
三种梯度下降算法的区别(BGD, SGD, MBGD)
前言
我们在训练网络的时候经常会设置 batch_size,这个 batch_size 究竟是做什么用的,一万张图的数据集,应该设置为多大呢,设置为 1、10、100 或者是 10000 究竟有什么区别呢?
# 手写数字识别网络训练方法
network.fit(
train_images,
train_labels,
epochs=5,
batch_size=128)
批量梯度下降(Batch Gradient Descent,BGD)
梯度下降算法一般用来最小化损失函数:把原始的数据网络喂给网络,网络会进行一定的计算,会求得一个损失函数,代表着网络的计算结果与实际的差距,梯度下降算法用来调整参数,使得训练出的结果与实际更好的拟合,这是梯度下降的含义。
批量梯度下降是梯度下降最原始的形式,它的思想是使用所有的训练数据一起进行梯度的更新,梯度下降算法需要对损失函数求导数,可以想象,如果训练数据集比较大,所有的数据需要一起读入进来,一起在网络中去训练,一起求和,会是一个庞大的矩阵,这个计算量将非常巨大。当然,这也是有优点的,那就是因为考虑到所有训练集的情况,因此网络一定在向最优(极值)的方向在优化。
随机梯度下降(Stochastic Gradient Descent,SGD)
与批量梯度下降不同,随机梯度下降的思想是每次拿出训练集中的一个,进行拟合训练,进行迭代去训练。训练的过程就是先拿出一个训练数据,网络修改参数去拟合它并修改参数,然后拿出下一个训练数据,用刚刚修改好的网络再去拟合和修改参数,如此迭代,直到每个数据都输入过网络,再从头再来一遍,直到参数比较稳定,优点就是每次拟合都只用了一个训练数据,每一轮更新迭代速度特别快,缺点是每次进行拟合的时候,只考虑了一个训练数据,优化的方向不一定是网络在训练集整体最优的方向,经常会抖动或收敛到局部最优。
小批量梯度下降(Mini-Batch Gradient Descent,MBGD)
小批量梯度下降采用的还是计算机中最常用的折中的解决办法,每次输入网络进行训练的既不是训练数据集全体,也不是训练数据集中的某一个,而是其中的一部分,比如每次输入 20 个。可以想象,这既不会造成数据量过大计算缓慢,也不会因为某一个训练样本的某些噪声特点引起网络的剧烈抖动或向非最优的方向优化。
对比一下这三种梯度下降算法的计算方式:批量梯度下降是大矩阵的运算,可以考虑采用矩阵计算优化的方式进行并行计算,对内存等硬件性能要求较高;随机梯度下降每次迭代都依赖于前一次的计算结果,因此无法并行计算,对硬件要求较低;而小批量梯度下降,每一个次迭代中,都是一个较小的矩阵,对硬件的要求也不高,同时矩阵运算可以采用并行计算,多次迭代之间采用串行计算,整体来说会节省时间。
看下面一张图,可以较好的体现出三种剃度下降算法优化网络的迭代过程,会有一个更加直观的印象。
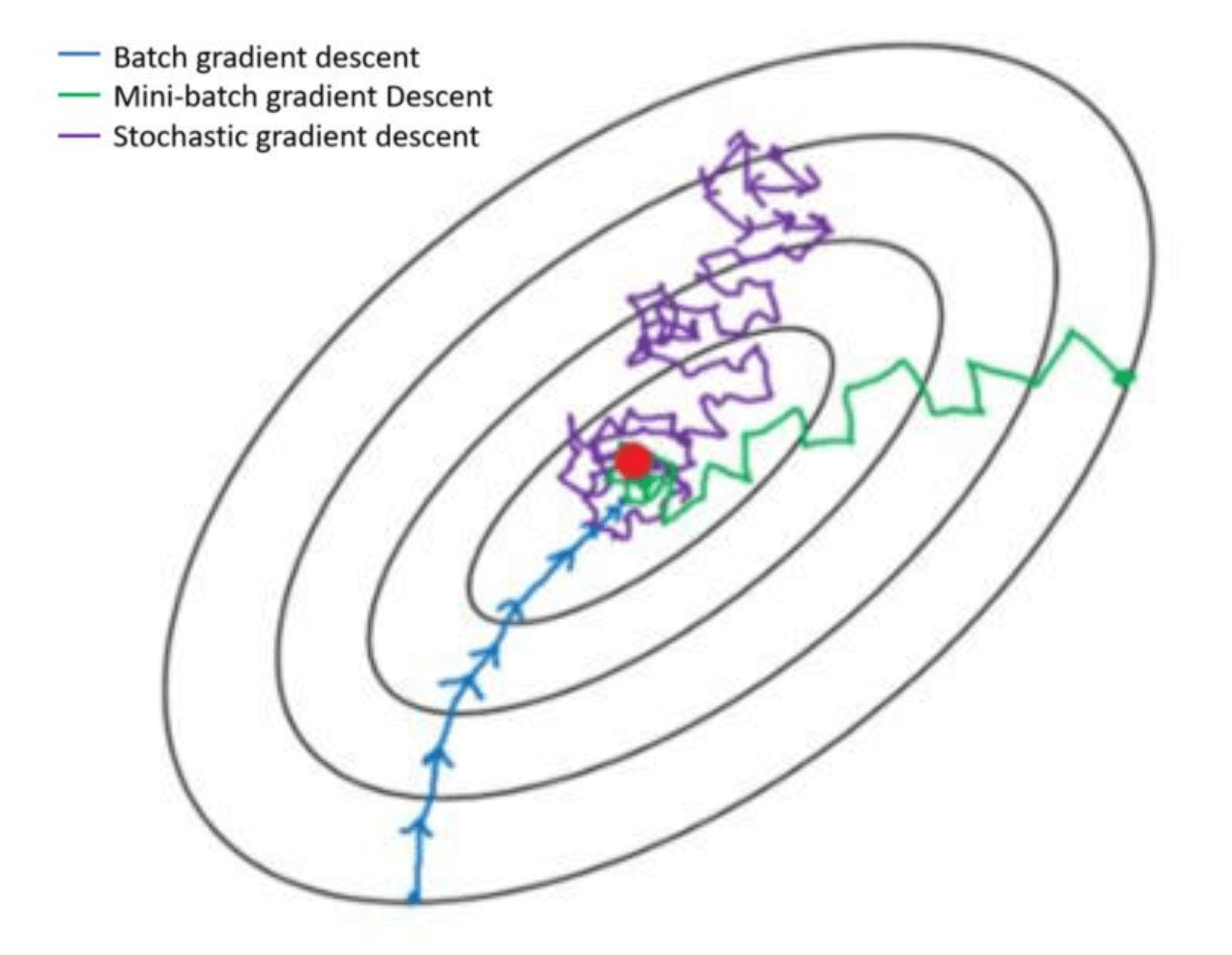
总结
梯度下降算法的调优,训练数据集很小,直接采用批量梯度下降;每次只能拿到一个训练数据,或者是在线实时传输过来的训练数据,采用随机梯度下降;其他情况或一般情况采用批量梯度下降算法更好。
- 本文首发自: RAIS

