k8s总结复习
一、k8s介绍
Kubernetes(k8s)是Google开源的容器集群管理系统。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模 容器集群管理的便捷性。
1、k8s的优势
容器编排;轻量级;开源;弹性伸缩;负载均衡
2、重要概念:
Cluster: 是 计算、存储和网络资源的集合,k8s利用这些资源运行各种基于容器的应用.
Master: master是cluster的大脑,他的主要职责是调度,即决定将应用放在那里运行。master运行linux操作系统,可以是物理机或者虚拟机。为了实现高可用,可以运行多个master。
Node: 职责是运行容器应用。node由master管理,node负责监控并汇报容器的状态,同时根据master的要求管理容器的生命周期。node运行在linux的操作系统上,可以是物理机或者是虚拟机。
Pod: pod是k8s的最小工作单元。每个pod包含一个或者多个容器。pod中的容器会作为一个整体被master调度到一个node上运行。
Controller: k8s通常不会直接创建pod,而是通过controller来管理pod的。controller中定义了pod的部署特性,比如有几个剧本,在什么样的node上运行等。为了满足不同的业务场景,
k8s提供了多种controller,包括deployment、replicaset、daemonset、statefulset、job等。
Deployment: 是最常用的controller。deployment可以管理pod的多个副本,并确保pod按照期望的状态运行。
Replicaset: 实现了pod的多副本管理。使用deployment时会自动创建replicaset,也就是说deployment是通过replicaset来管理pod的多个副本的,我们通常不需要直接使用replicaset。
Daemonset: 用于每个node最多只运行一个pod副本的场景。正如其名称所示的,daemonset通常用于运行daemon。
Job: 用于运行结束就删除的应用,而其他controller中的pod通常是长期持续运行的。
Service: deployment可以部署多个副本,每个pod 都有自己的IP,外界如何访问这些副本那?答案是service。k8s的 service定义了外界访问一组特定pod的方式。service有自己的IP和端口,
service为pod提供了负载均衡。k8s运行容器pod与访问容器这两项任务分别由controller和service执行。
Namespace: 可以将一个物理的cluster逻辑上划分成多个虚拟cluster,每个cluster就是一个namespace。不同的namespace里的资源是完全隔离的。
二、k8s架构分析
k8s的集群由master和node组成,节点上运行着若干k8s服务。
1、master节点
master节点之上运行着的后台服务有kube-apiserver 、kube-scheduler、kube-controller-manager、etcd和pod网络(calico)
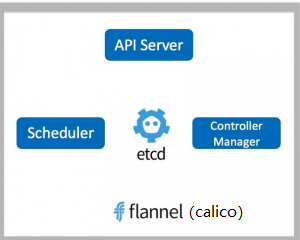
(1)API Server: API Server是k8s的前端接口,各种客户端工具以及k8s其他组件,可以通过它管理集群的各种资源。
(2)Scheduler: scheduer负责决定将pod放在哪个node上运行。另外scheduler在调度时会充分考虑集群的架构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
(3)Controller Manager: 负责管理集群的各种资源,保证资源处于预期的状态。
(4)etcd: 负责保存k8s集群的配置信息和各种资源的状态信息,当数据发生变化时,etcd会快速的通知k8s相关组件。
(5)pod网络:pod要能够相互通信,k8s集群必须掌握pod网络,fannel是其中一个可选的方案,我们用的是calico。
2、node节点
node是pod运行的地方。node上运行的k8s组件有kubelet、kube-proxy和pod网络(例如flannel、calico)
(1)kubelet: 是node的agent,当scheduler去确定在某个node上运行pod后,会将pod的具体配置信息发送给该节点的kubelet,kubelet会根据这些信息创建和运行容器,并向master报告运行状态。
(2)kube-proxy: 每个node都会运行kube-proxy服务,外界通过service访问pod,kube-proxy负责将降访问service的TCP/UDP数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
(3)pod网络:pod能能够互相通信,k8s集群必须部署pod网络,flannel是其中一个可以选择的方案
3、部署过程:
(1)kubectl 发送部署请求到 API Server。
(2)API Server 通知 Controller Manager 创建一个 deployment 资源。
(3)Scheduler 执行调度任务,将两个副本 Pod 分发到 k8s-node1 和 k8s-node2。
(4)k8s-node1 和 k8s-node2 上的 kubectl 在各自的节点上创建并运行 Pod。
三、创建资源的方式
1、用kubectl命令直接创建,比如:
kubectl run httpd-app --image=reg.yunwei.com/learn/httpd:latest --replicas=2
2、通过配置文件和kubectl apply -f 创建:
kubectl apply -f httpd.yaml
#httpd.yaml的内容:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: httpd-deployment spec: replicas: 2 template: metadata: labels: name: httpd spec: containers: - name: httpd-app image: reg.yunwei.com/learn/httpd:latest
3、比较
基于命令的方式:
(1)简单直观快捷,上手快。
(2)适合临时测试或实验。
基于配置文件的方式:
(1)配置文件描述了what,即应用最终要达到的状态。
(2)配置文件提供了创建资源的模板,能够重复部署。
(3)可以像管理代码一样管理部署。
(4)适合正式的、跨环境的、规模化部署。
(5)这种方式要求熟悉配置文件的语法,有一定的难度。
四、deployment yaml 文件
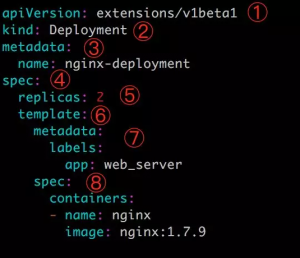
① apiVersion 是当前配置格式的版本。
② kind 是要创建的资源类型,这里是 Deployment。
③ metadata 是该资源的元数据,name 是必需的元数据项。
④ spec 部分是该 Deployment 的规格说明。
⑤ replicas 指明副本数量,默认为 1。
⑥ template 定义 Pod 的模板,这是配置文件的重要部分。
⑦ metadata 定义 Pod 的元数据,至少要定义一个 label。label 的 key 和 value 可以任意指定。
⑧ spec 描述 Pod 的规格,此部分定义 Pod 中每一个容器的属性,name 和 image 是必需的。
注意:最后name前面加个横线是因为container后面是一个列表
运行yaml文件:
kubectl apply -f httpd.yaml #运行pod kubectl delete -f http.yaml #删除pod
(1)伸缩(Scale Up/Down):是指在线增加或减少 Pod 的副本数。直接改写yaml配置文件的 replicas 参数即可
(2)节点故障(Failover):若其中一个node故障, Kubernetes 会检查到 k8s-node3 不可用,将 k8s-node1 上的 Pod 标记为 Terminating 状态,并在 k8s-node2 上新创建两个 Pod,维持总副本数为原指定副本数 3。
当 k8s-node2 恢复后,Terminating 的 Pod 会被删除,不过已经运行的 Pod 不会重新调度回 k8s-node2。
(3)用 label 控制 Pod 的位置: 默认配置下,Scheduler 会将 Pod 调度到所有可用的 Node。不过有些情况我们希望将 Pod 部署到指定的 Node,比如将有大量磁盘 I/O 的 Pod 部署到配置了 SSD 的 Node;或者 Pod 需要 GPU,需要运行在配置了 GPU 的节点上。
Kubernetes 是通过 label 来实现这个功能的。label 是 key-value 对,各种资源都可以设置 label,灵活添加各种自定义属性。
给节点添加label:
kubectl label node 192.168.11.5 disktype=ssd
yaml文件中yaml的应用:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: httpd-deployment spec: replicas: 2 template: metadata: labels: name: httpd spec: containers: - name: httpd-app image: reg.yunwei.com/learn/httpd:latest nodeSelector: disktype: ssd
五、daemonset
Deployment 部署的副本 Pod 会分布在各个 Node 上,每个 Node 都可能运行好几个副本。DaemonSet 的不同之处在于:每个 Node 上最多只能运行一个副本。
(2)在每个节点上运行日志收集 Daemon,比如 flunentd 或 logstash。
