利用angr符号执行去除ollvm虚假控制流
利用angr的SM(Simulation Managers)模拟管理器,通过调用SM的step()方法可以寻找到被混淆函数所有active状态的基本块(可达的基本块)。去除虚假控制流混淆的思路就是:先找到目标函数所有的基本块,然后将可达的基本块去除之后剩下的就是不可达的基本块,最后将不可达的基本块以及会跳转到不可达基本块的跳转指令进行nop即可去混淆。目标函数混淆之前的反编译代码如下:
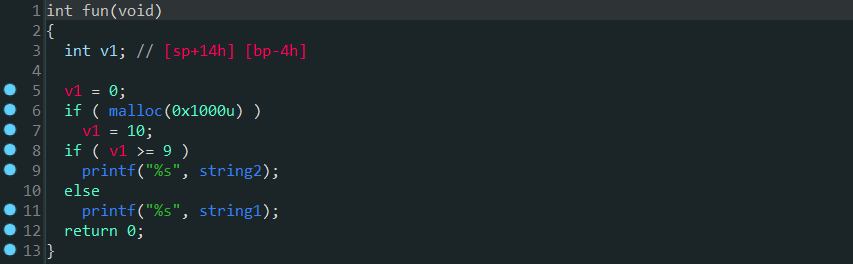
利用-mllvm -bcf -mllvm -bcf_loop=3 -mllvm -bcf_prob=40对其添加虚假控制流混淆后反编译代码如下:
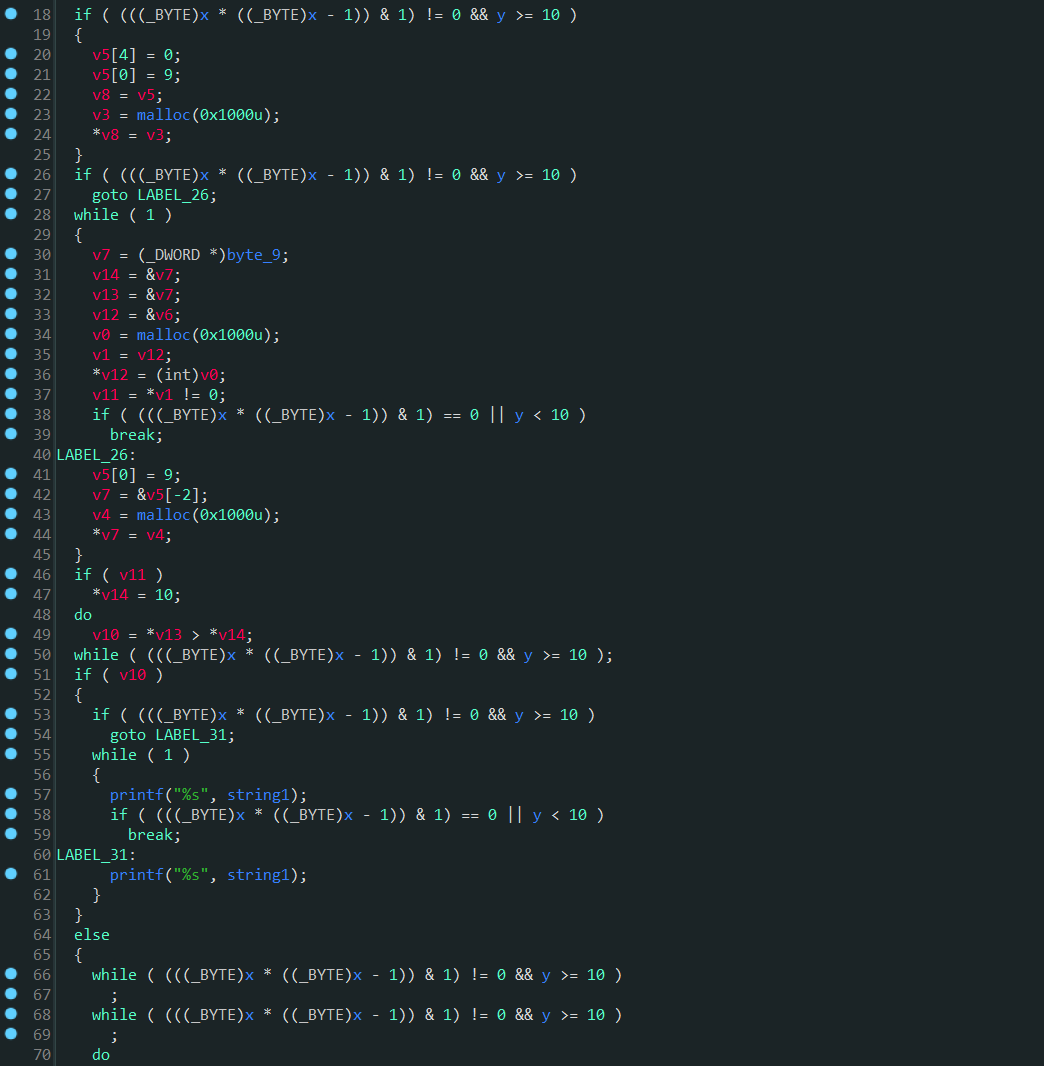
其对应的控制流程图如下,混淆后增加了很多的虚假块。

利用angr去除虚假控制流
找到所有的基本块
利用angr的接口函数proj.analyses.CFGFast,但是应用过程发现此函数好像存在一个暂未解决的bug,对于android平台arm/arm64的可执行文件此接口并不支持(对于linux平台的arm/arm64是支持的),会出现如下错误angr.errors.SimProcedureError: static_exits() is not implemented for (SimProcedure __libc_init),具体原因请参考链接https://github.com/angr/angr/issues/967。

因为我对angr还不是太熟悉无法解决上述问题,所以自己实现基本块的获取。如果函数只进行了虚假控制流混淆而未进行控制流平坦化的话,其基本块的寻找方法与包含控制流平坦化的基本块寻找方法略有差别,因为其基本块除了包含以跳转指令结尾的基本块之外还包含不以跳转指令结尾的基本块。(更新:问题已经解决,通过设置CFGFast的范围为指定函数可以解决上述错误)
