
Hadoop(九):Shuffle组件
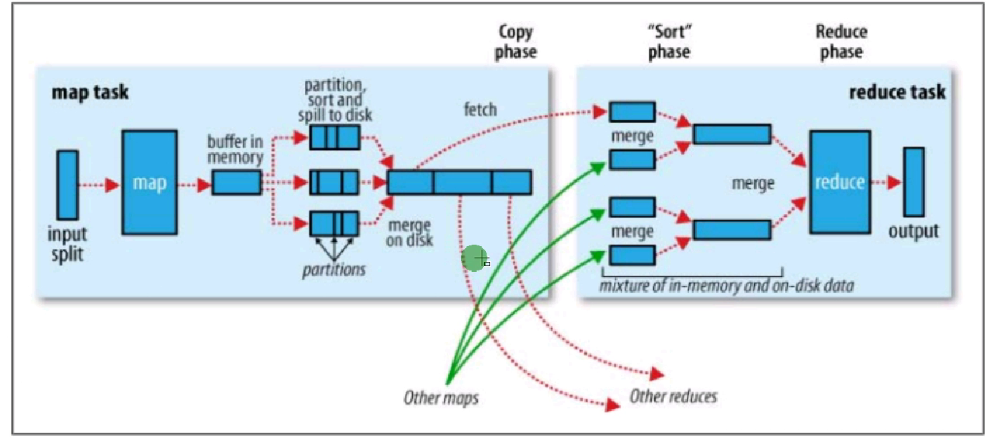
工作流程
-
开始执行输入(InputFormat),先对文件进行分片,然后读取数据输入到Map中。
-
Mapper读取输入内容,解析成键值对,1行内容解析成1个键值对,每个键值对调用一次map方法。
-
每个键值对执行map重写
-
多个Mapper的输出,按照不同的分区,通过网络复制到不同的Reducer节点。
-
Map shuffle阶段。
-
Reduce shuffle阶段
-
-
对多个Mapper的输出进行合并、排序,执行重写的reduce方法,再次输出新的键值对。
-
把最后的结果保存到文件中。
定义
-
Shuffle阶段就是指Map输出到Reduce输入的过程,可以区分为Map shuffle阶段和Reduce shuffle阶段。
-
shuffle机制的主要功能作用是将数据进行排序、分组、分区。
-
由于shuffle是reduce task节点通过http拉取map task的执行结果,这个过程就会有网络开销和磁盘IO开销,因此我们要降低网络开销、减少磁盘IO对其他task的影响、获取完整的结果数据。
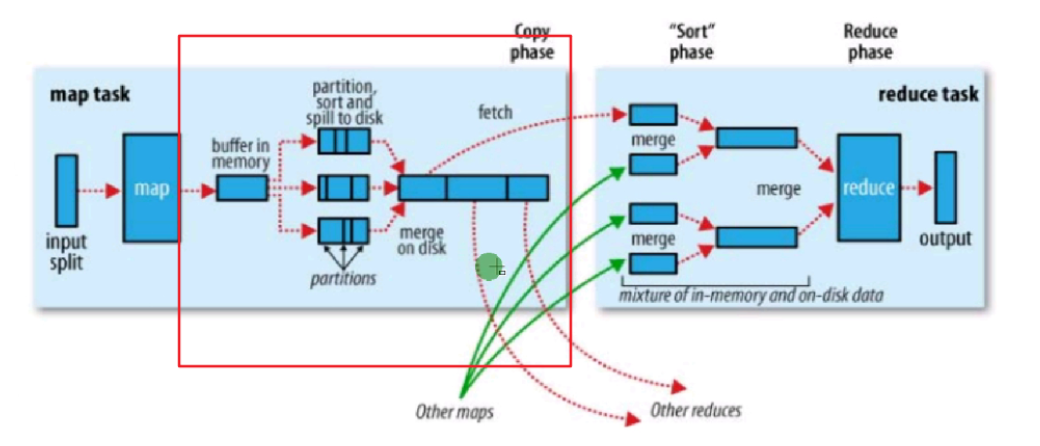
Map shuffle阶段
-
Map shuffle主要功能是将map方法输出的<key,value>键值对最终输出到map task节点的本地文件系统(而不是HFDS文件系统)的一个文件(而不是多个文件!)中,让reduce task获取。
-
主要步骤:
-
write to memory buffer(写出到内存缓存)
-
write to disk file(写出到磁盘文件)
-
combin(组合器,可控制))
-
partition(分区,可控制)
-
sort(排序,可控制))
-
write to disk file(写出到磁盘文件)
-
-
merge disk file(合并磁盘文件)
-
1.write to memory buffer(写出到内存缓存)
-
第一步就是将数据添加到memory buffer中,该memory buffer是一个环形的内存缓存区,当写入容量达到80%(默认)的时候,会触发溢出操作
-
触发溢出操作的时候会将已经写入的缓存区(80%)锁住,同时map task允许往剩下的缓存区中写入数据。也就是说当触发溢出操作的时候,不会阻塞map task的继续写出操作
-
Map端内存中有个环形的内存缓存结构体,该结构体的内存大小由参数mapreduce.task.io.sort.mb控制,默认大小为100MB。
-
其中控制阀值的是参数mapreduce.map.sort.spill.percent,默认值0.8
2. write to disk file(写出到磁盘文件)
-
在触发溢出操作的时候,会同时触发<key,value>键值对的combiner、partitioner以及sort三种操作(MapOutputBuffer类)。
-
操作后会在磁盘中生成(Spill)一个磁盘文件(每次溢出就会有一个文件,文件是进行合并后的,排序好的,按照reduce分区好的数据文件)。
-
当执行完Spill操作后,磁盘中会多一个数据文件,同时会将环形内存缓存写出数据部分进行清空操作,允许map task往这部分填写数据。
-
可能会触发多次combiner操作。
-
reduce分区:1个reduce任务就要做一个reduce分区。
3.merge disk file(合并磁盘文件)
-
当map task执行完成后,会执行溢出文件归并操作,通过combiner、partitioner以及sort操作,最终将多个溢出文件以及内存中没有溢出的数据写出到一个本地磁盘文件中。
