k8s集群部署(2)
一、利用ansible部署kubernetes准备阶段
1、集群介绍
基于二进制方式部署k8s集群和利用ansible-playbook实现自动化;二进制方式部署有助于理解系统各组件的交互原理和熟悉组件启动参数,有助于快速排查解决实际问题。
2、集群规划和基础参数设定
(1)搞哭用集群所需节点配置如下;
- 部署节点 x1 : 运行这份 ansible 脚本的节点
- etcd节点 x3 : 注意etcd集群必须是1,3,5,7...奇数个节点
- master节点 x1 : 运行集群主要组件
- node节点 x3 : 真正应用部署的节点,根据需要增加机器配置和节点数

(2)在部署节点准备ansible:
1)保证源时可用的,selinux和firewalld是关闭的(这里配的是云唯图书馆里的内部源)
2)下载并安装docker,并启动docker,开机自启docker
3)下载ansible
4)配置每台机器之间的静态解析和免密登陆
[root@ren8 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.11.3 ren3 192.168.11.4 ren4 192.168.11.5 ren5 192.168.11.6 ren6 192.168.11.7 ren7 192.168.11.8 ren8 192.168.11.8 reg.yunwei.com
3、在部署节点上传ansible工作文件:
[root@ren8 kubernetes]# ls bash ca.tar.gz harbor-offline-installer-v1.4.0.tgz image image.tar.gz k8s197.tar.gz kube-yunwei-197.tar.gz scope.yaml sock-shop [root@ren8 kubernetes]# tar zxf kube-yunwei-197.tar.gz [root@ren8 kubernetes]# ls bash harbor-offline-installer-v1.4.0.tgz image.tar.gz kube-yunwei-197 scope.yaml ca.tar.gz image k8s197.tar.gz kube-yunwei-197.tar.gz sock-shop [root@ren8 kubernetes]# cd kube-yunwei-197 [root@ren8 kube-yunwei-197]# ls 01.prepare.yml 03.docker.yml 05.kube-node.yml 99.clean.yml bin manifests tools 02.etcd.yml 04.kube-master.yml 06.network.yml ansible.cfg example roles [root@ren8 kube-yunwei-197]# mv ./* /etc/ansible/ [root@ren8 kube-yunwei-197]# cd /etc/ansible/ [root@ren8 ansible]# ls 01.prepare.yml 03.docker.yml 05.kube-node.yml 99.clean.yml bin hosts roles 02.etcd.yml 04.kube-master.yml 06.network.yml ansible.cfg example manifests tools
[root@ren8 ansible]# cd example/ [root@ren8 example]# ls hosts.s-master.example [root@ren8 example]# cp hosts.s-master.example ../hosts
[root@ren8 ansible]# vim hosts # 部署节点:运行ansible 脚本的节点 [deploy] 192.168.11.8 # etcd集群请提供如下NODE_NAME、NODE_IP变量,请注意etcd集群必须是1,3,5,7...奇数个节点 [etcd] 192.168.11.7 NODE_NAME=etcd1 NODE_IP="192.168.11.7" 192.168.11.6 NODE_NAME=etcd2 NODE_IP="192.168.11.6" 192.168.11.5 NODE_NAME=etcd3 NODE_IP="192.168.11.5" [kube-master] 192.168.11.7 NODE_IP="192.168.11.7" [kube-node] 192.168.11.7 NODE_IP="192.168.11.7" 192.168.11.6 NODE_IP="192.168.11.6" 192.168.11.5 NODE_IP="192.168.11.5" [all:vars] # ---------集群主要参数--------------- #集群部署模式:allinone, single-master, multi-master DEPLOY_MODE=single-master #集群 MASTER IP MASTER_IP="192.168.11.7" #集群 APISERVER KUBE_APISERVER="https://192.168.11.7:6443" #TLS Bootstrapping 使用的 Token,使用 head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 生成 BOOTSTRAP_TOKEN="d18f94b5fa585c7123f56803d925d2e7" # 集群网络插件,目前支持calico和flannel CLUSTER_NETWORK="calico" # 部分calico相关配置,更全配置可以去roles/calico/templates/calico.yaml.j2自定义 # 设置 CALICO_IPV4POOL_IPIP=“off”,可以提高网络性能,条件限制详见 05.