

python locust的基本使用
python + locust 记录一次性能测试的实施
前言
一直以来都是使用的工具压测系统接口,常用JMETER ,后面学习python,发现还能用脚本去测试系统性能,迫不及待试了一次,记录下
实施
安装python环境是自然要的,加上配置环境变量啥的,这些网上一大把,这里就不详述了。
要用到的python库locust (官方文档:Locust说明文档)
一、认识Locust
1、定义
Locust是一款易于使用的分布式负载测试工具,完全基于事件,即一个locust节点也可以在一个进程中支持数千并发用户,不使用回调,通过gevent使用轻量级过程(即在自己的进程内运行)。
# gevent是第三方库,通过greenlet实现协程。greenlet是python的并行处理的一个库。 python 有一个非常有名的库叫做 stackless ,用来做并发处理, 主要是弄了个叫做tasklet的微线程的东西, 而greenlet 跟stackless的最大区别是greenlet需要你自己来处理线程切换, 就是说,你需要自己指定现在执行哪个greenlet再执行哪个greenlet。
2、特点
①、不需要编写笨重的UI或者臃肿的XML代码,基于协程而不是回调,脚本编写简单易读;
②、有一个基于web简洁的HTML+JS的UI用户界面,可以实时显示相关的测试结果;
③、支持分布式测试,用户界面基于网络,因此具有跨平台且易于扩展的特点;
④、所有繁琐的I / O和协同程序都被委托给gevent,替代其他工具的局限性;
3、locust与jmeter的区别
| 工具 | 区别 |
| jmeter | 需要在UI界面上通过选择组件来“编写”脚本,模拟的负载是线程绑定的,意味着模拟的每个用户,都需要一个单独的线程。单台负载机可模拟的负载数有限 |
| locust | 通过编写简单易读的代码完成测试脚本,基于事件,同样配置下,单台负载机可模拟的负载数远超jmeter |
PS:但locust的局限性在于,目前其本身对测试过程的监控和测试结果展示,不如jmeter全面和详细,需要进行二次开发才能满足需求越来越复杂的性能测试需要。
二、安装Locust
1、支持的python版本:2.7、3.4、3.5、3.6;
2、Windows系统安装locust
①、直接通过 pip install locustio 命令安装;
②、安装成功后可以输入 pip show locust 命令查看是否安装成功,以及通过 locust -help 命令查看帮助信息。
PS:运行大规模测试时,建议在Linux机器上执行此操作,因为gevent在Windows下的性能很差。
三、一个简单的示例
locust里面请求是基于requests的,每个方法请求和requests差不多,请求参数、方法、响应对象和requests一样的使用,之前学过requests库的,这里就非常简单了
- requests.get 对应client.get
- requests.post 对应client.post


1 from locust import HttpLocust,TaskSet,task
2
3 class Demo(TaskSet):
4 '''例子'''
5 @task(1)
6 def baidu(self):
7 url = '/huahuage/p/12917114.html'
8 header = {"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36"}
9 req = self.client.get(url, headers=header, verify=False)
10
11 if req.status_code == 200:
12 print("success")
13 else:
14 print("fails")
15
16 class websitUser(HttpLocust):
17 task_set = Demo
18 min_wait = 3000
19 max_wait = 6000
20
21 if __name__=="__main__":
22 import os
23 os.system("locust -f demo.py --host=https://www.cnblogs.com")
2. 设置tasks的两种方式
from locust import HttpLocust, TaskSet, task
def index(l):
l.client.get("/")
def stats(l):
l.client.get("/stats/requests")
class UserTasks(TaskSet):
# 列出需要测试的任务形式一
tasks = [index, stats]
# 列出需要测试的任务形式二
@task
def page404(self):
self.client.get("/does_not_exist")
class WebsiteUser(HttpLocust):
host = "http://127.0.0.1:8089"
