作业9.2:论文查重
零、最前面
| 这个作业属于哪个课程 | 班级链接 |
|---|---|
| 这个作业要求在哪里 | 作业要求链接 |
| 这个作业的目标 | 设计论文查重算法;学会 Git 版本控制。 |
Github 链接:博客正文首行 github 链接
一、整体设计
开发环境
- 编程语言:python 3
- IDE:PyCharm 2024.2.1 (Professional Edition)
整体设计
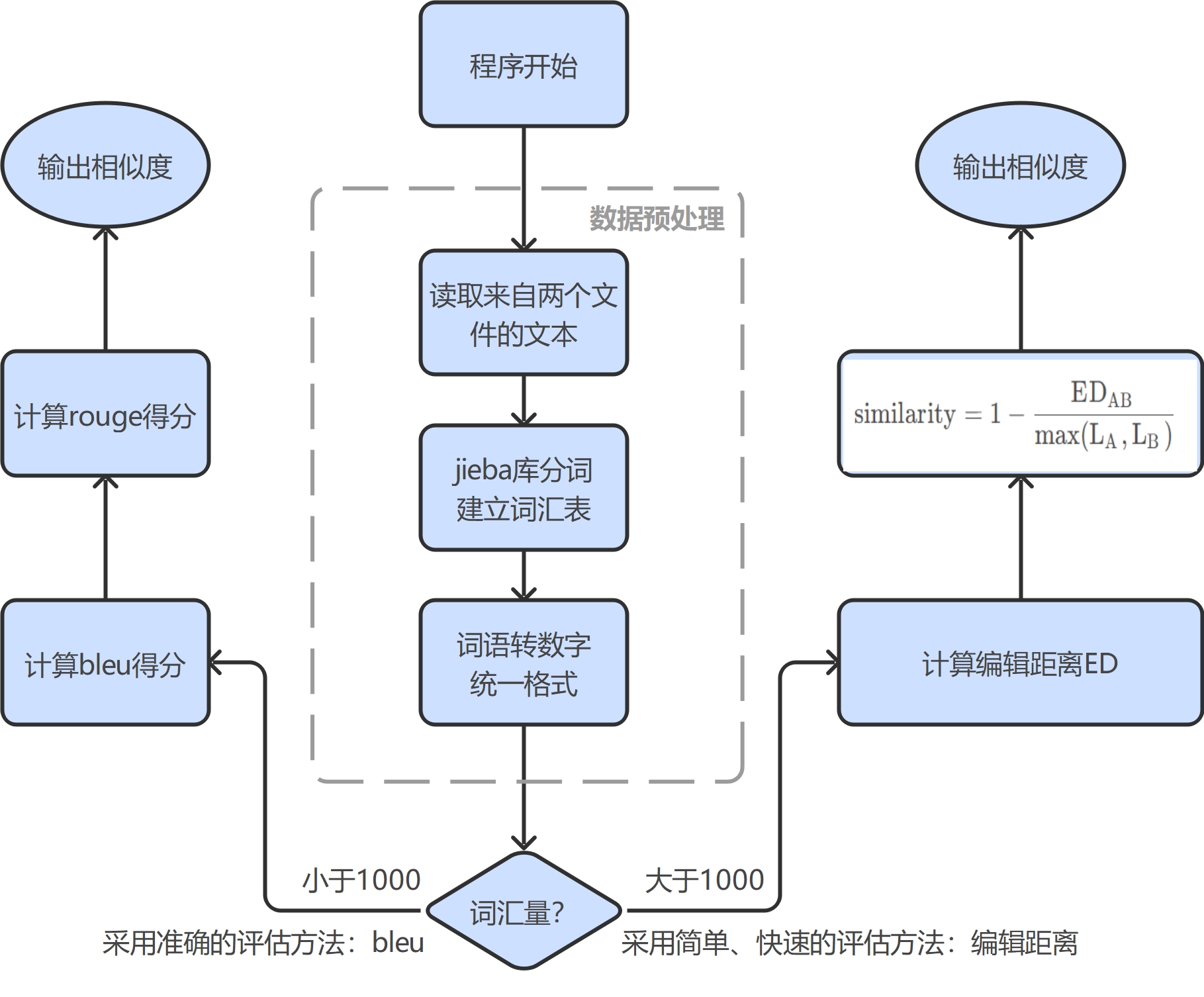
项目结构
.
├── .idea
├── 3121005661
├── src // 存放测试类
│ ├── get_tokenize.py // 数据预处理模块
│ ├── google_bleu.py // BLEU 模块
│ └── rouge.py // ROUGE 模块
├── test // 存放测试类
│ ├── test_bleu.py // 测试函数:BLEU
│ ├── test_generate_string.py // 测试函数:词元化
│ ├── test_generate_vocab.py // 测试函数:生成词表
│ ├── test_index_token.py // 测试函数:token 序列化
│ ├── test_leven_sim.py // 测试函数:编辑距离
│ └── test_rouge.py // 测试函数:Rouge
├── readme.md // Github readme 文档
├── call_graph.py // 打印程序调用关系图
└── main.py // 程序入口
二、模块接口的设计与实现
核心的类与方法
main_process方法:算法的主程序,将全流程调用的各种方法串联起来levenshtein_similarity方法:计算编辑距离的算法eval_accuracies方法:计算精确相似度的程序,调用方法计算bleu得分和rouge得分Rouge类:计算rouge得分的算法compute_bleu方法:计算bleu得分的算法