安装calico网络组件.md CALICO_IPV4POOL_IPIP="always" # 设置 calico-node使用的host IP,bgp邻居通过该地址建立,可手动指定端口"interface=eth0"或使用如下自动发现 IP_AUTODETECTION_METHOD="can-reach=223.5.5.5" # 部分flannel配置,详见roles/flannel/templates/kube-flannel.yaml.j2 FLANNEL_BACKEND="vxlan" # 服务网段 (Service CIDR),部署前路由不可达,部署后集群内使用 IP:Port 可达 SERVICE_CIDR="10.68.0.0/16" # POD 网段 (Cluster CIDR),部署前路由不可达,**部署后**路由可达 CLUSTER_CIDR="172.20.0.0/16" # 服务端口范围 (NodePort Range) NODE_PORT_RANGE="20000-40000" # kubernetes 服务 IP (预分配,一般是 SERVICE_CIDR 中第一个IP) CLUSTER_KUBERNETES_SVC_IP="10.68.0.1" # 集群 DNS 服务 IP (从 SERVICE_CIDR 中预分配) CLUSTER_DNS_SVC_IP="10.68.0.2" # 集群 DNS 域名 CLUSTER_DNS_DOMAIN="cluster.local." # etcd 集群间通信的IP和端口, **根据实际 etcd 集群成员设置** ETCD_NODES="etcd1=https://192.168.11.7:2380,etcd2=https://192.168.11.6:2380,etcd3=https://192.168.11.5:2380" # etcd 集群服务地址列表, **根据实际 etcd 集群成员设置** ETCD_ENDPOINTS="https://192.168.11.7:2379,https://192.168.11.6:2379,https://192.168.11.5:2379" # 集群basic auth 使用的用户名和密码 BASIC_AUTH_USER="admin" BASIC_AUTH_PASS="admin" # ---------附加参数-------------------- #默认二进制文件目录 bin_dir="/usr/local/bin" #证书目录 ca_dir="/etc/kubernetes/ssl" #部署目录,即 ansible 工作目录 base_dir="/etc/ansible"
二、部署kubernetes过程
解压二进制文件包,将解压后的二进制文件替换/etc/ansible/bin下的所有文件:
[root@ren8 ~]# tar xf bin.tar.gz [root@ren8 ~]# ls anaconda-ks.cfg bin.tar.gz docker k8saddons.tar.gz kubernetes.tar.gz token.sh bin cert.tar.gz k8saddons kubernetes original-ks.cfg yum-repo.sh [root@ren8 ~]# mv bin/* /etc/ansible/bin/ [root@ren8 bin]# ls bridge cfssljson docker-containerd-ctr docker-proxy flannel kubectl loopback calicoctl docker docker-containerd-shim docker-runc host-local kubelet portmap cfssl docker-compose dockerd etcd kube-apiserver kube-proxy VERSION.md cfssl-certinfo docker-containerd docker-init etcdctl kube-controller-manager kube-scheduler
进入/etc/ansible目录,准备安装k8s集群:
[root@ren8 ansible]# ls 01.prepare.yml 03.docker.yml 05.kube-node.yml 99.clean.yml bin hosts roles 02.etcd.yml 04.kube-master.yml 06.network.yml ansible.cfg example manifests tools
1、创建CA证书和环境配置
ansible-playbook 01.prepare.yml
主要完成CA证书创建、分发、环境变量。
kubernetes 系统各组件需要使用 TLS 证书对通信进行加密,使用 CloudFlare 的 PKI 工具集生成自签名的CA证书,用来签名后续创建的其它 TLS 证书。
2、安装etcd集群
ansible-playbook 02.etcd.yml
kuberntes 系统使用 etcd 存储所有数据,是最重要的组件之一,注意 etcd集群只能有奇数个节点(1,3,5...),本文档使用3个节点做集群。
3、kubectl命令行工具
kubectl使用~/.kube/config 配置文件与kube-apiserver进行交互,且拥有完全权限,因此尽量避免安装在不必要的节点上。cat ~/.kube/config可以看到配置文件包含 kube-apiserver 地址、证书、用户名等信息。