min_wait = 2000
max_wait = 5000
task_set = UserTasks3. 设置登录只运行一次的代码,后续请求不需要再次登录
from locust import HttpUser, TaskSet, task
import subprocess
import json # abc
# 性能测试任务类 TaskSet.
class UserBehavior(TaskSet):
# 登录截取token
def doLogin(self):
# 只写路径即可
login_url = "/login/accountLogin"
# 由于本例中的timestamp和每个接口请求的sign一段时间内是不变的,所以直接使用抓取的接口数据
# 密码可直接从接口中抓取已加密过的数据,也可在脚本中根据规则转换
login_params = {
"_sign": "833e83c223faf3ef446573d05618d150",
"_timestamp": "1626312457295",
"_v": "1.0.0",
"os": "android",
"password": "yourpassword",
"terminal": "1",
"username": "yourname",
"uuid": "youruuid"
}
response = self.client.post(url=login_url, params=login_params)
ret = json.loads(response.content)["results"]["ret"]
if ret == 200:
print(u"登录成功")
print(json.dumps(ret, ensure_ascii=False))
else:
print(u"登录失败")
print(ret)
# 此处获取的token,可在后面的函数中使用
self.token = json.loads(response.content)["results"]["data"]["access_token"]
if self.token != 0:
print(self.token)
return self.token
# 在进行压测前,执行一次
def on_start(self):
print("--------------登录获取token--------------")
self.doLogin()
# 任务,数字表示权重,数字越大,执行的概率越高
@task(1)
def getTagVals(self):
global token
u"""
request_url:请求路径
request_params:请求头参数
request_json:请求json参数
"""
request_url = "/video/commitComment"
request_params = {
"_sign": "833e83c223faf3ef446573d05618d150",
"_timestamp": "1626312457295",
"_v": "1.0.0",
"content": "2222",
"key": "9db6b3345fbd41c7bd42e239e655fce7",
"os": "android",
"terminal": "1",
# 调用获取的token
"token": self.token,
"uuid": "youruuid"
}
response = self.client.post(
url=request_url,
params=request_params,
)
# 这里可以编写自己需要校验的返回内容
content = json.loads(response.content)["results"]["ret"]
if content == 200:
print(u"评论成功")
print(json.dumps(content, ensure_ascii=False))
else:
print(u"评论失败")
print(content)
# 性能测试配置
class MobileUserLocust(HttpUser):
u"""
min_wait :用户执行任务之间等待时间的下界,单位:毫秒。
max_wait :用户执行任务之间等待时间的上界,单位:毫秒。
"""
# weight = 3
tasks = [UserBehavior]
host = "https://*****.cn"
min_wait = 3000
max_wait = 6000
if __name__ == "__main__":
subprocess.Popen("locust -f main_pt.py", shell=True)
这是转载别人的,我自己直接运行这个python文件,提示 terminal is not a tty terminal ,然后就在pycharm下边的terminal下边直接运行locust命令,然后就可以了
另外一点,就是运行了locust命令之后了,只是启动了这个服务,http://localhost:8089,然后在浏览器中输入这个地址,然后输入虚拟用户数和启动时间,然后点击start运行才会真正的开始发情请求
