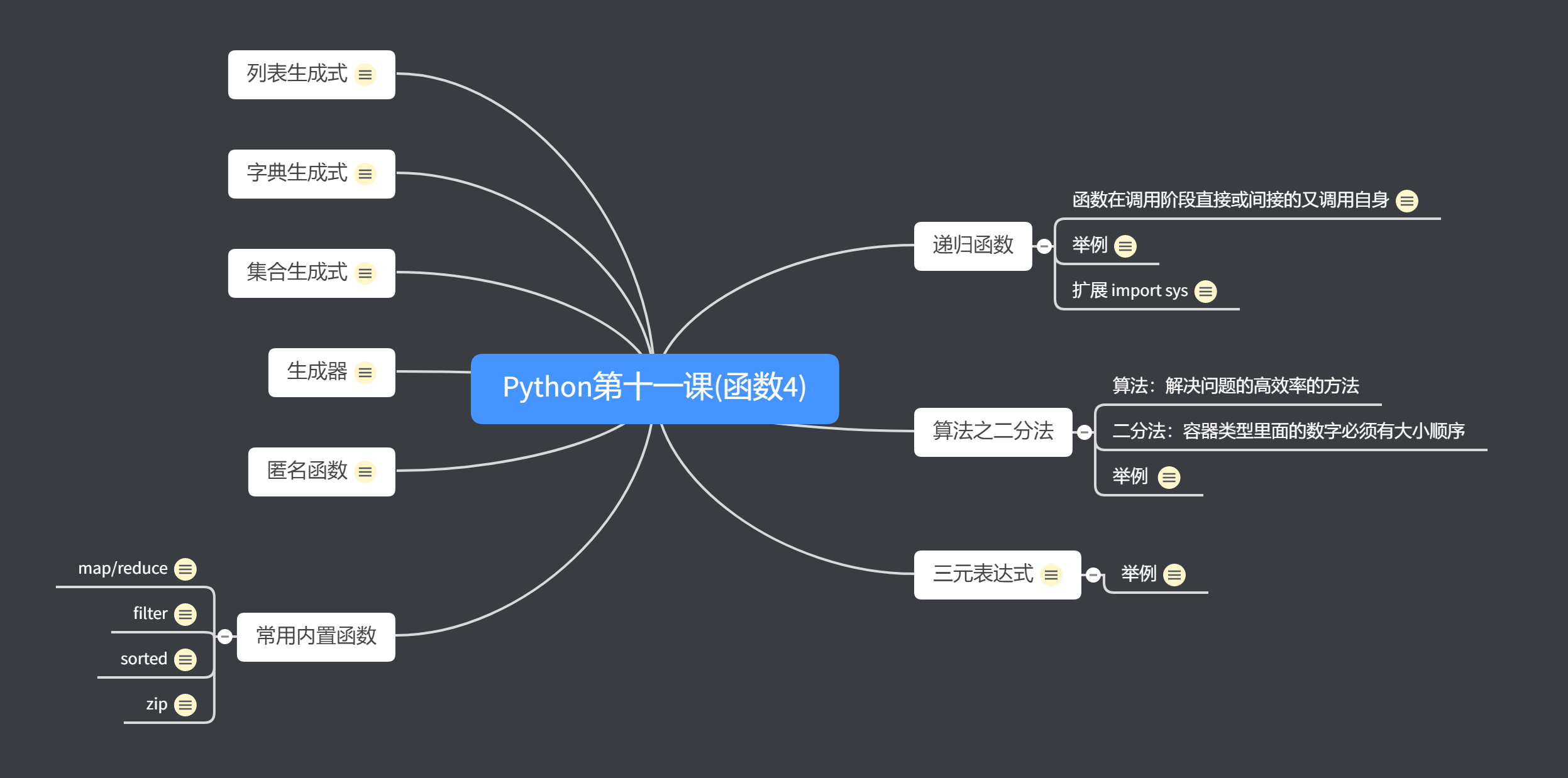
Python第十一课(函数4)
Python第十一课(函数4) >>>转到思维导图>>>转到中二青年
递归函数
函数在调用阶段直接或间接的又调用自身
如果一个函数在内部调用自身本身,这个函数就是递归函数。

# 举个例子,我们来计算阶乘n! = 1 x 2 x 3 x ... x n,用函数fact(n)表示,可以看出: # fact(n) = n! = 1 x 2 x 3 x ... x (n-1) x n = (n-1)! x n = fact(n-1) x n # 所以,fact(n)可以表示为n x fact(n-1),只有n=1时需要特殊处理。 # 于是,fact(n)用递归的方式写出来就是: def fact(n): if n==1: return 1 return n * fact(n - 1) # 如果我们计算fact(5),可以根据函数定义看到计算过程如下: ===> fact(5) ===> 5 * fact(4) ===> 5 * (4 * fact(3)) ===> 5 * (4 * (3 * fact(2))) ===> 5 * (4 * (3 * (2 * fact(1)))) ===> 5 * (4 * (3 * (2 * 1))) ===> 5 * (4 * (3 * 2)) ===> 5 * (4 * 6) ===> 5 * 24 ===> 120
扩展 import sys
# import sys # print(sys.getrecursionlimit()) # 不是很精确 # sys.setrecursionlimit(2000) # 也可以手动设定最大地柜次数
算法之二分法
算法:解决问题的高效率的方法
二分法:容器类型里面的数字必须有大小顺序
# 快速查找一个值是否存在一个有序列表里 l = [1,2,3,4,5,6,7,8,9,10] num = 9 def get_num(l,num): if not l: # 如果列表为空还没找到就返回给用户不存在 print('不存在') return middle_num = len(l)//2 if num > l[middle_num]: num_right = l[middle_num+1:] get _num(num_right,num) elif num < l[middle_num]: num_left = l[0:middle_num] get_num(num_left,num) else: print('find it',num) get_num(l,num)
三元表达式
三元表达式固定表达式
值1 if 条件 else 值2
条件成立 值1
条件不成立 值2
三元表达式的应用场景只推荐只有两种的情况的可能下
def my_max(x,y): if x > y: return x else: return y """ 当x大的时候返回x当y大的时候返回y 当某个条件成立做一件事,不成立做另外一件事 """ x = 99999 y = 9898898 res = x if x > y else y # 如果if后面的条件成立返回if前面的值 否则返回else后面的值 print(res)
列表生成式
# 要生成list[1,2,3,4,5]可以用list(range(1,6)) # 要生成[1X1,2X2,3X3,4X4,5X5]一般方法是循环: l = [] for x in rang(1,6): l.append(x*x) # 但是for循环太繁琐,列表生成式则可以一行语句生成: [x*x for x in range(1,6)] # for循环后可以加上if判断 [x*x for x in range(1,6) if x%2 == 0] # 后面不支持再加else的情况 # 先for循环依次取出列表里面的每一个元素 # 然后交由if判断 条件成立才会交给for前面的代码 # 如果条件不成立 当前的元素 直接舍弃
字典生成式
