哈希集unordered_set - 用法
哈希集是集合的实现之一,它是一种存储不重复值的数据结构。
我们提供了在 Java,C++ 和 Python 中使用哈希集的示例。 如果你不熟悉哈希集的用法,那么通过这一示例将会很有帮助。
#include<unordered_set> using namespace std; int main() { unordered_set<int>hashset; hashset.insert(3); hashset.insert(2); hashset.insert(1); //delete a key hashset.erase(2); //check if the key is in the hash set if(hashset.count(2)<=0) { cout<<"2 is not in the hashset"<<endl; } //get the size of the hash set cout<<"the size of the hashset is "<<hashset.size()<<endl; //iterate the hashset for(auto it=hashset.begin();it!=hashset.end();it++) { cout<<(*it)<<endl; } //clear the hashset hashset.clear(); //check if the hash set is empty if(hashset.empty()) cout<<"hashset is empty now"<<endl; }
unordered_set可以把它想象成一个集合,它提供了几个函数让我们可以增删查:
unordered_set::insert
unordered_set::find
unordered_set::erase
这个unorder暗示着,这两个头文件中类的底层实现----Hash。 也是因为如此,你才可以在声明这些unordered模版类的时候,传入一个自定义的哈希函数,准确的说是哈希函数子(hash function object)。
单向迭代器
哈希表的实现复杂了该容器上的双向遍历,似乎没有一种合适的方法能够做到高效快速。 因此,unorder版本的map和set只提供前向迭代器(非unorder版本提供双向迭代器)。
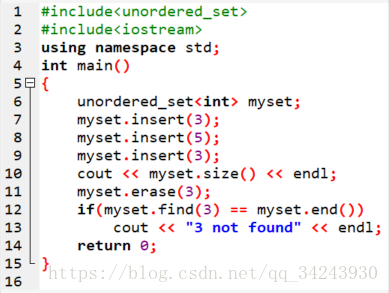
首先要include这个unordered_set头文件。
然后就是第六行我们定义了一个整型int的集合,叫myset。
后面几行,我们演示了insert/find/erase的用法。
有两点需要注意:
一是这个容器是个集合,所以重复插入相同的值是没有效果的。大家可以看到我们这里第7行和第9行插入了2次3,实际上这个集合里也只有1个3,第10行输出的结果是2。
二是find的返回值是一个迭代器(iterator),如果找到了会返回指向目标元素的迭代器,没找到会返回end()。
对于unordered_set,insert/find/erase的平均复杂度是O(1),但是最坏复杂度是O(N)的,这里N是指容器中元素数量。
有两种情况会出现O(N)复杂度。
1是你的哈希函数太烂了,导致很多不同元素的哈希值都相同,全是碰撞,这种情况复杂度会变成O(N)。但是这种情况一般不用担心,因为对于string以及int double之类的基本数据类型,都有默认的哈希函数,而且默认的哈希函数足够好,不会退化到O(N)。如果是你自定义的哈希函数,那你要小心一点,别写的太差了。
2是如果insert很多数据,会触发rehash。就是整个哈希表重建。这个过程有点类似向vector里不断添加元素,vector会resize。比如你新建一个vector时,它可能只申请了一块最多保存10个元素的内存,当你插入第11个元素的时候,它会自动重新申请一块更大空间,比如能存下20个元素。哈希表也是类似,不过rehash不会频繁发生,均摊复杂度还是O(1)的,也不用太担心
=key") 得到key对应的key-value,这样就能完成统计某个年龄的员工个数。而在这个例子中,也存在这样一个问题,两个员工的年龄相同,但其他信息(如:名字、身份证)不同,通过前面说的哈希函数,会发现其都位于数组的相同位置,这里,就涉及到“冲突”。准确来说,冲突是不可避免的,而解决冲突的方法常见的有:开发地址法、再散列法、链地址法(也称拉链法)。而unordered_set内部解决冲突采用的是----链地址法,当用冲突发生时把具有同一关键码的数据组成一个链表。下图展示了链地址法的使用:
得到key对应的key-value,这样就能完成统计某个年龄的员工个数。而在这个例子中,也存在这样一个问题,两个员工的年龄相同,但其他信息(如:名字、身份证)不同,通过前面说的哈希函数,会发现其都位于数组的相同位置,这里,就涉及到“冲突”。准确来说,冲突是不可避免的,而解决冲突的方法常见的有:开发地址法、再散列法、链地址法(也称拉链法)。而unordered_set内部解决冲突采用的是----链地址法,当用冲突发生时把具有同一关键码的数据组成一个链表。下图展示了链地址法的使用:unordered_set
- template < class Key,
- class Hash = hash<Key>,
- class Pred = equal_to<Key>,
- class Alloc = allocator<Key>
- > class unordered_set;
C++ 11中对unordered_set描述大体如下:无序集合容器(unordered_set)是一个存储唯一(unique,即无重复)的关联容器(Associative container),容器中的元素无特别的秩序关系,该容器允许基于值的快速元素检索,同时也支持正向迭代。
hash<Key>
- 整型值:bool、char、unsigned char、wchar_t、char16_t、char32_t、short、int、long、long long、unsigned short、unsigned int、unsigned long、unsigned long long。上述的基本数据类型,其标准库提供的hash函数只是简单将其值转换为一个size_t类型值,具体可以参考标准库functional_hash.h头文件,如下所示:
对于指针类型,标准库只是单一将地址转换为一个size_t值作为hash值,这里特别需要注意的是char *类型的指针,其标准库提供的hash函数只是将指针所指地址转换为一个sieze_t值,如果,你需要用char *所指的内容做hash,那么,你需要自己写hash函数或者调用系统提供的hash<string>。
- /// Primary class template hash.
