
Hadoop(七):自定义输入输出格式
-
数据输入格式 InputFormat。
-
用于描述MR作业的数据输入规范。
-
输入格式在MR框架中的作用:
-
-
从输入分块中将数据记录逐一读出,并转换为Map的输入键值对。
-
-
如果想自定义输入格式,需要实现:
-
顶级输入格式类:org.apache.hadoop.mapreduce.InputFormat
-
顶级块类:org.apache.hadoop.mapreduce.InputSplit
-
顶级块数据读取类:org.apache.hadoop.mapreduce.RecordReader
-
Hadoop内置输入格式
-
Hadoop提供了大量的内置数据输入格式,包括:CombineFileInputFormat、SequenceFileInputFormat、SequenceFileAsTextInputFormat、NlineInputFormat、FileInputFormat、TextInputFormat、KeyValueTextInputFormat等。最常用的是TextInputFormat和KeyValueTextInputFormat这两种。
-
TextInputFormat是MR框架默认的数据读入格式(一般学习的第一个例子wordcount就是用的这个格式),
-
可以将文本文件分块逐行读入一遍Map节点处理。
-
key为当前行在整个文本文件中的字节偏移量,value为当前行的内容。
-
-
KeyValueTextInputFormat。
-
可以将一个按照<key,value>格式逐行保存的文本文件逐行读出,并自动解析为相对于的key和value。默认按照'\t'分割。
-
也就是说1行的\t前的内容是key,后面是value。
-
如果没有\t,value就设置为empty。
-
自定义输入格式从MySQL中取数
-
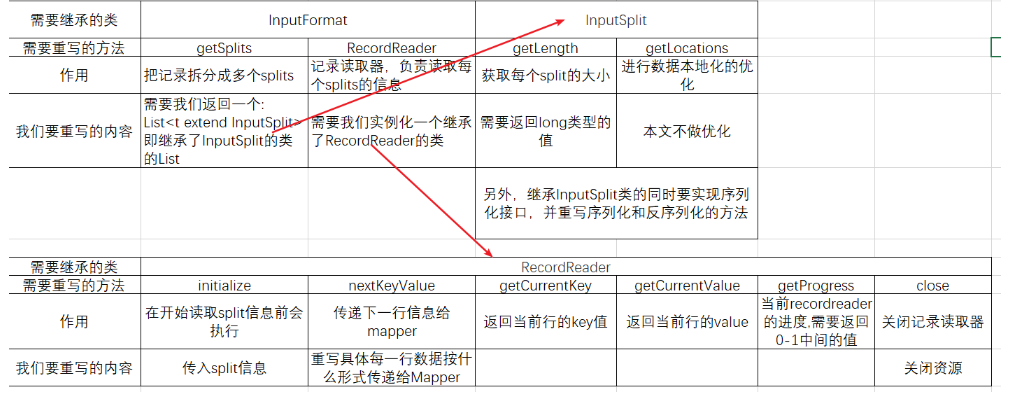
自定义输入格式,我们需要继承InputFormat,InputSplit和RecordReader三个类,并重写以下方法:
-
基本的作用和我们要重写的内容见下表。
-
下表内容并不限定于MySQL中取数(就是从文件取数也要实现这些)。
-
1个split就是一个Map,和Reduce的个数不同,Mapper的任务个数是InputFormat决定的,Reduce任务个数是客户决定的。
-
-
自定义输入Value抽象类,因为我们从MySQL中读取的是一行数据,必然要使用一个对象来存储这些数据,我们先定义这个对象的抽象类,这样可以先暂时跳过这个类具体的内容。
package com.rzp.ifdemo; import org.apache.hadoop.io.Writable; import java.sql.ResultSet; import java.sql.SQLException; /** * mysql输入的value类型,其实应用中使用到的数据类型必须继承自该类 */ public abstract class MysqlInputValue implements Writable { //从数据库返回链接中读取字段信息 public abstract void readFields(ResultSet rs) throws SQLException; }
-
自定义输入格式
package com.rzp.ifdemo; import com.rzp.pojo.UrlCountMapperInputValue; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapred.MapTask; import org.apache.hadoop.mapreduce.*; import org.apache.hadoop.util.ReflectionUtils; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import java.sql.*; import java.util.ArrayList; import java.util.HashSet; import java.util.List; /** * */ public class MysqlInputFormat<V extends MysqlInputValue> extends InputFormat<LongWritable,V> { public static final String MYSQL_INPUT_DRIVER_KEY = "mysql.input.driver"; //数据库链接drive,后续在主方法会重新传参数 public static final String MYSQL_INPUT_URL_KEY = "mysql.input.url"; //数据库链接url,后续在主方法会重新传参数 public static final String MYSQL_INPUT_USERNAME_KEY = "mysql.input.username"; //数据库链接username,后续在主方法会重新传参数 public static final String MYSQL_INPUT_PASSWORD_KEY = "mysql.input.password"; //数据库链接password,后续在主方法会重新传参数 public static final String MYSQL_SELECT_KEY = "mysql.input.select"; //查询总记录数量的sql,后续在主方法会重新传参数 public static final String MYSQL_SELECT_RECORD_KEY = "mysql.input.select.record"; //查询记录的sql,后续在主方法会重新传参数 public static final String MYSQL_INPUT_SPLIT_KEY = "mysql.input.split.pre.record.count"; //决定多少条记录1个split,后续在主方法会重新传参数 public static final String MYSQL_OUTPUT_VALUE_CLASS_KEY = "mysql.output.value.class"; //最终输出的value,暂时不管 @Override public List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException { //该方法的作用就是返回数据分块,ApplicationMaster根据分块信息数量决定map task的数量 Configuration conf = context.getConfiguration(); Connection