


安装hadoop集群--hdfs
准备一台干净的虚拟机-centos7
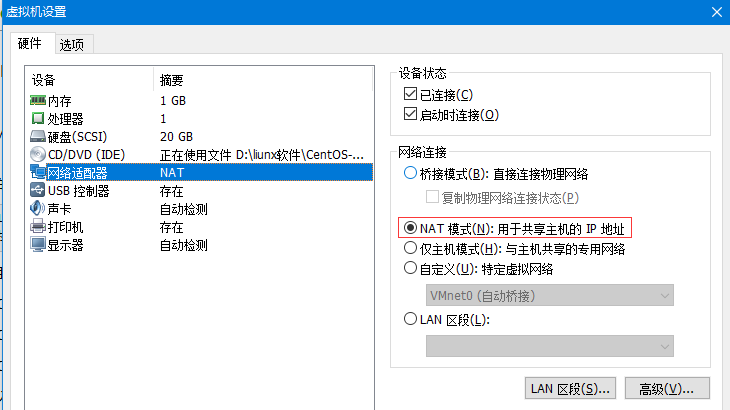
网络连接改成NAT模式 进行下一步安装
[root@hdp-01 ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
ONBOOT=no改为ONBOOT=yes
重启网络服务:
[root@hdp-01 ~]# sudo service network restart [root@hdp-01 ~]# mkdir apps [root@hdp-01 ~]# tar -zxvf jdk-8u152-linux-x64.tar.gz -C apps/
[root@hdp-01 ~]# mv jdk1.8.0_152 java [root@hdp-01 ~]# vi /etc/profile
[root@hdp-01 ~]# vi /etc/profile
在文件最后加入:
export JAVA_HOME=/root/apps/java
export PATH=$PATH:$JAVA_HOME/bin
修改完成后,记得 source /etc/profile使配置生效
hdp-01为模板克隆四台虚拟机 分别为hdp-02 hdp-03 hdp-04
Windows配置hosts文件
C:\Windows\System32\drivers\etc
192.168.137.138 hdp-01 192.168.137.139 hdp-02 192.168.137.140 hdp-03 192.168.137.141 hdp-04
配置SSH免密登录
在每台服务器或虚拟机上配置hosts,命令行输入:
vi /etc/hosts
在其中添加所有服务器或虚拟机节点ip和对应的域名
192.168.137.138 hdp-01 192.168.137.139 hdp-02 192.168.137.140 hdp-03 192.168.137.141 hdp-04
在hdp-01中输入ssh-keygen 一直回车
复制公钥到其他节点
ssh-copy-id -i .ssh/id_rsa.pub root@hdp-01 ssh-copy-id -i .ssh/id_rsa.pub root@hdp-02 ssh-copy-id -i .ssh/id_rsa.pub root@hdp-03 ssh-copy-id -i .ssh/id_rsa.pub root@hdp-04
复制完成即可实现免密登录,测试一下:
ssh 0.0.0.0
上传hadoop-2.8.4.tar.gz到hdp-01
[root@hdp-01 ~]# tar -zxvf hadoop-2.8.4.tar.gz -C apps/
[root@hdp-01 apps]# mv hadoop-2.8.4/ hadoop
修改配置文件
指定hadoop的默认文件系统为:hdfs
指定hdfs的namenode节点为哪台机器
指定namenode软件存储元数据的本地目录
指定datanode软件存放文件块的本地目录
hadoop的配置文件在:/root/apps/hadoop/etc/hadoop/
[root@hdp-01 ~]# cd apps/hadoop/etc/hadoop
[root@hdp-01 hadoop]# vi hadoop-env.sh
