openstack总结复习
一、云计算概念
1、云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问, 通过互联网进入可配置的计算资源共享池(资源包括网络,计算,存储,应用软件,服务)
2、云计算所包含的几个层次服务:
• SaaS( Software as a Service): 软件即服务,把在线软件作为一种服务。
• Paas( Platform as a Service): 平台即服务,把平台作为一种服务。
• Iaas( Infrastructure as a Service):基础设施即服务,把硬件设备作为一种服务。
3、OpenStack:是由Rackspace和NASA(美国国家航空航天局)共同开发的云计算平台, 是一个开源的 IaaS(基础设施及服务)云计算平台,让任何人都可以自行建立和提供云端运算服务,每半年发布一次,用Python语言编写
4、openstack的版本:
5、云应用形式
(1)私有云
将基础设施与软硬件资源构建于防火墙内,基于iaas构建私有云平台供企业内部使用,开源组件有:openstack(最为出色),cloudstack等
(2)云存储
云存储系统是一个以数据存储和管理为核心的云计算系统
(3)云游戏
游戏运行云平台服务端,云平台将游戏画面解压缩后传给用户,用户端无需高配置处理器和显卡,只需要基本的视频解压缩能力即可。
(4)云物联
基于云平台实现物物相连的互联网。
(5)云安全
通过网状的大量客户端检测网络中软件的异常,获取木马,恶意程序的最新信息,推送到云平台服务端自动分析和处理,再把解决方案发送给每一个客户端。云平台使用者越多,越安全。
(6)公有云
云平台对外开放,主要以Iaas和Paas为主,较为成熟的是Iaas,如阿里云,腾讯云,青云,ucloud,首都在线等
(7)混合云
公有云和私有云的结合,即对企业内部又对企业外部,例如AWS
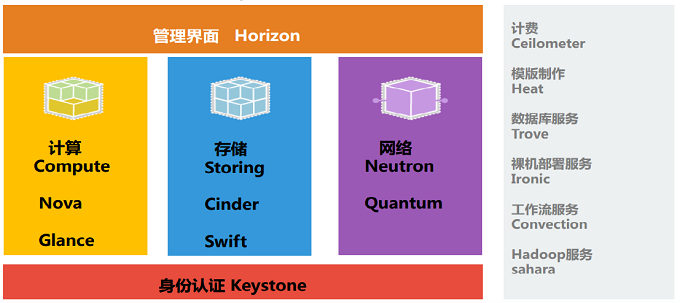
二、openstack的构成组件
OpenStack共享服务组件:
数据库服务( Database Service ):MairaDB 及 MongoDB
消息传输(Message Queues):RabbitMQ
缓存(cache): Memcached
时间(time sync):NTP
存储(storge provider):ceph、GFS、LVM、ISICI等
高可用及负载均衡:pacemaker、HAproxy、keepalive、lvs等
OpenStack核心组件:
身份服务( Identity Service ):Keystone
计算( Compute ): Nova
镜像服务( Image Service ): Glance
网络 & 地址管理( Network ): Neutron
对象存储( Object Storage ): Swift
块存储 (Block Storage) : Cinder
UI 界面 (Dashboard) : Horizon
测量 (Metering) : Ceilometer
部署编排 (Orchestration) : Heat
三、信息队列rabbitmq
1、概念:属于一个流行的开源消息队列系统。属于AMQP( 高级消息队列协议 ) 标准的一个 实现。是应用层协议的一个开放标准,为面向消息的中间件设计。用于在分布式系统中存储转发消息,在 易用性、扩展性、高可用性等方面表现不俗。
消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然。
AMQP 的主要特征是面向消息、队列、路由(包括点对点和发布 / 订阅)、可靠性、安全。
RabbitMQ的特点:
使用Erlang编写
支持持久化
支持HA
提供C# , erlang,java,perl,python,ruby等的client开发端
2、rabbitmq中的概念名词
Broker:简单来说就是消息队列服务器实体。
Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
Routing Key:路由关键字, exchange根据这个关键字进行消息投递。
vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
producer:消息生产者,就是投递消息的程序。
consumer:消息消费者,就是接受消息的程序。
channel:消息通道,在客户端的每个连接里,可建立多个channel,每个 channel代表一个会话任务。
3、rabbitmq工作原理