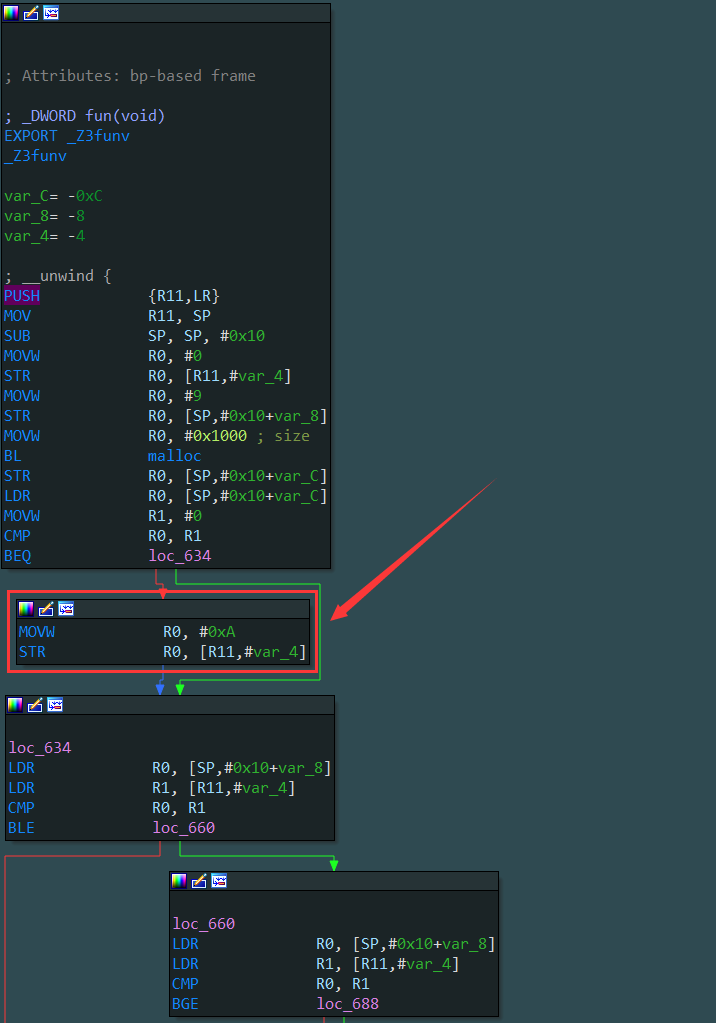
所以获取基本块的思路是先获取所有以跳转指令结尾的基本块,然后获取所有基本块中跳转指令跳转到的目标基本块,这样就可以获取到所有的基本块信息。
def find_block(file_data):
global dict_code_blocks
global md
#寻找并保存以跳转指令结尾的基本块
is_new_block = 1
for i in md.disasm(file_data[func_start_address : func_end_address], func_start_address):
if is_new_block:
current_start_address = i.address
is_new_block = 0
if(i.group(ARM_GRP_JUMP) or i.id == ARM_INS_POP):
#需要过滤外部函数调用指令
if i.operands[0].type == ARM_OP_IMM:
if (i.operands[0].value.imm < func_start_address) or \
(i.operands[0].value.imm > func_end_address):
continue
elif i.operands[0].type == ARM_OP_REG:
if i.id != ARM_INS_POP:
continue
is_new_block = 1
dict_code_blocks[current_start_address] = {'start_address': current_start_address, \
'end_address': i.address}