问题1:直接在pycharm下直接运行py文件,提示 terminal is not a tty terminal ,然后就在pycharm下边的terminal下边直接运行locust命令,然后就可以了
问题2:今天开始自己写了请求,开始跑,然后发现在UI的页面的报告的地方,没有显示请求数量,然后对比了一下,因为自己没有调用user de client ,自己直接写请求是不行的,修改后就可以了
requests.post(url=path, data=json.dumps(data), headers=headers, verify=True) ------修改前
res=self.client.post(url=path, data=json.dumps(data), headers=headers, verify=True)--------修改后
问题3:在terminal终端运行时,刚开始切换到当前.py文件所在目录运行,提示找不到引用的模块,然后切换目录至项目的根目录下开始运行,然后就可以了
脚本说明:
新建一个类Demo(TaskSet),继承TaskSet,该类下面写需要请求的接口以及相关信息;
self.client调用get和post方法,和requests一样;
@task装饰该方法表示为用户行为,括号里面参数表示该行为的执行权重:数值越大,执行频率越高,不设置默认是1;
WebsiteUser()类用于设置性能测试。
task_set:指向定义了用户行为的类
min_wait :模拟负载的任务之间执行时等待时间的下界,单位:毫秒
max_wait :模拟负载的任务之间执行时等待时间的上界,单位:毫秒
PS:默认情况下,时间是在min_wait和max_wait之间随机选择,但是可以通过将wait_function设置为任意函数来使用任何用户定义的时间分布。
四、启动Locust
1、如果启动的locust文件名为locustfile.py并位于当前工作目录中,可以在编译器中直接运行该文件,或者通过cmd,执行如下命令:
locust --host=https://www.cnblogs.com
2、如果Locust文件位于子目录下且名称不是locustfile.py,可以使用-f命令启动上面的示例locust文件:
locust -f testscript/locusttest.py --host=https://www.cnblogs.com
3、如果要运行分布在多个进程中的Locust,通过指定-master以下内容来启动主进程 :
locust -f testscript/locusttest.py --master --host=https://www.cnblogs.com
4、如果要启动任意数量的从属进程,可以通过-salve命令来启动locust文件:
locust -f testscript/locusttest.py --salve --host=https://www.cnblogs.com
5、如果要运行分布式Locust,必须在启动从机时指定主机(运行分布在单台机器上的Locust时不需要这样做,因为主机默认为127.0.0.1):
locust -f testscript/locusttest.py --slave --master-host=192.168.0.100 --host=https://cnblogs.com
6、启动locust文件成功后,编译器控制台会显示如下信息:
[2018-10-09 01:01:44,727] IMYalost/INFO/locust.main: Starting web monitor at *:8089
[2018-10-09 01:01:44,729] IMYalost/INFO/locust.main: Starting Locust 0.8
PS:8089是该服务启动的端口号,如果是本地启动,可以直接在浏览器输入http://localhost:8089打开UI界面,如果是其他机器搭建locust服务,则输入该机器的IP+端口即可;
五、locust的UI界面
1、启动界面

Number of users to simulate:设置模拟的用户总数
Hatch rate (users spawned/second):每秒启动的虚拟用户数
Start swarming:执行locust脚本
2、测试结果界面
PS:点击STOP可以停止locust脚本运行:
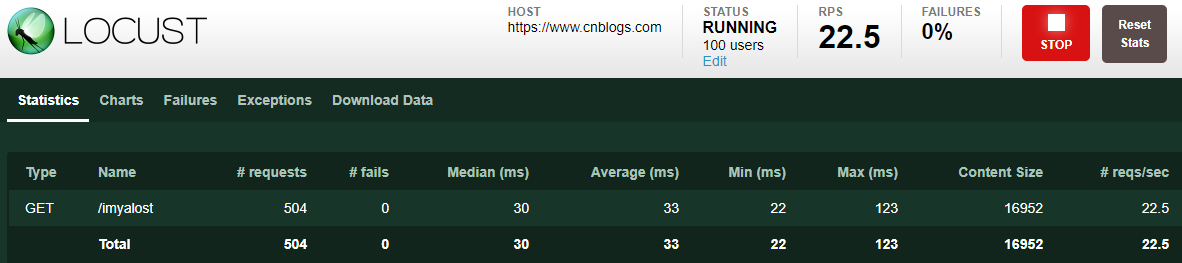
Type:请求类型,即接口的请求方法;
Name:请求路径;
requests:当前已完成的请求数量;
fails:当前失败的数量;
Median:响应时间的中间值,即50%的响应时间在这个数值范围内,单位为毫秒;
Average:平均响应时间,单位为毫秒;
Min:最小响应时间,单位为毫秒;
Max:最大响应时间,单位为毫秒;
Content Size:所有请求的数据量,单位为字节;
reqs/sec:每秒钟处理请求的数量,即QPS;
3、各模块说明
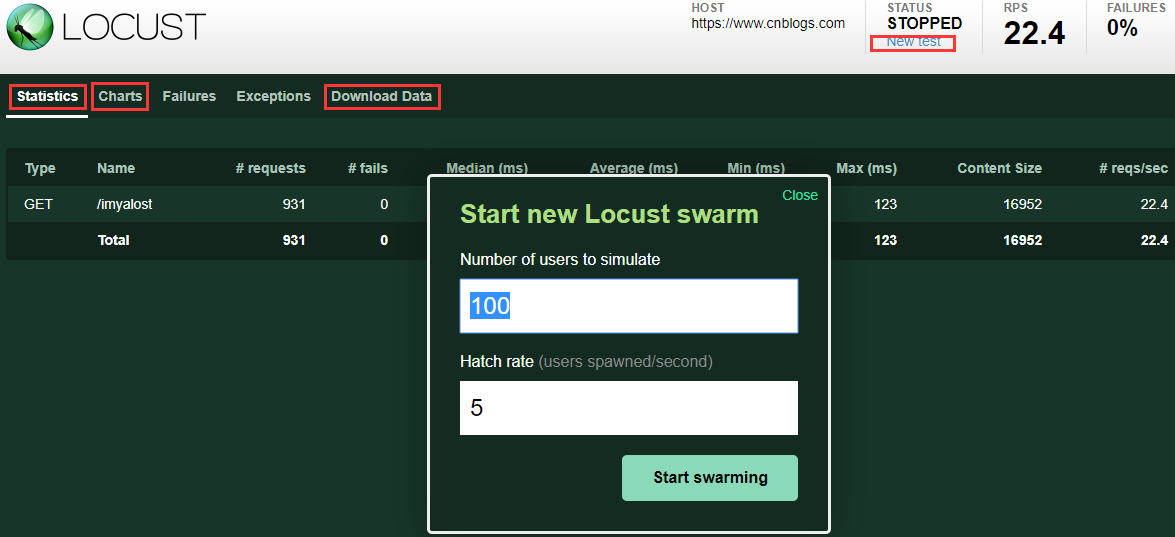
New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑;
Statistics:类似于jmeter中Listen的聚合报告;
Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数;
Failures:失败请求的展示界面;
Exceptions:异常请求的展示界面;
Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions;
*************************************************************************locust命令中文说明*********************************************************************************************************************************
参数中文说明
参数名称 参数值 参数说明
-h, --help 不带参数 查看帮助信息
-H HOST, –host=HOST HOST 指定被测试的主机,采用以格式:http://10.21.32.33
–web-host=WEB_HOST WEB_HOST 指定运行 Locust Web 页面的主机,默认为空 “。
-P PORT, –port=PORT, –web-port=PORT PORT 指定 –web-host 的端口,默认是8089
-f LOCUSTFILE, –locustfile=LOCUSTFILE LOCUSTFILE 指定运行 Locust 性能测试文件,默认为: locustfile.py
–csv=CSVFILEBASE, –csv-base-name=CSVFILEBASE CSVFILEBASE 以CSV格式存储当前请求测试数据。
–master 不带参数 Locust 分布式模式使用,当前节点为 master 节点。
–slave 不带参数 Locust 分布式模式使用,当前节点为 slave 节点。
–master-host=MASTER_HOST MASTER_HOST 分布式模式运行,设置 master 节点的主机或 IP 地址,只在与 –slave 节点一起运行时使用,默认为:127.0.0.1.
–master-port=MASTER_PORT MASTER_PORT 分布式模式运行, 设置 master 节点的端口号,只在与 –slave 节点一起运行时使用,默认为:5557。注意,slave 节点也将连接到这个端口+1 上的 master 节点。
–master-bind-host=MASTER_BIND_HOST MASTER_BIND_HOST 做分布式压测时,指定分机IP。只用于master。如果没有指定,默认是所有可用的IP(即所有标记主机IP的slave)
–master-bind-port=MASTER_BIND_PORT MASTER_BIND_PORT 做分布式压测时,指定分机port。默认是5557与5558。
–no-web no-web -c 和 -r 配合 模式运行测试,需要 -c 和 -r 配合使用.
-c NUM_CLIENTS, –clients=NUM_CLIENTS NUM_CLIENTS 指定并发用户数,作用于 –no-web 模式。
-r HATCH_RATE, –hatch-rate=HATCH_RATE HATCH_RATE 指定每秒启动的用户数,作用于 –no-web 模式。
-t RUN_TIME, –run-time=RUN_TIME RUN_TIME 设置运行时间, 例如: (300s, 20m, 3h, 1h30m). 作用于 –no-web 模式。
-L LOGLEVEL, –loglevel=LOGLEVEL LOGLEVEL 选择 log 级别(DEBUG/INFO/WARNING/ERROR/CRITICAL). 默认是 INFO.
–logfile=LOGFILE LOGFILE 日志文件路径。如果没有设置,日志将去 stdout/stderr
–print-stats 不带参数 在控制台中打印数据
–only-summary 不带参数 只打印摘要统计
–no-reset-stats 不带参数 Do not reset statistics once hatching has been completed。
-l, –list 不带参数 显示测试类, 配置 -f 参数使用
–show-task-ratio 不带参数 打印 locust 测试类的任务执行比例,配合 -f 参数使用.
–show-task-ratio-json 不带参数 以 json 格式打印 locust 测试类的任务执行比例,配合 -f 参数使用.
-V, –version 不带参数 查看当前 Locust 工具的版本.
————————————————
版权声明:本文为CSDN博主「全栈测试开发日记」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liudinglong1989/article/details/106991650/
转载:https://www.cnblogs.com/huahuage/p/12917114.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律