Linux进阶之RAID磁盘阵列、系统启动及dd命令
本节内容
1. 磁盘阵列
RAID0: 条带卷 2+ 100% 读写速度快,不容错
RAID1: 镜像卷 2 50% 读写速度慢,容错
RAID5: 奇偶校验条带卷 3 读写速度快,容错,只允许错一块
RAID10: RAID0+RAID1 4 50% 读写速度快,容错
2. 创建阵列方式
硬件:磁盘阵列盒
软件: mdadm
3. mdadm命令
-C: 创建
-v: 显示创建过程
-a: 添加磁盘、自动检测设备
-l: 阵列级别
-n: 磁盘数量
-x: 备份盘数量
-f: 模拟损坏
-D:查看阵列详细信息
-S:停止阵列
-r: 移除磁盘
4. 创建RAID10
mdadm -Cv /dev/md10 -n 4 -l 10 /dev/sd{b,c,d,e}
5. 模拟损坏
mdadm /dev/md10 -f /dev/sdd
6. 磁盘损坏后的操作
poweroff
移除坏磁盘
新硬盘添加
虚拟机操作: mdadm /dev/md10 -a /dev/sdd
7. 搭建RAID5+热备盘
mdadm -Cv /dev/md5 -n 3 -l 5 -x 1 /dev/sd{b,c,d,e}
8. 自动挂载
echo "/dev/md5 /ken xfs defaults 0 0" >> /etc/fstab
9. 系统启动
1. BISO初始化,post开机自检
2. 加载MBR到内存
3. grub阶段
4. 加载内核和initramfs模块
5. 内核初始化,使用centos7系统使用的是systemd替换了centos6当中的init
10. dd if=/dev/zero of=/dev/swap bs=XM count=2048
磁盘阵列
一、概念
1、什么是RAID
RAID全称Redundant Array of Inexpensive Disks,廉价冗余磁盘阵列,通过多块磁盘组成一种模式,来提高吞吐量和可靠性。磁盘阵列是由很多价格较便宜的磁盘,以硬件(RAID卡)或软件(MDADM)形式组合成一个容量巨大的磁盘组,利用多个磁盘组合在一起,提升整个磁盘系统效能。
RAID可以把硬盘整合成一个大磁盘,还可以在大磁盘上再分区,放数据;还有一个大功能,多块盘放在一起可以有冗余(备份)。
RAID的创建有两种方式:软RAID(通过操作系统软件来实现)和硬RAID(使用硬件阵列卡)
RAID基本思想:把好几块硬盘通过一定组合方式把它组合起来,成为一个新的硬盘阵列组,从而使它能够达到高性能硬盘的要求。
2、磁盘阵列功能
A 整合闲置磁盘空间
B 提高磁盘读取效率
C 提供容错功能
3、磁盘阵列等级
- RAID-0:要求磁盘的容量相同,总容量为所有磁盘容量的和
- RAID-1:要求磁盘容量相同,总容量为一块硬盘容量
- RAID-1+0:请参考RAID-0/1
- RAID-5:要求容量相同,总容量为磁盘容量减一
- 备用磁盘:闲着没用,用于顶替坏盘
|
RAID类型 |
最低磁盘个数 |
空间利用率 |
各自的优缺点 |
|
|
级别 |
说明 |
|||
|
RAID0 |
条带卷 |
2+ |
100% |
读写速度快,不容错 |
|
RAID1 |
镜像卷 |
2 |
50%(1/n) |
读写速度一般,容错 |
|
RAID5 |
带奇偶校验的条带卷 |
3+ |
(n-1)/n |
读写速度快,容错,允许坏一块盘 |
