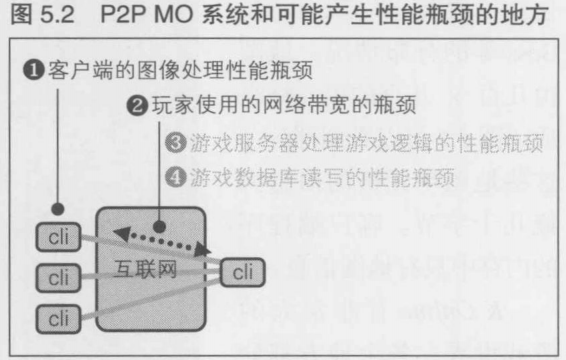
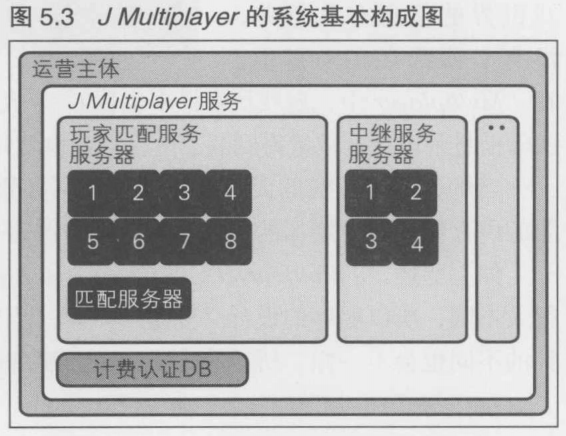
5.3.2 进程关系图
C/S MMO类型的游戏, 包含的进程有客户端程序, 游戏服务器, 登录服务器,验证服务器和数据库服务器等,按不同的功能划分有十几种.它们之间的关系需要详细定义.但是对于P2P MO游戏来说, 只有游戏客户端一种,所以可以不用制作系统关系图的资料
开始开发后, 后期比较难更改的部分如下:
- 使用星状拓扑结构还是网状拓扑结构
- 同步,非同步还是网页方式实现
这两点从一开始就需要考虑清楚
关于第二点, 因为J Multiplayer是在互联网上通信所以不能使用同步的方式,而网页方式又没有那么多玩家参与,所以采用非同步的方式实现是较为合适的
相对麻烦的是网络拓扑结构的选择,到底是用星状拓扑还是网状拓扑
星状拓扑结构还是网状拓扑结构
星状拓扑结构和网状拓扑结构的区别在于, 共享全部客户端程序(玩家机器上运行的游戏程序)的数据所必须的通信链路连接数.星状拓扑结构是2, 网状拓扑结构是1.星状拓扑结构的客户端之间通信需要经过主机, 而网状拓扑结构不需要.所以,经过互联网的通信延迟除主机之外, 玩家机器之间理论上都有两倍的延迟. 但是, 网络拓扑结构除了网络的NAT问题之外,互相之间不能通信的玩家也比较多,会有无法进行游戏的情况.
因此, 就网络拓扑结构来说, 只有对反应速度要求较高的对战格斗游戏, 街机游戏或者任天堂DS等使用ad-hoc通信的掌机等,没有NAT问题,可以保证通信延迟在几微妙之内的情况下才使用
另外, 在星状拓扑结构中,根据游戏内容的不同, 如果有排他限制的功能时,可以在主机的处理程序中实现相应功能, 程序也比较简单
首先来验证星状拓扑结构
通过以上分析,我们可以知道在开发P2P MO类型游戏时,基本的流程是首先验证能否采用星状拓扑结构, 在追求较快响应速度的特殊情况时再验证网状拓扑结构.面向互联网用户的游戏基本上都是采用星状拓扑结构
本章的案例游戏J Multiplayer也是采用星状拓扑结构实现. 也就是说, 在玩家中由一人作为主机,剩下的玩家作为客户端.作为主机的玩家首先初始化并开始游戏.之后其他玩家再加入这个游戏, 直到人数达到上限
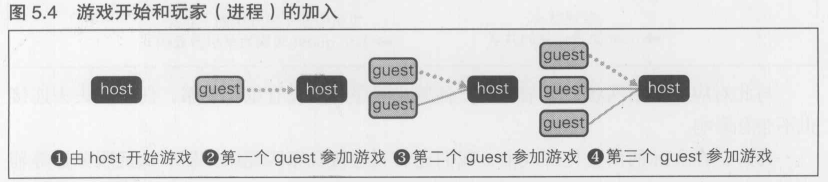
中途加入游戏的实现
不论是星状拓扑结构还是网状拓扑结构,都可以实现途中加入游戏的功能.不过星状拓扑结构相对容易实现
首先, 我们来看一下星状拓扑结构的做法. 在主机的游戏程序中已经保存了排他限制的相关信息以及所有游戏运行数据,当新的玩家加入后,只需要下载所有的数据就可以保持最新的游戏状态.采用网络拓扑结构时, 需要先确认游戏内容都没有排他限制后再直接和其他游戏客户端建立连接.比如典型的赛车游戏,流程如下: (1) 首先和所有的游戏客户端建立连接. (2) 在其他游戏客户端初始化并显示新加入玩家的赛车 (3) 开始传输新加入游戏玩家的操作数据 (4) 更新所有游戏客户端中新加入玩家的赛车位置信息
实现中途加入游戏功能时, 需要传输初始化游戏所需要的数据.在游戏进行的同时传输数据,对客户端程序的处理和带宽有一定要求.如果数据量特别大, 则无法实现中途加入游戏的功能. 另一种做法是让之后参加游戏的玩家处于等待状态,直到下一个合适的时间点再进入游戏.比如可以在一局游戏尚未结束时禁止新的玩家加入.一般中途参加游戏对程序的负担比较大, 增加这个功能时需要慎重考虑
无论是星状拓扑结构还是网状拓扑结构,根据游戏内容的不同,中途参加游戏功能的开发还有很多难点.就拿赛车游戏来说, 信号灯变绿表示游戏开始,实现比较简单,也容易理解. 其他的桌游,比如麻将, 从游戏内容上来说并不适合中途参加游戏.即时战略类(RTS)游戏也是如此,游戏初期状态和开局非常重要,中途参加游戏很难实现.但是第一人称射击类(FPS)游戏就比较容易实现途中参加游戏的功能.所以根据游戏的题材和设计,途中参加游戏功能的开发难度和工期也有很大不同.
采用星状拓扑结构时, 如果游戏进行时主机连接中断,所有的玩家就会失去连接,变成单人游戏状态.比较典型的情况是y由AI(电脑)代替其他玩家的操作.有些游戏在主机掉线时,其他玩家可以变成主机,并允许新的玩家加入
与此对应, 使用网状拓扑结构时,各游戏程序之间没有依存关系, 任何人失去连接也不会有影响
另外, 在实际的商业化游戏中, 我们还需要连接玩家匹配服务器,认证服务器等辅助系统.
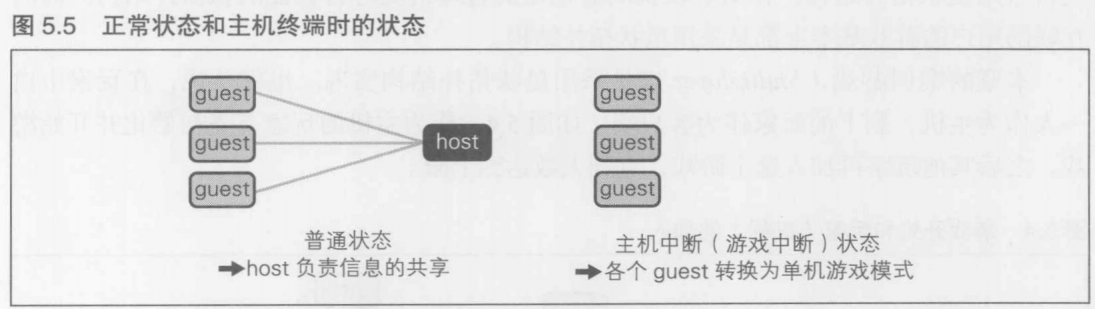
5.3.3 带宽/服务器资源计算资料
不需要考虑服务器数量的预算.在服务器端也没有使用专用的网络,除了后面章节会介绍的辅助系统之外也不用考虑带宽的情况
5.3.4 通信协议定义资料和API规格
C/S MMO类型的游戏需要定义不同进程之间的通信协议,对于P2P MO游戏来说,只有游戏客户端一种,所以通信协议也比较简单
就拿本章的案例游戏来说J Multiplayer来说, 除了辅助系统以外游戏只需要处理ping, getid, guestid, sync和delete这5种函数, 这其中比较重要的sync和delete在客户端和服务端都需要使用
通信协议的序列图
在C/S MMO 游戏中, 从客户端->游戏服务器->数据库服务器,数据会经过多层服务器, 需要保持其一致性.但是在P2P MMO游戏中, 如果是星状拓扑结构,基本上只有主机和客户端之间的通信, 不需要画序列图进行详细确认
函数和常量的定义
J Multiplayer的通信协议定义了以下5种操作类型
- ping函数和pong函数
ping和pong函数用来验证主机和客户端直接能否通信,以及网络延迟情况
void ping(U64 guestclock); 客户端调用的函数,参数为64位无符号整数 void pong(U64 hostclock, U64 guestclock); 主机调用的函数
如上述例子所示, 客户端和主机之间交换时间.客户端和主机都分别管理着自己的时间. 在调用ping函数时,将程序启动后经过的时间(单位是毫秒)传递给主机,然后主机通过pong函数返回主机的时间.如果网络延迟大于一定数值会显示警告信息,并断开与主机的网络连接进入单人游戏模式
P2P MO游戏没有服务器也可以进行游戏,所以大部分游戏会在遇到网络问题时转入单人游戏模式,这也是在游戏逻辑上与C/S MMO游戏不同的地方
- getid----ID管理池
getid函数用来分配在游戏房间内的唯一ID, 使用了ID管理池的方式实现,占用位数少.
void getid(U16 num); void getid_result(U64 ids[1000]); getid_result函数返回新的ID
ID管理池用来管理游戏房间内可动物体的唯一ID,是一种常用方法. ID管理池的示意图如图5.6所示
获取特定进程内唯一ID的方法很简单, 只需要计数器逐渐累加即可.但是如图5.5那样有主机和客户端两个进程同时运行时,因为两者的计数器之间并无联系, 所以可能会分配到相同的ID. 为了避免这种问题, 有两种解决方式
- 方案1: ID由[进程ID, 程序内部ID]两部分组成.例如, host的进程ID是0, 客户端是1的话,[0, 1]和[1, 1]就构成了不同的ID.这种方法可以叫做进程ID法
- 方案2: 客户端的ID都通过主机分配,由主机的ID管理池分配,并自动累加.这种方式叫做ID管理池
ID管理池是第二种方式.可以在最开始采用方法2获取了起始ID后, 再用方法1获取之后的ID
第一种进程ID法再获取最初的进程ID也需要访问主机.例如, 使用两个变量[U32型的进程ID, U32型的内部ID]的情况和使用ID管理池时,[在最开始的时候一次性分配32位,也就是42亿个ID]是差不多的.所以ID管理池和进程法在实际的程序开发中的工作量几乎没有区别
笔者比较偏向于使用ID管理池的方式, 因为ID可以使用一个原生数据类型(U64或者U32)保存, 代码简单高效, 节省内存性能优异, 而且ID的位数比较小, ID的读取, 搜索会使程序的循环处理比较多,所以应该尽可能让ID的构成简单化,只有一个变量会比较方便使用
不管是进程ID法还是ID管理池的方式,如果客户端长时间不能访问主机, 会造成不能生成新的ID的情况.所以需要根据游戏的内容来决定采用什么管理策略. 假设游戏中每秒新产生3个敌人,游戏时间在一个小时左右,如果能够保证生成10万个ID,理论上就基本没有问题了
前面的例程所示生成新ID的getid_result函数可以返回ID列表, 例如, 一次申请6个ID时, 就会返回连续的ID[100, 101, 102, 103, 104, 105].不过这样会造成带宽的浪费,可以使用start=100,end=105的方式,让返回结果更经济高效
- guestinfo
guestinfo函数是主机用来分配所在游戏空间内与主机相连接的客户端的唯一ID
void guestid(U32 id);
这个函数是主机告诉所有客户端他们各自的唯一ID
对于一个ID来说,理论上主机知道它是客户端申请的还是主机自己使用的,不过逐个搜索会比较慢,所以在物体移动时,会在所有的同步数据包内包含控制该物体移动的guestid,这样就可以省略搜索了. 主机可以使用guestid函数来告诉客户端该唯一ID.在J Multiplayer游戏中,主机的guestid默认为0, 客户端是1以上的值
- sync
sync函数用来同步可动物体在移动时的数据.可动物体出现时, 根据之前不存在的ID所对应可动物体的移动来判断
void sync(U32 guestid, U32 id, U8 data[200]) 一个对象的变化在200字节以内表达
guestid是客户端的ID,id是可动物体的ID,在整个游戏房间内是唯一的.data是2进制的数组,格式如下所示,大小限制在200字节以内
data: X列
X: [1字节, 表示变量类型][1 ~ 4字节, 数据]
J Multiplayer游戏包含1字节的U8, 4字节的I32和4字节的浮点数(Float).很多游戏没有使用8字节的双精度浮点数(double)类型, 这是因为和精度相比更重视节省带宽. 大部分游戏也不需要使用这种双精度浮点数的数据
另外, 在J Multiplayer中, "表示变量类型的ID"(类型ID)使用了以下枚举变量的定义
typedef enum { SVT_TYPEID, VT_HP, SVT_COORD_X, SVT_MAXHP, SVT_COORD_Y, SVT_MP, SVT_DELTAPERSEC_X, SVT_MAXMP, SVT_DELTAPERSEC_Y, SVT_EXP, SVT_GOAL_X, SVT_GOAL_Y, SVT_LEVEL, SVT_TOSTOP, SVT_HITTYPE, SVT_TODELTE, SVT_SHOOTER_ID, SVT_TARGETID } SyncValueType;
例如, 在主机上新生成了可动物体,分配的ID是45, 调用sync函数同步客户端数据,参数为guestid=0,id=45.客户端首先在内存中搜索, 如果id=45的物体不存在,就新建该物体; 如果存在该物体,就使用服务端发送来的数据替换本地内存的数据
- delete
delete函数用来删除可动物体的信息. 例如主机要删除45号可动物体则调用delete(0, 45),向各个客户端发送该消息
void delete(U32 guestid, U32 id);
专栏 什么是"游戏逻辑"
游戏逻辑(Game Logic)一词在本书中经常出现,目前还没有准确的定义
本书中该词的意思和Web程序中经常使用的业务逻辑(Business Logic)类似.在Web程序开发中,业务逻辑是指"控制数据库和用户接口之间的数据操作的逻辑",在游戏开发中,包含以下两点
- 游戏运行时的数据: 以象棋为例, 指棋子的分布情况, 和数据库相关联
- 用户界面信息: 还是以象棋为例,在游戏界面中什么地方应该绘制什么颜色,鼠标可以在什么地方点击等信息
游戏逻辑就是这些数据背后相应的控制逻辑
比如下面这一系列的游戏规则.