-
同时保存一个reducer节点到文件内容的偏移量的一个索引文件。比如reduce1取1-10,2取11-20...
-
只所以不采用一个reducer对应一个文件的方式,是因为如果一个大的集群有很多个reducer task节点,那么最终每个map task执行完成后,都会产生多个本地文件,不好维护。
-
-
当map task节点完成数据写出操作后(最终产生一个磁盘文件后),map task正式完成,同时通知ApplicationMaster服务,完成map task。
-
并告诉application master服务,最终数据保存文件地址信息。
-
当完成的map task数量达到百分之五的时候,会启动reducer task任务。控制参数为mapreduce.job.reduce.slowstart.completedmaps,默认值0.05。
-
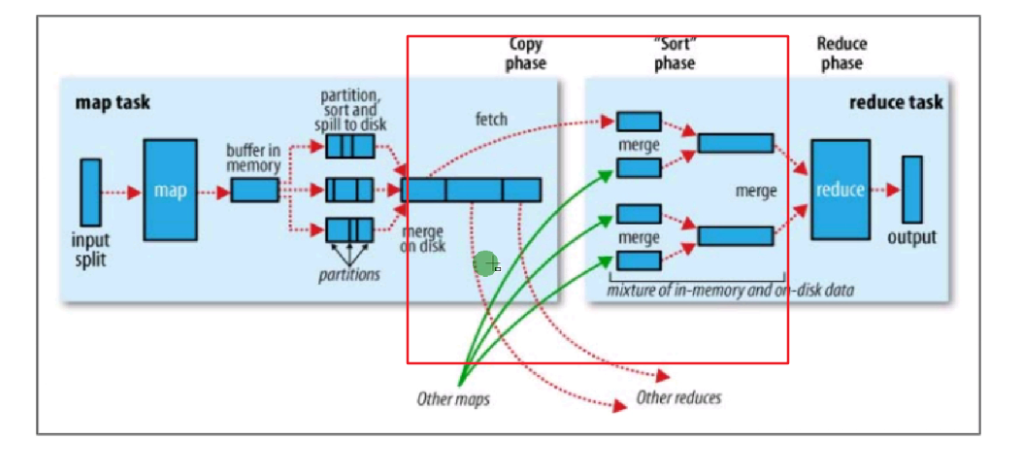
Reduce shuffle阶段
-
Reduce端的shuffle主要功能是将该reduce task节点需要处理的所有map端输出数据拉取过来,然后通过排序和合并操作,形成输入到reduce方法的<key,Iterator<value>>的键值对形式的数据。
-
Reduce端的shuffle操作指定类和Mapper不同,Mapper不能自定义,但是Reduce可以由参数指定:
-
默认为Shuffle.class类。可以通过参数mapreduce.job.reduce.shuffle.consumer.plugin.class指定
-
-
主要步骤:
-
copy
-
spill & merge & sort
-
group(分组,可控制)
-
1.copy
-
根据已经完成的map信息生成Fetcher线程组。
-
启动好Fetcher线程后,就开始从远程map task节点通过HttpURLConnection获取流来读取数据,并将数据先写到内存中。
-
内存不够(75%)的时候再溢出到磁盘中,内存大小是reduce task当前堆大小。
-
Fetcher线程组的数量由参数mapreduce.reduce.shuffle.parallelcopies控制,默认为5个。
-
内存大小不受用户参数控制,只所以选择使用当前堆大小作为内存大小,是因为此时reduce task不会进行任何任何其他操作(而Map还要计算),不需要额外的内存空间。
2. spill & merge & sort
-
和map端的溢出类似,reduce端在进行copy的时候由于内存不够,会进行溢出操作,在这个过程中会触发sort和merge操作,最终会产生一个磁盘文件(可能存在于内存中)。
-
reduce端的merge操作有三种方式:
-
内存到内存
-
内存到磁盘
-
磁盘到磁盘
-
默认情况下第一种方式是没有开启的,当内存容量不够的时候,会启动第二种方式,然后一直处于运行状态,直到map端数据全部拉取完成,最后会启动第三种方式进行归并操作。
-
3.group
-
group就是Reduce阶段输入的value是迭代器的原因,就是在这里实现的。
-
当reduce进行完merge操作后,会有一个数据文件存放到本地磁盘系统中或者内存中,为下一步reduce方法的执行提供数据。
-
每次获取数据的时候,会判断下一个key是否和当前key一样,通过group comparable来进行比较
-
如果一致,认为属于同一组key,那么在同一组中进行处理
-
否则直接结束当前组的处理,新起一个组来进行reduce方法的调用。
-
Shuffle 可控制的插件
-
