哈希表
哈希表是一种使用哈希函数组织数据,以支持快速插入和搜索的数据结构。
有两种不同类型的哈希表:哈希集合和哈希映射。
哈希集合是集合数据结构的实现之一,用于存储非重复值。哈希映射是映射数据结构的实现之一,用于存储(key, value)键值对。
在标准模板库的帮助下,哈希表是易于使用的。大多数常见语言(如Java,C ++ 和 Python)都支持哈希集合和哈希映射。
哈希表的原理
正如我们在介绍中提到的,哈希表是一种数据结构,它使用哈希函数组织数据,以支持快速插入和搜索。在本文中,我们将简要说明哈希表的原理。
哈希表的原理
哈希表的关键思想是使用哈希函数将键映射到存储桶。更确切地说,
- 当我们插入一个新的键时,哈希函数将决定该键应该分配到哪个桶中,并将该键存储在相应的桶中;
- 当我们想要搜索一个键时,哈希表将使用相同的哈希函数来查找对应的桶,并只在特定的桶中进行搜索。
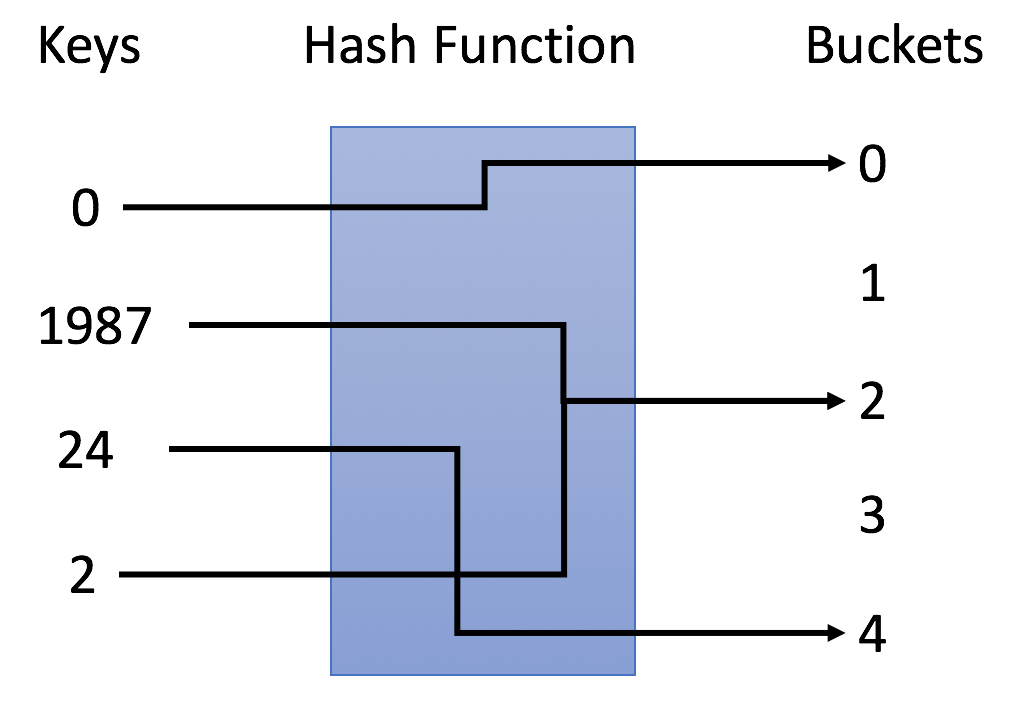
示例
![]()
在示例中,我们使用
y = x % 5作为哈希函数。让我们使用这个例子来完成插入和搜索策略:- 插入:我们通过哈希函数解析键,将它们映射到相应的桶中。
- 例如,1987 分配给桶 2,而 24 分配给桶 4。
- 搜索:我们通过相同的哈希函数解析键,并仅在特定存储桶中搜索。
- 如果我们搜索 1987,我们将使用相同的哈希函数将1987 映射到 2。因此我们在桶 2 中搜索,我们在那个桶中成功找到了 1987。
- 例如,如果我们搜索 23,将映射 23 到 3,并在桶 3 中搜索。我们发现 23 不在桶 3 中,这意味着 23 不在哈希表中。
设计哈希表的关键
在设计哈希表时,你应该注意两个基本因素。
1. 哈希函数
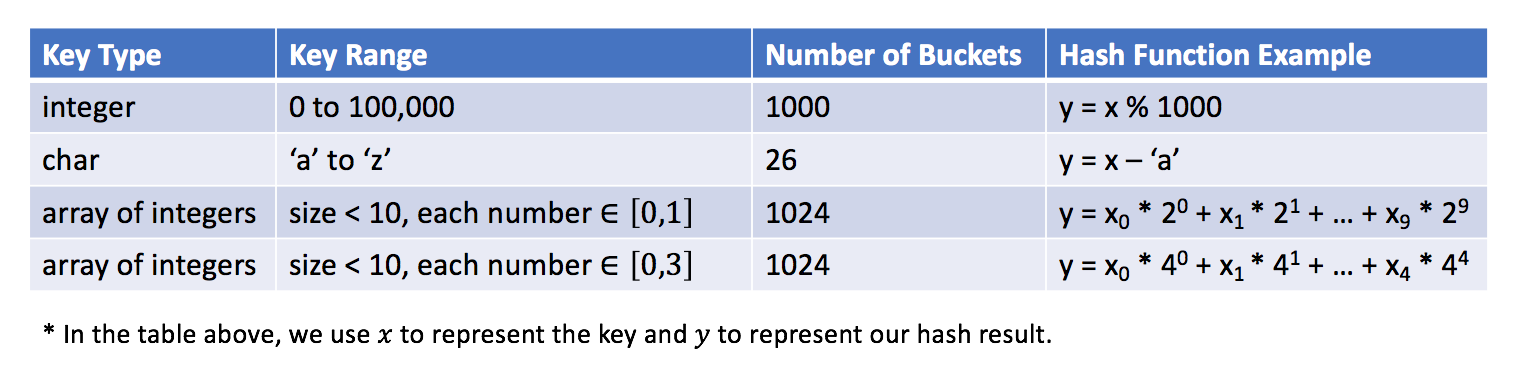
哈希函数是哈希表中最重要的组件,该哈希表用于将键映射到特定的桶。在上一篇文章中的示例中,我们使用
y = x % 5作为散列函数,其中x是键值,y是分配的桶的索引。散列函数将取决于
键值的范围和桶的数量。下面是一些哈希函数的示例:
![]()
哈希函数的设计是一个开放的问题。其思想是尽可能将键分配到桶中,理想情况下,完美的哈希函数将是键和桶之间的一对一映射。然而,在大多数情况下,哈希函数并不完美,它需要在桶的数量和桶的容量之间进行权衡。
