
第二次结对编程作业
第二次结对编程作业
1.博客及仓库地址
2.具体分工
李至恒:python写AI
蔡嘉懿:UI界面,AI与服务器的接口
3.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| Estimate | 估计这个任务需要多少时间 | 10 | 10 |
| Development | 开发 | 480 | 800 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 20 | 30 |
| Design Review | 设计复审 | 30 | 45 |
| Coding Standard | 代码规范(为开发制定合适的规范) | 15 | 25 |
| Design | 具体设计 | 100 | 110 |
| Coding | 具体编码 | 120 | 180 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 150 | 200 |
| Reporting | 报告 | 40 | 60 |
| Test Repor | 测试报告 | 10 | 10 |
| Size Measurement | 计算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| Total | 总计 | 1135 | 1705 |
4.解题思路描述和设计实现说明
1.网络接口的使用
- 注册+绑定
def register(self):
def register_(user, psw, num, numpsw):
url = 'http://api.revth.com/auth/register2'
headers = {
'Content-Type': 'application/json'
}
data = {
"username": user,
"password": psw,
"student_number": num,
"student_password": numpsw
}
r = requests.post(url,headers=headers,data=json.dumps(data))
return r
r =register_(self.user,self.psw,self.num,self.numpsw)
status = r.json()['status']
if status == 0 and 'user_id' in r.json()['data']:
self.user_id = r.json()['data']['user_id']
self.is_register = True
print('register successful')
print(r.text)
else:
print('register failed!')
report(status)
print(r.text)
- 登录
def login(self):
def login_(user, psw):
url = "http://api.revth.com/auth/login"
headers = {
'content-type': 'application/json'
}
data = {
"username": user,
"password": psw
}
r = requests.post(url, data=json.dumps(data), headers=headers)
return r
r = login_(self.user, self.psw)
status = r.json()['status']
if status == 0 and 'user_id' in r.json()['data']:
self.user_id = r.json()['data']['user_id']
self.token = r.json()['data']['token']
self.logged = True
print('Login successful')
print(r.text)
else:
print('login failed!')
report(status)
print(r.text)
- 注销
def logout(self):
def logout_(token):
url = "http://api.revth.com/auth/logout"
headers = {
'x-auth-token': token
}
r = requests.post(url, headers=headers)
return r
r = logout_(self.token)
status = r.json()['status']
if status == 0:
self.logged = False
print('Logout successful')
print(r.text)
else:
print('logout failed!')
report(status)
print(r.text)
- 开始战局
def getCard(self):
url = 'http://api.revth.com/game/open'
headers = {'X-Auth-Token': self.token}
response = requests.post(url, headers=headers)
response_dict = response.json()
status = response_dict['status']
if (status == 0):
self.roomid = response_dict['data']['id']
card = response_dict['data']['card'].split(' ')
self.cards = card
else:
print('getCard Failed!')
print(response.text)
return card
- 历史战绩
def get_history(self, page, limit, play_id):
def history(token, page, limit, play_id):
url = "http://api.revth.com/history"
querystring = {
"page": page,
"limit": limit,
"player_id": play_id
}
headers = {
'x-auth-token': token
}
r = requests.get(url, headers=headers, params=querystring)
return r
data = []
r = history(self.token, page, limit, play_id)
status = r.json()['status']
if status == 0:
data = r.json()['data']
else:
print('get_history failed!')
report(status)
print(r.text)
print(data)
- 获取排行榜
def get_rank(self):
url = "http://api.revth.com/rank"
r = requests.get(url)
print(r.text)
2.类图
3.算法的关键与关键实现部分流程图
个人在熟悉规则后第一个关于算法的想法是
- 后墩尽可能大
- 中墩也越大越好
- 前墩也越大越好
只要足够大,打枪就追不上我
本着这个想法,很容易让人想到贪心算法,这也是我的第一版代码,就是传入牌型,按照从大到小判断牌型,将牌从大到小,从前往后排序
但是很快就发现实现起来有难度,而且我也感觉到这个算法不够智能
所以在队友的帮助下去看了权值矩阵
所以确定了最终算法(其实也是从大佬那里看来的算法,但是这也是没办法的,因为上个班的事情已经证明了这个算法是最优解,留给我们的发挥空间也不多了......)
