python中序列化和反序列化
1.字典的序列化与反序列化
a.序列化:把python的数据类型转为str类型的过程
b.反序列化:str的类型转为python的数据结构
需要导入的包:
import json
import requests #在pychram 中进行包的导入安装file-->settings--->Project Interpreter
示例:
dict1 = {'name':'rzq','age':18}
#序列化:dict -->str
dict_str =json.dumps(dict1)
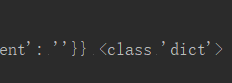
print('序列化后的结果信息:')
print(dict_str,type(dict_str))
#反序列化:str --->dict
str_dict =json.loads(dict_str)
print('反序列化后的结果信息:\n',str_dict,type(str_dict))
结果:
2.列表的序列化与反序列化
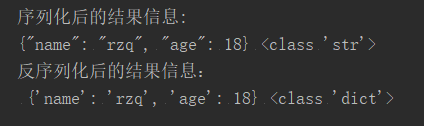
'''列表的序列化与发序列化过程''' list1 = ['admin','pwd','测试小伙子',18] #序列化 list_str = json.dumps(list1) print("序列化后的结果信息:\n",list_str,type(list_str)) #反序列化 str_list = json.loads(list_str) print("反序列化后的结果信息:\n",str_list,type(str_list))
结果:
3.元组的序列化与反序列化过程
注意:元组经过序列化和反序列化后数据类型为列表,不再是元组
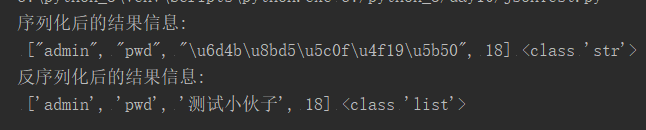
tuple1 = ('a',1,'测试小伙子','msg') #序列化 tuple_str = json.dumps(tuple1) print('序列化后的结果信息:\n',tuple_str,type(tuple_str)) #反序列化 str_tuple = json.loads(tuple_str) print('字符串tuple_str反序列化后的内容为:{0},类型为:{1}\n'.format(str_tuple,type(str_tuple)))
结果:

4.文件的序列化与反序列化
'''文件的序列化与反序列化''' ''' 注意:在进行序列化时,一定要先看返回来的数据是什么类型,如何直接是str类型,那么就不需要转化了 ''' r = requests.get(url='https://www.tianqiapi.com/api/?version=v6') # print(r.text,type(r.text)) #对文件进行序列化-->就是把服务器端的响应数据写到文件中 # print(json.dump(r.text,open('weather.json','w')),type(r.text)) #对文件进行反序列化-->就是读取文件中的内容 dict1 = json.loads((json.load(open('weather.json','r'))).encode('utf-8'))#先把文件中的数据进行反序列化,此时得到的结果是unicode,然后再次反序列化进行编码,使数据类型为字典类型就可以了 print(dict1['city'])
结果: