Rscan-目标采集之Fofa爬虫
本文分离了Rscan中的fofa爬取模块,供单独调用
运行环境:python3
需要模块:requests、bs4
是否需要账号:需要
代码已封装类,考虑到爬取效果,首先你得有一个fofa账号,登录后复制cookie中的_fofapro_ars_session出来,填写到obj_fofa = Fofa(query='', session_key='') 中的session_key中即可,其中query填写搜索关键词。
爬虫19年9月4日测试可用,若失效请留言,小弟将会及时更新,记得点赞收藏哟,谢谢啦
代码如下
# coding : utf-8
import requests
import base64
import time
from bs4 import BeautifulSoup
class Fofa(object):
def __init__(self, query, session_key):
self.query = query
self.session_key = session_key
self.cookies = dict(_fofapro_ars_session=session_key)
def requester(self, page):
url = "https://fofa.so/result?page=" + str(page) + "&qbase64=" + base64.b64encode(self.query.encode('utf-8')).decode()
r = requests.get(url, cookies=self.cookies)
content = str(r.text)
if len(content)< 20000:
print(" Speed Too Fast. Waiting 5s... ")
time.sleep(5)
content = self.requester(page)
return content
def get_count_of_page(self):
content = self.requester(1)
pages = content.split("</a> <a class=\"next_page\"")[0].split(">")[-1]
return int(pages)
def parser(self, content):
ip_port = []
soup = BeautifulSoup(content, 'html.parser')
list_mod = soup.find_all('div', class_='list_mod')
for item in list_mod:
ip = str(item).split('href="/hosts/')[1].split('"')[0]
port = str(item).split("<a href=\"/result?qbase64=")[1].split("\">")[1].split("</a>")[0]
ip_port.append(ip+':'+port)
return ip_port
def run(self):
result = []
pages = self.get_count_of_page()
for page in range(1, (pages + 1)):
print("Page: " + str(page))
content = self.requester(page)
ip_port_list = self.parser(content)
for item in ip_port_list:
result.append(item)
print(item)
return result
if __name__ == '__main__':
obj_fofa = Fofa(query='', session_key='')
result = obj_fofa.run()
print(len(result))
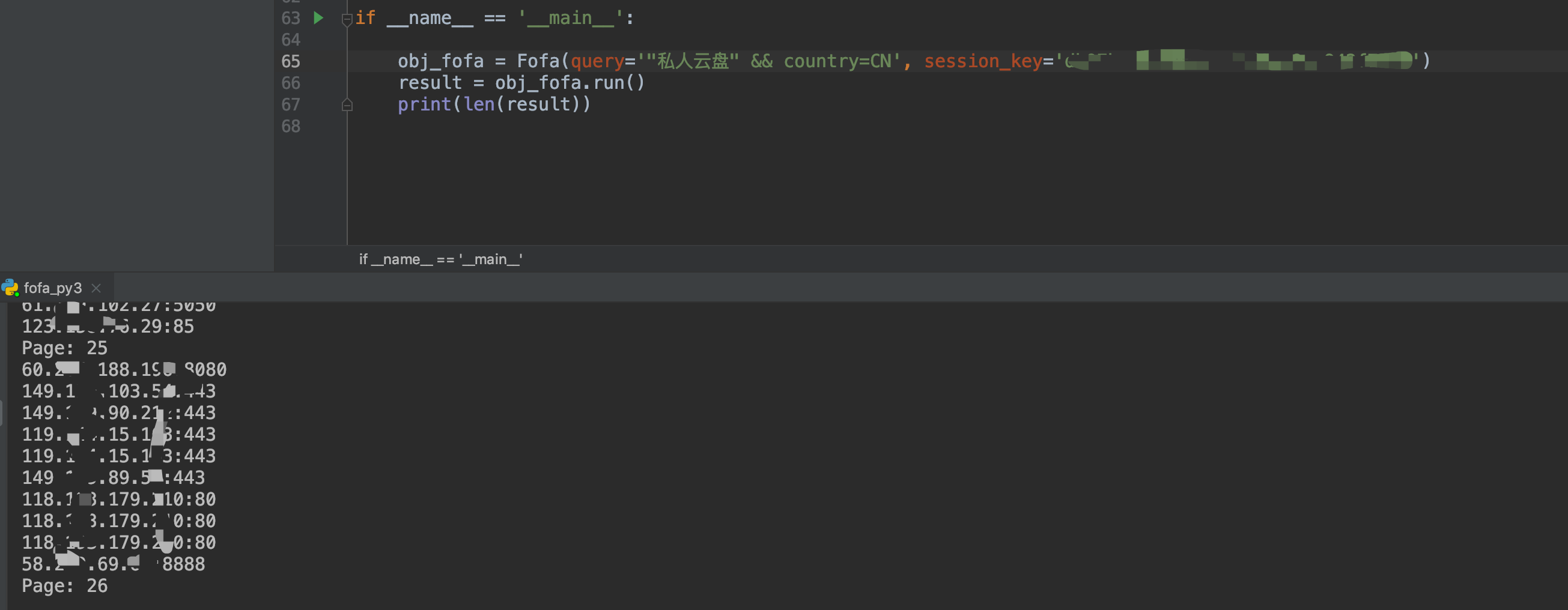
效果演示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号