类与函数的调用关系
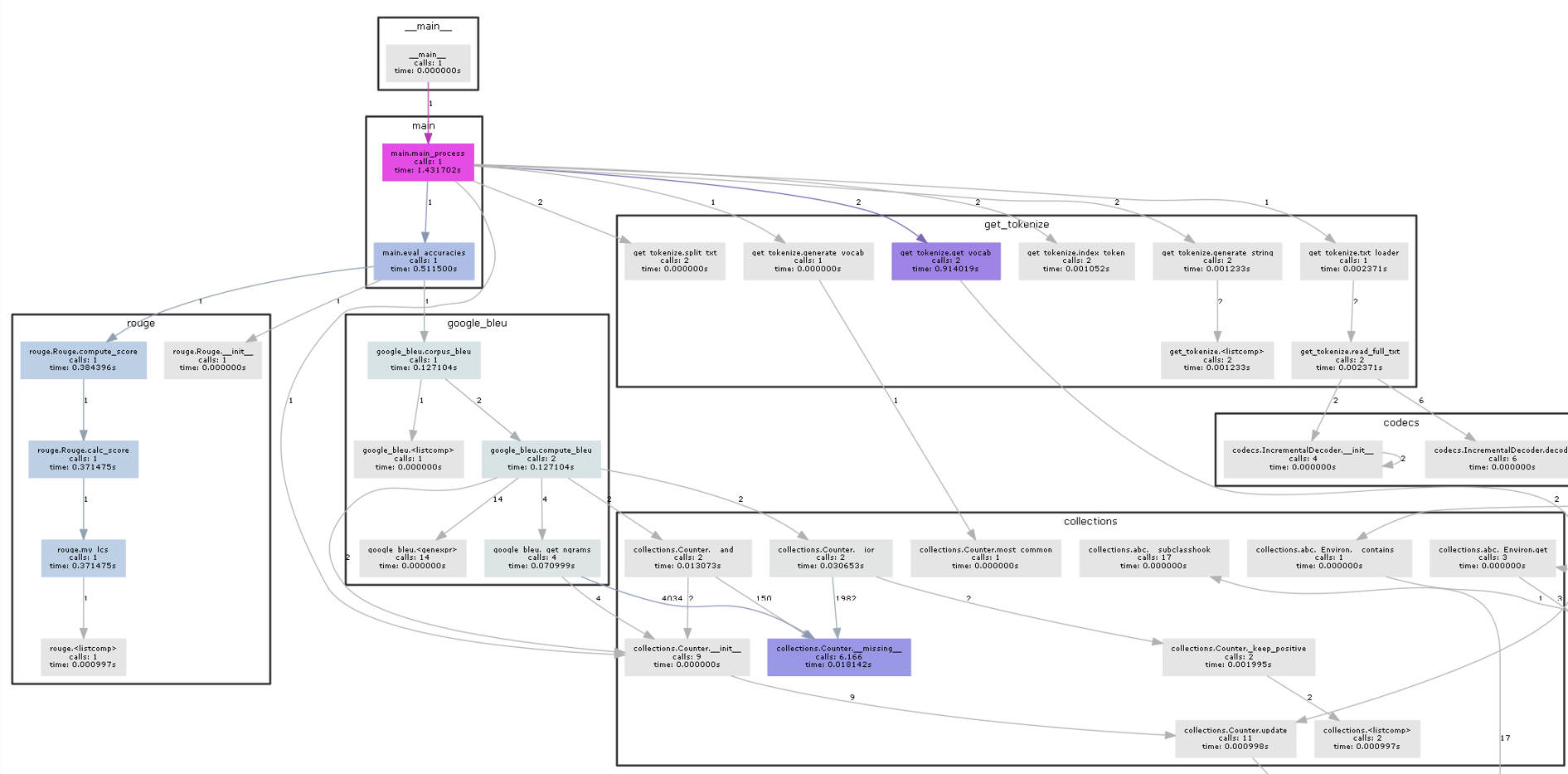
上图为程序的调用关系图,该图由pycallgraph库通过运行代码自动生成。图中,灰色标注的方块是系统内部的函数,彩色标注的方块是我自己编写的函数。由图可见,程序开始执行时,首先调用main_process函数,该函数调用get_tokenize.py文件的方法,对输入的文本进行预处理,然后调用eval_accuracies函数进行评估,该函数又调用了google_bleu.py和rouge.py文件的具体方法。
核心算法
本程序的一个核心算法是BLEU算法
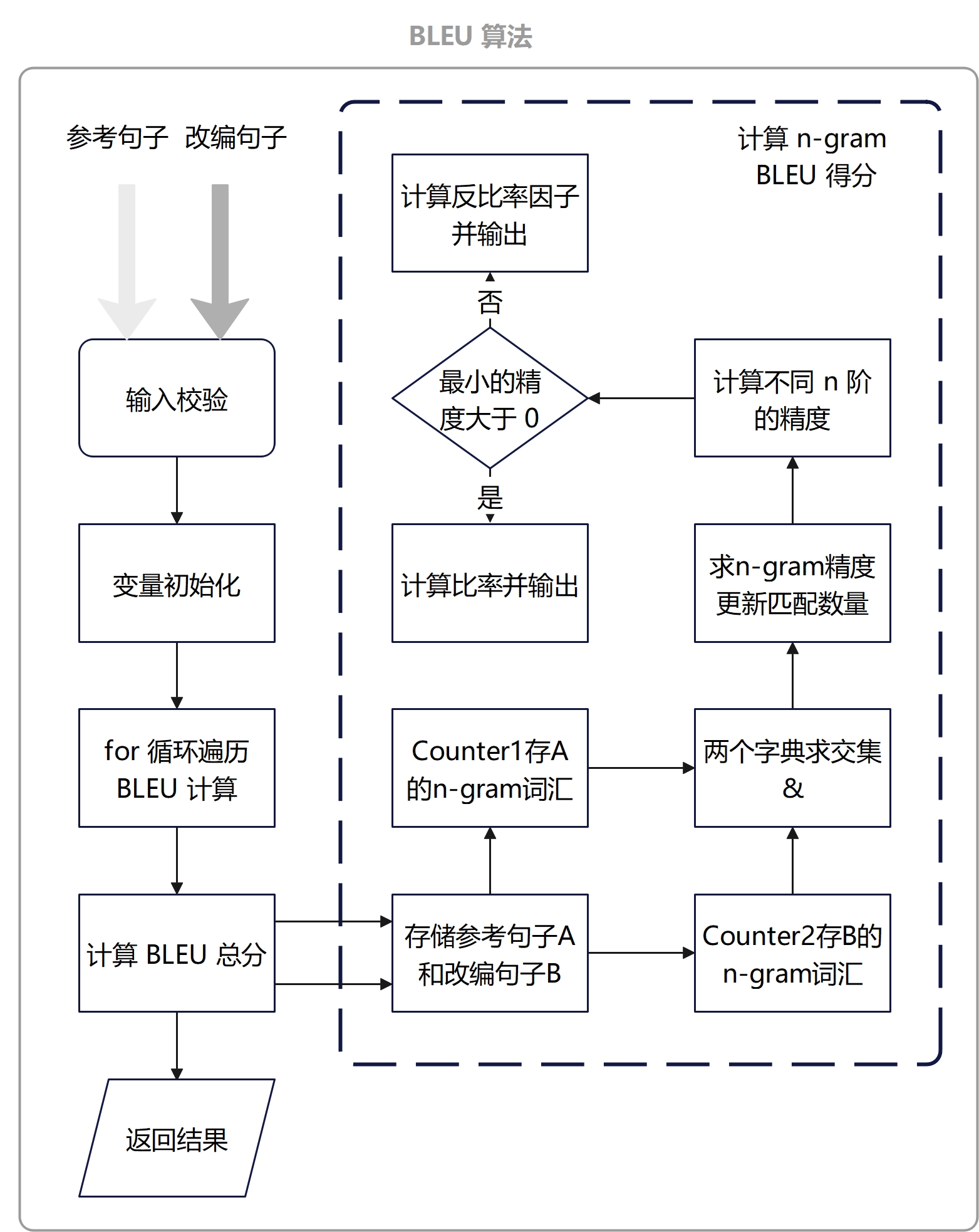
算法关键:n-gram准确率的计算。n-gram是指n个连续单词组成的单元,称为n元语法。如果采用1-gram匹配,如果每个文本一共6个词,有5个词语都相同,那么它1-gram的匹配度为 5/6。如果每个文本一共可以分为四个3-gram的词组,其中有两个可以命中参考译文,那么它3-gram的匹配度为 2/4。
独到之处:
- 在本算法中,对于参考句子和改编句子的
token,我首先取得他们各自的n-gram语法的token序列,用字典存储。然后,通过对两个字典取交集,可以很方便地得到两个token序列中匹配的部分。 - 在本算法中,求低元语法可以在求高元语法的基础上进行,避免了重复运算。例如,在
4-gram语法的token序列后,我通过遍历每个token,就能获得3-gram语法、2-gram语法、1-gram语法的token序列,从而既能求得4-gram准确率,又能求得3-gram、2-gram、1-gram准确率,而不需要重头开始计算他们。
三、接口部分性能改进
性能分析图
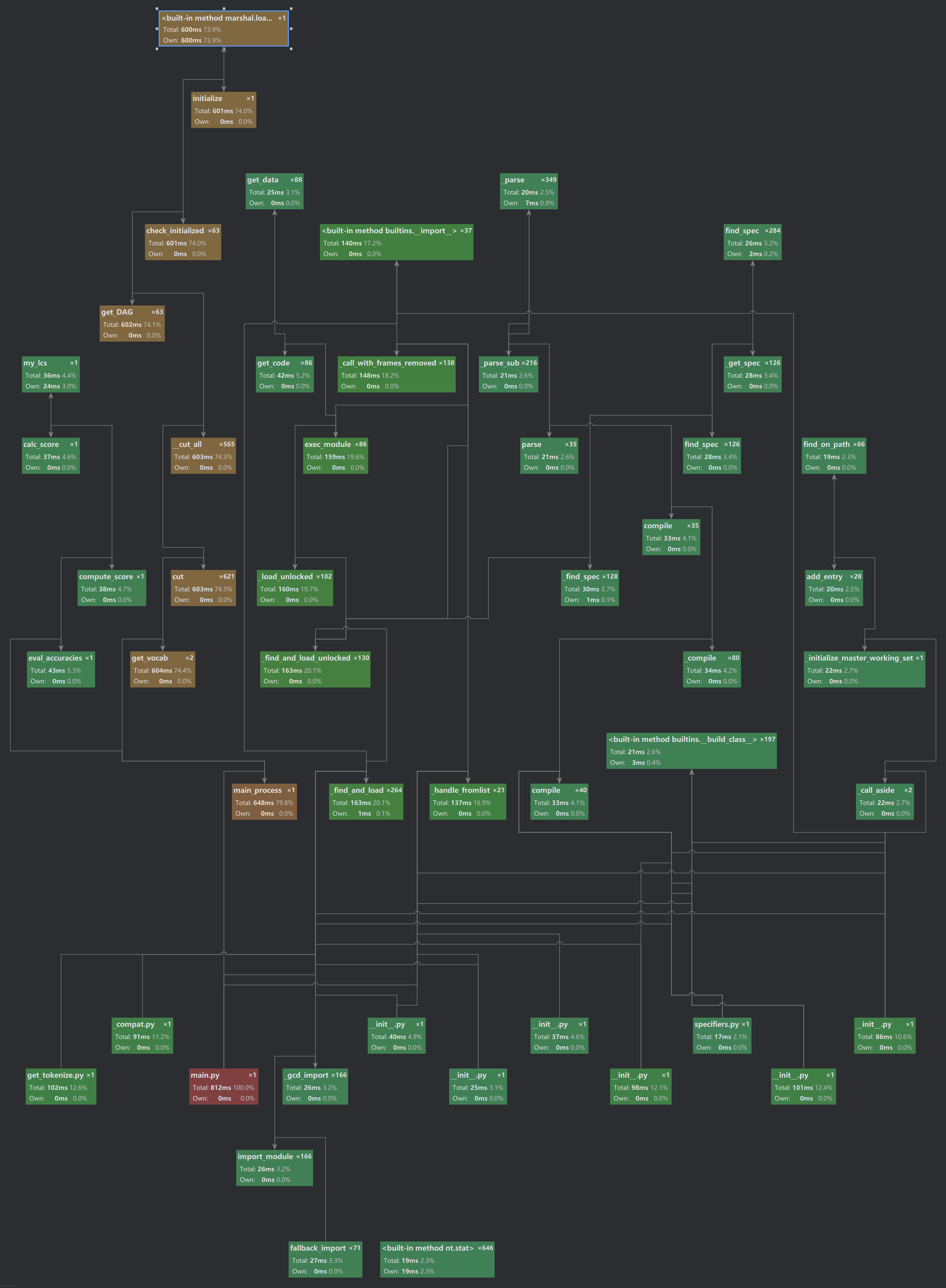