[root@ren8 ansible]# cd ~/.kube/ [root@ren8 .kube]# ls cache config http-cache [root@ren8 .kube]# cat config apiVersion: v1 clusters: - cluster: certificate-authority-data: ###### server: https://192.168.11.7:6443 name: kubernetes contexts: - context: cluster: kubernetes user: admin name: kubernetes current-context: kubernetes kind: Config preferences: {} users: - name: admin user: client-certificate-data: ######
4、安装docker服务
ansible-playbook 03.docker.yml
5、安装kube-master节点
ansible-playbook 04.kube-master.yml
部署master节点包含三个组件`apiserver` `scheduler` `controller-manager`,其中:
apiserver:提供集群管理的REST API接口,包括认证授权、数据校验以及集群状态变更等
(1)只有API Server才直接操作etcd
(2)其他模块通过API Server查询或修改数据
(3)提供其他模块之间的数据交互和通信的枢纽
scheduler:负责分配调度Pod到集群内的node节点
(1)监听kube-apiserver,查询还未分配Node的Pod
(2)根据调度策略为这些Pod分配节点
controller-manager:由一系列的控制器组成,它通过apiserver监控整个集群的状态,并确保集群处于预期的工状态
6、安装kube-node节点
ansible-playbook 05.kube-node.yml
node 是集群中承载应用的节点,前置条件需要先部署好master节点(因为需要操作用户角色绑定、批准kubelet TLS 证书请求等),它需要部署如下组件:
(1)docker:运行容器
(2)calico: 配置容器网络
(3)kubelet: node上最主要的组件
(4)kube-proxy: 发布应用服务与负载均衡
7、安装网络
(1)每个节点准备如下镜像tar包:
[root@ren8 ~]# tar xf k8saddons.tar.gz [root@ren8 ~]# ls anaconda-ks.cfg bin.tar.gz docker k8saddons.tar.gz kubernetes.tar.gz token.sh bin cert.tar.gz k8saddons kubernetes original-ks.cfg yum-repo.sh [root@ren8 ~]# cd k8saddons [root@ren8 k8saddons]# ls bash-completion bash-completion-2.1-6.el7.noarch.rpm kubeimage [root@ren8 k8saddons]# cd kubeimage/ [root@ren8 kubeimage]# ls calico-cni-v2.0.5.tar calico-node-v3.0.6.tar heapster-v1.5.1.tar kubernetes-dashboard-amd64-v1.8.3.tar.gz calico-kube-controllers-v2.0.4.tar coredns-1.0.6.tar.gz influxdb-v1.3.3.tar pause-amd64-3.1.tar
[root@ren8 k8saddons]# scp -r kubeimage/* ren7:/root/ [root@ren8 k8saddons]# scp -r kubeimage/* ren6:/root/ [root@ren8 k8saddons]# scp -r kubeimage/* ren5:/root/
[root@ren7 ~]# cd k8saddons/ [root@ren7 k8saddons]# ls bash-completion bash-completion-2.1-6.el7.noarch.rpm kubeimage [root@ren7 k8saddons]# cd kubeimage/ [root@ren7 kubeimage]# ls calico-cni-v2.0.5.tar calico-node-v3.0.6.tar heapster-v1.5.1.tar kubernetes-dashboard-amd64-v1.8.3.tar.gz calico-kube-controllers-v2.0.4.tar coredns-1.0.6.tar.gz influxdb-v1.3.3.tar pause-amd64-3.1.tar [root@ren7 kubeimage]# for ls in `ls`;do docker load -i $ls;done
每个机器镜像导入完成后,再执行下一步
(2)ansible安装网络
ansible-playbook 06.network.yml
(3)验证calico网络:
[root@ren8 ~]# kubectl get pod No resources found. [root@ren8 ~]# kubectl get ns NAME STATUS AGE default Active 20h kube-node-lease Active 20h kube-public Active 20h kube-system Active 20h [root@ren8 ~]# kubectl get pod -n kube-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-7dd985b95c-s8q64 1/1 Running 0 20h calico-node-fwrnb 2/2 Running 4 20h calico-node-tpbgh 2/2 Running 0 20h calico-node-z7wxb 2/2 Running 0 20h
8、部署coredns服务
(1)进入/etc/ansible/manifests目录:
[root@ren8 ~]# cd /etc/ansible/manifests/ [root@ren8 manifests]# ls coredns dashboard efk heapster ingress kubedns
(2)进入coredns工作目录,并创建pod:
[root@ren8 manifests]# cd coredns/ [root@ren8 coredns]# ls coredns.yaml [root@ren8 coredns]# kubectl create -f coredns.yaml
(3)验证coredns:
[root@ren8 coredns]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-7dd985b95c-s8q64 1/1 Running 0 20h 192.168.11.6 192.168.11.6 <none> <none> calico-node-fwrnb 2/2 Running 4 20h 192.168.11.7 192.168.11.7 <none> <none> calico-node-tpbgh 2/2 Running 0 20h 192.168.11.6 192.168.11.6 <none> <none> calico-node-z7wxb 2/2 Running 0 20h 192.168.11.5 192.168.11.5 <none> <none> coredns-64d5b756bc-bcmqd 1/1 Running 0 20h 172.20.33.65 192.168.11.6 <none> <none> coredns-64d5b756bc-bmj2v 1/1 Running 0 20h 172.20.72.129 192.168.11.5 <none> <none>
要保证在集群中任意节点都能ping通pod服务IP
[root@ren7 ~]# ping 172.20.33.65 PING 172.20.33.65 (172.20.33.65) 56(84) bytes of data. 64 bytes from 172.20.33.65: icmp_seq=1 ttl=63 time=33.0 ms 64 bytes from 172.20.33.65: icmp_seq=2 ttl=63 time=0.552 ms ^C --- 172.20.33.65 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1000ms rtt min/avg/max/mdev = 0.552/16.777/33.002/16.225 ms [root@ren7 ~]# ping 172.20.72.129 PING 172.20.72.129 (172.20.72.129) 56(84) bytes of data. 64 bytes from 172.20.72.129: icmp_seq=1 ttl=63 time=34.6 ms 64 bytes from 172.20.72.129: icmp_seq=2 ttl=63 time=0.643 ms ^C --- 172.20.72.129 ping statistics --- 2 packets transmitted, 2 received, 0% packet loss, time 1001ms rtt min/avg/max/mdev = 0.643/17.666/34.690/17.024 ms
9、部署dashboard
(1)进入dashboard工作目录,并创建pod:
[root@ren8 coredns]# cd ../dashboard/ [root@ren8 dashboard]# ls 1.6.3 admin-user-sa-rbac.yaml kubernetes-dashboard.yaml ui-admin-rbac.yaml ui-read-rbac.yaml [root@ren8 dashboard]# kubectl create -f .
(2)验证dashboard:
[root@ren8 dashboard]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-7dd985b95c-s8q64 1/1 Running 0 20h 192.168.11.6 192.168.11.6 <none> <none> calico-node-fwrnb 2/2 Running 4 20h 192.168.11.7 192.168.11.7 <none> <none> calico-node-tpbgh 2/2 Running 0 20h 192.168.11.6 192.168.11.6 <none> <none> calico-node-z7wxb 2/2 Running 0 20h 192.168.11.5 192.168.11.5 <none> <none> coredns-64d5b756bc-bcmqd 1/1 Running 0 20h 172.20.33.65 192.168.11.6 <none> <none> coredns-64d5b756bc-bmj2v 1/1 Running 0 20h 172.20.72.129 192.168.11.5 <none> <none> kubernetes-dashboard-6f75588d94-g6vcr 1/1 Running 0 20h 172.20.72.130 192.168.11.5 <none> <none>
