利用unicorn模拟执行去除ollvm平坦化
去混淆思路
- 先找到函数中所有的基本块
- 确定状态变量是保存在宿主寄存器中还是栈中(局部变量)
- 观察判断控制块的特点,将所有控制块剔除。剔除之后基本块中还包含真实块(如果不存在虚假控制流)
- 确定各个真实块的执行路径,即一个真实块能跳转到哪几个块(1/2个块),通常通过
unicorn模拟执行或者angr符号执行寻找路径 - 对于只包含一个路径的真实块直接在其代码块末尾patch,跳转到对应的真实块
- 对于包含两个路径的真实块,平坦化是通过在此真实块的末尾根据跳转条件更改状态变量的值来实现跳转到不同的真实块中,我们需要将其通过更改状态变量的跳转到不同真实块的方式修改为通过条件跳转指令的方式实现(bge,ble...)。我们需要根据实际的修改状态变量的指令来使用对应的跳转指令例如:其通过
movne修改状态变量的值,那么我们就可以修改为bne指令.
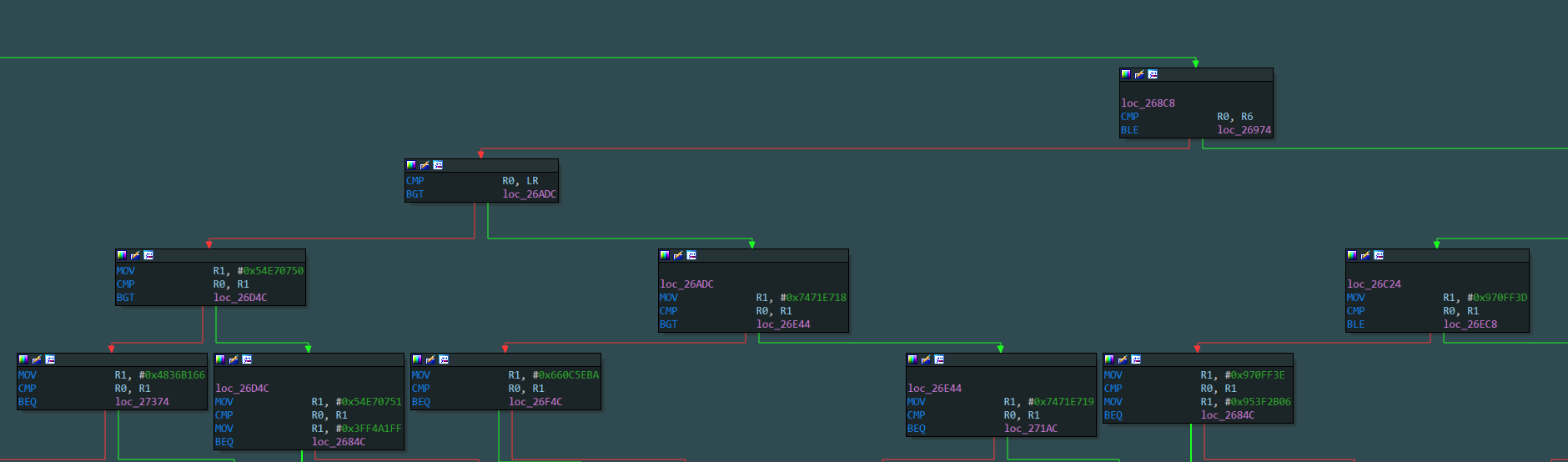
目标函数被混淆后的程序流程图如下,可以看到其进行的平坦化处理。

找到所有基本块
通过反汇编引擎capstone对目标函数的指令进行解析,
控制流平坦化后的基本块的划分是通过跳转指令ARM_GRP_JUMP以及返回指令ARM_INS_POP分割的。并且需要过滤外部函数调用指令,如果操作数在目标函数地址范围外或者操作数是一个寄存器则说明此跳转指令是一个外部函数调用指令。(因为有时候目标程序的代码和数据会冗杂在一起,而capstone是顺序执行的反汇编引擎,遇见这种情况就会反汇编失败,所以其实最好的方法是利用angr获取函数的cfg)
dict_code_block_item = {}
#寻找所有的基本块,解析并保存基本块的基本信息
is_new_block = 1
assembly_string = ''
for i in md.disasm(file_data[func_start_address : func_end_address], func_start_address):
assembly_string += "0x%x:%s%s\n" %(i.address, i.mnemonic, i.op_str)
if is_new_block:
dict_code_block_item = {}
dict_code_block_item['start_address'] = i.address
is_new_block = 0
if(i.group(ARM_GRP_JUMP) or i.id == ARM_INS_POP):
#需要过滤外部函数调用指令,这些跳转指令并不能作为基本块划分的标准。
if i.operands[0].type == ARM_OP_IMM:
if (i.operands[0].value.imm < func_start_address) or (i.operands[0].value.imm > func_end_address):
