【学习笔记】珂朵莉树(ODT)
珂朵莉树(ODT)是一种玄学数据结构,得名于 Codeforces 896 C,可以在较快的时间复杂度内实现区间赋值和区间修改等操作。
0x00 Prologue
在太阳西斜的这个世界里,
置身天上之森。
等这场战争结束之后,
不归之人与望眼欲穿的众人,
人人本着正义之名,
长存不灭的过去、逐渐消逝的未来。
我回来了,纵使日薄西山,即便看不到未来,
此时此刻的光辉,盼君勿忘。
这几天闲着慌,就去学了学珂朵莉树,作为一个很有用的骗分数据结构,个人认为还是有必要学一学的。反正又不难
0x01 What is it?
珂朵莉树起源于Codeforces 896 C,由于出题人的 CF id 为 Old Driver,因此又被称为 Old Driver Tree(ODT)。
原题需要我们实现一种数据结构,可以快速维护以下操作:(保证数据随机)
- 区间加;
- 区间赋值;
- 求区间第 \(k\) 小;
- 求区间 \(k\) 次方和。
很明显,普通的线段树等数据结构都很难实现这种要求,但是这种似乎很复杂的数据结构,在出题人这位毒瘤眼中竟然可以用......
暴力实现?
珂朵莉树的思想在于把一段连续的值相同的区间用一个结构体来存储,由于数据随机且有大量区间赋值操作,这样的结构体数量会大大减少,从而保证了珂朵莉树接近线性的时间复杂度。
乍一看,珂朵莉树似乎并不像是一个树形数据结构,但因为它一般基于 std::set 来实现,而 std::set 本质是红黑树,所以也跟“树”勉强搭得上边。
0x02 如何实现?
珂朵莉树的精髓在于区间推平操作会产生大量的元素值相同的区间,因此我们用三个变量 \(l,r,v\) 来表示一个下标为 \([l,r]\) 中元素值为 \(v\) 的区间。接着我们把这些三元组存储到 std::set 中。写成代码就是这样的:
struct node {
int l,r;
mutable int v; // 这里mutable关键字保证了可以直接在set中修改v的值
node() {}
node(int L,int R,int V): l(L),r(R),v(V) {}
const bool operator < (const node& x) const { return l < x.l; } // 按照区间所在的位置排序
}; typedef set < node > :: iterator iter; // 简化迭代器
set < node > s; // 存储到std::set中
比如当输入数据为 1 2 2 2 3 3 4 4 时, set 内存储的数据就是这样的:

操作1:split
然而,我们操作的区间并不总是正好覆盖我们存储的区间。因此我们需要一个函数来实现分裂开每个区间的操作,也就是 split 函数。split 函数接受一个参数 \(\textit{pos}\) ,然后把包含 \(\textit{pos}\) 的区间 \([l,r]\) “分裂”成 \([l,pos)\) 和 \([pos,r]\) :
iter split(ll pos) {
iter it = s.lower_bound(node(pos,0,0)); // lower_bound寻找包含pos的区间
if(it != s.end() && it -> l == pos) return it; // 如果已经存在就直接返回
it --; // 往前数一个才是我们想要的
ll l = it -> l,r = it -> r,v = it -> v;
s.erase(it); // 删除原来的
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first; // 分裂成两个并返回后面一个的迭代器
}
对于刚才那个图,如果我们执行 split(4),那么他就会变成这样:
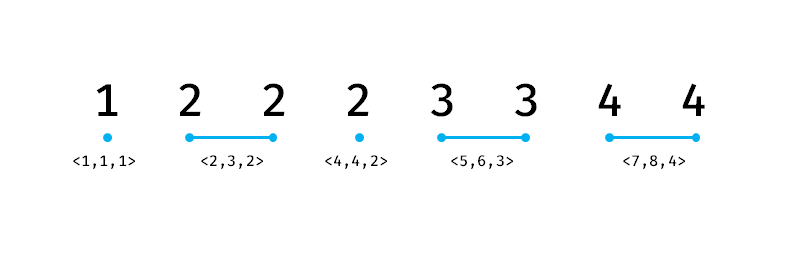
这里的运行流程:lower_bound 找到区间 <5,6,3> ,往前回滚找到 <2,4,2> ,并将其修改成 <2,3,2> 和 <4,4,2> 。
在进行区间操作时,我们常常要左右端点各 split 一次,此时我们要先 split 右端点,否则左端点的迭代器可能会失效而导致错误。
操作2:assign
很明显,如果操作中全是 split 的话,区间数会越来越多,复杂度必然爆炸。这时我们就需要区间赋值操作减少区间数量:assign。
assign 函数接受三个参数,表示区间和要赋的值。赋值时,把左右端点 split 一下,然后把中间的部分变成一个新的区间就行了:
void assign(ll l,ll r,ll v) {
iter itr = split(r + 1),itl = split(l); // 左右端点各split一遍
s.erase(itl,itr); // 两端点之间的节点全部删去
s.insert(node(l,r,v)); // 插入新的区间
}
还是刚刚那个图,如果我们执行 assign(3,5,5),就变成了这个亚子:
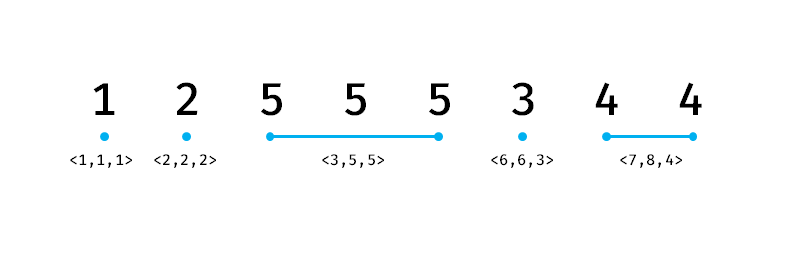
其他操作:暴力出奇迹
区间加: 一个一个加一遍就完事了
void add(int l,int r,int x) {
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) itl -> v += x;
}
区间第 \(k\) 大: 塞到 vector 里排序就完事了
int kth(int l,int r,int k) {
vector < pair < int,int > > vec; // pair存储值以及区间长度