5.关键代码解释
取最高权重算法,在外层有一个循环用来选出分数最大的牌型并将得分最大的牌型填入output链表中
for index_hou in range(len(list_2)):
#print("looping again")
#print(list_2[index])
list_2 = list(itertools.combinations(list_1,5))
score = 0
get_score(index_hou)
#print("score:%d" %score)
#print("score_max:%d" %score_max)
if(score > score_max):
score_max = score
##print("score_max:%d" %score_max) #这个可以优先取消注释
list_output[0] = list_qian[0]
list_output[1] = list_qian[1]
list_output[2] = list_qian[2]
list_output[3] = list_zhong[0]
list_output[4] = list_zhong[1]
list_output[5] = list_zhong[2]
list_output[6] = list_zhong[3]
list_output[7] = list_zhong[4]
list_output[8] = list_hou[0]
list_output[9] = list_hou[1]
list_output[10] = list_hou[2]
list_output[11] = list_hou[3]
list_output[12] = list_hou[4]
get_score算法其实应该最好是用递归写的,但是因为写的时候很着急而且只有2层循环,所以用了循环法,核心思想是先确定一个后墩牌,循环求出在该后墩牌为后墩的前提下中墩和前墩能取得的最高分数,将得分最高的牌型返回主函数,和最大得分值比较,分值高的被记录进output链表
同时其中有get_weight函数,用来计算各墩的权重,防止出现相公的情况。
def get_score(i):
score_max_private = 0
global score
global list_2
global list_2_backup
list_zhong_private = ['','','','','']
weight_hou = get_weight(i,0)
#print("后墩权重:%d" %weight_hou)
list_hou[0] = list_2[i][0]
list_hou[1] = list_2[i][1]
list_hou[2] = list_2[i][2]
list_hou[3] = list_2[i][3]
list_hou[4] = list_2[i][4]
#print("后墩牌:",end = "")
##print(list_hou)
#print("firstscore:%d" %score)
#print(list_input)
#list_copyright = copy.copy(list_hou)
list_copyright = list(set(list_input).difference(set(list_hou)))