continue
elif i.operands[0].type == ARM_OP_REG:
if i.id != ARM_INS_POP:
continue
#保存此代码块的信息
dict_code_block_item['end_address'] = i.address
dict_code_block_item['assembly_string'] = assembly_string
dict_code_blocks[dict_code_block_item['start_address']] = dict_code_block_item
print(dict_code_block_item['assembly_string'])
#解析下一个代码块
is_new_block = 1
assembly_string = ''
确定状态变量
因为后面通过模拟执行引擎寻找路径时需要主动控制状态变量的值,所以需要先找到状态变量。通过分析主分发器的代码可以确定状态变量是保存在寄存器中还是栈中(局部变量),因为每次状态变量被更改并保存在某个宿主寄存器或者栈中之后都会跳转到主分发器中继续进行路径寻找,所以很明显此函数的状态变量保存在了宿主寄存器r1。
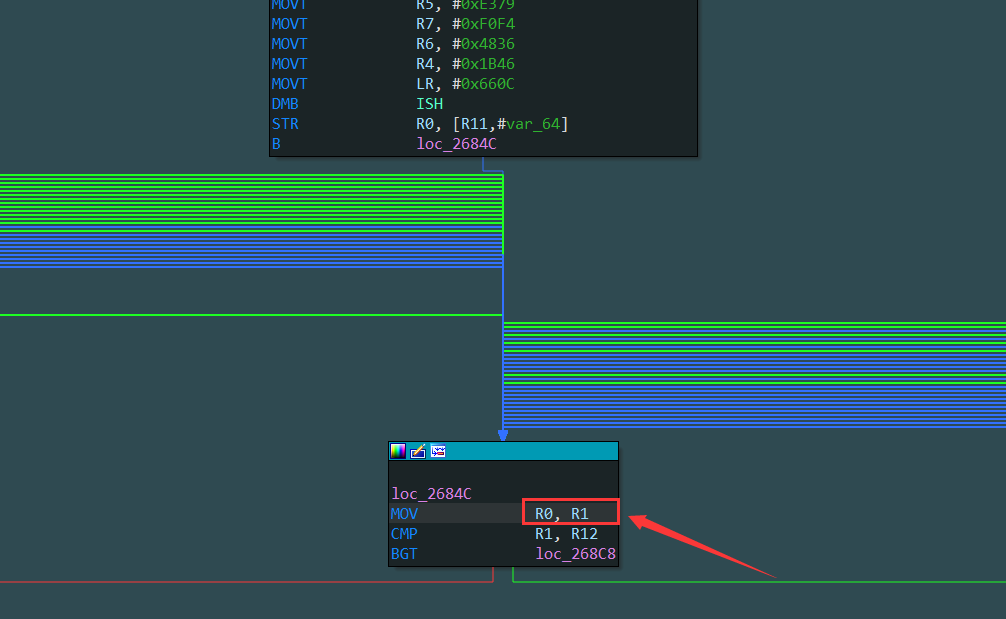
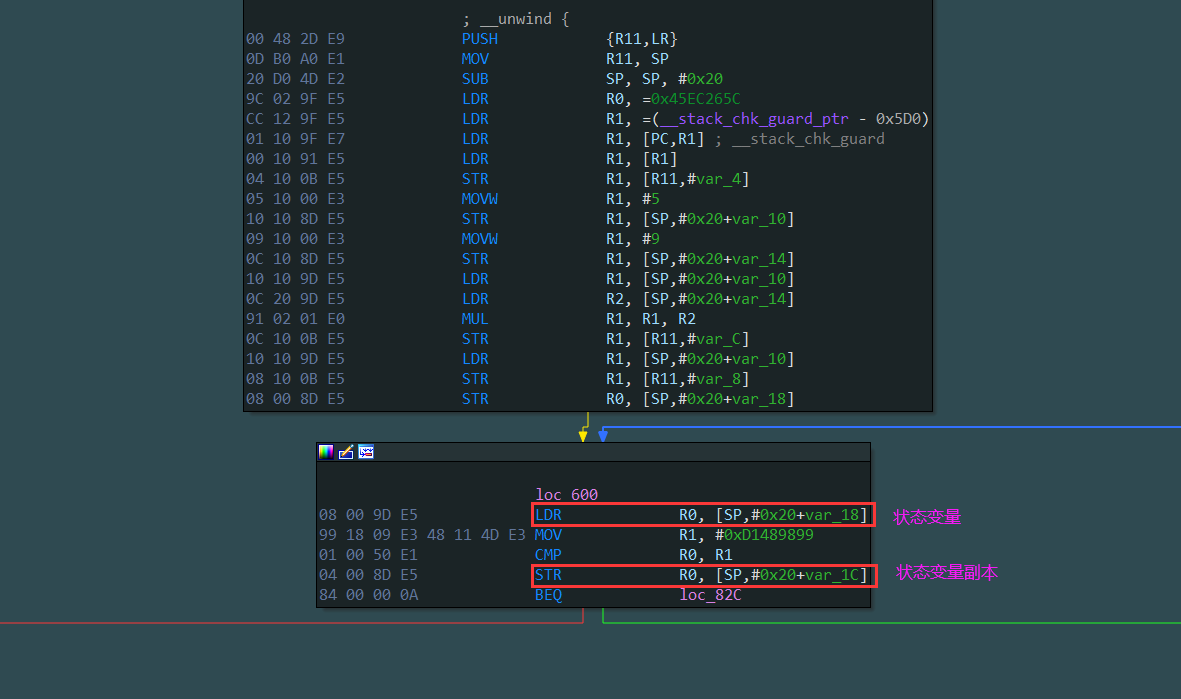
有的则保存在栈中,例如下面这个被混淆的函数就将状态变量保存在了栈中(局部变量)[sp, 8],并且其还包含了一个副本也保存在栈中(局部变量)[sp, 4]
去除所有控制块
因为控制块的目的是为了通过状态变量索引路径,本身和原程序逻辑并没有任何关系,所以需要通过其特征对其进行去除。
- 如果状态变量保存在寄存器中则其控制块特点是:不包含pop指令,不包含外部函数调用指令,不包含任何内存操作。
- 如果状态变量保存在栈中则其控制块特点是:不包含pop指令,不包含外部函数调用指令,不包含任何除了访问状态变量和其副本的内存操作。
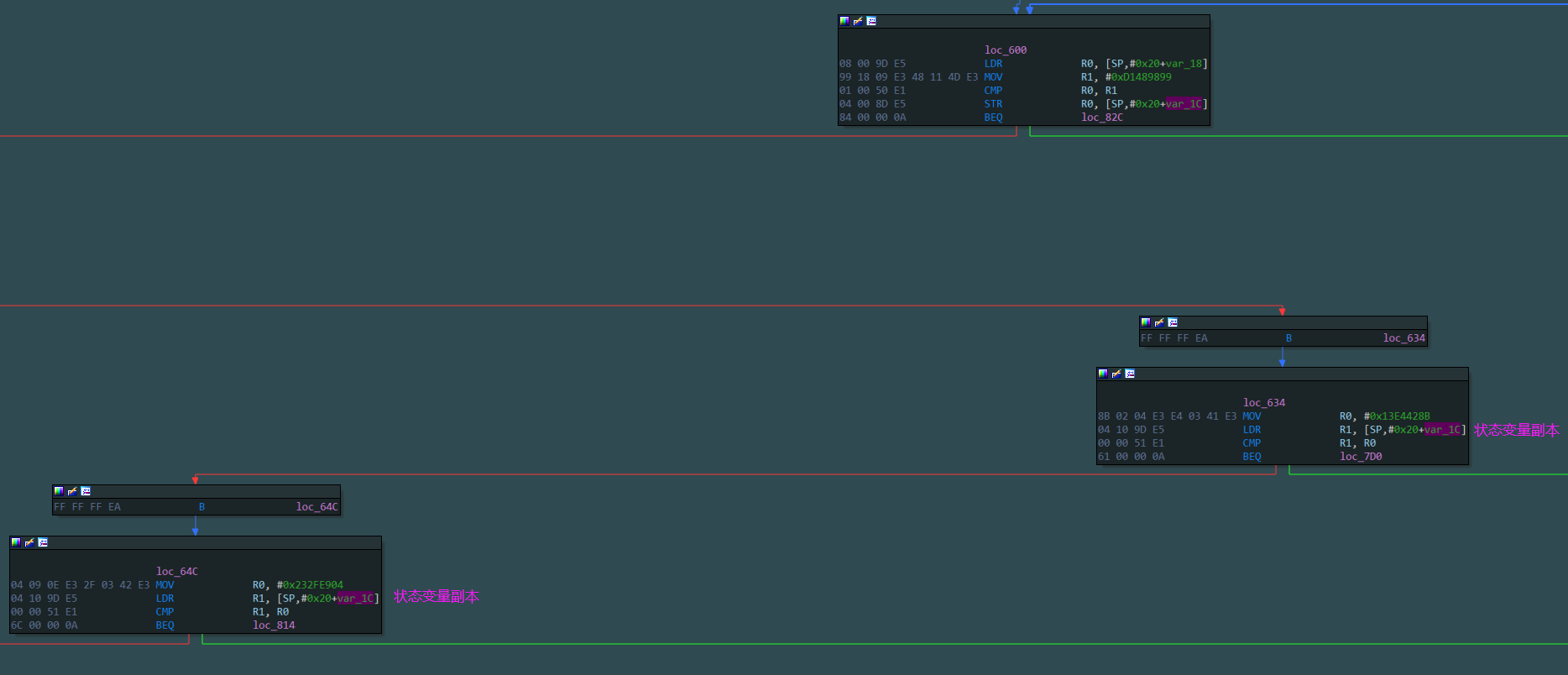
根据这些特点就可以将所有的控制块过滤,剩下的基本块包含真实块。(还有的情况是控制常量存放在代码段,所以控制块会访问内存获取控制常量的值)
#过滤出所有的真实块
#每一种ollvm混淆的控制块特征可能不一样,需要看具体情况分析特征
for i in dict_code_blocks:
flag_filter = False
insns = dict_code_blocks[i]['assembly_string'].split('\n')
for ins in insns:
#真实块一般会包含内存操作,pop指令或者bl(x)外部函数调用指令
if (-1 != ins.find('[') and -1 == ins.find('[sp, #' + str(status_mem[0]) + ']') \