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) vec.push_back(make_pair(itl -> v,itl -> r - itl -> l + 1));
sort(vec.begin(),vec.end()); // 默认优先按照第一关键字排序
for(int i = 0;i < vec.size();i ++) {
k -= vec[i].second;
if(k <= 0) return vec[i].first;
}
}
区间 \(k\) 次方和: 每个取出来做快速幂求和就完事了
int sum(int l,int r,int x,int y) { // x次方和除以y的余数
int res = 0;
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++)
res = (res + (itl -> r - itl -> l + 1) % y * fpow(itl -> v,x,y) % y) % y; // fpow就是快速幂
return res;
}
真的是暴力出奇迹......然而因为 split 和 assign 的存在, set 中的区间数量也不会太多,所以速度可以保证。不过如果数据不随机,珂朵莉树还是很容易被 hack 掉的。比如 CF896C 中提供了一个随机数生成器就是为了防止 hack。
最后附上 CF896C 的全部代码:
#include <algorithm>
#include <cstdio>
#include <vector>
#include <set>
using namespace std;
typedef long long ll;
struct node {
ll l,r;
mutable ll v;
node() {}
node(ll _l,ll _r,ll _v): l(_l),r(_r),v(_v) {}
const bool operator < (const node& x) const { return l < x.l; }
}; typedef set < node > :: iterator iter;
set < node > s;
ll n,m,seed,vmax,op,l,r,x,y;
ll a[100005];
ll rnd(ll mod) {
ll ret = seed;
seed = (seed * 7 + 13) % 1000000007;
return ret % mod + 1;
}
ll fpow(ll a, ll b, ll mod) {
ll res = 1,ans = a % mod;
while(b) {
if(b & 1) res = res * ans % mod;
ans = ans * ans % mod;
b >>= 1;
}
return res;
}
iter split(ll pos) {
iter it = s.lower_bound(node(pos,0,0));
if(it != s.end() && it -> l == pos) return it;
it --;
ll l = it -> l,r = it -> r,v = it -> v;
s.erase(it);
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first;
}
void assign(ll l,ll r,ll v) {
iter itr = split(r + 1),itl = split(l);
s.erase(itl,itr);
s.insert(node(l,r,v));
}
void add(ll l,ll r,ll x) {
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) itl -> v += x;
}
ll kth(ll l,ll r,ll k) {
vector < pair < ll,ll > > vec;
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) vec.push_back(make_pair(itl -> v,itl -> r - itl -> l + 1));
sort(vec.begin(),vec.end());
for(int i = 0;i < vec.size();i ++) {
k -= vec[i].second;
if(k <= 0) return vec[i].first;
}
}
ll sum(ll l,ll r,ll x,ll y) {
ll res = 0;
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++)
res = (res + (itl -> r - itl -> l + 1) % y * fpow(itl -> v,x,y) % y) % y;
return res;
}
int main() {
scanf("%lld%lld%lld%lld",&n,&m,&seed,&vmax);
for(int i = 1;i <= n;i ++) {
a[i] = rnd(vmax);
s.insert(node(i,i,a[i]));
}
for(int i = 1;i <= m;i ++) {
op = rnd(4),l = rnd(n),r = rnd(n);
if(l > r) swap(l,r);
if (op == 3) x = rnd(r - l + 1);
else x = rnd(vmax);
if (op == 4) y = rnd(vmax);
switch(op) {
case 1: add(l,r,x); break;
case 2: assign(l,r,x); break;