- 游戏开始时棋子的位置应该怎么摆放
- 不同棋子可以移动的位置
- "步"(也称步兵)只能纵向走一路
- 不能将己方棋子放在对方棋子之上
只有遵守一定的游戏规则才能保证游戏的乐趣
和web程序开发一样, 游戏逻辑部分和其他模块之间的界面并不十分明确. 所以开发的时候,需要尽可能的让逻辑部分和数据库以及用户界面分离开来,这样才能称之为游戏逻辑部分
5.3.5 带宽消耗量的估算
下面我们来看一下带宽消耗量的估算. J Multiplayer运行时的画面如图5.7所示.和 C/S MMO的感觉差不多,图像的质量这里暂且忽略

在图5.7中, 白色的为玩家控制的角色,黑色的是地方角色,小圆点表示子弹.敌人左上方的鼠标表示调试时可动物体的ID.从图5.7中可以看到可动物体共计8个(玩家, 角色, 敌人角色, 子弹)
在游戏设定中, 实际运行时可动物体的峰值大概是40~50个(如图5.8),如果包括屏幕外的可动物体,最多有1000个左右. 这个游戏是一个会与大量的敌人作战的游戏. 在实际的即时战略类游戏(RTS)中,可动物体一般没有1000个

该游戏客户端运行时每秒帧数为60, 也就是说, 这1000个可动物体每秒可以动60次
根据前面的协议说明大部分是调用sync函数更新坐标, 即计算坐标后调用sync函数, 如下所示
[UPD/IP 标头 20字节] [函数标头4字节] [U32 guestid] [U32 id] [U8 变量类型ID] [Float4 X坐标] [U8 变量类型ID] [Float4 Y坐标]
函数标头包含函数ID和数据长度等信息,总共4字节
60 x 1000 x (20 + 4 + 4 + 4 + 1 + 4 + 1 + 4) x 8位 = 20.0Mbit/s. 4人同时游戏时, 主机需要和3个客户端通信,通信负荷为20.0Mbit/s x 3 = 60Mbit/s(!). 即便是光纤用户也会比较紧张
一般的游戏机要求通信量在50~150kbit/s左右. 大部分用户使用的是普通宽带,实际的带宽达不到几Mbit/s这种程度
"1/600"的实现方法----仔细检查游戏设计寻找解决方案
假如想让主机通信量在100kbit/s,需要压缩"1/600"左右. 这个目标可以实现吗?遇到问题时, 我们可以采用相同的办法. 即"仔细检查游戏设计寻找解决方案".这里先不考虑J Multiplayer的游戏内容是否有趣,从开发角度可以采用下面的分析步骤
- 方案1: 是否可以不同步和自己无关的敌人信息?
这个是P2P MO游戏必须要考虑的问题. 在J Multiplayer游戏中, 敌人按照下面的顺序移动
- 受到玩家角色攻击时, 锁定该角色并追击, 在一定时间后恢复原状态
- 就算没有受到攻击, 只要玩家靠近就追击玩家
J Multiplayer 的基本游戏玩法是同追击自己的敌人战斗.所以没有追击玩家的敌人就可以不用同步相关信息.这不是"极端情况的处理", 而是在实际开发中应该选择的,也是技术上经常采用的方式.
分析的结果就是需要同步一部分敌人的信息, 但是没有追击玩家的敌人可以不用同步.
在实际开发时, 两个客户端在同一时间的游戏截图请参考图5.9,玩家的位置相同, 但是敌人的位置不一样. 两个画面放在一起比较我们会觉得游戏体验不一样,但实际上是两个不同玩家通过网络进行游戏,不存在体验不同的问题.J Multiplayer游戏的基准是"敌人数量一致",只需要确保敌人出现和死亡的时间一致.这样就可以只在出现和删除时进行通信,从而减少大量因为移动而产生的数据通信
根据这个结论,假设1000个敌人的构成如下所示
- 200个追击玩家A(主机)
- 200个追击玩家B(客户端)
- 200个追击玩家C(客户端)
- 200个追击玩家D(客户端)
- 200个空闲敌人,随机分布
上述情况,对于主机玩家A来说, 应该向客户端玩家B发送什么信息呢?首先追击玩家A的敌人信息是不需要向B~D玩家发送的.追击B的敌人是在B客户端上运算, 所以也不需要发送. 这样就只需要同步剩下那200个空闲敌人的信息
这样一来就成功的减少了"1/5"的通信量.在带宽上可以削减12Mbit/s,而且游戏体验也更好了.另一方面, 正如第3章所讲,游戏的策划内容中说明了除Boss角色之外的敌人在出现后会很快死掉,所以也不需要同步每个角色.如果是哪种角色之间相互影响,角色寿命也比较长的游戏就不能使用这个方法了
现在距离100kbit/s的目标还需要减少1/120......

- 方案2: 距离远的敌人信息可以不同步吗?
J Mutliplayer游戏的地图i比较大, 没有显示在屏幕上的地方有很多, 所以可以每次只同步离玩家近的敌人信息,距离远的偶尔同步一次.通过观察图5.10的游戏画面,对于屏幕外一定距离的可动物体,每一帧都同步,其他位置的物体每100帧同步一次,这样又可以减少大约一半的通信量.现在是6Mbit/s,距离100kbit/s 还有1/60......

- 方案3: 1/60的话......那可以每60帧同步一次吗?
这样就可以一下减少到1/60了....不过需要仔细考虑才行.同步频率降低可能会大幅度影响游戏体验
首先,J Multiplayer中的角色移动很快,每秒移动4格.60帧同步1次的话就是1秒通信一次.因为移动1格是0.25秒,1秒最少可以移动3次.如果"向右移动一步再向左移动1步",可能会显示成"没有移动".这是游戏无法接受的情况,应该"每秒至少同步5次".1秒5次就是12帧同步一次,这样可以一下减少到6Mbit/s/12 = 500kbit/s
但是,如果12帧才更新一次位置信息,会造成"移动时的画面跳动",看上去会不舒服,为了有更流畅的移动效果,需要加入"角色移动时的坐标补充"处理
再"削减1/5"就到100kbit/s了
- 方案4: 可以只同步变化的数据吗?
J Multiplayer中的敌人角色不是一直移动.处于待机状态的情况也很多, 特别是敌人刚出现时大部分是待机的.而且移动的情况也比较少,多数是上下左右十字方向的移动.如果"只在X坐标改变时"或者"只在Y坐标改变时"同步, 也可以减少通信量.在屏幕显示的部分,游戏运行画面中移动的物体(需要同步的)只有原来的一半. 这个方法效果也很好,"500kbit/s的一半"是250kbit/s,还差最后一点
- 方案5: 子弹的处理可以优化吗?
J Multiplayer中的子弹是直线飞行.所以知道了发射的时间,方向和速度,只需要一次同步, 之后的运行是可以计算的.调用sync函数同步子弹信息时, 只要在数据包内添加发射时间就可以了.时间差可以通过ping函数调整.这个方法有一个问题,就是在子弹发射后进入游戏的玩家会看不到之前的子弹.不过这个问题不大, 可以忽略不计. 根据游戏画面观察和计算,游戏运行时子弹的数量大概占可动物体的20%左右,所以效果应该很明显
现在的通信量是250bit/s x 0.8 = 200kbit/s,还差一半
- 方案6: 数据包可以优化后再发送吗?
现在sync函数的格式如下
[UDP/IP 标头 20字节] [函数标头4字节] [U32 guestid] [U32 id] [U8 变量类型ID] [Float4 X 坐标] [U8 变量类型 ID] [Float4 Y 坐标]
上述格式中[UDP/IP 标头 20字节] [函数标头4字节] [U32 guestid]是冗余部分,不包含坐标值,每次都重复发送同样的数据.UDP数据包最大可以传输1500字节的数据, 所以
[UPD/IP 标头 20字节] [函数标头4字节] [U32 guestid] [剩余的数据]
数据包的头28个字节只需发送一次,剩下的1472字节用来传输移动坐标, 我们假设一下最坏的情况,所有的可动物体X和Y都发生变化
[U32 id] [U8 变量类型 ID] [Float4 X坐标] [U8 变量类型 ID] [Float4 Y 坐标]
(4 + 1 + 4 +1 + 4) = 14字节, 应该可以削减不少
全部按低压缩率, X坐标和Y坐标都变化的情况下, 1个可动物体的数据是(20 + 4 + 4 + 4 + 1 + 4 + 1 + 4) = 42字节,用新的方法只需要(4 + 1 + 4 + 1 + 4) = 14字节,差不多可以压缩"1/3".标头的大小在1500字节中比重很小,可以不用计算
我们将按这个协议通信的函数名定义为sync_multi,通过调用
void sync_multi(U32 guestid, U32 id_array[100], data_array[]);
可以实现数组方式的通信
这样200kbit/s/3 = 70kbit/s左右,还能有一些缓冲空间,真是可喜可贺
- 方案7: 敌人少时多发送一些数据
游戏开发者的特点就是不会仅仅满足于达到通信量的需求.已经确保在敌人最多时也不会发生数据传输的问题,那么在敌人少时就能多同步一些信息,给玩家提供更准确的游戏状态.可以按照一下方式划分: 敌人数量在50个以上时, 每12帧同步一次;20个以上时, 每6帧同步一次; 10个以上时每3帧同步一次;10个以下时每2帧同步一次
5.3.6 其他资料
5.4 客户端/服务器软件 + 中间件,基本原则
5.4.1 P2P MO 开发的最终交付产品
P2P MO游戏和C/S MMO游戏的最终交付产品有很大不同. 首先就是服务器端程序和客户端程序并没有分开
笔者开发J Multiplayer的原型时使用的文件结构如下所示.客户端程序和服务器端最终被编译成了一个可执行文件,所以只有一个文件夹.通信协议的定义文件(j.xml)也只有一个,和可执行文件放在同一位置, 没有测试用的机器人程序
- 编译用
Makefile: 笔者使用的是UNIX的操作系统,通过Emacs调用GNU Make编译程序.也可以使用IDE(集成开发环境)
- 源代码
app.cpp, app.h: 源程序文件, 包含每帧的实际处理程序
floor.cpp, floor.h: 管理内存中地形数据的类. 定义了地图单元格的种类和大小,实现了碰撞检测等
font.cpp, font.h: 在游戏画面上控制字符显示
game.h: 明确了游戏中使用的地形, 敌人种类, 坐标值等游戏设定信息
id.h: ID管理池的实现
movable.cpp, movable.h: 可动物体以及其子类等的实现
net.cpp,net.h: 从网络接收数据后相关处理的实现,还有之后会提到的SyncValue类的实现
sdlmain.cpp: 在使用SDL开发程序时main函数的实现
sprite.cpp, sprite.h: 使用SDL开发的绘制小精灵的程序
util.cpp, util.h: 通用工具类代码
- 通信协议定义相关
j.xml: J Multiplayer游戏中5种必要RPC的定义
jproto.cpp, jproto.h: 通过j.xml自动生成的RPC存根文件(stub file)
- 数据
fonts: 绘制文字所需要的一些必要的英文字母, 数字和符号的图像文件
images: 存放玩家角色, 敌人, 子弹和地形相关图片资源的文件夹
5.4.2 P2P MO 中使用的中间件
5.4.3 编程时应该注意的基本原则----针对P2P MO游戏
在4.13节针对C/S MMO游戏列举了以下4个基本原则
- 数据结构优先原则
- 保持游戏状态原则
- 后台处理延迟原则
- 连续测量原则
P2P MO游戏因为没有后台服务器,所以除了第3条以外, 其他原则都同样适用
5.5 P2P MO 游戏 J Multiplayer的实现----正式开始编程
5.5.1 J Multiplayer的编程计划
5.5.2 开发流程----K Online的回顾
5.5.3 J Multiplayer开发阶段----开发顺序和内容
- 开发可以单人进行游戏的版本
- 在单机版基础上实现具有cli连接和共享内存功能的多人版本
- 最后添加玩家匹配, 排行榜和交流功能,使其更接近商业化版本
5.5.4 第1阶段的要点
开发可以单人进行游戏的版本
绘图UI(从cli程序复制)
单屏幕地图
TILE = 32 x 32
CELL = 128 x 128
玩家角色在屏幕中间
点击鼠标的位置
如果是地面则移动到该位置
如果是敌人则发射子弹攻击
使用弓连续射击时会有冷却时间(冷却时间有上限)
大的房间
敌人=100个哥布林左右, 1种类型, 用子弹攻击
随机移动 + 玩家角色进入一定范围后开始追击+攻击
敌人在本地机器移动
不用同步所有敌人
死亡时同步
新生成时同步
用子弹攻击时同步
每30秒同步一次位置(大致30秒左右就行, 不用太精准)
敌人之间检测碰撞(子弹之间不用检测)
ID唯一(毫秒单位的启动时间+计数器)
不考虑路径探索,直线移动
玩家角色(PC)
HP
EXP
LEVEL
网络(Net)
同一台服务器可以启动多个客户端, 可以通过参数直接指定IP
5.5.5 客户端程序的开发案例

5.5.6 "共享内存方式"的实现----开始编码
单机版开发好以后, 就可以开始实现"共享内存方式"的功能了.顾名思义,共享内存就是将相同的内存数据共享到不同进程之间.需要共享的具体数据包括可动物体的坐标,种类以及移动方向等信息
竞争状态----共享内存方式的注意点
使用共享内存时需要注意的是内存容易遇到资源竞争状态(Race Condition).竞争状态是指处理结果和预期结果不一致.比如"整数变量加1",这个最简单的处理也有可能发生竞争状态
如果用C语言来说明,变量i初始值为0, 进行加1的运算如下所示
i = i + 1; 这里i的结果应该是1
这行代码在实际编译后可分解为以下处理
- 从变量i的内存区域中将值拷贝到变量a的内存区域
- 给变量a加1
- 将变量a的值从内存区域中拷贝到变量i的内存区域中
该例子执行了两次拷贝和1次数据计算
只有1个进程时,按照上述处理顺序执行一定会得到预期的结果.但是有两个进程的时候, 1~3处理的执行顺序就不一定了

加锁处理
竞争状态发生的根本原因是同一个处理(i的值+1)被分解成了多个操作. 所以要避免发生竞争状态,一般可以在处理实际运行前后给资源加锁,让分解的操作集中执行.这个也叫做原子处理.