(3)在每个节点上运行监控 Daemon,比如 Prometheus Node Exporter 或 collectd。
六、job
apiVersion: batch/v1 kind: Job metadata: name: job spec: template: spec: containers: - name: job image: reg.yunwei.com/learn/busybox:latest command: ["echo","hello kubernetes"] restartPolicy: Never
① batch/v1 是当前 Job 的 apiVersion。
② 指明当前资源的类型为 Job。
③ restartPolicy 指定什么情况下需要重启容器。对于 Job,只能设置为 Never 或者 OnFailure。对于其他 controller(比如 Deployment)可以设置为 Always 。
七、cronjob
apiVersion: batch/v1beta1 kind: CronJob metadata: name: timing spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: timing image: reg.yunwei.com/learn/busybox:latest command: ["echo","hello k8s cronjob!"] restartPolicy: OnFailure
① batch/v1beta1 是当前 CronJob 的 apiVersion。
② 指明当前资源的类型为 CronJob。
③ schedule 指定什么时候运行 Job,其格式与 Linux cron 一致。这里 */1 * * * * 的含义是每一分钟启动一次。
④ jobTemplate 定义 Job 的模板,格式与前面 Job 一致。
八、service
1、通过service访问pod
Kubernetes Service 从逻辑上代表了一组 Pod,具体是哪些 Pod 则是由 label 来挑选。Service 有自己的 IP,而且这个 IP 是不变的。客户端只需要访问 Service 的 IP,Kubernetes 则负责建立和维护 Service 与 Pod 的映射关系。无论后端 Pod 如何变化,对客户端不会有任何影响,因为 Service 没有变。
#先创建deployment文件,在创建service文件:
apiVersion: v1 kind: Service metadata: name: httpd-svc spec: ports: - port: 8080 targetPort: 80 protocol: TCP selector: run: httpd
① v1 是 Service 的 apiVersion。
② 指明当前资源的类型为 Service。
③ Service 的名字为 httpd-svc。
④ selector 指明挑选那些 label 为 run: httpd 的 Pod 作为 Service 的后端。
⑤ 将 Service 的 8080 端口映射到 Pod 的 80 端口,使用 TCP 协议。
iptables 将访问 Service 的流量转发到后端 Pod,而且使用类似轮询的负载均衡策略。
2、dns访问service
coredns 是一个 DNS 服务器。每当有新的 Service 被创建,coredns 会添加该 Service 的 DNS 记录。Cluster 中的 Pod 可以通过 <SERVICE_NAME>.<NAMESPACE_NAME> 访问 Service。
我们通过另一个容器来访问刚才的pod
(1)启动容器busybox
(2)通过名称访问service中运行的pod(进入到容器busybox中)
wget httpd-svc:80
发现可以访问。但要注意,通过名称访问,只能在同一名称空间。如果不是在同一名称空间,需要指定namespace. 执行如下:


1 apiVersion: extensions/v1beta1 2 kind: Deployment 3 metadata: 4 name: httpd2 5 namespace: kube-public 6 spec: 7 replicas: 2 8 template: 9 metadata: 10 labels: 11 name: httpd2 12 run: httpd2 13 spec: 14 containers: 15 - name: httpd-app2 16 image: reg.yunwei.com/learn/httpd:latest 17 ports: 18 - containerPort: 80 19 20 --- 21 apiVersion: v1 22 kind: Service 23 metadata: 24 name: httpd-svc2 25 namespace: kube-public 26 spec: 27 ports: 28 - port: 8080 29 targetPort: 80 30 protocol: TCP 31 selector: 32 run: httpd2