如上图所示,我使用pycharm专业版的profile工具,通过程序性能分析图展现各个模块的大致性能情况,红色代表耗时最大,橙色代表耗时较大,绿色代表耗时较小。通过上图观察发现,除了耗时最大的主程序main和main process,一个核心的自定义方法get_vocab也是耗时较多的,是需要重点改进、优化的对象。
为了验证上述说法,我们通过profile工具的性能统计数据来进一步了解程序各部分的详细耗时数据。
性能统计数据

如上表所示,展示了程序执行过程中用到了各种方法和耗时情况,其中包括自定义方法和一些内部方法。如果按照Call Count进行调用次数的从大到小排序,发现大多都是系统类型的调用,其中调用最多的是一个核心的内部方法max,一共调用了 94150 次。通过这种方式无法找出性能优化的方向。
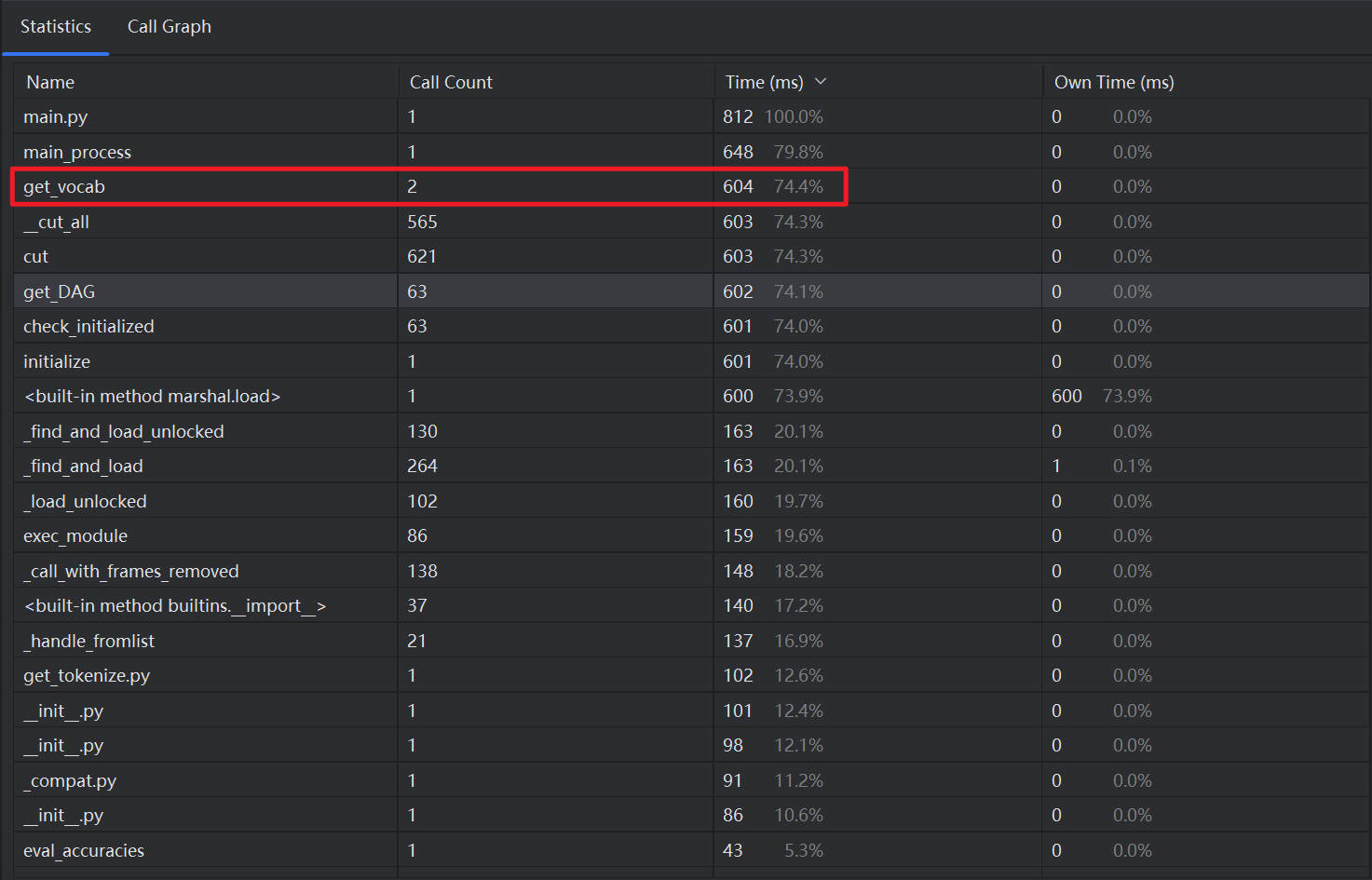
如上表所示,如果按照Time进行耗时的从大到小排序,可以发现,除了核心主程序main和main process,一个核心的自定义方法get_vocab是所有自定义方法中耗时最多的,而这一方法只是用于对token建立词汇表,进一步验证了这个方法其实是需要改进或者是需要被优化的。
性能改进
基于上面的问题,我们对算法进行调整,对于输入的两个文本,我们直接使用轻量级的编辑距离计算相似度,如果相似度低于 50% ,为了确保查重的准确率,我们才调用自定义方法get_vocab、使用BLEU算法进行计算。性能优化后的情况如下:
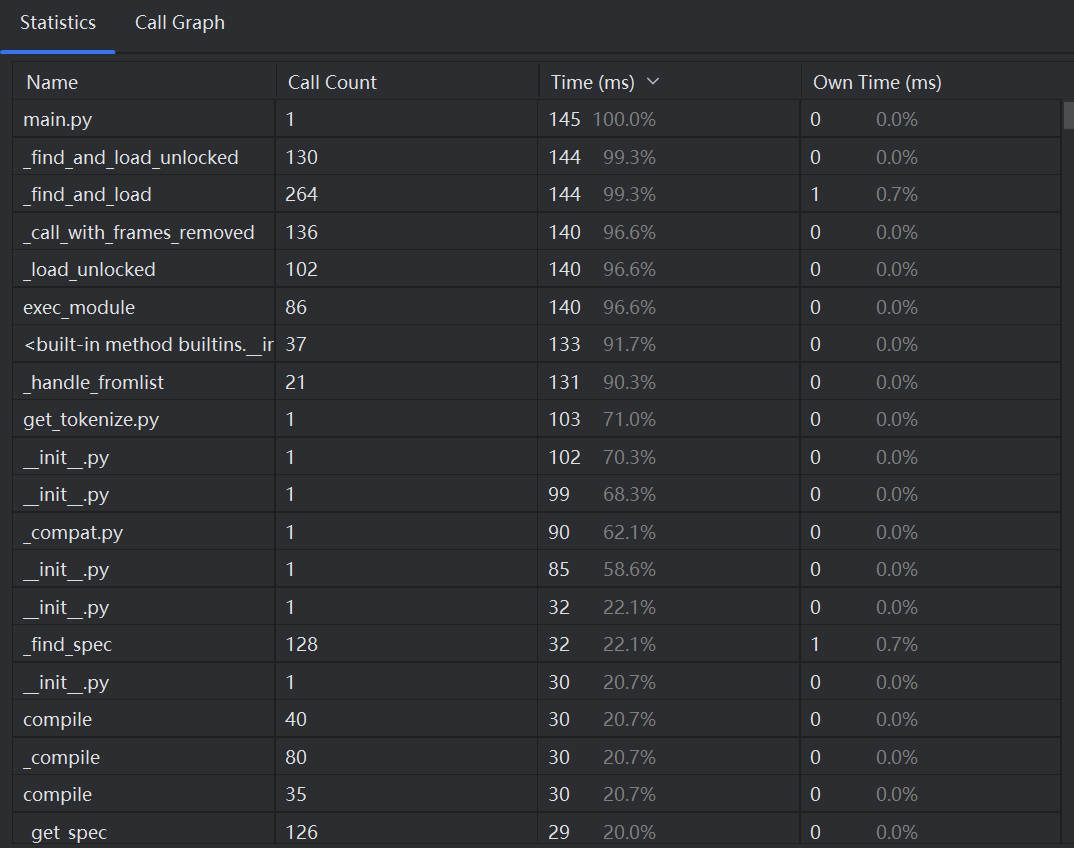
可以看到主程序main的总用时变为 145 ms,相较于之前快了 667 ms,一般情况下的性能有所提高。
四、单元测试
单元测试概览
| 测试功能 | 测试文件 | 测试等价类1 | 测试等价类2 | 测试等价类3 | 测试覆盖率 |
|---|---|---|---|---|---|
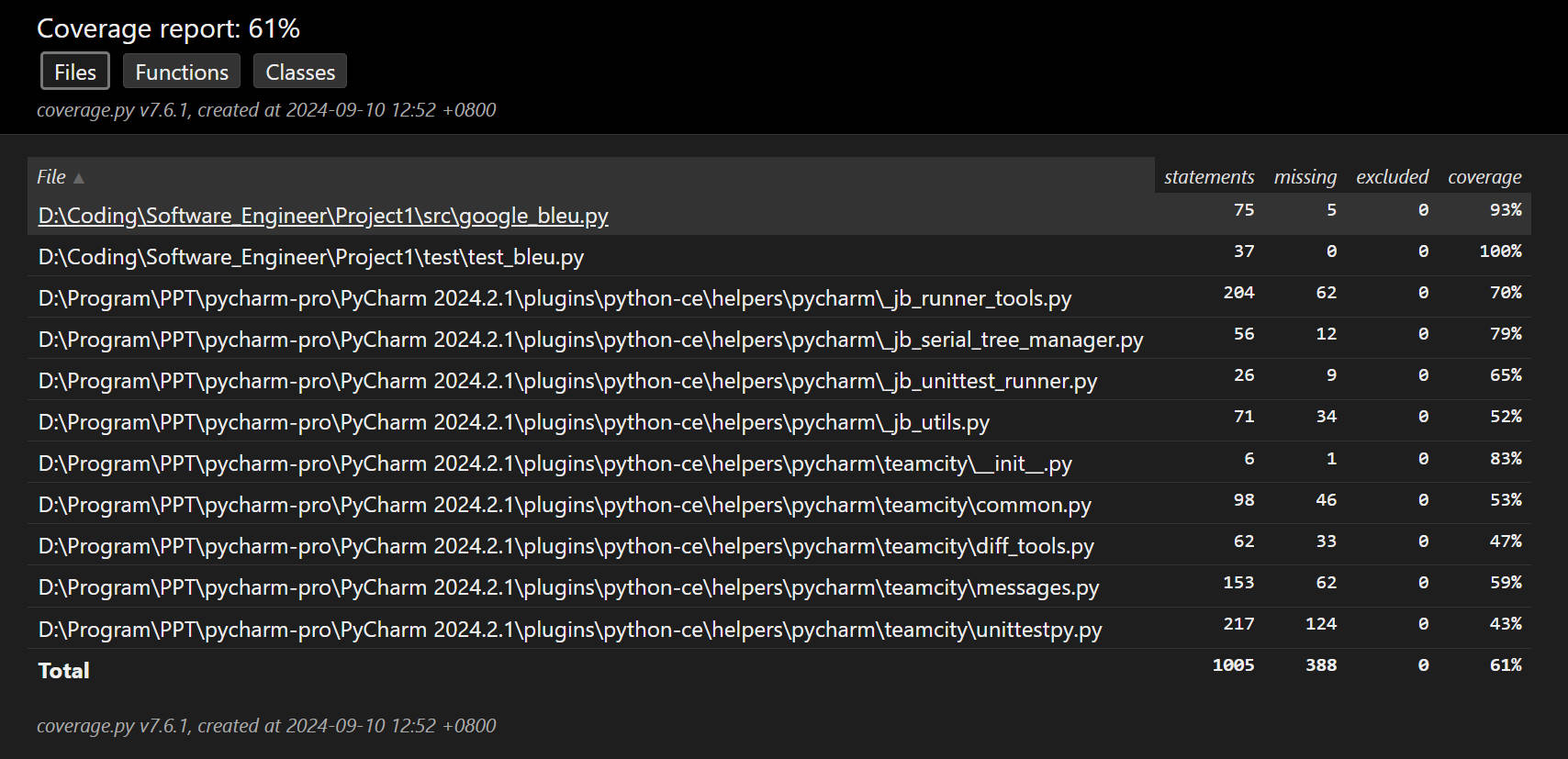
BLEU计算 |
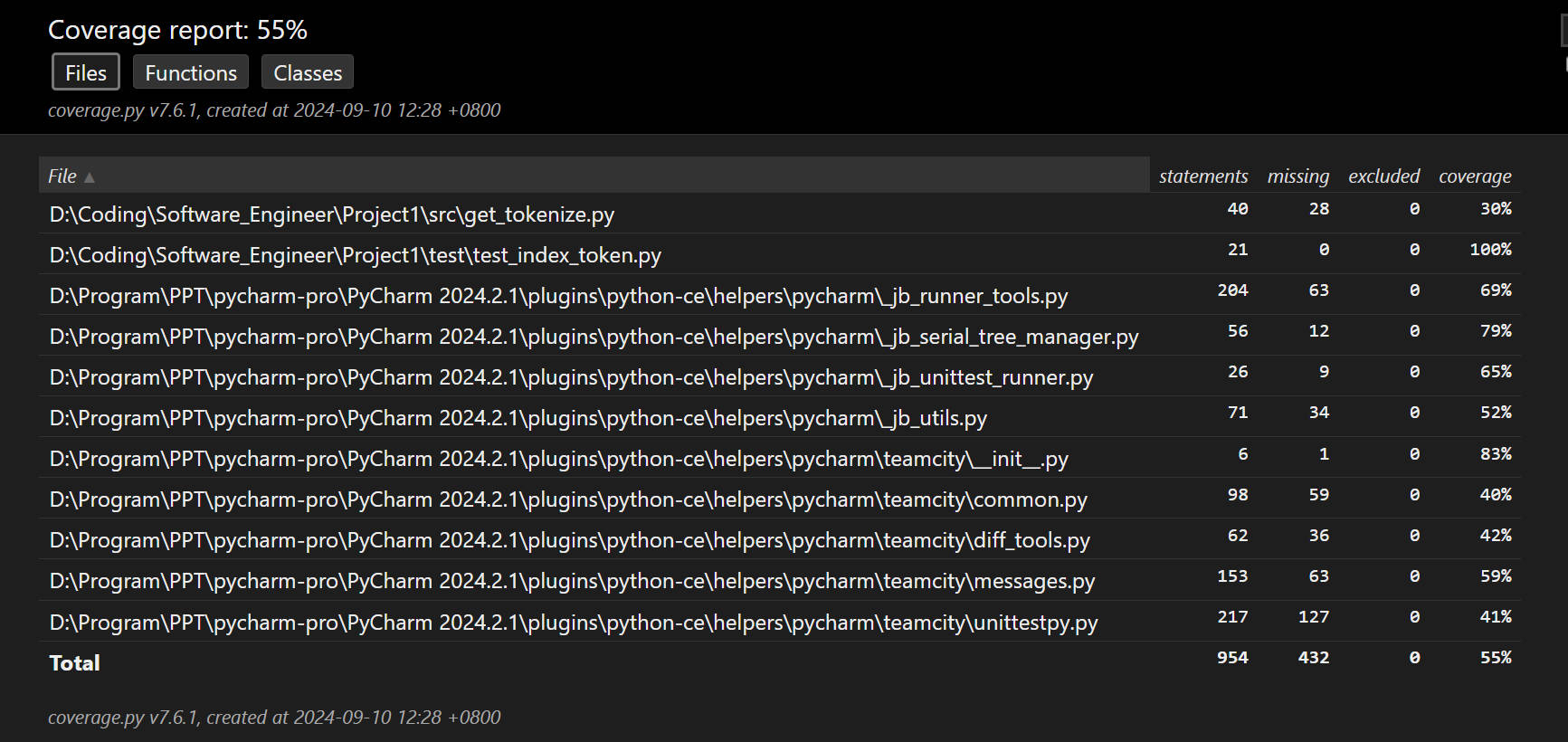