MQ 是消费 - 生产者模型的一个典型的代表,一端往消息队列中不断写入消息,而另一端则可以读取或者订阅队列中的消息。 MQ 则是遵循了 AMQP协议的具体实现和产品。在项目中,将一些无需即时返回且耗时的操作提取出来,进行了异步处理,而这种异步处理的方式大大的节省了服务器的请求响应时间,从而提高了系统的吞吐量。
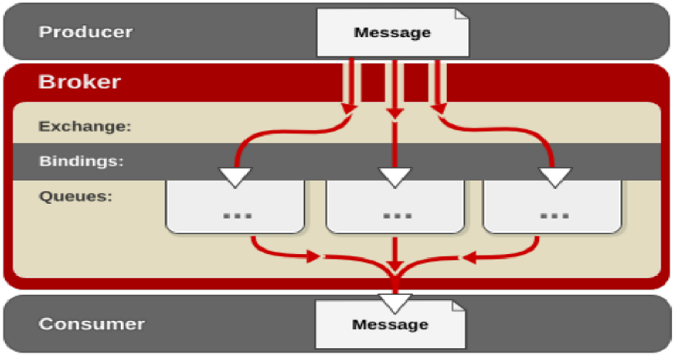
( 1)客户端连接到消息队列服务器,打开一个channel。
( 2)客户端声明一个exchange,并设置相关属性。
( 3)客户端声明一个queue,并设置相关属性。
( 4)客户端使用routing key,在exchange和queue之间建立好绑定关系。
( 5)客户端投递消息到exchange。
( 6) exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里
4、rabbitmq相关命令:
(1)查看监听的端口:
netstat -lantp | grep 5672
(2)配置文件:
vim /etc/rabbitmq/rabbitmq.config
(3)rabbitmqctl命令:
rabbitmqctl status #查看节点状态 rabbitmqctl cluster_status #检查集群状态 rabbitmqctl stop_app #停止应用 rabbitmqctl join_cluster --ram rabbit@ren3 #以ram的方式加入集群 rabbitmqctl start_app #启动应用 rabbitmqctl reset #重置节点
5、注意事项
四、memcache缓存系统(端口:11211)
1、概念(key-value)
Memcached 是一个开源的、高性能的分布式内存对象缓存系统。通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高网站访问速度,加速动态WEB应用、减轻数据库负载。
2、memcache缓存流程
(1)检查客户端请求的数据是否在 Memcache 中,如果存在,直接将请求的数据返回,不在对数据进行任何操作。
(2)如果请求的数据不在 Memcache 中,就去数据库查询,把从数据库中获取的数据返回给客户端,同时把数据缓存一份 Memcache 中
(3)每次更新数据库的同时更新 Memcache 中的数据库。确保数据信息一致性。
(4)当分配给 Memcache 内存空间用完后,会使用LRU(least Recently Used ,最近最少使用 ) 策略加到其失效策略,失效的数据首先被替换掉,然后在替换掉最近未使用的数据。
五、keystone身份认证服务
1、概念(端口:5000,35357)
keystone 是OpenStack的组件之一,用于为OpenStack家族中的其它组件成员提供统一的认证服务,包括身份验证、令牌的发放和校验、服务列表、用户权限的定义等等。云环境中所有的服务之间的授权和认证都需要经过 keystone. 因此 keystone 是云平台中第一个即需要安装的服务。
Authentication 是 Keystone 验证 User 身份的过程。User 访问 OpenStack 时向 Keystone 提交用户名和密码形式的 Credentials,Keystone 验证通过后会给 User 签发一个 Token 作为后续访问的 Credential。
安全包含两部分:Authentication(认证)和 Authorization(鉴权)
2、基本框架
3、认证流程

六、glance镜像服务
1、概念
Glance是Openstack项目中负责镜像管理的模块,其功能包括虚拟机镜像的查找、注册和检索等。 Glance提供Restful API可以查询虚拟机镜像的metadata及获取镜像。 Glance可以将镜像保存到多种后端存储上,比如简单的文件存储或者对象存储。
2、glance架构
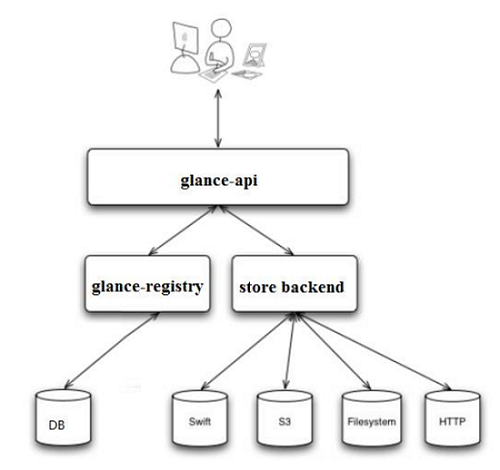
(1)glance-api 是系统后台运行的服务进程。 对外提供 REST API,响应 image 查询、获取和存储的调用。(端口:9292)
(2)glance-registry 是系统后台运行的服务进程。 负责处理和存取 image 的 metadata,例如 image 的大小和类型。(端口:9191)
glance支持多种格式的 image,包括:Raw,vmdk,ISO,QCOW2等