同样启动容器busybox,并指定名称空间进行访问
wget httpd2-svc.kube-public:80
或者在启动容器busybox时就指定名称空间
kubectl run -it –image=busybox -n kube-public /bin/sh
3、外网访问pod
除了 Cluster 内部可以访问 Service,很多情况我们也希望应用的 Service 能够暴露给 Cluster 外部。Kubernetes 提供了多种类型的 Service,默认是 ClusterIP。
(1)ClusterIP
Service 通过 Cluster 内部的 IP 对外提供服务,只有 Cluster 内的节点和 Pod 可访问,这是默认的 Service 类型,前面实验中的 Service 都是 ClusterIP。
(2)NodePort
Service 通过 Cluster 节点的静态端口对外提供服务。Cluster 外部可以通过 <NodeIP>:<NodePort> 访问 Service。
(3)LoadBalancer
Service 利用 cloud provider 特有的 load balancer 对外提供服务,cloud provider 负责将 load balancer 的流量导向 Service。目前支持的 cloud provider 有 GCP、AWS、Azur 等。
apiVersion: v1 kind: Service metadata: name: httpd-svc3 spec: ports: - port: 8080 targetPort: 80 protocol: TCP nodePort: 30000 selector: run: httpd type: NodePort
(1)nodePort 是节点上监听的端口。
(2)port 是 ClusterIP 上监听的端口(svc的端口)。
(3)targetPort 是 Pod 监听的端口。
九、数据管理(volume)
1、emptyDir
emptyDir 是最基础的 Volume 类型。一个 emptyDir Volume 是 Host 上的一个空目录。emptyDir Volume 对于容器来说是持久的,对于 Pod 则不是。当 Pod 从节点删除时,Volume 的内容也会被删除。但如果只是容器被销毁而 Pod 还在,则 Volume 不受影响。emptyDir Volume 的生命周期与 Pod 一致。
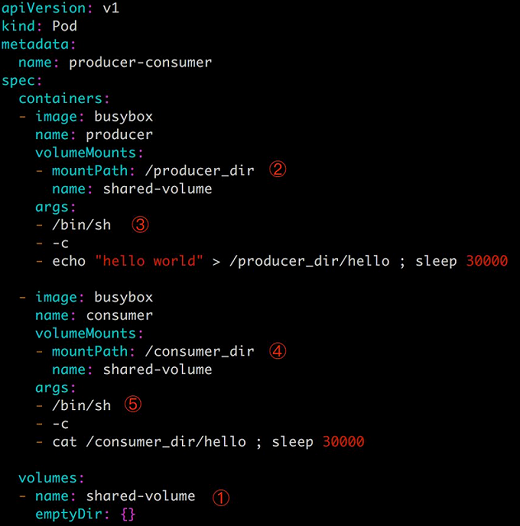
① 文件最底部 volumes 定义了一个 emptyDir 类型的 Volume shared-volume。
② producer 容器将 shared-volume mount 到 /producer_dir 目录。
③ producer 通过 echo 将数据写到文件 hello 里。
④ consumer 容器将 shared-volume mount 到 /consumer_dir 目录。
⑤ consumer 通过 cat 从文件 hello 读数据。
emptyDir 是 Host 上创建的临时目录,其优点是能够方便地为 Pod 中的容器提供共享存储,不需要额外的配置。但它不具备持久性,如果 Pod 不存在了,emptyDir 也就没有了。
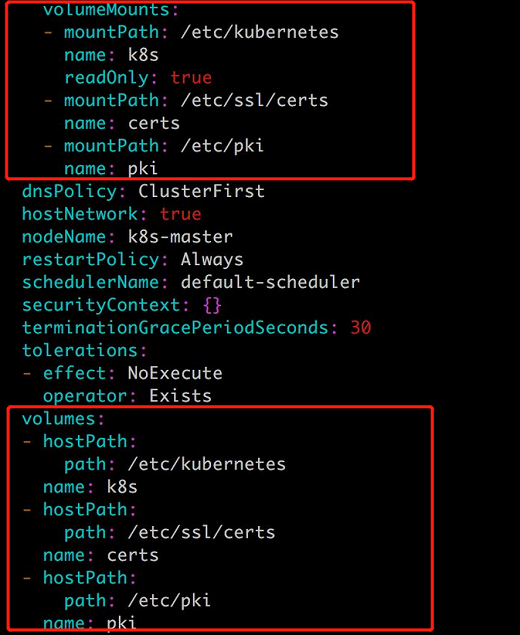
2、hostPath Volume
hostPath Volume 的作用是将 Docker Host 文件系统中已经存在的目录 mount 给 Pod 的容器。大部分应用都不会使用 hostPath Volume,因为这实际上增加了 Pod 与节点的耦合,限制了 Pod 的使用。不过那些需要访问 Kubernetes 或 Docker 内部数据(配置文件和二进制库)的应用则需要使用 hostPath。
3、外部Storage Provider
如果 Kubernetes 部署在诸如 AWS、GCE、Azure 等公有云上,可以直接使用云硬盘作为 Volume,下面是 AWS Elastic Block Store 的例子:
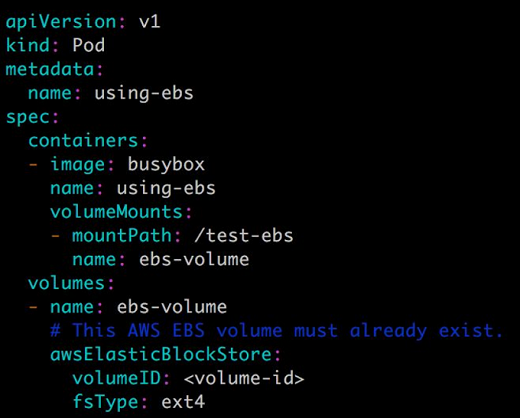
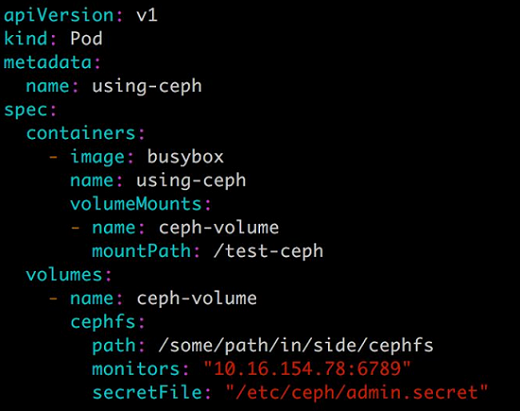
Kubernetes Volume 也可以使用主流的分布式存,比如 Ceph、GlusterFS 等,下面是 Ceph 的例子:
4、PV & PVC
PersistentVolume (PV) 是外部存储系统中的一块存储空间,由管理员创建和维护。与 Volume 一样,PV 具有持久性,生命周期独立于 Pod。