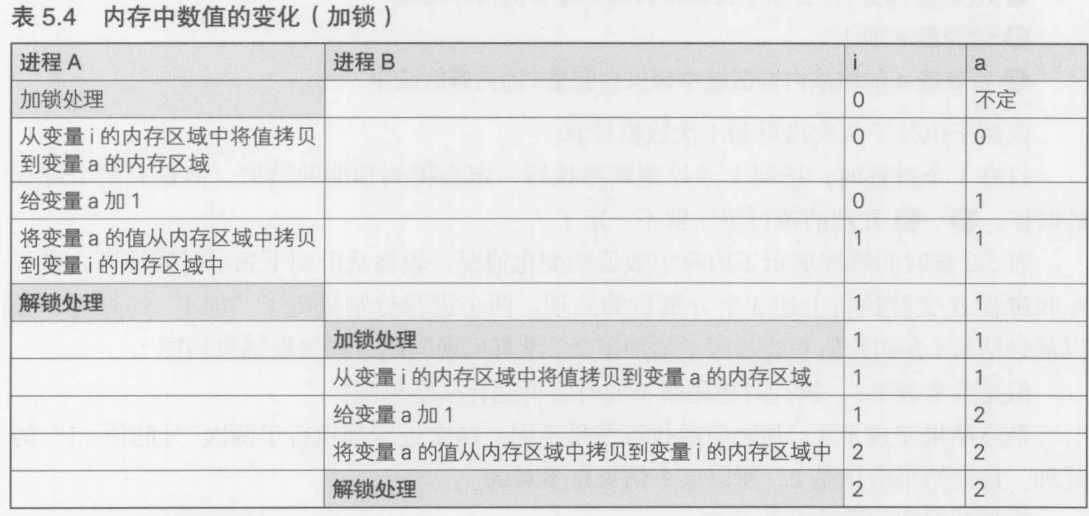
lock(); 加锁处理
i = i + 1;
unloc(); 解锁处理
加锁处理同时只能调用一次,在某一进程调用加锁处理时其他进程会处于等待状态
P2P MO和竞争状态
在C/S MMO游戏中, 管理着全部游戏状态的游戏服务器一边会进行加锁处理.玩家的任何操作都需要请求服务器进行实际的数据操作,游戏状态只能通过服务器进行变更,所以不会发生竞争状态
P2P Mo游戏也可以采用相同的方式, 只是将玩家的机器当作游戏服务器,以"分布式MMO"的方式实现,从而避免竞争状态的发生. 最近这种实现方式的使用逐渐增多,但是其存在的问题是"一旦主机在游戏中途退出",其他玩家就不能切换到单人模式继续游戏. 另外, MMO游戏的进行完全依赖其他的进程这点会造成网络延迟,所以对于激烈的动作类游戏这种方式也不适合
P2P MO游戏其实还有与前面描述的"加锁处理"类似的实现办法.不过这个方法和一般程序中使用的mutex或者FIFO(先进先出)等方式不同,为了避免不同机器上运行的进程之间发生竞争状态,需要实现带有通信功能的加锁处理.在不同的机器上运行的进程为了进行加锁处理需要和主机之间进行通信,所以理论上和前面描述的分布式MMO有同样的网络延迟问题.但是, 好处是中途退出时可以切换到单人模式继续游戏
5.5.7 P2P MO 游戏开发中该如何防止发生竞争状态
综上所述,在P2P MO游戏的开发中, 判断该如何防止共享内存中数据发生竞争状态十分重要. 对于游戏内容的充分理解可以帮助开发者做出正确的选择
5.3节中"带宽消耗的预估"部分为了节省宽带决定"不同步没有追击玩家的敌人",这个节省带宽的实现方式也是最重要的判断依据
同步处理的实现例子
下面是关于同步处理正式编码前的记录. 这里展示的是未经修改的实际文档,阅读可能稍微有点困难.我们以此为基础来说明在实际编码中应该注意的地方
* Enemey
* Create: host->guest(sync, ALL)
* Move
* target(有): guest处理
* target(无): host->guest(sync, coord)
* Delete: guestAttackKill->hostKill->guestKill(delete ALL)
* PlayerCharacter
* Create, Move, Delete: guest->host->guest(sync ALL)
* Bullet
* Create, Move, Delete: local
上面这些记录是J Multiplayer游戏中关于可动物体同步的设计资料,但具体该怎么设计呢?
可动物体的枚举类型和类的设计
首先一起来看看在游戏中出现的所有可动物体
* Enemy
* PlayerCharacter
* Bullet
J Multiplayer客户端程序中可动物体的类设计如图5.12所示.各个类的要点如下所示
* class Movable
可动物体的基类.包含坐标, 移动方向, 图像编号等信息
* class Character
游戏角色类,继承Movable类. 可以互相攻击,包含HP等状态信息
* class Enemey
敌人角色类,继承Character类.具有管理攻击值的人工智能(AI)
* class PlayerCharacter
玩家角色, 继承Character类. 能通过网络来控制
* class Bullet
子弹类, 继承Movable类.可以击中Enemy或者PlayerCharacter
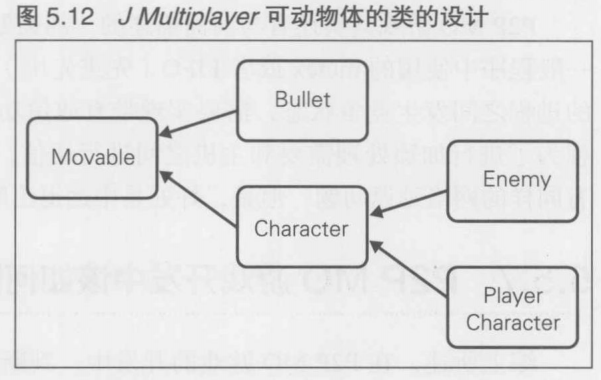
基本操作的矩阵
接下来, 像在DB中进行CRUD那样, 将基本操作Create, Move, Delete 矩阵化,这些都是机械化的工作
* Enemy * PlayerCharacter * Bullet
* Create * Create * Create
* Move * Move * Move
* Delete * Delete * Delete
修改游戏进行状态相关处理的规范
创建敌人,移动玩家角色的操作都属于修改游戏进行状态的处理, 这些处理有两点需要考虑
- 最初在哪里发生?
- 应该通知哪里?
下面, 我们来针对这两点分别说明各个类的相关处理规范
"哪里"主要只是主机和客户端.如果是在主机发生, 并且需要发送信息到所有客户端的话, 记为: host->guest
玩家角色的处理规范
首先从简单的地方开始规范
玩家角色最多同时出现4个,对带宽的影响很小.这其中,其他玩家的位置和他们正在做什么是最重要的信息,所以这些信息需要一直保持同步. 另外, 其他进程无法修改玩家角色自身的状态,所以玩家A操作的时候,A的角色信息会得到更新,而其他玩家则不能修改这个角色的信息
因此, Create, Move, Delete这些操作只在各自的客户端执行,然后向主机发送信息, 再由主机通知全部客户端. 可以简化记为 guest->host->guest. 下面的代码(syncALL)表示使用sync通信协议,向所有的客户端发送信息
* Create, Move, Delete: guest -> host -> guest(sync ALL)
敌人的处理规范----Enemy/Create
下面是最重要的Enemy类,敌人的处理是比较复杂的
首先Create操作是指生成新的敌人.根据笔者的经验, 在P2P MO游戏中生成新的可动物体有两种方法
- 在主机生成
- 在客户端生成, 但不同步
这两种方法在设计上不容易出现问题
这是因为在客户端生成的物体如果要同步到其他机器需要经过两次跳转,系统整体可能出现的状态会增加(图5.13)
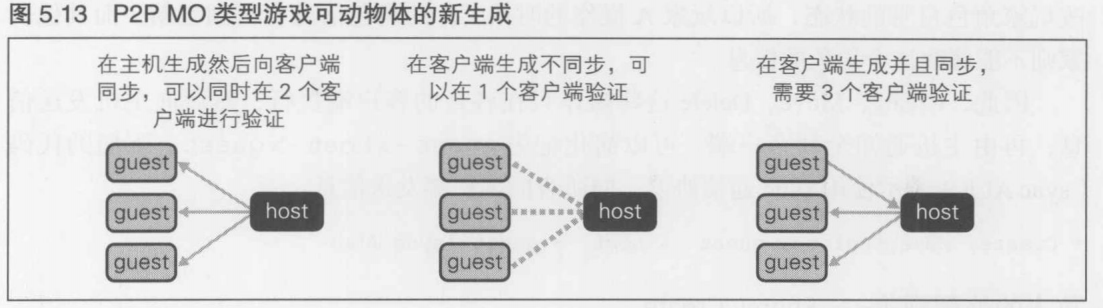
如图5.13所示,如果采用客户端生成并同步的方式,为了调试需要使用guest-host-guest三个进程,重新bug比较麻烦.另一方面, 系统可能出现的状态增加为以下三种
- 在客户端A生成后还没有向其他机器同步
- 客户端A通知了主机, 但主机还没有通知其他奇迹
- 客户端A通知了所有的客户端
敌人状态的同步是这个游戏最重要的部分, 如果因为对应的状态管理变得复杂而增加了验证的难度, 那就有可能导致不必要的技术上的问题
为了实现J Multiplayer的设计内容, 应该慎重考虑在客户端生成的可动物体是否需要同步到其他客户端.在示例代码中没有进行同步,所有生成敌人的处理也都由主机来控制, 这样可以将产生问题的风险降到最低.不仅游戏内容的开发会变得更加容易,调试会比较方便, 而且能够缩短开发周期
简而言之, 就是只在主机生成敌人, 然后同步到所有客户端. 可以调用sync协议(sync, ALL)来进行同步,如下面的代码所示
* Create: host -> guest (sync, ALL)
以上就是敌人的创建
Enemy/Move
接下来是Move操作, 需要规范的是当敌人移动时, 应该同步的信息和同步的方式
如果Create不同步的的话, Move或者Delete等后续的操作当然也不需要同步.Move操作也是host->guest
在5.3节中提到过,J Multiplayer游戏的设定是"追击玩家的敌人在客户端本地机器上进行处理,分散在地图上处于待机状态的敌人由主机控制移动并向各个客户端同步数据"
在这里可以将该设定加入到程序的规范中, 在Enemey类里添加成员变量targetID, 用来记录追击目标的ID, 即被追击的玩家ID.没有追击目标时设为0,追击ID3的玩家设为3
* Move
* target (有): guest处理
* target (无): host -> guest (sync, coord)
上述"target(有)" 表示targetID不为0.这种情况时, "guest处理"表示在target所在的客户端处理; "target(无)"表示没有追击目标,通过host -> guest进行同步,使用sync通信协议来传输坐标(Coordinate),而且只同步坐标,不用传输HP等信息.当然大Boss这样需要很长时间才能击倒的敌人可能需要同步HP, 但是虾兵蟹将的话同步下位置信息就可以了.通过这些判断,在实现游戏内容的过程中, 也许能够找到如何减少带宽消耗,处理内容, 编码量等问题的方法
Enemy/Delete
最后是Delete操作, 在J Multiplayer游戏中敌人死亡的唯一条件是受到攻击.在5.3节中提到过的设定是"敌人的数量需要同步",这也可以直接作为程序的规范
敌人的死亡有以下两种情况
- 在客户端被玩家击倒
- 在主机被主机的玩家击倒
* Delete: guestAttackKill -> hostKill -> guestKill(delete ALL)
第1种情况时, 如果在客户端A被击倒, 调用delete通信协议以 guestA -> host -> 其他客户端的顺序同步. 而在主机被击倒时, 顺序则是 host -> 其他客户端. 用总结成一行的方式来描述可能更为明确
* Delete: [ guestAttackKill -> ] hostKill - > guestKill(delete ALL)
[]内表示可以省略
以上大体明确了Enemey同步处理的规范
子弹的处理规范
还剩下子弹相关的处理
* Bullet
* Create, Move, Delete: local
只有正在追击目标的敌人才发射子弹,四处分布的待机敌人不会发射子弹, 因此可以在各个客户端分别处理而不需要同步
因为设定太过简单反而有些犹豫,但是经过实际测试并没有发现问题,所以还是把它作为规范保留了下来
在实际开发中随着测试的不断进行,会发现"这里还需要更多同步","这个不需要吧?","这里的同步频率不提高的话可能会有问题","装备这个武器的时候需要提高同步频率", "只同步这个敌人"等问题,所以需要根据游戏内容,在深入调查的同时不断调整同步的处理
5.5.8 共享内存开发方式该如何编码----共享内存开发方式和RPC开发方式的比较
如果提到共享内存一般是指POSIX规格的共享内存(shm_函数)
但是本章的"共享内存"只是为了与RPC开发方式进行比较,和POSIX的shm函数并没有关系. 这里稍微有点复杂,所以需要明确说明"共享内存开发方式"和"RPC开发方式"的区别
二者在实现上的根本区别是: 在游戏逻辑中, 游戏进度数据的保存处理(覆盖或者不覆盖数据)所发生的时间和地点不同
RPC开发方式----C/S MMO游戏
C/S MMO游戏采用的RPC开发方式是按照下列顺序更新游戏进度数据的
- 玩家在客户端(程序)进行角色移动的操作
- 客户端向服务器端发送操作的RPC请求 例: 向服务器发送move(5,5)函数
- 服务器接收到move(5,5)函数的请求后, 首先检测参数(5,5)是否正确,如果正确就在游戏进度数据中将角色的位置坐标更新为(5,5)
- 服务器更新数据成功后, 将新的值同步到其他客户端
采用RPC开发方式时,网络上传输的是"变更的请求",而不是"变更的结果".所以根据处理结果的不同,有可能会发生值并没改变的情况
共享内存开发方式----P2P Mo游戏
P2P MO游戏采用的共享内存开发方式要求客户端和服务器端共享相同的数据.在这个前提下按照下列顺序处理游戏数据
- 玩家在客户端(程序)进行角色移动的操作
- 客户端检测移动操作是否正确, 如果没有问题则更新本机管理的游戏进度数据
- 客户端将更新后的数值传输到其他客户端
- 其他客户端无条件接收更新后的结果
采用共享内存方式时, 网络上传输的是"变更的结果",而不是"变更的请求".所以只需要无条件替换对应的数值
如果灵活运用共享内存开发方式的特性就能够大幅度减少代码量, 这也是采用这种方式的优点
为了体现这个优点, 我们以move(5, 5)为例来比较RPC开发方式和共享内存开发方式在代码量上的区别
RPC开发方式的代码量----move(5,5)
void player_touched(mouseX, mouseY) { send_move(mouseX, mouseY); } vodi recv_move(int x, int y) { if (check(x, y) == OK) { data->x = x; data->y = y; data->broardcast_move_notify(x, y); } } void recv_move_notify(int x, int y) { character->x = x; character->y = y; }
要增加z参数的时候, 需要在客户端的send_move函数和服务器端的recv_move函数, broadcast_move_notify函数,客户端的recv_move_notify函数中都添加int z参数.而包含int x, int y两组参数的地方也都必须添加相应参数
为了避免这样的麻烦,RPC所有的参数都可以使用同一个参数构造体,但是这样难免会降低代码的可读性
共享内存开发方式的代码量----move(5,5)
共享内存开发方式的代码参考以下示例