(3)store backend:Glance 自己并不存储 image。 真正的 image 是存放在 backend 中的。 Glance 支持多种 backend。包括:1. A directory on a local file system(这是默认配置)2. GridFS 3. ceph RBD 4. Amazon S3 5. Sheepdog 6. OpenStack Block Storage (Cinder) 7. OpenStack Object Storage (Swift) 8. VMware ESX;具体使用哪种哪种 backend,是在 /etc/glance/glance-api.conf 中配置的
3、查看保存目录

每个 image 在目录下都对应有一个文件,文件以 image 的 ID 命名。
4、glance创建镜像
OpenStack 为终端用户提供了 Web UI(Horizon)和命令行 CLI 两种交换界面。
CLI创建image:
openstack image create "cirros" --file cirros-0.3.3-x86_64-disk.img.img --disk-format qcow2 --container-format bare --public
七、nova计算服务
1、概念
Nova 是 OpenStack 最核心的服务,负责维护和管理云环境的计算资源。OpenStack 作为 IaaS 的云操作系统,虚拟机生命周期管理也就是通过 Nova 来实现的。
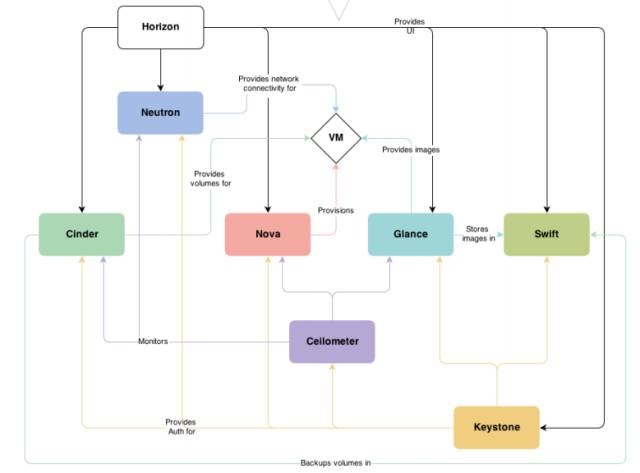
在上图中可以看到,Nova 处于 Openstak 架构的中心,其他组件都为 Nova 提供支持: Glance 为 VM 提供 image;Cinder 和 Swift 分别为 VM 提供块存储和对象存储;Neutron 为 VM 提供网络连接。
2、nova架构
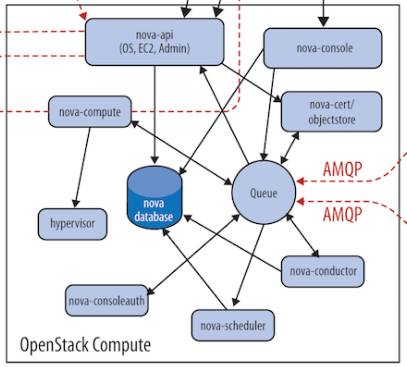
(1)nova-api是整个Nova 组件的门户,接收和响应客户的 API 调用。所有对 Nova 的请求都首先由 nova-api 处理。(端口:8774,8775)
Nova-api 对接收到的 HTTP API 请求会做如下处理:
1)检查客户端传入的参数是否合法有效
2)调用 Nova 其他子服务的处理客户端 HTTP 请求
3)格式化 Nova 其他子服务返回的结果并返回给客户端
(2)nova-scheduler:虚机调度服务,负责决定在哪个计算节点上运行虚机。
在 /etc/nova/nova.conf 中,nova 通过 driver=filter_scheduler 这个参数来配置 nova-scheduler。
Filter scheduler 是 nova-scheduler 默认的调度器,调度过程分为两步:
1) 通过过滤器(filter)选择满足条件的计算节点(运行 nova-compute)
2) 通过权重计算(weighting)选择在最优(权重值最大)的计算节点上创建 Instance。
(3)nova-compute 是管理虚机的核心服务,在计算节点上运行。通过调用Hypervisor API实现节点上的 instance的生命周期管理。
Openstack中虚机默认的保存路径在:/var/lib/nova/instances
(4)nova-conductor:nova-compute 经常需要更新数据库,比如更新和获取虚机的状态。 出于安全性和伸缩性的考虑,nova-compute 并不会直接访问数据库,而是将这个任务委托给 nova-conductor。
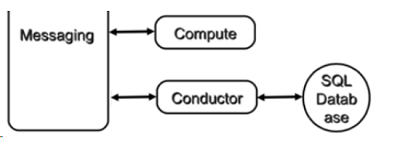
(5)Console Interface
openstack-nova-api:nova门户
openstack-nova-conductor:帮助nova-compute访问数据库的
openstack-nova-console:提供多种方式访问虚机的控制台
openstack-nova-novncproxy:是基于web浏览器提供虚机的控制台(端口:6080)
openstack-nova-scheduler:负责调度虚机启动到哪一个计算节点
openstack-nova-placement-api:资源使用情况追踪
openstack-nova-spicehtml5proxy: 基于 HTML5 浏览器的 SPICE 访问
openstack-nova-xvpnvncproxy: 基于 Java 客户端的 VNC 访问
openstack-nova-consoleauth: 负责对访问虚机控制台请求提供 Token 认证
openstack-nova-cert: 提供 x509 证书支持