# 通过列表生成式,我们把[]换成{},推演出字典生成式 l1 = ['name','password','hobby'] l2 = ['jason','123','DBJ','egon'] d = {} for i,j in enumerate(l1): d[j] = l2[i] print(d) l1 = ['jason','123','read'] d = {i:j for i,j in enumerate(l1) if j != '123'} print(d)
集合生成式
res = {i for i in range(10) if i != 4}
print(res)
生成器
#我们继续根据上面的列生成式表和字典生成式推演 #把[]换成(),这个时候并不是元组生成式,而是生成器 #返回的是个生成器 >>> g = (x * x for x in range(10)) >>> g <generator object <genexpr> at 0x1022ef630> #而我们要想取生成器的元素,需要用for循环 >>> g = (x * x for x in range(10)) >>> for n in g: ... print(n)
匿名函数
# 没有名字的函数,临时存在,用完就没了 (lambda x: x * x) # :左边的相当于函数的形参 # :右边的相当于函数的返回值 # 匿名函数通常不会单独使用,是配合内置函数一起使用 # 匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。 >>> f = lambda x: x * x >>> f <function <lambda> at 0x101c6ef28> >>> f(5) 25
常用内置函数
map/reduce
""" map()函数接收两个参数,一个是函数,一个是序列 map将传入的函数一次作用到序列的每个元素,并把结果作为新的序列返回。 例如我们把一个匿名函数lambda x: x * x作用[1,2,3,4,5]上 """ res = map(lambda x:x*x,[1,2,3,4,5]) """ reduce()把一个函数作用在一个序列上,这个函数必须接收两个参数, reduce把结果继续和序列的下一个元素做累计计算。 例如我们对一个序列求和 """ res = reduce(lambda x,y:x+y,[1,2,3,4,5])
filter
""" filter()函数用于过滤序列,和map()类似,filter()也接收一个函数和一个序列。 和map()不同的是,filter()把传入的函数依次作用于每个元素, 然后根据返回值是True还是False决定保留还是丢弃该元素。 例如在一个列表中删掉偶数只保留奇数 """ list(filter(lambda x:x%2==1,[1,2,3,4,5,6]))
sorted
#sorted()函数就可以对list进行排序: sorted([36, 5, -12, 9, -21]) #sorted()函数还可以reverse来实现自定义的排序, >>> sorted([2,4,3,1,5], reverse=True) [5,4,3,2,1]
zip
""" zip()函数用于将序列作为参数,将序列中对应的元素打包成一个个元组,然后返回由这些元组组成的列表 如果各个序列的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。 例如 """ >>>a = [1,2,3] >>>b = [4,5,6] >>>c = [4,5,6,7,8] >>>zipped = zip(a,b) # 打包为元组的列表 [(1, 4), (2, 5), (3, 6)] >>> zip(a,c) # 元素个数与最短的列表一致 [(1, 4), (2, 5), (3, 6)] >>> zip(*zipped) # 与 zip 相反,*zipped 可理解为解压,返回二维矩阵式 [(1, 2, 3), (4, 5, 6)]
END

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步