void player_touched(mouseX, mouseY) { <-* character->x = mouseX; character->y = mouseY; character->changed(VAL_X); character->changed(VAL_Y); character->broadcastChanged(); } void recv_changed(int type, int value) { switch (type) { case VAL_X: character->x = value; break; case VAL_Y: character->y = value; break; default: break; } }
要增加z参数时, 代码如下
void player_touched(mouseX, mouseY, mouseZ) { character->x = mouseX; character->y = mouseY; character->z = mouseZ; character->changed(VAL_X); character->changed(VAL_Y); character->changed(VAL_Z); character->broadcastChanged(); } void recv_changed(int type, int value) { switch (type) { case VAL_X: character->x = value; break; case VAL_Y: character->y = value; break; case VAL_Z: character->z = value; break; default: break; } }
把上面标记了"*"符号的3个地方修改后就可以告诉别的进程Z坐标发生了变化.因为是无条件接收改变后的值,并没有返回值,所以代码量也会有很大不同. 而且如果想要"只修改X和Z",采用RPC方式不仅需要定义新的函数, 还需要重新编译相关的文件.而采用共享内存方式则不需要增加新的函数,只要修改并编译相关文件即可
共享内存开发方式的优缺点
虽然增加参数这样的调整不能使用IDE的重构工具,但是代码的修改还是比较容易的.在游戏开发中, 需要一边试玩一边进行无数次的细微调整,因此迭代的速度直接决定了游戏的品质.通过比较可以发现"采用共享内存开发方式更容易进行细微的修改, 有利于追求更高的品质"
共享内存方式的缺点是即使只有少数几个数值发生了变化也需要进行通信, 这样可能会产生一些多余的通信量
5.5.9 SyncValue类
在J Multiplayer案例代码中, SyncValue类的实现采用了前面提到的共享内存方式. SyncValue是用来记录在共享内存中变化部分的类,而实际用来处理可动物体的内存区域则是通过别的方式管理的
首先来看可动物体类Movable, 为了方便说明做了以下变化
可动物体类 class Movable { public: U32 id; 游戏房间内的唯一ID float x, y; 现在的位置 float dx, dy; 方向 U32 typeID; 种类ID SyncValue * m_pSyncValue; 同步内存指针 enum { SVT_TYPEID, SVT_X, SVT_Y }; 构造函数 Movable(U32 _id, float _x, float _y, U32 _typeID): id(_id), x(_x), y(_y), typeID(_typeID) { m_pSyncValue = new SyncValue(); m_pSyncValue->registerIntType(SVT_TYPEID); m_pSyncValue->registerFloatType(SVT_X); m_pSyncValue->registerFloatType(SVT_Y); m_pSyncValue->setInt(SVT_TYPEID, typeID); m_pSyncValue->setFloat(SVT_X, x); m_pSyncValue->setFloat(SVT_Y, y); } };
正如前文所述, 为了保证执行效率, 需要直接访问原生float型坐标值x,y.构造函数通过指针在缓存中记录SyncValue内的数值变化,使用registerIntType函数记录变量类型, 调用setInt函数修改实际的值
在游戏的主循环中,同步可动物体移动后变更值的代码可以简化如下:
x += dx; y += dy; this->m_pSyncValue->setFloat(SVT_X, x); this->m_pSyncValue->setFloat(SVT_Y, y);
通过上述代码在SyncValue类的实例中记录了变更结果,所以如果在主循环之外的地方有修改,就可以通过网络发送修改信息
std::vector<Movable*>::iterator itm; for (itm = vm.begin(); itm != vm.end(); ++ itm) { 遍历所有的Movable Movable *m = (*item); vce::VUint8 buf[256]; size_t buflen; m->m_pSync->getDiffBuff(buf, &buflen); 只取得缓存中变化了的部分 if (buflen > 0) { 如果有需要同步的就发送信息 broadcast_sync(m_guestid, m->id, buf, buflen); } m->m_pSync->clearChanges(); }
broadcast_sync()函数只取出缓存中变化的部分并发送信息
void receive_sync(U32 id, const U8 *data, U32 data_qt) { SyncValue sval; 声明SyncValue变量 注册数据格式 sval.registerIntType(SVT_TYPEID); sval.registerFloatType(SVT_X); sval.registerFloatType(SVT_Y); 从网络中读取缓存数据 sval.readBuffer(data, data_qt); Movable * m = g_app->getMovable(id); 通过ID获取Movable实例的指针 如果有变更就同步(直接覆盖写入本地内存) if (sval.isChanged(SVT_TYPEID)) { m_typeID = sval.getFloat(SVT_TYPEID); } if (sval.isChanged(SVT_X)) { m->x = sval.getFloat(SVT_X); } if (sval.isChanged(SVT_Y)) { m->y = sval.getFloat(SVT_Y); } }
为了实现上述操作, SyncValue类需要有以下成员变量
class SyncValue { private: static const int SYNCVALUES_MAX = 32; 以同步的变量个数上限 static const int BUFLEN = 128; vce::VUint8 m_buf[BUFLEN]; 不保存大量数据所以设为固定值 size_t m_offsets[SYNCVALUES_MAX]; ID,从哪一位开始;如果是0则为m_buf[0];类型种类决定大小.这个在add操作时确定 size_t m_sizes[SYNCVALUES_MAX]; 不同变量的大小 bool m_changes[SYNCVALUES_MAX]; 记录变化了的ID bool m_uses[SYNCVALUES_MAX]; 使用了哪些域 size_t m_currentOffset;
在上述代码中,m_buf变量用来记录使用setFloat函数变更后的数据,m_offsets, m_sizes保存变量和变量所在的位置. m_changes保存变更的变量ID,m_uses表示使用的变量. 这些数组都使用了SVT_枚举型中定义的值,当最大值大于SYNCVALUES_MAX时就会报错
SyncValue类的构造函数仅使用默认值0初始化所有的变量
public: SyncValue类的构造函数,必要的变量都初始化为0 SyncValue(): m_currentOffset(0), m_offsets(), m_sizes(), m_changes(), m_uses() { }
SyncValue类现在支持的3种类型都是比较实用的类型,可以在构造函数内进行无限扩展.reg是内部使用的函数,计算并保存缓存的使用方式
void registerCharType(int index) { reg(index, 1); } void registerIntType(int index) { reg(index, 4); } void registerFloatType(int index) { reg(index, 4); }
setChar, setInt, setFloat函数通知发生实际变化的数据
index是SVT_枚举型. 更新m_buf中的数值后将m_changes设为true, 之后就可以发送消息同步数据
void setChar(int index, char val) { char prev = ((char *)(m_buf + ofs(index)))[0]; if (prev != val) { ((char *)(m_buf + ofs(index)))[0] = val; m_changes[index] = true; } } void setInt(int index, int val) { int prev = ((int *)(m_buf + ofs(index)))[0]; if (prev != val) { ((int *)(m_buf + ofs(index)))[0] = val; m_changes[index] = true; } } void setFloat(int index, float val) { float prev = ((float *)(m_buf + ofs(index)))[0]; if (prev != val) { ((float *)(m_buf + ofs(index)))[0] = val; m_changes[index] = true; } }
上面是set相关函数,接下来是get相关函数
char geChar(int index) { return ((char*)(m_buf + ofs(index)))[0]; ) int getInt(int index) { return ((int *)(m_buf + ofs(index)))[0]; } float getFloat(int index) { return ((float *)(m_buf + ofs(index)))[0]; }
使用get函数取得变量值是很简单的处理, 只需从m_buf中获取数值. 下列clearChanges, fillChanges, isChanged函数用来清除变更标记,设定变更标记和取得变更标记
voic clearChanges() { fillChanges(false); } void fillChanges(bool flag) { for (int i = 0; i < SYNCVALUES_MAX; i++) { if (m_uses[i]) { m_changes[i] = flag; } } } bool isChanged(int index) { assert(index < SYNCVALUES_MAX); return m_changes[index]; }
下面的(1)号函数getDiffBuff将m_buf中变更的部分全部输出到缓存outbuf后, 返回该变量
(2)号函数readBuffer, 从缓存参数中读取数据并且判断哪些变量发生了改变,变更值为多少, 从而为get操作准备必要的信息
void getDiffBuff(vce::VUint8 * outbuf, size_t * outbuflen); (1)
void readBuffer(const vce::VUint8 * inbuf, size_t inbuflen); (2)
专栏 数据中心的地理位置分布
K Online或者J Multiplayer这样的网络游戏和Web服务器相比需要更高的相应速度,为了保证游戏体验应该尽可能在离玩家近的地方,甚至是玩家所在国家或地区设置服务器. 在日本和北美两个区域使用同一服务器提供游戏已经是能做到的最大限度
不过也并不是每个游戏公司都有能力在多个国家设置自己的分支机构, 一般的做法是将游戏的服务器代码, 编译后的程序或者设定文件等授权给不同国家的运营商,由这些运营商l来提供服务而己方仅收取授权费(License Fee).当然利用的是当地的数据中心等资源
这种情况下应该尽量避免不同地区的数据中心互相连接,让数据库之间没有相互依赖的关系,保持完全独立的运行状态
现在网络环境在不断改善,有通过使用统一的Web站点来降低成本的趋势,但是距离"单一位置"服务器提供游戏服务还需要很长时间的发展
5.6 支持 C/S MO 游戏的技术[补充]
5.6.1 C/S MO和NAT问题
C/S MO是Client/Server型MO(少数用户在线的)游戏的简称.之前提到过很多次,P2P MO游戏最大的问题是"不是任何玩家都可以直接连接".例如, 当J Multiplayer使用星状拓扑结构时,直接与网络连接但是没有公网IP地址的玩家机器不能做主机,这就是"NAT问题"