3、nova各组件的额协同工作
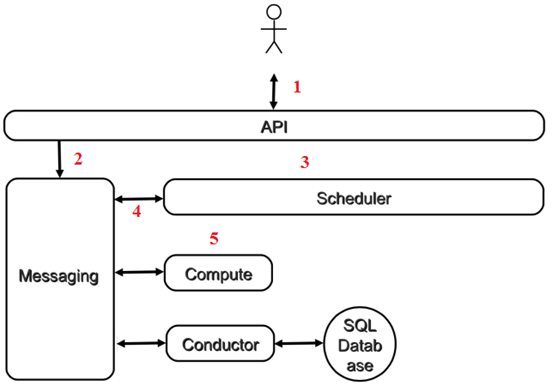
-
客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(nova-api)发送请求:“帮我创建一个虚机”
-
API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个虚机”
-
Scheduler(nova-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计算节点中选出节点 A
-
Scheduler 向 Messaging 发送了一条消息:“在计算节点 A 上创建这个虚机”
-
计算节点 A 的 Compute(nova-compute)从 Messaging 中获取到 Scheduler 发给它的消息,然后在本节点的 Hypervisor 上启动虚机。
-
在虚机创建的过程中,Compute 如果需要查询或更新数据库信息,会通过 Messaging 向 Conductor(nova-conductor)发送消息,Conductor 负责数据库访问。
以上是创建虚机最核心的步骤, 这几个步骤向我们展示了 nova-* 子服务之间的协作的方式,也体现了 OpenStack 整个系统的分布式设计思想,掌握这种思想对我们深入理解 OpenStack 会非常有帮助。
4、nova创建虚机的详细过程
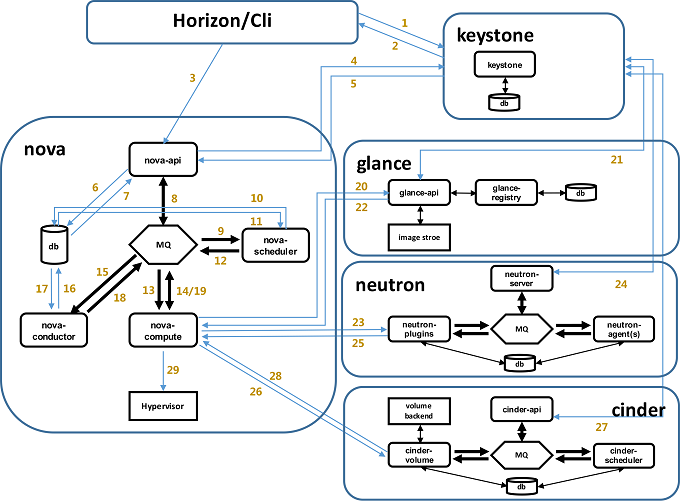
1)界面或命令行通过RESTful API向keystone获取认证信息。
2)keystone通过用户请求认证信息,并生成auth-token返回给对应的认证请求。
3)界面或命令行通过RESTful API向nova-api发送一个boot instance的请求(携带auth-token)。
4)nova-api接受请求后向keystone发送认证请求,查看token是否为有效用户和token。
5)keystone验证token是否有效,如有效则返回有效的认证和对应的角色(注:有些操作需要有角色权限才能操作)。
6)通过认证后nova-api和数据库通讯。
7)初始化新建虚拟机的数据库记录。
8)nova-api通过rpc.call向nova-scheduler请求是否有创建虚拟机的资源(Host ID)。
9)nova-scheduler进程侦听消息队列,获取nova-api的请求。
10)nova-scheduler通过查询nova数据库中计算资源的情况,并通过调度算法计算符合虚拟机创建需要的主机。
11)对于有符合虚拟机创建的主机,nova-scheduler更新数据库中虚拟机对应的物理主机信息。
12)nova-scheduler通过rpc.cast向nova-compute发送对应的创建虚拟机请求的消息。
13)nova-compute会从对应的消息队列中获取创建虚拟机请求的消息。
14)nova-compute通过rpc.call向nova-conductor请求获取虚拟机消息。(Flavor)
15)nova-conductor从消息队队列中拿到nova-compute请求消息。
16)nova-conductor根据消息查询虚拟机对应的信息。
17)nova-conductor从数据库中获得虚拟机对应信息。
18)nova-conductor把虚拟机信息通过消息的方式发送到消息队列中。
19)nova-compute从对应的消息队列中获取虚拟机信息消息。
20)nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求glance-api获取创建虚拟机所需要镜像。
21)glance-api向keystone认证token是否有效,并返回验证结果。
22)token验证通过,nova-compute获得虚拟机镜像信息(URL)。
23)nova-compute通过keystone的RESTfull API拿到认证k的token,并通过HTTP请求neutron-server获取创建虚拟机所需要的网络信息。
24)neutron-server向keystone认证token是否有效,并返回验证结果。
25)token验证通过,nova-compute获得虚拟机网络信息。
26)nova-compute通过keystone的RESTfull API拿到认证的token,并通过HTTP请求cinder-api获取创建虚拟机所需要的持久化存储信息。
27)cinder-api向keystone认证token是否有效,并返回验证结果。