and -1 == ins.find('[sp, #' + str(status_mem[1]) + ']')) or \
(-1 != ins.find('pop') or \
((-1 != ins.find('bl') and -1 != ins.find('#0x') and \
int(ins[ins.find('#0x') + 3: len(ins)], 16) < func_start_address and \
int(ins[ins.find('#0x') + 3: len(ins)], 16) > func_end_address))):
flag_filter = True
break
#将过滤出的真实块的起始地址保存
if flag_filter:
list_real_blocks.append(dict_code_blocks[i]['start_address'])
利用unicorn寻找真实块的路径
判断基本块存在几条路径
目标混淆函数的状态变量宿主寄存器为r1,所以一个真实块如果存在带条件后缀的movxx r1指令,并且偏移大于mov r1指令的偏移则证明此真实块可能存在两条路径,否则只存在一条路径。
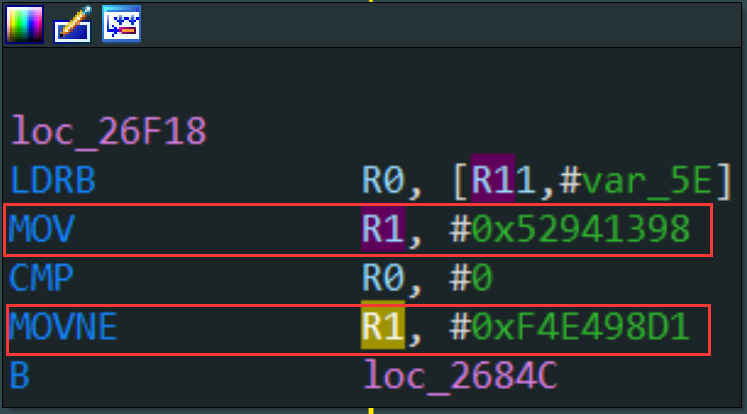
判断带条件后缀的movxx r1指令偏移大于mov r1指令的偏移,如果大于就说明此基本块可能会有两条路径。对于有两条路径的真实块就需要分两次去寻找两条路径下对应的真实块,而对于没有两条路径的真实块就直接寻找一次路径即可。
# 通过判断(mov 状态变量宿主寄存器,状态变量)和(movxx 状态变量宿主寄存器,状态变量)
# 这两种指令在当前代码块的出现的先后顺序判断是否有可能存在两个路径
offset = 0
mov_offset = 0
movxx_offset = 0
for i in current_assembly_code:
offset = offset + 1
if (i.find('movweq' + status_regs_string) != -1) or \
(i.find('movteq' + status_regs_string) != -1) or \
(i.find('moveq' + status_regs_string) != -1) or \
.........
(i.find('movwne' + status_regs_string) != -1) or \
(i.find('movtne' + status_regs_string) != -1) or \
(i.find('movne' + status_regs_string) != -1) :
movxx_offset = offset
elif(i.find('movw' + status_regs_string) != -1) or \