PersistentVolumeClaim (PVC) 是对 PV 的申请 (Claim)。PVC 通常由普通用户创建和维护。需要为 Pod 分配存储资源时,用户可以创建一个 PVC,指明存储资源的容量大小和访问模式(比如只读)等信息,Kubernetes 会查找并提供满足条件的 PV。
#NFS pv的编排文件:
apiVersion: v1 kind: PersistentVolume metadata: name: mypv1 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Recycle storageClassName: nfs nfs: path: /nfsdata/pv1 #需要创建pv1目录,否则pod起不来 server: 192.168.11.7
① capacity 指定 PV 的容量为 1G。
② accessModes 指定访问模式为 ReadWriteOnce,支持的访问模式有:
ReadWriteOnce – PV 能以 read-write 模式 mount 到单个节点。
ReadOnlyMany – PV 能以 read-only 模式 mount 到多个节点。
ReadWriteMany – PV 能以 read-write 模式 mount 到多个节点。
persistentVolumeReclaimPolicy 指定当 PV 的回收策略为 Recycle,支持的策略有:rm -rf /thevolume/*。 ④ storageClassName 指定 PV 的 class 为 nfs。相当于为 PV 设置了一个分类,PVC 可以指定 class 申请相应 class 的 PV。
⑤ 指定 PV 在 NFS 服务器上对应的目录。
#PVC的编排文件:
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mypvc1 spec: accessModes: - ReadWriteOnce resources: requests: storage: 1Gi storageClassName: nfs
#在pod中使用PVC:
apiVersion: v1 kind: Pod metadata: name: mypod1 spec: containers: - name: mypod1 image: reg.yunwei.com/learn/busybox:latest args: - /bin/sh - -c - sleep 30000 volumeMounts: - mountPath: "/mydata" name: mydata volumes: - name: mydata persistentVolumeClaim: claimName: mypvc1
回收pv:
(1)先停掉pod
(2)删除PVC
(3)删除pv
pv的动态供给:
动态供给是通过 StorageClass 实现的
十、机密信息管理(secret)
Secret 会以密文的方式存储数据,避免了直接在配置文件中保存敏感信息。Secret 会以 Volume 的形式被 mount 到 Pod,容器可通过文件的方式使用 Secret 中的敏感数据;此外,容器也可以环境变量的方式使用这些数据。
Secret 可通过命令行或 YAML 创建。比如希望 Secret 中包含如下信息:
1)用户名 admin
2)密码 123456
1、四种常见secret的方法:
(1)通过 --from-literal:
kubectl create secret generic mysecret --from-literal=username=admin --from-literal=password=123
(2)通过 --from-file:
echo -n admin > ./username echo -n 123456 > ./password kubectl create secret generic mysecret --from-file=./username --from-file=./password
(3)通过 --from-env-file:
cat << EOF > env.txt username=admin password=123456 EOF kubectl create secret generic mysecret --from-env-file=env.txt
(4)通过 YAML 配置文件:
apiVersion: v1 kind: Secret metadata: name: mysecret data: username: YWRtaW4= password: MTIzNDU2
文件中的敏感数据必须是通过 base64 编码后的结果。(-n 不换行)
[root@ren7 ~]# echo -n admin | base64 YWRtaW4= [root@ren7 ~]# echo -n 123456 | base64 MTIzNDU2
2、volume方式使用secret