5.6.2 什么是NAT问题
据笔者所知, 关于NAT问题科乐美公司(Konami Digital Entertainment, Inc.)的佐藤良先生在网上发布的资料最为详细.其中的重点部分请参考图5.14
http://homepage3.nifty.com/toremoro/study/voip2008/NATTraversal.pdf
注意图5.14中"公开网络(Open Internet)"部分, 在韩国可以作为主机的用户比例很高, 而在日本几乎为0,而且不同国家的比率都不相同
一般来说, 如果家庭使用Softbank等运营商提供的"宽带路由器"连接网络, PC的IP地址和路由器的外网IP地址是不同的,这时NAT是有效状态. 因为PC的IP地址和路由器的外网IP地址通过某种规则可以转换,所以叫做网络地址转换(Network Address Translation). 使用NAT不仅可以解决公网IP地址不足问题,还具有提高安全性和简化网络连接等优点
不过网络游戏需要和网络上的其他PC联网, 而NAT可能会造成网络无法连接问题
5.6.3 NAT遍历----解决NAT问题建立通信路径的技术
图5.14说明了NAT遍历(traversal),即解决NAT问题建立通信路径的技术.该技术不仅在网络游戏中使用, 在VoIP(Voice over IP), 网络会议系统, VPN等领域也有广泛应用,因此市场上除了各种中间件产品, 还有很多开源产品
首先按限制程度将互联网用户的NAT状态划分为6个阶段,如下所示, 强度逐渐增加
1. 公共网络
拥有公网IP的终端
2. 无限制NAT -> 图5.14中的"完全圆锥型"(Full cone)
访问路由器的指定端口时, 固定转换为LAN中PC的特定端口.可以传输所有的收到的数据包
3. 限制地址的NAT -> 图5.14中的"受限圆锥型"(Address----Restricted cone)
只接收来自于NAT内部, 并且之前有发送过数据包的终端的数据包. 通过设定IP地址提高安全性,不接受之前没有产生过通信的IP地址所发送的数据, 这也叫做"受限圆锥形"
4. 限制端口的NAT -> 图5.14中的"端口受限型"(Port----Restricted cone)
和限制地址的NAT相同,不过又增加了端口号的限制, 也叫做"地址/端口受限型"
5. 对称NAT(Symmetric NAT) -> 图5.14中的"对称型UDP防火墙"
每次建立通信路径时都使用不同的端口号,不同的地址. 这个方式有很多分支类型
6. UDP禁止型 -> 图5.14中的"对称型"
禁止使用UDP通信
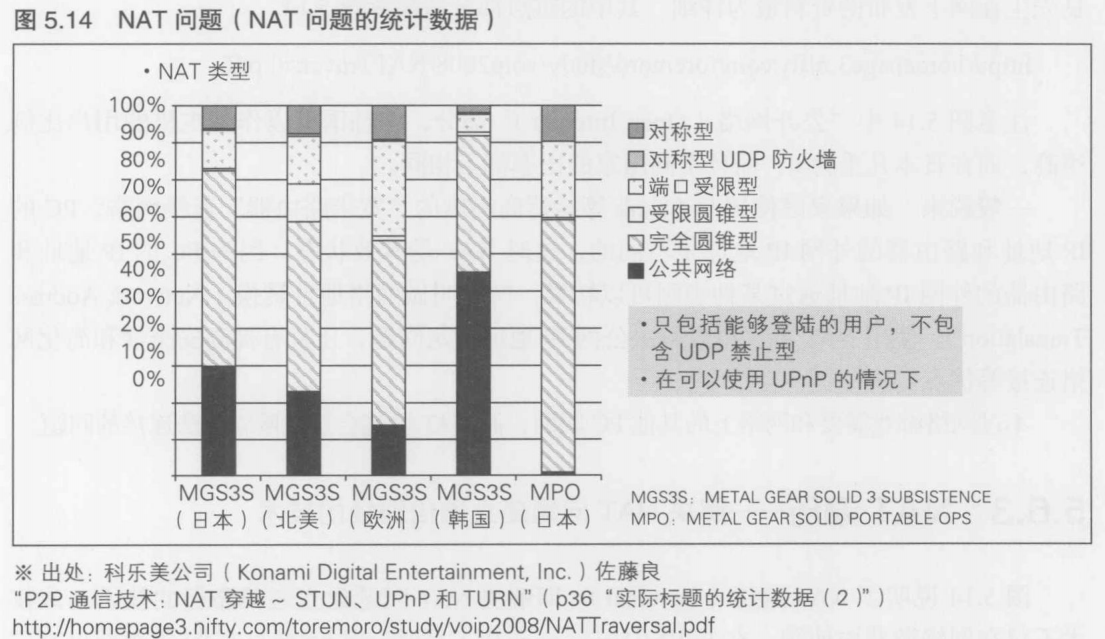
NAT遍历技术的限制
以现有的技术基本可以解决1到4中的NAT问题.针对5的情况可以使用"UDP Hole Punching","STUN"等技术,不过不能保证100%解决问题.5的一部分和6的NAT问题目前还无法解决
使用NAT遍历技术的其他缺点
使用NAT遍历技术的另一个缺点是,在玩家和其他PC实际建立连接交换数据之前需要各种初始化处理和验证处理,这不但需要花费数秒至数十秒的时间,还需要专门的服务器, 所以产生了成本问题.此外, 5的一部分玩家和6的玩家的NAT问题也暂时无法解决
5.6.4 NAT问题的实际解决方法
NAT问题的一个实际解决案例如下
- 在Microsoft的Xbox 360标准程序库中, 为了与别的玩家建立连接, 采用了多个阶段的通信确保数据包能够到达
- 如果还是有问题,则使用中继服务器建立连接
因为大部分的开发者并不是为了Xbox360平台开发游戏,这里主要介绍使用中继服务器的方法.使用中继服务器可以让用户的连接失败率降到几乎为0
5.6.5 中继服务器
中继服务器是指第3章介绍的"反射型架构"的数据包中继服务器.这种服务器既不检测数据包中的数据,也不需要认证.
调用SyncValue的逻辑在J Multiplayer中直接保留,只需要修改物理网络的使用方法
J Multiplayer最初的原型没有使用反射型架构,而是采用了直接连接的P2P/星状拓扑结构,所以当4个人游戏时,主机接收3个客户端的连接.如图3.12所示
使用中继服务器的时候, 主机之外的客户端连接的IP地址仅从主机地址变成中继服务器的地址, 所以主机的操作只需要稍微调整一下即可
具体来说主机需要添加以下功能
- 启动时连接中继服务器,创建新的通信频道(channel)
- 广播时, 不向客户端直接发送数据,而是向中继服务器发送
此外在客户端, 为了获取中继服务器的通信频道信息,需要使用匹配服务器等辅助系统,还要从主机获取通信频道的ID
使用中继服务器进行交换的数据和使用直接连接方式时的一样,都是SyncValue的差分数据
5.6.6 中继服务器的折衷方案
实际上中继服务器的实现十分简单, 不过在程序开发上有两个需要折衷的地方
1. 因为通信需要经过服务器,所以会有游戏延迟
2. 需要消耗服务器带宽
将影响降低到最小正是需要开发者大显身手的地方, 虽然Xbox 360平台有提供解决方案, 不过还可以进一步得到改善
1. 游戏延迟增大的问题
首先关于游戏延迟增大的问题, 并不是每个用户都需要使用中继服务器, 让那些怎么都无法建立主机的玩家使用就可以了.这样两种方式共存, 在一定时间内不能建立通信的情况下切换成使用中继服务器的模式
2. 消耗服务器带宽的问题
关于服务器带宽的消耗问题有几个阶段的折衷方案. 虽然可以尽可能的压缩带宽消耗, 不过这样会增加开发时间
这里介绍几种方法
- 什么都不调整的时候
首先来看看什么都不调整的情况. 假设4个人同时进行J Multiplayer游戏, 主机需要100kbit/s的带宽,那么1个人做主机有100kbit/s带宽, 向其他3个客户端发送数据,每个客户端需要33kbit/s
主机: [上行] 33kbit/s x 3 = 100kbit/s, [下行] 非常少
客户端: [上行] 非常少, [下行] 33kbit/s
通信量[非常少]是因为游戏开发规范中要求同步敌人数据的时候只同步Create/Delete操作
综上所述4个人同时连接时需要中继服务器100kbit/s的上行下行带宽, 如果以同时连接数4000为基准,需要100kbits x (4000/4) = 100Mbit/s带宽.目前这个带宽的每月花费大概在几万到几十万日元之间. 这不是一笔小数目,所以需要考虑该如何解决这个问题
- 解决方案1
4个人中如果有1个人可以使用NAT遍历, 那么就让这个人作为主机开始游戏, 同时作为中继服务器进行通信
假设按照刚才图5.14的数据, 在日本可以使用NAT遍历的用户大概是7成.4个玩家在线时,不能使用NAT遍历的概率是0.3除以4等于0.008, 不到1%.所以服务器成本马上缩减为1/100.不过这样可能会遇到通信测试时间很长的问题,全部玩家都测试的话估计要花费1~2分钟
在服务器保存通信测试结果也许可以缩短等待时间(不过笔者目前还没遇到这样的做法)
- 解决方案2
将同步数据拷贝到中继服务器
主机向其他3个客户端发送的同步数据都是一样的,如果主机将发给3个客户端的相同数据包改为只发送一次同步数据,由中继服务器将该数据发送给其他3个人,这样也可以减少上传数据消耗的带宽.4个玩家时所需带宽如下
主机: [上行] 33kbit/s x 1 = 33kbit/s
客户端: [下行] 33kbit/s
上行带宽一下减少到1/3, 整体看来可以减少2成左右.不过这种方案需要修改中继服务器的程序
使用中继服务器开发MO游戏时,需要注意上面两点.如果不实现这两点的优化,服务器成本可能会很高,难以实现游戏的商业化运营
5.7 总结
第6章 网络游戏的辅助系统 完善游戏服务的必要机制
6.1 辅助系统需要的各种功能
6.1.1 现有服务器提供的辅助系统功能
下面我们将服务分为通用, 游戏主机用, 网页游戏用, 现有中间件几类,一起来看一下其中包含的辅助系统
- 通用
通用服务可以用于多个平台, 并且没有游戏类型的限制.例如, 下面的Uplay服务可以为游戏主机,iPhone等移动平台以及PC等提供服务.Plus+可以用于C/S MMO游戏和P2P MO游戏和P2P MO游戏
Steam
官方网站: http://store.steampowered.com/
开发者网站: http://www.steampowered.com/steamworks/
这是2010年在全世界范围拥有3000万以上用户的大型服务.最大的特点是具有功能强大的销售渠道,提供游戏的介绍,下载和更新.还具有玩家匹配,玩家成绩管理等完善的功能.2010年继Windows版后发布了Mac版,可以玩Portal等主流游戏.此外, 将来还会发布Linux版,在发展中国家市场也会开始提供服务
Plus+
官方网站: http://plusplus.com/
开发者网站: http://www.openfeint.com/developers
提供玩家匹配, 点数管理, 玩家成绩管理, 连接社交网络等功能.没有中继服务,相对来说是比较简单的功能
OpenFeint
官方网站: http://www.openfeint.com
开发者网站: http://www.openfeint.com/developers
提供玩家匹配, 点数管理, 玩家成绩管理,连接社交网络并集成Apple Game Center等功能,早已支持Android平台.对于开发者来说这是个开放的环境,可以自由尝试SDK,没有什么政治上的约束
GameSpy Arcade
官方网站: http://www.gamespyarcade.com
开发者网站: 非公开(咨询网站: http://www.poweredbygamespy.com/)
历史最久的服务. 2000年左右就提供了玩家匹配, 玩家成绩管理等功能. SDK没有公开, 需要联系管理GameSpy服务的IGN公司并说明商业计划
Uplay
官方网站: http://uplay.uk.ubi.com/
开发网站: 非公开(需联系育碧公司Ubisoft)
没有向第三方公开,是育碧公司内部游戏的专用服务, 但是功能十分强大.独特的功能是Uplay管理的虚拟货币可以在游戏内购买道具
- 面向游戏主机的服务
针对游戏主机的服务,一般只需要联系游戏主机提供商(微软, 任天堂, 索尼电脑娱乐, 苹果等),提出服务申请,说明商业计划并签署保密条款后即可.一般在开发工具包内都会提供标准的平台开发SDK
Microsoft Xbox LIVE
官方网站: http://www.xbox.com/ja-jp/live/
开发者网站: 非公开
包括了玩家匹配,玩家成绩管理等各种业界标准的游戏辅助系统.SDK的文档十分详细
任天堂----Wi-Fi Connection
官方网站: http://Wi-Fi.nintendo.co.jp/
开发者网站: 非公开
提供玩家匹配, 玩家记录等基本服务.功能比Xbox LIVE少, 因为任天堂的游戏主机主要面向儿童和青少年,一般都不是很复杂的多人游戏
PlayStation Network
玩家匹配, 玩家成绩管理, 中继服务等, 提供和Xbox LIVE相当的最完备的辅助系统服务. SDK的文档虽然可以更为详细,但和PSP交互的普通游戏的基本功能已经相当完备
App Game Center
官方网站: http://www.apple.com/game-center/
开发者网站: http://developer.apple.com/
提供了许多针对iPhone/iPad的功能,包括P2P MO游戏使用的通信,玩家匹配,玩家成绩管理,语音聊天等.特点是可以使用iTunes并提供了强大的应用内付费功能,具有非常方便的游戏发售渠道
- 面向网页游戏的服务
针对网页游戏, 比较有名的现有服务如下
Kongregate
官方网站: http://www.kongregate.com/
开发者网站: http://www.kongregate.com/labs
基于浏览器的Flash游戏使用的平台.提供玩家匹配, 玩家成绩管理等基本功能
- 现有中间件
现有中间件提供了程序库,但需要自己准备服务器并搭建环境
Rendez-Vous
官方网站: http://www.quazal.com/
开发者网站: 没有公开的开发者社区网站
是世界上市场占有率最高的网络程序库.根据Quazal公司官方网站的描述, 他们提供的功能包括: 好友列表, 工会, 比赛系统, Ping统计,聊天室, 用户管理, 即时聊天系统, 邀请, 聊天, 敏感词过滤, 联赛, 排行榜, 统计, 事件日历,账号管理, 加密, 认证,文件上传,下载, 等等. 这是功能最全的程序库, 堪称网络游戏辅助系统的功能大全.软件授权价格是非公开的, 基本以公司为单位,根据不同的商业需求定制了不同的价格. 如果是针对游戏主机的开发, 因为游戏主机平台已经提供了很多相同的功能, 所以还可以选择使用其中的部分功能
6.1.2 现有服务的功能一览
6.1.3 网页游戏开发方法和客户端游戏的开发方法
6.2 交流/通信功能
6.2.1 玩家匹配 P2P MO
用途: P2P MO游戏中查找对手玩家
问题: 无法解决NAT问题, 很难避免高级玩家遇到低级玩家, 需要一些处理时间,不能很好地取消匹配, 无法顺利实现中途参加游戏的功能