conn = null; //Mysql链接 PreparedStatement pstmt = null; ResultSet rs = null; String sql = conf.get(MYSQL_SELECT_KEY); long recordCount = 0;//总记录数量 try { conn = this.getConnection(conf); //传入的sql是查询总数量的,在执行主程序中会传入select count(*) from pstmt = conn.prepareStatement(sql); rs = pstmt.executeQuery(); if (rs.next()){ //recordCount = 表的总行数 recordCount = rs.getLong(1); //获取数量 } } catch (Exception e) { e.printStackTrace(); }finally { this.closeConnection(conn,pstmt,rs); } //开始处理生成input split List<InputSplit> list = new ArrayList<InputSplit>(); //把配置文件中的MYSQL_INPUT_SPLIT_KEY对应的value取出来,如果没找到,则取默认值(100) long preRecordCountOfSplit = conf.getLong(MYSQL_INPUT_SPLIT_KEY,100); int numSplits = (int)(recordCount / preRecordCountOfSplit + (recordCount % preRecordCountOfSplit ==0 ? 0:1)); for (int i = 0; i < numSplits; i++) { if (i != numSplits-1){ list.add(new MysqlInputSplit(i*preRecordCountOfSplit,(i+1)*preRecordCountOfSplit)); }else{ list.add(new MysqlInputSplit(i*preRecordCountOfSplit,recordCount)); } } return list; } @Override public RecordReader<LongWritable, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //返回具体处理分块数据的recordReader类对象 RecordReader<LongWritable,V> reader = new MysqlRecordReader(); // reader.initialize(split,context); return reader; } //根据配置信息获取数据库链接 private Connection getConnection(Configuration conf) throws SQLException, ClassNotFoundException { String driver = conf.get(MYSQL_INPUT_DRIVER_KEY); String url = conf.get(MYSQL_INPUT_URL_KEY); String username = conf.get(MYSQL_INPUT_USERNAME_KEY); String password = conf.get(MYSQL_INPUT_PASSWORD_KEY); Class.forName(driver); return DriverManager.getConnection(url,username,password); } //关闭链接 private void closeConnection(Connection conn,Statement state,ResultSet rs) { try { if (rs!=null)rs.close(); if (state!=null)state.close(); if (conn!=null)conn.close(); } catch (SQLException e) { e.printStackTrace(); } } //自定义读取数据的recordReader类 public class MysqlRecordReader extends RecordReader<LongWritable,V>{ private Connection conn; private Configuration conf; private MysqlInputSplit split; private LongWritable key = null; private V value = null; private ResultSet resultSet = null; private long post = 0; //位置信息 @Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { //传入分块信息,当我们传入的mysplit是1-4时,查询的结果就是1-4行记录 this.split = (MysqlInputSplit) split; this.conf = context.getConfiguration(); } //创建value对象 private V createValue(){ Class<? extends MysqlInputValue> clazz= this.conf.getClass(MYSQL_OUTPUT_VALUE_CLASS_KEY,NullMysqlInputValue.class,MysqlInputValue.class); return (V) ReflectionUtils.newInstance(clazz,this.conf); } //获取查询sql private String getQuerqSql(){ String sql = this.conf.get(MYSQL_SELECT_RECORD_KEY); try { //根据传入的split数值,形成查询数据的sql,当我们传入的mysplit是1-4时,查询的结果就是1-4行记录 sql += " limit "+ this.split.getLength(); sql += " offset "+ this.split.getStart(); } catch (Exception e) { e.printStackTrace(); } return sql; } //重写方法--获取下一行的value @Override public boolean