修改hadoop-env.sh
export JAVA_HOME=/root/apps/java
修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hdp-01:9000</value>
</property>
</configuration>
修改hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/dfs/data</value>
</property>
</configuration>
[root@hdp-01 ~]# cd apps/hadoop/share/
[root@hdp-01 share]# rm -rf doc/
拷贝整个hadoop安装目录到其他机器
scp -r /root/apps/hadoop hdp-02:/root/apps/ scp -r /root/apps/hadoop hdp-03:/root/apps/ scp -r /root/apps/hadoop hdp-04:/root/apps/
启动HDFS
提示:要运行hadoop的命令,需要在linux环境中配置HADOOP_HOME和PATH环境变量
vi /etc/profile
export JAVA_HOME=/root/apps/java export HADOOP_HOME=/root/apps/hadoop export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
[root@hdp-01 ~]# scp -r /etc/profile hdp-02:/etc/profile [root@hdp-01 ~]# scp -r /etc/profile hdp-03:/etc/profile [root@hdp-01 ~]# scp -r /etc/profile hdp-04:/etc/profile
初始化namenode的元数据目录
hdp-01上执行hadoop的一个命令来初始化namenode的元数据存储目录
[root@hdp-01 ~]# hadoop namenode -format
创建一个全新的元数据存储目录
生成记录元数据的文件fsimage
生成集群的相关标识:如:集群id——clusterID
启动namenode进程(在hdp-01上)
关闭防火墙
[root@hdp-01 ~]# hadoop-daemon.sh start namenode
启动完后,ps查看一下namenode的进程是否存在
windows中用浏览器访问namenode提供的web端口:50070
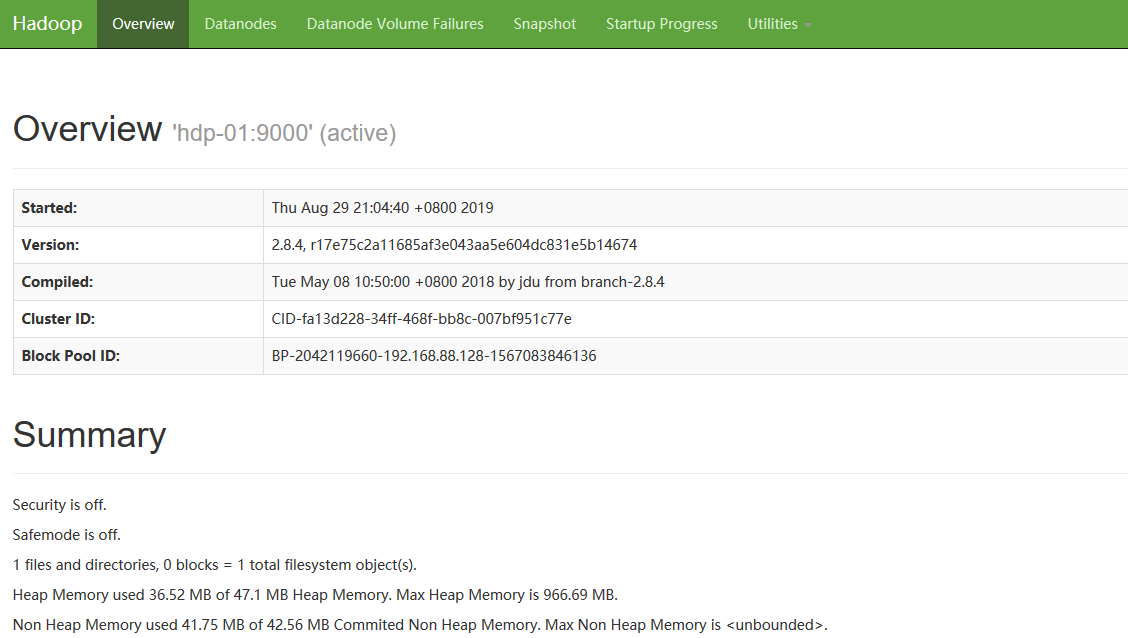
启动众datanode们(在任意地方)
hadoop-daemon.sh start datanode
用自动批量启动脚本来启动HDFS
修改hadoop安装目录中/etc/hadoop/slaves(把需要启动datanode进程的节点列入)
[root@hdp-01 ~]# vi apps/hadoop/etc/hadoop/slaves
//加入
hdp-01 hdp-02 hdp-03 hdp-04
在hdp-01上用脚本:start-dfs.sh 来自动启动整个集群
停止则用脚本:stop-dfs.sh

