
Zookeeper(一)简介
Zookeeper
-
Zookeeper其实就是一个应用在分布式系统上的管理系统,比如要修改一个分布式系统的配置,我们必须要手动一个个系统去修改,非常麻烦,而这个软件就是提供了同步自动修改的功能:Zookeeper可以帮助实现配置维护、命名管理、分布式同步、组服务等功能
-
是Google的Chubby的开源实现,是一个高效、可靠的协同工作系统。
-
Yahoo!开发并开源的一套可扩展的高吞吐分布式协调系统,目前在各种NoSQL数据库及诸多开源软件中获得广泛的使用。
-
现在是Apache基金会的一个项目,应用在HBase、Solr、Hadoop等项目中,在Yahoo!中也用于爬虫抓取服务和广告系统中。
-
Zookeeper提供了一套很好的分布式集群管理的机制,就是它这种基于层次型的目录树的数据结构,并对树中的节点进行有效管理,从而可以设计出多种多样的分布式的数据管理模型。
-
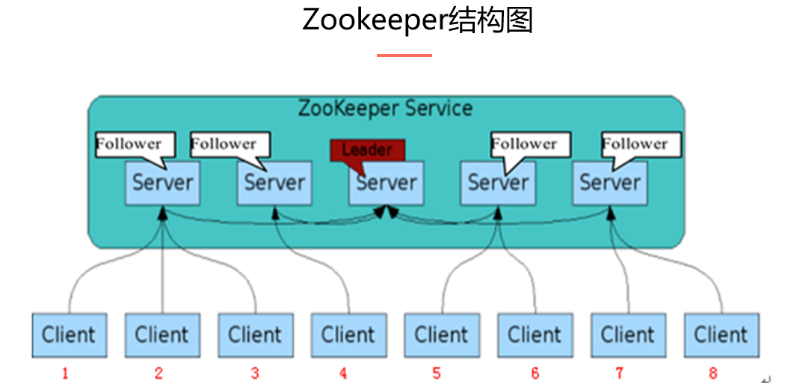
Zookeeper本身就是一个集群。
1.可靠性
ZooKeeper允许各分布式进程通过一个共享的命名空间相互联系,该命名空间类似于一个标准的层次型的文件系统:由若干注册了的数据节点构成(用Zookeeper的术语叫znode),这些节点类似于文件和目录。典型的文件系统是基于存储设备的,传统的文件系统主要用于存储功能,然而Zookeeper的数据是保存在内存中的。也就是说,可以获得高吞吐和低延迟。ZooKeeper的实现非常重视高性能、高可靠,以及严格的有序访问。
高性能保证了ZooKeeper可以用于大型的分布式系统,高可靠保证了ZooKeeper不会发生单点故障(就是不会出现单点的数据和其他不一致),严格的顺序访问保证了客户端可以获得复杂的同步操作原语。
2.健壮性
就像ZooKeeper需要协调的分布式系统一样,它本身就是具有冗余结构,它构建在一系列主机之上,叫做一个”ensemble”(组合)。
构成ZooKeeper服务的各服务器之间必须相互知道,它们维护着一个状态信息的内存映像,以及在持久化存储中维护着事务日志和快照。只要大部分服务器正常工作,ZooKeeper服务就能正常工作。
客户端连接到一台ZooKeeper服务器。客户端维护这个TCP连接,通过这个连接,客户端可以发送请求、得到应答,得到监视事件以及发送心跳。如果这个连接断了,客户端可以连接到另一个ZooKeeper服务器。
3.有序性/并发性
ZooKeeper给每次更新附加一个数字标签,表明ZooKeeper中的事务顺序,后续操作可以利用这个顺序来完成更高层次的抽象功能。同时通过判断这个数字标签是否一致,来决定操作是否成功。
4.快速
由于Zookeeper的设计之初就是用于协助其他分布式系统进行管理操作的,所以对于响应速度的要求比较高,一般要求响应在毫秒级别。在刚开始设计的时候就假定了zookeeper的应用场景主要以读操作为主,写操作为辅。
ZooKeeper特别适合于以读为主要负荷的场合。ZooKeeper可以运行在数千台机器上,如果大部分操作为读,例如读写比例为10:1,ZooKeeper的效率会很高。
集群组成
-
Zookeeper本身就是一个集群。
-
由leader(领导者)和learner(学习者)组成。
-
领导者(leader),负责进行投票的发起和决议,更新系统状态
-
learner由follower(跟随者)和observer(观察者)组成。
-
Follower用于接受客户端请求并向客户端返回结果,在选主过程中参与投票
-
Observer可以接受客户端请求,将写请求转发给leader,但observer不参加投票过程,只同步leader的状态,observer的目的是为了扩展系统,提高读取速度。
-
-
-
在一个zookeeper集群中,一般是一个leader节点,多个follower节点,observer节点可选(100台以上才使用)。
-
正式的zookeeper环境中,一般由奇数台servers组成。
-
因为Zookeeper有个选举机制,当leader宕机的时候,会让剩余服务器进行选举,如果是偶数,刚好一半一半就无法选举了,奇数可以保证集群的可用性
-
Zookeeper读写过程
