
JUC学习笔记(三):线程池和ForkJoin
-
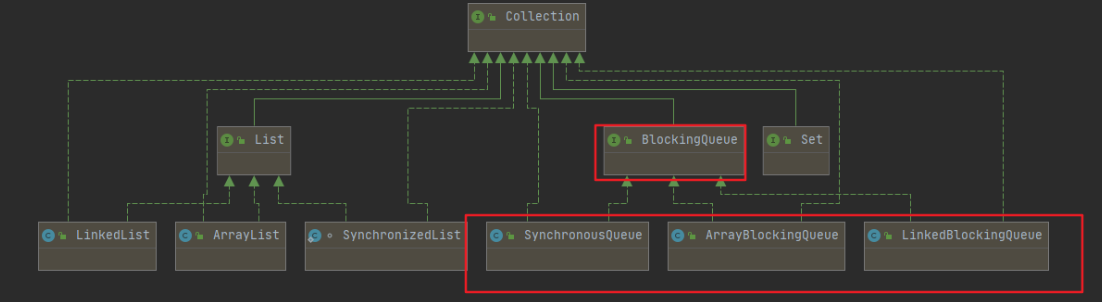
BlockingQueue
-
先进先出的数据结构。
-
写:如果队列满了,就必须阻塞等待消费。
-
取:如果队列是空的,就必须阻塞等待生产。
-
一般在多线程并发处理和线程池中使用。
-
有这些实现类,重要的是红色中的

-
继承结构其实和List类似
主要API
阻塞队列有4组API,其实就是添加、移除和查看队首元素的4组方法。
这4组方法面对无法执行的时候会有着不同的行为,可以根据业务需求去使用。
比如队列满了,无法添加元素的时候,add方法会抛出异常,offer则会返回false....
| 方式 | 抛出异常 | 有返回值 | 阻塞等待 | 超时等待 |
|---|---|---|---|---|
| 添加 | add | offer | put | offer(,int,TimeUnit) |
| 移除 | remove | poll | take | poll(int,TimeUnit) |
| 判断队列首 | element | peek |
-
抛出异常
//1.抛出异常 public static void test1(){ //实例化一个容纳3个元素的队列 ArrayBlockingQueue<Object> blockQueue = new ArrayBlockingQueue<>(3); //添加元素会返回true false System.out.println(blockQueue.add("A")); System.out.println(blockQueue.add("B")); System.out.println(blockQueue.add("C")); //添加第4个元素会抛出异常 :java.lang.IllegalStateException: Queue full // System.out.println(blockQueue.add("D")); //弹出元素会返回元素值 System.out.println(blockQueue.remove()); System.out.println(blockQueue.remove()); System.out.println(blockQueue.remove()); //空的集合再弹出元素会抛出异常: java.util.NoSuchElementException System.out.println(blockQueue.remove()); }
-
返回值
//2.不抛出异常给返回值 public static void test2(){ ArrayBlockingQueue<Object> blockQueue = new ArrayBlockingQueue<>(3); System.out.println(blockQueue.offer("A")); System.out.println(blockQueue.offer("B")); System.out.println(blockQueue.offer("C")); System.out.println(blockQueue.offer("D")); //不抛出异常,返回false System.out.println(blockQueue.element());//查看队首元素值,抛异常 System.out.println(blockQueue.poll()); System.out.println(blockQueue.element()); System.out.println(blockQueue.poll()); System.out.println(blockQueue.poll()); System.out.println(blockQueue.poll());//不抛出异常,返回null System.out.println(blockQueue.peek());//查看队首元素值,返回null System.out.println(blockQueue.element()); }
-
阻塞等待
//3.阻塞,一直等着直到队列中有空的位置 public static void test3() throws InterruptedException { ArrayBlockingQueue<String> blockQueue = new ArrayBlockingQueue<>(3); blockQueue.put("A"); blockQueue.put("B"); blockQueue.put("C"); // blockQueue.put("D");//会一直阻塞等待 System.out.println(blockQueue.take()); System.out.println(blockQueue.take()); System.out.println(blockQueue.take()); System.out.println(blockQueue.take());//会一直阻塞等待 }
-
超时等待
//超时退出 public static void test4() throws InterruptedException { ArrayBlockingQueue<String> blockQueue = new ArrayBlockingQueue<>(3); blockQueue.offer("A"); blockQueue.offer("B"); blockQueue.offer("C"); blockQueue.offer("D",2, TimeUnit.SECONDS); //等待超过两秒退出 System.out.println(blockQueue.poll()); System.out.println(blockQueue.poll()); System.out.println(blockQueue.poll()); System.out.println(blockQueue.poll(2,TimeUnit.SECONDS)); }
同步队列
-
同步队列:SynchronousQueue
-
实际上是AbstractQueue(非阻塞队列)的子类,但是又继承了BlockingQueue(阻塞队列)
