

Spring Data JPA注解@Version乐观锁是如何实现的
背景介绍
@Version是jpa里提供的一个注解,其作用是用于实现乐观锁。在JPA的帮助下实现乐观锁十分简单,只需将我们的一个java的entity加上一个由@version修饰的字段即可。然后我们每次去对这个entity进行更新操作的时候,JPA就会去比较这个version并且在操作成功之后自动更新它,若version与当前数据库的不匹配,则更新操作失败并抛出下面这个异常javax.persistence.OptimisticLockException。
下面是一个使用注解@Version的entity的例子代码
@Entity
@Table(name = "PRODUCT")
public class Product {
@Id
@Column(name = "ID")
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NotNull
@Column(name = "NAME")
private String name;
@Version
@Column(name = "VERSION")
private Integer version;
...
}在这个例子当中,我们定义了一个Integer类型的version作为用于检测的字段。这是比较常见的方式,还有一种方式是定义一个Date类型的字段作为检测的字段,使用哪种类型通常取决于所使用的jpa实现以及每个应用程序的实际情况。在JPA的帮助下,我们只需要按上述定义我们的Entity,就能实现乐观锁的效果。
那么JPA是如何实现乐观锁的呢?这是本篇博客主要想要探究的问题。
什么是JPA
在介绍乐观锁之前我们不妨先来看一下JPA是个什么样的东西。JPA全称是Java Persistence API,这是一套用来持久化存储数据到数据库的类和方法的集合。JPA主要是为了减轻程序员为关系对象编写代码的负担,使用JPA框架允许与数据库实例轻松交互。由于JPA本身只是一套开源的API,因此很多企业都有对它进行自己的实现,我们比较常见的包括Hibernate, Eclipselink, Toplink, Spring Data JPA等等。知道了JPA的作用之后,我们就更好理解为什么它会来实现数据更新的乐观锁的相关功能了。
什么是乐观锁?使用场景是什么?
乐观锁即Optimistic lock本质上是一个用来防止更新丢失的机制。所谓更新丢失指的是一种用户并发操作下可能会发生的场景。假设我们现在有两个用户,他们都有操作相同数据的权限,这两个用户现在都拿到了当前数据库最新的数据。这时其中一个用户更改了一部分数据,保存进了数据库,另一个用户又更改了另一部分数据并保存进了数据库,那么第二个用户的操作就会把第一个用户更新的数据冲掉。
这就是乐观锁要避免的场景。所谓乐观锁,就是指上面的第二个用户是可以编辑它已经过时的数据并保存的,只是最后保存的时候他会得到一个异常。
乐观锁的效果如下图所示:
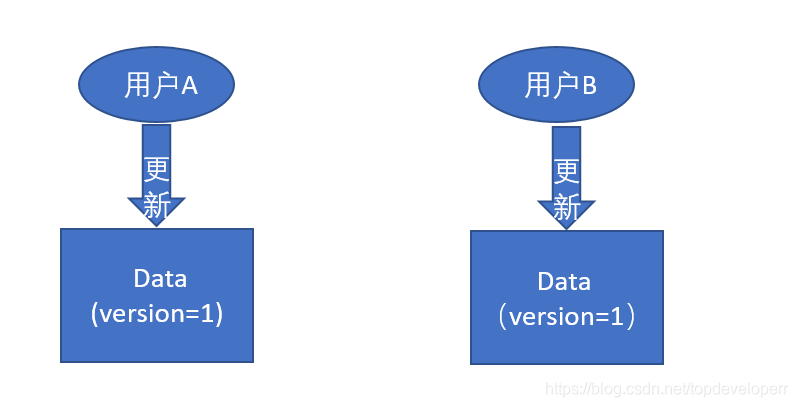
用户A和用户B同时对version为1的数据进行操作,那么只有先更新的用户能操作成功,后更新的用户则会因为数据不是最新的而更新失败,如下所示:
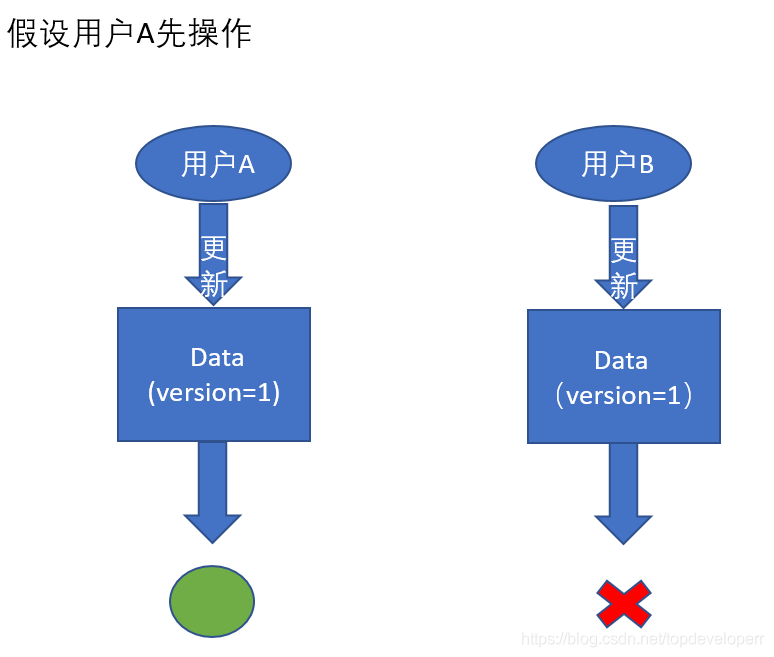
A用户先更新会成功,而B用户则会失败,抛出乐观锁异常,这就是乐观锁的效果.
JPA乐观锁的实现原理
我们在上面已经提到了JPA是通过在一个数据库表对应的Entity当中添加一个特殊的字段来使用乐观锁的。在添加这个特殊字段之后,数据库表里面的每一行记录也就多了这么一个字段,事实上这本质是是数据库的一种行级锁。因此我们完全可以先抛开乐观锁来看一下数据库的行级锁。
数据库的行级锁