-
client端连接上zookeeper集群的任何一台机器就可以了
-
进行读操作的时候,直接从client连接的机器上读取数据即可(zookeeper保证数据的操作顺序一致性)
-
当进行写操作的时候,如果client端连接的机器是leader机器,那么由leader机器负责数据的写操作,以及数据的集群同步操作。如果连接的机器不是leader机器,那么由连接的机器将请求转发给leader机器,进行写操作。
总结:读操作可以发生在任何机器上,更新(写、删除等)操作只能发生在leader机器上。
Zookeeper服务模型
-
ZooKeeper拥有一个树状的命名空间,这个和分布式的文件系统非常相似。
-
不同的是ZooKeeper命名空间中的Znode(也就是每个文件夹),兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分,并可以具有子znode。用户对znode具有增、删、改、查等操作(权限允许的情况下)。
-
Znode有二种类型:
-
临时节点:依赖于创建该节点的会话,当会话结束的时候,节点自动删除;不能有子节点。
-
永久节点:永久节点的生命周期不依赖于会话,只有当客户端显示删除的时候,才会被删除。默认情况下创建的都是永久节点。
-
-
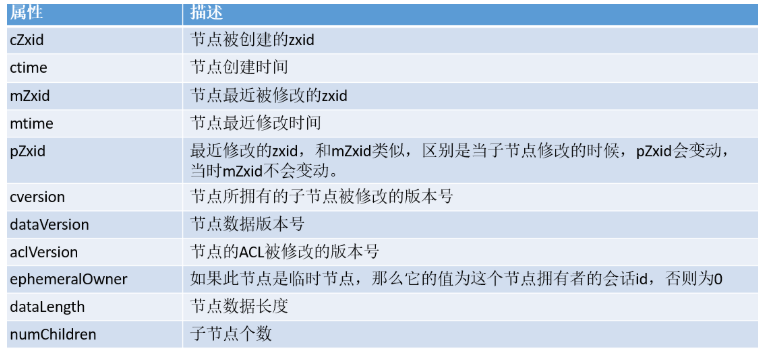
Znode有这些属性:
-
data数据,zookeeper中znode的数据操作是原子操作的。
-
children子节点;用于表示当前Znode的子节点列表。
-
state状态信息,在state状态信息中包含了版本号、时间戳等信息,当client操作的znode的状态信息和当前znode的状态信息不同的时候,操作就会失败。
-
-
Znode具有原子性操作,每个znode的数据将被原子性地读写,读操作会读取与znode相关的所有数据,写操作会一次性替换所有数据。
-
zookeeper的设计主要是用于管理调度数据,而不是用于常规的数据库和数据存储服务,每个znode的数据大小最大为1M,不过一般情况下,都只会有几KB。
Zookeeper 机制/特性
-
会话:当客户端成功连接到Zookeeper服务器时,会创建一个会话(Session)。每个会话有一个有效时间,如果在有效时间内没有发生任何请求操作,那么这个会话会过期。一般通过ping请求保持会话不过期。
-
监控(watch)机制,client可以在znode上设置watch(监视器),当节点的状态发生变化的时候,就会触发watch所对应的操作。当watch被触发的时候,zookeeper会向客户端发送且仅发送一条通知。
-
zxid机制;每个致使zookeeper发现状态变化的动作都会携带一个zxid格式的时间戳,并且这个时间戳在集群中全局有序。通过zxid来决定操作的顺序。实现中zxid是一个64位的数字,其中高32位数字是epoch用来表示leader,每次一个新的leader产生都会有一个新的epoch;低32位数字是一个递增计数。
Zookeeper权限验证
-
Zookeeper默认是没有开启权限验证的,也就是说可以被任何人访问到。
-
zookeeper内置有四种scheme,分别为world, auth, digest, ip。其中默认就是world,表示任何人均可以操作。
-
在给znode节点进行权限授予的时候采用格式为: scheme:user:auth。
-
scheme为上述介绍的四种
-
user为用户描述信息,比如digest为username:password;ip为ip地址。
-
auth为权限的缩写,分别为create(c), delete(d), read(r), write(w), admin(a)。
-
Zookeeper中的基本操作
-
create 创建znode(父znode存在)
-
delete 删除znode(znode没有子节点)
-
exits 测试znode是否存在,并获取元数据
-
getACL/setACL 为znode获取/设置ACL
-
getChildren 获取znode的所有子节点列表
-
getData/setData 获取/设置znode关联的相关数据
-