(i.find('movt' + status_regs_string) != -1) or \
(i.find('mov' + status_regs_string) != -1):
mov_offset = offset
#如果存在movxx指令,并且movxx指令的位置大于mov指令的位置则证明可能存在两种路径
if(movxx_offset != 0) and (movxx_offset > mov_offset):
#寻找路径1
is_find_two_path = True
set_context(reg_context)
path1_pc = find_path(pc, 1)
if path1_pc != None:
exec_queue.append((path1_pc, get_context()))
dict_all_path[pc].append(path1_pc)
#寻找路径2
is_find_two_path = True
set_context(reg_context)
path2_pc = find_path(pc, 2)
if (path2_pc != None) and (path2_pc != path1_pc):
exec_queue.append((path2_pc, get_context()))
dict_all_path[pc].append(path2_pc)
else:
#只需要寻找一次路径
is_find_two_path = False
path_pc = find_path(pc)
dict_all_path[pc].append(path_pc)
if path_pc != None:
exec_queue.append((path_pc, get_context()))
模拟执行hook
在利用unicorn进行模拟执行的时候设置hook回调函数,每次指令待执行时都会先调用此回调函数
pass无关代码
在利用unicorn模拟执行代码寻找路径的时候只关心真实块能够寻找到的路径,如果当前待执行指令是无关的指令可以直接pass跳过避免产生错误。例如外部函数跳转指令,不在自己映射范围内的内存访问指令。
#对bl带链接跳转指令进行判断,如果跳转超过范围或者通过寄存器间接跳转则pass不执行
if -1 != ins.mnemonic.find('bl'):
#如果操作数是立即数则计算器跳转范围,超过函数范围pass不执行
if ins.operands[0].type == ARM_OP_IMM:
if (ins.operands[0].value.imm < func_start_address) or (ins.operands[0].value.imm > func_end_address):
flag_pass = True
elif ins.operands[0].type == ARM_OP_REG:
flag_pass = True
#对于不在自己映射范围的内存操作,直接pass不执行