case 3: printf("%lld\n",kth(l,r,x)); break;
case 4: printf("%lld\n",sum(l,r,x,y)); break;
}
}
return 0;
}
0x03 更广泛的运用
1. CF915E Physical Education Lessons
有两种操作,每次操作把区间内的值全部赋成 \(0\) 或 \(1\),求每次操作后整个序列内元素的和。
区间赋值+区间求和,简直是珂朵莉树的模板!不过在这题中,我们可以把 sum 函数简化掉,只需要在 assign 中求和即可。
code:
#include <cstdio>
#include <set>
using namespace std;
typedef long long ll;
struct node {
ll l,r;
mutable ll v;
node() {}
node(ll _l,ll _r,ll _v): l(_l),r(_r),v(_v) {}
const bool operator < (const node& x) const { return l < x.l; }
}; typedef set < node > :: iterator iter;
set < node > s;
ll n,q,sum; // sum存储区间和
iter split(ll pos) {
iter it = s.lower_bound(node(pos,0,0));
if(it != s.end() && it -> l == pos) return it;
it --;
ll l = it -> l,r = it -> r,v = it -> v;
s.erase(it);
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first;
}
void assign(ll l,ll r,ll v) {
int cnt = 0,len = 0; // cnt代表区间内的和,len代表区间长度
iter itr = split(r + 1),itl = split(l);
for(iter it = itl;it != itr;it ++) {
len += (it -> r - it -> l + 1);
cnt += it -> v * (it -> r - it -> l + 1);
}
s.erase(itl,itr);
s.insert(node(l,r,v));
if (v == 1) sum += (len - cnt);
else sum -= cnt; // 更新sum的值
}
int main() {
scanf("%lld%lld",&n,&q);
sum = n,s.insert(node(1,n,1));
for(int l,r,k;q;q --) {
scanf("%lld%lld%lld",&l,&r,&k);
assign(l,r,k == 1 ? 0 : 1);
printf("%lld\n",sum);
}
return 0;
}
2. 洛谷P1047 校门外的树
我知道这题可以用模拟差分线段树分块做
但如果把区间长度 \(L\) 的范围加大到 \(10^9\),这些方法就不行了。这时我们就要祭出今天的主角:珂朵莉树。
由于 \(m\) 的范围并没有那么大,因此区间的数量并不会那么多(在 \(O(m)\) 级别)。由于题目只要求实现区间清零的操作,我们可以直接仿照上个例子来完成。
code:
#include <cstdio>
#include <set>
using namespace std;
struct node {
int l,r;
mutable int v;
node() {}
node(int _l,int _r,int _v): l(_l),r(_r),v(_v) {}
const bool operator < (const node& x) const { return l < x.l; }
}; typedef set < node > :: iterator iter;
set < node > s;
int L,m,sum;
iter split(int pos) {
iter it = s.lower_bound(node(pos,0,0));
if(it != s.end() && it -> l == pos) return it;
it --;
int l = it -> l,r = it -> r,v = it -> v;
s.erase(it);
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first;
}
void assign(int l,int r) {
int cnt = 0,len = 0;
iter itr = split(r + 1),itl = split(l);
for(iter it = itl;it != itr;it ++) {
len += (it -> r - it -> l + 1);
cnt += it -> v * (it -> r - it -> l + 1);
}
s.erase(itl,itr);
s.insert(node(l,r,0));
sum -= cnt;
}
int main() {
scanf("%d%d",&L,&m);
sum = L + 1,s.insert(node(0,L,1));
for(int l,r;m;m --) {
scanf("%d%d",&l,&r);
assign(l,r);
}
printf("%d\n",sum);
return 0;
}
当然,如果真的遇到这道题,且不保证数据随机时,珂朵莉树有可能被 hack 掉,此时这题的正解应该是离散化然后差分。
3. 洛谷P2572 [SCOI2010]序列操作
一道不错的练习珂朵莉树骗分的题目。很明显,第 \(0,1,3\) 个操作都是珂朵莉树的板子,而其他两个操作只要稍作修改就行了:
code(部分):
区间取反:
void reverse(int l,int r) { // 挨个取出来取反
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) itl -> v ^= 1; // 值异或1是个简单的取反方法
}
求区间最大连续1的长度:
int query(int l,int r) {
int ans = 0,sum = 0;
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++) // 挨个取出来计数
if(itl -> v) sum += itl -> r - itl -> l + 1;
else ans = ans > sum ? ans : sum,sum = 0;
return ans > sum ? ans : sum;
}
对于本题,有两个注意点:
-
下标从 \(0\) 开始,因此处理时要全部 \(+1\);
-
原题出自 2010 年四川省选,当时的数据较弱,ODT 可以轻松过;但在洛谷上,本题数据经过精心构造,普通 ODT 只能过 \(3\) 个点。这也是一般 ODT 只能用作骗分手段的原因。
4. 洛谷P2787 语文1(chin1)- 理理思维
又是一道 ODT 骗分题。前两个操作都是 ODT 基操,第三个操作开桶排序即可。
code:
#include <iostream>
#include <cstring>
#include <cstdio>
#include <string>
#include <set>
using namespace std;
struct node {
int l,r;
mutable int v;
node() {}
node(int _l,int _r,int _v): l(_l),r(_r),v(_v) {}
const bool operator < (const node& x) const { return l < x.l; }
}; typedef set < node > :: iterator iter;
set < node > s;
string buf;
int n,m;
int a[100005];
inline int read() {
#define gc c = getchar()
int d = 0,f = 0,gc;
while(c < 48 || c > 57) f |= (c == '-'),gc;
while(c > 47 && c < 58) d = (d << 1) + (d << 3) + (c ^ 48),gc;
#undef gc
return f ? -d : d;
}
inline int todigit(char c) { // alpha -> digits
if('A' <= c && c <= 'Z') return c - 'A' + 1;
if('a' <= c && c <= 'z') return c - 'a' + 1;
}
iter split(int pos) {
iter it = s.lower_bound(node(pos,0,0));
if(it != s.end() && it -> l == pos) return it;
it --;
int l = it -> l,r = it -> r,v = it -> v;
s.erase(it);
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first;
}
void assign(int l,int r,int v) {
iter itr = split(r + 1),itl = split(l);
s.erase(itl,itr);
s.insert(node(l,r,v));
}
inline int query(int l,int r,int k) {
int sum = 0;
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl ++)
if(itl -> v == k) sum += itl -> r - itl -> l + 1;
return sum;
}
void bsort(int l,int r) {
int pos = l,cnt[27];
memset(cnt,0,sizeof(cnt));
iter itr = split(r + 1),itl = split(l);
for(;itl != itr;itl = erase(itl)) cnt[itl -> v] += itl -> r - itl -> l + 1;
for(int i = 1;i <= 26;i ++)
if(cnt[i]) s.insert(node(pos,pos + cnt[i] - 1,i)),pos += cnt[i];
}
int main() {
n = read(),m = read();
cin >> buf;
for(int i = 1;i <= n;i ++) s.insert(node(i,i,todigit(buf[i - 1])));
for(int op,x,y;m;m --) {
op = read(),x = read(),y = read();
char k;
if(op != 3) { cin >> k; k = todigit(k); }
switch(op) {
case 1: printf("%d\n",query(x,y,k)); break;