|
RAID10 |
RAID1的安全+RAID0的高速 |
4 |
50% |
读写速度快,容错 |
4、RAID三个关键技术
镜像:提供了数据的安全性;
条带(块大小也可以说是条带的粒度),它的存在就是提供了数据并发性
数据的校验:提供了数据的安全
5、RAID等级详解
(1)RAID-0的工作原理
条带(strping),也是我们最早出现的RAID模式,需磁盘数量2块以上(大小最好相同),是组建磁盘阵列中最简单的一种形式,只需要2块以上的硬盘即可。
特点:成本低,可以提高整个磁盘的性能。RAID 0没有提供冗余或错误修复能力,速度快。
任何一个磁盘的损坏将损坏全部数据;磁盘利用率为100%。
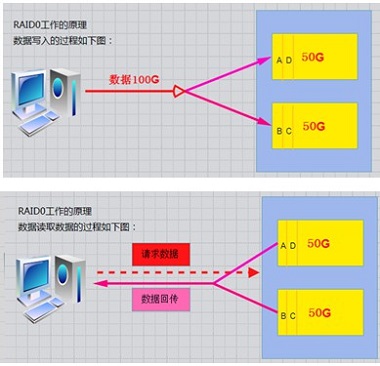
(2)RAID-1的工作原理
RAID 1 mirroring(镜像卷),至少需要两块硬盘。
原理:是把一个磁盘的数据镜像到另一个磁盘上,也就是说数据在写入一块磁盘的同时,会在另一块闲置的磁盘上生成镜像文件,(同步)
磁盘利用率为50%,即2块100G的磁盘构成RAID1只能提供100G的可用空间。
缺点:浪费资源,成本高
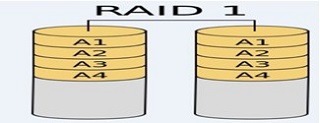
(3)RAID-5的工作原理
需要三块或以上硬盘,可以提供热备盘实现故障的恢复;只损坏一块,没有问题。但如果同时损坏两块磁盘,则数据将都会损坏。 空间利用率: (n-1)/n
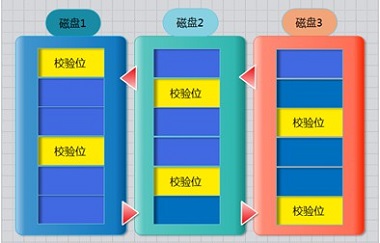
特点:读写性能一般,读还好一点,写不好
奇偶检验:raid5的数据恢复原理就是用公式算出来的
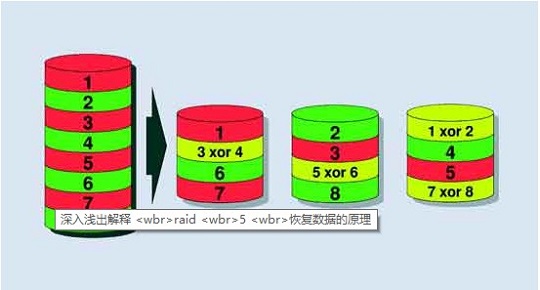
最左边的是原始数据,右边分别是三块硬盘,假设第二块硬盘出了故障,通过第一块硬盘上的 1 和第三块硬盘上的 1 xor 2,就能够还原出 2。同理可以还原出 3 和 8。至于 5 xor 6 则更简单了,直接用 5 和 6 运算出来即可。
RAID硬盘失效处理:热备和热插拔
a、热备:HotSpare
定义:当冗余的RAID组中某个硬盘失效时,在不干扰当前RAID系统的正常使用的情况下,用RAID系统中另外一个正常的备用硬盘自动顶替失效硬盘,及时保证RAID系统的冗余性
全局式:备用硬盘为系统中所有的冗余RAID组共享
专用式:备用硬盘为系统中某一组冗余RAID组专用
b、热插拔:HotSwap
定义:在不影响系统正常运转的情况下,用正常的物理硬盘替换RAID系统中失效硬盘。
(4)RAID-10镜像+条带(嵌套RAID级别)
RAID 10是将镜像和条带进行两级组合的RAID级别,第一级是RAID1镜像对,第二级为RAID 0。比如我们有8块盘,它是先两两做镜像,形成了新的4块盘,然后对这4块盘做RAID0;当RAID10有一个硬盘受损其余硬盘会继续工作,这个时候受影响的硬盘只有2块。
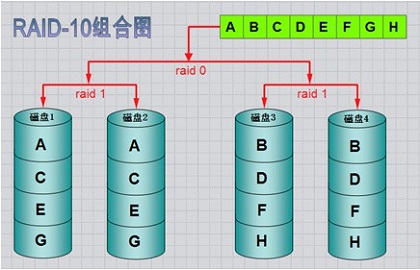
6、三种RAID的排序
冗余从好到坏:RAID1 RAID10 RAID5 RAID0
性能从好到坏:RAID0 RAID10 RAID5 RAID1
成本从低到高:RAID0 RAID5 RAID1 RAID10
二、硬件磁盘阵列介绍
不需要CPU处理的磁盘阵列就叫硬件磁盘阵列
面试题:我们做硬件RAID,是在装系统前还是之后?