- template<typename _Tp>
- struct hash;
- /// Partial specializations for pointer types.
- template<typename _Tp>
- struct hash<_Tp*> : public __hash_base<size_t, _Tp*>
- {
- size_t
- operator()(_Tp* __p) const noexcept
- { return reinterpret_cast<size_t>(__p); }
- };
- // Explicit specializations for integer types.
- #define _Cxx_hashtable_define_trivial_hash(_Tp) \
- template<> \
- struct hash<_Tp> : public __hash_base<size_t, _Tp> \
- { \
- size_t \
- operator()(_Tp __val) const noexcept \
- { return static_cast<size_t>(__val); } \
- };
- /// Explicit specialization for bool.
- _Cxx_hashtable_define_trivial_hash(bool)
- /// Explicit specialization for char.
- _Cxx_hashtable_define_trivial_hash(char)
- /// Explicit specialization for signed char.
- _Cxx_hashtable_define_trivial_hash(signed char)
- /// Explicit specialization for unsigned char.
- _Cxx_hashtable_define_trivial_hash(unsigned char)
- /// Explicit specialization for wchar_t.
- _Cxx_hashtable_define_trivial_hash(wchar_t)
- /// Explicit specialization for char16_t.
- _Cxx_hashtable_define_trivial_hash(char16_t)
- /// Explicit specialization for char32_t.
- _Cxx_hashtable_define_trivial_hash(char32_t)
- /// Explicit specialization for short.
- _Cxx_hashtable_define_trivial_hash(short)
- /// Explicit specialization for int.
- _Cxx_hashtable_define_trivial_hash(int)
- /// Explicit specialization for long.
- _Cxx_hashtable_define_trivial_hash(long)
- /// Explicit specialization for long long.
- _Cxx_hashtable_define_trivial_hash(long long)
- /// Explicit specialization for unsigned short.
- _Cxx_hashtable_define_trivial_hash(unsigned short)
- /// Explicit specialization for unsigned int.
- _Cxx_hashtable_define_trivial_hash(unsigned int)
- /// Explicit specialization for unsigned long.
- _Cxx_hashtable_define_trivial_hash(unsigned long)
- /// Explicit specialization for unsigned long long.
- _Cxx_hashtable_define_trivial_hash(unsigned long long)
- 标准库为string类型对象提供了一个hash函数,即:Murmur hash,。对于float、double、long double标准库也有相应的hash函数,这里,不做过多的解释,相应的可以参看functional_hash.h头文件。
- #include<bits\stdc++.h>
- using namespace std;
- struct myHash
- {
- size_t operator()(pair<int, int> __val) const
- {
- return static_cast<size_t>(__val.first * 101 + __val.second);
- }
- };
- int main()
- {
- unordered_set<pair<int, int>, myHash> S;
- int x, y;
- while (cin >> x >> y)
- S.insert(make_pair(x, y));
- for (auto it = S.begin(); it != S.end(); ++it)
- cout << it->first << " " << it->second << endl;
- return 0;
- }
equal_to<key>
- template<typename _Arg, typename _Result>
- struct unary_function
- {
- /// @c argument_type is the type of the argument
- typedef _Arg argument_type;
- /// @c result_type is the return type
- typedef _Result result_type;
- };
- template<typename _Tp>
- struct equal_to : public binary_function<_Tp, _Tp, bool>
- {
- bool
- operator()(const _Tp& __x, const _Tp& __y) const
- { return __x == __y; }
- };
扩容与缩容
。// unordered_set::find
#include <iostream>
#include <string>
#include <unordered_set>
int main ()
{
std::unordered_set<std::string> myset = { "red","green","blue" };