test_bleu.py | 输入均为空字典 | 输入数据不匹配 | 合法正例 | 61% |
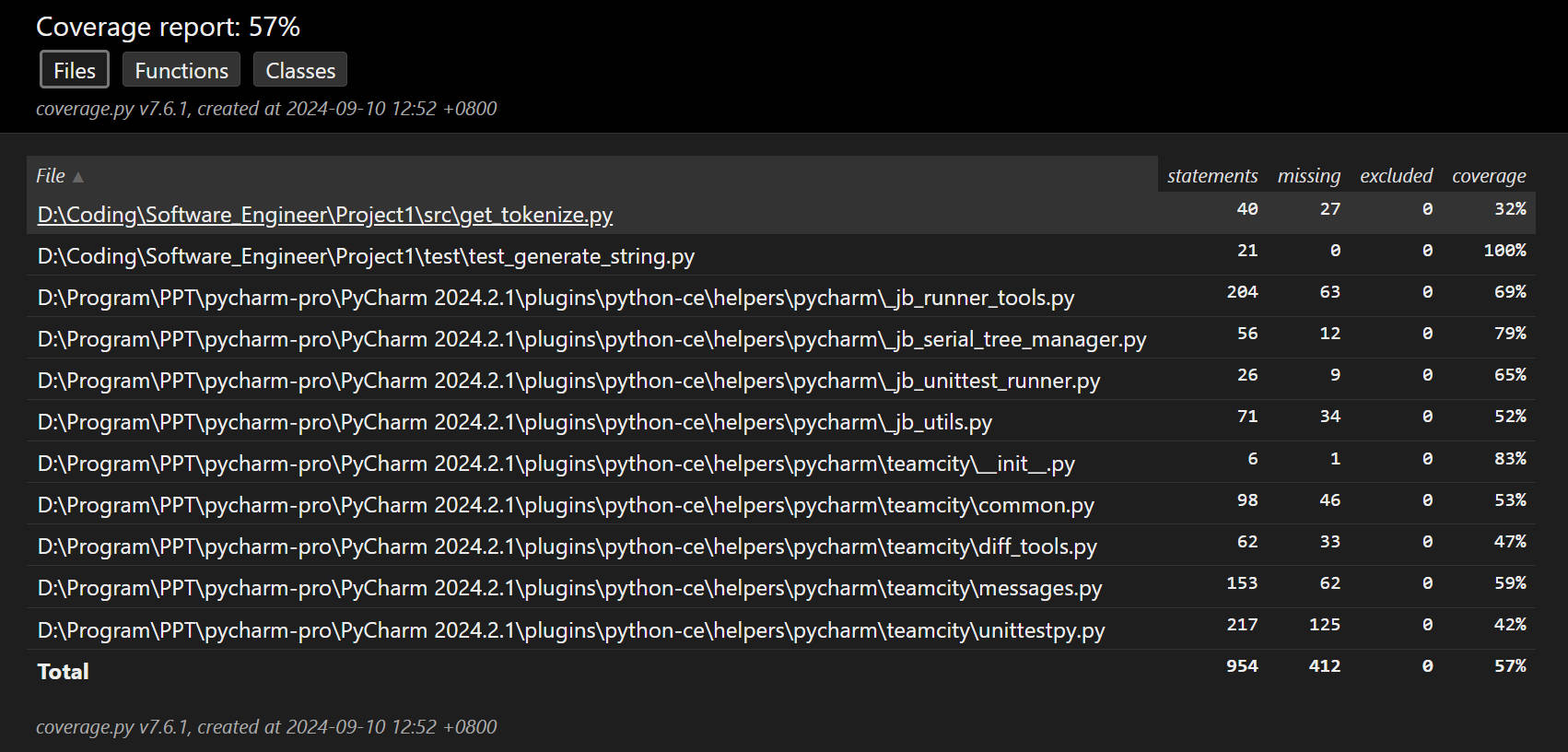
| 字符串生成 | test_generate_string.py | 输入为空字符串 | 输入错误数据类型 | 合法正例 | 57% |
| 词表生成 | test_generate_vocab.py | 输入为空 | 输入错误数据类型 | 合法正例 | 57% |
| 词元序列化 | test_index_token.py | 输入为空列表 | 特殊边界情况:UNK | 合法正例 | 55% |
| 编辑距离计算 | test_leven_sim.py | 输入为空字符串 | 输入错误数据类型 | 合法正例 | 50% |
ROUGE计算 |
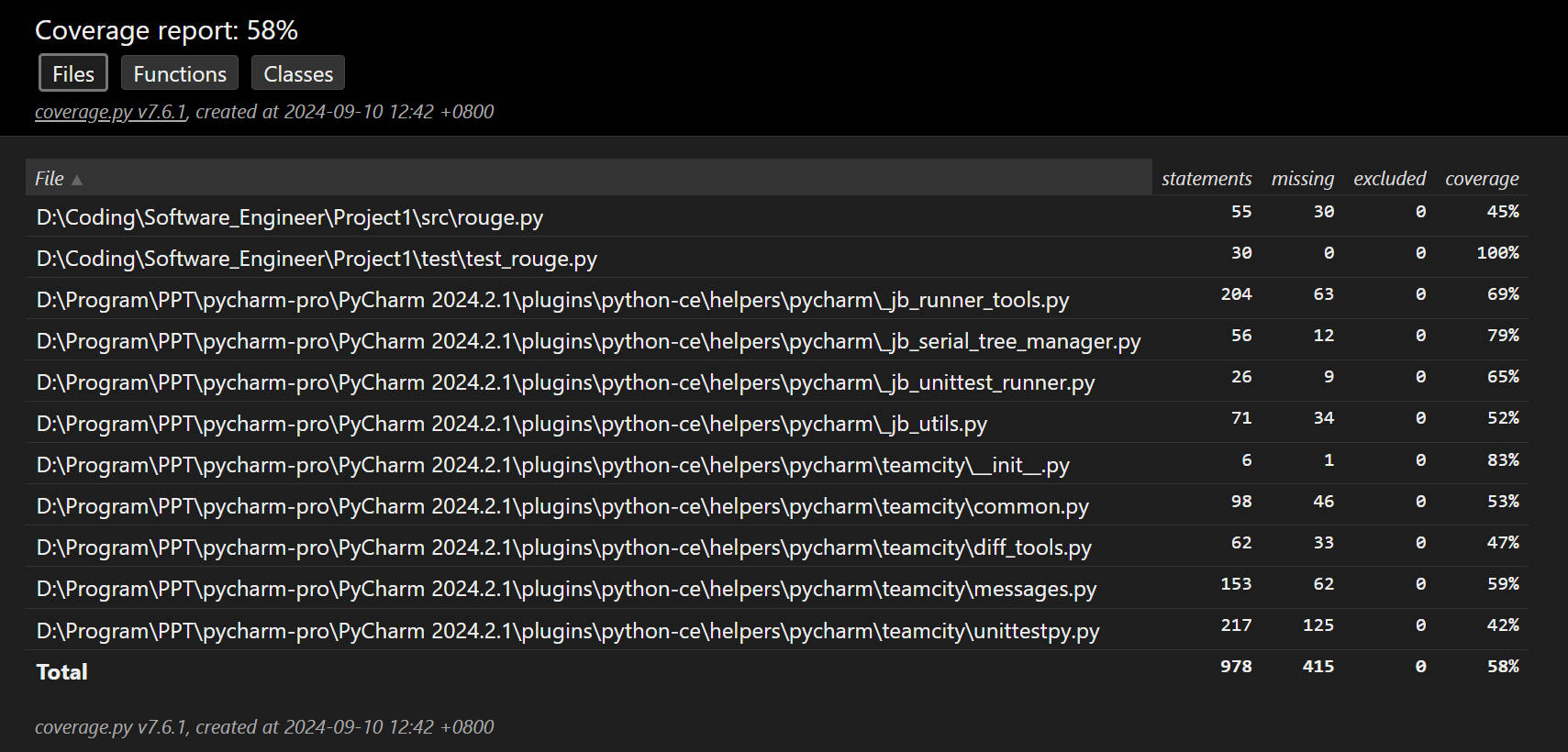
test_rouge.py | 输入均为空字典 | 输入数据不匹配 | 合法正例 | 58% |
测试函数的设计
由于测试函数和测试类过多,下面仅以BLEU计算的测试函数为例,介绍测试函数的设计,其余测试大同小异。
对于BLEU计算模块,他的基本特点如下:
| 特征 | 说明 |
|---|---|
| 函数功能 | 使用n-gram算法计算两段文本的BLEU相似度 |
| 输入 | 两个序列,分别代表两段文本 |
| 输入的数据类型 | 均为字典,其中他们的键必须相同,值必须为单字符串列表 |
| 输出 | 文本的BLEU相似度、每个句子的BLEU平均得分、BLEU得分字典 |
针对BLEU计算模块的基本特点,在下面的代码块中,我们设计了 5 个测试函数,囊括了 3 个基本等价类,从而能够对输入为空的情况、输入数据类型、正例进行严密的测试。当然,这次作业的目的是熟悉工具的使用,因此并不会对测试的完整性、异常情况处理等进行很仔细的讨论和实施,实际的开发过程应该要比当前情况严谨的多。
测试函数的说明与构造思路