Partition:用来完成Map节点数据的中间结果向Reduce节点的分区处理,也就是当Reduce节点为多个的时候(>1),决定数据是输出到那个节点。
-
Combine:用来减少Map过程输出的中间结果键值对的数量,降低网络开销。
-
Sorting:主要用来根据key来进行排序,并将结果按照sorting定义的顺序写出到磁盘文件或内存中。
-
Grouping:主要用来在Reduce节点处理数据的时候,将"相同"的key认为是同一组数据,一起进行处理操作
Partition
-
默认为HashPartitioner类,根据key的hashcode值进行分区操作。
-
自定义Partitioner要求:
-
实现org.apache.hadoop.mapreduce.Partitioner类
-
实现方法getPartition,返回当前key/value所属的分区号,分区号从0开始。
-
通过调用job.setPartitionerClass(CustomPartitioner.class)方法来进行设置。
-
示例
-
自定义类key数据类型,含用户id和访问时间time,根据id属性决定分区的Partitioner。
package com.rzp.pojo; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; //作为key,要实现WritableComparable public class CustomerValue implements WritableComparable<CustomerValue> { private String id; private long time; public int compareTo(CustomerValue o) { int tmp = this.id.compareTo(o.id); if (tmp!=0){return tmp;} tmp = Long.compare(this.time,o.time); return tmp; } public void write(DataOutput out) throws IOException { out.writeUTF(this.id); out.writeLong(this.time); } public void readFields(DataInput in) throws IOException { this.id = in.readUTF(); this.time = in.readLong(); }
//省略后续get/set/构造器-
重写Partitioner
-
使用一个简单的做法,就是调用Hadoop自带的HashPartitioner方法来实现按照ID分区
package com.rzp.pojo; import org.apache.hadoop.mapreduce.Partitioner; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; //自定义分区类 public class CustomerPartitioner extends Partitioner<CustomerValue,Object> { private Partitioner<String,Object> proxy = new HashPartitioner<String,Object> (); //numPartitions一般Hadoop会直接输入ReducerTask的数量 @Override public int getPartition(CustomerValue key, Object o, int numPartitions) { return this.proxy.getPartition(key.getId(),o,numPartitions); } }