答:先做阵列才装系统 ,一般服务器启动时,有显示进入配置Riad的提示。
硬RAID:需要RAID卡,我们的磁盘是接在RAID卡的,由它统一管理和控制。数据也由它来进行分配和维护;它有自己的cpu,处理速度快
软RAID:通过操作系统实现
三、软件磁盘阵列
1、mdadm命令详解
Linux内核中有一个md(multiple devices)模块在底层管理RAID设备,它会在应用层给我们提供一个应用程序的工具mdadm ,mdadm是linux下用于创建和管理软件RAID的命令。
Mdadm命令常见参数:
|
参数 |
全写 |
作用 |
|
-a |
--add --auto{=yes,md,mdp,part,p} |
添加磁盘 检测设备名称; |
|
-n |
--raid-devices=N |
指定设备数量 |
|
-x |
--spare-devices=N |
指定冗余设备数量 |
|
-l |
--level=[0 1 5] |
指定RAID级别 |
|
-C |
--create |
创建 |
|
-v |
--verbose |
显示过程 |
|
-f |
--fail |
模拟设备损坏 |
|
-r |
--remove |
移除设备 |
|
-Q |
--query |
查看摘要信息 |
|
-D |
--detail |
查看详细信息 |
|
-S |
--stop |
停止RAID磁盘阵列 |
2、实战搭建raid10阵列
第一步:新添加4块硬盘,查看磁盘
[root@renyz08 ~]# ls /dev/sd*
/dev/sda /dev/sda1 /dev/sda2 /dev/sdb /dev/sdc /dev/sdd /dev/sde
第二步:下载mdadm
[root@renyz08 ~]# yum install mdadm -y
第三步:创建raid10阵列
[root@renyz08 ~]# mdadm --create --verbose /dev/md10 --auto=yes --raid-devices=4 --level=10 /dev/sd{b,c,d,e}
mdadm: layout defaults to n2
mdadm: layout defaults to n2
mdadm: chunk size defaults to 512K
mdadm: size set to 20954112K
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md10 started.
第四步:格式化磁盘阵列为ext4
[root@renyz08 ~]# mkfs.ext4 /dev/md10
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=128 blocks, Stripe width=256 blocks
2621440 inodes, 10477056 blocks
523852 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2157969408
320 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
第五步:挂载
[root@renyz08 ~]# mkdir /raid10
[root@renyz08 ~]# mount /dev/md10 /raid10
[root@renyz08 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 1.2G 16G 7% /
devtmpfs 475M 0 475M 0% /dev
tmpfs 487M 0 487M 0% /dev/shm
tmpfs 487M 7.6M 479M 2% /run
tmpfs 487M 0 487M 0% /sys/fs/cgroup
/dev/sda1 1014M 133M 882M 14% /boot
tmpfs 98M 0 98M 0% /run/user/0
/dev/md10 40G 49M 38G 1% /raid10
第六步:查看/dev/md0的详细信息
[root@renyz08 ~]# mdadm --detail /dev/md10
/dev/md10:
Version : 1.2
Creation Time : Thu Jul 18 10:44:59 2019
Raid Level : raid10
Array Size : 41908224 (39.97 GiB 42.91 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Thu Jul 18 10:49:20 2019
State : clean