public class SynchronousQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, Serializable
-
这个队列没有容量。
-
1个线程要往队列里插入内容,必须是有另一个往队列里删除内容的线程存在,两个线程共存才能插入、删除成功。否则无法插入,也没有元素可以删除( poll() 会返回 null)。
-
这个队列也不能迭代,因为没有容量。
package com.rzp.rw; import java.util.concurrent.SynchronousQueue; import java.util.concurrent.TimeUnit; //同步队列 public class SynchronousQueueDemo { public static void main(String[] args) { SynchronousQueue synchronousQueue = new SynchronousQueue(); new Thread(()->{ try { System.out.println(Thread.currentThread().getName()+"put 1"); synchronousQueue.put("1"); System.out.println(Thread.currentThread().getName()+"put 2"); synchronousQueue.put("2"); System.out.println(Thread.currentThread().getName()+"put 3"); synchronousQueue.put("3"); } catch (InterruptedException e) { e.printStackTrace(); } },"T1").start(); new Thread(()->{ try { TimeUnit.SECONDS.sleep(1); System.out.println(Thread.currentThread().getName()+"="+synchronousQueue.take()); TimeUnit.SECONDS.sleep(1); System.out.println(Thread.currentThread().getName()+"="+synchronousQueue.take()); TimeUnit.SECONDS.sleep(1); System.out.println(Thread.currentThread().getName()+"="+synchronousQueue.take()); } catch (InterruptedException e) { e.printStackTrace(); } },"T2").start(); } }
线程池
池化技术
-
程序的运行,本质就是占用系统的资源,为了优化资源的使用,就出现了池化技术。
-
线程池、连接池、内存池、对象池。。。
-
池化技术:因为开启和关闭特别消耗资源,池化技术的核心就是事先准备好一定的资源,需要用的时候在这里取,用完以后再还回去。
好处
-
因为减少了创建和关闭资源的行为,因此:
-
降低资源的消耗
-
提高响应的速度
-
方便管理
-
-
线程复用,可以控制最大并发数,管理线程。
阿里巴巴
-
摘自阿里巴巴开发手册
【强制】线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
说明:Executors 返回的线程池对象的弊端如下:
1)FixedThreadPool 和 SingleThreadPool :
允许的请求队列长度为 Integer.MAX_VALUE(约为21亿),可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool 和 ScheduledThreadPool :
允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
三大方法
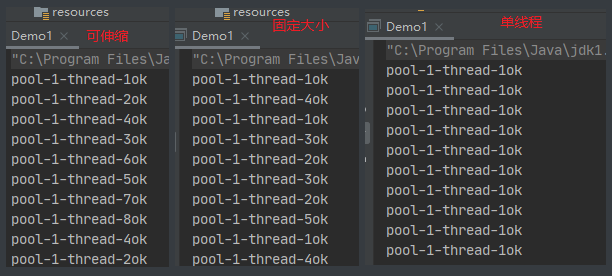
package com.rzp.pool; import java.util.concurrent.Executor; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class Demo1 { public static void main(String[] args) { ExecutorsTest(); } public static void ExecutorsTest() { //这个就是使用Executor创建线程池的3大方法。 // ExecutorService threadPool = Executors.newSingleThreadExecutor();//单个线程 // ExecutorService threadPool = Executors.newFixedThreadPool(5); //创建一个固定大小的线程池 ExecutorService threadPool = Executors.newCachedThreadPool(); //创建可伸缩线程池 try { for (int i = 0; i < 10; i++) { //从线程池中获取线程 threadPool.execute(() -> { System.out.println(Thread.currentThread().getName() + "ok"); }); } } catch (Exception e) { e.printStackTrace(); } finally { //关闭线程池 threadPool.shutdown(); } } }
七大参数
三大方法的源码:
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService //new ThreadPoolExecutor (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } public static ExecutorService newFixedThreadPool(int nThreads) { //new ThreadPoolExecutor return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } public static ExecutorService newCachedThreadPool() { //new ThreadPoolExecutor return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }
7大参数
-
可以看到,3个方法其实都是调用new ThreadPoolExecutor
// ThreadPoolExecutor构造方法的7个参数,就是所谓的7大参数 public ThreadPoolExecutor(int corePoolSize, //核心线程池大小 int maximumPoolSize, //最大线程池大小 long keepAliveTime, //超时等待时间 TimeUnit unit, //超时单位 BlockingQueue<Runnable> workQueue //阻塞队列 ThreadFactory threadFactory, //线程工厂 RejectedExecutionHandler handler //拒绝策略 ) { if (corePoolSize < 0 || maximumPoolSize <= 0 || maximumPoolSize < corePoolSize || keepAliveTime < 0) throw new IllegalArgumentException(); if (workQueue == null || threadFactory == null || handler == null) throw new NullPointerException(); this.acc = System.getSecurityManager() == null ? null : AccessController.getContext(); this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler;
作用
-
7大参数是如何起作用的:
-
线程工厂:创建线程的工厂,这个不需要改变。
-
核心线程池大小:开启线程池后,就会启用的线程数量,设为2。
-
假如核心线程池都被占用,也就是2条都在使用了,这时候如果有第3个程序要求调用,第3个程序就会进入阻塞队列之中等待:
-
-
阻塞队列:用于存放等待获取线程的容器。
-
假如核心线程池中有线程释放了,3就会获得线程。
-
假如核心线程一直在执行,这时又来了4、5...,这些都会进入阻塞队列,一旦阻塞队列也满了,这时候就会开启新的线程:
-
-
最大线程池大小:最多允许开始的线程数量,阻塞队列满员后逐个开放使用,直到达到最大值。
-
一旦达到最大值了、并且阻塞队列也满了,就会启用拒绝策略:
-
-
拒绝策略:最大线程池、阻塞队列都满员的情况下,如果还有新的程序要求调用线程,就会按拒绝策略对该程序反馈。
-
超时等待时间、超时单位:非核心线程池中的线程,超过等待时间都没有被调用,就会被关闭。
-
也就是说,上面的例子中,如果最后阻塞队列空了,所有线程也都释放了,那么除了核心线程中的2条线程会持续开启以外,其他线程超过等待时间后就会关闭掉。
-
创建线程池
public static void ThreadPoolTest() { ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 2, 5, 3, TimeUnit.SECONDS, new LinkedBlockingDeque<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy()); try { for (int i = 0; i < 15; i++) { int num = i; //从线程池中获取线程 threadPool.execute(() -> { System.out.println(Thread.currentThread().getName() + "=="+num+"ok"); }); } } catch (Exception e) { e.printStackTrace(); } finally { //关闭线程池 threadPool.shutdown(); } }
拒绝策略
-
就是这4个类

/** 抛出RejectedExecutionException异常 */ public static class AbortPolicy implements RejectedExecutionHandler //测试结果:抛出异常 /** 在原线程中直接调用run方法,让原线程执行 * 在下面例子中,把for循环数量调高,可以看到线程名称是main * 如果再来就会阻塞等待 */ public static class CallerRunsPolicy implements RejectedExecutionHandler //测试结果:表面看没有异常,而且所有任务都会执行完 /** 把队首的任务丢弃,然后把新任务放在队尾 */ public static class DiscardOldestPolicy implements RejectedExecutionHandler //测试结果,会有任务丢失 /**队列满了,不会抛出异常,但是任务会被抛弃 */ public static class DiscardPolicy implements RejectedExecutionHandler //测试结果,会有任务丢失
使用策略
-
如何定义线程池的最大数量?一般有两种策略
-
Cpu密集型 :按处理器数量定义,Cpu利用率最高。
//获取处理器数量 System.out.println(Runtime.getRuntime().availableProcessors()); //用处理器数量定义 ThreadPoolExecutor threadPool = new ThreadPoolExecutor( 2, Runtime.getRuntime().availableProcessors(), 3, TimeUnit.SECONDS, new LinkedBlockingDeque<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy());
