python3 Tornado + Celery + RabbitMQ
celery有多坑,能坑的你亲妈都不认识,信我!!!
声明:代码是从项目中截取的, 为进行测试
使用Celery任务队列,Celery 只是一个任务队列,需要一个broker媒介,将耗时的任务传递给Celery任务队列执行,执行完毕将结果通过broker媒介返回。官方推荐使用RabbitMQ作为消息传递,redis也可以
一、Celery 介绍:概念网上一搜一堆,自己百度去
注意:
1、当使用RabbitMQ时,需要按照pika第三方库,pika0.10.0存在bug,无法获得回调信息,需要按照0.9.14版本即可
2、tornado-celery 库比较旧,无法适应Celery的最新版,会导致报无法导入task Producter包错误,只需要将celery版本按照在3.0.25就可以了
二、安装、配置

python版本3.5.4 别用3.6, 也别用3.7,很多不支持,巨坑无比
redis 5.0.8.msi ----------- rabbitmq 这个应该没什么差异
pip install redis
pip3 install tornado==5.1.1 或者4.1
pip3 install celery==3.1
pip3 install pika==0.9.14
pip3 install tornado-celery
三、window下面测试最简单celery有返回值的实例--时间:2020/7/17
用redis和rabbitmq效率差的不是一点半点
tasks.py
from celery import Celery
#配置好celery的backend和broker
# app = Celery('tasks', backend='redis://localhost:6379/0', broker='redis://localhost:6379/0')
# app = Celery('tasks', backend='redis://localhost:6379', broker='redis://localhost:6379')
app = Celery('tasks', backend='amqp://localhost:5672', broker='amqp://localhost:5672')
# app.conf.CELERY_RESULT_BACKEND = "redis://localhost:6379/0"
# app.conf.CELERY_RESULT_BACKEND = "redis"
# app.conf.CELERY_ACCEPT_CONTENT = ['application/json']
# app.conf.CELERY_TASK_SERIALIZER = 'json'
# app.conf.CELERY_RESULT_SERIALIZER = 'json'
# app.conf.BROKER_HEARTBEAT = 30
# app.conf.CELERY_IGNORE_RESULT = False # this is less important
@app.task #普通函数装饰为 celery task
def add(x, y):
return x + y


#trigger.py
import time
from tasks import add
a = time.time()
result = add.delay(4, 4) #不要直接 add(4, 4),这里需要用 celery 提供的接口 delay 进行调用
# result = add.apply_async((4, 4)) #不要直接 add(4, 4),这里需要用 celery 提供的接口 apply_async 进行调用
print(result.ready())
# while not result.ready():
# time.sleep(1)
print('task done: {0}'.format(result.get()))
print(time.time() - a)
celery启动命令当前目录下
celery -A tasks worker --loglevel=info
升级版window下面测试最简单celery有返回值的实例(简单的调整了一下)



config.py
# file_name=init_celery.py # coding: utf-8 from celery import Celery BROKER_URL = 'amqp://localhost:5672' BACKEND_URL = 'amqp://localhost:5672' # Add tasks here CELERY_IMPORTS = ( 'tasks', ) celery = Celery('celery', broker=BROKER_URL, backend=BACKEND_URL, include=CELERY_IMPORTS, ) celery.conf.update( CELERY_ACKS_LATE=True, # 允许重试 CELERY_ACCEPT_CONTENT=['pickle', 'json'], CELERYD_FORCE_EXECV=True, # 有些情况可以防止死锁 CELERYD_CONCURRENCY=4, # 设置并发worker数量 CELERYD_MAX_TASKS_PER_CHILD=500, # 每个worker最多执行500个任务被销毁,可以防止内存泄漏 BROKER_HEARTBEAT=0, # 心跳 CELERYD_TASK_TIME_LIMIT=12 * 30, # 超时时间 )
main.py
from tasks import add def notify(a, b): result = add.delay(a, b) print("ready: ", result.ready()) print('return data: {0}'.format(result.get())) return result if __name__ == '__main__': import time a = time.time() haha = notify(6, 7) print("status: ", haha.status) print("id: ", haha.id) print("used time: %s s" % (time.time() - a))
tasks.py
from config import celery # 普通函数装饰为 celery task @celery.task def add(x, y): return x + y
run_celery.sh --当前目录下执行
celery -A config worker --loglevel=info
Python3.5.4 Tornado + Celery + Redis 得到Celery返回值(时间:2020/7/18记录)看到这,后面的就不用看了,这个例子最新
这个问题困扰我很久,今天终于解决了,为什么呢?因为呀过几天有个面试,可能涉及这个问题,所以熬了几天终于把这个问题给解决了
其实这个问题已经拖了几年了,原因是以前我用的是tornado+celery+rabbitmq,不需要返回值,直接去处理任务就好了,可是当时思考我如果需要拿返回值怎么办
后来就在这个地方卡住了,怎么也没找到正确的解决方法,因为一直认为是自己的写法或者没搞明白原理,而没有间接的去寻找解决方案
首先先把Tornado + Celery + RabbitMQ得不到返回值的解决方案说一下
用RabbitMQ的好处是,RabbitMQ的效率比Redis的效率要高,但为什么redis能拿到返回值呢