Active Devices : 4
Working Devices : 4
Failed Devices : 0
Spare Devices : 0
Layout : near=2
Chunk Size : 512K
Consistency Policy : resync
Name : renyz08:10 (local to host renyz08)
UUID : 8c2449e5:889b6950:3c8643c7:5a7cb07d
Events : 19
Number Major Minor RaidDevice State
0 8 16 0 active sync set-A /dev/sdb
1 8 32 1 active sync set-B /dev/sdc
2 8 48 2 active sync set-A /dev/sdd
3 8 64 3 active sync set-B /dev/sde
第七步:写入配置文件
[root@renyz08 ~]# echo "/dev/md10 /raid10 ext4 defaults 0 0" >> /etc/fstab
3、损坏磁盘阵列及修复
之所以在生产环境中部署RAID 10磁盘阵列,是为了提高硬盘存储设备的读写速度及数据的安全性,但由于我们的硬盘设备是在虚拟机中模拟出来的,因此对读写速度的改善可能并不直观。
在确认有一块物理硬盘设备出现损坏而不能继续正常使用后,应该使用mdadm命令将其移除,然后查看RAID磁盘阵列的状态,可以发现状态已经改变。
第一步:模拟设备损坏
[root@renyz08 ~]# cat /proc/mdstat #查看设备运行状态
Personalities : [raid10]
md10 : active raid10 sde[3] sdd[2] sdc[1] sdb[0]
41908224 blocks super 1.2 512K chunks 2 near-copies [4/4] [UUUU]
unused devices: <none>
[root@renyz08 ~]# mdadm /dev/md10 --fail /dev/sdb #损坏磁盘sdb
mdadm: set /dev/sdb faulty in /dev/md10
[root@renyz08 ~]# cat /proc/mdstat
Personalities : [raid10]
md10 : active raid10 sde[3] sdd[2] sdc[1] sdb[0](F)
41908224 blocks super 1.2 512K chunks 2 near-copies [4/3] [_UUU]
unused devices: <none>
第二步:添加新的磁盘
在RAID 10级别的磁盘阵列中,当RAID 1磁盘阵列中存在一个故障盘时并不影响RAID 10磁盘阵列的使用。当购买了新的硬盘设备后再使用mdadm命令来予以替换即可,在此期间我们可以在/RAID目录中正常地创建或删除文件。由于我们是在虚拟机中模拟硬盘,所以先重启系统,然后再把新的硬盘添加到RAID磁盘阵列中。
[root@renyz08 ~]# reboot
[root@renyz08 ~]# umount /raid10
[root@renyz08 ~]# mdadm /dev/md10 -a /dev/sdb
mdadm: added /dev/sdb
[root@renyz08 ~]# cat /proc/mdstat
Personalities : [raid10]
md10 : active raid10 sdb[4] sde[3] sdd[2] sdc[1]
41908224 blocks super 1.2 512K chunks 2 near-copies [4/3] [_UUU]
[==============>......] recovery = 71.4% (14966144/20954112) finish=0.1min speed=650701K/sec
unused devices: <none>
第三步:再次查看,已经构建完成
[root@renyz08 ~]# mdadm -D /dev/md10
4、实战搭建raid5阵列+备份盘
第一步:创建raid5磁盘阵列
[root@renyz08 ~]# ls /dev/sdb*
/dev/sdb /dev/sdb1 /dev/sdb2 /dev/sdb3 /dev/sdb4 /dev/sdb5
[root@renyz08 ~]# mdadm -C -a yes /dev/md5 -l 5 -n 3 -x 1 /dev/sdb{1,2,3,5}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md5 started.