-
这是HashPatitioner的方法
-
HashPatitioner其实是根据key值的HashCode进行分区
-
因为String类型相同的字符串的HashCode相同的特性,我们输入id值作为String传入即可。
-
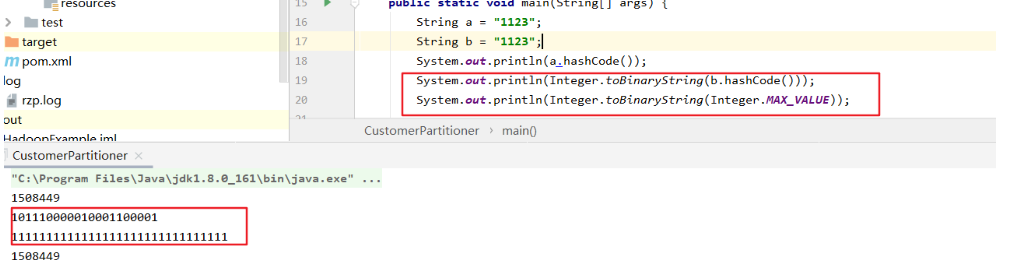
/** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }
-
方法中的&是位运算符,其实就是返回了key.hashCode
Combiner
-
默认为空,不进行任何合并操作。
-
Combiner其实就是在MapShuffle阶段,先进行部分数据的合并,减少要传输的数据,从而降低带宽的压力。
-
Combiner适合Map输出中的value是可以进行合并操作的场景,要求combiner的输入和输出的key/value键值对是一样的(combiner的输入是map的输出)。
-
自定义Combiner要求:
-
实现org.apache.hadoop.mapreduce.Reducer类
-
实现方法reduce。
-
通过调用job.setCombinerClass(CustomCombiner.class)方法来进行设置。
-
-
Combiner是由MR框架根据内存容量大小进行控制决定是否执行,而且执行次数不定,所以在编写Combiner的时候有一个要求:不管执行多少次Combiner操作,不影响最终运算结果(mr输出结果)。
示例
-
给计算WordCount的MR作业添加Combiner,然后查看Combiner是否执行。
package com.rzp.utils; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import org.apache.log4j.Logger; import java.io.IOException; //输入输出的键值对一摸一样 public class WordCountCombiner extends Reducer<Text, LongWritable,Text, LongWritable> { private static final Logger logger = Logger.getLogger(WordCountCombiner.class); private LongWritable count = new LongWritable(); @Override protected void setup(Context context) throws IOException, InterruptedException { super.setup(context); logger.debug("调用combiner"); } @Override protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException { logger.debug("执行combiner"+key); //先进行一部分的合并累加操作 int sum = 0; for (LongWritable value :values){ sum += value.get(); } this.count.set(sum); context.write(key,this.count); } @Override protected void cleanup(Context context) throws IOException, InterruptedException { super.cleanup(context); logger.debug("完成combiner的调用"); } }