因为pika,它连接了redis,而celery把值存储到了redis,这个时候生成了有个key存储到redis,然后tornado这面在从redis取值,知道了这个原理,那后面也就好说了
tornado + celery + redis的redis这里既充当了消息队列,还用到了redis的缓存
解决方案:
tornado也生成一个key,给celery,然后celery的task的函数(例如add)把返回值存储到缓存里面,tornado在去取就行了呀
rabbitmq充当消息队列,redis充当缓存角色
版本
python版本3.5.4 别用3.6, 也别用3.7,很多不支持,巨坑无比
redis 5.0.8.msi ----------- rabbitmq 这个应该没什么差异
pip install redis
pip3 install tornado==5.1.1 或者4.1
pip3 install celery==3.1
pip3 install pika==0.9.14
pip3 install tornado-celery
app.py --- 这里tcelery感觉并没有起到什么作用,如果谁有时间可以进行一下测试,看看
import tornado.ioloop import tornado.web from tornado import gen from tornado.gen import coroutine from tornado.web import asynchronous import tcelery from tasks import test tcelery.setup_nonblocking_producer() # 设置为非阻塞生产者,否则无法获取回调信息 class MainHandler(tornado.web.RequestHandler): @coroutine @asynchronous def get(self): import time a = time.time() # result = yield torncelery.async_me(test, "hello world") #不能这么用 # result = yield gen.Task(test.apply_async, args=["hello11"]) # 不能这么用 result = test.delay("hello world") print("result: ", result.get()) print("ready: ", result.ready()) print("status: ", result.status) print("id: ", result.id) b = time.time() print(b-a) self.write("%s" % result.get()) self.finish() application = tornado.web.Application([ (r"/", MainHandler), ]) if __name__ == "__main__": application.listen(8888) tornado.ioloop.IOLoop.instance().start()
tasks.py
from celery import Celery import time celery = Celery('tasks', backend='redis://localhost:6379', broker='redis://localhost:6379') # celery = Celery('tasks', backend='amqp://localhost:5672', broker='amqp://localhost:5672') celery.conf.update( CELERY_ACKS_LATE=True, # 允许重试 CELERY_ACCEPT_CONTENT=['pickle', 'json'], CELERYD_FORCE_EXECV=True, # 有些情况可以防止死锁 CELERYD_CONCURRENCY=4, # 设置并发worker数量 CELERYD_MAX_TASKS_PER_CHILD=500, # 每个worker最多执行500个任务被销毁,可以防止内存泄漏 BROKER_HEARTBEAT=60, # 心跳 CELERYD_TASK_TIME_LIMIT=12 * 30, # 超时时间 ) @celery.task def test(strs): print("str:", strs) return strs
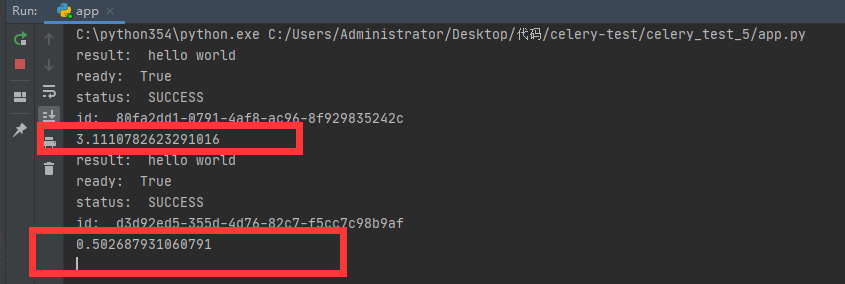
这里有一个问题,就是响应时间,第一次是3s,以后每次都是0.5s,如何提升效率
配置详情
单个参数配置: app.conf.CELERY_RESULT_BACKEND = ‘redis://localhost:6379/0‘
多个参数配置: app.conf.update( CELERY_BROKER_URL = ‘amqp://guest@localhost//‘, CELERY_RESULT_BACKEND = ‘redis://localhost:6379/0‘ )
从配置文件中获取:(将配置参数写在文件app.py中)
BROKER_URL=‘amqp://guest@localhost//‘ CELERY_RESULT_BACKEND=‘redis://localhost:6379/0‘ app.config_from_object(‘celeryconfig‘)
三、案例 --这个也有问题了
启动一个Celery 任务队列,也就是消费者:
from celery import Celery celery = Celery(‘tasks‘, broker=‘amqp://guest:guest@119.29.151.45:5672‘, backend=‘amqp‘) 使用RabbitMQ作为载体, 回调也是使用rabbit作为载体 @celery.task(name=‘doing‘) #异步任务,需要命一个独一无二的名字 def doing(s, b): print(‘开始任务‘) logging.warning(‘开始任务--{}‘.format(s)) time.sleep(s) return s+b
命令行启动任务队列守护进程,当队列中有任务时,自动执行 (命令行可以放在supervisor中管理)
--loglevel=info --concurrency=5
记录等级,默认是concurrency:指定工作进程数量,默认是CPU核心数
启动任务生产者 -- 当初写这个代码的时候没想好可能,现在的重新弄一下了
#!/usr/bin/env python # -*- coding:utf-8 -*- import tcelery from tornado.web import RequestHandler import tornado tcelery.setup_nonblocking_producer() # 设置为非阻塞生产者,否则无法获取回调信息 class MyMainHandler(RequestHandler): @tornado.web.asynchronous @tornado.gen.coroutine def get(self, *args, **kwargs): print('begin') result = yield tornado.gen.Task(sleep.apply_async, args=[10]) # 使用yield 获取异步返回值,会一直等待但是不阻塞其他请求 print('ok - -{}'.format(result.result)) # 返回值结果 # sleep.apply_async((10, ), callback=self.on_success) # print(‘ok -- {}‘.format(result.get(timeout=100)))#使用回调的方式获取返回值,发送任务之后,请求结束,所以不能放在处理tornado的请求任务当中,因为请求已经结束了,与客户端已经断开连接,无法再在获取返回值的回调中继续向客户端返回数据 # result = sleep.delay(10) #delay方法只是对apply_async方法的封装而已 # data = result.get(timeout=100) #使用get方法获取返回值,会导致阻塞,相当于同步执行 def on_success(self, response): # 回调函数 print('Ok - - {}'.format(response))