第二步:格式化
[root@renyz08 ~]# mkfs.xfs /dev/md5
第三步:挂载
[root@renyz08 ~]# mkdir /raid5
[root@renyz08 ~]# mount /dev/md5 /raid5
[root@renyz08 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/md5 8.0G 33M 8.0G 1% /raid5
第四步:查看
[root@renyz08 ~]# cat /proc/mdstat #查询运行状态
Personalities : [raid6] [raid5] [raid4]
md5 : active raid5 sdb3[4] sdb5[3](S) sdb2[1] sdb1[0]
8376320 blocks super 1.2 level 5, 512k chunk, algorithm 2 [3/3] [UUU]
unused devices: <none>
[root@renyz08 ~]# mdadm -D /dev/md5 #查询磁盘阵列信息
第五步:模拟错误
[root@renyz08 ~]# cat /proc/mdstat
md5 : active raid5 sdb1[5](S) sdb5[3] sdb2[1] sdb3[4]
[root@renyz08 ~]# mdadm /dev/md5 -f /dev/sdb2
mdadm: set /dev/sdb2 faulty in /dev/md5
[root@renyz08 ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md5 : active raid5 sdb1[5] sdb5[3] sdb2[1](F) sdb3[4]
第六步:移除磁盘
[root@renyz08 ~]# mdadm --manage /dev/md5 -r /dev/sdb2
mdadm: hot removed /dev/sdb2 from /dev/md5
[root@renyz08 ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md5 : active raid5 sdb1[5] sdb5[3] sdb3[4]
第七步:增加磁盘
[root@renyz08 ~]# mdadm --manage /dev/md5 -a /dev/sdb2
mdadm: added /dev/sdb2
[root@renyz08 ~]# cat /proc/mdstat
Personalities : [raid6] [raid5] [raid4]
md5 : active raid5 sdb2[6](S) sdb1[5] sdb5[3] sdb3[4]
第八步:停用磁盘阵列
[root@renyz08 ~]# mdadm -S /dev/md5 #未取消挂载,停用操作无用
mdadm: Cannot get exclusive access to /dev/md5:Perhaps a running process, mounted filesystem or active volume group?
[root@renyz08 ~]# umount /dev/md5 /raid5 #先取消挂载
umount: /raid5:未挂载
[root@renyz08 ~]# mdadm -S /dev/md5 #停用磁盘阵列
mdadm: stopped /dev/md5
四、centos7系统启动过程及相关配置文件
1. uefi或BIOS初始化,开始post(power on self test)开机自检;这个过程是开机后,BIOS或UEFI进行硬件检查的阶段。
2. 加载MBR到内存
自检硬件没有问题时候,这里以BIOS为例,BIOS将会直接找硬盘的第一个扇区,找到前446字节,将MBR加载到内存中,MBR将告诉程序下一阶段去哪里找系统的grub引导。此阶段属于grub第一阶段。grub还有1.5阶段和2阶段。
3. GRUB阶段
grub第1.5和第2阶段,信息默认存放在扇区中,如果使用grub-install生成的第2阶段的文件是存放在/boot分区中的。
为了加载内核系统,不得不加载/boot分区,而加载/boot分区,要有/boot分区的驱动,/boot分区驱动是放在/boot分区中的啊,我们好像进入死循环了,Linux是怎么解决的呢?就是靠放在1.5阶段中的数据,放在第一个扇区后的后续扇区中,第1.5阶段和2阶段总共27个扇区。
第1.5阶段:mbr之后的扇区,识别stage2所在的分区上的文件系统。
第2阶段:开机启动的时候看到Grub选项、信息,还有修改GRUB背景等功能都是stage2提供的,stage2会去读入/boot/grub/grub.conf或者menu.lst等配置文件。
4. 加载内核和initramfs模块
加载内核,核心开始解压,启动一些最核心的程序。
为了让内核足够的轻小,硬件驱动并没放在内核文件里面。
5. 内核开始初始化,使用systemd来代替centos6以前的init程序
(1)执行initrd.target
包括挂载/etc/fstab文件中的系统,此时挂载后,就可以切换到根目录了
(2)从initramfs根文件系统切换到磁盘根目录