-
IO密集型 :判断程序中消耗IO的线程,定义为IO线程的两倍
学习ForkJoin前需要对1.8的函数式接口学习
四大函数式接口
函数式接口
-
只有一个抽象方法的接口。
四大函数式接口
-
是指
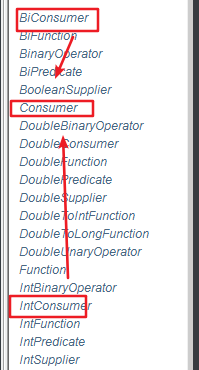
java.util.function这个包下的这四个接口:
Consumer
Function
Predicate
Supplier
-
这四个是function这个包下主要的四个接口,其他都是这四个接口的辅助包,可以从一些名字看出来
Function
-
Function这个接口要调用apply()方法,输入和输入都可以是object(任意类型)
public static void main(String[] args) { //Function函数型接口原始写法 Function function = new Function<String,String>() { @Override public String apply(String o) { return o; } }; System.out.println(function.apply("asd0"));; //Function lamda表达式简写 ,写一个工具方法就很简单了 Function<String,String> functiong = (str)->{return str;}; }
对比scala语言,scala写一个函数,虽然没scala简单,但是确实比没函数式接口之前简单很多了:
val f2 = (n1:Int,n2:Int) => n1+n2
Predicate
-
调用test方法,输入是object,返回是Boolean,,用于判断
//predicate的特点是输入是object,返回的只能是Boolean,调用的方法名是test,用于判断 public static void predicate(){ Predicate<String> emptyIf = str -> { return str.isEmpty();}; System.out.println(emptyIf.test(" "));; }
Consumer
-
调用accept()方法,输入是object,没有返回值
public static void ComsumeTest(){ //Consumer accept(T t); 只有输入,没有返回值 Consumer<String> consumer = str ->{System.out.println(str); }; consumer.accept("123"); }
Supplier
-
调用get(T t); 没有输入,只有返回值
public static void SupplierTest(){ //Consumer get(T t); 没有输入,只有返回值 Supplier supplier = () ->{return 1024; }; System.out.println(supplier.get()); }
Stream流式计算
-
和scala那套那不多,写起来还复杂点
package com.rzp.streamCount; import com.sun.xml.internal.ws.api.model.wsdl.WSDLOutput; import java.util.ArrayList; import java.util.Arrays; import java.util.List; import java.util.stream.Stream; public class Demo1 { public static void main(String[] args) { User user1 = new User(1, "a", 21); User user2 = new User(2, "b", 22); User user3 = new User(3, "c", 23); User user4 = new User(4, "d", 24); User user5 = new User(5, "e", 25); //存储交给集合 List<User> users = Arrays.asList(user1, user2, user3, user4, user5); //计算交给流 //转换成流 Stream<User> stream = users.stream(); //使用流的filter函数式接口,filter只能输入Predicate函数 //和scala非常类似,就是把容器中的每个元素放在函数里,把判定为true的放在一个新的数组里 Stream<User> filterStream = stream.filter(u -> { return u.getId() % 2 == 0; }); //map,输入Function函数 Stream<String> userStream = filterStream.map(u -> { return u.getName().toUpperCase(); }); //排序 Stream<String> sorted = userStream.sorted((u1, u2) -> { return u1.compareTo(u2); }); //只要第一个 Stream<String> limit = sorted.limit(1); //foreach,只能输入Consumer函数遍历每个元素 limit.forEach(System.out::println); //和scala一样,写成一行代码 users.stream().filter(u->{return u.getId() % 2 == 0;}) .map(u -> {return u.getName().toUpperCase();}) .sorted((u1, u2) -> {return u1.compareTo(u2);}).limit(1).forEach(System.out::println); } }