-
Runner
-
在outputvalue后面增加
-
//设置combainer job.setCombinerClass(WordCountCombiner.class);
Sorting & Grouping
-
Sorting 默认采用key的compareTo方法来进行排序定义,一般我们的做法也是重写compareTo的方法进行实现,而不是重写Hadoop的接口。
-
Grouping 默认采用Sorting采用的排序定义方法来进行分组操作。
-
自定义要求:
-
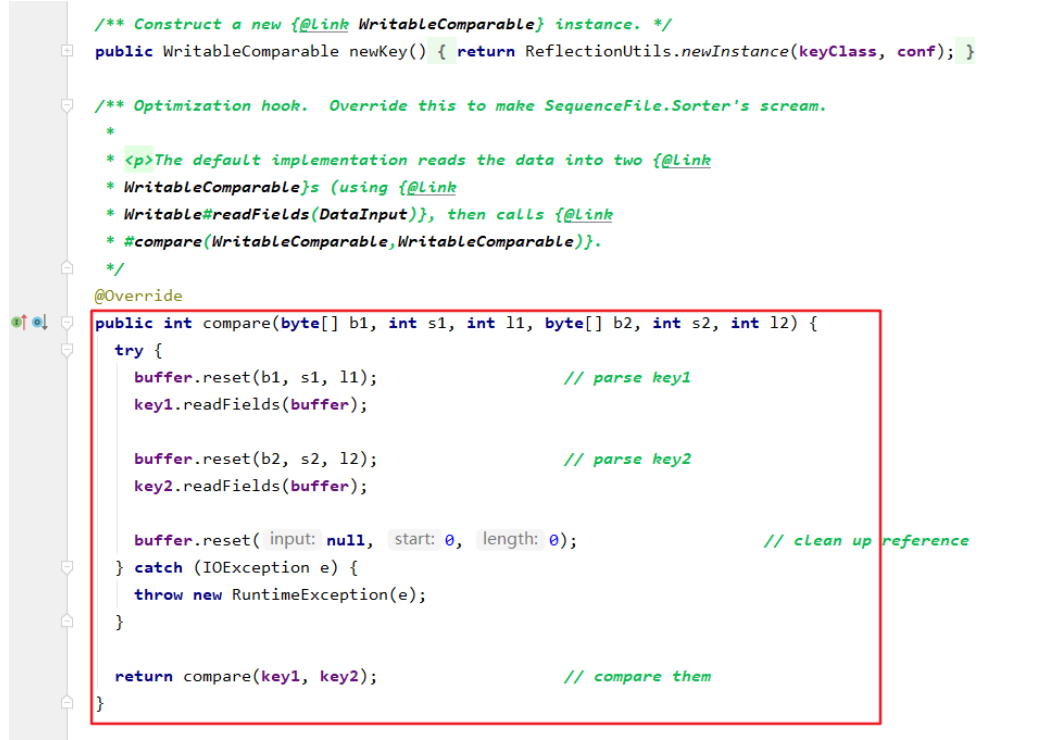
实现org.apache.hadoop.io.RawComparator接口,但是由于内部方法比较难实现,一般都是实现org.apache.hadoop.io.WritableComparator,并实现hashCode和equals方法。
-
通过调用job.setGroupingComparatorClass(CustomGrouping.class)设置。
-
备注
-
如果实现org.apache.hadoop.io.RawComparator接口,就要实现这个方法,按数组比较,就不是很好实现。
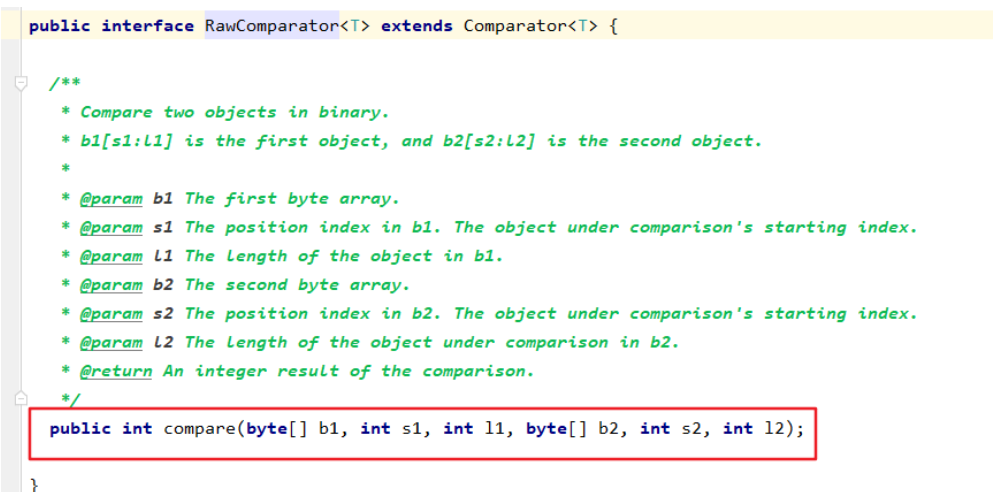
-
而org.apache.hadoop.io.WritableComparator本身就实现了这个方法,所以我们一般实现这个。
示例
-
自定义类key数据类型,含用户id和访问时间time,根据id属性决定分组Grouping。
package com.rzp.pojo; import org.apache.hadoop.io.WritableComparable; import org.apache.hadoop.io.WritableComparator; public class CustomGrouping extends WritableComparator { public CustomGrouping(){ //调用父类构造器,对父类要使用的key值赋值 //第一个参数是该grouping进行分组对应的key类 //第二个参数写true,表示直接创建对象 super(CustomerValue.class,true); } @Override public int compare(WritableComparable a, WritableComparable b) { CustomerValue cv1 = (CustomerValue)a; CustomerValue cv2 = (CustomerValue)b; return cv1.getId().compareTo(cv2.getId()); } }
二次排序
-
MR框架默认情况下只会map的输出key进行排序,从小到大排序,而没有对value进行排序操作,但是有些情况下,我们的最终结果需要按照value中的某些字段进行排序输出。这个时候,默认的MR执行流程就无法帮助我们完成任务。
-
此时就需要我们自定义分区、排序、分组等组件,使用二次排序,将value中需要进行排序的字段作为一个key中的一些属性进行排序,但是在分区分组的时候又要求不考虑这些额外的属性。
-
即:二次排序就是指不仅仅对key进行排序,而且对value也进行排序操作。实现方式就是排序使用key+value的方式,但是分区和分组只考虑key的方式进行。
案例:
-
我们需要把输入的文件,按照uid分组,按uid排序,每个uid后面显示url,按t1排序。

思路
-