list_copyright.sort(key=func_1)
#print(list_copyright)
#os.system("pause")
list_2 = list(itertools.combinations(list_copyright,5))
score_copyright = score
for index_zhong in range(len(list_2)):
score = score_copyright
list_2 = list(itertools.combinations(list_copyright,5))
#print(len(list_2))
weight_zhong = get_weight(index_zhong,weight_hou)
#print("中墩权重:%d" %weight_zhong)
#print("secondscore:%d" %score)
if(weight_zhong>weight_hou):
score = 0
continue
list_zhong_private[0] = list_2[index_zhong][0]
list_zhong_private[1] = list_2[index_zhong][1]
list_zhong_private[2] = list_2[index_zhong][2]
list_zhong_private[3] = list_2[index_zhong][3]
list_zhong_private[4] = list_2[index_zhong][4]
#print("中墩牌private:",end = "")
#print(list_zhong_private)
list_copyright_backup = copy.copy(list_copyright)
list_copyright_backup = list(set(list_copyright).difference(set(list_zhong_private)))
list_copyright_backup.sort(key=func_1)
list_2_backup = list_copyright_backup
weight_qian = get_weight_qian()
#print("前墩权重:%d" %weight_qian)
#print(score)
if(weight_qian>weight_zhong):
continue
if(score>score_max_private):
score_max_private = score
#print("中墩权重:%d" %weight_zhong)
list_zhong[0] = list_zhong_private[0]
list_zhong[1] = list_zhong_private[1]
list_zhong[2] = list_zhong_private[2]
list_zhong[3] = list_zhong_private[3]
list_zhong[4] = list_zhong_private[4]
#print("中墩牌:",end = "")
#print(list_zhong)
#print("score_max_zhong:%d" %score_max_private)