#寻找不以跳转指令结尾的基本块
dict_code_blocks_tmp = {}
for v in dict_code_blocks:
for i in md.disasm(file_data[dict_code_blocks[v]['start_address'] : dict_code_blocks[v]['end_address'] + 4], \
dict_code_blocks[v]['start_address']):
if i.group(ARM_GRP_JUMP):
if i.operands[0].type == ARM_OP_IMM:
if (i.operands[0].value.imm < func_start_address) or \
(i.operands[0].value.imm > func_end_address):
continue
elif i.operands[0].type == ARM_OP_REG:
continue
#如果跳转指令对应的块地址还不在已经获取的基本块列表中,就寻找跳转地址所在的块并将其分割成两个块
if i.operands[0].value.imm not in dict_code_blocks:
for k in dict_code_blocks:
if i.operands[0].value.imm > dict_code_blocks[k]['start_address'] and \
i.operands[0].value.imm < dict_code_blocks[k]['end_address']:
dict_code_blocks_tmp[i.operands[0].value.imm] = {'start_address': i.operands[0].value.imm ,\
'end_address' : dict_code_blocks[k]['end_address'] ,\
'queue_start_address' : k ,\
'queue_end' : i.operands[0].value.imm - 4}
#保存不以跳转指令结尾的基本块
for i in dict_code_blocks_tmp:
dict_code_blocks[dict_code_blocks_tmp[i]['queue_start_address']]['end_address'] = dict_code_blocks_tmp[i]['queue_end']
dict_code_blocks[dict_code_blocks_tmp[i]['start_address']] = {'start_address' : dict_code_blocks_tmp[i]['start_address'] ,\
'end_address' : dict_code_blocks_tmp[i]['end_address']}
符号执行获取所有可达基本块
通过angr的SM模拟管理器提供的step()方法从函数的入口开始符号执行,step每一次执行都会寻找SM包含的所有active状态的基本块可能到达的下一个基本块,然后SM将包含下一个active状态的基本块,之前active状态的基本块将被移除。当SM不再包含active状态的基本块时证明此函数不再有可达的基本块。
while len(simgr.active):
print(simgr.active)
for active in simgr.active:
# delete execd block
blocks.discard(active.addr - proj.loader.main_object.mapped_base)
#对每一个active块进行执行
simgr.step()