按照uid和t1进行排序我们只需要把uid和t1作为Mapper OutputKey,重写compare方法就可以了。
-
要分组显示我们要使用grouping。
-
但是如果有多个Reducer Task任务,就可能会造成同一组去了不同的Task,导致结果不符合要求。
-
因此我们还要加上Patitioner。
实现:
-
如果我们只对key值排序:
-
Mapper OutputValue
package com.rzp.sorttwice; import org.apache.hadoop.io.WritableComparable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; // public class SortOutputKey implements WritableComparable<SortOutputKey> { private String uid; private String time; public int compareTo(SortOutputKey o) { //主要用于排序,先把需要group的字段排序,然后再进行其他字段排序 //拿this比较o,那么得到结果是从小到大 int tmp = this.uid.compareTo(o.uid); if (tmp!=0){ return tmp; } //tmp = this.time.compareTo(o.time); //time从小到大 tmp = o.time.compareTo(this.time); return tmp; } public void write(DataOutput out) throws IOException { out.writeUTF(this.uid); out.writeUTF(this.time); } public void readFields(DataInput in) throws IOException { this.uid = in.readUTF(); this.time = in.readUTF(); } public String getUid() { return uid; } public void setUid(String uid) { this.uid = uid; } public String getTime() { return time; } public void setTime(String time) { this.time = time; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; SortOutputKey that = (SortOutputKey) o; if (uid != null ? !uid.equals(that.uid) : that.uid != null) return false; return time != null ? time.equals(that.time) : that.time == null; } @Override public int hashCode() { int result = uid != null ? uid.hashCode() : 0; result = 31 * result + (time != null ? time.hashCode() : 0); return result; } @Override public String toString() { return "SortOutputKey{" + "uid='" + uid + '\'' + ", time='" + time + '\'' + '}'; } }