
Kafka(二):环境搭建
node-2做以下步骤
安装包下载
http://kafka.apache.org/downloads

https://www.scala-lang.org/download/2.12.11.html
上传后解压文件
#要先创建目录 [root@node-2 ins]# tar -zxvf kafka_2.12-2.4.1.tgz -C /usr/myapp/kafka/ [root@node-2 ins]# tar -zxvf scala-2.12.11.tgz -C /usr/myapp/scala/
配置Scala环境变量
## scala export SCALA_HOME=/usr/myapp/scala/scala-2.12.11 export PATH=$PATH:$SCALA_HOME/bin
测试Scala安装成功
[root@node-2 scala-2.12.11]# scala Welcome to Scala 2.12.11 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_65). Type in expressions for evaluation. Or try :help. scala> print ("123123") 123123 scala> 1+254 res1: Int = 255 :help #帮助文档 :quit #退出 修改Kafka配置
server.properties
#kafka的config目录下 [root@node-2 config]# cp server.properties server2.properties #修改文件内容 # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. broker.id=2 ############################# Socket Server Settings ############################# # The port the socket server listens on port=9092 # Hostname the broker will bind to. If not set, the server will bind to all interfaces #host.name=localhost # Hostname the broker will advertise to producers and consumers. If not set, it uses the # value for "host.name" if configured. Otherwise, it will use the value returned from # java.net.InetAddress.getCanonicalHostName(). #advertised.host.name=<hostname routable by clients> # The port to publish to ZooKeeper for clients to use. If this is not set, # it will publish the same port that the broker binds to. #advertised.port=<port accessible by clients> # The number of threads handling network requests num.network.threads=2 # The number of threads doing disk I/O num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=1048576 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=1048576 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files log.dirs=/tmp/kafka-logs/log2 # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. num.partitions=2 ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk #log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush #log.flush.interval.ms=1000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=536870912 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=60000 # By default the log cleaner is disabled and the log retention policy will default to just delete segments after their retention expires. # If log.cleaner.enable=true is set the cleaner will be enabled and individual logs can then be marked for log compaction. log.cleaner.enable=false ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. zookeeper.connect=node-1:2181,node-2:2182,node-2:2183/kafka # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=1000000 [root@node-2 config]# cp server2.properties server3.properties #修改以下内容 broker.id=3 port=9093 log.dirs=/tmp/kafka-logs/log3 zookeeper.connect=node-1:2181,node-2:2182,node-2:2183/kafka
环境变量
##kafka export KAFKA_HOME=/usr/myapp/kafka/kafka_2.12-2.4.1 export PATH=$PATH:$KAFKA_HOME/bin
node-1
在node-1中重复上述步骤,但是只配置1个properties文件,只修改这里
broker.id=1 log.dirs=/tmp/kafka-logs/log1
zookeeper中建立Kafka结点
[zk: localhost:2181(CONNECTED) 1] create /kafka "" Created /kafka
测试
-
这是一个前台启动的软件,向Web logic那种会在前台一直挂着。所以最好使用后台启动并且把日志输出到指定位置。
-
那么就可以使用tail命令持续查看日志
#后台启动kafka,并把日志输出到指定位置 nohup kafka-server-start.sh server3.properties 1>/usr/myapp/kafkalog.log 2>&1 & [2] 78384
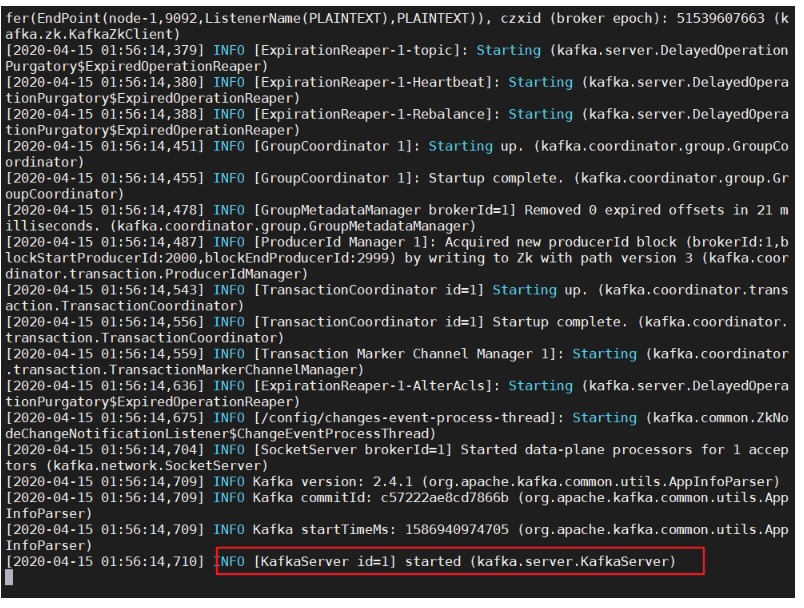
日志最后有这个输出就说明成功了
jps也可以看到对应进程

停止
#停止指定kafka kafka-server-stop.sh server3.properties #全部停止 kafka-server-stop.sh