实现: 三种方式: 在现有服务的基础上定制开发, 基于Web技术简单实现或者C/S架构实现. 可以采用横向分区,常驻内存方式实现
P2P MO游戏中多人游戏需要满足的条件
P2P MO多人游戏需要满足以下条件
- (必要条件)参加游戏的玩家机器之间可以相互通信
- (尽可能)可以选择一起游戏的玩家
在客户端和服务器端都可以实现满足上述条件的功能, 不过为了避免重复开发,一般会在"玩家匹配服务器"中实现全部功能
玩家匹配服务器
为了满足上述两个条件, 玩家匹配功能会按照以下方式实现
- 发送"多人游戏请求"到玩家匹配服务器
- 匹配服务器收到请求后, 查询"匹配候补列表",如果找到满足条件的玩家,则向各个客户端返回匹配消息
- 如果"匹配候补列表"中没有符合条件的玩家, 则将相关信息加入候补列表,并保存变化后的信息
- 所有的客户端在取消玩家匹配请求后(关闭客户端程序时),游戏开始后和游戏结束后需要将相关状态的变化通知匹配服务器
- 状态更新后, 匹配服务器需要从候补列表中查询出满足条件的玩家
- 客户端的通信中断后, 匹配服务器需要进行垃圾清理(必要时)
采用上述实现方式, 匹配服务器的负荷计算方法: 想进行多人游戏的玩家数 x 状态变化频率
满足多人游戏的两个条件的具体做法----J Multiplayer游戏
要在J Multiplayer游戏中实现上述两个条件的具体做法如下
- (必要条件)参加游戏的玩家机器之间可以相互通信
- (尽可能)可以选择一起游戏的玩家
满足多人游戏的两个条件的实现----J Multiplayer游戏
- 在匹配服务器采用计算量不大的算法
- 开发时需要注意的两点
无需持久化
不易扩展性能
匹配结果画面
"匹配成功"后的结果必须包括以下信息
- 主机的IP地址和端口,以及NAT类型
- 玩家的信息(名字, 级别等)
6.2.2 游戏大厅 P2P MO
用途: 在P2P MO游戏中查找对手玩家
问题: 没有特别难的问题, 不过想要开发容易变更, 成本低的服务器需要更多时间
实现: 利用现有服务或者C/S方式实现两种选择.容易进行横向区分
游戏大厅是匹配服务器的一种形式.匹配服务器是自动为玩家查询游戏对手, 而游戏大厅是由玩家自己从列表中选择游戏对手
游戏大厅和匹配
有些游戏可以同时使用游戏大厅和匹配服务两种方式.这时通常会把匹配服务称作"快速匹配".从名称上来区别, 自动帮玩家找对手的叫做"快速匹配",玩家自己选对手的叫做"游戏大厅"
使用游戏大厅得到的结果包括以下信息
- 主机的IP地址和端口号, 以及NAT类型
- 玩家的信息(名字,级别等)
和匹配服务的结果包含的信息相同
"游戏大厅"是从酒店的"大厅"(Lobby)一词引申而来, 意为"等待的地方".游戏开始前需要等待,查询游戏对手,找到合适的对手才开始游戏.和匹配服务不同, 除了P2P MO游戏,C/S MMO游戏在选择服务器的时候也经常使用游戏大厅
《星际争霸2》(StarCraft II)的例子
以《星际争霸2》为例, 游戏中的"战网(Battle.net)"就相当于游戏大厅和匹配服务.战网是由暴雪娱乐公司提供的专门用于暴雪娱乐公司出品游戏的对战平台. 这个服务发布的时间很早, 功能十分完善,是游戏大厅的行业标准,影响力很大. J Multiplayer的游戏大厅基本上是参考战网的功能开发的
《星际争霸2》的游戏大厅画面可以显示由玩家创建的"自定义游戏"列表, 列表中还可以列出没有NAT问题的玩家
自定义游戏是指玩家创建的,自己设定游戏玩法和地图的游戏.可以在游戏大厅选择其他玩家创建好的自定义游戏,建立连接后开始游戏
《星际争霸2》的自定义游戏可以设定地图种类, 胜负方式, 奖励方式,参加条件等,因为条件非常多, 自动匹配很难得到理想结果,所以采用了手动选择的方式.在游戏大厅画面的列表中选择自定义游戏后,可以显示更详细的信息
开发要点
游戏大厅很像实时变化的拍卖场一样, 开发时需要注意以下要点
- 玩家创建(自定义)游戏后, 将相关信息发送到游戏大厅服务器(只有能做主机的玩家需要发送NAT状态)
- 游戏大厅服务器收到"现在游戏的列表"请求后返回相关信息
- 当玩家加入游戏或者其他操作导致游戏状态发生变化时,将该状态发送到游戏大厅服务器
- 游戏客户端定期向服务器发送请求更新游戏列表
对玩家来说, 即使游戏大厅按游戏条件在DB上进行横向分区,也不会影响其查询结果, 所以不需要在这上面考虑过多.负荷过高时分区即可.具体的实现可以利用现有服务, Web技术或者C/S架构

6.2.3 中继服务器 P2P MO
用途: 解决有NAT问题的P2P MO游戏玩家通信问题
问题: 吞吐量(Throughput)小, 带宽要求高, 响应时间长
实现: 利用TCP C/S(TCP客户端服务器)方式实现. 服务器操作系统的选择,分组方式,保障安全性的方式
中继服务器需要的性能
中继服务器需要尽量避免网络延迟,让通信可以快速进行.由中继服务器造成的网络延迟大致估算如下.
首先假设互联网的平均跳转数是20,20次跳转的通信延迟大概是30毫秒,玩家之间直接连接时,发送数据包的延迟是30毫秒
客户端->网络(20次跳转)->主机
经过中继服务器时的过程如下
客户端->互联网(20次跳转)->中继服务器->互联网(20次跳转)->主机
总计40次跳转, 延迟60毫秒,其中可以看到中继服务器增加的延迟.P2P MO游戏要求游戏延迟在50毫秒以内,这里由于中继服务器的原因让整体延迟超过了50毫秒,无法实现预期的游戏内容.因为有游戏内容上的限制,所以中继服务器自身的延迟需要在10毫秒以下,甚至要尽可能缩短到1毫秒左右
6.2.4 聊天 P2P MO C/S MMO
用途: 通用
问题: 吞吐量(Throughput)小
实现: 利用Web技术或者TCP C/S 技术.性能扩展方法, 不同国家访问方式的不同, Spike问题的对应
P2P MO游戏中的实现方式是由客户端向主机发送信息, 主机再向其他客户端发送消息. C/S MMO游戏是客户端向游戏服务器发送消息,然后由游戏服务器向全体客户端发送消息
聊天功能的实现
如果P2P MO游戏玩家之间的通信超过了网络限制范围, 或者C/S MMO游戏中的通信跨越了游戏服务器就会出现一些问题
出现这种情况时请参考IRC,设置专用的聊天服务器,并实现服务器之间的通信处理.笔者也开发过这样的聊天系统, 仅仅使用开源的IRC实现并不能满足服务器端的功能需求,所以基本上项目中都是自己开发
虽然是自己开发, 但是只要注意一些要点,处理逻辑比起实现游戏服务器来说还是简单很多
聊天功能的基本处理
聊天功能的基本处理整理如下
- cli(游戏客户端)向聊天服务器发送消息, 并同时向需要的客户端发送
- 需要在1~2秒内将消息送达需要的客户端(Push)
- 和邮件不同, 不需要给不在线的玩家发消息, 所以不用保存信息
- 服务器端不需要保存用户的日志
一般客户端和服务器之间的TCP会话(session)会一直保持, Push时会利用这个会话发送消息.也可以使用HTTP轮询或者Comet的方式,不过会增加服务器的负荷
因为在单台服务器上无法为几万用户同时提供服务,所以当游戏用户量超过一定规模时需要多服务器处理
同步发送消息的规模
接下来, 针对"应该对哪些用户同步发送消息"这一点,我们分成几类来讨论, 对于网络游戏,根据游戏策划内容的不同, 有如下一些典型的形式
- 1对1: 也叫做Tell, Whisper, Private或者Direct等.某个玩家和某个玩家之间的通信
- 小规模: 也叫做Party, 在5~6人的临时小组内发送消息
- 中等规模: 也叫做Clan, Guild或者Group等.对SNS的组群级别的全部用户发送消息
- 大规模: 也叫做服务器消息, 对某个服务器的全体用户发送消息.最多可以同时发送给1000人以上, 根据传送距离又分为Shout, Scream等
- 最大规模: 也叫做世界消息, 针对游戏的全体玩家发送. 一般是游戏管理员发出的通知. 比如在游戏策划中, 某个城池被攻陷时发出的通知,为了系统的特殊目的而使用的消息.同时对几万玩家发送, 这是负荷最高的聊天消息
为了满足大量客户端的响应需求, 需要多台服务器分别处理. 其中最重要的问题是"哪些客户端连接哪些服务器比较好"
比如游戏策划中需要Tell, Party和Guild三种消息类型,其中大部分是Party类,对于这种情况,尽可能让小团队内部的玩家都连接相同的服务器, 这样可以减少服务器之间的通信
比如图6.2中的结构, 前端服务器之间的通信经过后端服务器, 连接聊天服务器时,会根据团队成员连接的是哪台服务器来做相应的选择,只有必要的时候才会连接后端服务器

还有一种情况,游戏策划中只有Tell和Party消息时,服务器之间就没有通信的需要. 如图6.3所示,这种结构的服务器之间没有通信,如果想和不在团队内的玩家发送私信, 可以在自身团队所在的服务器和对方所在的服务器中建立两个会话.当会话数上限最低为2时,就可以实现这种需求
这种情况情况不需要后端服务器,管理起来也比较容易. 以上是两种比较典型的服务器结构,基本可以满足各种游戏的需求.
6.2.5 邮件 P2P MO C/S MMO
用途: 通用
问题: 没有特别难的问题,但要注意控制成本.已读邮件管理,逻辑删除,服务提供商责任限制法
实现: 利用现有服务,Web技术或者C/S技术(和Web应用开发相同,横向分区比较容易)实现
邮件服务和聊天服务有以下不同点
- 消息比较长
- 对于不在线的用户也需要发送邮件(需要持久化)
- 需要记录日志
- 允许邮件延迟,几秒至20秒左右都可以接受
- 需要管理已读邮件
- 可能需要提供查询服务
因为可以有一定延迟,所以一般通过采用HTTP协议的Web服务(Web Service)来实现. 此外,利用Web服务实现的邮件系统和C/S MMO的游戏服务器之间也可以进行通信. 编码, 测试和发布一体化非常方便,所以经常使用这种方式
邮件系统可以很容易地按照用户ID进行横向分区,没有特别需要注意的地方
6.2.6 好友列表 P2P MO C/S MMO
用途: 通用
问题: 有单向和双向两种选择, 双向列表会有不一致的情况
实现: 列表不会很大,没有特别困难的地方. 利用Web技术, C/S 技术都可以实现, 也可以使用现有服务
即朋友列表,自己在Twitter等平台上关注的人成为好友
和邮件相同, 好友列表也可以按照用户ID进行横向分区, 不会出现负荷过高的情况. 访问频率的变化也不大,可以使用HTTP协议实现. 现有的服务也都比较成熟,可以很容易集成到游戏中
6.2.7 玩家状态 P2P MO C/S MMO
用途: 共享P2P MO或者C/S MMO游戏中好友的游戏
问题: 吞吐量不大
实现: 可以使用现有服务, 自己开发的话因为需要频繁通信所以建议采用C/S结构; 不需要性能扩展方面的考虑
玩家状态是指实时通知好友是否在线的服务. 以Skype的联系列表为例, 好友状态分为在线, 离线和自动回复等.网络游戏中, 为了查询同时游戏的玩家,需要知道好友列表中的玩家目前是在线还是离线状态,对于很多游戏来说这个信息十分重要
游戏中的玩家状态服务的特点
和Skype等软件不同, 游戏的玩家状态功能需要显示的信息很多.比如某个C/S MMO游戏, 玩家被敌人攻击时HP的变化也需要通知好友.所以, 根据游戏策划的不同,玩家状态服务器的负荷有可能比较高
玩家状态服务器和聊天服务器中"工会"(Guild)消息的通信量差不多,不过有以下一些区别
- 特征1: 工会成员列表对于所有工会内的成员都是一样的,但是好友列表不同, 每人的好友是不一样的,所以不能像工会那样可以指定专用服务器
- 特征2: 和聊天不一样,比如HP的变化这样的消息,中间丢失几条也不要紧
- 特征3: 消息传输不用像聊天消息那么快, 允许延迟10~30秒左右
玩家状态服务的实现
参考上面提到的这些特征,基本采用和聊天服务器的实现相同的结构,在实现上需要花一些功夫
首先需要估算通信量,消息可以分为以下三种
- 1. 绝对不能省略的消息 登录,退出的通知
- 2. 尽量不要省略的消息 现在所在服务器, 所在位置
- 3. 可以省略的消息 HP的变化,击倒的敌人的名字等
不管什么游戏,登录和退出都不会很频繁地发生. 就拿笔者参与过的MMO游戏项目来说,时间短的平均是40分钟一次.假设100万玩家同时在线(非常高的设定,很少见),平均2000秒1次的话,1秒也只有500次访问.这种规模的用户,前端服务器应该有100台左右.
对于特征3"可以允许一些延迟",需要做以下处理
- 后端服务器收到状态变化通知后记录所有信息
- 前端服务器没每10秒从后端服务器更新一次状态变化信息
- 前端服务器将更新后的状态通知各个客户端
关键点是不用全部实时通知.后端服务器需要进行以下处理
- 保存状态变化: 每秒接收500条消息,向前端服务器分配
- 读取状态变化并通知: 每秒响应10台前端服务器的请求
以使用MySQL的后端服务器为例,在单个服务器实例(instance)中, 每秒500次简单的update操作, 需要进行10次1万行数据的select查询.表不需要持久化,所以可以在内存上操作
这种情况下不仅可以满足上述"(1)绝对不能省略的消息"的性能要求, 还有一些富余
"(2)尽量不要省略的消息"可以使用剩余的性能部分.剩余的性能部分具体是多少呢?不如我们来测试一下MySQL的性能,看看吞吐量是多少,这样效率更高一些.假设update操作可以达到每秒3000次左右,因为已经使用了500次,所以还剩2500次可以使用.