(3)查看dashboard服务端点,并登陆:
[root@ren8 dashboard]# kubectl cluster-info Kubernetes master is running at https://192.168.11.7:6443 CoreDNS is running at https://192.168.11.7:6443/api/v1/namespaces/kube-system/services/coredns:dns/proxy kubernetes-dashboard is running at https://192.168.11.7:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
将dashboard服务端点复制到浏览器并打开(用户名/密码:admin/admin)火狐浏览器
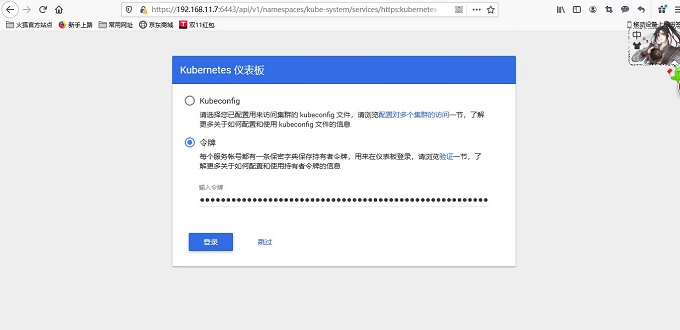
需要输入 Token 方可登陆,获取 Token:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret|grep admin-user|awk '{print $1}')
登陆成功:
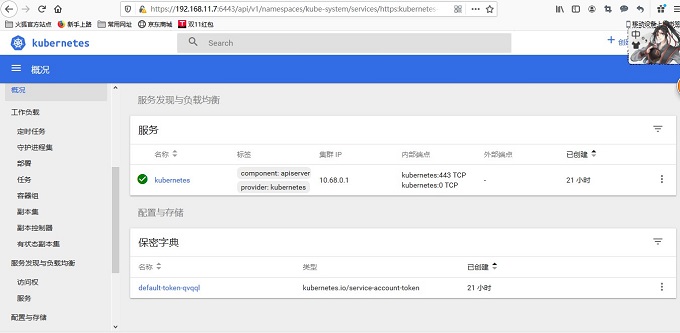
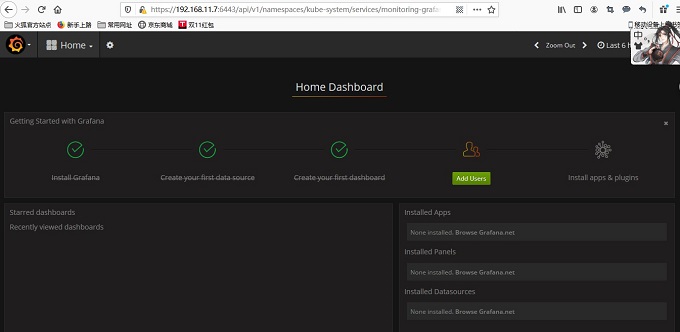
10、部署heapster监控
(1)进入heapster工作目录,并创建pod:
[root@ren8 manifests]# ls coredns dashboard efk heapster ingress kubedns [root@ren8 manifests]# cd heapster/ [root@ren8 heapster]# ls grafana.yaml heapster.yaml influxdb-v1.1.1 influxdb-with-pv influxdb.yaml [root@ren8 heapster]# kubectl create -f .
(2)验证监控:
[root@ren8 heapster]# kubectl get pod -n kube-system -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES calico-kube-controllers-7dd985b95c-s8q64 1/1 Running 0 23h 192.168.11.6 192.168.11.6 <none> <none> calico-node-fwrnb 2/2 Running 4 23h 192.168.11.7 192.168.11.7 <none> <none> calico-node-tpbgh 2/2 Running 0 23h 192.168.11.6 192.168.11.6 <none> <none> calico-node-z7wxb 2/2 Running 0 23h 192.168.11.5 192.168.11.5 <none> <none> coredns-64d5b756bc-bcmqd 1/1 Running 0 23h 172.20.33.65 192.168.11.6 <none> <none> coredns-64d5b756bc-bmj2v 1/1 Running 0 23h 172.20.72.129 192.168.11.5 <none> <none> heapster-7f48ff4cd9-6zmqr 1/1 Running 0 104m 172.20.33.68 192.168.11.6 <none> <none> kubernetes-dashboard-6f75588d94-g6vcr 1/1 Running 0 22h 172.20.72.130 192.168.11.5 <none> <none> monitoring-grafana-6c76875cb-8zjrv 1/1 Running 0 104m 172.20.33.67 192.168.11.6 <none> <none> monitoring-influxdb-66dbc76bf9-9lsqk 1/1 Running 0 104m 172.20.72.134 192.168.11.5 <none> <none>
[root@ren8 heapster]# kubectl cluster-info Kubernetes master is running at https://192.168.11.7:6443 CoreDNS is running at https://192.168.11.7:6443/api/v1/namespaces/kube-system/services/coredns:dns/proxy kubernetes-dashboard is running at https://192.168.11.7:6443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy monitoring-grafana is running at https://192.168.11.7:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号