将step每一次执行后SM所包含的active状态的基本块(可达的基本块)从基本块列表中移除后,即可获取到此函数所有不可达的基本块。
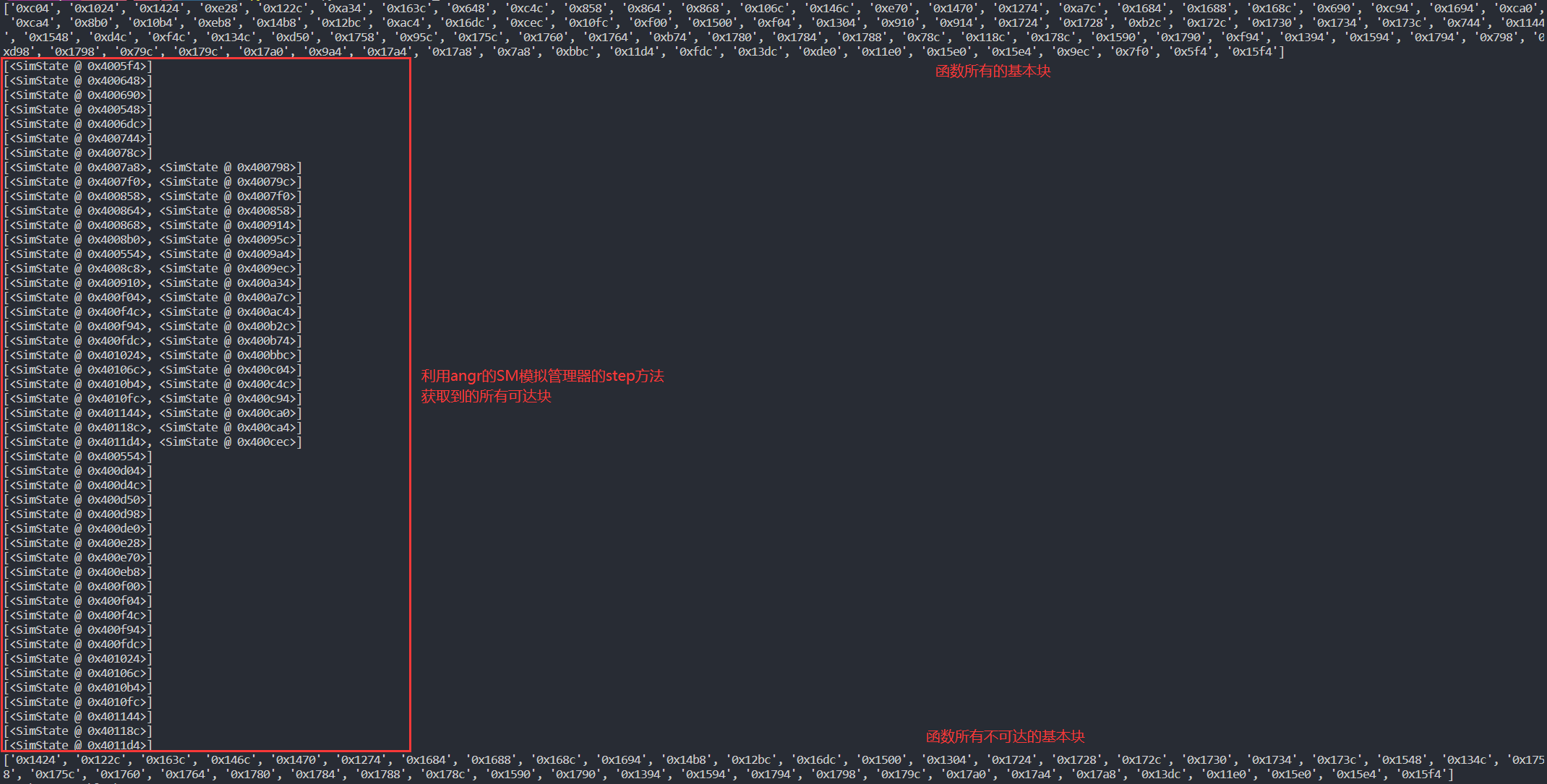
nop所有不可达基本块
nop_op = 0xE320F000
for block_addr in blocks:
size = dict_code_blocks[block_addr]['end_address'] - dict_code_blocks[block_addr]['start_address'] + 4
binfile[block_addr: block_addr + size] = nop_op.to_bytes(4, 'little') * int(size / 4)
nop所有跳转到不可达基本块的跳转指令
因为不可达块永远不会执行,所以所有会跳转到不可达块的跳转指令都需要进行nop
for block_addr in dict_code_blocks:
for ins in md.disasm(file_data[dict_code_blocks[block_addr]['start_address'] : dict_code_blocks[block_addr]['end_address'] + 4], \
dict_code_blocks[block_addr]['start_address']):
if (ins.group(ARM_GRP_JUMP)):
if ins.operands[0].type == ARM_OP_IMM:
if (ins.operands[0].value.imm < func_start_address) or \
(ins.operands[0].value.imm > func_end_address):
continue