=======================
#!/usr/bin/env python # -*- coding:utf-8 -*- from tornado.web import Application from tornado.ioloop import IOLoop import tcelery from com.analysis.handlers.data_analysis_handlers import * from com.analysis.handlers.data_summary_handlers import * from com.analysis.handlers.data_cid_sumjson_handler import Cid_Sumjson_Handler from com.analysis.handlers.generator_handlers import GeneratorCsv, GeneratorSpss Handlers = [ (r"/single_factor_variance_analysis/(.*)", SingleFactorVarianceAnalysis), # 单因素方差检验 ] if __name__ == "__main__": tcelery.setup_nonblocking_producer() application = Application(Handlers) application.listen(port=8888, address="0.0.0.0") IOLoop.instance().start()
#!/usr/bin/env python # -*- coding:utf-8 -*- import tornado.gen import tornado.web from com.analysis.core.base import BaseAnalysisRequest from com.analysis.tasks.data_analysis import * class SingleFactorVarianceAnalysis(BaseAnalysisRequest): @tornado.gen.coroutine def get(self, *args, **kwargs): response = yield self.celery_task(single_factor_variance_analysis.apply_async, params=args) print(response.result) self.write(response.result[2])
#!/usr/bin/env python # -*- coding:utf-8 -*- from collections import defaultdict import pandas as pd import numpy as np import pygal import tornado.gen from pygal.style import LightStyle from tornado.web import RequestHandler import json from com.analysis.db.db_engine import DBEngine from com.analysis.utils.log import LogCF from com.analysis.handlers.data_cid_sumjson_handler import cid_sumjson class BaseRequest(RequestHandler): def __init__(self, application, request, **kwargs): super(BaseRequest, self).__init__(application, request, **kwargs) class BaseAnalysisRequest(BaseRequest): def __init__(self, application, request, **kwargs): super(BaseAnalysisRequest, self).__init__(application, request, **kwargs) @tornado.gen.coroutine def celery_task(self, func, params, queue="default_analysis"): args_list = list(params) args_list.insert(0, "") response = yield tornado.gen.Task(func, args=args_list, queue=queue) raise tornado.gen.Return(response)
#!/usr/bin/env python # -*- coding:utf-8 -*- from celery import Celery from com.analysis.core.chi_square_test import CST from com.analysis.generator.generator import GeneratorCsv, GeneratorSpss celery = Celery( 'com.analysis.tasks.data_analysis', broker='amqp://192.168.1.1:5672', include='com.analysis.tasks.data_analysis' ) celery.conf.CELERY_RESULT_BACKEND = "amqp://192.168.1.1:5672" celery.conf.CELERY_ACCEPT_CONTENT = ['application/json'] celery.conf.CELERY_TASK_SERIALIZER = 'json' celery.conf.CELERY_RESULT_SERIALIZER = 'json' celery.conf.BROKER_HEARTBEAT = 30 celery.conf.CELERY_IGNORE_RESULT = False # this is less important logger = Logger().getLogger() @celery.task() def single_factor_variance_analysis(*args): return SFV().do_(*args)
作者:沐禹辰
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
出处:http://www.cnblogs.com/renfanzi/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 字符编码:从基础到乱码解决
2017-09-04 C艹目录
2017-09-04 C艹重复输入小方法,for循环+while