elif ins.op_str.find('[') != -1:
if ins.op_str.find('[sp') == -1:
flag_pass = True
for op in ins.operands:
if op.type == ARM_OP_MEM:
addr = 0
if op.value.mem.base != 0:
addr += mu.reg_read(reg_ctou(ins.reg_name(op.value.mem.base)))
elif op.value.index != 0:
addr += mu.reg_read(reg_ctou(ins.reg_name(op.value.mem.index)))
elif op.value.disp != 0:
addr += op.value.disp
if (addr >=0 and addr <= 4 * 1024 * 1024) or (addr >= 0x80000000 and addr <= 0x80000000 + (4 * 1024 * 128)):
flag_pass = False #如果是我们自己的映射范围内就不pass
获取待变更状态变量的值
如果当前待执行指令为movxx带条件后缀的指令并且第一个操作数为状态变量宿主寄存器r1,那么就获取第二个操作数的值,此值就是状态变量待变更的值。并且需要pass这条修改状态变量的指令,后面我们自己主动控制状态变量的值
if (ins.mnemonic == 'movweq' or \
ins.mnemonic == 'movteq' or \
ins.mnemonic == 'moveq' or \
........
ins.mnemonic == 'movwne' or \
ins.mnemonic == 'movtne' or \
ins.mnemonic == 'movne'):
if is_find_two_path == True:
#如果第一个操作数是状态变量宿主寄存器
if ins.operands[0].type == ARM_OP_REG and ins.operands[0].value.reg == status_regs:
#对于控制状态变量的mov指令,直接pass,我们主动控制状态变量的值
#先获取控制变量的值
flag_pass = True
#对于包含w,t的mov指令而言,其对应的第二个操作数就是立即数
if ins.mnemonic.find('w') != -1:
if ins.operands[1].type == ARM_OP_IMM:
status_num = ins.operands[1].value.imm
elif ins.mnemonic.find('t') != -1:
if ins.operands[1].type == ARM_OP_IMM:
status_num = status_num + (ins.operands[1].value.imm << 16)
#对于不包含w, t的mov指令而言,其对应的第二个操作数可能是立即数,或者是寄存器
else:
if ins.operands[1].type == ARM_OP_IMM:
status_num = ins.operands[1].value.imm
elif ins.operands[1].type == ARM_OP_REG:
status_num = uc.reg_read(ins.operands[1].value.reg)
主动控制状态变量的值
因为所有的真实块最后都会执行b指令跳转到预处理器,或者主分发器中。在这之前状态变量的值可能会根据程序原有的条件判断进行修改,上面已经将修改状态变量的指令pass不执行了,所以我们需要自己主动控制状态变量的值进而去寻找两条目标路径。当寻找第一条路径时不对状态变量的值进行修改,当寻找第二条指令的时候强制对状态变量的值进行修改。
# 所有的真实块最后都会执行b指令跳转到预处理器,获取主分发器中
if ins.mnemonic == 'b':
if is_find_two_path == True:
#如果是路径1
if branch_control == 1:
print('first')
#如果是路径2
elif branch_control == 2:
#如果状态变量保存在栈中
if status_mem[0] != 0:
uc.mem_write(uc.reg_read(UC_ARM_REG_SP) + status_mem[0], status_num.to_bytes(4, 'little'))
#如果状态变量保存在寄存器中
else:
uc.reg_write(status_regs, status_num)
is_find_two_path = False
判断是否寻找到新路径
通过判断当前待指令的地址是否等于之前过滤出来的所有真实块的起始地址中的任意一个,如果是就说明找到了新路径,暂停模拟执行并返回。
#如果待执行的指令是一个真实块的首地址则说明找到了新路径 且不是一次新的模拟执行过程
if address in list_real_blocks and flag_new_exec != True:
is_find_path_success = True
path_address = address
uc.emu_stop()
return
patch程序重建控制流
- 对于不包含条件判断的真实块(只有一条路径),直接在真实块尾部构建b指令跳转到对应的唯一路径的真实块
- 对于包含了条件判断的真实块(包含两条路径),利用跳转指令跳转到第一条路径,然后利用b指令跳转到第二条路径。需要注意条件跳转指令的选择,要看其在修改状态变量对应的条件判断指令来选择对应的跳转指令,例如在修改状态变量时使用
moveq那么就需要patchbeq指令。
def patch():