28)token验证通过,nova-compute获得虚拟机持久化存储信息。
29)nova-compute根据instance的信息调用配置的虚拟化驱动来创建虚拟机。
八、neutron网络服务 (端口:9696)
1、概念
Neutron 的设计目标是实现“网络即服务(Networking as a Service)”。为了达到这一目标,在设计上遵循了基于 SDN 实现网络虚拟化的原则。
SDN 模式服务— NeutronSDN( 软件定义网络 ),通过使用它,网络管理员和云计算操作员可以通过程序来动态定义虚拟网络设备。Openstack 网络中的 SDN 组件就是 Quantum。但因为版权问题而改名为Neutron 。
2、neutron网络基本概念
(1)network
Neutron 支持多种类型的 network,包括 local, flat, VLAN, VxLAN 和 GRE。
1)vlan
vlan 网络是具有 802.1q tagging 的网络。vlan 是一个二层的广播域,同一 vlan 中的 instance 可以通信,不同 vlan 只能通过 router 通信。vlan 网络可跨节点,是应用最广泛的网络类型。
2)vxlan
vxlan 是基于隧道技术的 overlay 网络。vxlan 网络通过唯一的 segmentation ID(也叫 VNI)与其他 vxlan 网络区分。vxlan 中数据包会通过 VNI 封装成 UDP 包进行传输。因为二层的包通过封装在三层传输,能够克服 vlan 和物理网络基础设施的限制。
(2)subnet
subnet 是一个 IPv4 或者 IPv6 地址段。instance 的 IP 从 subnet 中分配。每个 subnet 需要定义 IP 地址的范围和掩码。
network namespace 是一种网络的隔离机制。
(3)port
port 可以看做虚拟交换机上的一个端口。port 上定义了 MAC 地址和 IP 地址,当 instance 的虚拟网卡 VIF(Virtual Interface) 绑定到 port 时,port 会将 MAC 和 IP 分配给 VIF。
(Project,Network,Subnet,Port 和 VIF 之间关系):
Project 1 : m Network 1 : m Subnet 1 : m Port 1 : 1 VIF m : 1 Instance
3、Neutron功能
Neutron 为整个 OpenStack 环境提供网络支持,包括二层交换,三层路由,负载均衡,防火墙和 VPN 等。
(1)二层交换switching:
Nova 的 Instance 是通过虚拟交换机连接到虚拟二层网络的。Neutron 支持多种虚拟交换机,包括 Linux 原生的 Linux Bridge 和 Open vSwitch。 Open vSwitch(OVS)是一个开源的虚拟交换机,它支持标准的管理接口和协议。
利用 Linux Bridge 和 OVS,Neutron 除了可以创建传统的 VLAN 网络,还可以创建基于隧道技术的 Overlay 网络,比如 VxLAN 和 GRE(Linux Bridge 目前只支持 VxLAN)。
(2)三层路由routing:
Instance 可以配置不同网段的 IP,Neutron 的 router(虚拟路由器)实现 instance 跨网段通信。router 通过 IP forwarding,iptables 等技术来实现路由和 NAT。
(3)负载均衡Load-Balancing:
Openstack 在 Grizzly 版本第一次引入了 Load-Balancing-as-a-Service(LBaaS),提供了将负载分发到多个 instance 的能力。LBaaS 支持多种负载均衡产品和方案,不同的实现以 Plugin 的形式集成到 Neutron,目前默认的 Plugin 是 HAProxy。
(4)防火墙Firewalling:
Neutron 通过下面两种方式来保障 instance 和网络的安全性。
1) Security Group
通过 iptables 限制进出 instance 的网络包。
2) Firewall-as-a-Service
FWaaS,限制进出虚拟路由器的网络包,也是通过 iptables 实现。
(5)OpenStack 至少包含下面几类网络类型
1)Management 网络(集群网)
用于节点之间 message queue 内部通信以及访问 database 服务,所有的节点都需要连接到 management 网络。
2)API 网络