test_corpus_bleu_empty:该测试函数测试输入数据为空的情况,旨在测试原函数的输入检验模块。当函数的输入为空,意味着比较的文本是不存在的,在BLEU计算中会出现除数为 0 的情况。这是程序中的异常情况,因此应当采用assertRaises输出提示信息,并且抛出异常。test_corpus_bleu_ID_incorrect:该测试函数测试输入数据类型错误的情况。当函数的输入不是字典,意味着预处理后的数据存在问题,而这个问题可能与当前模块无关。这是程序中的异常情况,因此应当采用assertRaises输出提示信息,并且抛出异常。test_corpus_bleu_right:测试正例。当两个的输入完全一致,意味着文本的相似度为 100%,程序应输出相似度1。test_corpus_bleu_ID_incorrect2:该测试函数测试输入数据存在键值对错误的情况,旨在测试原函数的输入检验模块。当函数的输入存在多个 hypothesis 和 reference 的 ID 相同,即键的数量不匹配,某个输入多了或者少了,意味着预处理后的数据存在问题,而这个问题可能与当前模块无关。这是程序中的异常情况,因此应当采用assertRaises输出提示信息,并且抛出异常。test_corpus_bleu_hyp_list_incorrect:该测试函数测试输入数据类型错误的情况,对第二个测试函数进行补充。
测试代码
import unittest
import sys
sys.path.append('..')
from src.google_bleu import corpus_bleu, compute_bleu
class TestGetVocab(unittest.TestCase):
def test_corpus_bleu_empty(self):
"""
空
"""
hypothesis = {}
references = {}
self.assertRaises(ZeroDivisionError, corpus_bleu, hypothesis, references)
def test_corpus_bleu_ID_incorrect(self):
"""
数据类型错误
"""
hypothesis = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
references = {
'id3': ['This is a test.'],
'id4': ['This is another test.']
}
self.assertRaises(AssertionError, corpus_bleu, hypothesis, references)
def test_corpus_bleu_right(self):
"""
正例
"""
hypothesis = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
references = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
bleu, avg_score, ind_score = corpus_bleu(hypothesis, references)
self.assertEqual(bleu, 1.0)
self.assertEqual(avg_score, 1.0)
self.assertEqual(ind_score, {'id1': 1.0, 'id2': 1.0})
def test_corpus_bleu_ID_incorrect2(self):
"""
存在多个 hypothesis 和 reference 的 ID 相同
"""
hypothesis = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
references = {
'id1': ['This is a test.'],
'id2': ['This is another test.'],
'id3': ['This is a different test.']