(3)systemd执行默认target配置
centos7表面是有“运行级别”这个概念,实际上是为了兼容以前的系统,每个所谓的“运行级别”都有对应的软连接指向,默认的启动级别时/etc/systemd/system/default.target,根据它的指向可以找到系统要进入哪个模式
模式:
0 ==> runlevel0.target, poweroff.target
1 ==> runlevel1.target, rescue.target
2 ==> runlevel2.target, multi-user.target
3 ==> runlevel3.target, multi-user.target
4 ==> runlevel4.target, multi-user.target
5 ==> runlevel5.target, graphical.target
6 ==> runlevel6.target, reboot.target
(4)systemd执行sysinit.target
有没有很眼熟?是的,在CentOS6上是被叫做rc.sysint程序,初始化系统及basic.target准备操作系统
(5)systemd启动multi-user.target下的本机与服务器服务
(6)systemd执行multi-user.target下的/etc/rc.d/rc.local
6. Systemd执行multi-user.target下的getty.target及登录服务
getty.target我们也眼熟,它是启动终端的systemd对象。如果到此步骤,系统没有被指定启动图形桌面,到此就可以结束了,如果要启动图形界面,需要在此基础上启动桌面程序
7. systemd执行graphical需要的服务
CentOS6,7启动区别
系统启动和服务器守护进程管理器,它不同于centos5的Sysv init,centos6的Upstart(Ubuntu制作出来),systemd是由Redhat的一个员工首先提出来的,它在内核启动后,服务什么的全都被systemd接管,kernel只是用来管理硬件资源,相当于内核被架空了,因此linus很不满意Redhat这种做法。
五、如何不用新分区添加swap(dd)
在之前的教程中我们提到过如何去添加一个swap分区,以及如何给你的swap进行扩容。在教程中我们使用的是新分区的方式,也就是新添加一块硬盘,或在原有硬盘空余空间的基础上新建一个分区,然后将其格式化为交换分区,最后进行挂载。
现在很多朋友使用的都是云主机,云主机一般不会设置swap(如某里云)购买之后一般使用的都是赠送的磁盘空间,且因为数据量小的原因并不会购买数据盘,导致没有可用分区转换为swap,有没有什么办法可以不用分区即可添加或扩容swap呢?今天就来教大家个方法!
首先使用dd命令生成一个固定大小的文件,文件的大小就是添加或扩容swap的大小:
- dd if=/dev/zero of=/opt/swap bs=1M count=2048
然后使用mkswap命令将其格式化:
- mkswap /opt/swap
使用swapon命令挂载:
- swapon /opt/swap
看下一下,交换分区是不是变大了?
[root@renyz08 ~]# free -h
total used free shared buff/cache available
Mem: 972M 85M 766M 7.6M 119M 741M
Swap: 2.0G 0B 2.0G
[root@renyz08 ~]# dd if=/dev/zero of=/opt/swap bs=1M count=2048
记录了2048+0 的读入
记录了2048+0 的写出
2147483648字节(2.1 GB)已复制,20.2102 秒,106 MB/秒
[root@renyz08 ~]# mkswap /opt/swap
正在设置交换空间版本 1,大小 = 2097148 KiB
无标签,UUID=88cbe933-fdc6-495c-9155-deea9b0b8948
[root@renyz08 ~]# swapon /opt/swap
swapon: /opt/swap:不安全的权限 0644,建议使用 0600。
[root@renyz08 ~]# chmod 600 /opt/swap
[root@renyz08 ~]# free -h
total used free shared buff/cache available
Mem: 972M 84M 60M 7.6M 826M 712M
Swap: 4.0G 0B 4.0G
原理:Linux中皆是文件,swap对于linux系统来说也是一个文件,/opt/swap对于linux系统来说也是一个文件,这样概念就对等了。实际上这些文件就像一个笔记本,它是一个实体也是一个载体,我们是可以在笔记本中记录内容,如同可以在/opt/swap中写入数据的。
/dev/null 黑洞文件(不保存)
/dev/zero 白洞文件源源不断的向外输出文件
转换和拷贝文件
if=file
从 file 中读而不是标准输入。
of=file
写到 file 里去而不是标准输出
bs=bytes
一次读和写 bytes 字节
count=blocks
只拷贝输入文件的前 blocks 块

 浙公网安备 33010602011771号
浙公网安备 33010602011771号