std::string input;
std::cout << "color? ";
getline (std::cin,input);
std::unordered_set<std::string>::const_iterator got = myset.find (input);
if ( got == myset.end() )
std::cout << "not found in myset";
else
std::cout << *got << " is in myset";
std::cout << std::endl;
return 0;
}
unordered_set与与unordered_map相似,这次主要介绍unordered_set
unordered_set它的实现基于hashtable,它的结构图仍然可以用下图表示,这时的空白格不在是单个value,而是set中的key与value的数据包
有unordered_set就一定有unordered_multiset.跟set和multiset一样,一个key可以重复一个不可以
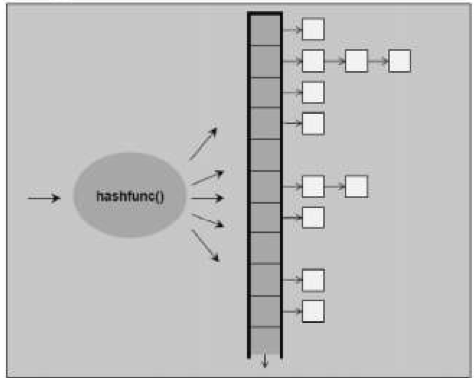
unordered_set是一种无序集合,既然跟底层实现基于hashtable那么它一定拥有快速的查找和删除,添加的优点.基于hashtable当然就失去了基于rb_tree的自动排序功能
unordered_set无序,所以在迭代器的使用上,set的效率会高于unordered_set
注:
一是这个容器是个集合,所以重复插入相同的值是没有效果的。大家可以看到我们这里第7行和第9行插入了2次3,实际上这个集合里也只有1个3,第10行输出的结果是2。
二是find的返回值是一个迭代器(iterator),如果找到了会返回指向目标元素的迭代器,没找到会返回end()。
对于unordered_set,insert/find/erase的平均复杂度是O(1),但是最坏复杂度是O(N)的,这里N是指容器中元素数量。

-
template<class _Value,
-
class _Hash = hash<_Value>,
-
class _Pred = std::equal_to<_Value>,
-
class _Alloc = std::allocator<_Value> >
-
class unordered_set
-
: public __unordered_set<_Value, _Hash, _Pred, _Alloc>
-
{
-
typedef __unordered_set<_Value, _Hash, _Pred, _Alloc> _Base;
-
}
参数1 _Value key和value的数据包
参数2 _Hash hashfunc获取hashcode的函数
参数3 _Pred 判断key是否相等
参数4 分配器
下面介绍一下unordered_set的基本使用,最后我会分享一下我的测试代码
一 定义
-
//定义
-
unordered_set<int> c1;
-
//operator=
-
unordered_set<int> c2;
-
c2 = c1;
二 容量操作
-
//判断是否为空
-
c1.empty();
-
//获取元素个数 size()
-
c1.size();
-
//获取最大存储量 max_size()
-
c1.max_size();
三 迭代器操作
-
//返回头迭代器 begin()
-
unordered_set<int>::iterator ite_begin = c1.begin();
-
//返回尾迭代器 end()
-
unordered_set<int>::iterator ite_end = c1.end();
-
//返回const头迭代器 cbegin()
-
unordered_set<int>::const_iterator const_ite_begin = c1.cbegin();
-
//返回const尾迭代器 cend()
-
unordered_set<int>::const_iterator const_ite_end = c1.cend();
-
//槽迭代器
-
unordered_set<int>::local_iterator local_iter_begin = c1.begin(1);
-
unordered_set<int>::local_iterator local_iter_end = c1.end(1);
四 基本操作
-
//查找函数 find() 通过给定主键查找元素
-
unordered_set<int>::iterator find_iter = c1.find(1);
-
//value出现的次数 count() 返回匹配给定主键的元素的个数
-
c1.count(1);
-
//返回元素在哪个区域equal_range() 返回值匹配给定搜索值的元素组成的范围
-
pair<unordered_set<int>::iterator, unordered_set<int>::iterator> pair_equal_range = c1.equal_range(1);
-
//插入函数 emplace()
-
c1.emplace(1);
-
//插入函数 emplace_hint() 使用迭代器
-
c1.emplace_hint(ite_begin, 1);
-
//插入函数 insert()
-
c1.insert(1);
-
//删除 erase()
-
c1.erase(1);//1.迭代器 value 区域
-
//清空 clear()
-
c1.clear();
-
//交换 swap()
-
c1.swap(c2);
五 篮子操作
-
//篮子操作 篮子个数 bucket_count() 返回槽(Bucket)数
-
c1.bucket_count();
-
//篮子最大数量 max_bucket_count() 返回最大槽数
-
c1.max_bucket_count();
-
//篮子个数 bucket_size() 返回槽大小
-
c1.bucket_size(3);
-
//返回篮子 bucket() 返回元素所在槽的序号
-
c1.bucket(1);
-
// load_factor 返回载入因子,即一个元素槽(Bucket)的最大元素数
-
c1.load_factor();
-
// max_load_factor 返回或设置最大载入因子
-
c1.max_load_factor();
六 内存操作
-
// rehash 设置槽数
-
c1.rehash(1);
-
// reserve 请求改变容器容量
-
c1.reserve(1000);
七 hash func
-
//hash_function() 返回与hash_func相同功能的函数指针
-
auto hash_func_test = c1.hash_function();
-
//key_eq() 返回比较key值得函数指针

 浙公网安备 33010602011771号
浙公网安备 33010602011771号