OpenStack 各组件通过该网络向用户暴露 API 服务。Keystone, Nova, Neutron, Glance, Cinder, Horizon 的 endpoints 均配置在 API 网络上。通常,管理员也通过 API 网络 SSH 管理各个节点。
3)VM 网络(租户网)
VM 网络也叫 tenant 网络,用于 instance 之间通信。
VM 网络可以选择的类型包括 local, flat, vlan, vxlan 和 gre。
VM 网络由 Neutron 配置和管理。
4)External 网络(外网)
External 网络指的是 VM 网络之外的网络,该网络不由 Neutron 管理。 Neutron 可以将 router attach 到 External 网络,为 instance 提供访问外部网络的能力。 External 网络可能是企业的 intranet,也可能是 internet。
这几类网络只是逻辑上的划分,物理实现上有非常大的自由度。
4、neutron架构(分布式架构)
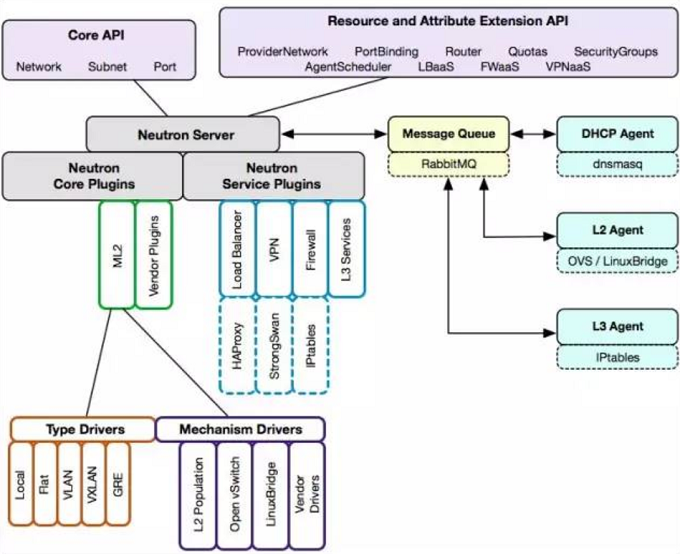
1)Neutron 通过 plugin 和 agent 提供的网络服务。
2)plugin 位于 Neutron server,包括 core plugin 和 service plugin。
3)agent 位于各个节点,负责实现网络服务。
4)core plugin 提供 L2 功能,ML2 是推荐的 plugin。
5)使用最广泛的 L2 agent 是 linux bridage 和 open vswitch。
6)service plugin 和 agent 提供扩展功能,包括 dhcp, routing, load balance, firewall, vpn (Virtual Private Network)等。
5、ML2
Moduler Layer 2(ML2):是 Neutron 在 Havana 版本实现的一个新的 core plugin,用于替代原有的 linux bridge plugin 和 open vswitch plugin。 作为新一代的 core plugin,提供了一个框架,允许在 OpenStack 网络中同时使用多种 Layer 2 网络技术,不同的节点可以使用不同的网络实现机制。
ML2 对二层网络进行抽象和建模,引入了 type driver 和 mechansim driver。这两类 driver 解耦了 Neutron 所支持的网络类型(type)与访问这些网络类型的机制(mechanism),其结果就是使得 ML2 具有非常好的弹性,易于扩展,能够灵活支持多种 type 和 mechanism。
mechanism driver 有三种类型:
Agent-based
包括 linux bridge, open vswitch 等。
Controller-based
包括 OpenDaylight, VMWare NSX 等。
基于物理交换机
包括 Cisco Nexus, Arista, Mellanox 等。 比如前面那个例子如果换成 Cisco 的 mechanism driver,则会在 Cisco 物理交换机的指定 trunk 端口上添加 vlan100。
linux bridge 和 open vswitch 的 ML2 mechanism driver 作用是配置各节点上的虚拟交换机。linux bridge driver 支持的 type 包括 local, flat, vlan, and vxlan。open vswitch driver 除这 4 种 type 还支持 gre。
L2 population driver 作用是优化和限制 overlay 网络中的广播流量。 vxlan 和 gre 都属于 overlay 网络。
6、Core Plugin/Agent 负责管理核心实体:net, subnet 和 port。而对于更高级的网络服务,则由 Service Plugin/Agent 管理。
7、虚机获取IP
Neutron 通过 dnsmasq 提供 DHCP 服务,而 dnsmasq 通过 Linux Network Namespace 独立的把每个 network 服务都隔离
ip netns list 命令列出所有的 namespace ip netns exec <network namespace name> <command> 管理 namespace
veth pair 是一种成对出现的特殊网络设备,它们象一根虚拟的网线,可用于连接两个 namespace。
instance 获取 IP 的过程如下:
1)vm 开机启动,发出 DHCPDISCOVER 广播,该广播消息在整个 net 中都可以被收到。