nextKeyValue() throws IOException, InterruptedException { //防止key、value、链接为空 if(this.key == null){ this.key = new LongWritable(); } if(this.value == null){ this.value = this.createValue(); } if(this.conn==null){ try { this.conn = MysqlInputFormat.this.getConnection(this.conf); } catch (Exception e) { e.printStackTrace(); } } try { //还没查数据库时才需要查resuleSet if(resultSet ==null){ //调用getQuerqSql方法查询当前split的数据 String sql = this.getQuerqSql(); PreparedStatement pstmt = this.conn.prepareStatement(sql); //把查询到的数据输入到resultSet中 this.resultSet = pstmt.executeQuery(); } //正式的进行处理操作 if(!this.resultSet.next()){ return false;//resultSet没有结果了 } //Mapper会调用run方法循环执行nextKeyValue()(就是我们重写的这个方法) //备注(Mapper不是直接调用我们的方法,中间经过很多层,比如MapTask类,里面还会执行进度(progress的修改) //因此我们实现的时候只需要写每一行是如何传入value的就可以了 //这里我们调用了UrlCountMapperInputValue实体类的写参数的方法 this.value.readFields(this.resultSet); this.key.set(this.post); this.post++; return true; } catch (SQLException e) { e.printStackTrace(); } return false; } //重写方法,返回当前行的key值 @Override public LongWritable getCurrentKey() throws IOException, InterruptedException { return this.key; } //重写方法,返回当前行的value @Override public V getCurrentValue() throws IOException, InterruptedException { return this.value; } //重写方法,当前recordreader的进度,需要返回0-1中间的值 //所以返回了当前位置和本块总的长度 @Override public float getProgress() throws IOException, InterruptedException { return this.post/this.split.getLength(); } //重写方法,关闭记录读取器--因此添加关闭连接的代码 @Override public void close() throws IOException { MysqlInputFormat.this.closeConnection(this.conn,null,this.resultSet); } } //默认的空输出对象 public class NullMysqlInputValue extends MysqlInputValue{ @Override public void readFields(ResultSet rs) throws SQLException {} public void write(DataOutput out) throws IOException {} public void readFields(DataInput in) throws IOException {} } //继承InputSplit类,重写数据分块的方法 //继承InputSplit的时候一定要同时实现序列化接口,否则会报错 //使用内部类的时候序列化必须要static public static class MysqlInputSplit extends InputSplit implements Writable { private String[] emptyLocation = new String[0]; private long start;//从第几行开始读数据(包含这一行) private long end;//读到第几行(不包含) @Override public long getLength() throws IOException, InterruptedException { //分片大小,就是读了几行数据 return this.end-this.start; } @Override public String[] getLocations() throws IOException, InterruptedException { // 返回一个空的数组,表示不进行数据本地化的优化,那么map执行节点随机选择 //虽然是随机选择但是Hadoop默认会使用同一节点执行计算 return emptyLocation; } //重写序列化方法 public void write(DataOutput out) throws IOException { out.writeLong(this.start); out.writeLong(this.end); } //重写反序列化方法 public void readFields(DataInput in) throws IOException { this.start = in.readLong(); this.end = in.readLong(); } //下面是set/get和构造器 public long getStart() { return start; } public void setStart(long start) { this.start = start; } public long getEnd() { return end; } public void setEnd(long end) { this.end = end; } public MysqlInputSplit() { } public MysqlInputSplit(long start, long end) { this.start = start; this.end = end; } } }