Python格式化处理json数据的方式
1.问题
在遇到json数据的过程中,我们经常需要获取json数据中某个值的操作,如果是用get方法去取比较繁琐,接下来介绍两种方式来取值。
2.jsonpath来格式化处理json数据
2.1介绍
JsonPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括JavaScript、Python、PHP和Java。JsonPath对于JSON来说,就相当于XPATH对于XML。
JsonPath结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。
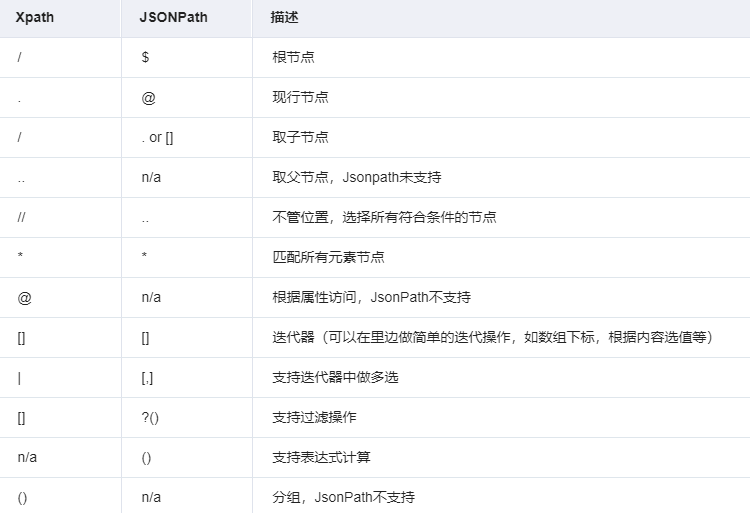
2.2安装
pip安装:
pip install jsonpath
官网文档:http://goessner.net/articles/JsonPath
2.3使用
使用方法: # 导入 import jsonpath # 结果会以列表形式返回,如下请求接口返回数据提取例子 jsonpath.jsonpath(参数1,参数2)[] # 参数 参数1:数据对象 参数2:jsonpath表达式
[]:如果有重复的键,需要获取第几个键的值
2.4使用示例:
import jsonpath json_data = { "resultcode":"200", "reason":"成功的返回", "result": { "company":"顺丰", "com":"sf", "no":"575677355677", "list":[ { "datetime":"2013-06-25 10:44:05", "remark":"已收件", "zone":"台州市" }, { "datetime":"2013-06-25 11:05:21", "remark":"快件在 台州 ,准备送往下一站 台州集散中心 ", "zone":"台州市" } ], "status":1 }, "error_code":0 } resultcode = jsonpath.jsonpath(json_data,"$..resultcode")[0] print("返回的code:",resultcode) company = jsonpath.jsonpath(json_data, "$..company")[0] print("快递公司:",company) remark = jsonpath.jsonpath(json_data,"$..remark")[-1] print("快递目前到达的地点:",remark) 结果: 返回的code: 200 快递公司: 顺丰 快递目前到达的地点: 快件在 台州 ,准备送往下一站 台州集散中心
3.jmespath来格式化处理json数据
jmespath是另一种用来处理json数据的库。
3.1安装
pip安装:
pip install jmespath
官网文档:https://jmespath.org/tutorial.html
3.2基本操作
import jmespath source = {"a": "foo", "b": "bar", "c": "baz"} result = jmespath.search('b', source) print(repr(result)) 结果: 'bar'
3.3 .操作符
import jmespath source1 = {"a": {"b": {"c": {"d": "value"}}}} result1 = jmespath.search('a.b.c', source1) print(repr(result1)) 结果: {'d': 'value'}
3.4下标操作(仅用于数组)
import jmespath source_2 = ["a", "b", "c", "d", "e", "f"] index_result = jmespath.search("[1]",source_2) print(repr(index_result)) 结果: 'b'
3.5下标和.操作符混合操作
import jmespath source3 = {"a": { "b": { "c": [ {"d": [0, [1, 2]]}, {"d": [3, 4]} ] } }} result3 = jmespath.search('a.b.c[0].d[1][0]',source3) print(repr(result3)) 结果: 1
3.6接下来用实际的json数据测试一下
import jmespath json_data = { "resultcode":"200", "reason":"成功的返回", "result": { "company":"顺丰", "com":"sf", "no":"575677355677", "list":[ { "datetime":"2013-06-25 10:44:05", "remark":"已收件", "zone":"台州市" }, { "datetime":"2013-06-25 11:05:21", "remark":"快件在 台州 ,准备送往下一站 台州集散中心 ", "zone":"台州市" } ], "status":1 }, "error_code":0 } resultcode = jmespath.search("resultcode",json_data) print("返回的code:",resultcode) company = jmespath.search("result.company",json_data) print("快递公司:",company) remark = jmespath.search("result.list[1].remark",json_data) print("快递目前到达的地点:",remark) 结果: 返回的code: 200 快递公司: 顺丰 快递目前到达的地点: 快件在 台州 ,准备送往下一站 台州集散中心
3.7jmespath的其他使用方式
•切片
import jmespath source_4 = ["a", "b", "c", "d", "e", "f"] result4 = jmespath.search("[1:3]",source_4) print(repr(result4)) 结果: ['b', 'c']
•投影
投影其实就是初始时定义好格式,然后按照格式的方式进行取值。
投影主要包括以下几种:
List Projections列表投影
Slice Projections切片投影
Object Projections对象投影
Flatten Projections正则投影
Filter Projections过滤条件投影
注意:取列表用[],取字典用.