6.2.8 加锁服务器 P2P MO C/S MMO
用途: 防止C/S MMO游戏中双重登录, 数据损坏或者无限增长的情况
问题: 锁定状态残留,解锁攻击的漏洞
实现: C/S, 处理序列原子化(atomic)
C/S MMO游戏有多个游戏服务器,如果同时登录多个服务器, 最后退出的玩家数据会覆盖之前的数据, 导致玩家状态回档, 如果被恶意利用还会发生无限道具的问题. 所以需要防止C/S MMO游戏的双重登录,加锁服务器可以实现这个功能
加锁服务器的实现
加锁服务器的功能一般会在开发玩家状态服务器时一起实现,这里将针对功能本身进行说明
首先,我们来看一下采用MySQL实现加锁服务器的方式
- 玩家登录的时候, 首先在加锁信息表中使用select操作查询目前的状态
- 如果已经登录则拒绝再次登录
- 如果是退出状态则允许登录, 并使用update操作更新加锁信息表, 设为登录状态
这里有个问题,如果没有实现"游戏服务器发生异常退出时, 解除该服务器的所有锁定状态"的功能,就会发生锁定状态残留的问题
所以使用MySQL实现是比较麻烦的,一般会"实现专用的常驻内存处理方式的服务器".例如在第4章介绍K Online的章节中, 防止双重登录的功能是在管理玩家状态的消息服务器(msgsv)中实现的.锁定状态不需要持久化, 所以不会有性能问题(负荷比玩家状态管理要小很多)
6.2.9 黑名单 P2P MO C/S MMO
用途: 通用
问题: 降低处理负荷, 在客户端还是服务器进行限制, 黑名单被其他玩家看见会很麻烦
实现: 没有可以使用的现有服务, 可以采用Web, C/S架构.名单不大所以比较简单
黑名单是指在聊天或者邮件等与其他玩家通信的功能中, 用于屏蔽特定玩家的通信的功能,也叫做"限制名单"
最近, 游戏中发送垃圾消息的玩家多了起来,所以很多游戏需要黑名单功能. 这个功能可以拒绝黑名单里的用户发送出的邮件,不显示他们发出的聊天信息
黑名单功能的实现
游戏中的黑名单功能需要考虑下面两个问题从而决定实现方式
- 黑名单的信息是在客户端还是在服务器端保存
- 黑名单的判定是在客户端还是在服务器端进行
Web应用的所有处理都是在服务器端进行. 而对于游戏来说,主数据(master data)可以在客户端保存, 登录时再发送给服务器
"黑名单的判定在客户端进行"是指服务器将全部消息发给客户端, 由客户端来决定是否显示
黑名单的信息也包含隐私信息, 所以需要结合游戏策划考虑采用什么方式.如果黑名单功能的实现是在服务器端,比如与玩家状态,聊天,邮件等功能结合时,这种情况下黑名单的判定处理可能会占大部分处理负荷,在设计时需要十分小心
6.2.10 语音聊天 P2P MO C/S MMO
用途: 通用
问题: 占用宽带太多, NAT问题
实现: 利用现有服务器或者使用中继服务器自己开发,使用编码解码器
语音聊天技术非常复杂,详细说明的话可以写一本书. 对于主机游戏或者PC游戏来说, 利用现有服务会比较方便快捷,比如BOSE公司的商业程序库或者各个平台提供的工具
如果要自己开发, 需要注意以下几点(笔者也没有实际的开发经验,也不好多说......)
最大的问题是占用宽带太多, 一个用户发言时需要10kbit/s左右,以此为平均标准,向5个人发消息时, 服务器就需要占用50kbit/s.服务器带宽不足时, 虽然可以像P2P MO游戏那样转换成玩家之间直接连接的方式,但这样又会遇到NAT的问题
不过不发言时是不占用宽带的,实际上游戏中同时发言的玩家人数并不是很多(10个人一起发言的情况应该没有,一般都是一个人说话其他人听),所以可以利用这个特点进行相关设计
6.3 游戏客户端实现相关的辅助系统
6.3.1 玩家成绩管理 P2P MO C/S MMO
用途:通用
问题: 如何防止作弊, 怎样在之后追加游戏成绩
实现: 可以使用现有服务.如果自己开发, 需要在客户端处理还是上传全部游戏数据在服务器端处理, 自己开发也不是很麻烦
玩家成绩管理是指保存/浏览/查询共享游戏中的成就.一般的游戏策划中玩家可以获得的成就就能达到10~100种, 例如"超过了100万分","击败了最终BOSS"和"清除全部敌人"等,如果在游戏过程中获得了这些成就则显示在列表中, 其他玩家也可以看到
玩家成绩管理的实现
玩家成绩管理一般在游戏服务器或者游戏程序内部实现, 因为是通用功能,所以XBoxLive平台集成了该功能. 现在还可以使用其他服务.利用这些现有功能,可以在玩家成绩管理的实现上节省很多时间
在游戏机或者iPhone等手机上开发游戏时,可以在客户端程序中, 利用一些公司提供的玩家成绩管理服务的开发程序库,当游戏内满足条件时调用相应的函数,显示成绩画面, 并将信息发送到玩家成绩管理服务器
使用这种方式记录玩家成绩的P2P MO游戏,很容易通过对游戏客户端程序的破解来作弊. 所以并不适合那种根据游戏成绩来获取稀有物品的游戏策划方案.
C/S MMO游戏可以在服务器端实现玩家成绩管理. 目前大部分的游戏都是自己开发该功能. 只要对程序库稍微修改一下就可以调用服务器记录玩家的成绩,所以那些轻量级的C/S MMO游戏可以直接利用这些程序库
自己开发的话, 因为记录成绩的频率不是很高,可以很容易地使用HTTP协议实现. 分区方式和邮件系统的实现基本相同,可以根据用户ID进行横向分区
6.3.2 存储功能 P2P MO
用途: 在服务器而不是存储卡内保存P2P MO游戏的游戏进度
问题: 作弊, DB碎片化
实现: 利用现有服务,可以采用Web,C/S 架构.不是很困难,横向分区简单
在服务器端保存P2P MO游戏的游戏进度的功能.为了中途继续游戏, 需要在某个地方保存游戏的进度.可以保存在游戏机的主机或者手机的存储卡中
- 在基于网页的Flash游戏中, 想从多台电脑启动并获取相同进度
- 在朋友家的机器上读取自己的进度继续游戏
- 为了防止进度丢失
- 获得更多存储空间
- 想让游戏数据和网站失联
为了满足上面的需求, 需要在服务器端保存游戏数据. 很多公司提供了这种功能的服务. 如果是自己开发, 也可以像邮件系统那样通过用户ID进行横向分区
6.3.3 (游戏客户端)更新 P2P MO C/S MMO
用途: 更新需要安装的游戏
问题: 带宽, 文件一致性, 更新补丁
实现: 现有服务, 利用BitTorrent等工具实现, 需要策划. CDN(Contents Delivery Network)
为了延长游戏的寿命,需要发布更新补丁, 升级服务器.所以要求定期进行低成本地维护游戏
不管是P2P MO游戏还是C/S MMO游戏都需要更新游戏客户端程序.目前主流的做法是直接利用现有服务(苹果, 微软, Steam等公司提供的平台).按照不同平台的打包方式压缩并上传,通过审查后就可以发布
当然, 该功能只是针对可以在客户端安装程序的平台
更新的基本功能
- 如果自己开发更新模块, 需要哪些功能呢?
- 在游戏客户端启动时, 访问更新服务器,确认是否有新的安装包需要更新
- 如果有新的安装包则开始下载
- 下载安装包
- 下载完成后进行内容的校验
- 如果没有问题就更新已有游戏(一般不备份)
- 重新启动游戏
客户端的实现不是很难, 仅有的问题是服务器的带宽. 游戏中使用了大量的图片和声音, 所以一般更新包会比较大.假设需要给1万用户发布10兆字节的更新包,则需要100吉字节的通信量,即使是使用全速100Mbit/s的专线也需要8000秒(两个小时以上).现在有很多高画质的游戏需要几百兆字节, 甚至几吉字节大小的更新包
更新和访问模式

自己开发更新功能
现有服务都有高性能的基础设施, 所以基本上不需要担心上述问题, 但是对于下列情况,还是需要通过某种方式自己开发该功能
- 使用Flash的游戏
- 在平台的审查前或者规避审查的游戏
笔者参与过的项目采用了下面的方法
- 在游戏的官方网站只发布文件尺寸比较小的安装程序,图像等数据可以和Akamai等CDN公司合作,分散下载负荷
- 利用BitTorrent程序库分散下载负荷
- 利用Nifty Cloud等公开云计算服务, 临时增加Web服务器,发布静态文件
BitTorrent方法是上面3种方法种成本最低的,但是在实际分散负荷之前, 文件的传播时间比较长, 需要花费数小时甚至数日,短时间内的负荷分散率比较低, 所以只有在那种推迟更新也不影响正常游戏(没有登录限制)的游戏策划中才能考虑这个方法
6.3.4 排行榜 P2P MO C/S MMO
用途: 通用
问题: 服务器负荷非常高, 使用SQL实现"显示距玩家排名前后5位的玩家"比较麻烦
实现: 现有服务比较方便,可以采用Web或者C/S架构.批处理, 性能扩容比较困难
排名功能的实现----网络游戏特有的需求
使用现有平台的排名服务比较简单
自己开发时,可以使用HTTP方式访问,需要注意的是DB的设计方法.一般采用Web服务的方式实现排名功能,对于游戏来说有以下特征
- 排行榜的名单很长,有的射击游戏在排行榜中的玩家在10万人以上
- 玩家想知道自己的排名
如果每次查询排行情况时都对所有数据排序,负荷同样会比较高
为了解决这个问题,常用方法是
- 使用DBMS时:增加"rank"列,排名前100的数据每次都重新排序并更新实时的结果,其他数据可以暂时允许有不正确的结果,所有数据的排序和更新每天做1次,一般的查询就返回不正确的排名结果, 这个做法叫做"临时排名法"
- 使用C++或者Java这样的高级语言在内存中处理,每次都进行排序,但是不能处理大于100万行的数据
对于大规模的用户,推荐使用第一种方法
临时排名法
临时排名法是指,找出"在比自己分数低的玩家中, 分数最高的玩家的排名",然后加1
> select * from scores where point <= 新分数 order by point desc limit 2
尽管不正确,但是玩家也应该不会有意见
6.4 运营辅助系统
新闻发布 P2P MO C/S MMO
用途: 消息通知
问题: 限定时间, 自动更新,已读管理
实现: 如果有邮件功能的话可以附加在其中,如果没有就使用Web技术实现,比较简单
新闻发布是指游戏运营团队发送通知的方式,尽可能向所有玩家发布同样消息的系统
新闻的内容可以是服务器的故障报告或者游戏更新通知,活动通知.等等.虽然这些信息可以在游戏的官方网站的首页,开发博客,Twitter等发布,但是这些途径只能将消息传递给不到10%的玩家,而且时效性也不高
新闻发布的机制
这里需要特殊的机制,采用下面的方法可以在短时间内提高到达率
- 客户端程序更新时
如果设计要求每次程序启动时访问Web服务器确认是否有最新版,可以在这个过程中同时发送最新的消息,然后在更新时的画面或者更新处理画面中显示该消息
- 客户端程序启动时
在程序启动时访问Web服务器获取最新的消息,并将游戏开始按钮设为不可用,直到读完新的消息,以此确保消息确实被玩家阅读过
- 游戏中
游戏中玩家操作时,肯定会注视着游戏画面,在适当的时机显示消息,例如,打开邮件时,或者在商店买东西时
对玩家来说,重复着同样的消息是非常令人讨厌的,所以需要实现已读管理功能,避免同样的消息对同一个玩家多次显示.这样一来,即使消息比较多时也可以大大减少玩家的压力.