elif ins.operands[0].type == ARM_OP_REG:
continue
# 如果有跳转指令会跳转到不可达块就进行patch
if ins.operands[0].value.imm in blocks:
binfile[ins.address: ins.address + ins.size] = nop_op.to_bytes(4, 'little') * int(ins.size / 4)
break
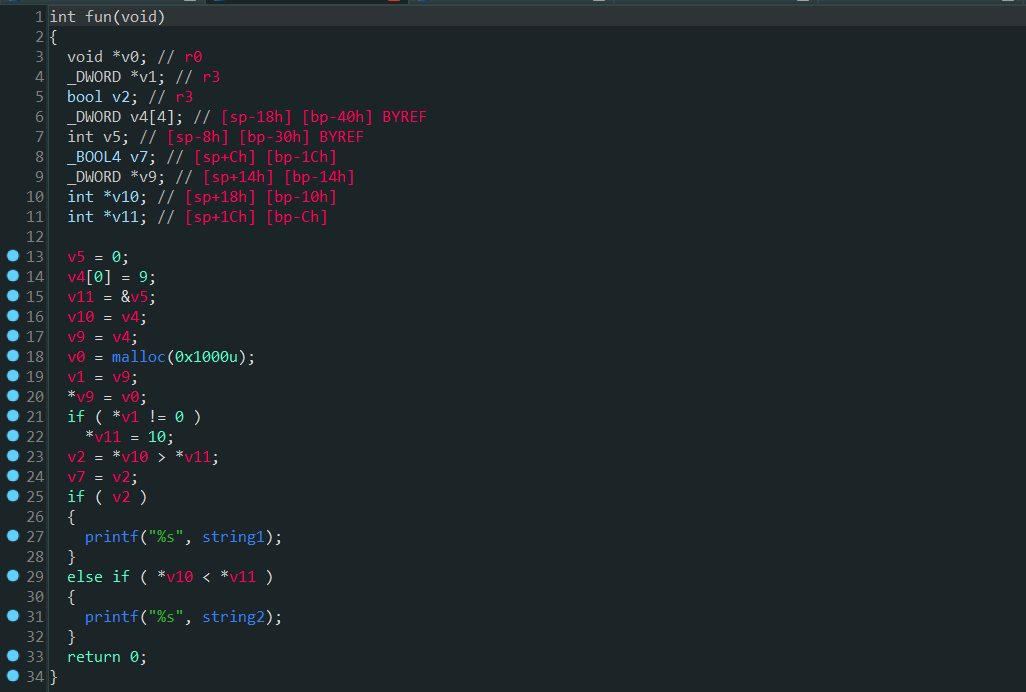
最后去混淆的反编译代码如下,可以看到程序的基本逻辑已经被还原了。
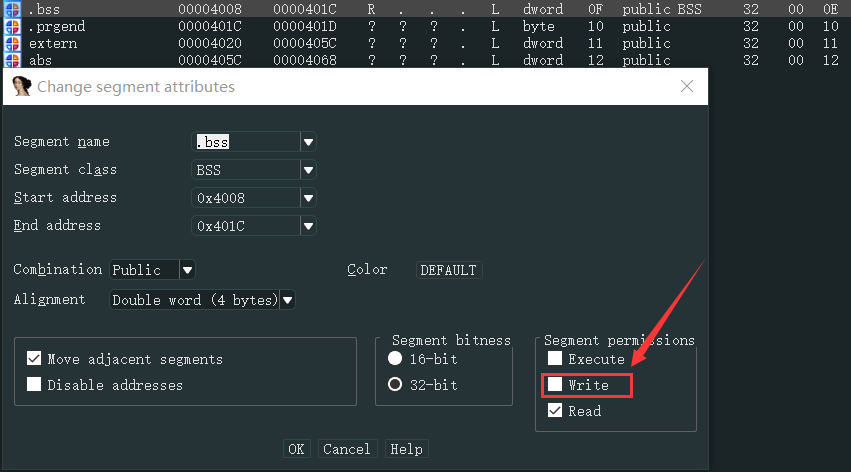
删除不透明谓词去除虚假控制流
因为控制流平坦化本质是通过不透明谓词构造恒成立的条件,ida无法识别确定这些不透明谓词的结果所以无法对程序进行优化。如果让ida能够确定不透明谓词的结果,那么ida就会自动对程序进行优化。将不透明谓词表达式对应的x,y变量所在的段设置为只读,并将其值设置为0。
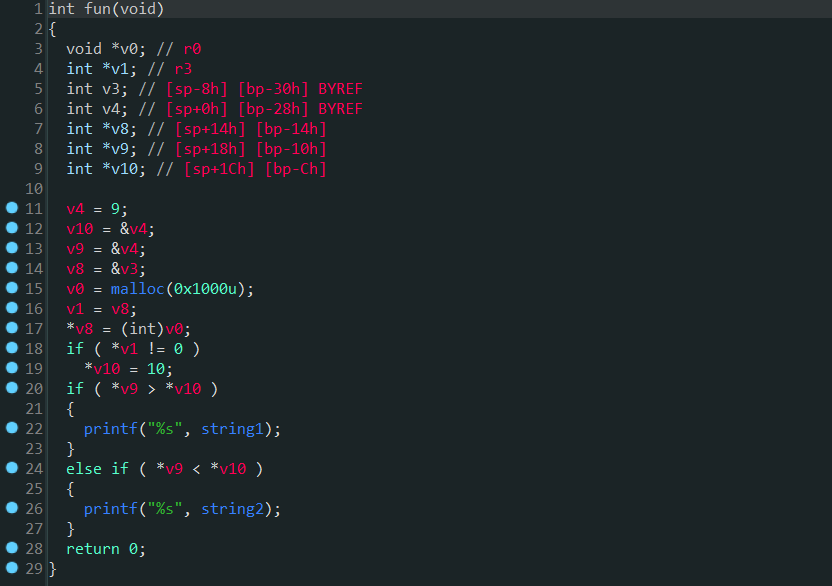
然后再次F5后ida就可以将程序进行优化,优化后的结果如下,与之前通过angr符号执行去混淆的反编译结果基本相同。
参考:https://bbs.kanxue.com/thread-266005.htm
https://blog.csdn.net/qq_45323960/article/details/124440184
https://github.com/angr/angr/issues/967
https://blog.csdn.net/jitaliangliang111/article/details/104085410

 浙公网安备 33010602011771号
浙公网安备 33010602011771号