2. 冲突解决
理想情况下,如果我们的哈希函数是完美的一对一映射,我们将不需要处理冲突。不幸的是,在大多数情况下,冲突几乎是不可避免的。例如,在我们之前的哈希函数(y = x % 5)中,1987 和 2 都分配给了桶 2,这是一个
冲突。冲突解决算法应该解决以下几个问题:
- 如何组织在同一个桶中的值?
- 如果为同一个桶分配了太多的值,该怎么办?
- 如何在特定的桶中搜索目标值?
根据我们的哈希函数,这些问题与
桶的容量和可能映射到同一个桶的键的数目有关。让我们假设存储最大键数的桶有
N个键。通常,如果 N 是常数且很小,我们可以简单地使用一个数组将键存储在同一个桶中。如果 N 是可变的或很大,我们可能需要使用
高度平衡的二叉树来代替.。插入和搜索是哈希表中的两个基本操作。此外,还有基于这两个操作的操作。例如,当我们
删除元素时,我们将首先搜索元素,然后在元素存在的情况下从相应位置移除元素。复杂度分析 - 哈希表
在本文中,我们将讨论哈希表的性能。
复杂度分析
如果总共有
M个键,那么在使用哈希表时,可以很容易地达到O(M)的空间复杂度。但是,你可能已经注意到哈希表的时间复杂度与设计有很强的关系。
我们中的大多数人可能已经在每个桶中使用
数组来将值存储在同一个桶中,理想情况下,桶的大小足够小时,可以看作是一个常数。插入和搜索的时间复杂度都是O(1)。但在最坏的情况下,桶大小的最大值将为
N。插入时时间复杂度为O(1),搜索时为O(N)。内置哈希表的原理
内置哈希表的典型设计是:
- 键值可以是任何
可哈希化的类型。并且属于可哈希类型的值将具有哈希码。此哈希码将用于映射函数以获取存储区索引。 - 每个桶包含一个
数组,用于在初始时将所有值存储在同一个桶中。 - 如果在同一个桶中有太多的值,这些值将被保留在一个
高度平衡的二叉树搜索树中。
插入和搜索的平均时间复杂度仍为 O(1)。最坏情况下插入和搜索的时间复杂度是
O(logN),使用高度平衡的 BST。这是在插入和搜索之间的一种权衡。
- 插入:我们通过哈希函数解析键,将它们映射到相应的桶中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号