6.5 付费相关的辅助系统
6.5.1 付费认证 P2P MO C/S MMO
用途: 通用
问题: 不保存用户个人信息,外部系统的延迟,多重化,库封装
实现: 除了现有的外部系统的ID,其他信息都不保存
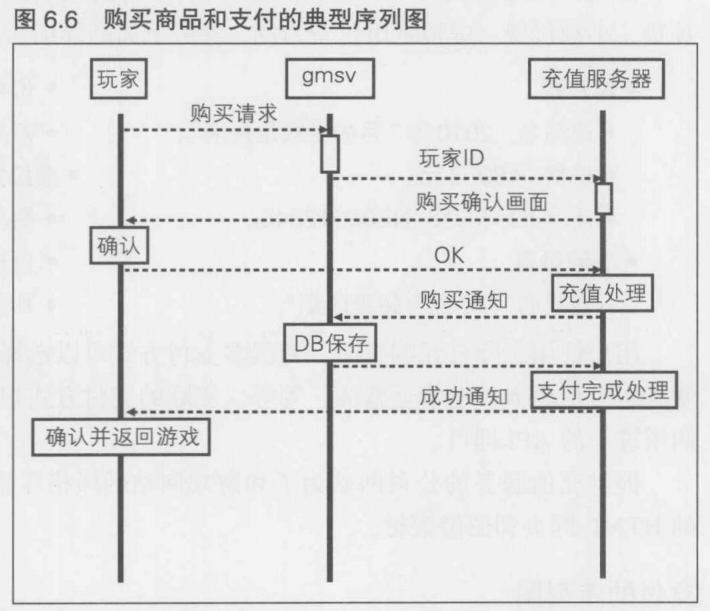
6.5.2 虚拟货币管理 P2P MO C/S MMO
用途: 通用
问题: 丢失的话会比较麻烦
实现: 尽量使用现有服务,自己开发的话要做好日志记录(Journaling),从最开始就决定好"定期结算"的方针
专栏 C/S MMO 游戏的收入
- 游戏软件销售
- 小额付费(付费道具)
- 网吧授权费
- 包月费
- 按时间计费
- 广告
6.6 其他辅助功能
6.6.1 游戏数据浏览/查询工具 P2P MO C/S MMO
游戏数据的保存状态
- 清晰地划分为不同的数据列保存
- BLOB形式
- 两种形式混用
6.6.2 敏感词过滤 P2P MO C/S MMO
敏感词过滤是指聊天,邮件或者角色名中出现不合适的词语或文字时,显示警告并删除的功能.比较典型的用途有防止电话号码泄露等.实现方式的判断条件如下所示
- 主数据保存在客户端还是服务器
- 关键词判断处理在客户端执行还是服务器端执行
其他和黑名单基本相同, 有所区别的地方是
- 不需要用户动态增加关键词
- 不想让用户看到敏感词列表(里面包含了开发者的名字或者公司名字等,有可能会被用于毁谤中伤等)
- 不需要实时更新数据(也不需要停止服务器)
这些都涉及到游戏发行公司的相关政策,应该按照相关规定决定实现的方式.如果是在服务器实现这个功能,应该按照与黑名单同样的负荷来考虑
6.7 本章小结
第7章 支持网络游戏运营的基础设施 架构,负荷测试和运营
7.1 基础设施架构的基础知识
7.1.1 C/S MMO 和 P2P MO的基础设施(概要)
7.1.2 基础设施架构需要进行的工作----从开发整体来看
7.1.3 基础设施的成本估算
- 初期费用
信息设备: 服务器,交换器,路由器等
软件: Red Hat操作系统等
其他: 机柜,电缆,电源等
服务: 服务器监控费用,数据中心使用费,域名费,电子签名等
- 后续费用
网络带宽费
电费
软件: 杀毒软件使用费等
服务: Red Hat的服务费,域名费等
- 保修费用
信息设备: 设备故障更换,保修等
7.1.4 成本的概念, 单位
7.1.5 网络游戏服务器在一定程度上可以接收的条件
7.1.6 硬件, 信息设备
- 服务器
- 存储设备
- 网络交换机
- 路由器/防火墙
7.1.7 软件
- 服务器操作系统
- 数据库管理系统
- 杀毒软件
- 虚拟化软件
7.1.8 数据中心相关的成本



7.1.9 服务费(数据中心以外)
服务器监控服务
域名使用费,电子签名服务费
7.1.10 网络带宽费
7.1.11 电费
7.2 开发者需要知道的基础设施架构技巧
7.2.1 服务规模的扩大/缩小----用户数和需要的基础设施规模
7.2.2 典型的环境
- 初始环境
- 数据中心
- 公有云服务
7.2.3 负荷曲线
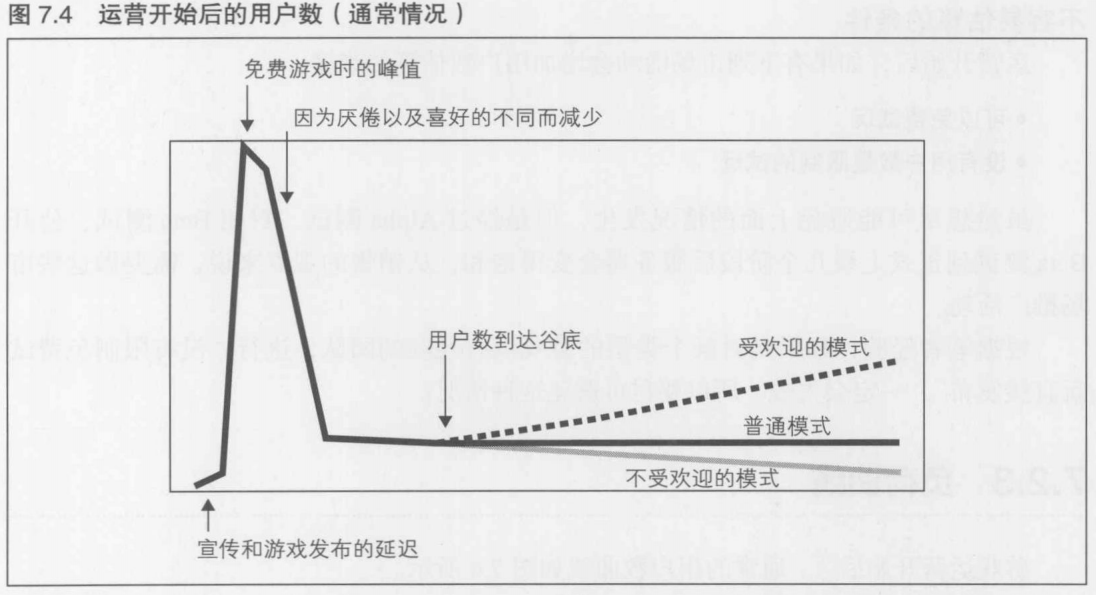
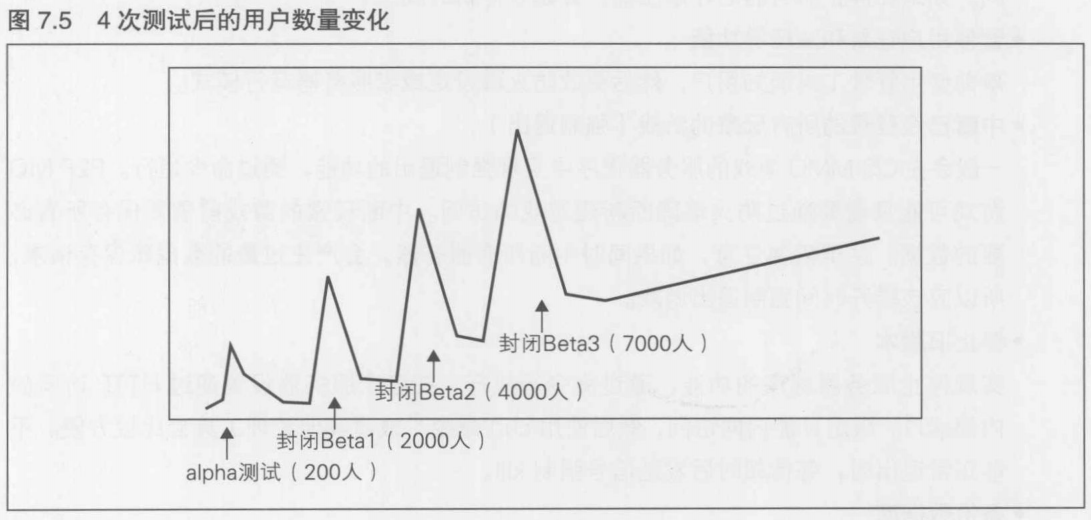
7.2.4 面向开发者的基础设施架构要点
7.2.5 服务器部署
- 服务器程序的测试
- 将测试完成的程序打包
- 上传打包后的程序到各个服务器并解压缩
- 暂停用户登录和注册功能
- 中断已经登录的所有玩家的游戏(强制退出)
- 停止旧版本
- 备份数据库
- 需要修正数据库时,运行相应的SQL批处理
- 确认数据库
- 启动新版本的服务器程序
- 新版本服务器程序的测试
- 开放用户登录
- 从服务器转移备份好的数据和日志文件
7.2.6 登台环境
7.2.7 服务器的监控, 生死监控
- 服务器操作系统监控
- MySQL等数据库操作系统监控
- 应用程序监控
- 用户行为的正常性监控
7.2.8 日志输出/管理
- 日志保留的策略
- 日志输出的方法
- 日志服务器
7.3 K Online, J Multiplayer游戏的基础设施架构
7.3.1 K Online 的基础设施
Alpha测试
封闭Beta测试
公开Beta测试
7.3.2 J Multiplayer 的基础设施
自己开发部分辅助系统
首先进行负荷测试,估算基础设施
同时在线数和注册用户数
预测玩家的游戏方式
根据测试结果修改设计
7.4 负荷测试
7.4.1 负荷测试的准备
7.4.2 K Online 在生产环境的负荷测试
7.4.3 负荷测试时使用的服务器监控命令
7.4.4 J Multiplayer在生产环境下的负荷测试
7.5 游戏上线
7.5.1 游戏上线前----从确认安全设定开始
7.5.2 游戏上线后----系统监控
7.5.3 服务器的组群化
7.5.4 故障发生时的应对
7.6 本章小结
第8章 网络游戏的开发体制 团队管理的挑战
8.1 游戏的策划内容和开发团队 网络游戏特有的挑战
8.1.1 游戏的策划内容是团队管理的关键
网络游戏的开发团队面对的挑战大致可以归纳为以下几点
- 游戏数据的持久化
- 游戏中玩家之间的关系
- 游戏结果的共享范围
- 聊天系统的内容
- 维护和升级的计划
- 代码的规模
8.1.2 游戏数据的持久化
运营刚开始的3个月最困难,运营可以持续5~10年
实际项目管理中的挑战
- 希望长期参与游戏项目的人是否也持有相关的技能
- 如何合理使用在初期开发结束后想马上参与新项目的技术人员
- 游戏开始运营后团队的休假计划如何调整
- 项目奖金该如何处置
8.1.3 游戏中玩家之间的关系
在游戏中,"玩家之间是什么关系"非常重要.游戏策划一般按照以下几种方式划分玩家之间的关系
- VS(对抗): 玩家之间可以互相攻击,破坏.还可以相互PK(Player Kill).例如对战类,即时战略类(RTS)游戏,将对手全部消灭或者使其投降才算获得胜利
- Compete(竞争): 以玩家之间互相竞争为基础的游戏,比如看谁先登上山顶,看谁速度更快的竞速游戏
- CO-OP(合作): 以玩家合作为基础的游戏.如果不合作就无法取得进展,不存在胜负
- Share(共享): 玩家之间没有直接的联系,但是可以共享少量数据.比如给好友送礼或者在玩家的游戏空间搞一些小破坏,FarmVille就属于这类游戏.这种游戏基本上单人也可以玩
- Share nothing(无关): 仅仅作为一个分类,但是多人游戏的玩家之间应该不会没有任何关系吧
8.1.4 游戏结果的共享范围
- 只展示给自己
- 可以逐个发送给别的玩家
- 互相关注的好友
- 展示给粉丝(关注自己的玩家)
- 工会,粉丝团中的玩家
- 游戏服务器的范围
- 不限定范围的全体玩家
8.1.5 聊天系统的内容
- 没有聊天
- 有固定句子
- 自由输入
8.1.6 维护和升级的计划
8.1.7 代码规模----如果需要迭代的代码过多就会遇到问题
- 编译时间
- 程序启动时间
- 测试的步骤数
- 服务器程序的启动步骤
- 数据验证
8.2 网络游戏开发团队的实际情况----和一般软件开发相同的地方
8.2.1 工作分配
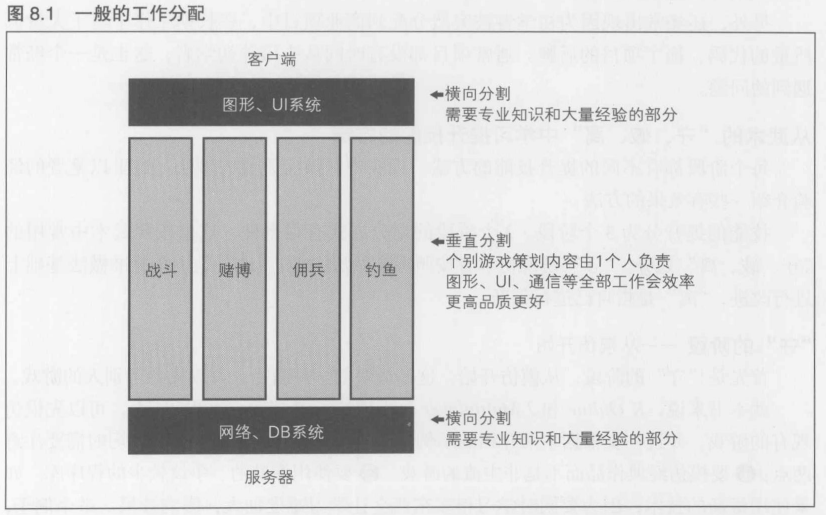
8.2.2 持续提升网络游戏程序员技能的方法
从武术的"守,破,离"中学习提升技能的方法
- "守"的阶段----从模仿开始
- "破"的阶段----研讨会,技术会议
- “离”的阶段----应该怎样进入工程师的最高级阶段
8.2.3 项目管理术---游戏开发和Scrum
8.2.4 开发环境的选择
8.2.5 项目的移交----理所当然的事情也需要仔细归纳总结
8.3 本章小结
专栏 网络游戏开发的成本
开发项目有常识性的日程安排和成本.不过日程安排和成本是不能划等号的,当然,同时参与项目的人越多,即使工期时间短,成本也会非常高
程序开发中增加人数并不会让工作效率呈线性增加,不过美术方面的工作可以通过增加人数来提高开发速度.因为美术工作可以按照"100个道具的图像"来量化规模,所以可以按照美工人数来分配
程序的开发成本
- C/S MMO
PC原生游戏: 40~100人月
Flash: 20~40人月
手机游戏: 20~40人月
- P2P MO
PC原生游戏: 15~30人月
Flash: 3~30人月
手机游戏: 2~20人月
Web社交游戏: 2~20人月
美术成本
- 大型MMORPG
3D: 20~400人月
2D像素: 30~300人月
- 简单的MMOG
3D: 10~100人月
2D像素: 20~100人月
- P2P MO
3D: 10~200人月
2D像素: 20~200人月
Web社交游戏: 1~10人月
运营成本
C/S MMO: 每月成本为初期项目每月开发成本的50%~100%
P2P MO: 每月成本为初期项目每月开发成本的5%~20%
Web社交游戏: 每月成本为初期项目每月开发成本的100%~200%
如果是AAA游戏,大概需要在上述成本上再加上一位数.开发工期大致如下
- C/S MMO
PC原生游戏: 1~3年
Flash: 半年~1年
手机游戏: 3个月~1年
- P2P MO
PC原生游戏: 半年~1年
Flash: 3个月~1年
手机游戏: 3个月~1年
Web社交游戏: 2~6个月


 浙公网安备 33010602011771号
浙公网安备 33010602011771号