apiVersion: v1 kind: Pod metadata: name: mypod spec: containers: - name: mypod image: reg.yunwei.com/learn/busybox:latest args: - /bin/sh - -c - sleep 10; touch /tmp/healthy; sleep 30000 volumeMounts: - mountPath: "/etc/foo" name: foo readOnly: true volumes: - name: foo secret: secretName: mysecret
① 定义 volume foo,来源为 secret mysecret
② 将 foo mount 到容器路径 /etc/foo,可指定读写权限为 readOnly
自定义存放数据的文件名:
secret: secretName: mysecret items: - key: username path: my-group/my-username - key: password path: my-group/my-password
以 Volume 方式使用的 Secret 支持动态更新:Secret 更新后,容器中的数据也会更新。
3、环境变量方式使用secret
apiVersion: v1 kind: Pod metadata: name: mypod3 spec: containers: - name: mypod3 image: reg.yunwei.com/learn/busybox:latest args: - /bin/sh - -c - sleep 10; touch /tmp/healthy; sleep 30000 env: - name: SECRET_USERNAME valueFrom: secretKeyRef: name: mysecret key: username - name: SECRET_PASSWORD valueFrom: secretKeyRef: name: mysecret key: password
环境变量读取 Secret 很方便,但无法支撑 Secret 动态更新。
Secret 可以为 Pod 提供密码、Token、私钥等敏感数据。
十一、配置信息管理(configmap)
Secret 可以为 Pod 提供密码、Token、私钥等敏感数据;对于一些非敏感数据,比如应用的配置信息,则可以用 ConfigMap
ConfigMap 的创建和使用方式与 Secret 非常类似,主要的不同是数据以明文的形式存放。
与 Secret 一样,ConfigMap 也支持四种创建方式:(--from-literal、--from-file、--from-env-file、yaml)
十二、k8s监控
1、Weave Scope 是 Docker 和 Kubernetes 可视化监控工具。Scope 提供了至上而下的集群基础设施和应用的完整视图,用户可以轻松对分布式的容器化应用进行实时监控和问题诊断。
Weave Scope 的最大特点是会自动生成一张 Docker 容器地图,让我们能够直观地理解、监控和控制容器。
2、Heapster 是 Kubernetes 原生的集群监控方案。Heapster 以 Pod 的形式运行,它会自动发现集群节点、从节点上的 Kubelet 获取监控数据。Kubelet 则是从节点上的 cAdvisor 收集数据。
Heapster 将数据按照 Pod 进行分组,将它们存储到预先配置的 backend 并进行可视化展示。Heapster 当前支持的 backend 有 InfluxDB(通过 Grafana 展示),Google Cloud Monitoring 等。
3、Prometheus是一个开源系统监测和警报工具箱。 Prometheus Operator 是 CoreOS 开发的基于 Prometheus 的 Kubernetes 监控方案,也可能是目前功能最全面的开源方案。
主要特征:
1)多维数据模型(时间序列由metri和key/value定义)
2)灵活的查询语言
3)不依赖分布式存储
4)采用 http 协议,使用 pull 拉取数据
5)可以通过push gateway进行时序列数据推送
6)可通过服务发现或静态配置发现目标
7)多种可视化图表及仪表盘支持
Prometheus组件包括:Prometheus server、push gateway 、alertmanager、Web UI等。
Prometheus server 定期从数据源拉取数据,然后将数据持久化到磁盘。Prometheus 可以配置 rules,然后定时查询数据,当条件触发的时候,会将 alert 推送到配置的 Alertmanager。Alertmanager 收到警告的时候,可以根据配置,聚合并记录新时间序列,或者生成警报。同时还可以使用其他 API 或者 Grafana 来将收集到的数据进行可视化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号