针对以上这个数据库表,如果有两个不同的事务尝试更新同一条记录,则后一个执行修改更新语句的事务将被会一直被锁定到第一个事务完成其工作(第一个事务有可能是提交或回滚)。例如:
事务一:
-
BEGIN;
-
UPDATE PRODUCT
-
SET NAME = "Car new"
-
WHERE ID = 1;
-
COMMIT;
事务二:
-
BEGIN;
-
UPDATE PRODUCT
-
SET NAME = "Car new 1"
-
WHERE ID = 1;
-
COMMIT;如果事务一和二碰巧在执行期间同时执行上述各个语句,则其中一个语句肯定会在该更新语句上被锁定,直到另一个事务完成,这一点是由数据库保证的,这也是数据库的基本职责之一。 其原因就是他们正在更新相同的记录,即主键都为ID = 1的记录。 数据库将锁定该记录的所有修改,直到持有锁的事务完成其工作。
乐观锁
现在,有了上述知识之后,我们再来看乐观锁的实现就非常容易了。正如之前提到的一样,乐观锁的实现是依赖于更新执行期间的数据比较。 这意味着我们需要一个可用于此比较的字段,或字段集合,比如我们在前面定义的version字段。下面我们就来看一下使用另一个名为version的字段的场景:

乐观锁的实现原理是,任何要更新某条记录的事务必须首先读取该记录,以便知道当前version字段的值,在之后的update语句也需要用到该值。
假设现在有一个事务要更新上表中ID为1的记录。那么首先它将读取这条记录,获取当前这条记录的version值,这个事务不仅需要将当前的version和它读到的做校验,同时还要在校验成功之后将version值更新成另一个值,这里所谓的做校验,就是将这个读到的version值放当sql语句的where条件里面即可。下面是一个例子:
-
UPDATE PRODUCT
-
SET NAME = "new name", VERSION = 3
-
WHERE ID = 1 AND VERSION = 2;
而数据库中有一个机制是在一条语句执行之后返回更新的数据的数量,那么在这条语句的事务执行之后,自然也会返回一个count,因此作为jpa的实现者可以通过count判定是否更新成功了,若count为1则代表执行成功,若count为0则表示更新失败,而更新失败则说明此时另一个事务已经更新了这条数据,jpa实现通常会返回一个OptimisticLockException.
以postgresql数据库为例,执行一个更新一条记录的语句成功之后,可以看到下面的message:

这里的one row affected,就表明更新的数据数量为1.
再看我们上面的例子,如果在这条语句执行时没有其他事务同时更改了该记录,则VERSION值仍然是2,where条件满足,因此数据库返回的更新的数据行数将是预期的:1。这样,应用程序就能知道没有其他并发更新发生,可以继续安全地提交更改。
一句话总结起来:jpa实现更新时将version值置于sql语句的where条件当中,去尝试更新(乐观的),通过返回的更新条数判断是否更新成功。
哪些数据类型可以作为乐观锁的判定条件
如果系统可以更改Integer,Long等类型,则使用这样的字段通常是一个好的选择。
我们也可以使用一个Date类型的变量来实现。但是如果极端的并发情况超越了我们数据库的时间粒度,则这种锁可能会fail
还有一种比较昂贵的实现方式则是把整个entity作为一个判定对象。
其他
乐观锁只适用于我们的系统由于某些业务需求而无法容忍丢失的更新现象,当然,也有许多系统丢失更新根本不是问题,因此乐观锁多他们来说并不适用。
在某些情况下,当version的更新与batch的操作一起使用时,可能会出现问题。有一个例子是Oracle JDBC驱动程序无法在JDBC批处理语句执行中提取正确数量的更新行计数。如果我们还遇到此问题,可以检查是否已将Hibernate属性hibernate.jdbc.batch_versioned_data设置为true。当此设置为true时,即使针对版本化数据进行更新,Hibernate也将使用批量更新。Hibernate中此设置的默认值为false,因此当它检测到将在给定的刷新操作中执行版本化数据更新时,将不会使用批量更新。
此外我们不难看出乐观锁定实际上并不是真正的DB的锁。 它只是通过比较版本列的值来工作。 并不会阻止其他进程访问任何数据。