global dict_all_path
global dict_code_blocks
global file_data
for k in dict_all_path:
if dict_all_path[k] == [None]: continue
patch_offset = 0
#被patch的这些块都属于控制块
for i in dict_code_blocks:
if dict_code_blocks[i]['start_address'] == k:
dict_code_block_item = dict_code_blocks[i]
insns = dict_code_block_item['assembly_string'].split('\n')
#如果此代码块有分支
if len(dict_all_path[k]) == 2:
branch1 = dict_all_path[k][0]
branch2 = dict_all_path[k][1]
patch_offset = dict_code_blocks[i]['end_address'] - 4
print('patch_offset: %x' % patch_offset)
for ins in insns:
if ins.find('eq' + status_regs_string) != -1:
file_data = file_data[:patch_offset] + \
bytes(_ks_assemble(("beq #0x%x" % branch2),patch_offset)) + \
bytes(_ks_assemble(("b #0x%x" % branch1),patch_offset+ 4)) + \
file_data[patch_offset+8:]
elif ins.find('ne' + status_regs_string) != -1:
file_data = file_data[:patch_offset] + \
bytes(_ks_assemble(("bne #0x%x" % branch2),patch_offset)) + \
bytes(_ks_assemble(("b #0x%x" % branch1),patch_offset+ 4)) + \
file_data[patch_offset+8:]
elif ins.find('cs' + status_regs_string) != -1:
file_data = file_data[:patch_offset] + \
bytes(_ks_assemble(("bcs #0x%x" % branch2),patch_offset)) + \
bytes(_ks_assemble(("b #0x%x" % branch1),patch_offset+ 4)) + \
file_data[patch_offset+8:]
........