case 2: assign(x,y,k); break;
case 3: bsort(x,y); break;
}
}
return 0;
}
5. 洛谷P2146 [NOI2015] 软件包管理器
树链剖分+ODT。由于只有 assign 操作,ODT 理论时间复杂度不会太高,开 O2 优化即可通过。
code:
#include <cstdio>
#include <set>
const int maxn = 1e5 + 5;
using std::set;
struct Edge {
int v,g;
Edge(int to = 0,int nxt = 0): v(to),g(nxt) {}
} edge[maxn];
struct pack {
int hson,siz,dfn,top,fa;
} p[maxn];
struct node {
int l,r;
mutable int v;
node() {}
node(int _l,int _r,int _v): l(_l),r(_r),v(_v) {}
const bool operator < (const node& x) const { return l < x.l; }
}; typedef set < node > :: iterator iter;
set < node > s;
int n,q,tot1,tot2,head[maxn];
char buf[50];
inline int read() {
#define gc c = getchar()
int d = 0,f = 0,gc;
for(;c < 48 || c > 57;gc) f |= (c == '-');
for(;c > 47 && c < 58;gc) d = (d << 1) + (d << 3) + (c ^ 48);
#undef gc
return f ? -d : d;
}
iter split(int pos) {
iter it = s.lower_bound(node(pos,0,0));
if(it != s.end() && it -> l == pos) return it;
it --;
int l = it -> l,r = it -> r,v = it -> v;
s.erase(it);
s.insert(node(l,pos - 1,v));
return s.insert(node(pos,r,v)).first;
}
int assign(int l,int r,int v) {
int ans = 0;
iter itr = split(r + 1),itl = split(l);
for(iter it = itl;it != itr;it ++) ans += (it -> r - it -> l + 1) * (it -> v ^ v);
s.erase(itl,itr);
s.insert(node(l,r,v));
return ans;
}
inline void add_edge(int u,int v) {
edge[++ tot1] = Edge(v,head[u]);
head[u] = tot1;
}
int dfs1(int u) {
p[u].siz = 1;
for(int i = head[u];i;i = edge[i].g) {
int v = edge[i].v;
if(v == p[u].fa) continue;
p[v].fa = u;
p[u].siz += dfs1(v);
if(p[v].siz > p[p[u].hson].siz) p[u].hson = v;
}
return p[u].siz;
}
void dfs2(int u,int tp) {
p[u].dfn = ++ tot2;
p[u].top = tp;
if(!head[u]) return ;
dfs2(p[u].hson,tp);
for(int i = head[u];i;i = edge[i].g) {
int v = edge[i].v;
if(v != p[u].fa && v != p[u].hson) dfs2(v,v);
}
}
void ins(int id) {
int res = 0;
for(;p[id].top != 1;) {
res += assign(p[p[id].top].dfn,p[id].dfn,1);
id = p[p[id].top].fa;
}
res += assign(1,p[id].dfn,1);
printf("%d\n",res);
}
void unins(int id) {
printf("%d\n",assign(p[id].dfn,p[id].dfn + p[id].siz - 1,0));
}
int main() {
n = read();
s.insert(node(1,n + 1,0));
for(int u,i = 2;i <= n;i ++) {
u = read() + 1;
add_edge(u,i);
}
dfs1(1);
dfs2(1,1);
q = read();
for(int x;q;q --) {
scanf("%s",buf);
x = read() + 1;
if(buf[0] ^ 'u') ins(x);
else unins(x);
}
return 0;
}
0x04 Epilogue
我永远喜欢珂朵莉!(雾
珂朵莉树作为一个较为简单的数据结构,是在 OI 比赛中骗分的一个不错的工具蒟蒻选手的福音。在许多复杂的线段树题目中,它能够体现出清晰易懂、代码量小的优势。
所以,大家快来膜拜 lxl,lxl 是我们的光!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号