list_qian[0] = list_2_backup[0]
list_qian[1] = list_2_backup[1]
list_qian[2] = list_2_backup[2]
#print("前墩牌:",end = "")
#print(list_qian)
#print("lastscore:%d" %score)
#print("_______________________")
score = score_max_private
(这一部分的代码写的真的不好看,里面很多变量的命名也很随意,基本是想到哪写到哪。因为最近在准备考试......基本是本着功能实现就好的想法写的,也没有去做重构,很抱歉)
6.性能分析与改进
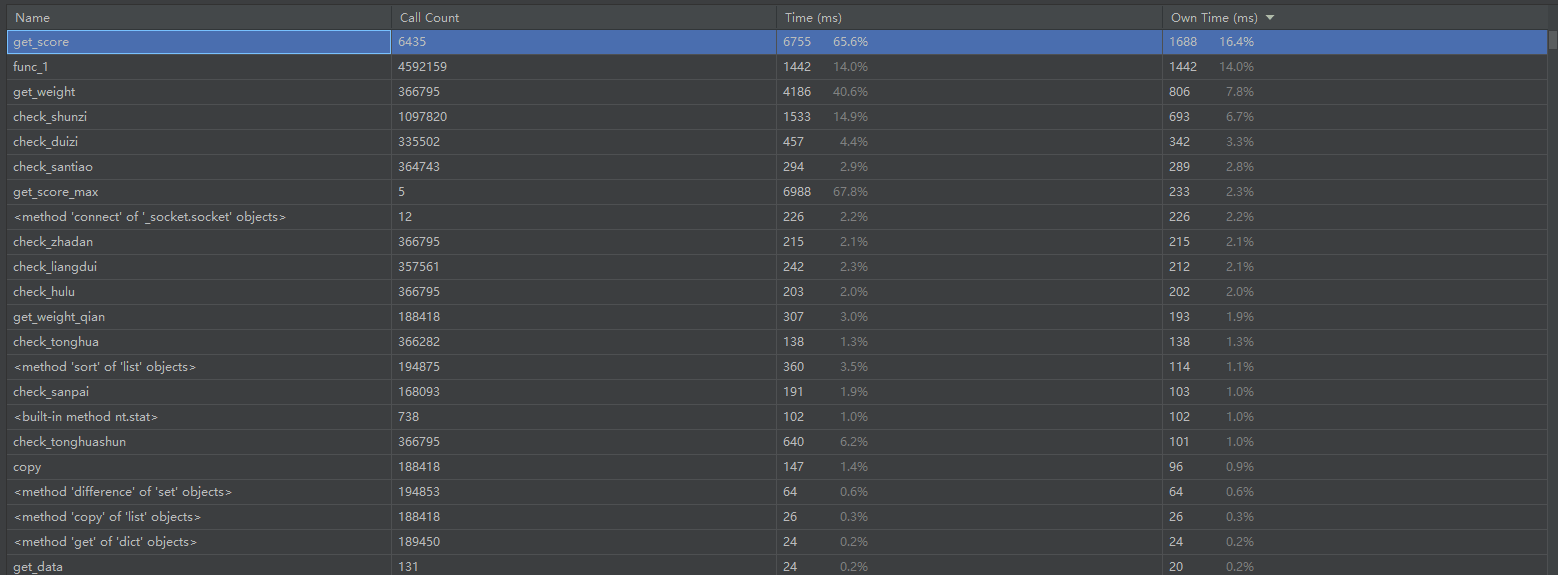
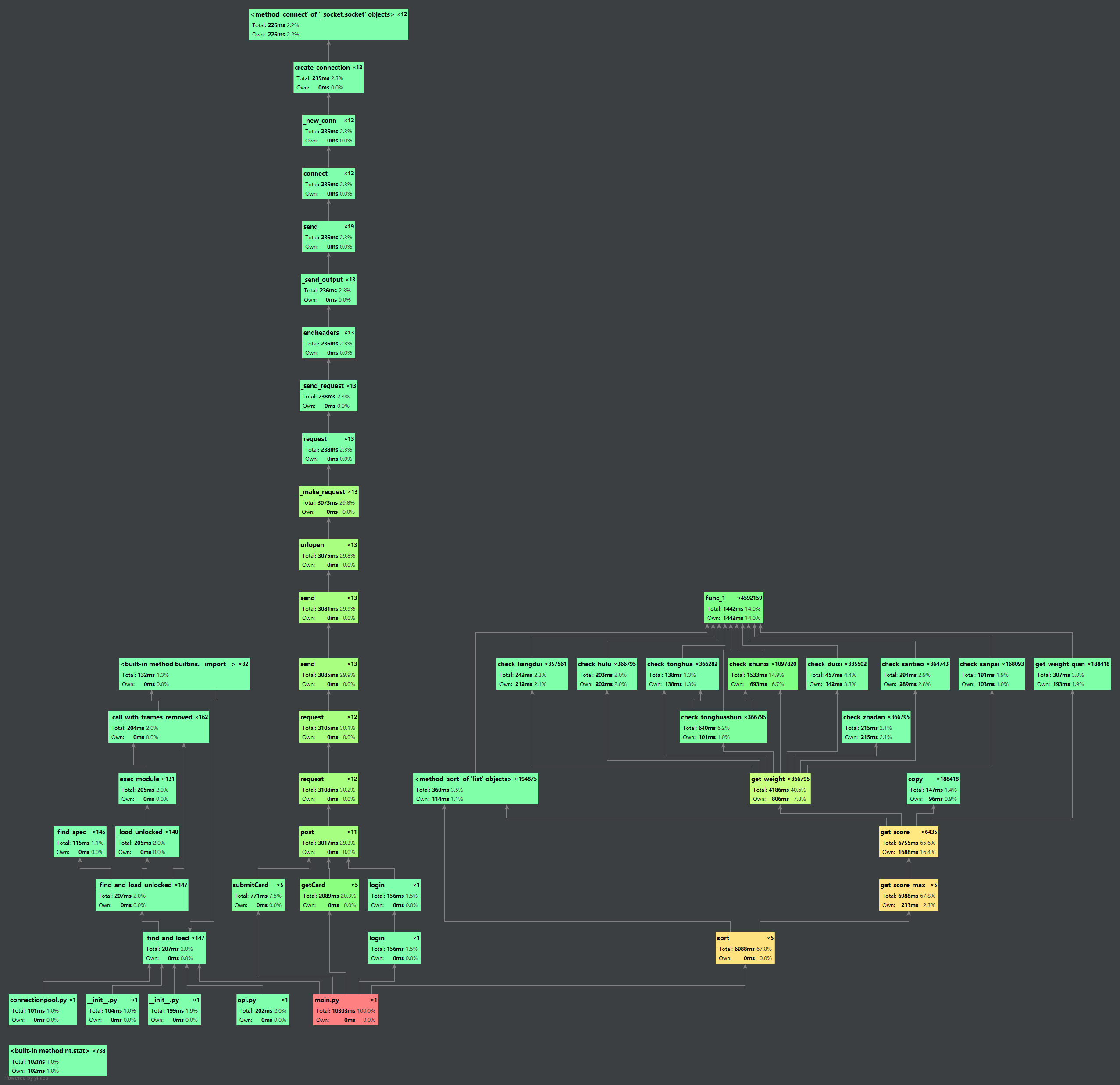
时间占比最高的函数为获取分数的函数,这是因为该函数会进行7w+的循环来找出最优牌组,而获取分数的函数里面占比最高的是func_1函数,这个函数主要是因为使用次数极多,这个的作用是在做数值计算的时候把K转换成12,A转换成13,Q转换成11,以此类推,我觉得这个函数很好的让我的编写过程变得愉快,因为元组一直在变换,就算用数值也要不停地做记录,我觉得并不能简化时间而且会增加内存,所以这是我目前能采用地最好策略。
7.单元测试
8.贴出github的代码迁入记录
9.遇到的代码异常或结对困难及解决方法
李至恒:
| 问题描述 | 做过哪些尝试 | 是否解决 | 有何收获 |
|---|---|---|---|
| 怎么设计出最优良的算法 | 贪心算法和权值矩阵 | 未完全解决 | 在算法这一块确实不如别人机灵,写出来的基本都是套用和平庸的作品 |
| 防止相公的情况出现 | 添加了weight值,让中墩的weight不能超过后墩,前墩不能超过中墩 | 基本解决 | 在服务器上跑了几百次基本没有出现相公的情况了 |
蔡嘉懿:
| 问题描述 | 做过哪些尝试 | 是否解决 | 有何收获 |
|---|---|---|---|
| 刚开始不会调用api | 网络搜索加问询同学 | 解决 | 学会了api的调用,有助于以后软件设计 |
| pygame初学,很多概念不懂 | 学些了网络的教程 | 基本解决 | 学习了pygame一些前端知识,掌握了一些基本技能 |
10.评价你的队友
李至恒
队友真的干了很多很多活,本来后端应该也要做接口这一块的,但是他为了让我专心去搞算法把这个的活一起拿走了
蔡嘉懿
队友算法真的顶,分数拿的很高,因为考试原因时间不够我ui部分没做完整,很愧疚对不起队友。
学习进度条
| 第N周 | 新增代码(行) | 累计代码(行) | 本周学习耗时(小时) | 累计学习耗时(小时) | 重要成长 |
|---|---|---|---|---|---|
| 1 | 0 | 0 | 13 | 13 | 学习了axcure RP的使用。 |
| 2 | 300 | 300 | 8 | 18 | 确定了基本的后端算法,如何分牌型,如何组牌 |
| 3 | 0 | 0 | 20 | 38 | 推翻了原本的贪心算法,重构了代码并进行了测试和调错,代码量没有本质增加,但是做的活不少 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号