#如果此代码块无分支
elif len(dict_all_path[k]) == 1:
branch = dict_all_path[k][0]
patch_offset = dict_code_blocks[i]['end_address']
print('patch_offset: %x' % patch_offset)
file_data = file_data[:patch_offset] + \
bytes(_ks_assemble(("b #0x%x" % branch),patch_offset)) + \
file_data[patch_offset+4:]
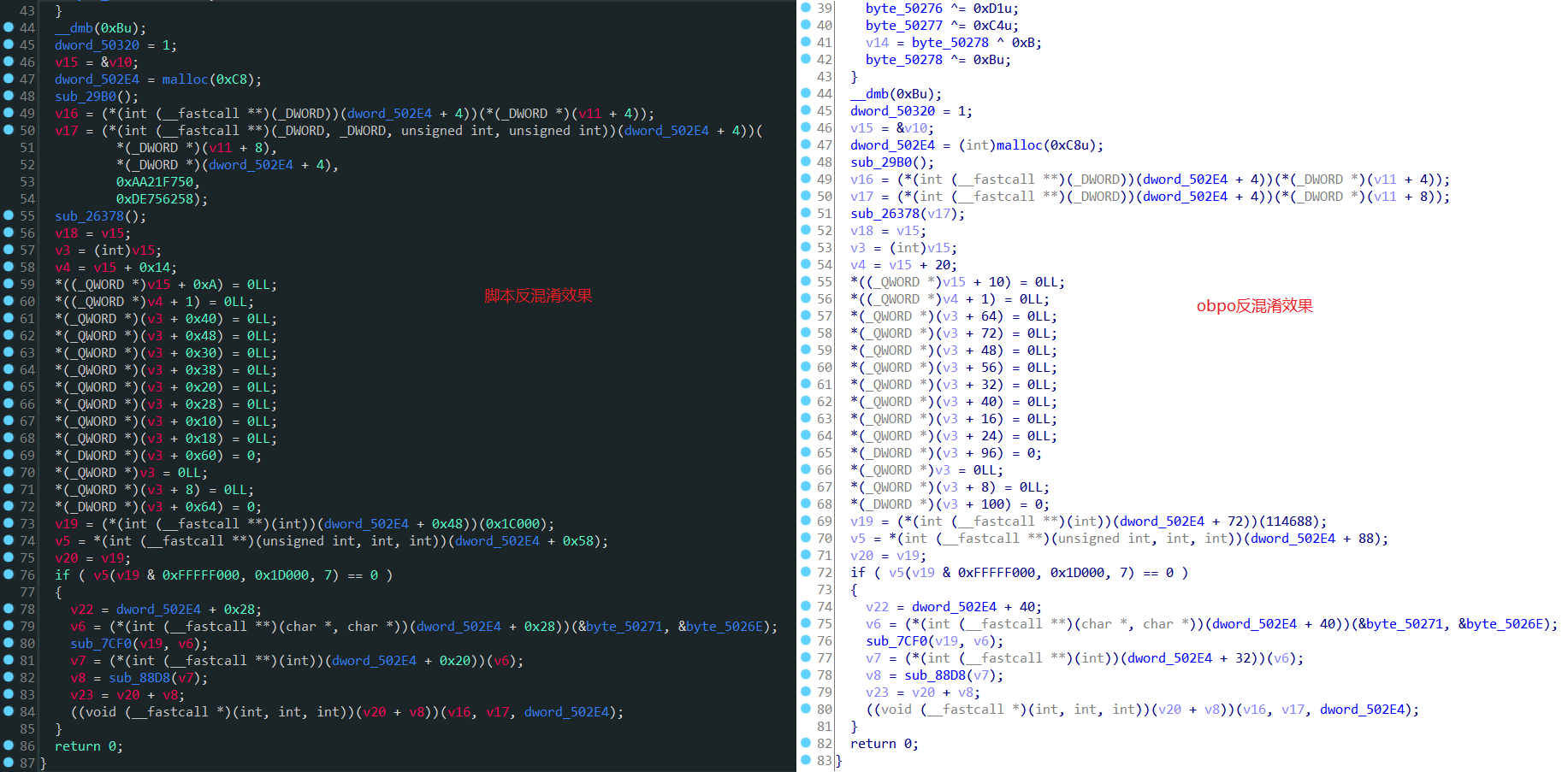
去混淆的效果
去混淆后的控制流程图

与ollvm反混淆插件obpo的去混淆结果对比基本一致。
以上均为个人研究观点,仅供参考。
参考链接:
https://bbs.pediy.com/thread-252321.htm
https://github.com/obpo-project/obpo-plugin

 浙公网安备 33010602011771号
浙公网安备 33010602011771号