2)广播到达 veth tap19a0ed3d-fe,然后传送给 veth pair 的另一端 ns-19a0ed3d-fe。dnsmasq 在它上面监听,dnsmasq 检查其 host 文件,发现有对应项,于是dnsmasq 以 DHCPOFFER 消息将 IP(192.168.254.18)、子网掩码(255.255.255.0)、地址租用期限等信息发送给 vm。
3)vm 发送 DHCPREQUEST 消息确认接受此 DHCPOFFER。
4)dnsmasq 发送确认消息 DHCPACK,整个过程结束。
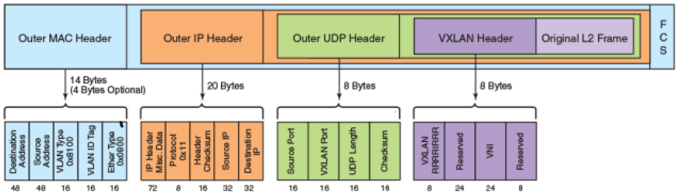
8、VXLAN
VXLAN 为 Virtual eXtensible Local Area Network。正如名字所描述的,VXLAN 提供与 VLAN 相同的以太网二层服务,但拥有更强的扩展性和灵活性。与 VLAN 相比,
VXLAN 有下面几个优势:
1)支持更多的二层网段。
VLAN 使用 12-bit 标记 VLAN ID,最多支持 (2^12)4094 个 VLAN,这对大型云部署会成为瓶颈。VXLAN 的 ID (VNI 或者 VNID)则用 24-bit 标记,支持 (2^24)16777216 个二层网段。
2)能更好地利用已有的网络路径。
VLAN 使用 Spanning Tree Protocol 避免环路,这会导致有一半的网络路径被 block 掉。VXLAN 的数据包是封装到 UDP 通过三层传输和转发的,可以使用所有的路径。
3)避免物理交换机 MAC 表耗尽。
由于采用隧道机制,TOR (Top on Rack) 交换机无需在 MAC 表中记录虚拟机的信息。
VXLAN 是将二层建立在三层上的网络。通过将二层数据封装到 UDP 的方式来扩展数据中心的二层网段数量。
VXLAN 是一种在现有物理网络设施中支持大规模多租户网络环境的解决方案。VXLAN 的传输协议是 IP + UDP。
VXLAN 包的格式如下:
9、Open vSwitch(东西流向:VM--VM 南北流向:VM--外网)(neutron-openvswitch端口:6633)
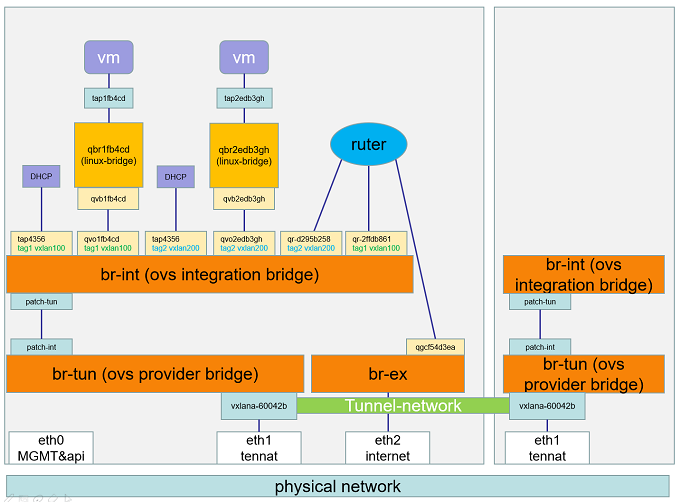
Open vSwitch 中的网络设备:(端口:6640)
br-ex:连接外部(external)网络的网桥。
br-int:集成(integration)网桥,所有 instance 的虚拟网卡和其他虚拟网络设备都将连接到该网桥。
br-tun:隧道(tunnel)网桥,基于隧道技术的 VxLAN 和 GRE 网络将使用该网桥进行通信。
tap interface:命名为 tapXXXX。
linux bridge:命名为 qbrXXXX。
veth pair:命名为 qvbXXXX, qvoXXXX
OVS integration bridge:命名为 br-int。
OVS patch ports:命名为 int-br-ethX 和 phy-br-ethX(X 为 interface 的序号)。
OVS provider bridge:命名为 br-ethX(X 为 interface 的序号)。
物理 interface:命名为 ethX(X 为 interface 的序号)。
OVS tunnel bridge:命名为 br-tun。
ovs网络的相关命令:
ovs-vsctl add-br br-ex ovs-vsctl add-port br-ex ens38 ovs-vsctl show
10、虚机通外网(iptables-SNAT)
11、外网访问虚机(floating ip)(iptables-DNAT)
九、horizon Web管理界面
1、概念
Horizon 为 Openstack 提供一个 WEB 前端的管理界面 (UI 服务 )通过 Horizone 所提供的 DashBoard 服务 , 管理员可以使用通过 WEB UI 对 Openstack 整体云环境进行管理 , 并可直观看到各种操作结果与运行状态。
配置文件(/etc/openstack-dashboard/local_settings)
placement端口:8778
2、区域(Region)
(1)地理上的概念,可以理解为一个独立的数据中心,每个所定义的区域有自己独立的Endpoint;
(2)区域之间是完全隔离的,但多个区域之间共享同一个Keystone和Dashboard(目前Openstack中的Dashboard还不支持多个区域);