列表和切片投影
import jmespath source5 = { "people": [ {"first": "James", "last": "d"}, {"first": "Jacob", "last": "e"}, {"first": "Jayden", "last": "f"}, {"missing": "different"} ], "foo": {"bar": "baz"} } result5 = jmespath.search('people[*].first', source5) print(result5) 结果: ['James', 'Jacob', 'Jayden']
对象投影
列表投影是为JSON数组定义的,而对象投影是为JSON对象定义的。
import jmespath source6 = { "ops": { "functionA": {"numArgs": 2}, "functionB": {"numArgs": 3}, "functionC": {"variadic": True} } } result6 = jmespath.search('ops.*.numArgs', source6) print(repr(result6)) 结果: [2, 3]
Filter Projections 带过滤条件投影
格式[? <expression> <comparator> <expression>]
支持 ==, !=, <, <=, >, >=
import jmespath source7 = { "people": [ { "general": { "id": 100, "age": 20, "other": "foo", "name": "Bob" }, "history": { "first_login": "2014-01-01", "last_login": "2014-01-02" } }, { "general": { "id": 101, "age": 30, "other": "bar", "name": "Bill" }, "history": { "first_login": "2014-05-01", "last_login": "2014-05-02" } } ] } result7 = jmespath.search("people[?general.age > `20`].general | [0]", source7) print(repr(result7)) 结果: {'id': 101, 'age': 30, 'other': 'bar', 'name': 'Bill'}
4.自己写个类来处理json数据
class ExtractData: def traverse_take_field(data,fields,values=[],currentKye=None): ''' 遍历嵌套字典列表,取出某些字段的值 :param data: 嵌套字典列表 :param fields: 列表,某些字段 :param values: 返回的值 :param currentKye: 当前的键值 :return: 列表 ''' if isinstance(data,list): for i in data: ExtractData.traverse_take_field(i,fields,values,currentKye) elif isinstance(data,dict): for key,value in data.items(): ExtractData.traverse_take_field(value,fields,values,key) else: if currentKye in fields: values.append(data) return values if __name__ == '__main__': json_data = { "resultcode":"200", "reason":"成功的返回", "result":{ "company":"顺丰", "com":"sf", "no":"575677355677", "list":[ { "datetime":"2013-06-25 10:44:05", "remark":"已收件", "zone":"台州市" }, { "datetime":"2013-06-25 11:05:21", "remark":"快件在 台州 ,准备送往下一站 台州集散中心 ", "zone":"台州市" } ], "status":1 }, "error_code":0 } resultcode = ExtractData.traverse_take_field(data=json_data,fields="resultcode") print("返回的code:",resultcode) 结果: 返回的code: ['200']
目前自己写的这个类还不完善,有以下几个缺点:
1、只能获取最底层的值
2、重复的键例如:remark,获取值后,会把所有的值都获取出来。
3、对于包含的键,无法做出区分,列如:想要获取键company的值,会吧键com的值也一起获取出来。
等有时间可以继续完善。
posted on 2021-01-17 22:40 Test-Admin 阅读(3089) 评论(0) 编辑 收藏 举报