}
self.assertRaises(AssertionError, corpus_bleu, hypothesis, references)
def test_corpus_bleu_hyp_list_incorrect(self):
"""
hypothesis 和 reference 的 数量不匹配
"""
hypothesis = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
references = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
hyp_list = [hypothesis['id1']]
ref_list = [references['id1'], references['id2']]
self.assertRaises(AttributeError, corpus_bleu, hyp_list, ref_list)
测试覆盖率截图
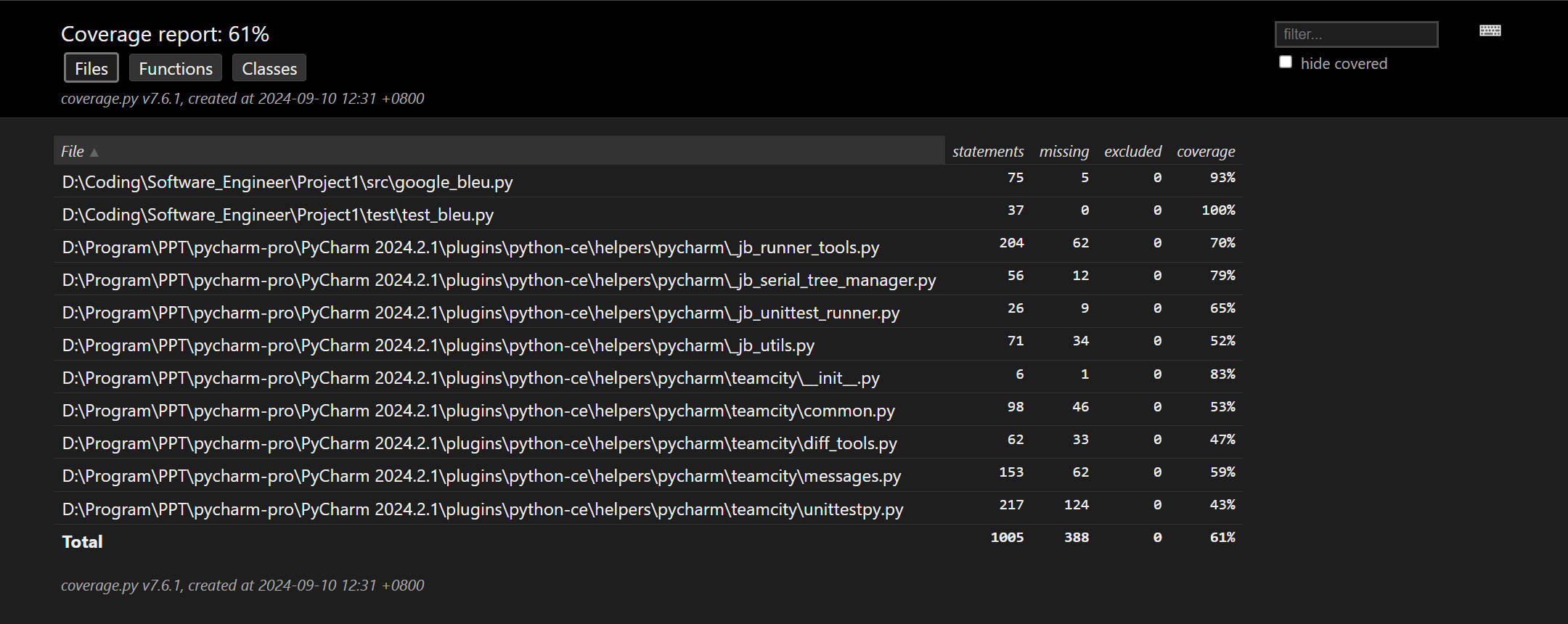
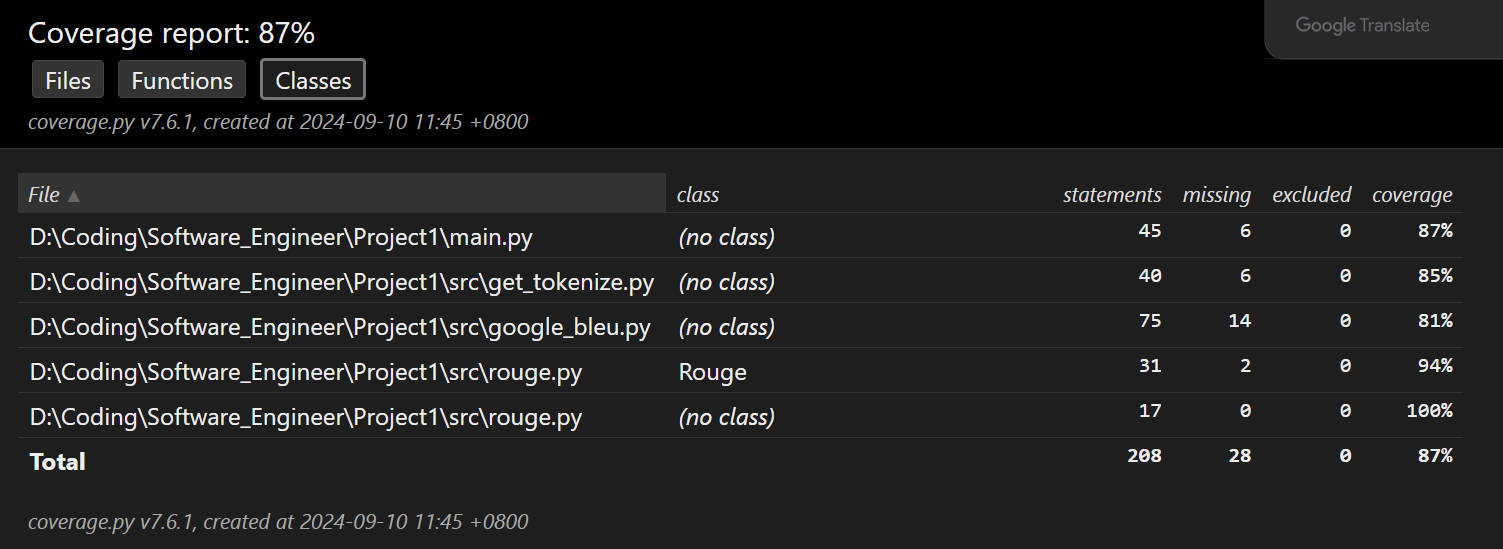
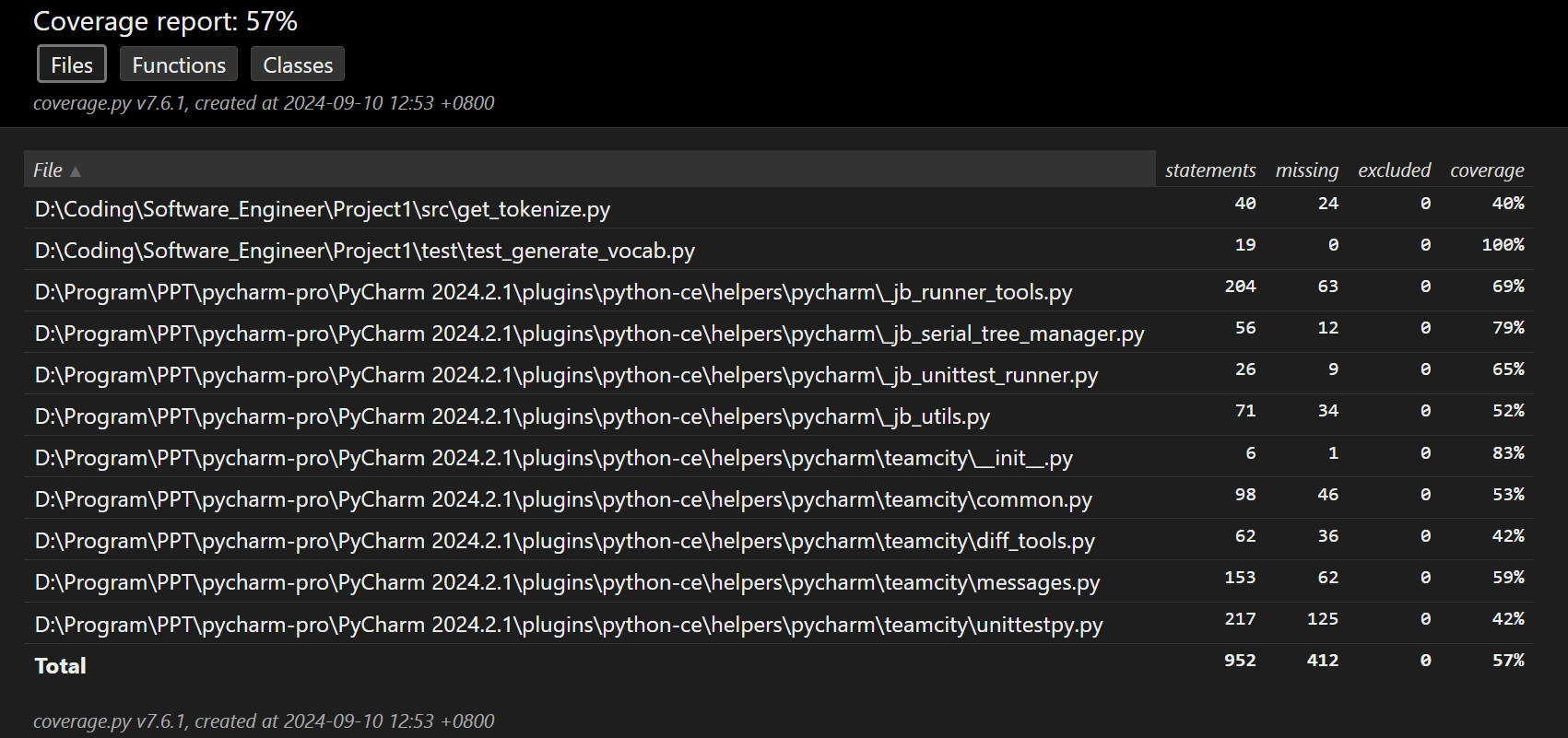
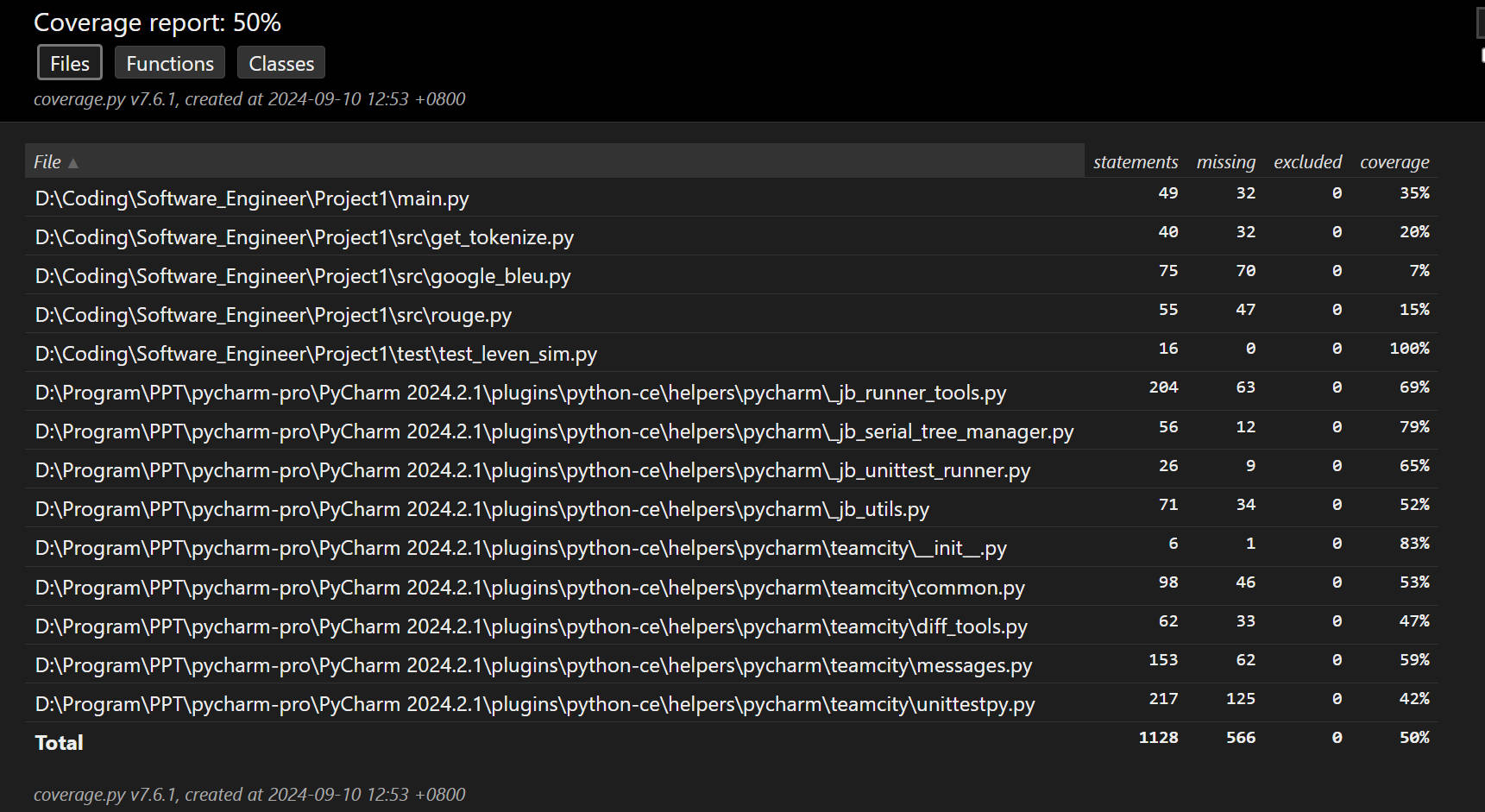
五、异常处理
异常处理设计
对于程序中可能出现的异常,我们为了保证程序的继续执行,往往将异常抛出的同时执行一系列的异常处理代码。对于作业,相对来说不需要太严谨,因此我这里只将异常抛出即可。因为异常处理涉及的模块较多,这里以以BLEU计算模块为例,介绍设计思路
1. AttributeError
设计目标
当输入错误的数据类型,将报错信息引出,同时让用户修改数据类型或者将当前数据改为正确类型的数据。
单元测试样例
def test_corpus_bleu_ID_incorrect(self):
"""
数据类型错误
"""
hypothesis = {
'id1': 'This is a test.',
'id2': ['This is another test.']
}
references = {
'id3': ['This is a test.'],
'id4': ['This is another test.']
}
self.assertRaises(AssertionError, corpus_bleu, hypothesis, references)
错误对应场景
输入的数据中存在不是字典的数据。当输入错误的数据类型,原程序执行到Ids = list(hypotheses.keys())这一句,程序会引发AttributeError异常,我们拿到这样的数据,说明前面的代码存在问题,因此我们将报错信息引出,同时让用户修改数据类型或者将当前数据改为正确类型的数据。
2. ZeroDivisionError
设计目标
当输入为空,将报错信息引出,同时让用户重新输入
单元测试样例
def test_corpus_bleu_ID_incorrect(self):
"""
数据类型错误
"""
hypothesis = {
'id1': 'This is a test.',
'id2': ['This is another test.']