(3)除了提供隔离的功能,区域的设计更多侧重地理位置的概念,用户可以选择离自己更新的区域来部署自己的服务,选择不同的区域主要是考虑那个区域更靠近自己,如用户在美国,可以选择离美国更近的区域;
(4)区域的概念是由Amazon在AWS中提出,主要是解决容错能力和可靠性;
3、可用性区域(Availablilty Zone)
AZ是在Region范围内的再次切分,例如可以把一个机架上的服务器划分为一个AZ,划分AZ是为了提高容灾能力和提供廉价的隔离服务;
4、Host Aggreates
一组具有共同属性的节点集合,如以CPU作为区分类型的一个属性,以磁盘(SSD\SAS\SATA)作为区分类型的一个属性,以OS(Windows\Linux)为作区分类型的一个属性;
5、Cell
nova为了增加横向扩展以及分布式、大规模(地理位置级别)部署的能力,同时又不增加数据库和消息中间件的复杂度,引入了cell的概念,并引入了nova-cell服务。
(1)主要是用来解决OpenStack的扩展性和规模瓶颈;
(2)每个Cell都有自己独立的DB和AMQP,不与其他模块共用DB和AMQP,解决了大规模环境中DB和AMQP的瓶颈问题;
(3)Cell实现了树形结构(通过消息路由)和分级调度(过滤算法和权重算法),Cell之间通过RPC通讯,解决了扩展性问题;
十、cinder存储服务
1、block storage
操作系统获得存储空间的方式一般有两种:
(1)通过某种协议(SAS,SCSI,SAN,iSCSI 等)挂接裸硬盘,然后分区、格式化、创建文件系统;或者直接使用裸硬盘存储数据(数据库)
(2)通过 NFS、CIFS 等 协议,mount 远程的文件系统
第一种裸硬盘的方式叫做 Block Storage(块存储),每个裸硬盘通常也称作 Volume(卷)
第二种叫做文件系统存储。NAS 和 NFS 服务器,以及各种分布式文件系统提供的都是这种存储。
2、cinder的具体功能:
(1)提供 REST API 使用户能够查询和管理 volume、volume snapshot 以及 volume type
(2)提供 scheduler 调度 volume 创建请求,合理优化存储资源的分配
(3)通过 driver 架构支持多种 back-end(后端)存储方式,包括 LVM,NFS,Ceph 和其他诸如 EMC、IBM 等商业存储产品和方案
3、cinder架构
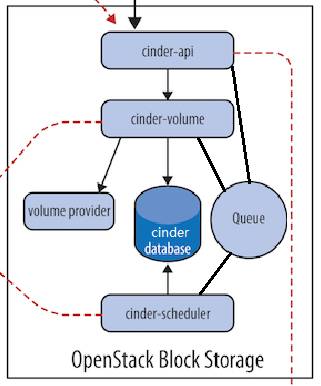
4、cinder子组件
(1)Cinder-api:接收 API 请求,调用 cinder-volume ;(端口:8776)
(2)Cinder-volume:管理 volume 的服务,与 volume provider 协调工作,管理 volume 的生命周期。运行 cinder-volume 服务的节点被称作为存储节点。
(3)cinder-scheduler:scheduler 通过调度算法选择最合适的存储节点创建 volume。
(4)volume provider:数据的存储设备,为 volume 提供物理存储空间。 cinder-volume 支持多种 volume provider,每种 volume provider 通过自己的 driver 与cinder-volume 协调工作。
(5)Message Queue:Cinder 各个子服务通过消息队列实现进程间通信和相互协作。因为有了消息队列,子服务之间实现了解耦,这种松散的结构也是分布式系统的重要特征。
(6)Database Cinder :有一些数据需要存放到数据库中,一般使用 MySQL。数据库是安装在控制节点上。
5、cinder各组件的协同工作

1)客户(可以是 OpenStack 最终用户,也可以是其他程序)向 API(cinder-api)发送请求:“帮我创建一个 volume”
2)API 对请求做一些必要处理后,向 Messaging(RabbitMQ)发送了一条消息:“让 Scheduler 创建一个 volume”
3)Scheduler(cinder-scheduler)从 Messaging 获取到 API 发给它的消息,然后执行调度算法,从若干计存储点中选出节点 A
4)Scheduler 向 Messaging 发送了一条消息:“让存储节点 A 创建这个 volume”
5)存储节点 A 的 Volume(cinder-volume)从 Messaging 中获取到 Scheduler 发给它的消息,然后通过 driver 在 volume provider 上创建 volume。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号