初识OLLVM
编译器
一般编译器分为前端,中间优化和后端三部分。前端进行语法分析,中间进行优化后由后端编译成对应平台(arm,x86)的汇编代码(机器码)。现在主流的编译器有linux平台下的gcc 和 llvm-clang,以及windows平台下的msvc编译器。

LLVM
gcc编译器虽然强大但是有一个缺点就是因为其相当于一个完整的可执行文件,编译器的前端,中间优化和后端中间的耦合度比较高,所以要想增加一个前端用来支持一种新的语言,或者增加一个后端来生成一种新平台的机器码都需要做很大的改动很不方便。于是就有了LLVM的出现,LLVM是一个编译器框架,和传统的编译器一样也分为前端,中间优化和后端三部分。但是其利用与平台无关的中间语言IR来实现前端,中间优化和后端的分离,这样如果编译器需要新增加一种语言只需要增加一个前端语法解析器即可。例如Clang就是基于LLVM架构的能够支持C/C++/Objective-C语言的编译器前端。
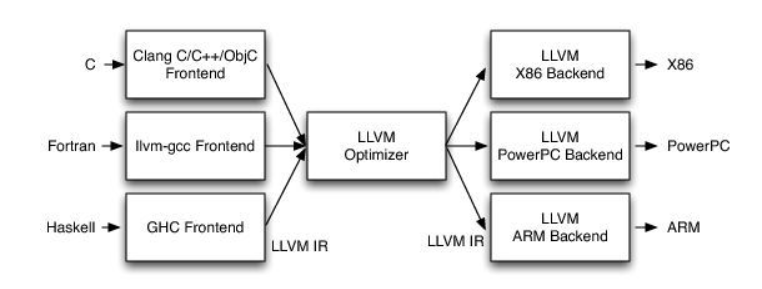
LLVM编译过程
llvm编译过程大致分为 预处理-->语法分析-->生成IR代码-->opt将IR代码优化-->生成汇编代码(x86, arm)-->汇编器进行汇编生成目标文件,之后就是链接器链接各个目标文件并生成可执行文件的过程。(所以汇编的过程实际包含在编译过程中)
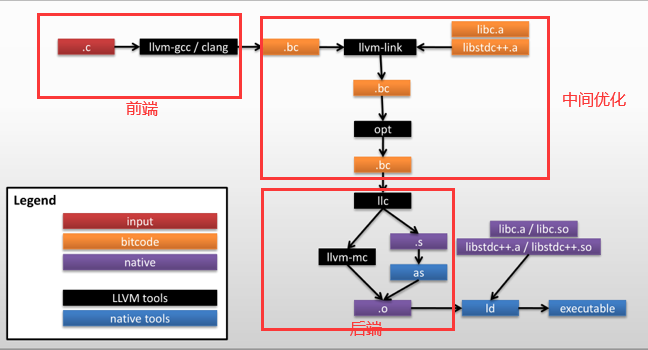
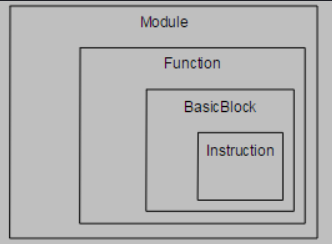
LLVM IR代码文件的格式为ll/bc,ll是一种人类可以阅读的格式,而bc是一种bitcode的格式(二进制文件)。还有一种格式就是内存中的格式,LLVM在内存中会将IR分为Module,function,basicblock,Instruction四种表达形式。
- Module就是一个c/cpp文件
- function就是一个函数
- basicblock就是控制流的一个基本块
- Instruction就是一条具体的指令
LLVM中间优化过程
llvm通过将前端代码(c/cpp等)生成与平台无关的llvm IR中间代码,然后通过多个pass(就是一个一个的类,每一个类对应一种功能)来对IR代码进行优化。

OLLVM
OLLVM是一种通过利用LLVM会生成IR中间代码并通过pass优化代码的特点,通过增加自己的pass来对代码进行优化,但是这种优化不是为了让代码更简洁相反是让代码更复杂,达到混淆的目的。一般支持三种主要的混淆手段:控制流平坦化,虚假执行流和替换指令。
OLLVM之控制流平坦化
ollvm三种混淆手段中控制流平坦化混淆效果最佳。其原理是将函数分为若干个代码基本块,这些基本块是以跳转指令(函数调用指令不算在内)结尾的,原本函数逻辑是经过条件判断后直接跳转到对应的基本块中,经过平坦化之后经过条件判断后修改状态变量的值,然后利用switch结构通过判断状态变量的值来跳转到对应的基本块。
- 序言:通常是一个函数开头的部分
- 主分发器/子分发器:通过状态变量寻找对应的真实块,也称为控制块
- 预处理器:会统一跳转回主分发器中(也有很多不经过预处理器直接跳转回主分发器中)
- 真实块:包含函数实际的代码逻辑的基本快
- 虚假块:永远都不会执行到的基本块(与不透明谓词有关)
- return块:函数结束代码块
去除ollvm控制流平坦化
根据ollvm控制流平坦化混淆的原理可得去混淆的步骤如下。
- 先找到函数中所有的基本块
- 确定状态变量是保存在宿主寄存器中还是栈中(局部变量)
- 观察判断控制块的特点,将所有控制块剔除。剔除之后基本块中还包含真实块(如果不存在虚假控制流)
- 确定各个真实块的执行路径,即一个真实块能跳转到哪几个块(1/2个块),通常通过模拟执行
unicorn寻找路径 - 对于只包含一个路径的真实块直接在其代码块末尾patch,跳转到对应的真实块
- 对于包含两个路径的真实块,平坦化是通过在此真实块的末尾根据跳转条件更改状态变量的值来实现跳转到不同的真实块中,我们需要将其通过更改状态变量的跳转到不同真实块的方式修改为通过条件跳转指令的方式实现(bge,ble...)。我们需要根据实际的修改状态变量的指令来使用对应的跳转指令例如:其通过
movne修改状态变量的值,那么我们就可以修改为bne指令.
当然在实际分析中可能有很多特殊的情况需要特殊处理,大致流程一样。
注意:对于arm-v7a(thumb)的指令集指令而言,修改pc指针的时候需要+1,这样cpu才会将其识别为thumb指令
参考链接:https://bbs.pediy.com/thread-252321.htm

 浙公网安备 33010602011771号
浙公网安备 33010602011771号