}
references = {
'id3': ['This is a test.'],
'id4': ['This is another test.']
}
self.assertRaises(AssertionError, corpus_bleu, hypothesis, references)
错误对应场景
当输入为空,除法的除数变成 0 ,引发异常。说明前面的代码存在问题,因此我们将报错信息引出,同时让用户重新输入
3. AssertionError
设计目标
当输入的数据键值对不匹配,将报错信息引出,同时让用户检查输入
单元测试样例
def test_corpus_bleu_ID_incorrect2(self):
"""
存在多个 hypothesis 和 reference 的 ID 相同
"""
hypothesis = {
'id1': ['This is a test.'],
'id2': ['This is another test.']
}
references = {
'id1': ['This is a test.'],
'id2': ['This is another test.'],
'id3': ['This is a different test.']
}
self.assertRaises(AssertionError, corpus_bleu, hypothesis, references)
错误对应场景
当输入的数据键值对不匹配,会引发AssertionError异常,我们拿到这样的数据,首先输出错误信息,然后让用户检查输入。
六、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 15 | 8 |
| · Estimate | · 估计这个任务需要多少时间 | 15 | 8 |
| Development | 开发 | 190 | 201 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 14 |
| · Design Spec | · 生成设计文档 | 20 | 12 |
| · Design Review | · 设计复审 | 10 | 6 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 10 | 18 |
| · Design | · 具体设计 | 20 | 14 |
| · Coding | · 具体编码 | 40 | 63 |
| · Code Review | · 代码复审 | 20 | 12 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 40 | 62 |
| Reporting | 报告 | 160 | 138 |
| · Test Repor | · 测试报告 | 60 | 121 |
| · Size Measurement | · 计算工作量 | 10 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 90 | 12 |
| 合计 | 365 | 347 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号